Downloaded 14 times

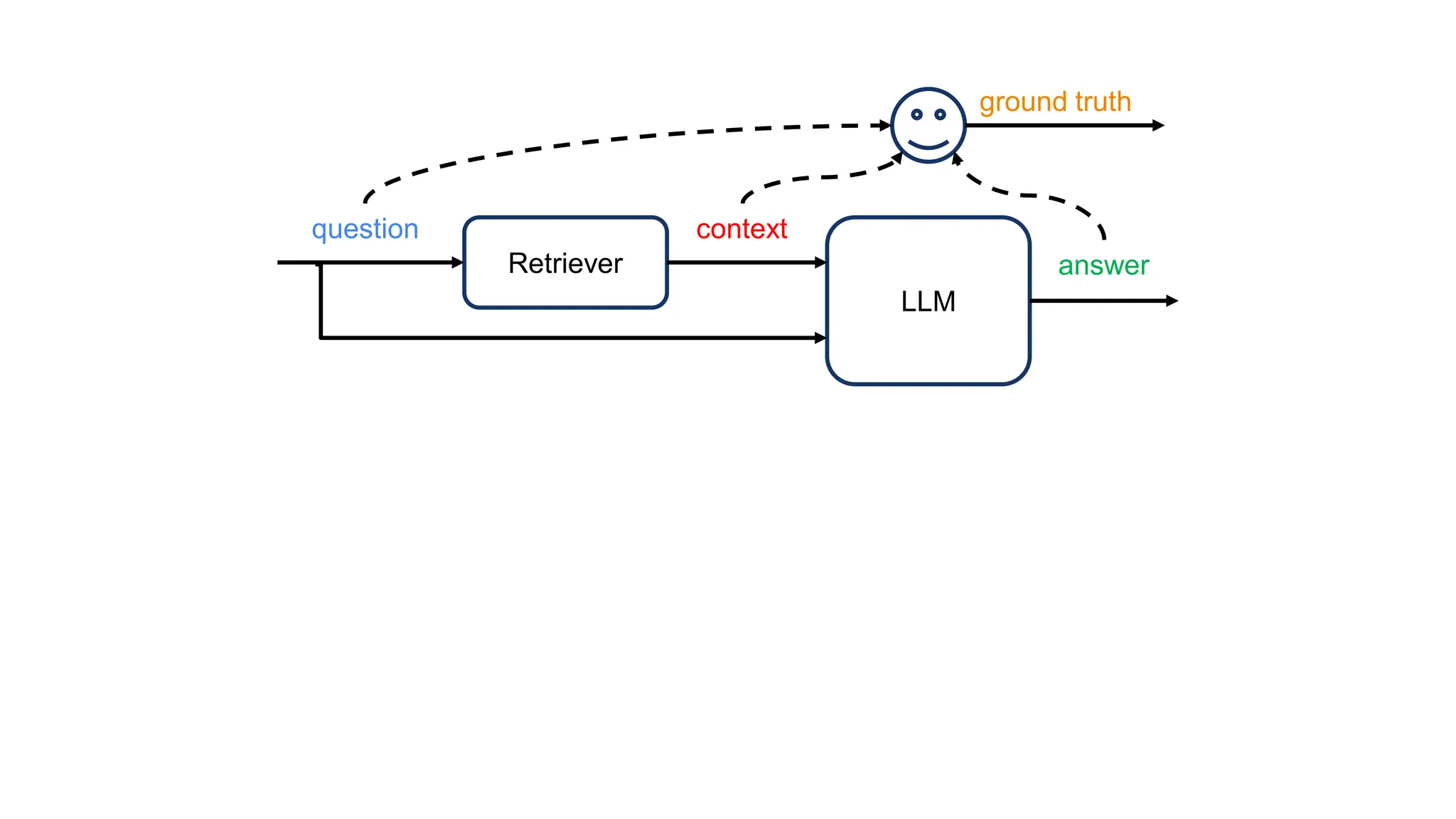
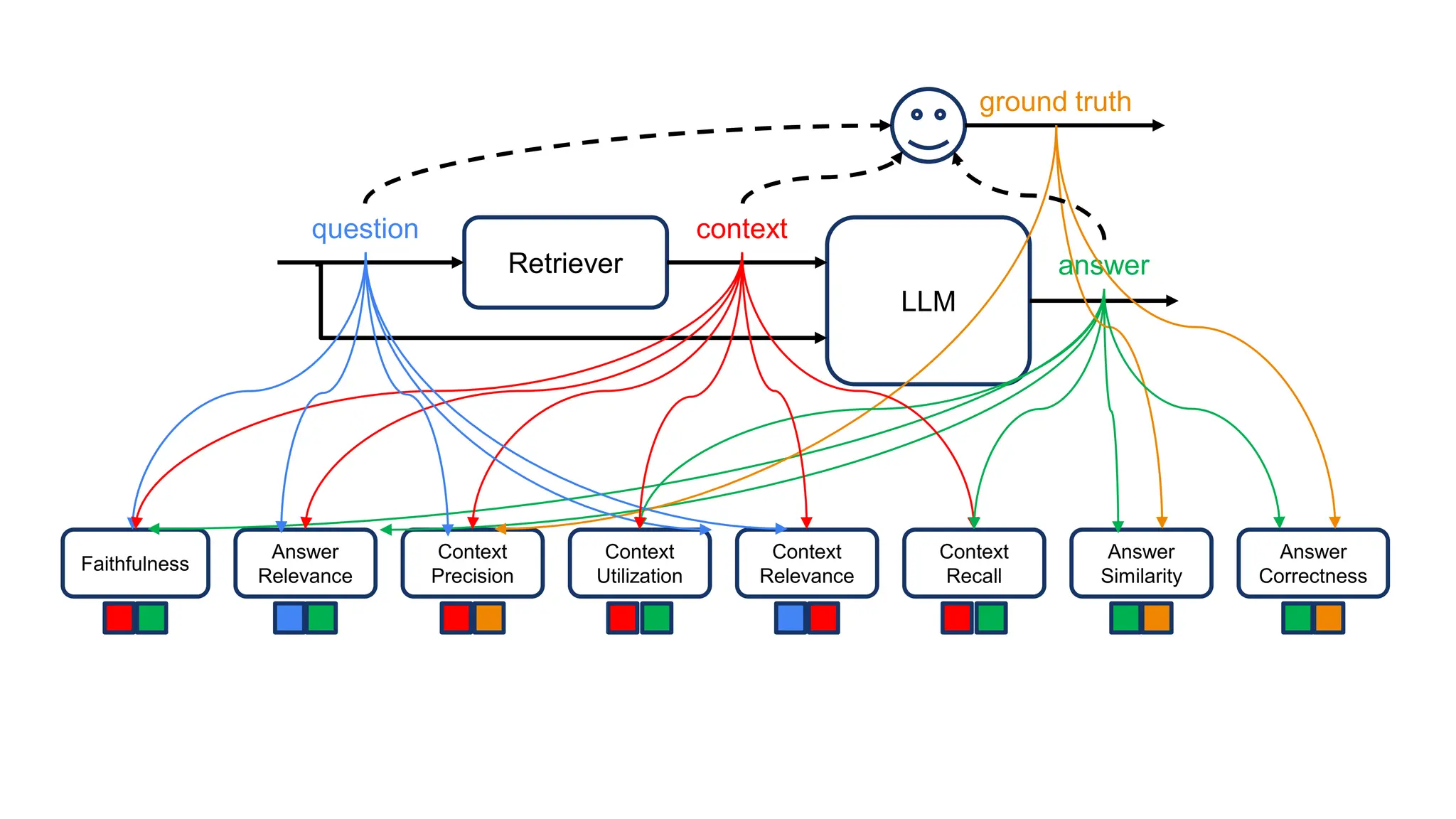
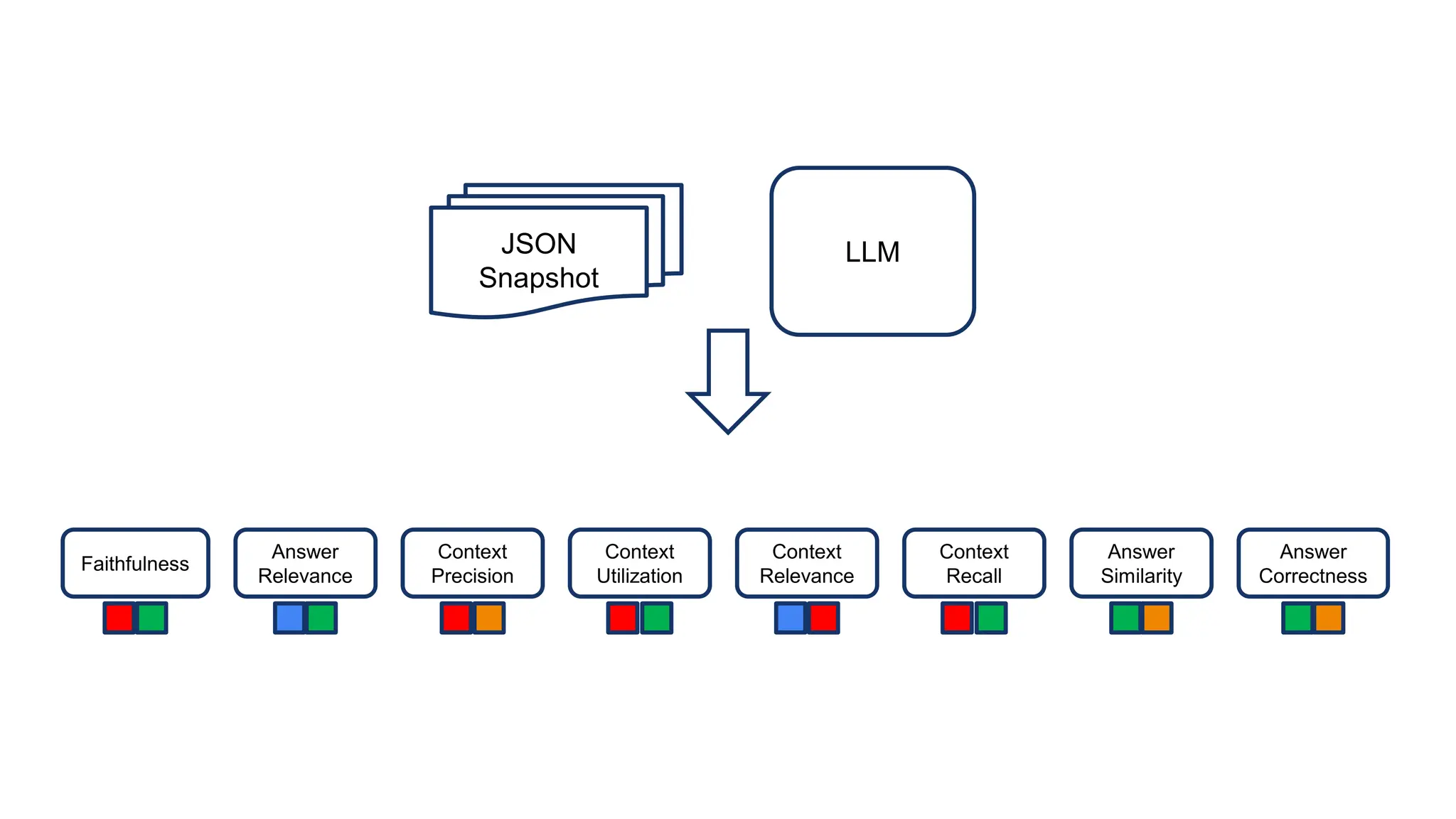
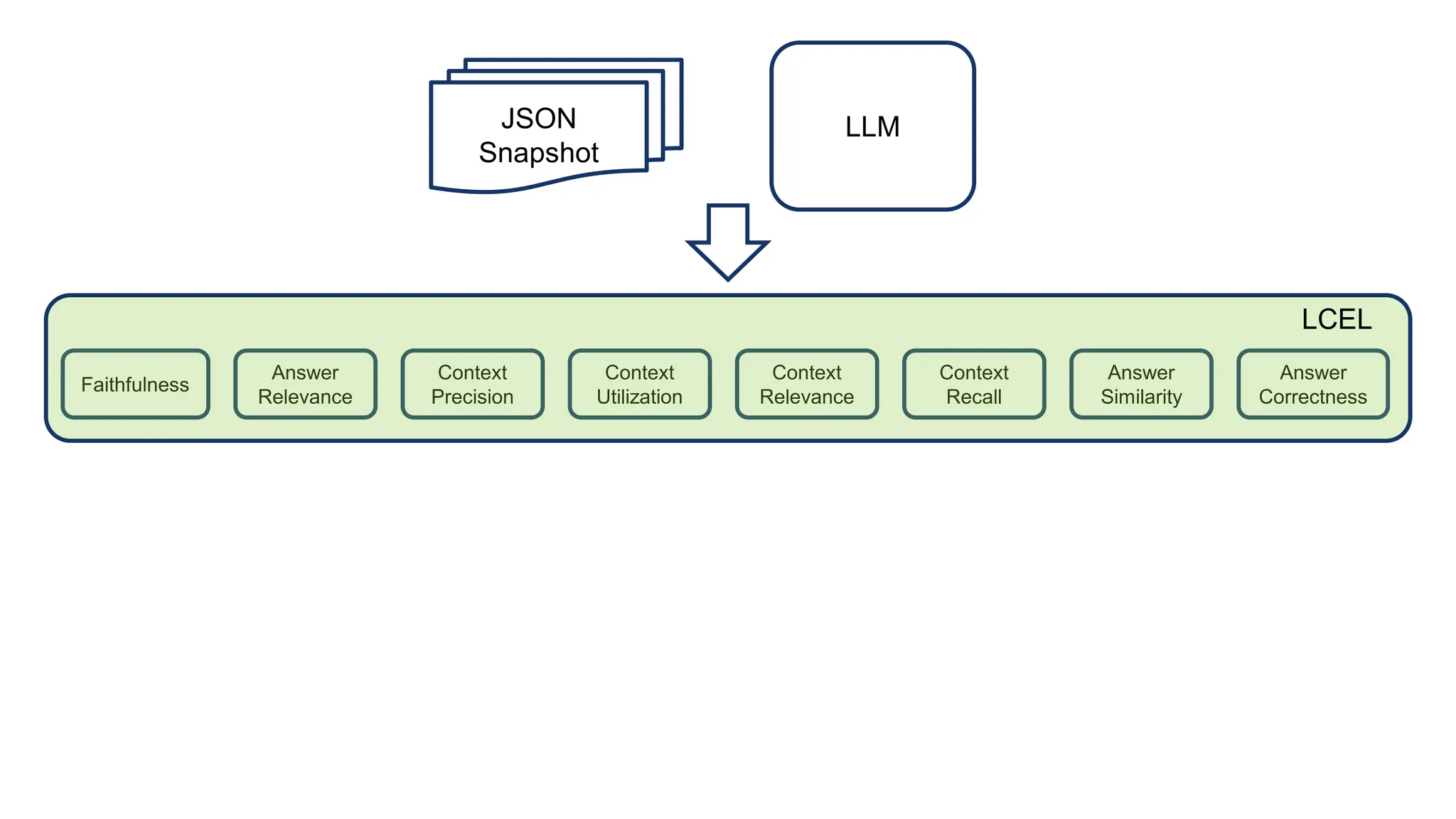
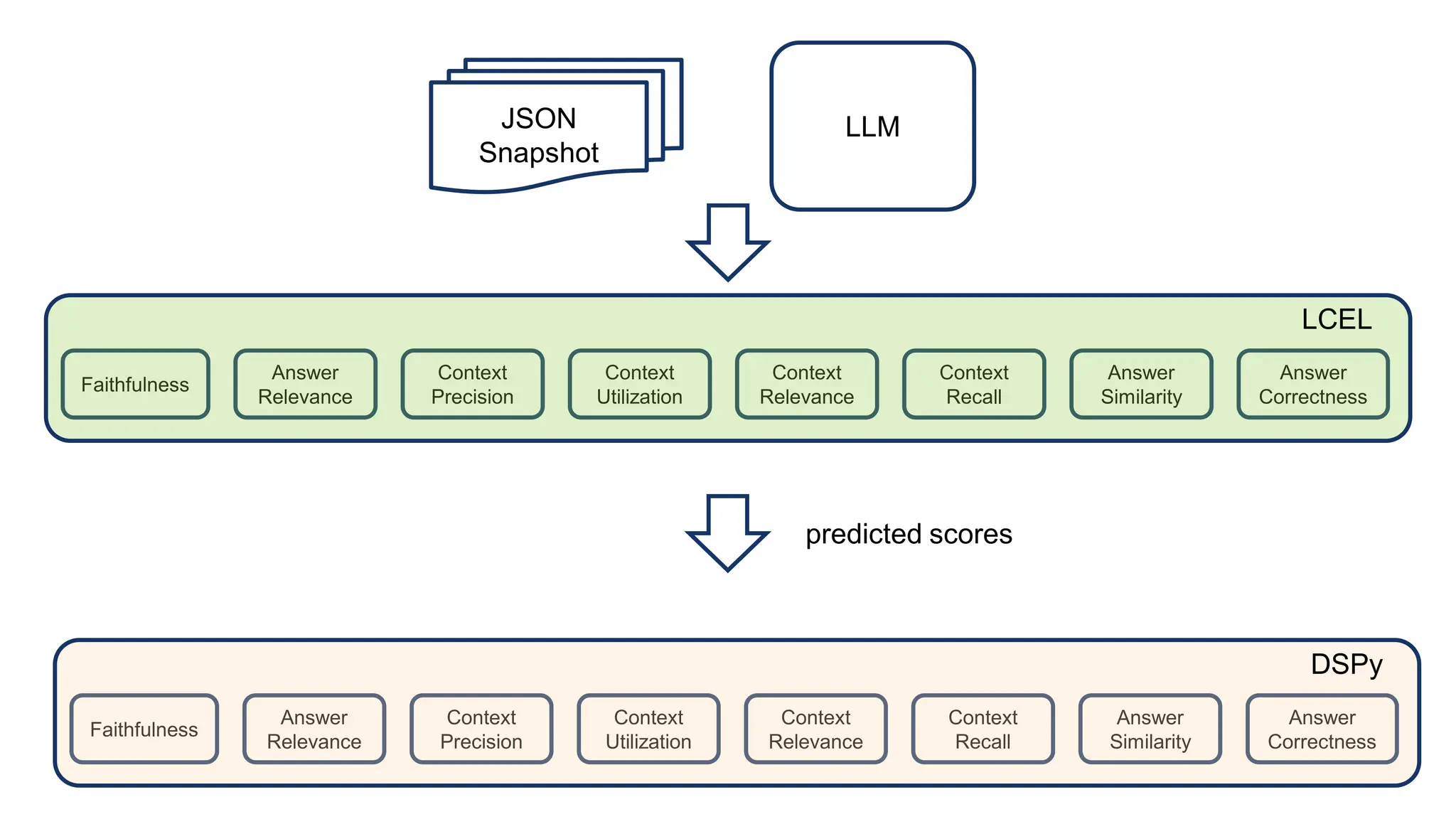
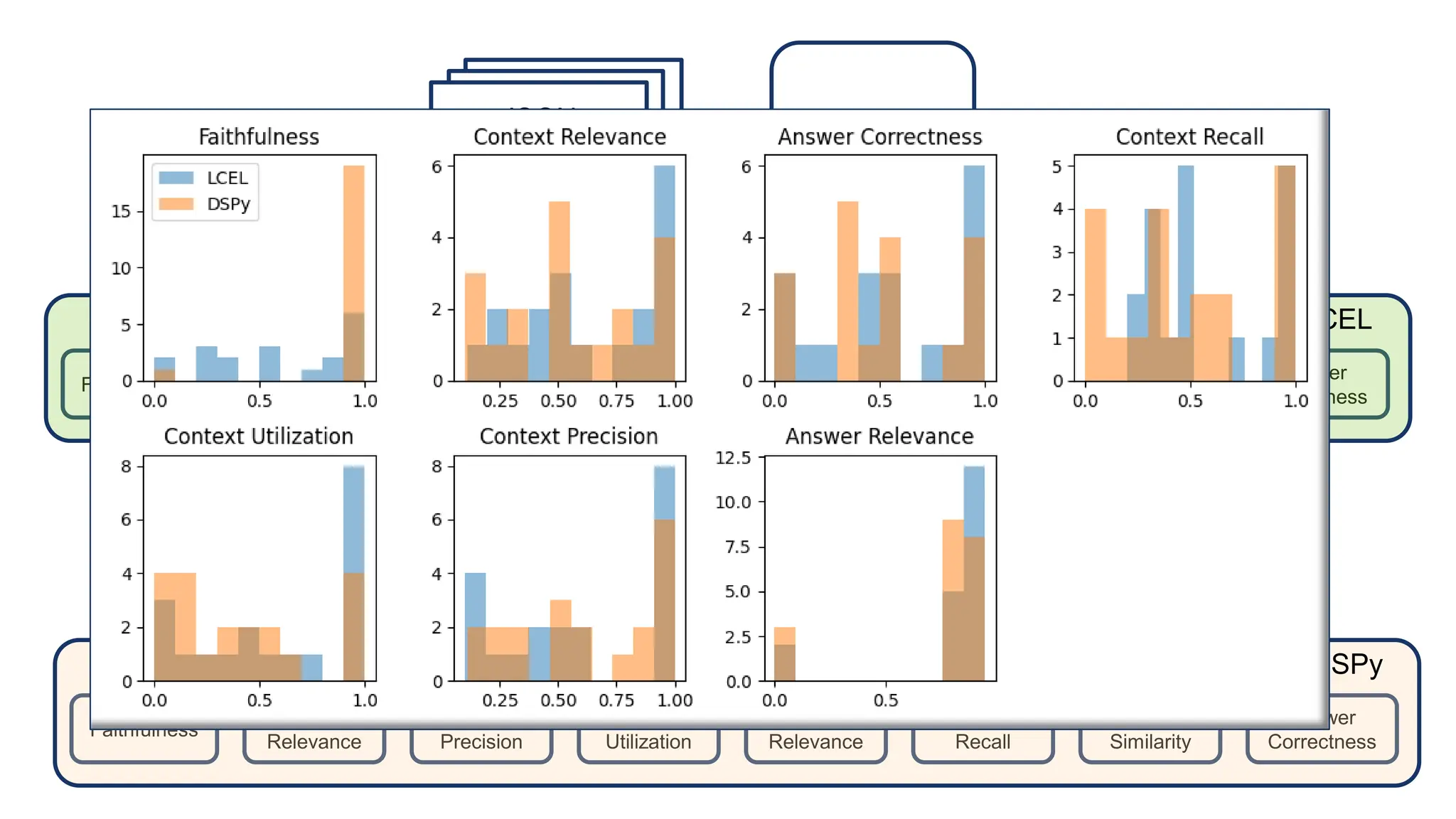
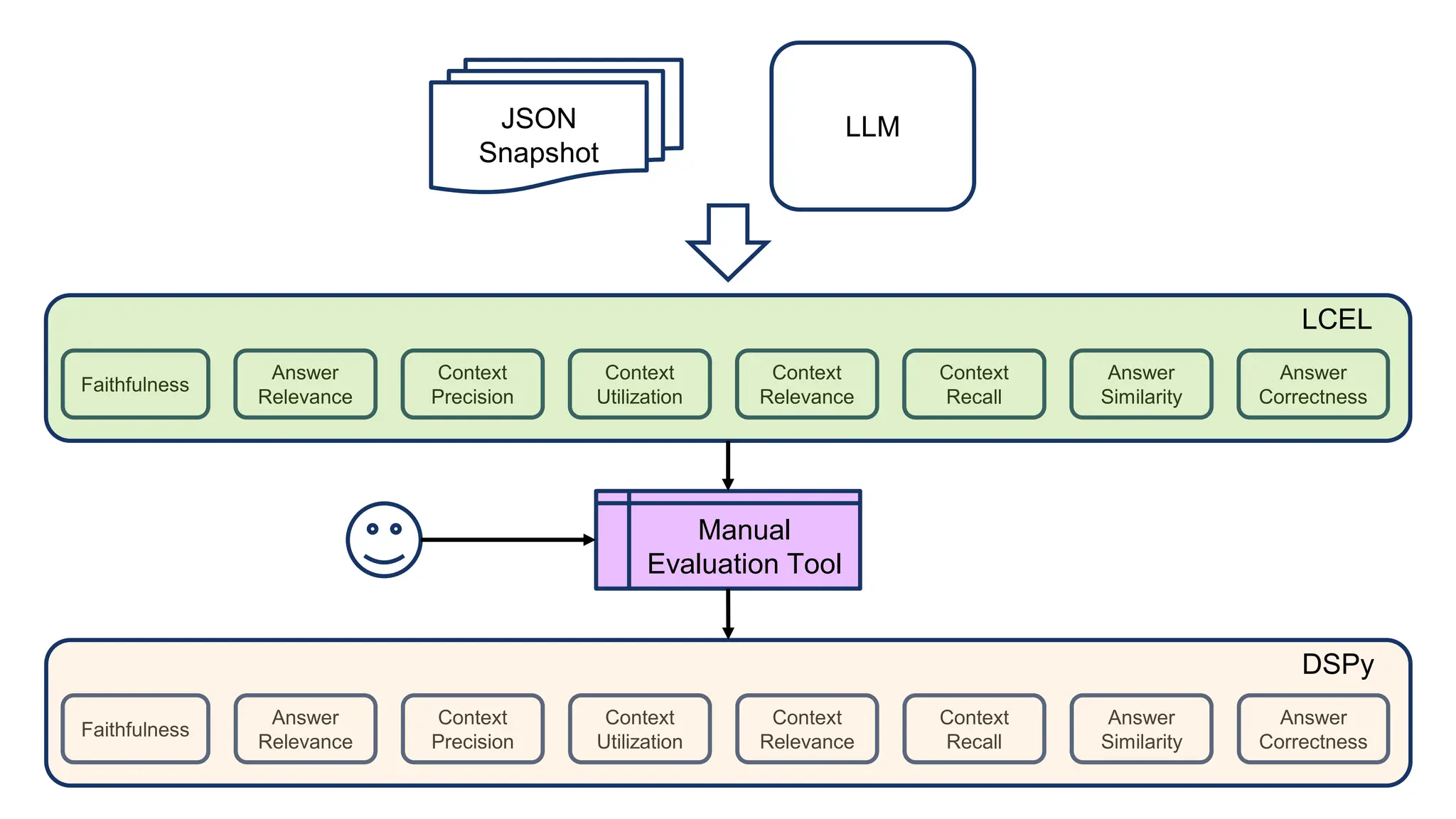
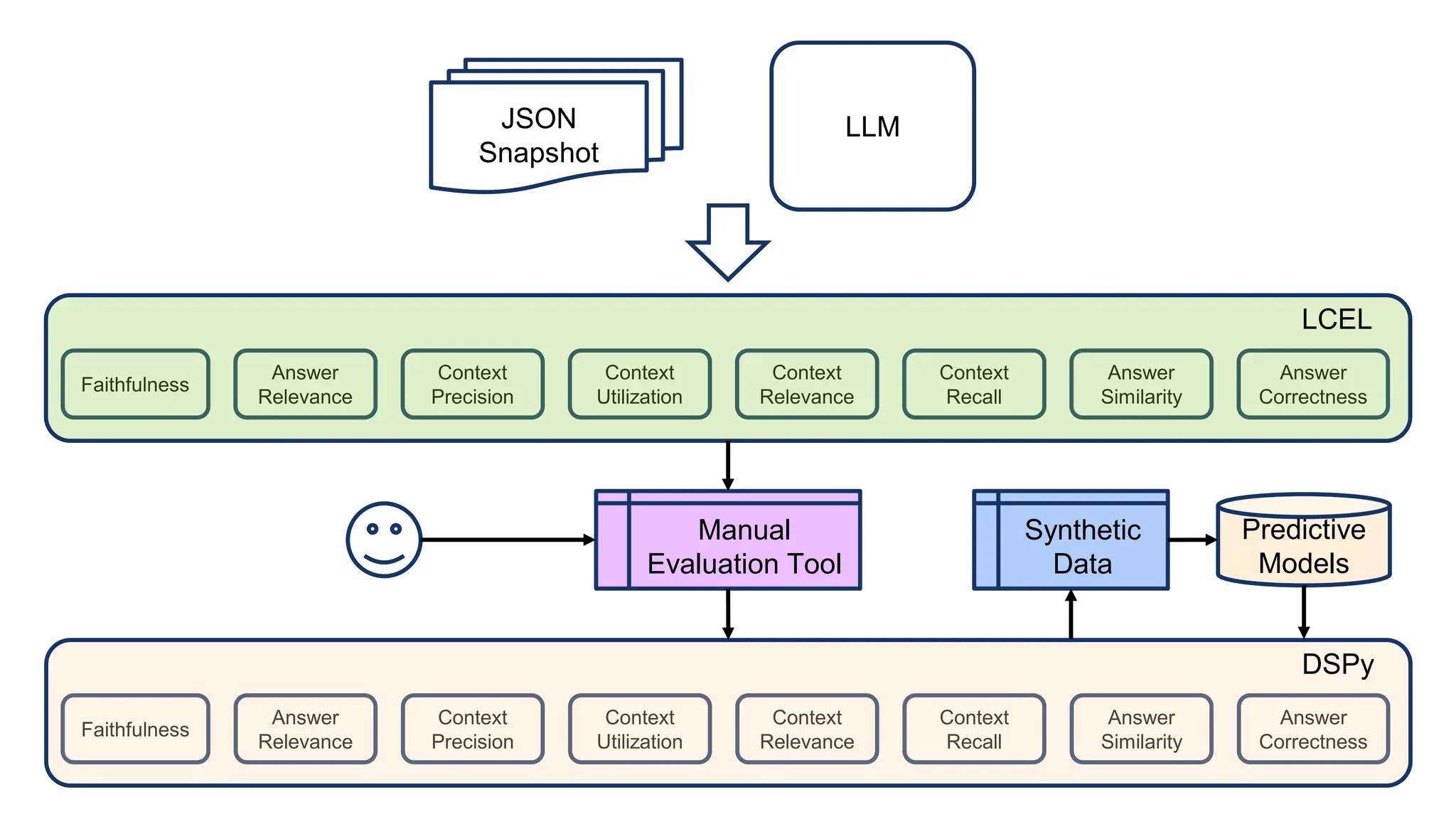


The document discusses an LLM-based evaluator for RAG, detailing metrics such as faithfulness, answer relevance, precision, and recall in the context of validating answers against ground truth. It mentions the use of JSON snapshots for capturing evaluation results and tools for manual evaluation. The author provides a GitHub link for further reference to the evaluation models and tools used.








































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)




