Recommended
PDF
深層生成モデルと世界モデル(2020/11/20版)
PDF
PDF
[DL輪読会]Control as Inferenceと発展
PDF
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
PPTX
Curriculum Learning (関東CV勉強会)
PDF
Attentionの基礎からTransformerの入門まで
PDF
Control as Inference (強化学習とベイズ統計)
PPTX
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
PPTX
PPTX
[DL輪読会]Flow-based Deep Generative Models
PPTX
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
PPTX
PDF
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
PDF
PDF
Transformerを多層にする際の勾配消失問題と解決法について
PDF
PDF
PDF
PDF
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
PDF
semantic segmentation サーベイ
PDF
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
PPTX
PDF
BlackBox モデルの説明性・解釈性技術の実装
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
PDF
PDF
More Related Content
PDF
深層生成モデルと世界モデル(2020/11/20版)
PDF
PDF
[DL輪読会]Control as Inferenceと発展
PDF
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
PPTX
Curriculum Learning (関東CV勉強会)
PDF
Attentionの基礎からTransformerの入門まで
PDF
Control as Inference (強化学習とベイズ統計)
What's hot
PPTX
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
PPTX
PPTX
[DL輪読会]Flow-based Deep Generative Models
PPTX
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
PPTX
PDF
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
PDF
PDF
Transformerを多層にする際の勾配消失問題と解決法について
PDF
PDF
PDF
PDF
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
PDF
semantic segmentation サーベイ
PDF
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
PPTX
PDF
BlackBox モデルの説明性・解釈性技術の実装
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
Similar to 形態素解析の過去・現在・未来
PDF
PDF
PDF
Segmenting Sponteneous Japanese using MDL principle
PPT
PDF
PDF
PDF
第三回さくさくテキストマイニング勉強会 入門セッション
PDF
PDF
PDF
PPTX
PDF
Developing User-friendly and Customizable Text Analyzer
PDF
文法圧縮入門:超高速テキスト処理のためのデータ圧縮(NLP2014チュートリアル)
PDF
Kuroda & Hasebe NLP15 slides on Pattern Lattice Model
PPTX
PPTX
PDF
PDF
[Basic 11] 文脈自由文法 / 構文解析 / 言語解析プログラミング
PPT
111127.lsj143.田川 japanese conjugation and dm
PDF
More from Preferred Networks
PDF
PodSecurityPolicy からGatekeeper に移行しました / Kubernetes Meetup Tokyo #57
PDF
Optunaを使ったHuman-in-the-loop最適化の紹介 - 2023/04/27 W&B 東京ミートアップ #3
PDF
Kubernetes + containerd で cgroup v2 に移行したら "failed to create fsnotify watcher...
PDF
深層学習の新しい応用と、 それを支える計算機の進化 - Preferred Networks CEO 西川徹 (SEMICON Japan 2022 Ke...
PDF
Kubernetes ControllerをScale-Outさせる方法 / Kubernetes Meetup Tokyo #55
PDF
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
PDF
最新リリース:Optuna V3の全て - 2022/12/10 Optuna Meetup #2
PDF
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2
PDF
スタートアップが提案する2030年の材料開発 - 2022/11/11 QPARC講演
PPTX
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」)
PPTX
PFNにおける研究開発(2022/10/19 東大大学院「融合情報学特別講義Ⅲ」)
PDF
自然言語処理を 役立てるのはなぜ難しいのか(2022/10/25東大大学院「自然言語処理応用」)
PDF
Kubernetes にこれから入るかもしれない注目機能!(2022年11月版) / TechFeed Experts Night #7 〜 コンテナ技術を語る
PDF
Matlantis™のニューラルネットワークポテンシャルPFPの適用範囲拡張
PDF
PFNのオンプレ計算機クラスタの取り組み_第55回情報科学若手の会
PDF
続・PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 #2
PDF
Kubernetes Service Account As Multi-Cloud Identity / Cloud Native Security Co...
PDF
KubeCon + CloudNativeCon Europe 2022 Recap / Kubernetes Meetup Tokyo #51 / #k...
PDF
KubeCon + CloudNativeCon Europe 2022 Recap - Batch/HPCの潮流とScheduler拡張事例 / Kub...
PDF
独断と偏見で選んだ Kubernetes 1.24 の注目機能と今後! / Kubernetes Meetup Tokyo 50
形態素解析の過去・現在・未来 1. 2. ⾃自⼰己紹介
l 海野 裕也 (@unnonouno)
l unno/no/uno
l 研究開発部⾨門 リサーチャー
l 専⾨門
l ⾃自然⾔言語処理理
l テキストマイニング
l 職歴
l 2008/4~2011/3 ⽇日本アイ・ビー・エム(株)東京
基礎研究所
l 2011/4~ 現職
2
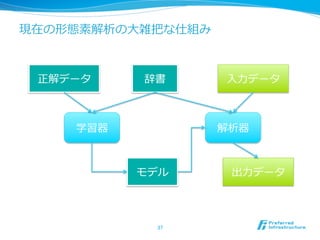
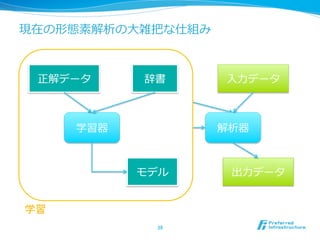
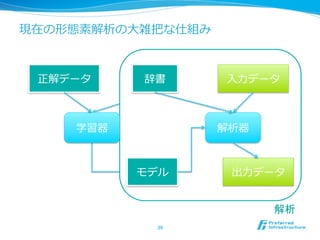
3. 今⽇日の発表の⽬目的
l 形態素解析器の中で何が⾏行行われているか
l コスト最⼩小化, HMM, MEMM, CRF etc.
,
l JUMAN, Chasen, MeCab, etc.
l ・・・だけだとよくあるので、最新の⼿手法と過
去の⼿手法をまとめる
l 現在の問題点に関してもまとめる
3
4. 5. 6. 7. 8. 9. 「形態素解析」とは何か?
l ⼤大雑把には以下の3つの処理理を⾏行行うこと
l 単語分割
l どこで分割するか当てる
l 例例:東京・都 or 東・京都
l 品詞推定
l 品詞を当てる
l 例例:「語」は 名詞(ご) or 動詞(かたる)
l 語義の推定
l 表記上曖昧な語を特定する
l 例例:きのう は「機能」or「昨⽇日」or「帰納」
どこまでやるかは曖昧
9
10. 形態素と単語は違うの?
l ⼀一般的には単語は1つ以上の形態素から成る
l 例例)⾼高さ=⾼高 + さ
l 例例)霧⾬雨=霧 + ⾬雨
l 実際は単語も形態素も単位は曖昧
l 「ある単位に分ける」問題と理理解しておく
l 曖昧と⾔言うかきっとみんなケンカするよ・・・
10
11. 12. 余談:英語の形態素って何?
l 普通は語基と接辞に分解される
playing =
play- -ing
l 代わりに品詞だけ当てることが多い
l 外国⼈人に「形態素解析やってるよ」と⾔言うと
びっくりされるかも・・・
12
13. 14. ⻑⾧長い歴史
l 1980~1990年年代
l ⽇日本語⼊入⼒力力の⼀一貫として成⻑⾧長
l ⼈人⼿手の規則、コスト調整
l 2000年年前後
l 解析済みデータの整備
l 機械学習の出現とコスト調整の⾃自動化
l 2000年年代
l オープンソースソフトウェアの熟成
l 検索索やテキストマイニングの前処理理として活⽤用
14
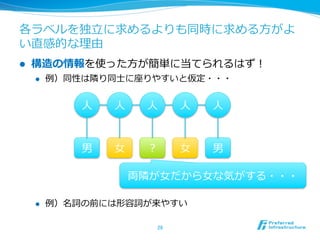
15. 直感に従って設計してみよう
l 品詞の接続に関する知識識を活⽤用しよう
l 名詞のあとには格助詞が来やすい
l 格助詞のあとには動詞語幹が来やすい
l 動詞語幹のあとには活⽤用語尾が来やすい
l 活⽤用語尾のあとには助動詞が来やすい
l ・・・
東京に行った
東京 に ⾏行行 っ た
15
16. 規則だけでは解決できない問題が存在する
l 本質的に曖昧な例例が存在する
l 例例)東京・都 vs 東・京都
l 例例)にわにはにわにわとりがいる
l そのため、何らかの基準で候補の良良し悪しを決
める必要がある
l 最⻑⾧長⼀一致法
l ⽂文節数最⼩小化法
l 接続コスト最⼩小化法
16
17. 最⻑⾧長⼀一致法
l ⼀一番⻑⾧長い形態素を順番に割り当てる
l N⽂文節ごとに⻑⾧長い解を優先する⼀一般化もある
東
東京都に住む
東京
17
18. ⽂文節数最⼩小法 [吉村1983]
l 出来る⽂文節の数が最⼩小になる候補を選択する
l ⽂文節とは、名詞、動詞などの連続+その他、の塊
l 最⻑⾧長⼀一致法が決定的に動くのに⽐比べて、全体最
適になっている点がよい
18
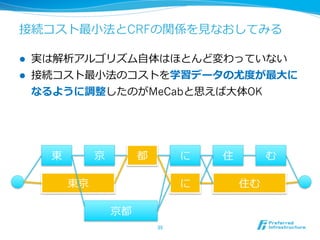
19. 接続コスト最⼩小法 [久光1991]
l 2つのリソースに分離離
l 辞書:表記と語彙(品詞情報など)へのマッピング
l 接続表:品詞と品詞のつながりのコスト
l コストの総和が最⼩小になる形態素列列を探す
l ⽂文節数最⼩小化の⼀一般化になっている
東 京 都 に 住 む
東京 に 住む
京都
19
20. コストが最⼩小のパスを探す⽅方法
l 端的に⾔言えばDAGにおける最短路路問題
l Viterbiアルゴリズム
l 単純な動的計画法
l Dijkstra法
l いわゆる最短路路計算
l A*法
l いわゆる最短路路計算その2
20
21. 正規⽂文法による⽅方法 [丸⼭山1994]
l 正規⽂文法で形態素列列を表現する
l 例例:名詞 à “関” サ変語尾
l サ変語尾 à “し” サ変連⽤用
l 接続表に⽐比べて柔軟に設計しやすい
l 接続表は品詞数の2乗に膨らむ
l ⽂文法で書けば類似品詞をまとめられる
l 例例:固有名詞、代名詞、普通名詞を名詞類にまとめる
l 複数語間の遷移を⾃自由に記述できる
l 例例:に・関・する
21
22. 23. 24. 昔の論論⽂文を読むと当時の問題意識識が⾒見見えてくる?
l ⽇日本語⽂文の形態素解析において残されている重要な課題である未登
録語、複合語、接頭・接尾語の処理理の問題を考える際に・・・
l 吉村賢治, ⽇日⾼高達, 吉⽥田将.「⽂文節数最⼩小法を⽤用いたべた書き⽇日本語⽂文の形態素解
析」(1983)より
l ・・・対象⽂文章に応じた決めの細かい⽂文法を⽤用意することができる.
このように,形態素解析⽂文法においては,可読性と柔軟性が⾮非常に
重要であると我々は考える.
l 丸⼭山宏, 荻野紫穂. 「正規⽂文法に基づく⽇日本語形態素解析」(1994)より
l 2つの連続する形態素間の制約で⽂文法を記述するには、精度度向上を
図る上で明らかに限界がある。
l 颯々野学.「JUMANにおける形態素⽂文法記述の問題点に関する考察」(1996)よ
り
24
25. ⼈人⼿手によるメンテナンスの限界
l コスト調整はドリフのタンス
l こっちを閉じるとあっちが開く
l ベストな解を探すのは難しい
l ⽂文法情報の爆発
l きめ細かくメンテナンスすると品詞数が爆発する
l メンテナンス要員の不不⾜足
l チューニングが困難
25
26. 機械学習によるコストの推定
l 正解データに合うように⾃自動に設定できないか?
l 品詞というものも意識識しないようにできないか?
l これが出来れば、規則をメンテナンスする代わりに正解
データをメンテナンスすればよくなる
機械学習、特に系列列ラベリング問題と相性がよい
26
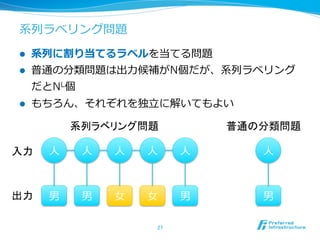
27. 系列列ラベリング問題
l 系列列に割り当てるラベルを当てる問題
l 普通の分類問題は出⼒力力候補がN個だが、系列列ラベリング
だとNL個
l もちろん、それぞれを独⽴立立に解いてもよい
系列ラベリング問題
普通の分類問題
入力
⼈人 ⼈人 ⼈人 ⼈人 ⼈人 ⼈人
出力
男 男 ⼥女女 ⼥女女 男 男
27
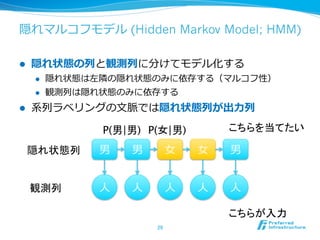
28. 29. 隠れマルコフモデル (Hidden Markov Model; HMM)
l 隠れ状態の列列と観測列列に分けてモデル化する
l 隠れ状態は左隣隣の隠れ状態のみに依存する(マルコフ性)
l 観測列列は隠れ状態のみに依存する
l 系列列ラベリングの⽂文脈では隠れ状態列列が出⼒力力列列
P(男|男)
P(女|男)
こちらを当てたい
隠れ状態列
男 男 ⼥女女 ⼥女女 男
観測列
⼈人 ⼈人 ⼈人 ⼈人 ⼈人
こちらが入力
29
30. 条件付き確率率率場 (Conditional Random Field; CRF)
[Lafferty2001]
l ラベルの同時確率率率を直接モデル化する
l P(y|x) ∝ exp(∑i f(i)・w)
l 特に⼊入⼒力力が系列列の時をlinear chain CRFと呼ぶ
l ⾃自然⾔言語処理理の⽂文脈で出てくるとほとんどがこれのこと
隣接ラベルのみに特徴関数fiが設定されている
⼈人 ⼈人 ⼈人 ⼈人 ⼈人
男 男 ⼥女女 ⼥女女 男
30
31. 32. CRFとHMMを⽐比較する
l ⾃自由な特徴量量を利利⽤用できる
l もはや品詞情報は特徴量量の⼀一つでしかない
l HMMでは隣隣接コストは品詞(隠れ状態)のみに依存
する
l バイアスが少ない
l HMMでは分岐数の少ないパスを選択されやすい(次
スライド)
32
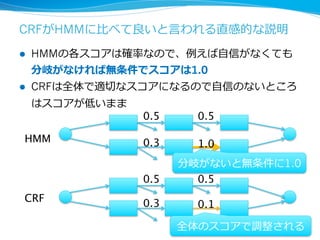
33. CRFがHMMに⽐比べて良良いと⾔言われる直感的な説明
l HMMの各スコアは確率率率なので、例例えば⾃自信がなくても
分岐がなければ無条件でスコアは1.0
l CRFは全体で適切切なスコアになるので⾃自信のないところ
はスコアが低いまま
0.5
0.5
HMM
0.3
1.0
分岐がないと無条件に1.0
0.5
0.5
CRF
0.3
0.1
全体のスコアで調整される
34. 35. 36. オープンスースソフトウェアの出現
l ChasenやMeCabといった優秀なオープンソースソフト
ウェアが出現
l かなり実⽤用的なレベルになって急速に広まる
l ⾃自分の周りでも⾃自然⾔言語処理理と無関係な⼈人も使うようになった
l それを利利⽤用したアプリケーションの発展
l 検索索インデックスへの応⽤用
l テキストマイニングへの応⽤用
l 機械学習における特徴量量として利利⽤用
36
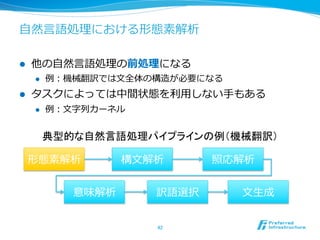
37. 38. 39. 40. 41. 42. ⾃自然⾔言語処理理における形態素解析
l 他の⾃自然⾔言語処理理の前処理理になる
l 例例:機械翻訳では⽂文全体の構造が必要になる
l タスクによっては中間状態を利利⽤用しない⼿手もある
l 例例:⽂文字列列カーネル
典型的な自然言語処理パイプラインの例(機械翻訳)
形態素解析 構⽂文解析 照応解析
意味解析 訳語選択 ⽂文⽣生成
42
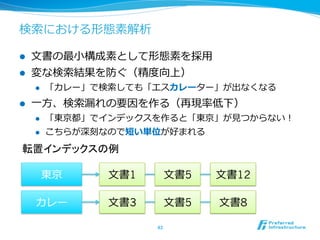
43. 検索索における形態素解析
l ⽂文書の最⼩小構成素として形態素を採⽤用
l 変な検索索結果を防ぐ(精度度向上)
l 「カレー」で検索索しても「エスカレーター」が出なくなる
l ⼀一⽅方、検索索漏漏れの要因を作る(再現率率率低下)
l 「東京都」でインデックスを作ると「東京」が⾒見見つからない!
l こちらが深刻なので短い単位が好まれる
転置インデックスの例
東京 ⽂文書1 ⽂文書5 ⽂文書12
カレー ⽂文書3 ⽂文書5 ⽂文書8
43
44. テキストマイニングにおける形態素解析
l テキストマイニングとは?
l ⼤大量量の⽂文書データを解析して何らかの知⾒見見を得る技術の総称
l 例例:単語頻度度の偏りを検知する
l ここで欲しいのは、単語というより「概念念」
l 同⼀一概念念はまとめたい(多義語問題、名寄問題)
l そのため単語単位は⻑⾧長めで、同義表現などがまとまると嬉しい
Michael Jackson
同一概念
King of Pop
44
45. 実際に仕事で使うと現れる問題・・・
「自然言語処理が邪魔をします」
l 予想外の切切れ⽅方をする
l 新しい単語を検出できない
l 形態素解析器がブラックボックス化
l 内部は複雑で挙動が読めなくなってしまった
45
46. アプリケーションごとの要望の違いに注⽬目すべき
l ⾃自然⾔言語処理理
l ⽂文全体の解析が必要
l 後処理理と単位が揃っている必要がある
l 検索索
l 境界さえあればよい
l 再現率率率を落落としたくない
l 絶対に境界じゃない部分だけわかれば良良い
l テキストマイニング
l 概念念をまとめ上げたい
l 名寄せ、表記ゆれ、同義語などの処理理が欲しい
それぞれのアプリケーションごとに工夫の仕方は異なるかも?
46
47. 難しい問題を解きすぎてはいないだろうか?
ある問題を解くとき、その問題よりも
難しい問題を途中段階で解いてはならない
l 「その単語が⾒見見つからないのは、動詞語幹として扱われ
ているものなので、名詞ではなくて・・・・」
l お客さんから⾒見見たら中でどうなっているか知りたくない
l ⾒見見つかるようにしてくれの⼀一⾔言に尽きる
47
48. 49. 最近の形態素解析関連の話題
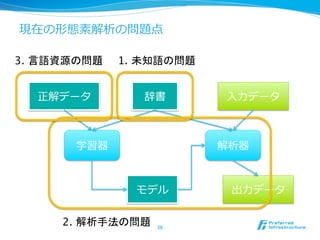
1. 未知語の問題
l 未知語辞書の⾃自動獲得
l 教師なし形態素解析
2. 解析⼿手法⾃自体の問題
l 確率率率的単語分割
l Shift/Reduce それぞれ1枚程度度です
l 点予測 がお許し下さい
3. ⾔言語資源の問題
l ⾔言語資源(教師データ)の与え⽅方
l ⾔言語資源そのもののクオリティ
49
50. 51. 1. 未知語の問題
l 未知語辞書の⾃自動獲得
l 教師なし形態素解析
2. 解析⼿手法⾃自体の問題
l 確率率率的単語分割
l Shift/Reduce
l 点予測
3. ⾔言語資源の問題
l ⾔言語資源(教師データ)の与え⽅方
l ⾔言語資源そのもののクオリティ
51
52. 53. 54. 教師なし形態素解析 [持橋2009, 持橋2011]
l 形態素列列を⽣生成する⽣生成モデルを作る
l 正解データ(解析済みデータ)を必要としない!
l 新語、未知語に対して頑健
l 例例)古⽂文、なのは問題、しょこたん語
l しかし、これを説明するにはこのスライドでは短すぎる・・・
持橋大地, 山田武士, 上田修功. 「ベイズ階層言語モデルによる教師なし形態素解析」より抜粋
54
55. 1. 未知語の問題
l 未知語辞書の⾃自動獲得
l 教師なし形態素解析
2. 解析⼿手法⾃自体の問題
l 確率率率的単語分割
l Shift/Reduce
l 点予測
3. ⾔言語資源の問題
l ⾔言語資源(教師データ)の与え⽅方
l ⾔言語資源そのもののクオリティ
55
56. 57. 58. 59. 点予測 (KyTea) [森2009, Neubig2010, 中⽥田2010]
l あえて系列列ラベリングを独⽴立立の問題として解く!
l 切切れ⽬目か否かの単純な⼆二値分類問題
NO
Yes
Yes
Yes
No
東 京 都 に 住 む
それぞれ別の問題だと思って解く
59
60. 点予測と⾔言語資源の関係
l 単純な問題のため、学習データを与えやすい
l 単語分割が不不⼗十分なら単語分割データを、品詞推定
が不不⼗十分なら品詞付与済みデータを与えれば良良い
l 部分的な解析データも与えやすい
60
61. 1. 未知語の問題
l 未知語辞書の⾃自動獲得
l 教師なし形態素解析
2. 解析⼿手法⾃自体の問題
l 確率率率的単語分割
l Shift/Reduce
l 点予測
3. ⾔言語資源の問題
l ⾔言語資源(教師データ)の与え⽅方
l ⾔言語資源そのもののクオリティ
61
62. 63. 64. まとめ
l 形態素解析の⼿手法と歴史
l ⼈人出による規則、コスト設定
l 機械学習によるコストの⾃自動設定
l 様々な応⽤用
l 検索索、テキストマイニング
l 実務の中からの問題発⾒見見
l 最新の⼿手法
l 未知語問題
l 新⼿手法
l ⾔言語資源の整備
64
65. 66. 参考⽂文献 – 全般 ~ 規則による⼿手法
l ⻑⾧長尾真編.
岩波講座ソフトウェア科学15 ⾃自然⾔言語処理理.
岩波書店, 1996
l ⾦金金明哲, 村上征勝, 永⽥田昌明, ⼤大津起夫, ⼭山⻄西健司.
⾔言語と⼼心理理の統計 ことばと⾏行行動の確率率率モデルによる分析.
岩波書店, 2003.
l [吉村1983] 吉村 賢治, ⽇日⾼高 達, 吉⽥田 将.
⽂文節数最⼩小法を⽤用いたべた書き⽇日本語⽂文の形態素解析.
情報処理理学会論論⽂文誌 24(1), 1983.
l [久光1991] 久光 徹, 新⽥田 義彦.
接続コスト最⼩小法による⽇日本語形態素解析.
第42回情報処理理学会全国⼤大会, 1991.
l [丸⼭山1994] 丸⼭山 宏, 荻野 紫穂.
正規⽂文法に基づく⽇日本語形態素解析.
情報処理理学会論論⽂文誌 35(7), 1994.
l 颯々野 学.
JUMANにおける形態素⽂文法記述の問題点に関する考察.
第53回情報処理理学会全国⼤大会, 1996.
67. 参考⽂文献 – 機械学習による⼿手法
l [Lafferty2001] John Lafferty, Andrew McCallum, Fernando Pereira.
Conditional Random Fields: Probabilistic Models for Segmenting and
Labeling Sequence Data.
ICML 2001.
l [Kudo2004] Taku Kudo, Kaoru Yamamoto, Yuji Matsumoto.
Appliying Conditional Random Fields to Japanese Morphological
Analysis.
EMNLP 2004.
l [⼯工藤2004] ⼯工藤 拓拓, ⼭山本 薫, 松本 裕治.
Conditional Random Fields を⽤用いた⽇日本語形態素解析.
NL研161, 2004.
67
68. 参考⽂文献 – 最近の研究 1/2
l [村脇2008] 村脇 有吾, ⿊黒橋 禎夫.
形態論論的制約を⽤用いた未知語の⾃自動獲得.
⾔言語処理理学会第14回年年次⼤大会, 2008.
l [持橋2009] 持橋 ⼤大地, ⼭山⽥田 武⼠士, 上⽥田 修功.
ベイズ階層⾔言語モデルによる教師なし形態素解析.
NL研190, 2009.
l [持橋2011] 持橋 ⼤大地, 鈴鈴⽊木 潤, 藤野 昭典.
条件付確率率率場とベイズ階層⾔言語モデルの統合による半教師あり形態素解析.
⾔言語処理理学会第17回年年次⼤大会, 2011.
l [Mori2004] Shinsuke Mori, Daisuke Takuma.
Word N-gram Probability Estimation From a Japanese Raw Corpus.
ICSLP 2004.
l [⼯工藤2005] ⼯工藤 拓拓.
形態素周辺確率率率を⽤用いた分かち書きの⼀一般化とその応⽤用.
⾔言語処理理学会第11回全国⼤大会, 2005.
l [岡野原2006] 岡野原 ⼤大輔, ⼯工藤 拓拓, 森 信介.
形態素周辺確率率率を⽤用いた確率率率的単語分割コーパスの構築とその応⽤用.
NLP若若⼿手の会第1回シンポジウム, 2006.
68
69. 参考⽂文献 – 最近の研究 2/2
l [岡野原2008] 岡野原 ⼤大輔, 辻井 潤⼀一.
Shift-Reduce操作に基づく未知語を考慮した形態素解析.
⾔言語処理理学会第14回年年次⼤大会, 2008.
l [森2009] 森 信介, ⼩小⽥田 裕樹.
3種類の辞書による⾃自動単語分割の精度度向上.
NL研193, 2009.
l [Neubig2010] Graham Neubig, 中⽥田 陽介, 森 信介.
点推定と能動学習を⽤用いた⾃自動単語分割器の分野適応.
⾔言語処理理学会第16回年年次⼤大会, 2010.
l [中⽥田2010] 中⽥田 陽介, Graham Neubig, 森 信介, 河原 達也.
点予測による形態素解析.
NL研198, 2010.
l [坪井2007] 坪井祐太, ⿅鹿鹿島久嗣, 森 信介, ⼩小⽥田裕樹, 松本 裕治.
部分的かつ曖昧なラベル付き構造データからのマルコフ条件付確率率率場の学習.
NL研182, 2007.
69


















![⽂文節数最⼩小法 [吉村1983]
l 出来る⽂文節の数が最⼩小になる候補を選択する
l ⽂文節とは、名詞、動詞などの連続+その他、の塊
l 最⻑⾧長⼀一致法が決定的に動くのに⽐比べて、全体最
適になっている点がよい
18](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-18-320.jpg)
![接続コスト最⼩小法 [久光1991]
l 2つのリソースに分離離
l 辞書:表記と語彙(品詞情報など)へのマッピング
l 接続表:品詞と品詞のつながりのコスト
l コストの総和が最⼩小になる形態素列列を探す
l ⽂文節数最⼩小化の⼀一般化になっている
東 京 都 に 住 む
東京 に 住む
京都
19](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-19-320.jpg)

![正規⽂文法による⽅方法 [丸⼭山1994]
l 正規⽂文法で形態素列列を表現する
l 例例:名詞 à “関” サ変語尾
l サ変語尾 à “し” サ変連⽤用
l 接続表に⽐比べて柔軟に設計しやすい
l 接続表は品詞数の2乗に膨らむ
l ⽂文法で書けば類似品詞をまとめられる
l 例例:固有名詞、代名詞、普通名詞を名詞類にまとめる
l 複数語間の遷移を⾃自由に記述できる
l 例例:に・関・する
21](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-21-320.jpg)





![条件付き確率率率場 (Conditional Random Field; CRF)
[Lafferty2001]
l ラベルの同時確率率率を直接モデル化する
l P(y|x) ∝ exp(∑i f(i)・w)
l 特に⼊入⼒力力が系列列の時をlinear chain CRFと呼ぶ
l ⾃自然⾔言語処理理の⽂文脈で出てくるとほとんどがこれのこと
隣接ラベルのみに特徴関数fiが設定されている
⼈人 ⼈人 ⼈人 ⼈人 ⼈人
男 男 ⼥女女 ⼥女女 男
30](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-30-320.jpg)
![条件付き確率率率場を使った形態素解析(MeCab)
[Kudo2004, ⼯工藤2004]
東 京 都 に 住 む
東京 に 住む
京都
l 形態素候補を全て列列挙して⼀一つのパスを選択する問題
l MeCabはlinear chain CRFではない
l 厳密に⾔言えばSemi Markov CRFの亜種かな・・・
31](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-31-320.jpg)













![周辺形態素からの未知語獲得 [村脇2008]
l 同じ品詞の単語は同じ様な振る舞いをする
l ⽂文法は辞書よりも頑健
村脇有吾「自然言語の解析のためのテキストからの語彙の自動獲得」より抜粋
53](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-53-320.jpg)
![教師なし形態素解析 [持橋2009, 持橋2011]
l 形態素列列を⽣生成する⽣生成モデルを作る
l 正解データ(解析済みデータ)を必要としない!
l 新語、未知語に対して頑健
l 例例)古⽂文、なのは問題、しょこたん語
l しかし、これを説明するにはこのスライドでは短すぎる・・・
持橋大地, 山田武士, 上田修功. 「ベイズ階層言語モデルによる教師なし形態素解析」より抜粋
54](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-54-320.jpg)

![曖昧な単語分割 [Mori2004, ⼯工藤2005]
l 切切れる切切れないの⼆二値ではなく、切切れる確率率率を与える
l CRFの⽂文脈で⾔言えば、周辺確率率率を利利⽤用できる
0.01
0.6
0.98
1.0
0.2
東 京 都 に 住 む
曖昧性を⾃自然に表現できる
56](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-56-320.jpg)
![曖昧単語分割の検索索への応⽤用 [岡野原2006]
l 単語分割を曖昧にしたまま検索索する
l 分割確率率率をスコアリングのみに使う
57](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-57-320.jpg)
![Shift/Reduceによる⼿手法 [岡野原2008]
l 前から順番に単語を決定する
l 境界だと思ったらReduce、違うと思ったらShiftする
l 未知語を⾃自然に扱える反⾯面、既知語に対しても不不要な未
知語候補を想定して精度度が下がってしまった
58](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-58-320.jpg)
![点予測 (KyTea) [森2009, Neubig2010, 中⽥田2010]
l あえて系列列ラベリングを独⽴立立の問題として解く!
l 切切れ⽬目か否かの単純な⼆二値分類問題
NO
Yes
Yes
Yes
No
東 京 都 に 住 む
それぞれ別の問題だと思って解く
59](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-59-320.jpg)


![部分的学習データからの学習 [坪井2007]
l 全部きっちり正解を与えるのは⼤大変
l ⼀一部分だけ正解を与えたデータから学習したい
NO
Yes
?
?
?
東 京 都 に 住 む
興味のある⼀一部分だけ正解を与える
62](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-62-320.jpg)



![参考⽂文献 – 全般 ~ 規則による⼿手法
l ⻑⾧長尾真編.
岩波講座ソフトウェア科学15 ⾃自然⾔言語処理理.
岩波書店, 1996
l ⾦金金明哲, 村上征勝, 永⽥田昌明, ⼤大津起夫, ⼭山⻄西健司.
⾔言語と⼼心理理の統計 ことばと⾏行行動の確率率率モデルによる分析.
岩波書店, 2003.
l [吉村1983] 吉村 賢治, ⽇日⾼高 達, 吉⽥田 将.
⽂文節数最⼩小法を⽤用いたべた書き⽇日本語⽂文の形態素解析.
情報処理理学会論論⽂文誌 24(1), 1983.
l [久光1991] 久光 徹, 新⽥田 義彦.
接続コスト最⼩小法による⽇日本語形態素解析.
第42回情報処理理学会全国⼤大会, 1991.
l [丸⼭山1994] 丸⼭山 宏, 荻野 紫穂.
正規⽂文法に基づく⽇日本語形態素解析.
情報処理理学会論論⽂文誌 35(7), 1994.
l 颯々野 学.
JUMANにおける形態素⽂文法記述の問題点に関する考察.
第53回情報処理理学会全国⼤大会, 1996.](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-66-320.jpg)
![参考⽂文献 – 機械学習による⼿手法
l [Lafferty2001] John Lafferty, Andrew McCallum, Fernando Pereira.
Conditional Random Fields: Probabilistic Models for Segmenting and
Labeling Sequence Data.
ICML 2001.
l [Kudo2004] Taku Kudo, Kaoru Yamamoto, Yuji Matsumoto.
Appliying Conditional Random Fields to Japanese Morphological
Analysis.
EMNLP 2004.
l [⼯工藤2004] ⼯工藤 拓拓, ⼭山本 薫, 松本 裕治.
Conditional Random Fields を⽤用いた⽇日本語形態素解析.
NL研161, 2004.
67](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-67-320.jpg)
![参考⽂文献 – 最近の研究 1/2
l [村脇2008] 村脇 有吾, ⿊黒橋 禎夫.
形態論論的制約を⽤用いた未知語の⾃自動獲得.
⾔言語処理理学会第14回年年次⼤大会, 2008.
l [持橋2009] 持橋 ⼤大地, ⼭山⽥田 武⼠士, 上⽥田 修功.
ベイズ階層⾔言語モデルによる教師なし形態素解析.
NL研190, 2009.
l [持橋2011] 持橋 ⼤大地, 鈴鈴⽊木 潤, 藤野 昭典.
条件付確率率率場とベイズ階層⾔言語モデルの統合による半教師あり形態素解析.
⾔言語処理理学会第17回年年次⼤大会, 2011.
l [Mori2004] Shinsuke Mori, Daisuke Takuma.
Word N-gram Probability Estimation From a Japanese Raw Corpus.
ICSLP 2004.
l [⼯工藤2005] ⼯工藤 拓拓.
形態素周辺確率率率を⽤用いた分かち書きの⼀一般化とその応⽤用.
⾔言語処理理学会第11回全国⼤大会, 2005.
l [岡野原2006] 岡野原 ⼤大輔, ⼯工藤 拓拓, 森 信介.
形態素周辺確率率率を⽤用いた確率率率的単語分割コーパスの構築とその応⽤用.
NLP若若⼿手の会第1回シンポジウム, 2006.
68](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-68-320.jpg)
![参考⽂文献 – 最近の研究 2/2
l [岡野原2008] 岡野原 ⼤大輔, 辻井 潤⼀一.
Shift-Reduce操作に基づく未知語を考慮した形態素解析.
⾔言語処理理学会第14回年年次⼤大会, 2008.
l [森2009] 森 信介, ⼩小⽥田 裕樹.
3種類の辞書による⾃自動単語分割の精度度向上.
NL研193, 2009.
l [Neubig2010] Graham Neubig, 中⽥田 陽介, 森 信介.
点推定と能動学習を⽤用いた⾃自動単語分割器の分野適応.
⾔言語処理理学会第16回年年次⼤大会, 2010.
l [中⽥田2010] 中⽥田 陽介, Graham Neubig, 森 信介, 河原 達也.
点予測による形態素解析.
NL研198, 2010.
l [坪井2007] 坪井祐太, ⿅鹿鹿島久嗣, 森 信介, ⼩小⽥田裕樹, 松本 裕治.
部分的かつ曖昧なラベル付き構造データからのマルコフ条件付確率率率場の学習.
NL研182, 2007.
69](https://image.slidesharecdn.com/20111020morphanalysis-111021024411-phpapp02/85/slide-69-320.jpg)


![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[Basic 11] 文脈自由文法 / 構文解析 / 言語解析プログラミング](https://cdn.slidesharecdn.com/ss_thumbnails/basic-11-180306134245-thumbnail.jpg?width=640&height=640&fit=bounds)





















