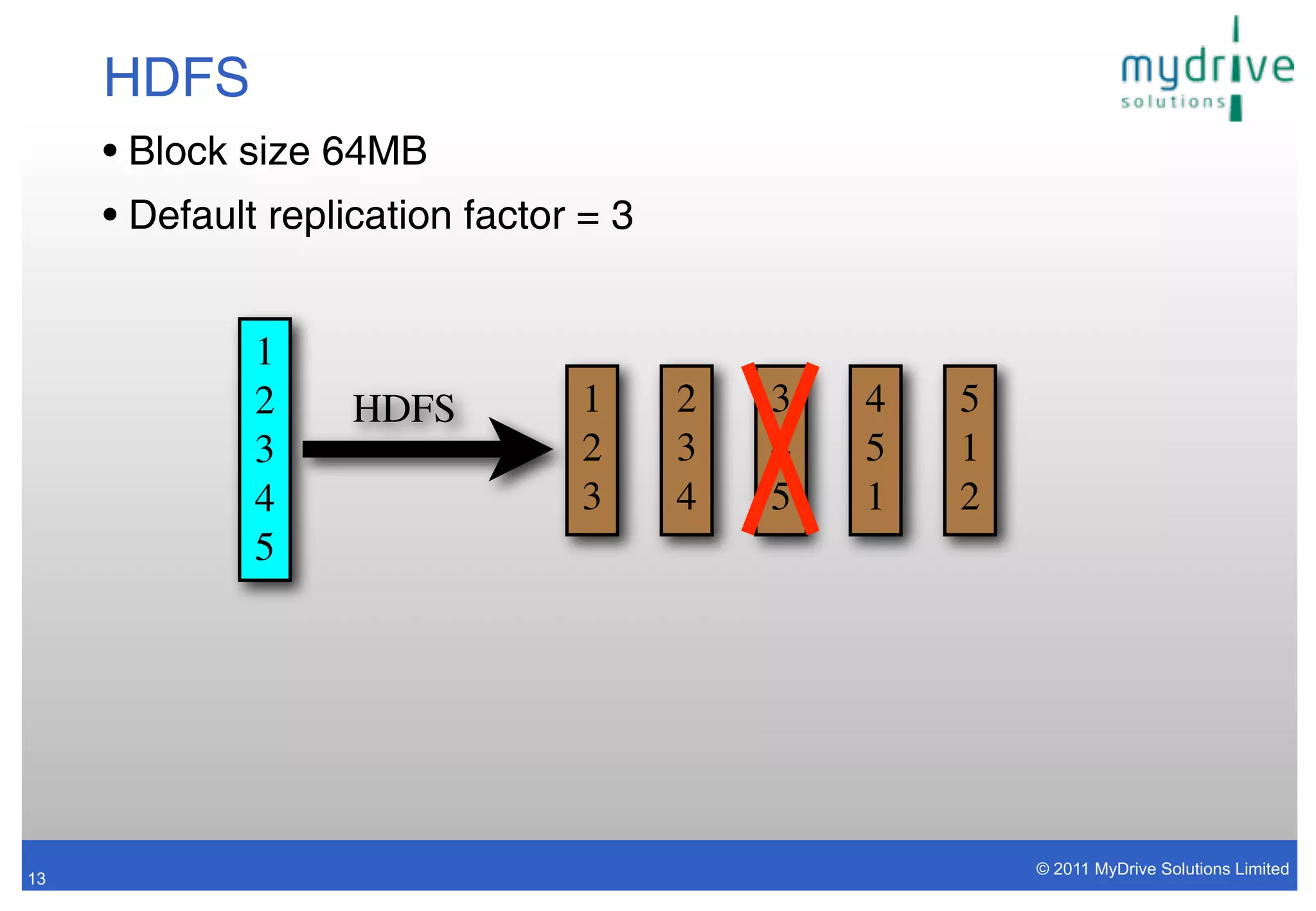
The document discusses the use of Apache Hadoop for managing and analyzing big data, particularly in the context of MyDrive Solutions, which focuses on improving driving safety and fuel economy using GPS data. It highlights the challenges associated with large data volumes and the capabilities of Hadoop, including its distributed computing platform and the MapReduce programming model. The document also outlines various tools within the Hadoop ecosystem, such as Pig and Hive, for data analysis and processing.












![MapReduce
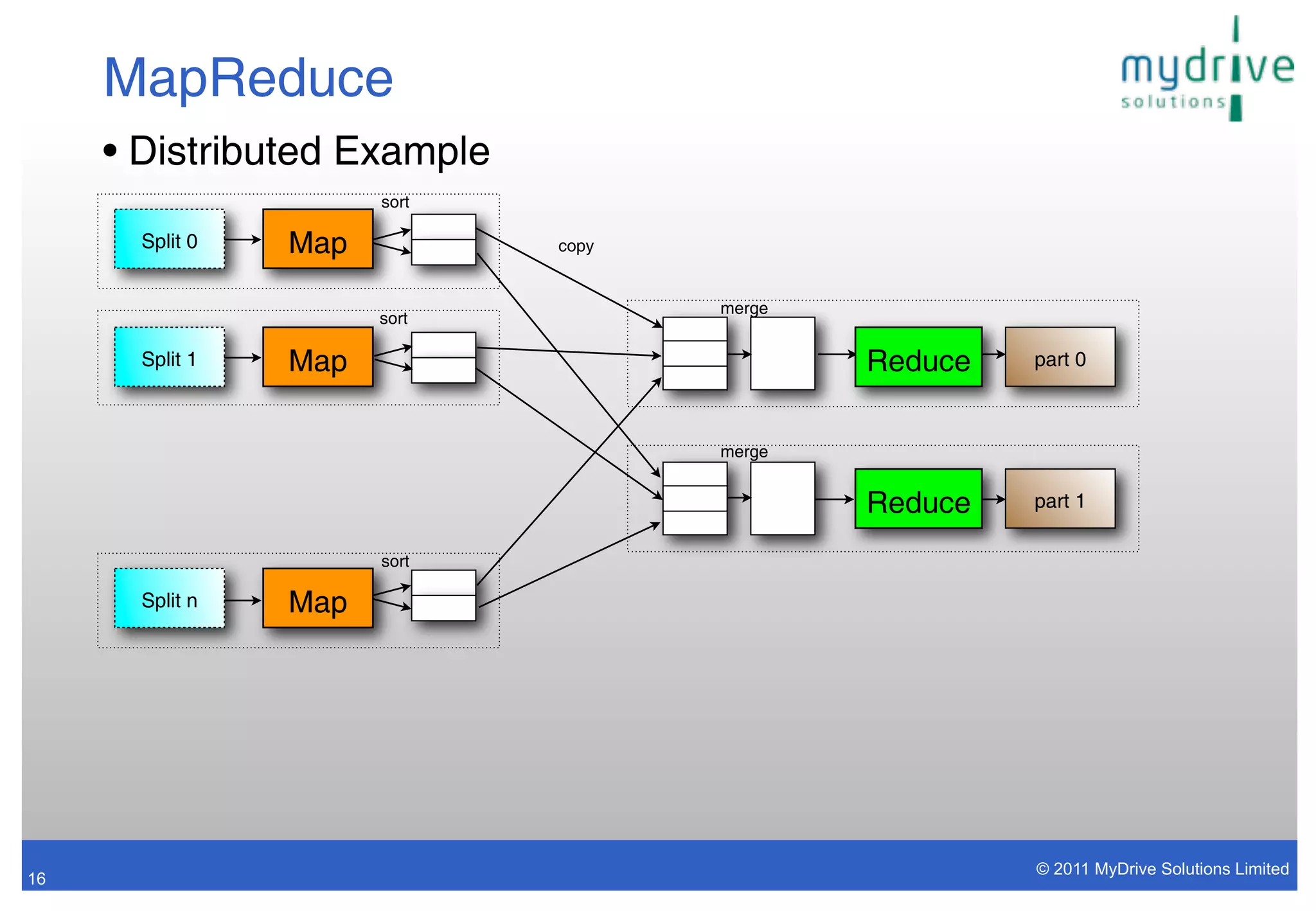
• “Single Threaded” MapReduce:
cat input/* | map | sort | reduce > output
• Map program parses the input and emits [key,value] pairs
• Sort by key
Reduce
Map Sort
• Extrapolate to PB of data on thousands of nodes
© 2011 MyDrive Solutions Limited
15](https://image.slidesharecdn.com/hadoop-accu2010copy-110725071753-phpapp02/75/Introduction-to-Hadoop-ACCU2010-16-2048.jpg)