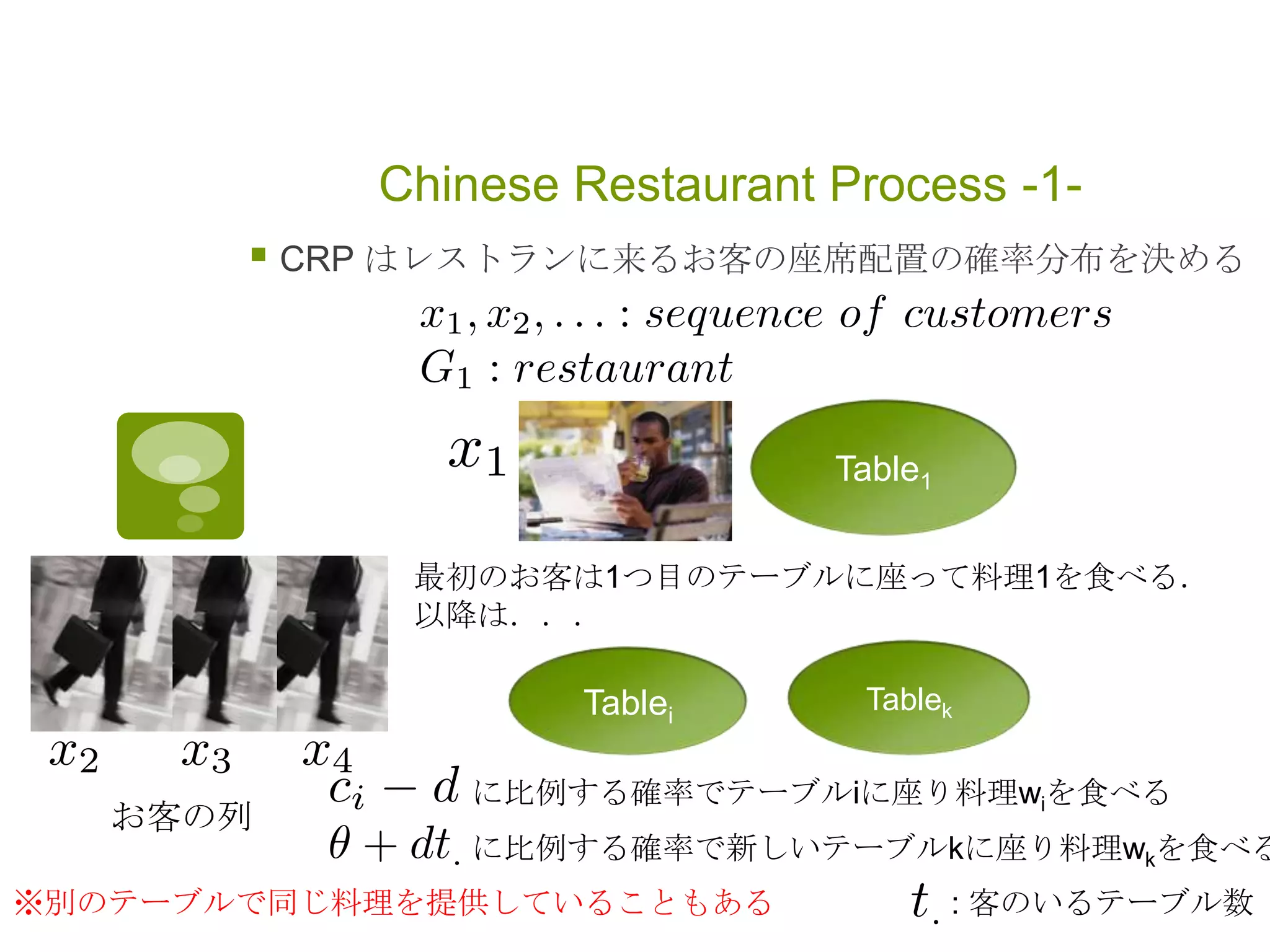
Chinese Restaurant Process-2-
新しいお客が料理 w を食べる確率は
料理 w を単語と見なすと unigram 言語モデル
: 今レストランにいるお客の総数
: 全語彙 V の一様分布 1/V
: 料理 w を食べている客の数
: 料理 w を提供しているテーブルの数
学習アルゴリズム
FOR i =1 to N
FOR t = 1 to T
READ {Context:u, word: wt}
IF i > 0 THEN
remove_customer(u, wt)
ENDIF
add_customer(u, wt)
ENDFOR
ENDFOR
add_customer(u, w)
(cuwk - d|u|)に比例する確率: cuwk++
(θ|u|+d|u|tu.)Pπ(u)(w)に比例する確率:
cuwk
new=1, tuw++
add_customer(π(u), w)
remove_customer(u, w)
cuwkに比例する確率: cuwk--
IF cuwk = 0 THEN
tuw--
remove_customer(π(u), w)
ENDIF
※dとθはカスタマの配置状態からサンプリングで推定できる
12.
Variable Pitman-Yor Language
Models[持橋,2006]
HPYLM ではn-gramオーダーが常に固定
Suffix Tree の深さ n-1 に必ずカスタマーが登録される
n が大きくなった時にノード数が膨大になってしまう
言語の意味のある固まり
n は常に一定ではない
e.g.
“The United States of America”(n=5)
“longer than”(n=2)
HPYLM を可変長 n-gram 言語モデルへ拡張
従来の可変長 n-gram は最大 n-gram を作ってからカットオフ
単語が生成された際の n を隠れ変数としてベイズ推定
文脈によってオーダーの異なる n-gram 言語モデルを提案
13.
可変長階層 Pitman-Yor 過程
Suffix Tree を根から辿る時に各ノードiで停止する確率を導入
共通のベータ事前分布から生成される
停止確率の分布から隠れ変数 n をサンプリングする
事例 t の n-gram オーダーを除外した全事例の n-gram オーダー
事例 t の配置を除外した全事例の Suffix Tree 上の座席配置
14.
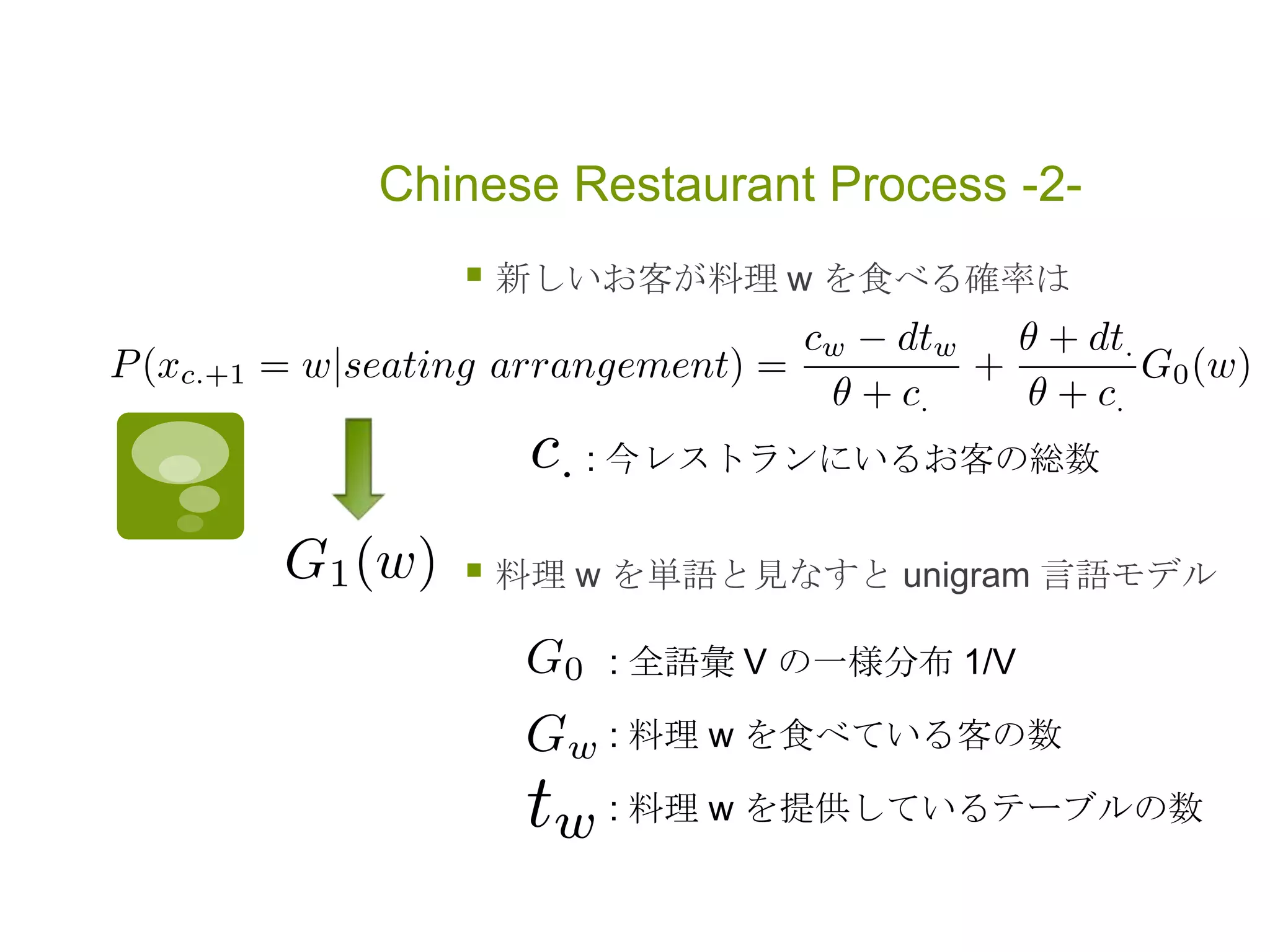
オーダー n のサンプリング
ベイズの定理から式を変形
ベータ事後分布の期待値で停止確率と通過確率を代用
ノード i にカスタマが停止した回数
ノード i をカスタマが通過した回数
オーダーをntと固定した時の単語の生起確率(HPYLMと同様)
ノードiで停止する期待値
15.
学習アルゴリズム
FOR i =1 to N
FOR t = 1 to T
READ {Context:u, word: wt, nt}
IF i > 0 THEN
remove_customer(u, wt, nt)
ENDIF
// オーダーとレストランを決定
nt = sample_order(u, wt)
add_customer(u, wt, nt)
ENDFOR
ENDFOR
add_customer(u, w, n)
IF n == |u| THEN a++
ELSE b++ ENDIF
cuwk - d|u|)に比例する確率: cuwk++
(θ|u|+d|u|tu.)Pπ(u)(w)に比例する確率:
cuwk
new=1, tuw++
add_customer(π(u), w, n)
remove_customer(u, w, n)
IF n == |u| THEN a--
ELSE b-- ENDIF
remove_order(u, w, n)
cuwkに比例する確率: cuwk--
IF cuwk = 0 THEN
tuw--
remove_customer(π(u), w, n)
ENDIF





![Hierarchical Pitman-Yor
Language Models [Teh, 2006]
ベイズアプローチから提案された適切なス
ムージングを導入した確率的言語モデル
これまで最も良いとされてきた Interpolated
Kneser-Ney は HPYLM の近似となっている
Interpolated Kneser-Ney
長い文脈に続く w の出現回数をディスカウントして,
短い文脈の w の確率で補完する
の値は交差検定で求める.
この部分を で変化させたり等の工夫がされてきた.](https://image.slidesharecdn.com/pylmpublic-130719052138-phpapp01/75/Pylm-public-5-2048.jpg)




![Variable Pitman-Yor Language
Models[持橋,2006]
HPYLM ではn-gramオーダーが常に固定
Suffix Tree の深さ n-1 に必ずカスタマーが登録される
n が大きくなった時にノード数が膨大になってしまう
言語の意味のある固まり
n は常に一定ではない
e.g.
“The United States of America”(n=5)
“longer than”(n=2)
HPYLM を可変長 n-gram 言語モデルへ拡張
従来の可変長 n-gram は最大 n-gram を作ってからカットオフ
単語が生成された際の n を隠れ変数としてベイズ推定
文脈によってオーダーの異なる n-gram 言語モデルを提案](https://image.slidesharecdn.com/pylmpublic-130719052138-phpapp01/75/Pylm-public-12-2048.jpg)













![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...](https://cdn.slidesharecdn.com/ss_thumbnails/acl2018reading-181029052106-thumbnail.jpg?width=640&height=640&fit=bounds)








































