Download to read offline








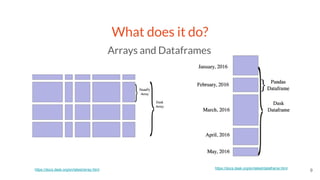
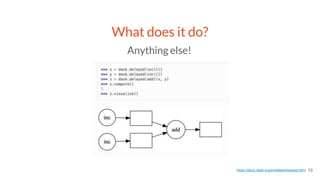


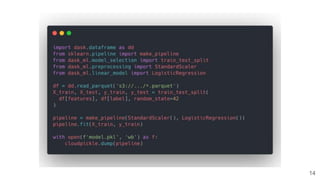




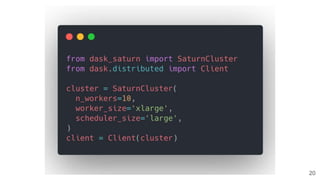

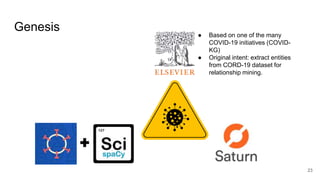

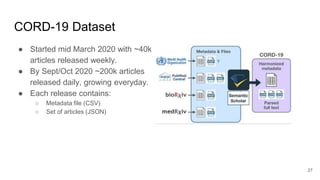

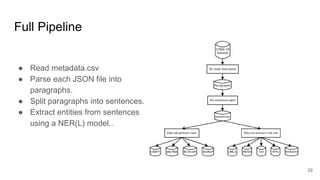




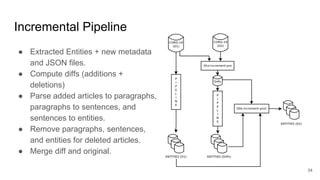






This document provides an overview of a project to extract entities from the CORD-19 dataset using SciSpaCy named entity recognition models on a Dask cluster. The goals were to create standoff entity annotations for the CORD-19 papers and output the data in a structured format. The pipeline involved parsing papers to paragraphs, splitting paragraphs to sentences, and then extracting entities from sentences using various NER models. The output was stored in Parquet files that could be accessed via Dask or Spark. The project delivered Jupyter notebooks demonstrating the code and entity data in Parquet format totaling around 70GB.



























































![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)

