


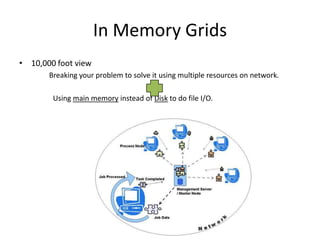
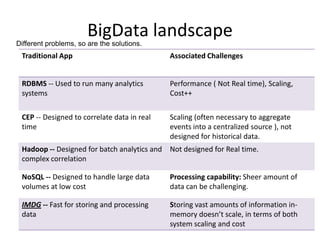

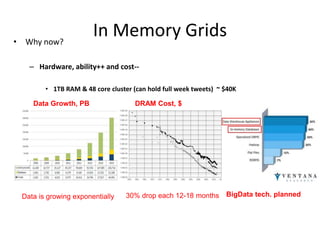


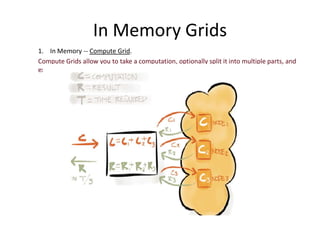


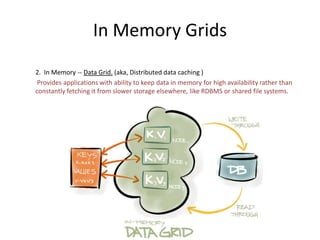






1. In Memory Grids break problems into parts that can be solved using multiple resources on a network, using main memory instead of disk for faster file I/O. 2. In Memory Compute Grids allow computation tasks to be split and executed in parallel across grid nodes, while In Memory Data Grids provide applications with the ability to keep frequently accessed data in memory across multiple JVMs for high availability and low latency access. 3. Reference architectures show how In Memory Grids distribute data, computation tasks, and resources across a cluster for real-time processing of large datasets.



































![[오픈소스컨설팅]오픈소스 클라우드 개발플랫폼_및_Docker의_이해_v1](https://cdn.slidesharecdn.com/ss_thumbnails/dockerv2-140827202405-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







































