Download as PDF, PPTX




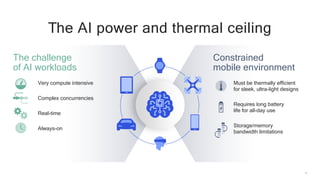

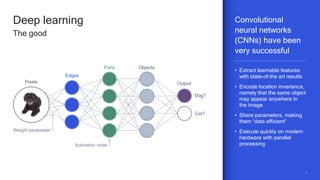
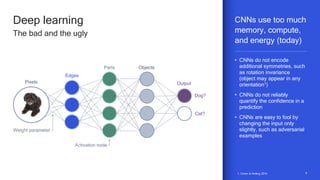
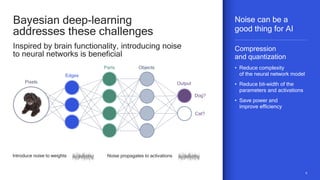
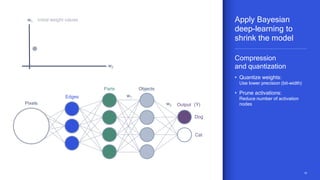
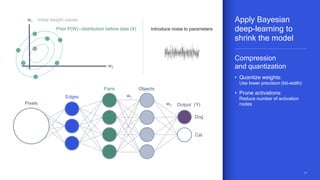
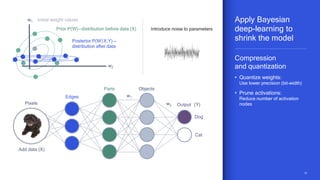
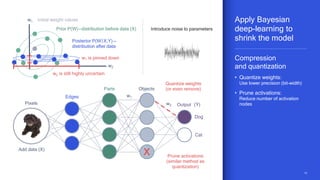
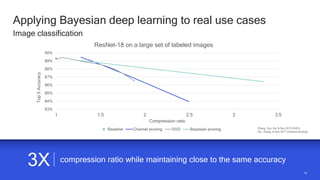
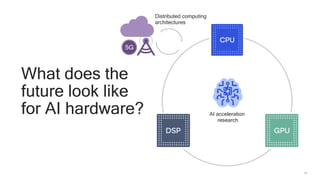
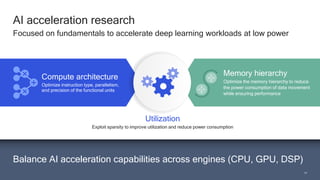
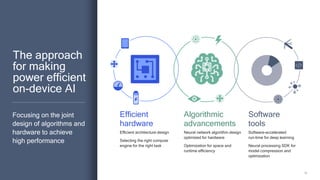



The document discusses the increasing energy consumption of AI and deep learning technologies, highlighting the need for energy-efficient solutions in on-device AI. It emphasizes the significance of Bayesian deep learning for model compression and quantization, which can improve efficiency while maintaining performance. Lastly, it outlines Qualcomm's focus on advancing algorithms and hardware design to optimize power efficiency in AI applications.






































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)















