Download as PDF, PPTX



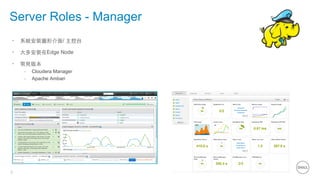
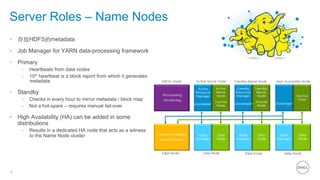
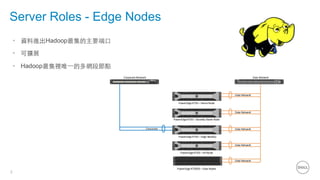


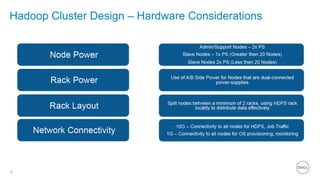


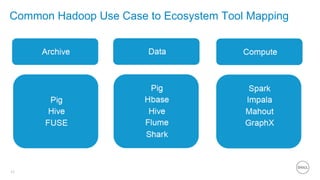
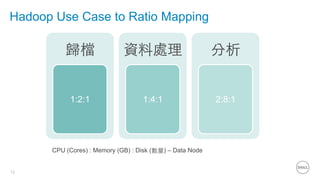

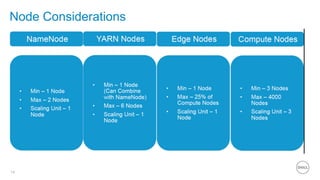



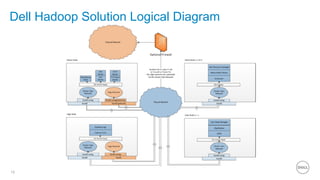
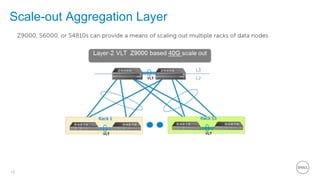


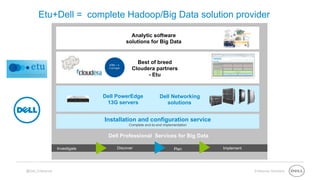
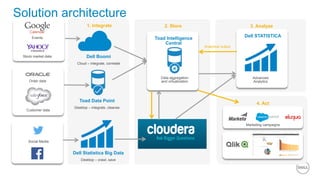




This document summarizes the roles of servers in a Hadoop cluster, including manager, name nodes, edge nodes, and data nodes. It discusses hardware considerations for Hadoop cluster design like CPU to memory to disk ratios for different use cases. It also provides an overview of Dell's Hadoop solutions that integrate PowerEdge servers, Dell Networking switches, and support from Etu for analytic software and Dell Professional Services for implementation. It briefly discusses futures around in-memory processing and virtualized Hadoop deployments.













![[db tech showcase Tokyo 2015] D25:The difference between logical and physical...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d25oracledbvisit-software-150619090737-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




























































































