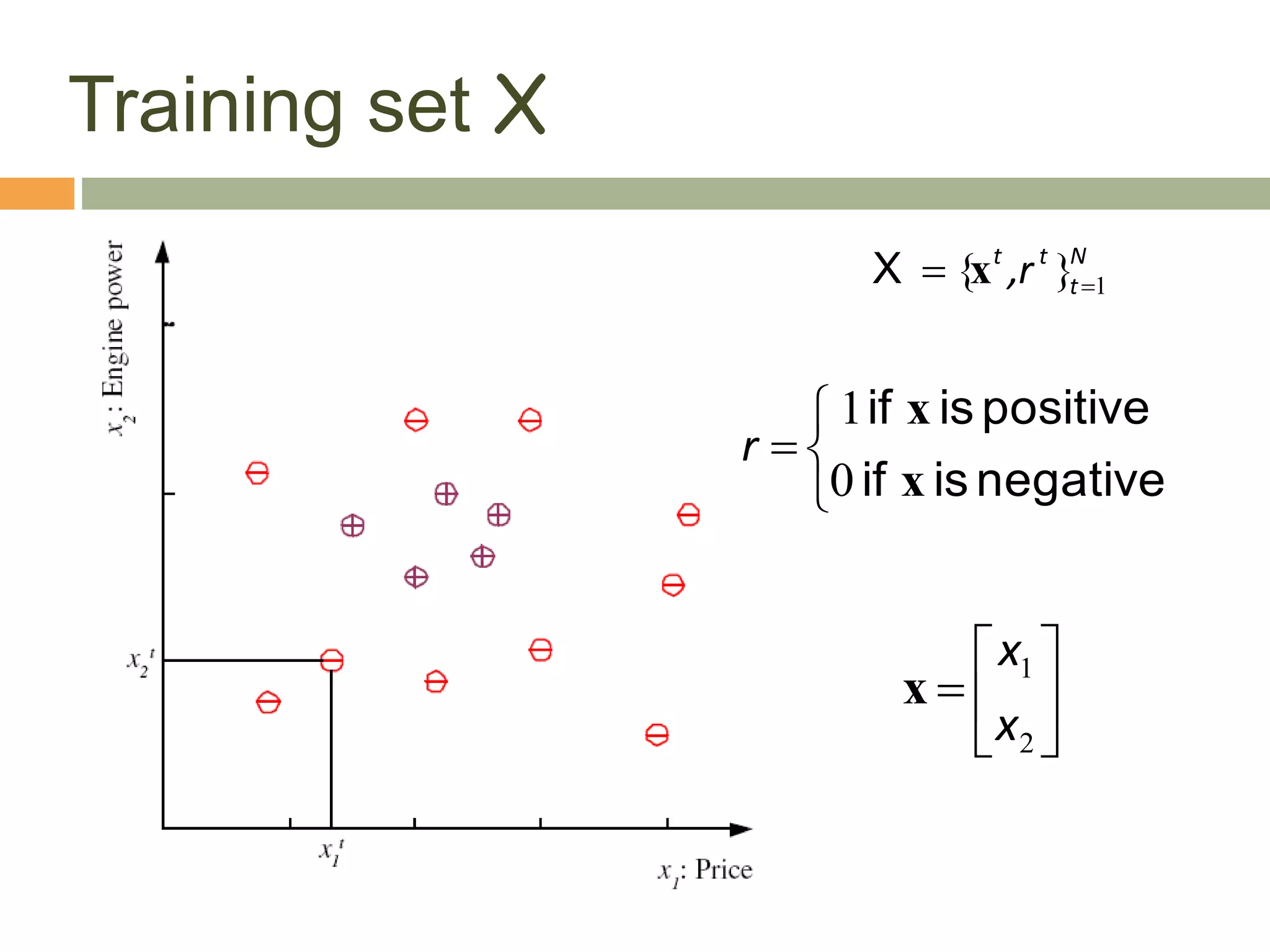
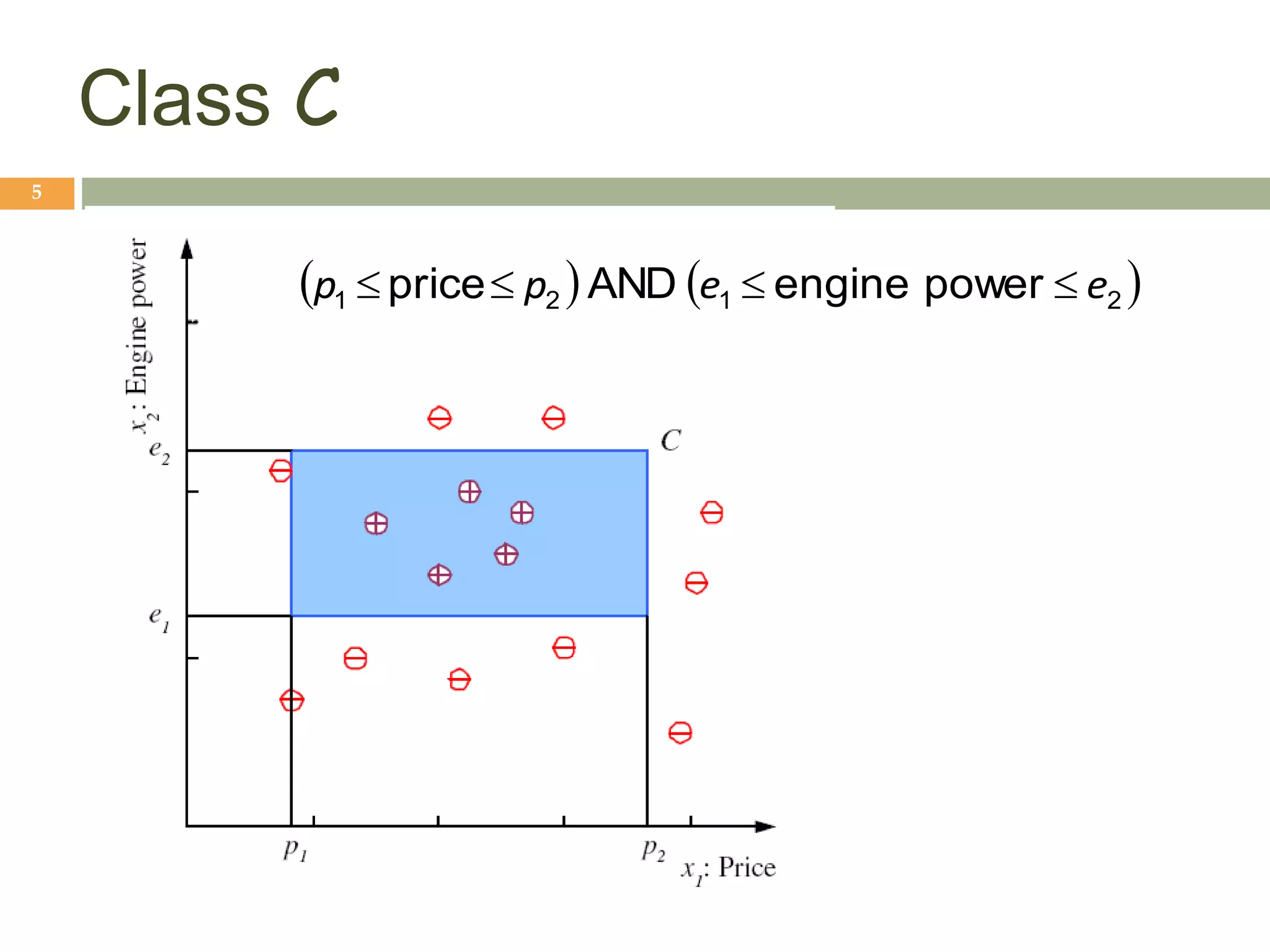
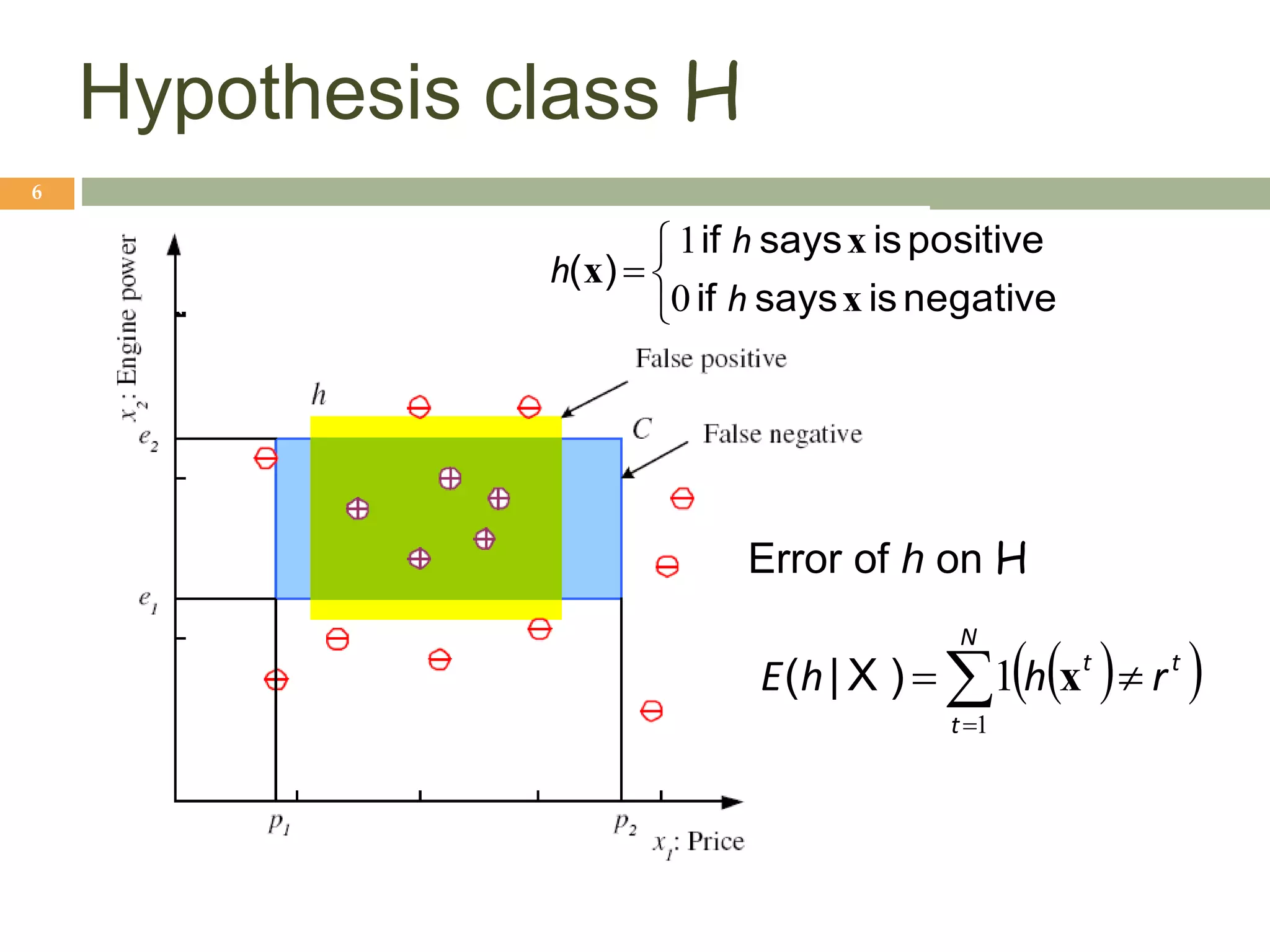
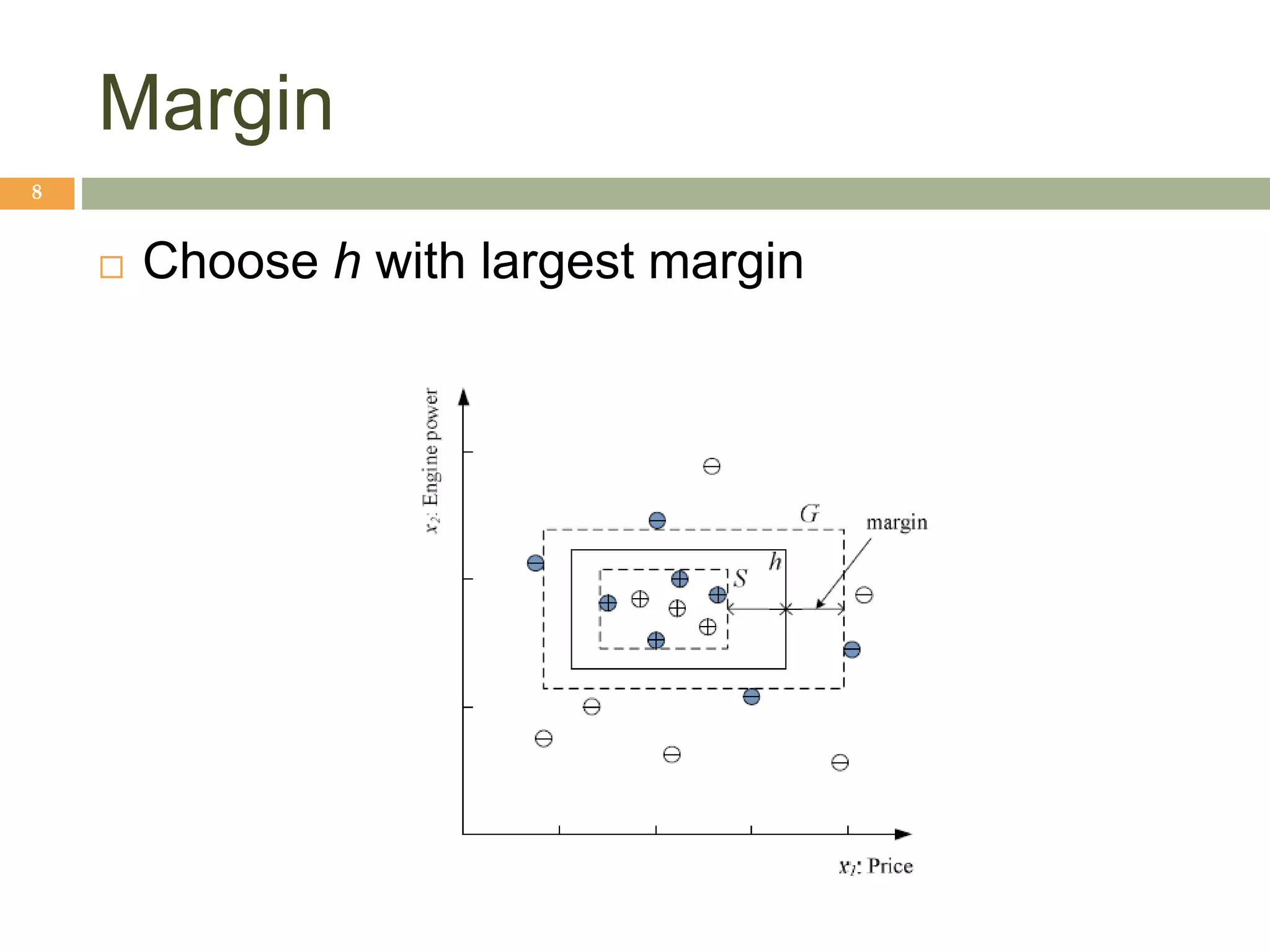
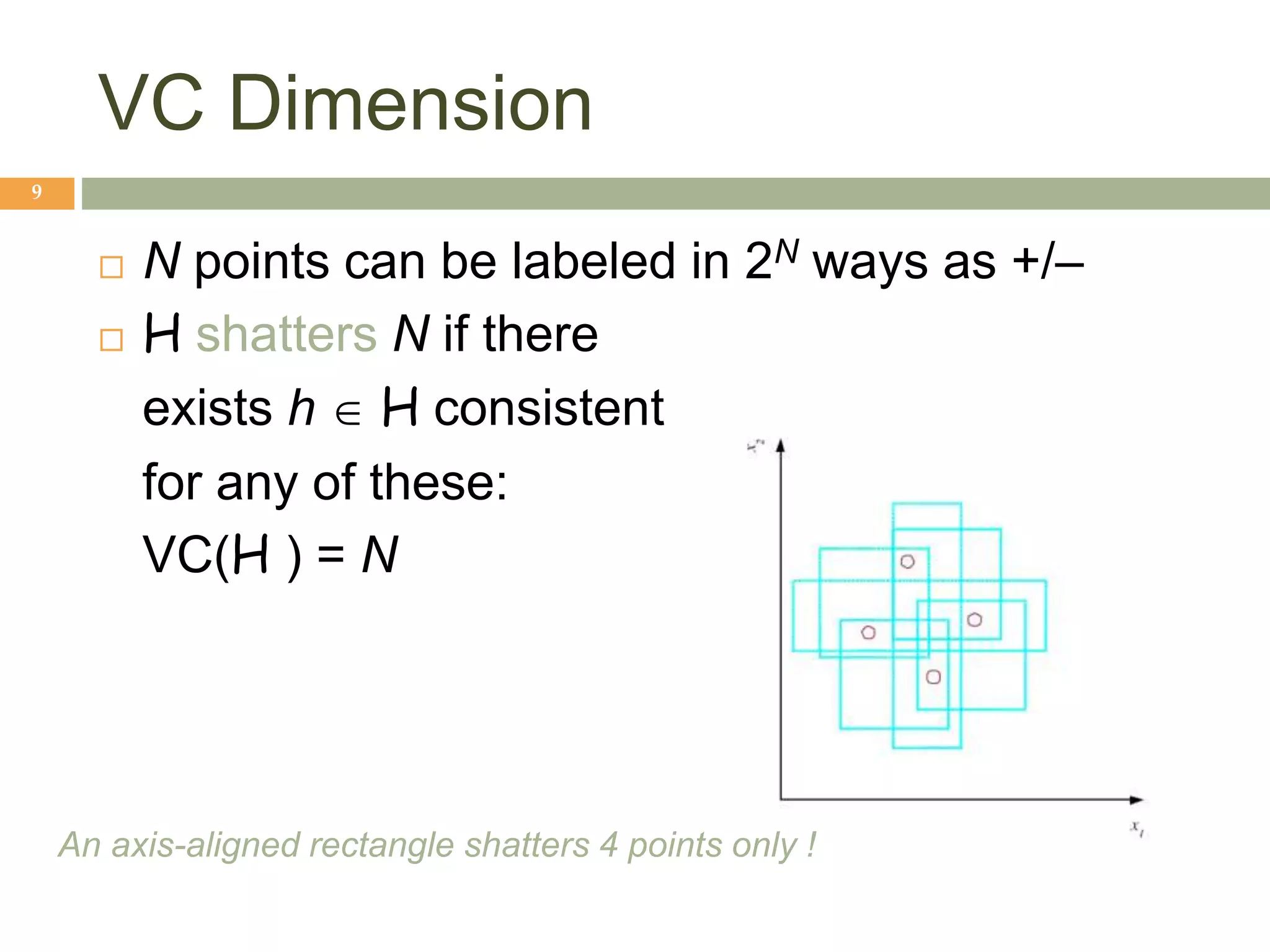
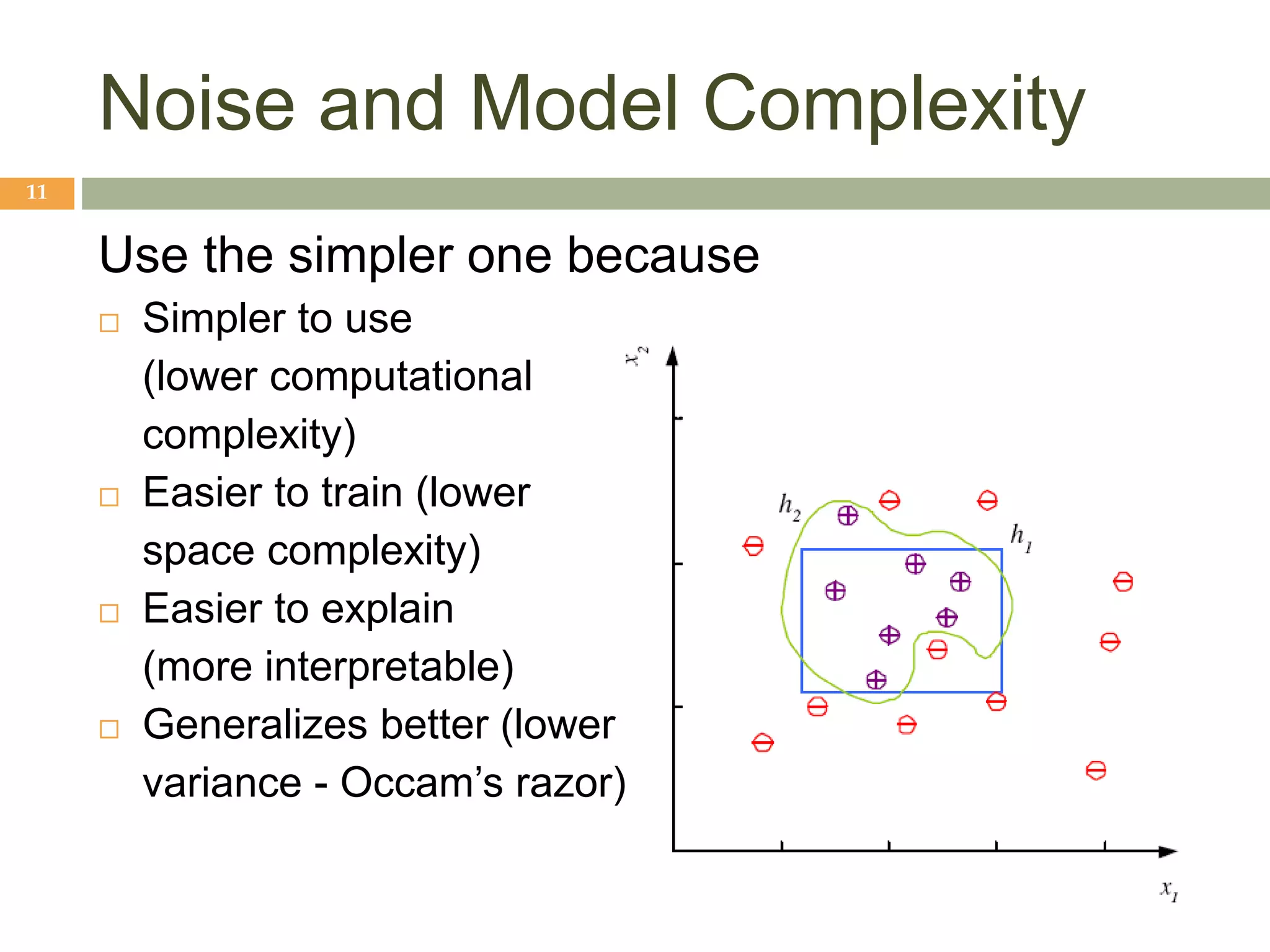
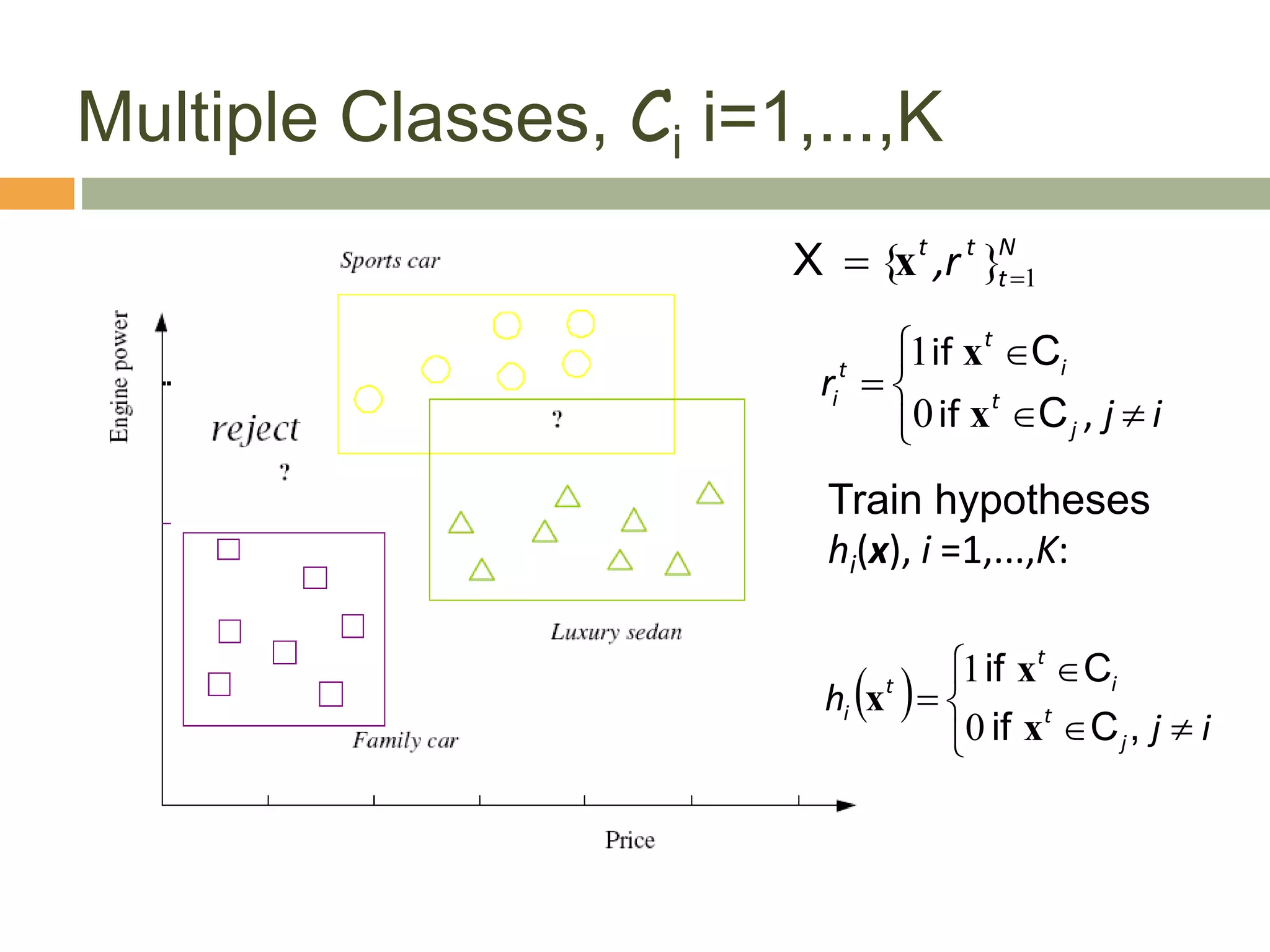
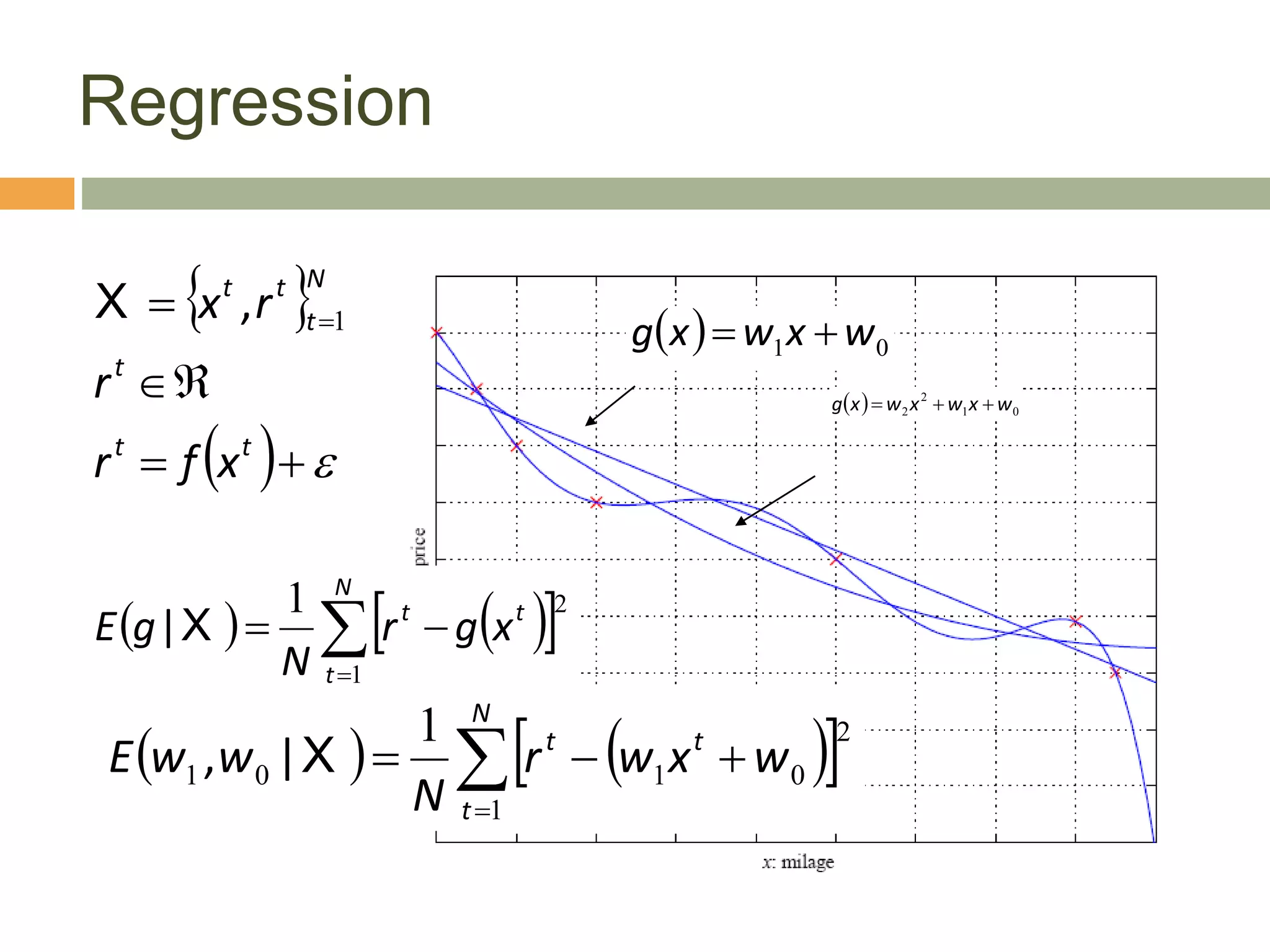
This document provides an introduction to machine learning and supervised learning. It discusses key concepts like training examples, hypotheses, error, model complexity, and overfitting. The goal of supervised learning is to learn a function that maps inputs to outputs from example input-output pairs. Choosing the right model complexity involves balancing training error, generalization error, and model interpretability.