[NeurIPS2018読み会@PFN] On the Dimensionality of Word Embedding
1.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
読み手:竹中 誠(首都大 M2)
*図・表は論文内のものを使用しました
2019年1月26日 NeurIPS2018読み会@PFN
2.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
一言で言うと
• 単語分散表現の次元数に最適値が存在することを理論的に示した
1
3.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
論文の貢献
1. 単語埋め込み間の非類似度を測る新しい損失関数を提案した
• Pairwise Inner Product(PIP)損失
2. 分散表現の次元数選択に関して、バイアス-バリアンスのトレードオフ
の関係を理論的に示した
• これに基づき、最適な次元が存在することを示した
3. 既存の埋め込み手法のパラメータに関する頑健性を定量的に評価した
• LSA や Skip-gram, GloVe が次元数に対して頑健であることを示した
4. 数学的に厳密な埋め込み次元数の選択手法をPIP損失の期待損失を最小
化する戦略にもとづき提案した
• 既存アルゴリズム(LSA, Skip-gram, GloVe)に適用し実験で確かめた
2
4.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
その前に、単語分散表現に関する前提
• 分散表現はユニタリ不変
• 複数の分散表現をひとつの空間にマッピングするような直交変換を構成できたという研
究で、概ねユニタリ不変だったのは副産物(だと個人的に理解している)
• 例:Hamilton et al. 2016 では、意味(分散表現)の時系列変化を捉えるために(ry
• 古典的にはカウントベースの行列分解(LSAなど)
• PMI行列やカウント行列を行列分解して、特異値の大きいほうからk次元とってきてEを
構成する方法
• ニューラルベースのやつも暗黙的に行列分解
• Skip-gram Negative Sampling
• PMI行列 の α=0.5 の行列分解に対応 [Levy & Goldberg2014]
• いくつか非自明な仮定はある
• GloVe は、log-count 行列の γ 乗の行列分解に対応(γ∈[0,1])[Levy et al. 2015]
3
5.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
研究のモチベーション
• 単語分散表現の次元数は重要ですよね
• みんな認識しつつも理論はなかったのでいずも経験的な決め方だった
• 典型的には300次元とか
• 小さすぎてもダメ
• 表現力不足(ハイバイアス)
• 大きくてもダメ
• over-fitting(ハイバリアンス)
• 計算量的にもアレ
• 最適な次元数があるはずで理論的に示したいよね
• Arora も言ってるし
Arora [2016] discussed in an article about a mysterious empirical observation of word embeddings:
“... A striking finding in empirical work on word embeddings is that there is a sweet spot for the
dimensionality of word vectors: neither too small, nor too large”
http://www.offconvex.org/2016/02/14/word-embeddings-2/
4
6.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
提案手法
• 分散表現のユニタリ不変性に着目したPIP行列を定義
• 真の分散表現(oracle embeddings)と観測データでトレーニングした
分散表現(training embeddings)のPIPの差をPIP損失として定義
• PIP損失の期待値の上界を導出
• 埋め込み次元kについてバイアスーバリアンス分解
• PIP損失最小のkがEの最適次元数 K* だと思う
5
7.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
準備:PIP行列、PIP損失
• PIP 行列の定義:i, j 成分は i-th 単語ベクトルと j-th 単語ベクトルの内積
• PIP行列の気持ち
• PIP行列の i 行目はその埋め込みにおける i-th 単語ベクトルviの相対位置
• PIP損失の定義
• PIP損失の気持ち
• 2つの埋め込み E1 と E2 における単語ベクトルの相対位置の変化
• E1におけるviの相対座標と E2 における vi の相対座標の相対関係(差)
• 故にこれらを小さくすることは E1 と E2 を近づけるということ
• E がユニタリ不変であれば E1と E2 の PIP損失=0
• PIP損失は2つのEがユニタリ変換に対してどれくらい不変か
転置とって左からかけると
U:ユニタリ行列
6
8.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
PIP損失にもとづく問題の定式化
• oracle embeddings:E
• Signal 行列 M を次元削減してd次元埋め込み行列Eを得る
• Mの例:真のPMI行列
• ちゃんと書くとこういう感じ
• training embeddings:
• 観測する M にはノイズ Z がのっている(Zの要素はiidなN(0, 分散σ2)
• 𝐸とE を近づけたい(近づき方のパラメータ依存性を知りたい)
• これを評価していく
7
9.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
(結論だけ)PIP 損失の次元数k依存性
• 定理1(α=0)、定理2(0<α<=1)から、オラクル埋め込み E と経験埋
め込み 𝐸 の PIP 損失の期待値の上界(定理3)を導出
• PIP 損失の期待値をkに対するバイアス項ーバリアンス項に分解
バイアス項 バリアンス項
8
10.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
期待PIP損失の特異値λに関する依存性に着目する
• バイアス項(第1項)→ 特異値の小さい側(k+1から最後(d)まで)が寄与する項
• kの増加に対して第1項は減少
• 特異値の大きいところで支配されている項
• kが十分に大きい(スペクトルの合計エネルギーの半分以上)のところでは、kの増加によるPIP損失への寄与は
わずか
• バリアンス項(2,3項)→特異値の大きい側(1からkまで)が寄与する項
• PIP損失に対して λk
2α-1 の依存性をもつ
• λk が小さい(<1)とき、αの減少に関して λk^2α-1 は増加する(PIP損失が増加)が増加の仕方が αの値に依存
• 2α-1<0 (α<0.5) → kの変化にPIP損失が敏感
• 0.5 ≦ α <1 で sub-linear →kの変化にPIP損失が鈍感
• 0.5 ≦ α <1のときover-parametrizationに対してロバスト
• つまり、αが大きいとき、大きいkを選んだとしてもoverfitしにくい
• 定理3 (主定理)
• ポイント:特異値λkの大きい側の寄与か、小さい側の寄与か
kまでの和
k+1からの和
9
11.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
評価実験
• 分散表現の頑健性と α の関係の理論評価と実験による検証
• Skipgram と Glove (α=0.5) が over-parametrization に対して頑健な
設定になっていることを示す
• トレーニングデータは text8(English Wikipedia のサブセット)
10
12.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
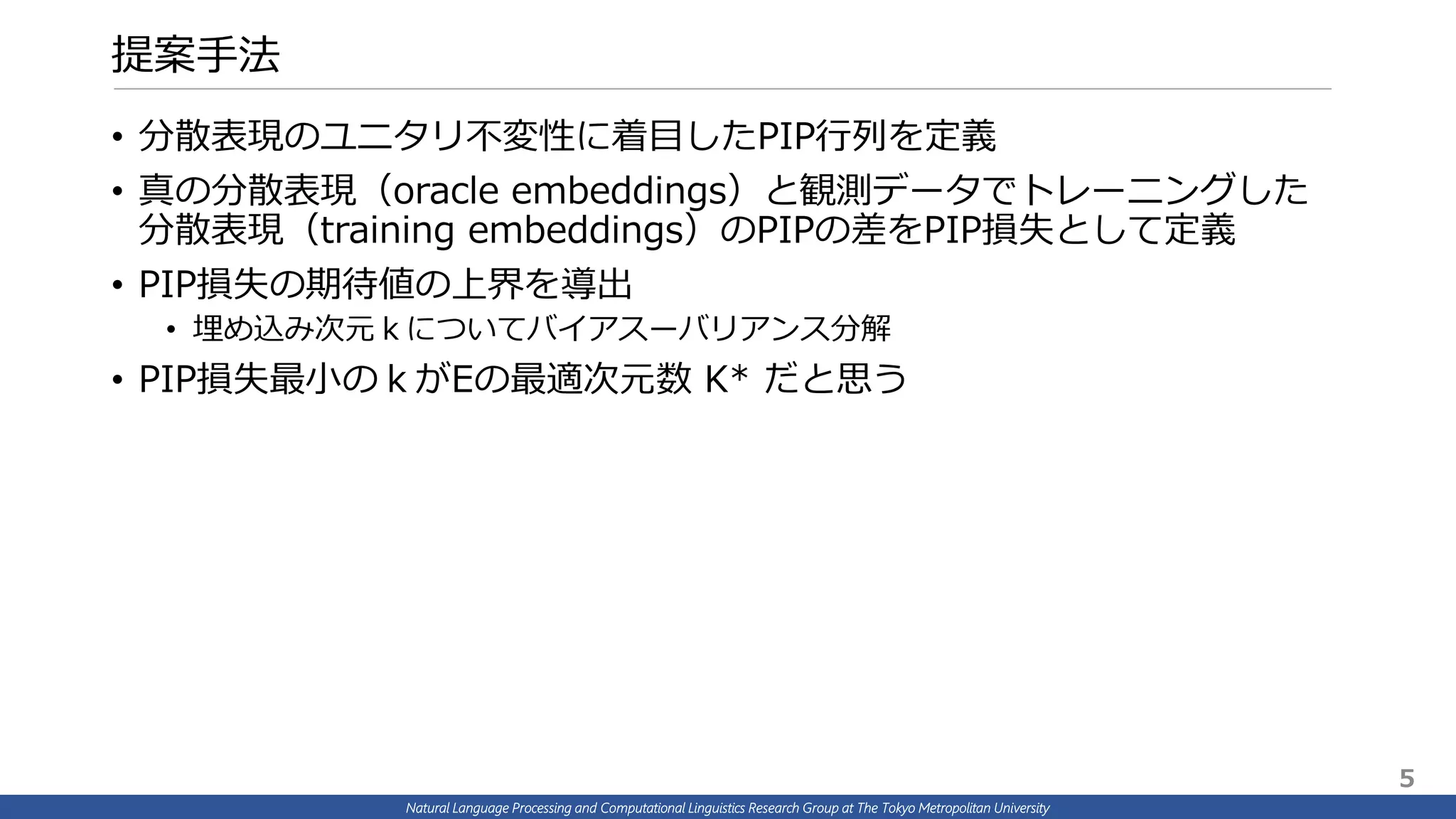
α および k 依存性の理論予想を検証
• (a) が理論予想(x軸:次元数k、y軸:相対PIP損失(低が良))
• (b)(c) が PPMI LSA の実験結果(x軸:次元数k、y軸:score(高が良))
• 線の色が α の値の違い α={0.0, 0.25, 0.5, 0.75, 1.0}
• k→大としたとき
• 小さいαでは性能への寄与が敏感
• 大きいαでは性能への寄与が鈍感
• 理論予想と実験結果がコンシステント
11
13.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
Skip-gram と GLoVe は over-parametrization(k→大) で頑健か?
• Skip-gramとGloVe(α=0.5)は提案理論では頑健(kの増加に対するPIP
損失の増加が鈍感)な領域であったが本当にそうなっているか
• これを確かめたのが Figure2(Skip-gram), Figure3(GloVe)
• 次元数k(横軸)の増加に対してAccuracy(縦軸)は鈍感であることがわかる
• 縦軸が高いほど高性能
12
14.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
LSA, Skip-gram, GloVe の k* を推定する
• Monte-Carlo サンプリング で ground-truth な E を得る
• ground-truth と 経験埋め込みとの PIP 損失を評価
• sub-optimal を表現する interval の定義
• intervalのこころ
• k が p% の範囲にあれば k* に対して最大 p% 悪化
13
15.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
PIP損失最小化に基づく最適次元数 k* の推定方法
• 摂動項 Z の標準偏差 σ、特異値をデータから推定する
• Noise Estimation
• 標準偏差 σ の推定量
• count-twice trick(Mを同じサイズでランダムに二分割→M~1,M~2)
• nは全語彙数(mn→∞でσ→ゼロ)
• Spectral Estimation
• universal singular value thresholding(USVT) [Chatterjee, 2015]
• 特異値 λ の推定量
λ~:empiricalな特異値
σ:推定したσを使う
14
Random matrix with Zero mean and 4σ2 variance
16.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
【結果】LSA の k*
• signal 行列 M は、PPMI行列を使う
• 大きい α で over-parametrization の影響少ない
• α が大きければ大きいほど interval が広い
• 前の結果(5.1)と無撞着
• empirical な最適次元数は理論最適値 k* の 5% interval にある
15
17.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
【結果】Skip-gram と GloVe のk*
• Skip-gram
• singal 行列 M は PMI 行列
• GloVe
• singal 行列 M は log-count 行列
• いずれも、empirical 最適値 は 理論最適値k*の 5 ないし10% interval にある
• 理論と実験は無撞着であることを確認できた
16
18.
Natural Language Processingand Computational Linguistics Research Group at The Tokyo Metropolitan University
まとめ
• 単語分散表現の次元数に対する頑健性を理論評価した
• 2つの埋め込み間の非類似度を測るPIP損失を提案
• 次元数に対して分散表現の性能はバイアスーバリアンスのトレードオフの関係にあ
ることを示した
• 提案理論に基づき、overfitに対する頑健性とαの関係を定量的に評価し、
既存手法(LSA、Skip-gram、GloVe)の頑健性を確かめた
• 分散表現の最適次元数k*の選択手法を提案
17


![Natural Language Processing and Computational Linguistics Research Group at The Tokyo Metropolitan University
その前に、単語分散表現に関する前提
• 分散表現はユニタリ不変
• 複数の分散表現をひとつの空間にマッピングするような直交変換を構成できたという研
究で、概ねユニタリ不変だったのは副産物(だと個人的に理解している)
• 例:Hamilton et al. 2016 では、意味(分散表現)の時系列変化を捉えるために(ry
• 古典的にはカウントベースの行列分解(LSAなど)
• PMI行列やカウント行列を行列分解して、特異値の大きいほうからk次元とってきてEを
構成する方法
• ニューラルベースのやつも暗黙的に行列分解
• Skip-gram Negative Sampling
• PMI行列 の α=0.5 の行列分解に対応 [Levy & Goldberg2014]
• いくつか非自明な仮定はある
• GloVe は、log-count 行列の γ 乗の行列分解に対応(γ∈[0,1])[Levy et al. 2015]
3](https://image.slidesharecdn.com/pfnonthedimensionalityofwordembedding-190126060357/75/NeurIPS2018-PFN-On-the-Dimensionality-of-Word-Embedding-4-2048.jpg)
![Natural Language Processing and Computational Linguistics Research Group at The Tokyo Metropolitan University
研究のモチベーション
• 単語分散表現の次元数は重要ですよね
• みんな認識しつつも理論はなかったのでいずも経験的な決め方だった
• 典型的には300次元とか
• 小さすぎてもダメ
• 表現力不足(ハイバイアス)
• 大きくてもダメ
• over-fitting(ハイバリアンス)
• 計算量的にもアレ
• 最適な次元数があるはずで理論的に示したいよね
• Arora も言ってるし
Arora [2016] discussed in an article about a mysterious empirical observation of word embeddings:
“... A striking finding in empirical work on word embeddings is that there is a sweet spot for the
dimensionality of word vectors: neither too small, nor too large”
http://www.offconvex.org/2016/02/14/word-embeddings-2/
4](https://image.slidesharecdn.com/pfnonthedimensionalityofwordembedding-190126060357/75/NeurIPS2018-PFN-On-the-Dimensionality-of-Word-Embedding-5-2048.jpg)







![Natural Language Processing and Computational Linguistics Research Group at The Tokyo Metropolitan University
PIP損失最小化に基づく最適次元数 k* の推定方法
• 摂動項 Z の標準偏差 σ、特異値をデータから推定する
• Noise Estimation
• 標準偏差 σ の推定量
• count-twice trick(Mを同じサイズでランダムに二分割→M~1,M~2)
• nは全語彙数(mn→∞でσ→ゼロ)
• Spectral Estimation
• universal singular value thresholding(USVT) [Chatterjee, 2015]
• 特異値 λ の推定量
λ~:empiricalな特異値
σ:推定したσを使う
14
Random matrix with Zero mean and 4σ2 variance](https://image.slidesharecdn.com/pfnonthedimensionalityofwordembedding-190126060357/75/NeurIPS2018-PFN-On-the-Dimensionality-of-Word-Embedding-15-2048.jpg)

















![[研究室論文紹介用スライド] Adversarial Contrastive Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/acepub-181119101425-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]It's not just size that maters small language models are also few sho...](https://cdn.slidesharecdn.com/ss_thumbnails/itsnotjustsizethatmaterssmalllanguagemodelsarealsofew-shotlearners-210910034516-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[論文紹介] Understanding and improving transformer from a multi particle dynamic ...](https://cdn.slidesharecdn.com/ss_thumbnails/understandingandimprovingtransformerfromamulti-particledynamicsystempointofview2-200506083516-thumbnail.jpg?width=640&height=640&fit=bounds)


![[論文紹介] Towards Understanding Linear Word Analogies](https://cdn.slidesharecdn.com/ss_thumbnails/pub20191102aclmoura-191109143218-thumbnail.jpg?width=640&height=640&fit=bounds)
