Download as PDF, PPTX






![Taking it further
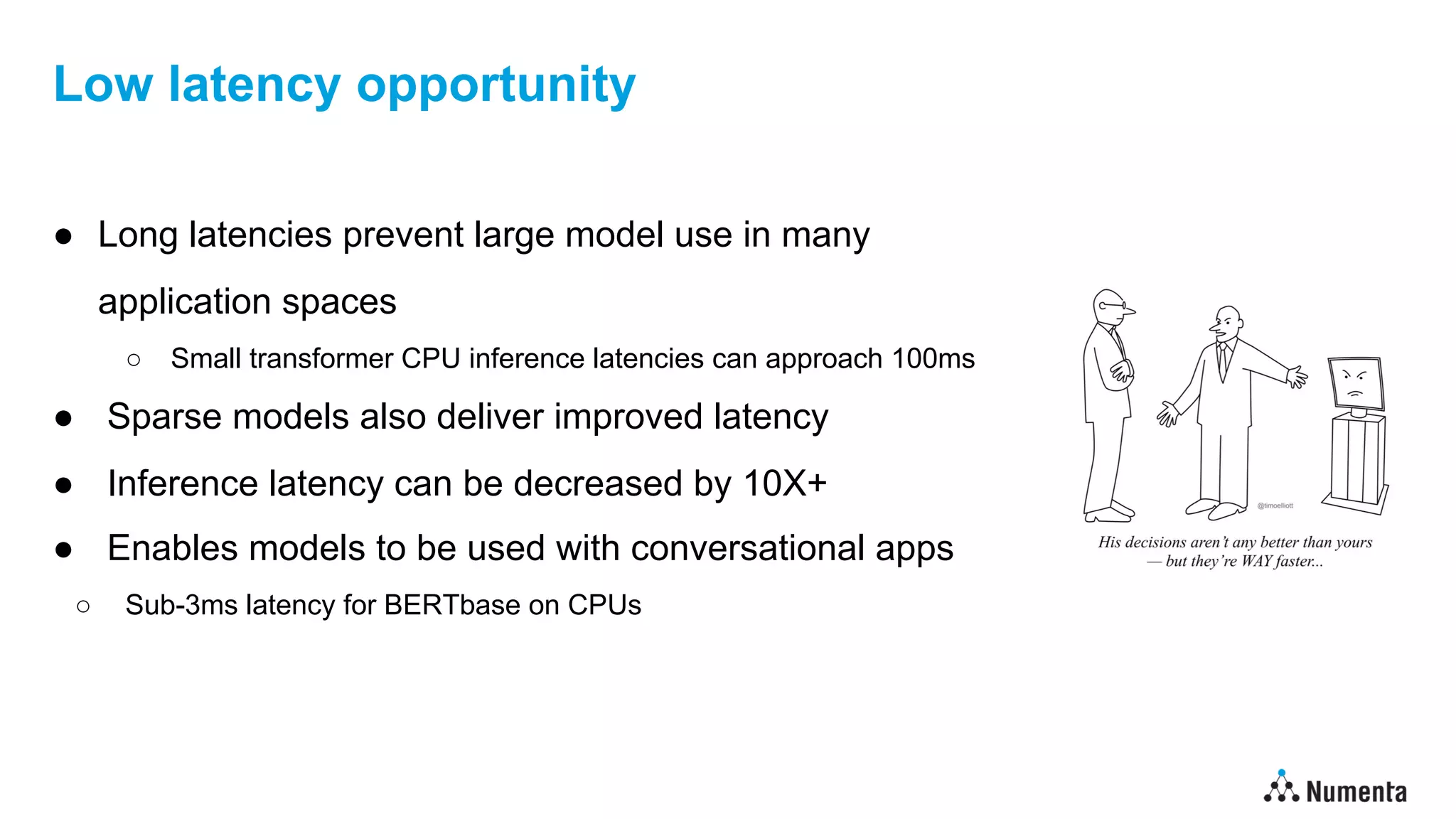
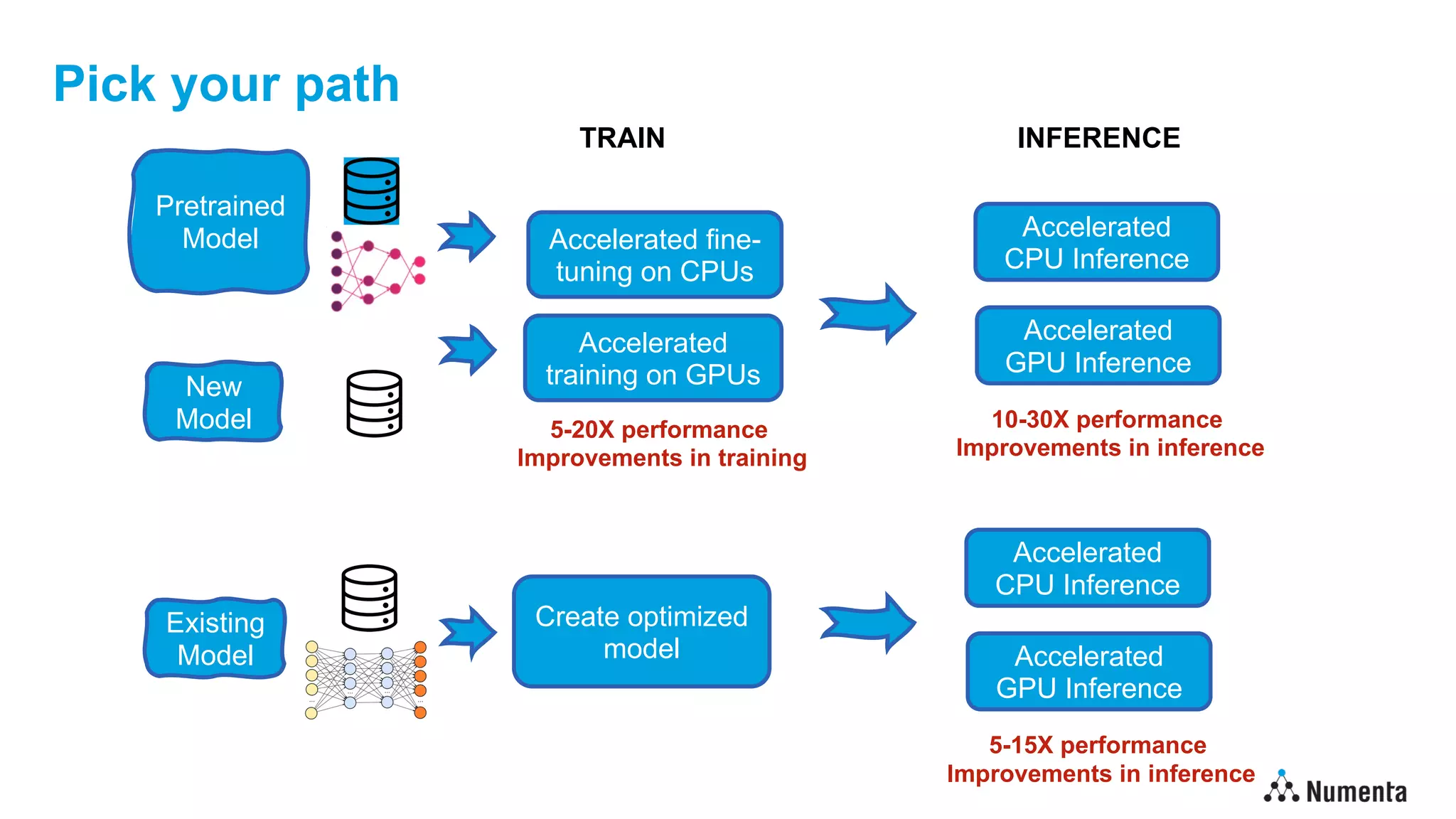
• Sparsity represents just the start of what’s possible
• Quantization
• Leverage reduced fidelity representations
• Further reduces memory footprint
• Translates into improved performance on most hardware [2.5X+]
• Knowledge distillation
• Reduce number/size of layers & use large teacher during training to maximize accuracy
• Fewer layers directly reduces inference costs [5X+]
• Benefits are multiplicative…
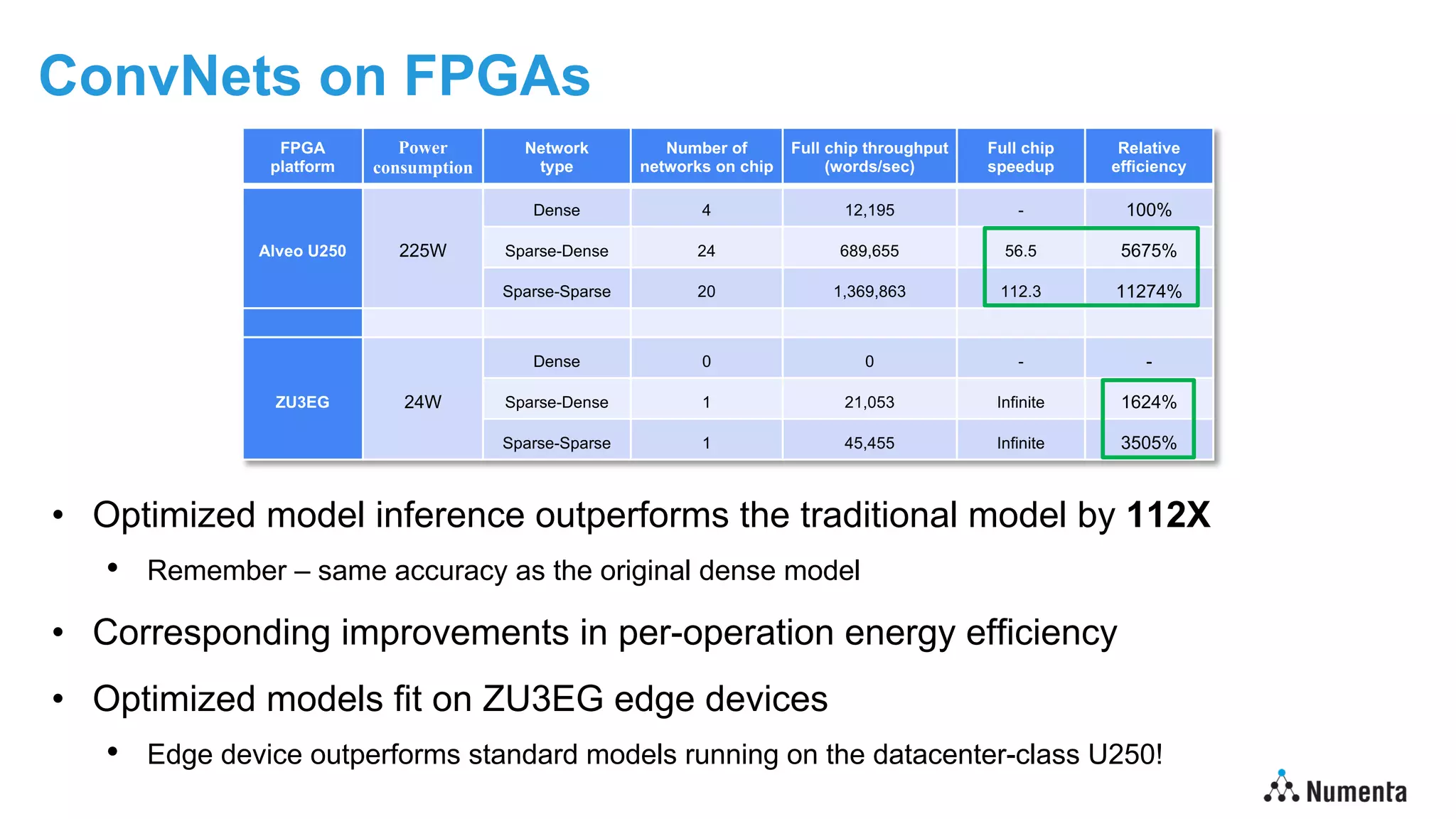
Deep learning models can run 100X faster on existing edge devices](https://image.slidesharecdn.com/edgeaisummit2022-lawrencespracklenv2-220919182003-bb3b0de4/75/Deep-learning-at-the-edge-100x-Inference-improvement-on-edge-devices-13-2048.jpg)


Deep learning models have grown exponentially in size, making them impractical for deployment on edge devices with limited resources. However, new research shows it is possible to achieve 100x faster inference on edge devices by leveraging sparse models inspired by the human brain. Sparse models activate only a small subset of connections between neurons, enabling significant computational savings without loss of accuracy. When precisely controlled to match hardware capabilities, sparse models can achieve speedups directly proportional to their reduction in parameters. This allows state-of-the-art deep learning models to run efficiently on edge devices, unlocking new applications in areas like computer vision, language processing, and health monitoring.



































































