Download to read offline








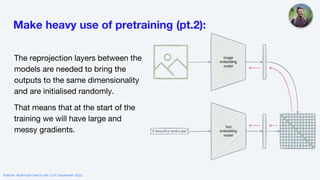
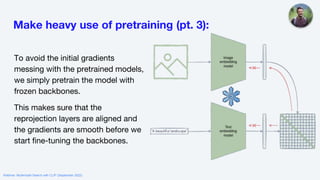


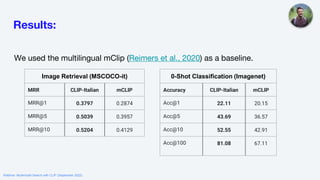
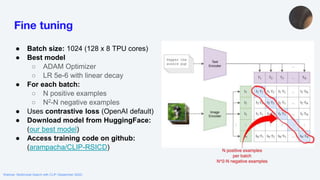
![Tips and Tricks pt. 2
Always augment your data!
We used pretty crazy image
transforms.
We tried text augmentations but did
not use them due to lack of time.
transforms = torch.nn.Sequential(
Resize(
[image_size],
interpolation=InterpolationMode.BICUBIC),
RandomCrop(
[image_size],
pad_if_needed=True,
padding_mode="edge"),
ColorJitter(hue=0.1),
RandomHorizontalFlip(),
RandomAffine(
degrees=15,
translate=(0.1, 0.1),
scale=(0.8, 1.2),
shear=(-15, 15, -15, 15),
interpolation=InterpolationMode.BILINEAR,
fill=127),
RandomPerspective(
distortion_scale=0.3,
p=0.3,
interpolation=InterpolationMode.BILINEAR,
fill=127),
RandomAutocontrast(p=0.3),
RandomEqualize(p=0.3),
ConvertImageDtype(torch.float)
)
Webinar: Multimodal Search with CLIP (September 2022)](https://image.slidesharecdn.com/multimodalsearchft-220901173955-1cf9a234/85/Searching-Across-Images-and-Test-20-320.jpg)














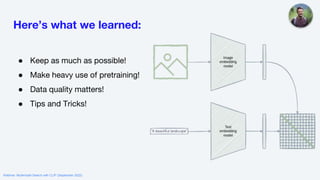
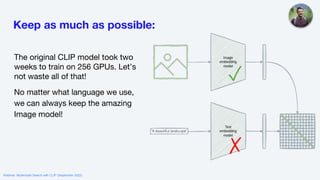
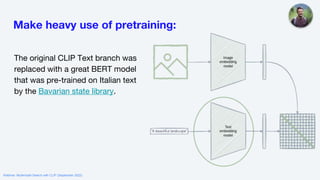
The webinar on multimodal search with CLIP, held in September 2022, provided an overview of the OpenAI CLIP model, including its applications in image and text search. It discussed fine-tuning CLIP for specific languages like Italian and specialized domains such as satellite imagery, highlighting tips for successful training and data quality. The session concluded with a demonstration of improved performance metrics in various search tasks using the adapted models.








































![[DSC Europe 24] Nemanja Milosevic - Beyond Supervised Learning with Zero-Shot...](https://cdn.slidesharecdn.com/ss_thumbnails/nemanjamilosevic-241219150756-b1cc16e6-thumbnail.jpg?width=640&height=640&fit=bounds)




![251027_Thuy_Labseminar[Scaling Language-Image Pre-training via Masking].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251027thuylabseminar-251027105015-a1b9f3e8-thumbnail.jpg?width=640&height=640&fit=bounds)

![251103_Thuy_Labseminar[Grounded Language-Image Pre-training].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103thuylabseminar-251103113311-941d56eb-thumbnail.jpg?width=640&height=640&fit=bounds)







































