Downloaded 13 times












![Extend the Phoenix:
A Shared-memory MapReduce Model
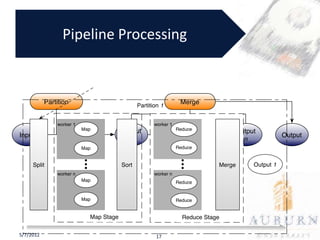
• Extend the Phoenix MapReduce Programming
Model by partitioning and merging
– New API: partition_input
– New Functions:
• partition (provided by the new API)
• merge (Develop by user)
• Example:
– wordcount [data-file][partition-size][]
5/7/2012 16](https://image.slidesharecdn.com/zhiyang-dissertation-defense-2011-120507213236-phpapp02/85/An-Active-and-Hybrid-Storage-System-for-Data-intensive-Applications-16-320.jpg)

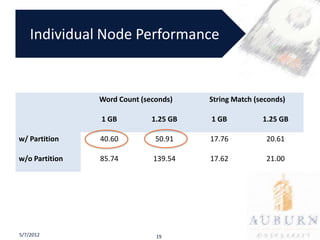





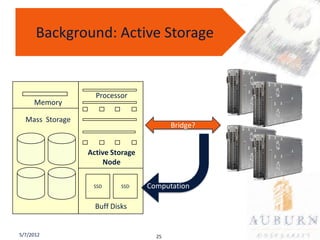


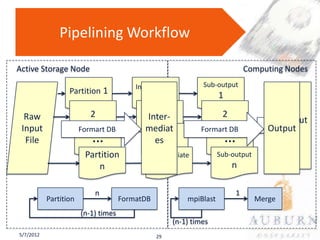

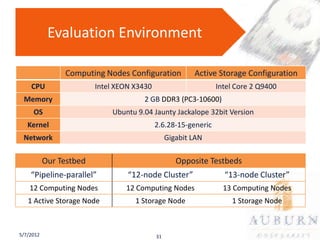
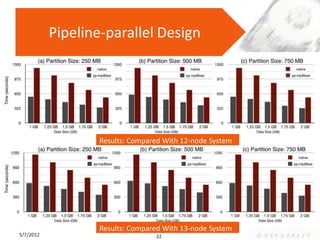
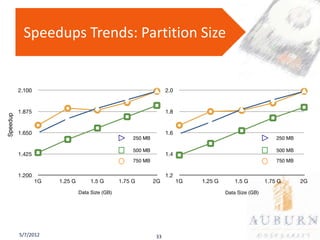




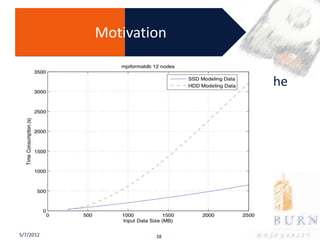



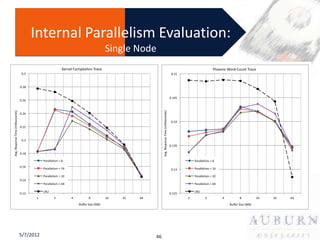
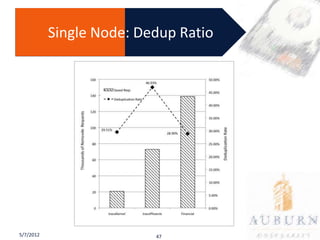
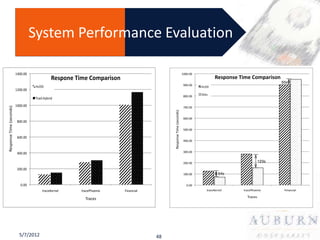
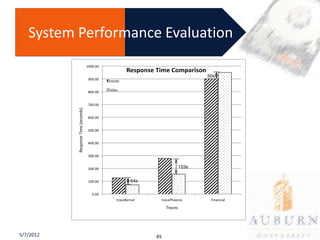





The document presents a PhD defense on an active and hybrid storage system aimed at improving data-intensive applications through the use of multicore active storage devices (MCSD) and a pipeline-parallel processing model. The research includes the design and evaluation of a prototype and discusses contributions such as pre-assembled processing modules and the extension of shared-memory MapReduce systems. The findings suggest that the proposed systems enhance performance by offloading computations and reducing I/O traffic.

































































































