Download as PDF, PPTX



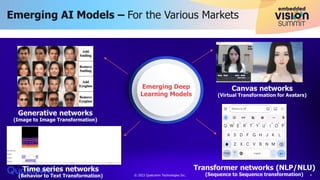

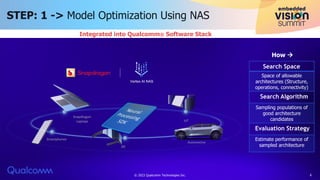





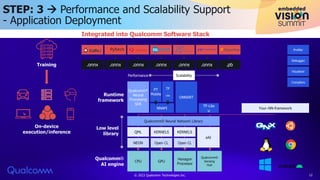
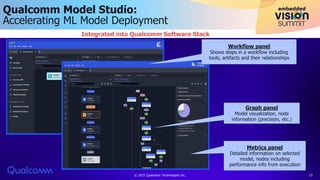






The document discusses Qualcomm's AI stack and its role in accelerating machine learning model deployment across various applications, emphasizing the importance of on-device intelligence, reduced latency, and efficient network use. It outlines emerging AI models, the integration of neural architecture search for model optimization, and advancements in quantization techniques to enhance performance and energy efficiency. The conclusion notes the expanding range of AI applications and Qualcomm's commitment to supporting new deep learning architectures and innovation.

![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)





















































































