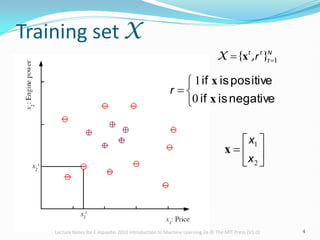
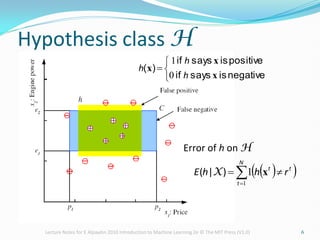
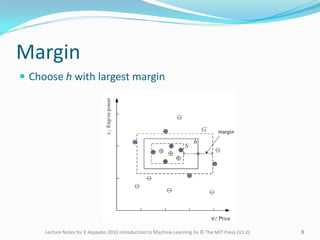
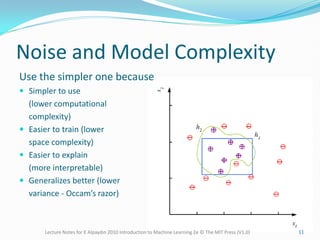
The document provides lecture notes on machine learning concepts, covering topics such as hypothesis classes, training examples, model complexity, and the importance of generalization. It discusses methods for estimating generalization error, such as cross-validation, and highlights the trade-offs between complexity, training set size, and error rates. Additionally, it addresses the concept of PAC learning and the need for inductive bias in the learning process.
























































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)



