Recommended
PDF
PDF
PPTX
Nl220 Pitman-Yor Hidden Semi Markov Model
PDF
PDF
PDF
Python nlp handson_20220225_v5
PDF
Segmenting Sponteneous Japanese using MDL principle
PDF
[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...
PDF
PDF
PPTX
PDF
PPTX
Dynamic Entity Representations in Neural Language Models
PPTX
PDF
PDF
Sigconf 2019 slide_ota_20191123
PDF
PPTX
[NeurIPS2018読み会@PFN] On the Dimensionality of Word Embedding
PDF
Japan.r 2018 slide ota_20181201
PPTX
All-but-the-Top: Simple and Effective Postprocessing for Word Representations
PPTX
EMNLP 2015 読み会 @ 小町研 "Morphological Analysis for Unsegmented Languages using ...
PPTX
PDF
PDF
第三回さくさくテキストマイニング勉強会 入門セッション
PDF
Chainer with natural language processing hands on
PPTX
最先端NLP勉強会 Context Gates for Neural Machine Translation
PPT
PDF
Jsai2021 winter ppt_ota_20211127
PDF
PDF
More Related Content
PDF
PDF
PPTX
Nl220 Pitman-Yor Hidden Semi Markov Model
PDF
PDF
PDF
Python nlp handson_20220225_v5
PDF
Segmenting Sponteneous Japanese using MDL principle
PDF
[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...
What's hot
PDF
PDF
PPTX
PDF
PPTX
Dynamic Entity Representations in Neural Language Models
PPTX
PDF
PDF
Sigconf 2019 slide_ota_20191123
PDF
PPTX
[NeurIPS2018読み会@PFN] On the Dimensionality of Word Embedding
PDF
Japan.r 2018 slide ota_20181201
PPTX
All-but-the-Top: Simple and Effective Postprocessing for Word Representations
PPTX
EMNLP 2015 読み会 @ 小町研 "Morphological Analysis for Unsegmented Languages using ...
PPTX
PDF
PDF
第三回さくさくテキストマイニング勉強会 入門セッション
PDF
Chainer with natural language processing hands on
PPTX
最先端NLP勉強会 Context Gates for Neural Machine Translation
PPT
PDF
Jsai2021 winter ppt_ota_20211127
Similar to Signl213
PDF
PDF
PDF
大規模日本語ブログコーパスにおける言語モデルの構築と評価
PDF
AGenT Zero: Zero-shot Automatic Multiple-Choice Question Generation for Skill...
PDF
論文紹介:AutoPrompt: Eliciting Knowledge from Language Models with Automatically ...
PPTX
PDF
DSIRNLP06 Nested Pitman-Yor Language Model
PDF
今日からできる構造学習(主に構造化パーセプトロンについて)
PDF
PPT
PDF
Developing User-friendly and Customizable Text Analyzer
PDF
文献紹介:Extracting Opinion Expression with semi-Markov Conditional Random Fields
PDF
構文情報に基づく機械翻訳のための能動学習手法と人手翻訳による評価
PDF
PDF
PDF
PPTX
A Monolingual Tree-based Translation Model for Sentence Simplification
PPTX
PPTX
Microsoft Cognitive Services NLP APIs
PDF
More from Kei Uchiumi
PPTX
PPTX
PDF
PPTX
PPTX
Sigir2013 retrieval models-and_ranking_i_pub
PDF
Signl213 1. 内海 慶, 塚原 裕史
K U C H I U M I @ D - I T L A B . C O . J P
H T S U K A H A R A @ D - I T L A B . C O . J P
デンソーアイティーラボラトリ
ベイズ階層言語モデルとSemi-Markov
SHDCRF の協調学習による
教師なし形態素解析
1
2. 3. 4. 5. 6. 1. 研究背景(4/6)
6
書き言葉で学習した形態素解析で解析
ず 助動詞,*,*,*,特殊・ヌ,連用ニ接続,ぬ,ズ,ズ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
ぺろぺろ 副詞,一般,*,*,*,*,ぺろぺろ,ペロペロ,ペロペロ
ぺろぺろ 副詞,一般,*,*,*,*,ぺろぺろ,ペロペロ,ペロペロ
マミタスマミタスラブマミタス 名詞,一般,*,*,*,*,*
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
だい 名詞,一般,*,*,*,*,だい,ダイ,ダイ
マミタス 名詞,一般,*,*,*,*,*
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
だい 名詞,一般,*,*,*,*,だい,ダイ,ダイ
マミタスマミタスマミタスラブマミタス 名詞,一
般,*,*,*,*,*
…
7. 1. 研究背景(5/6)
7
(若者言葉を含む)話し言葉の特徴
変化の早さ
明治前期 - 書生言葉
明治後期 - てよだわ言葉
90年代半ば - ギャル語
2000年代 - KY語, 2ちゃん語(ネットスラング), しょこたん語,
etc.
未知語の問題
常に新しい単語が産まれ続ける
アノテーションの難しさ
正解を決めるだけでも一苦労
人手で常時アノテーションし続けるのは難しい
8. 1. 研究背景(6/6)
8
教師なし形態素解析の需要
大量のデータから自動で分かち書きを獲得したい
深い言語処理に繋げるために品詞推定も同時に行いたい
e.g. 係り受け解析,固有表現抽出,etc.
#/ず も も も も /ぺ ろ ぺ ろ /ぺ ろ ぺ ろ /マ ミ タ ス /マ ミ タ ス /ラ ブ マ ミ タ
ス /た だ い マ ミ タ ス /た だ い マ ミ タ ス /マ ミ タ ス /マ ミ タ ス /ラ ブ マ ミ
タ ス /愛 の 神 話 マ ミ タ ス /愛 の 讃 歌 /マ ミ タ ス /マ ミ タ ス /マ ミ タ ス /ラ
ブ マ ミ タ ス
教師なし形態素解析によるしょこたんブログの解析結果
の例
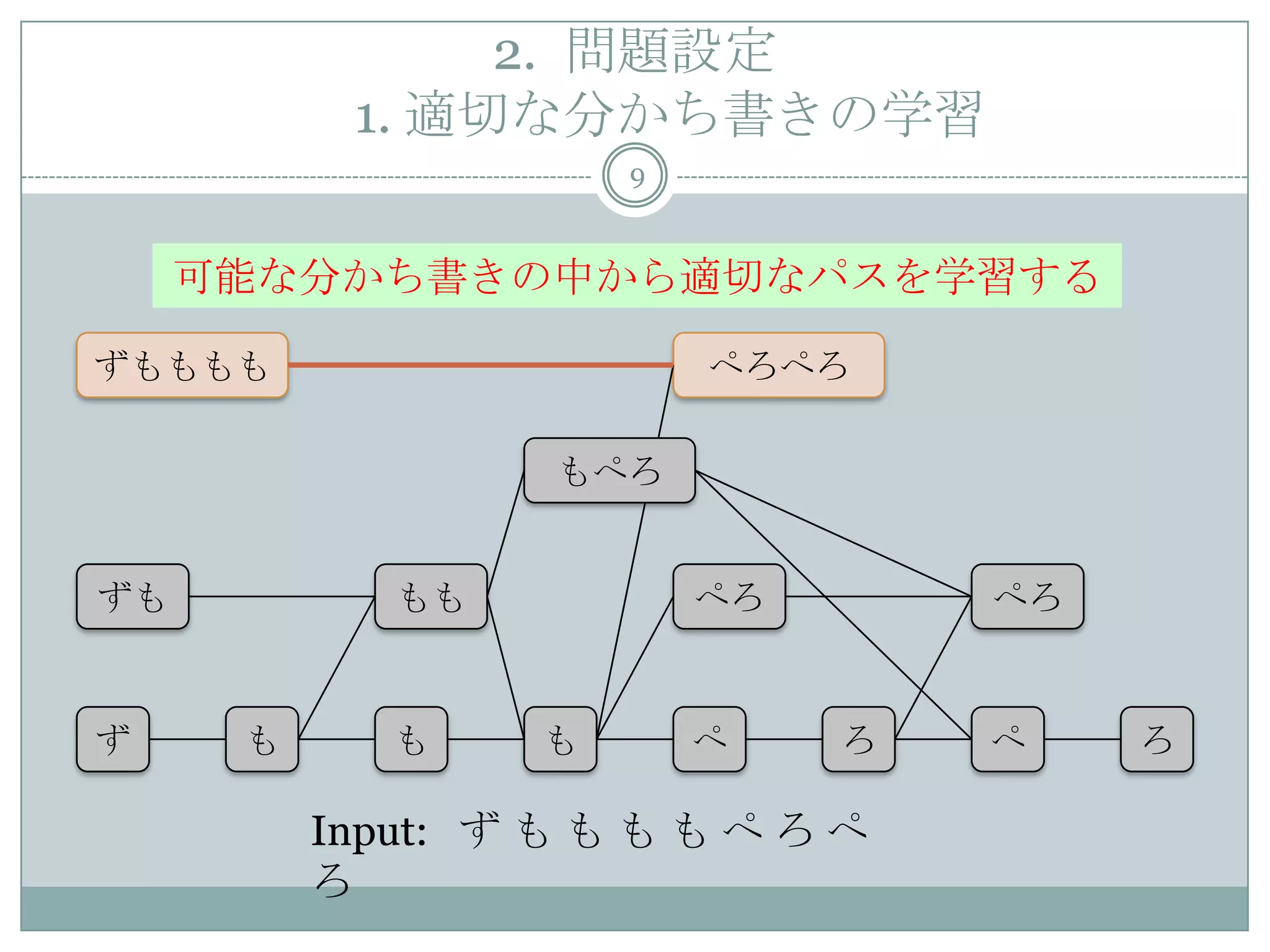
9. 10. 2. 問題設定
1. 適切な分かち書きの学習
10
Input: ず も も も も ぺ ろ ぺ
ろ
ずもももも ぺろぺろ
ず も も も ぺ ろ ぺ ろ
ずも もも ぺろ ぺろ
もぺろ
可能な分かち書きの中から適切なパスを学習する
NPYLM[Mochihashi, et al., ACL2009]
NPYCRF[持橋,他., NLP2011]
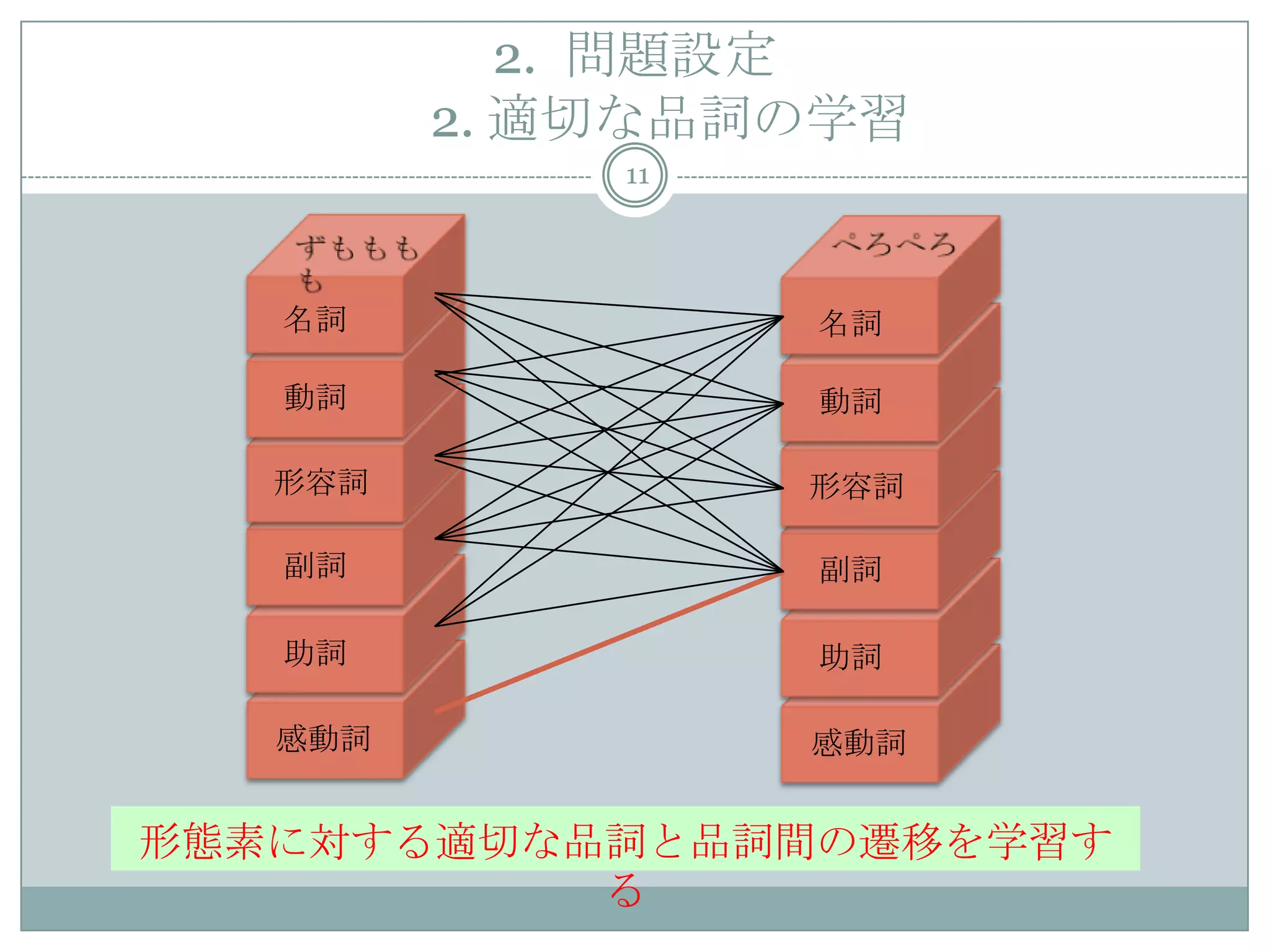
11. 感動詞 感動詞
2. 問題設定
2. 適切な品詞の学習
11
名詞 名詞
動詞
形容詞
副詞
助詞
動詞
形容詞
副詞
助詞
名詞
形態素に対する適切な品詞と品詞間の遷移を学習す
る
12. 感動詞 感動詞
2. 問題設定
2. 適切な品詞の学習
12
名詞 名詞
動詞
形容詞
副詞
助詞
動詞
形容詞
副詞
助詞
名詞
形態素に対する適切な品詞と品詞間の遷移を学習す
る
HMM[Brown et al., CL1992]
PYP-HMM[Blunsom, et al., ACL2011]
等,HMMを用いた手法
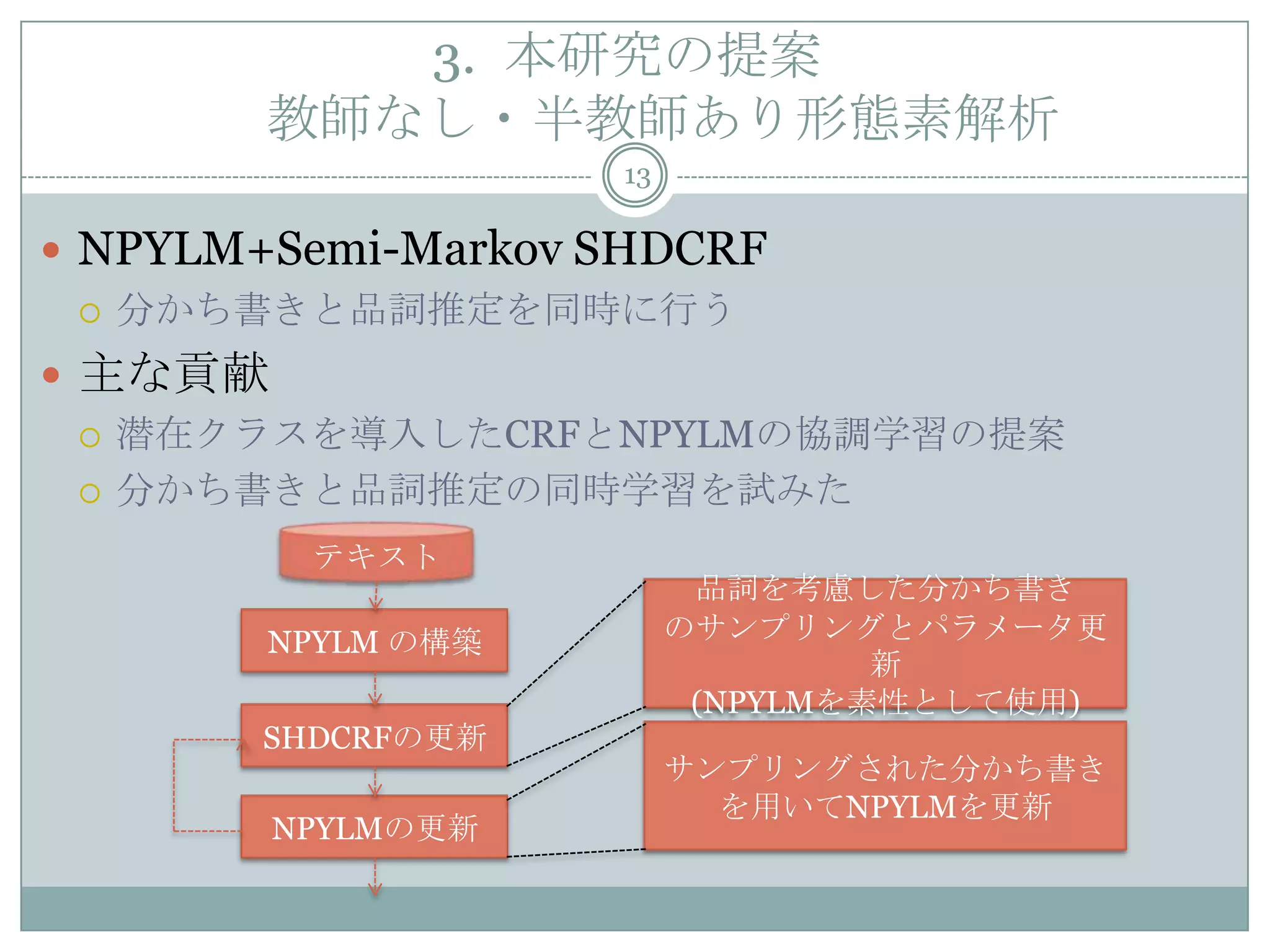
13. 3. 本研究の提案
教師なし・半教師あり形態素解析
13
NPYLM+Semi-Markov SHDCRF
分かち書きと品詞推定を同時に行う
主な貢献
潜在クラスを導入したCRFとNPYLMの協調学習の提案
分かち書きと品詞推定の同時学習を試みた
NPYLM の構築
テキスト
SHDCRFの更新
NPYLMの更新
品詞を考慮した分かち書き
のサンプリングとパラメータ更
新
(NPYLMを素性として使用)
サンプリングされた分かち書き
を用いてNPYLMを更新
14. 3. 1 提案手法のアイデア
14
分かち書きで獲得した形態素ごとに潜在クラスを割り当てる
割り当てられた潜在クラスを形態素の品詞と見なす
品詞間の遷移確率も学習するため,文法も獲得できる
15. 3. 2 SHDCRF(1/2)[Shen et al., WWW2011]
15
CRF の入力と出力の間に潜在クラスの層を導入したモデル
ラベル遷移ではなく潜在クラスの遷移を学習することで,ラ
ベル遷移では見れなかったサブクラスの遷移まで見ることが
できる
16. 3. 2 SHDCRF(2/2)[Shen et al., WWW2011]
16
SHDCRFは元々は検索クエリに対するユーザの意図推
定を目的として作られている
入力はセグメンテーション済みを想定しており,その
ままでは分かち書きと品詞推定の同時学習には利用で
きない
分かち書きと品詞推定の同時学習に適用するために,
Semi-Markov モデルに拡張する
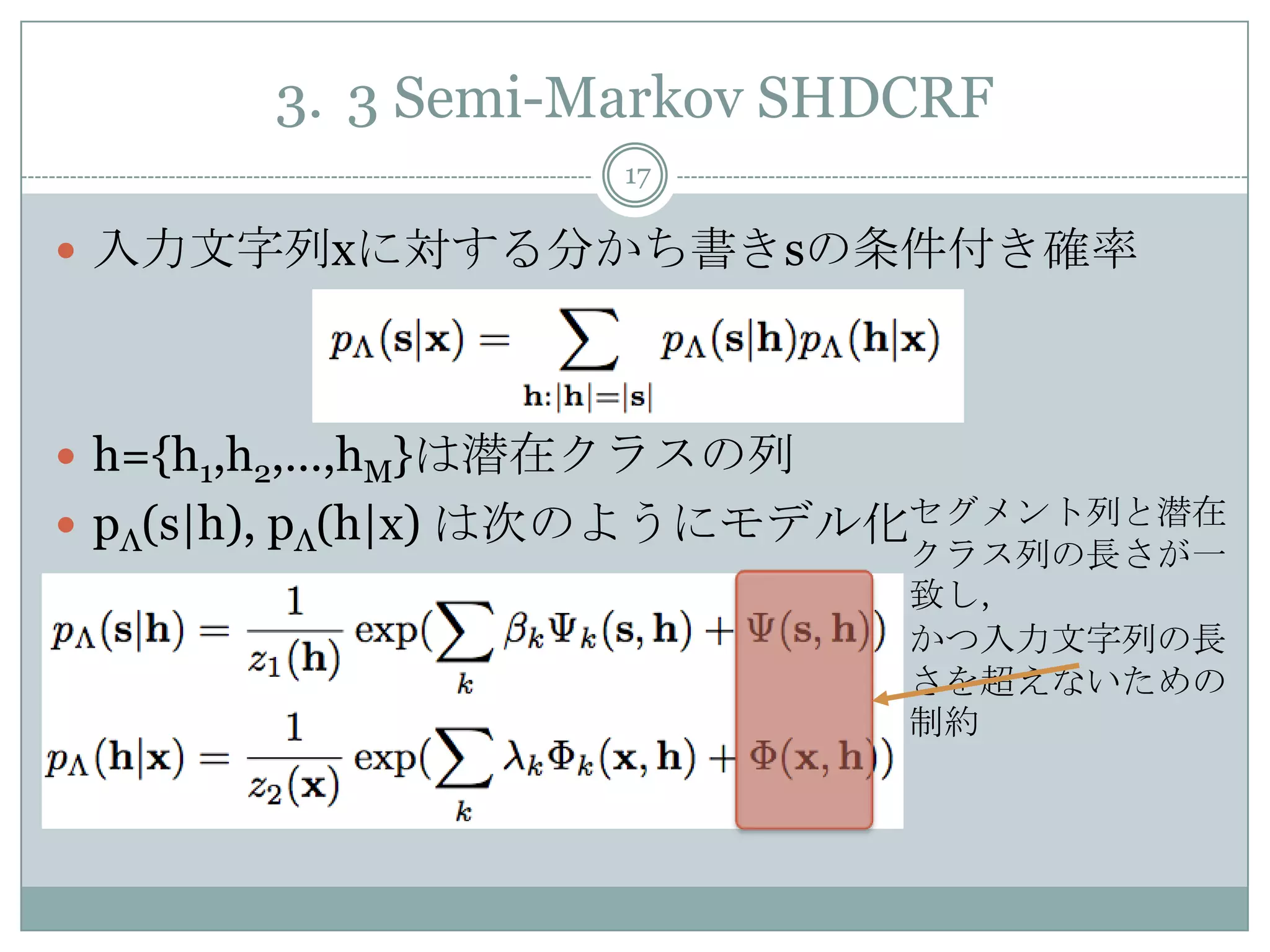
17. 3. 3 Semi-Markov SHDCRF
17
入力文字列xに対する分かち書きsの条件付き確率
h={h1,h2,…,hM}は潜在クラスの列
pΛ(s|h), pΛ(h|x) は次のようにモデル化セグメント列と潜在
クラス列の長さが一
致し,
かつ入力文字列の長
さを超えないための
制約
18. 3. 4 NPYLMとの協調学習
18
SHDCRFの素性関数の1つとしてNPYLMを利用する
NPYLM
入力系列と潜在クラスの間
の関係についての素性関数
セグメンテーションと潜在ク
ラスの間の関係についての素
性関数
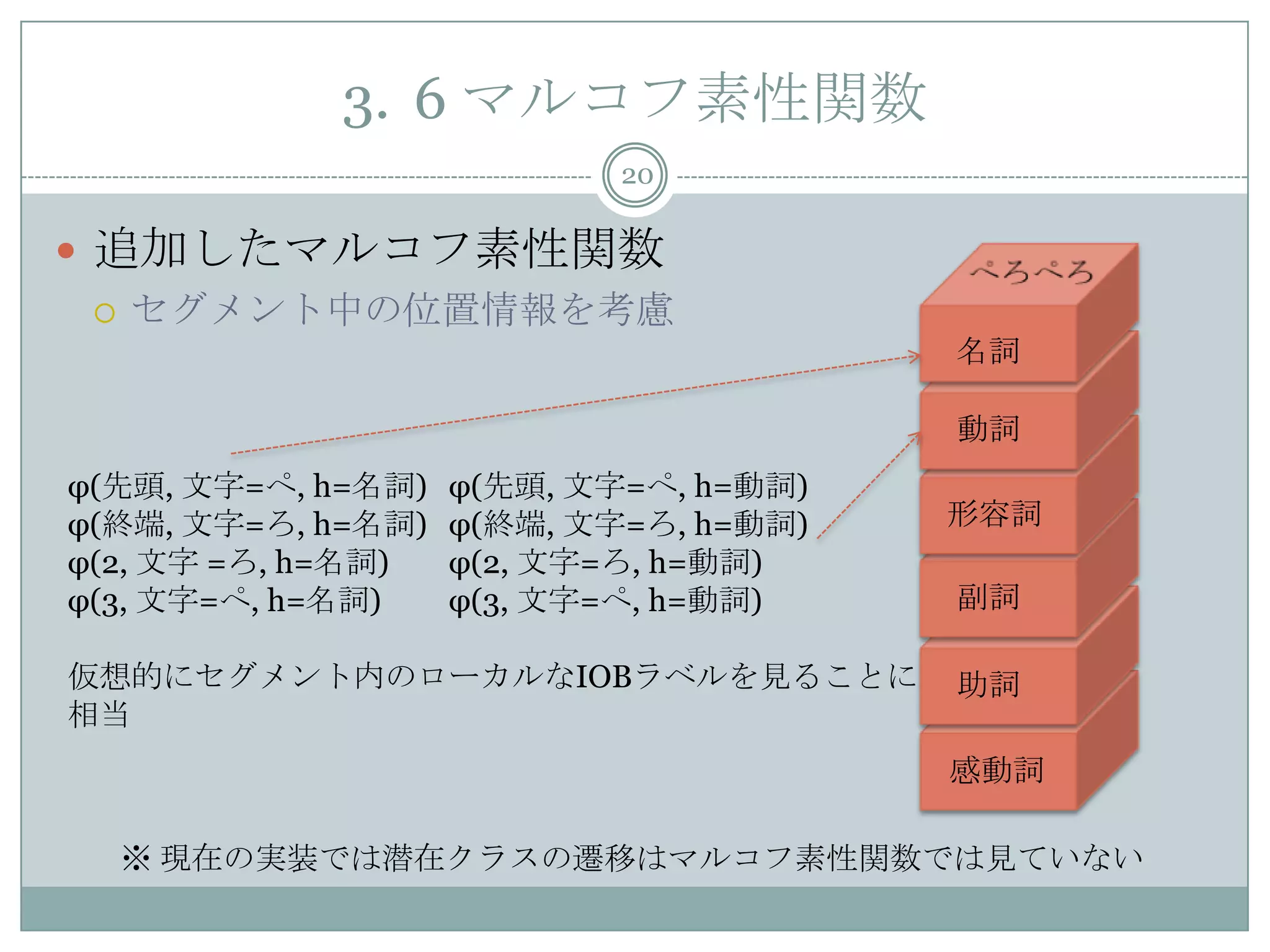
19. 3. 5 マルコフ素性関数の追加
19
セグメント素性関数をマルコフ素性関数の和とおく
j: セグメンテーションが与えられた時のセグメント
の位置
i: マルコフモデルで見た時の入力系列の位置
s(.): セグメントの先頭位置
e(.): セグメントの終了位置
20. 3. 6 マルコフ素性関数
20
追加したマルコフ素性関数
セグメント中の位置情報を考慮
※ 現在の実装では潜在クラスの遷移はマルコフ素性関数では見ていない
φ(先頭, 文字=ぺ, h=名詞) φ(先頭, 文字=ぺ, h=動詞)
φ(終端, 文字=ろ, h=名詞) φ(終端, 文字=ろ, h=動詞)
φ(2, 文字 =ろ, h=名詞) φ(2, 文字=ろ, h=動詞)
φ(3, 文字=ぺ, h=名詞) φ(3, 文字=ぺ, h=動詞)
仮想的にセグメント内のローカルなIOBラベルを見ることに
相当
感動詞
名詞
動詞
形容詞
副詞
助詞
名詞
21. 22. 23. 24. 5. 評価実験
24
使用データ
京大コーパス
毎日新聞1995年1月1日〜17日までの全記事約2万文
毎日新聞1995年1月〜12月の社説記事約2万文
テストデータ:ランダムで選んだ1000文
訓練データ:テストデータ以外
しょこたんブログ
2010年8月16日から2013年6月17日までの約13000記事
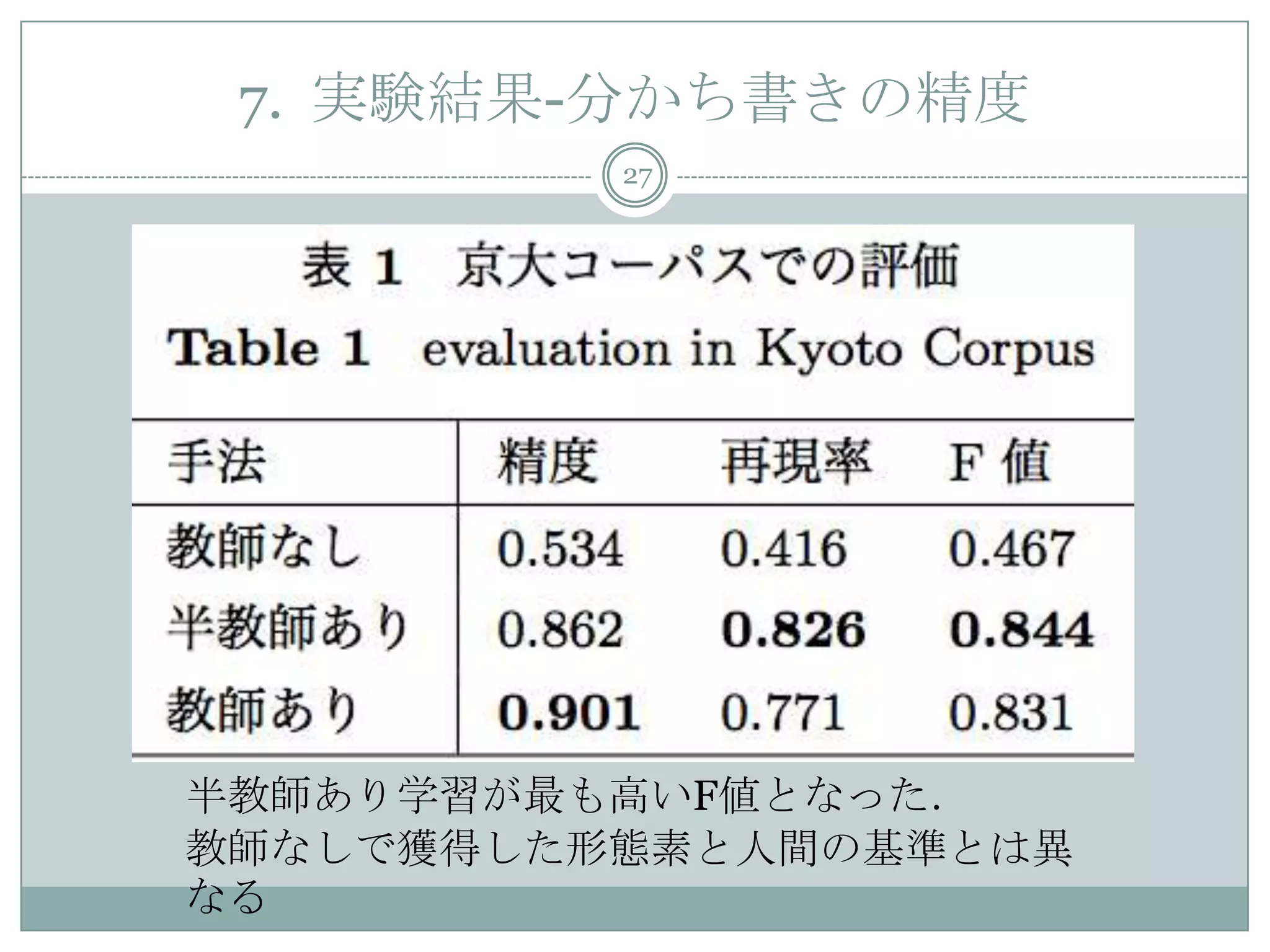
25. 6. 実験条件(1/2)
25
分かち書きの評価
1. 教師なし学習
訓練データに付与されている分かち書きを削除し,文字列のみを使
用
2. 半教師あり学習
ランダムに抽出した10K文を教師データ,残りは正解の分かち書き
を削除して使用
3. 教師あり学習
訓練データの分かち書きを全て使用
品詞推定
人手で付与された品詞と獲得した潜在クラスの対応関係を確認
26. 6. 実験条件(2/2)
26
使用した素性
セグメント素性
セグメントの長さ
潜在クラスの遷移
単語 unigram 確率
単語 bigram 確率
マルコフ素性
観測文字列の文字unigram
観測文字列の文字bigram
観測文字列の文字種unigram
観測文字列の文字種bigram ※文字種はUnicodeのCharacter nameを使
用
NPYLM
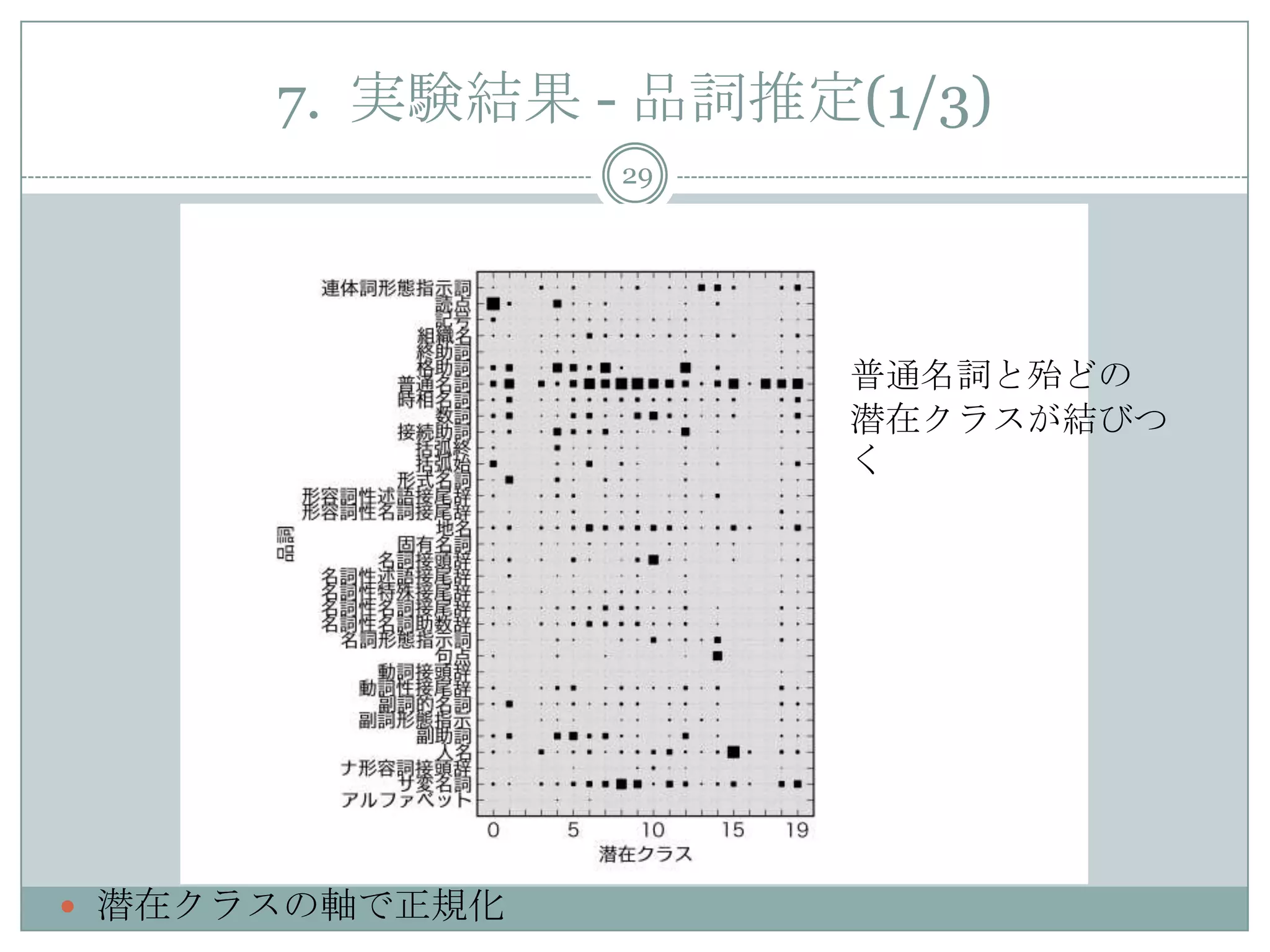
27. 28. 29. 7. 実験結果 - 品詞推定(1/3)
29
潜在クラスの軸で正規化
普通名詞と殆どの
潜在クラスが結びつ
く
30. 7. 実験結果 - 品詞推定(2/3)
30
正解と一致した形態素の品詞の分布
普通名詞: 106442
*: 84384
格助詞: 78642
サ変名詞: 52958
接続助詞: 38623
読点: 36484
...
終助詞: 321
ナ形容詞接頭辞: 189
アルファベット: 3
動詞接頭辞: 2
正しく分かち書きできた
形態素の品詞は名詞が
多く,偏りがある
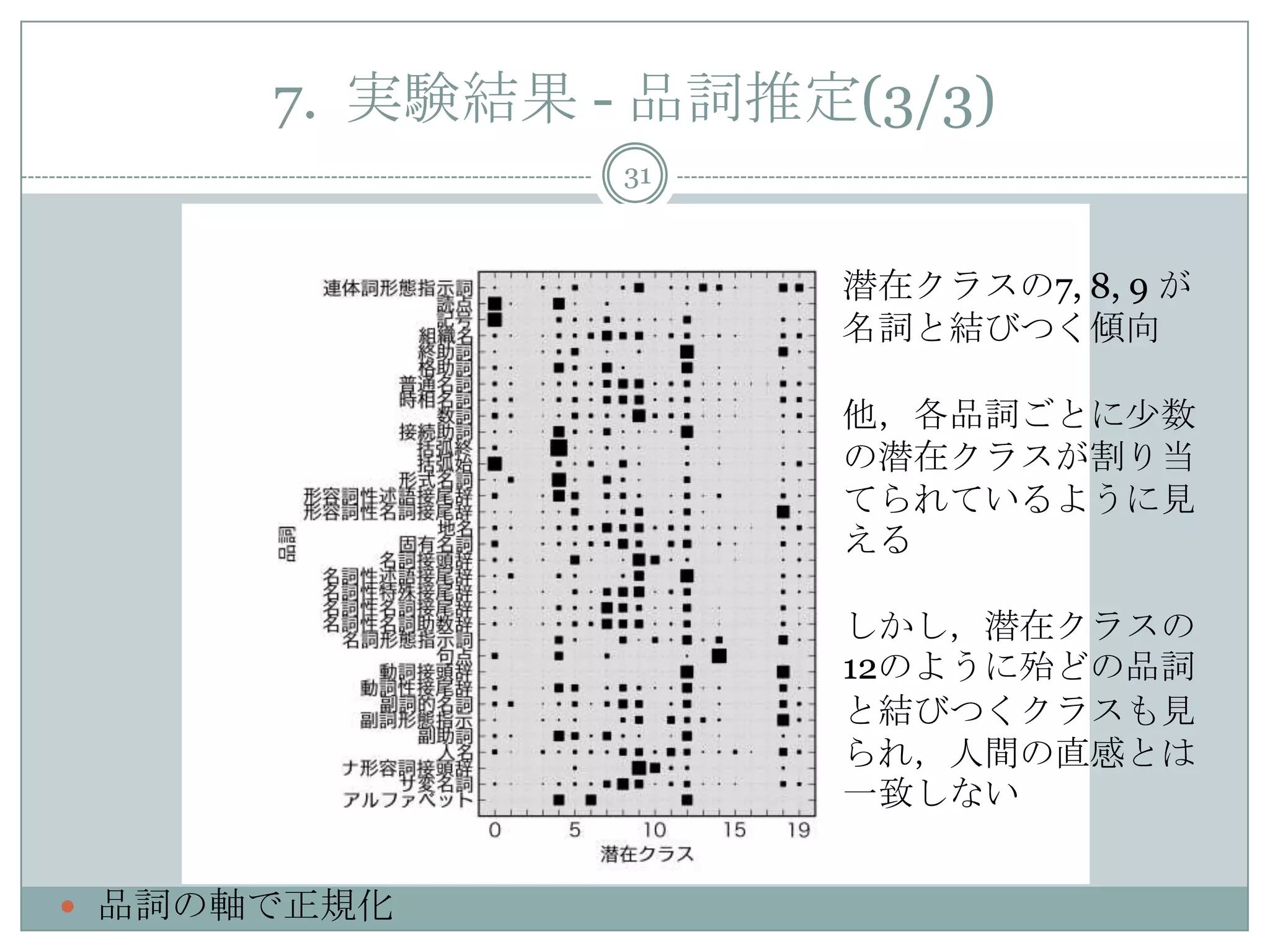
31. 7. 実験結果 - 品詞推定(3/3)
31
品詞の軸で正規化
潜在クラスの7, 8, 9 が
名詞と結びつく傾向
他,各品詞ごとに少数
の潜在クラスが割り当
てられているように見
える
しかし,潜在クラスの
12のように殆どの品詞
と結びつくクラスも見
られ,人間の直感とは
一致しない
32. 7. 実験結果 - ブログ記事の分かち書き
32
教師なしによるブログ記事の分かち書き
の例
顔文字や未知語の検出ができている
定量的な評価は正解を決めるのが難しいため今回は行っていない.
33. 8. まとめ
33
NPYLMとSemi-Markov SHDCRFの協調学習による教
師なし・半教師あり形態素解析を提案
分かち書きと品詞推定の同時学習を実現
京大コーパスを用いた評価で効果を示した
しょこたんブログを用いた実験で未知語や新語への対応ができる
ことを示した
今後の課題
品詞推定精度の向上
e.g. 品詞についても半教師あり学習を行うことで人間の直感と一致さ
せる
高速化
34. 9. 従来研究
34
教師なし学習に基づく分かち書き
MDL原理に基づく手法
[松原 他, NLP2007], [Argamon et al., ACL2004]
ノンパラメトリックベイズ法による形態素解析のための言語モデル
学習
[Mochihashi et al., ACL2009]
半教師あり学習に基づく分かち書き
NPYLMとCRFを用いた半教師あり形態素解析[持橋 他, NLP2011]
教師あり学習に基づく形態素解析
MEMMを用いた能動学習でアノテーションコストを削減[内元 他,
NLP2003]
書き言葉のアノテーション済みコーパスに少量の話し言葉のコーパ
スを追加して形態素解析の性能を改善
[松本 他, 自然言語処理研究会報告2001]









![2. 問題設定
1. 適切な分かち書きの学習
10
Input: ず も も も も ぺ ろ ぺ
ろ
ずもももも ぺろぺろ
ず も も も ぺ ろ ぺ ろ
ずも もも ぺろ ぺろ
もぺろ
可能な分かち書きの中から適切なパスを学習する
NPYLM[Mochihashi, et al., ACL2009]
NPYCRF[持橋,他., NLP2011]](https://image.slidesharecdn.com/signl213-130912211825-phpapp02/75/Signl213-10-2048.jpg)
![感動詞 感動詞
2. 問題設定
2. 適切な品詞の学習
12
名詞 名詞
動詞
形容詞
副詞
助詞
動詞
形容詞
副詞
助詞
名詞
形態素に対する適切な品詞と品詞間の遷移を学習す
る
HMM[Brown et al., CL1992]
PYP-HMM[Blunsom, et al., ACL2011]
等,HMMを用いた手法](https://image.slidesharecdn.com/signl213-130912211825-phpapp02/75/Signl213-12-2048.jpg)
![3. 2 SHDCRF(1/2)[Shen et al., WWW2011]
15
CRF の入力と出力の間に潜在クラスの層を導入したモデル
ラベル遷移ではなく潜在クラスの遷移を学習することで,ラ
ベル遷移では見れなかったサブクラスの遷移まで見ることが
できる](https://image.slidesharecdn.com/signl213-130912211825-phpapp02/75/Signl213-15-2048.jpg)
![3. 2 SHDCRF(2/2)[Shen et al., WWW2011]
16
SHDCRFは元々は検索クエリに対するユーザの意図推
定を目的として作られている
入力はセグメンテーション済みを想定しており,その
ままでは分かち書きと品詞推定の同時学習には利用で
きない
分かち書きと品詞推定の同時学習に適用するために,
Semi-Markov モデルに拡張する](https://image.slidesharecdn.com/signl213-130912211825-phpapp02/75/Signl213-16-2048.jpg)












![9. 従来研究
34
教師なし学習に基づく分かち書き
MDL原理に基づく手法
[松原 他, NLP2007], [Argamon et al., ACL2004]
ノンパラメトリックベイズ法による形態素解析のための言語モデル
学習
[Mochihashi et al., ACL2009]
半教師あり学習に基づく分かち書き
NPYLMとCRFを用いた半教師あり形態素解析[持橋 他, NLP2011]
教師あり学習に基づく形態素解析
MEMMを用いた能動学習でアノテーションコストを削減[内元 他,
NLP2003]
書き言葉のアノテーション済みコーパスに少量の話し言葉のコーパ
スを追加して形態素解析の性能を改善
[松本 他, 自然言語処理研究会報告2001]](https://image.slidesharecdn.com/signl213-130912211825-phpapp02/75/Signl213-34-2048.jpg)







![[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...](https://cdn.slidesharecdn.com/ss_thumbnails/acl2018reading-181029052106-thumbnail.jpg?width=640&height=640&fit=bounds)









![[NeurIPS2018読み会@PFN] On the Dimensionality of Word Embedding](https://cdn.slidesharecdn.com/ss_thumbnails/pfnonthedimensionalityofwordembedding-190126060357-thumbnail.jpg?width=640&height=640&fit=bounds)



































