EMNLP 2015 読み会 @ 小町研 "Morphological Analysis for Unsegmented Languages using Recurrent Neural Network Language Model"
首都大学東京 情報通信システム学域 小町研究室に行われた EMNLP 2015 読み会で "Morphological Analysis for Unsegmented Languages using Recurrent Neural Network Language Model" を紹介した際の資料です。
EMNLP 2015 読み会 @ 小町研 "Morphological Analysis for Unsegmented Languages using Recurrent Neural Network Language Model"
1.
EMNLP 2015 読み会@小町研
“Morphological Analysis for Unsegmented
Languages using Recurrent Neural Network
Language Model “
Hajime Morita, Daisuke Kawahara, Sadao Kurohashi
首都大学東京 情報通信システム学域
小町研究室 M2 塘 優旗
1
2.
Abstract
Recurrent NeuralNetwork Language Model
(RNNLM) を利用し、新たな形態素解析モ
デルを提案
意味的に一般化された言語モデルとして
RNNLMを利用
二つの日本語コーパスにおいて、提案手法
がベースラインに比べて良い結果を示した
2
3.
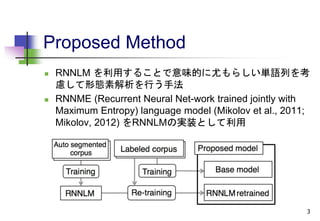
Proposed Method
RNNLMを利用することで意味的に尤もらしい単語列を考
慮して形態素解析を行う手法
RNNME (Recurrent Neural Net-work trained jointly with
Maximum Entropy) language model (Mikolov et al., 2011;
Mikolov, 2012) をRNNLMの実装として利用
3
4.
Recurrent Neural Network
LanguageModel (RNNLM)
Auto Segmented Corpus
生のWebコーパス1,000万文 (Kawahara and Kurohashi, 2006)を
JUMANで自動解析し作成
JUMANにおける解析誤りが含まれる
Training
Auto Segmented Corpus中のPOSタグ無し,レンマ化された単語
列で学習
学習されたモデルは,自動解析における誤りを含む
Re-training
人手でラベル付けされたコーパスで再学習
機能語の単語列に関するエラーの解消のため
4
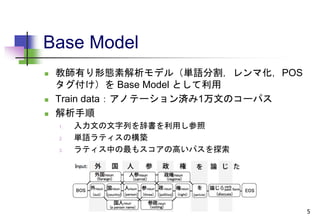
Base Model
辞書- 80万単語
レンマ,POS,活用形 の情報を含む
JUMAN辞書
追加辞書 – 日本語Wikipedia中の記事中の箇条書き,記事タイトル
で主に構成
Scoring function
Features
単語の 基本形, POS, 活用形 のunigram, bigram (Kudo et al. 2004)
文字種,trigram (Zhang and Clark 2008)
6
y : タグ付けされた単語列
Φ(y) : y に対しての素性べクトル
w : 重みベクトル
7.
Base Model
Training
重みベクトル w の学習のために soft confidence-weighted learning
(Wang et al., 2012) を利用
out-of-vocabulary (OOV) の取り扱い
解析時:文字種で入力列を分割することで自動で単語を生成
学習時:辞書中には無いが学習コーパスにある単語は OOV 単語
としてそれらの重みを学習する
Decording
second-order Viterbi algorithm (Thede and Harper, 1999)を利用す
ることで厳密なデコードが可能
7
RNNLM Integrated Model
Decording
RNNLMにおける可能な単語ラティスは組み合
わせ爆発が起こるため beam search (Zhang
and Clark 2008) を利用し,ビーム幅中の可能
なcontext 候補のみ保持する
十分なビームサイズは単語列の曖昧な候補を保
持することができると考える
各候補は context を表現するベクトルを持ち,
二つの単語の履歴を持つ
9
10.
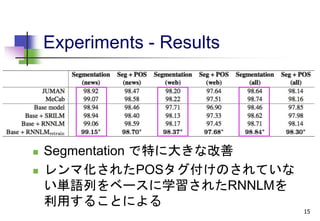
Experiments - Datasets
人手タグ付きコーパス
(RNNLMの再学習, base model の学習に利用)
Kyoto University Text Corpus (Kawahara et al.,
2002)
Kyoto University Web Document Leads Corpus
(Hangyo et al., 2012)
Test : 2000, Develop : 500, Train : 45000
10
11.
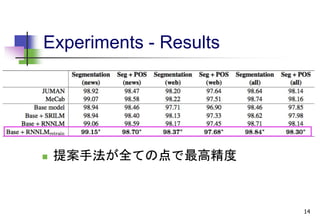
Experiments - Baselines
JUMAN
MeCab
Base model のみ
Base model + 従来の言語モデル
3-gram 言語モデル(同じ自動単語分割コーパ
スからSRILMを使いKneser-Ney Smothing を
行い作成)
11
12.
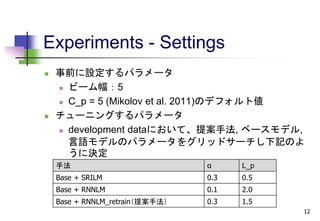
Experiments - Settings
事前に設定するパラメータ
ビーム幅:5
C_p = 5 (Mikolov et al. 2011)のデフォルト値
チューニングするパラメータ
development dataにおいて、提案手法, ベースモデル,
言語モデルのパラメータをグリッドサーチし下記のよ
うに決定
12
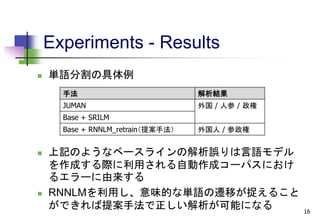
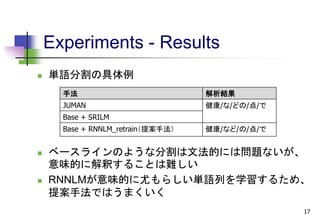
手法 α L_p
Base + SRILM 0.3 0.5
Base + RNNLM 0.1 2.0
Base + RNNLM_retrain(提案手法) 0.3 1.5
#4 RNNME language model (Mikolov et al., 2011; Mikolov, 2012) をRNNLMの実装として利用
RNNLM の学習リソース
自動で単語分割され構築されたコーパス
人手でラベル付けされたコーパス
Recurrent Neural Net-work trained jointly with Maximum Entropy model













![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)












![[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...](https://cdn.slidesharecdn.com/ss_thumbnails/acl2018reading-181029052106-thumbnail.jpg?width=640&height=640&fit=bounds)






























