Downloaded 490 times





























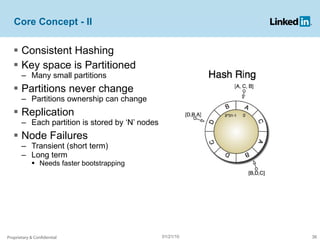

![Core Concepts - IV Vector Clock [Lamport] provides way to order events in a distributed system. A vector clock is a tuple {t1 , t2 , ..., tn } of counters. Each value update has a master node When data is written with master node i, it increments ti. All the replicas will receive the same version Helps resolving consistency between writes on multiple replicas If you get network partitions You can have a case where two vector clocks are not comparable. In this case Voldemort returns both values to clients for conflict resolution Proprietary & Confidential 01/21/10](https://image.slidesharecdn.com/hadoopusergroupjan2010-100121124010-phpapp01/85/Voldemort-Hadoop-Linkedin-Hadoop-User-Group-Jan-2010-38-320.jpg)

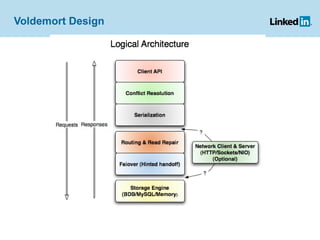




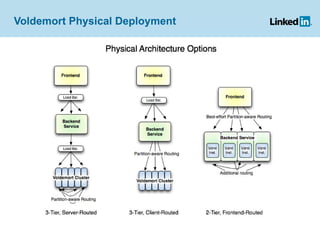





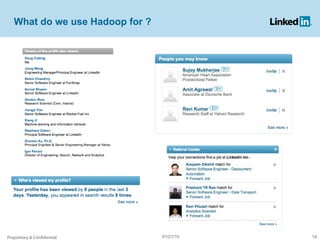
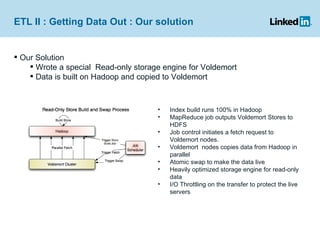
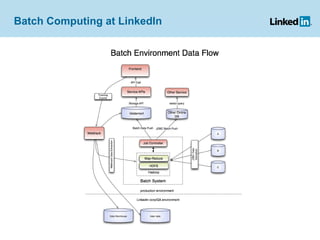
Project Voldemort is a distributed key/value storage system used by LinkedIn, based on concepts from Amazon Dynamo and memcached, providing high availability, scalability, and consistency despite failures. It features an administrative interface for dynamic rebalancing of clusters and supports performance optimizations and testing through a cloud-based framework. The document discusses various functionalities, including how data is stored, managed, and served, as well as addressing challenges like failures in distributed systems and ensuring efficient ETL processes.































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)



