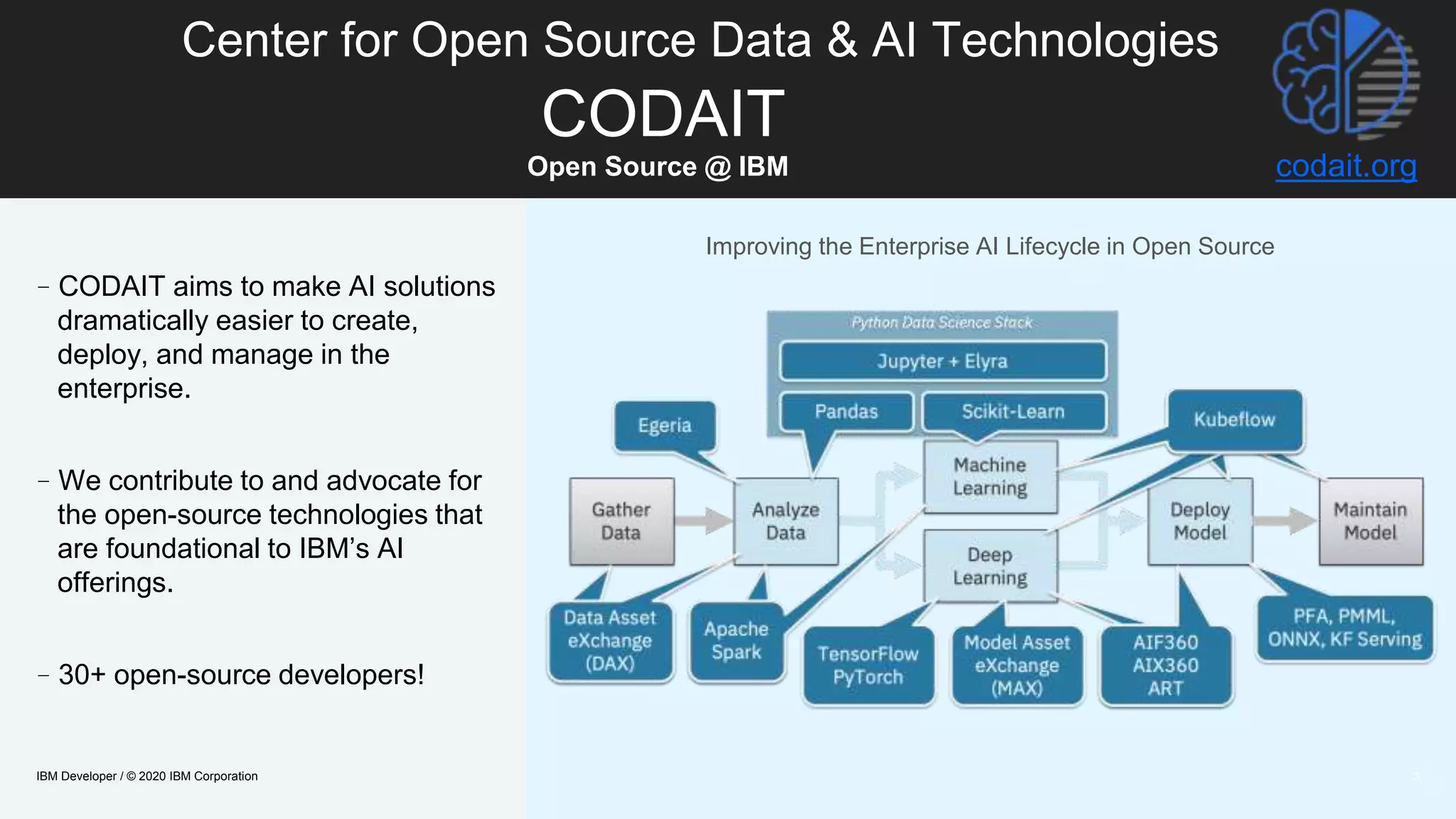
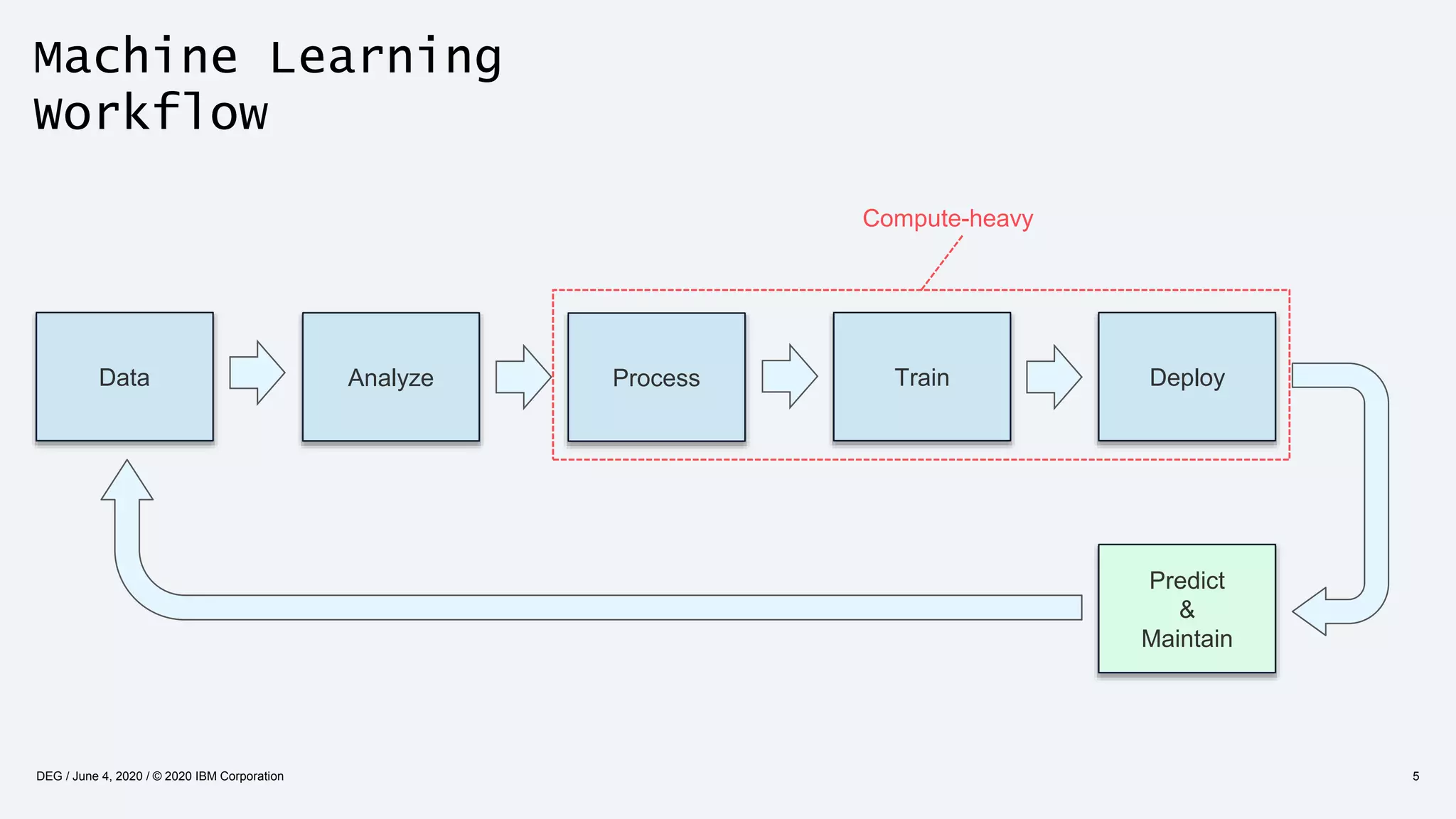
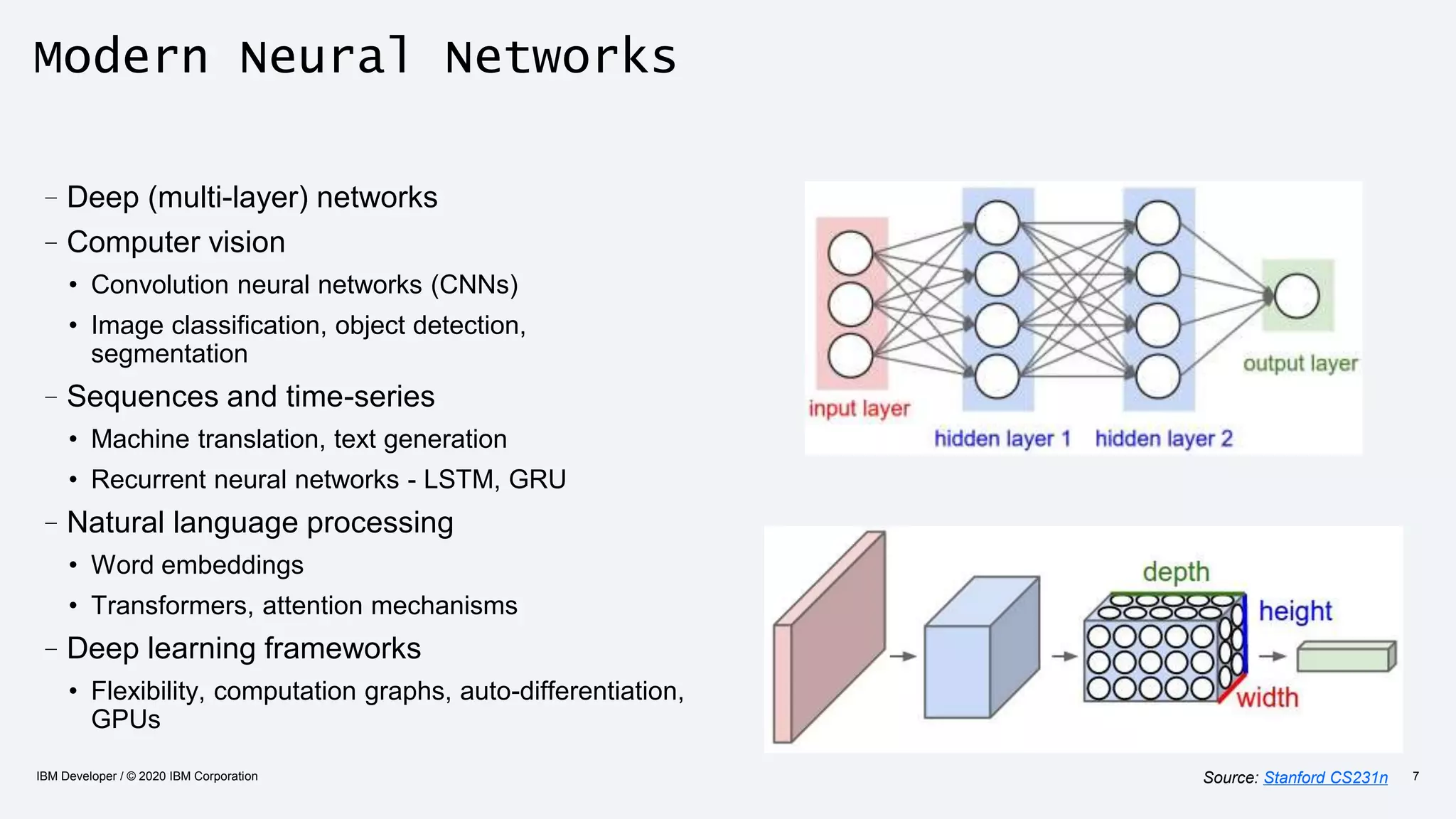
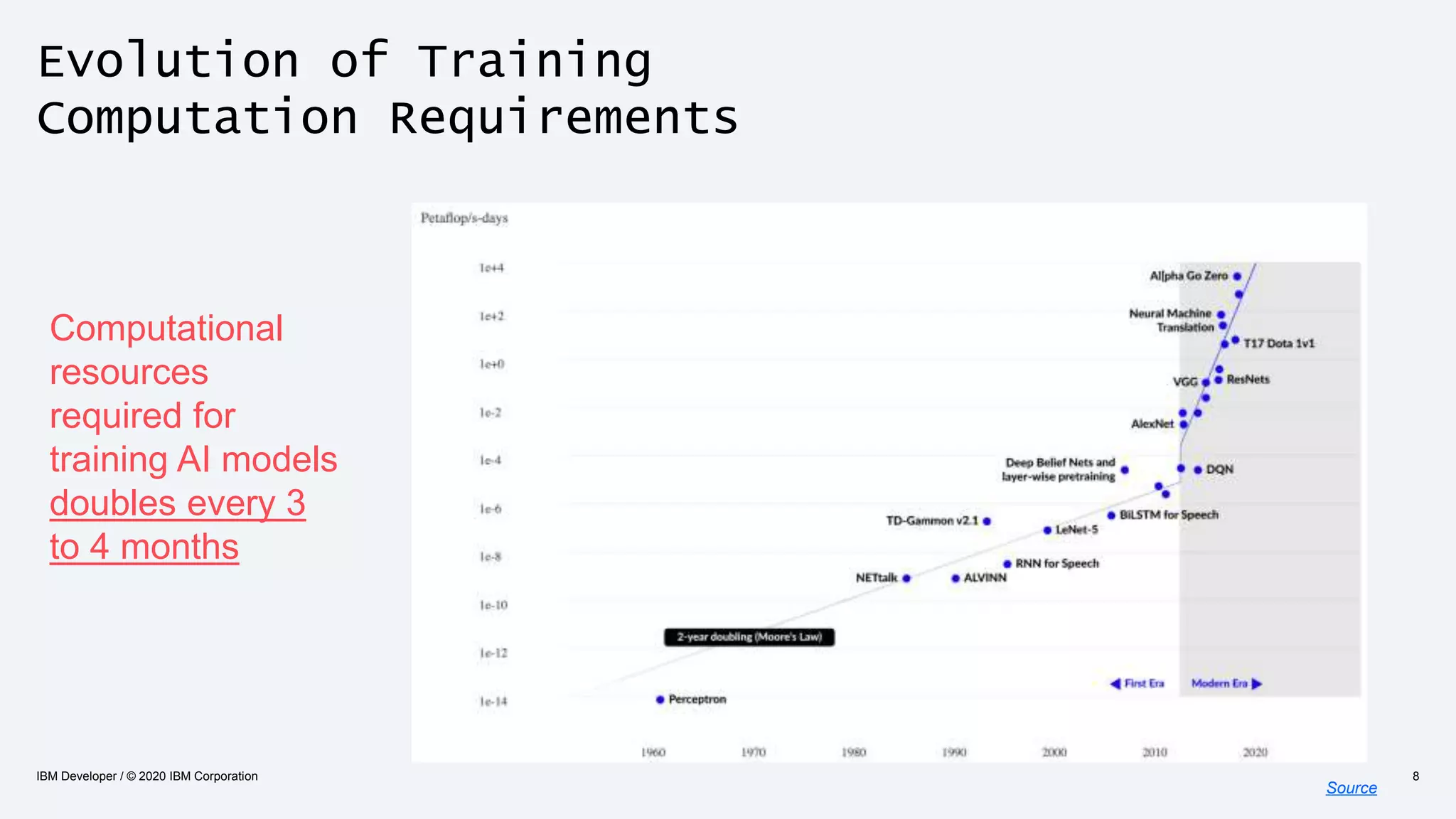
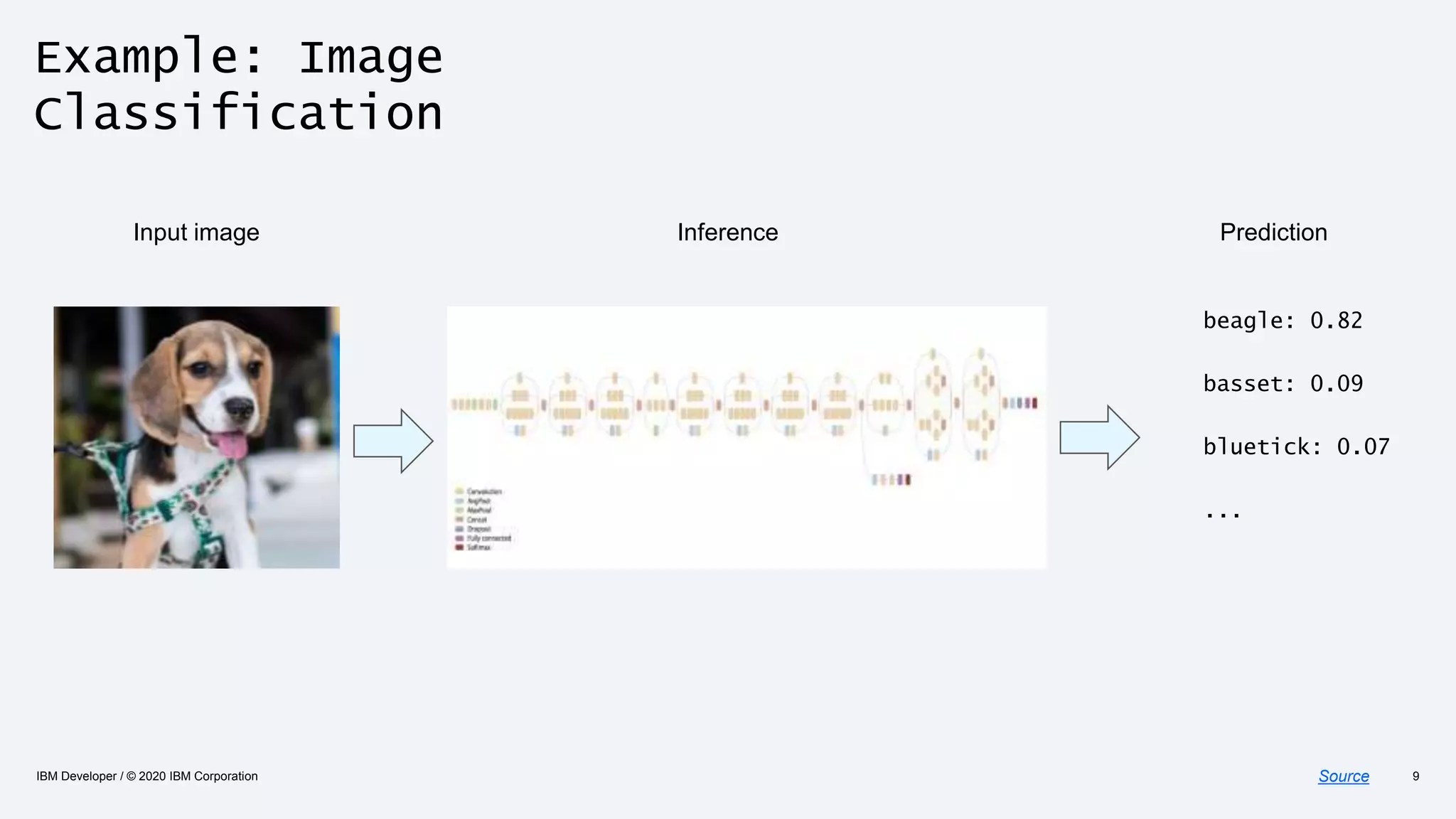
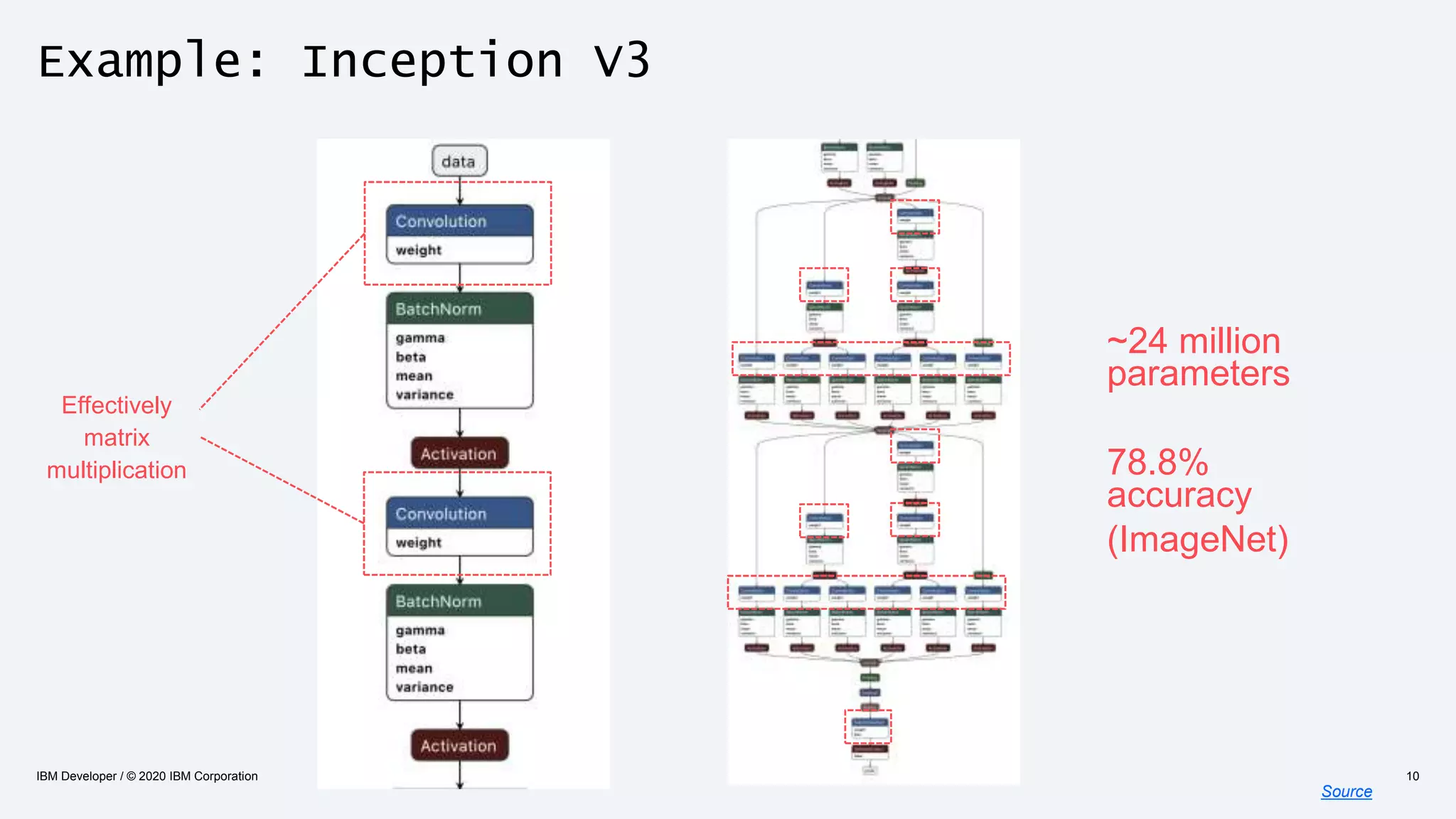
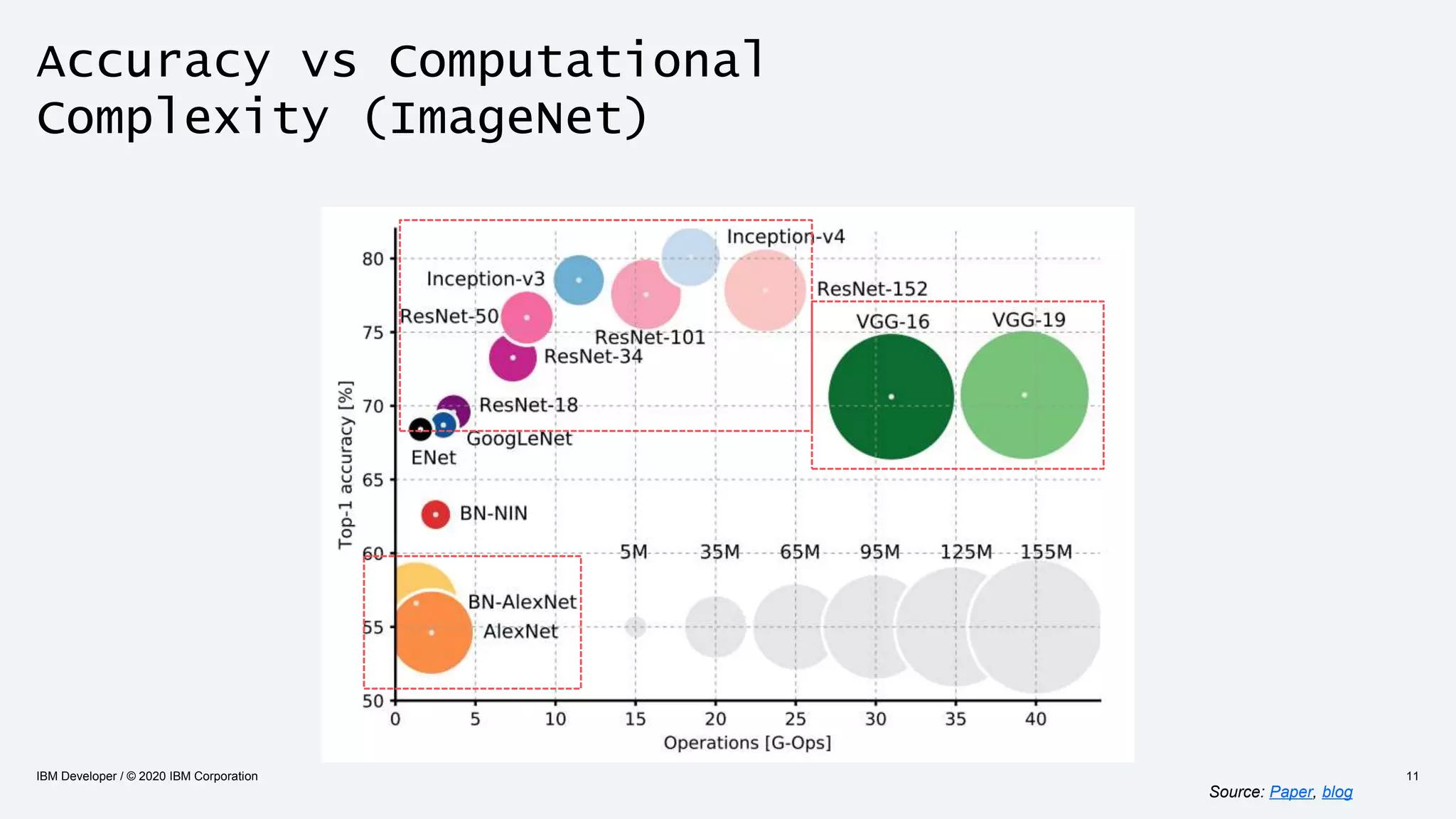
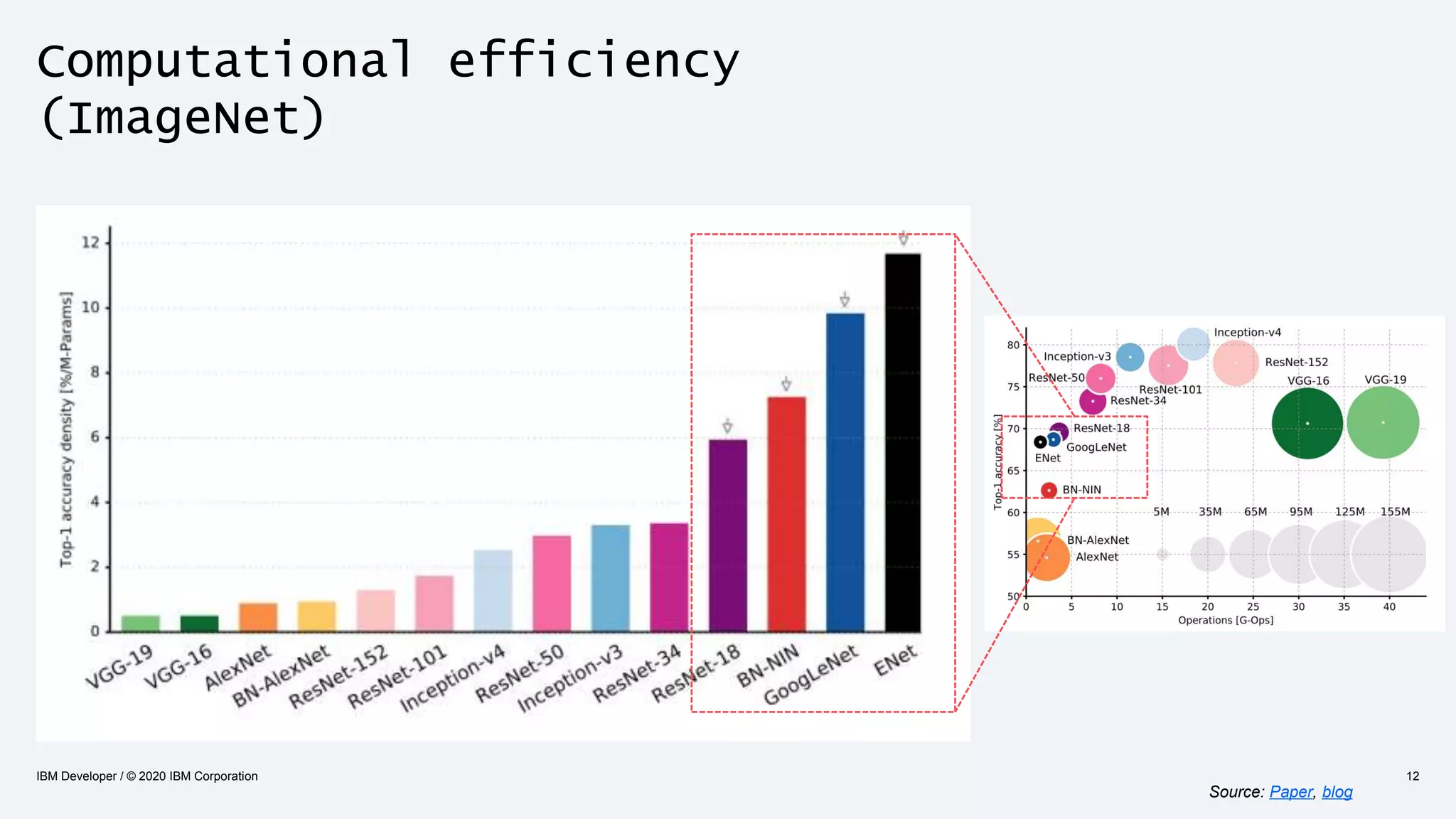
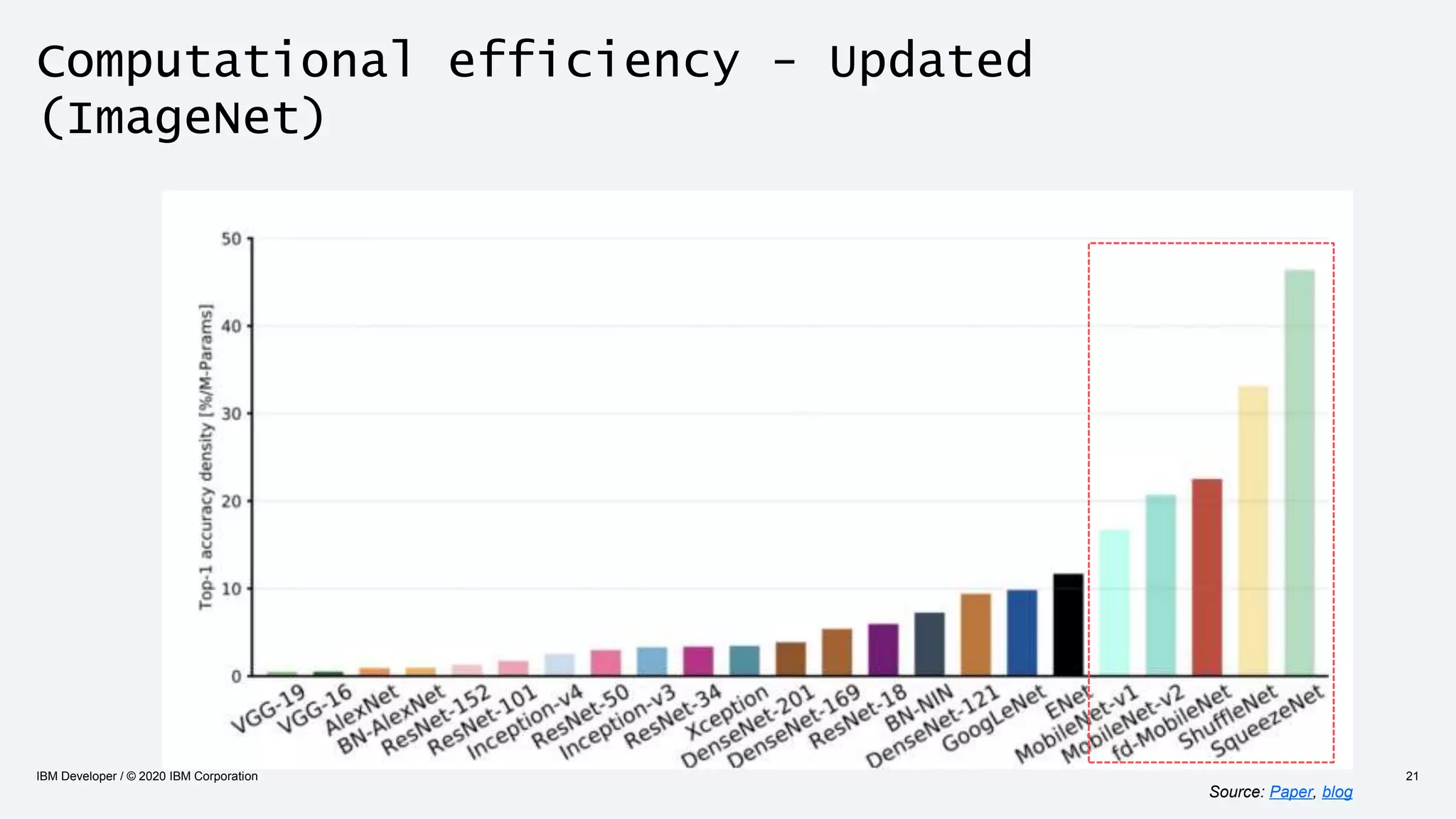
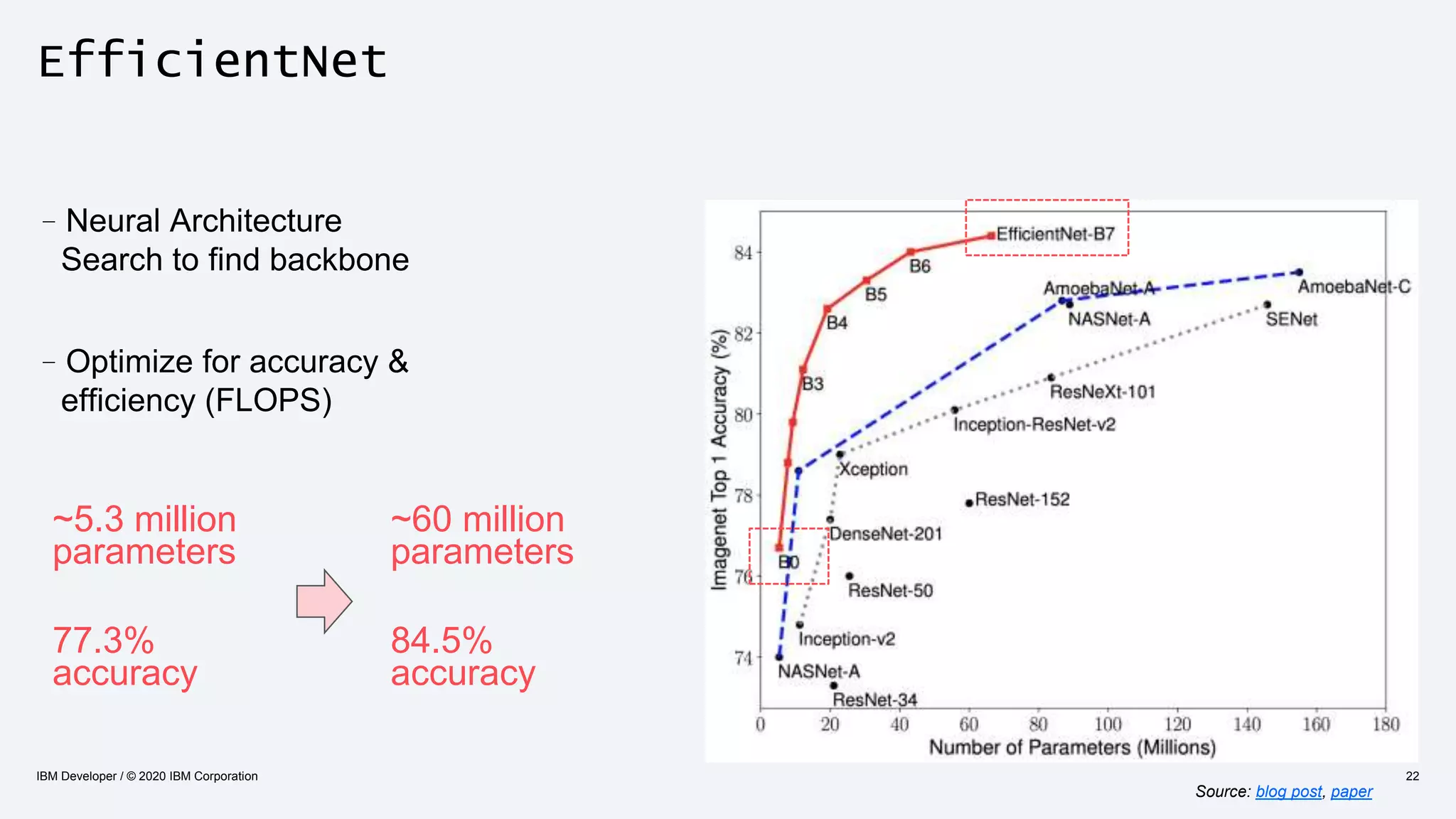
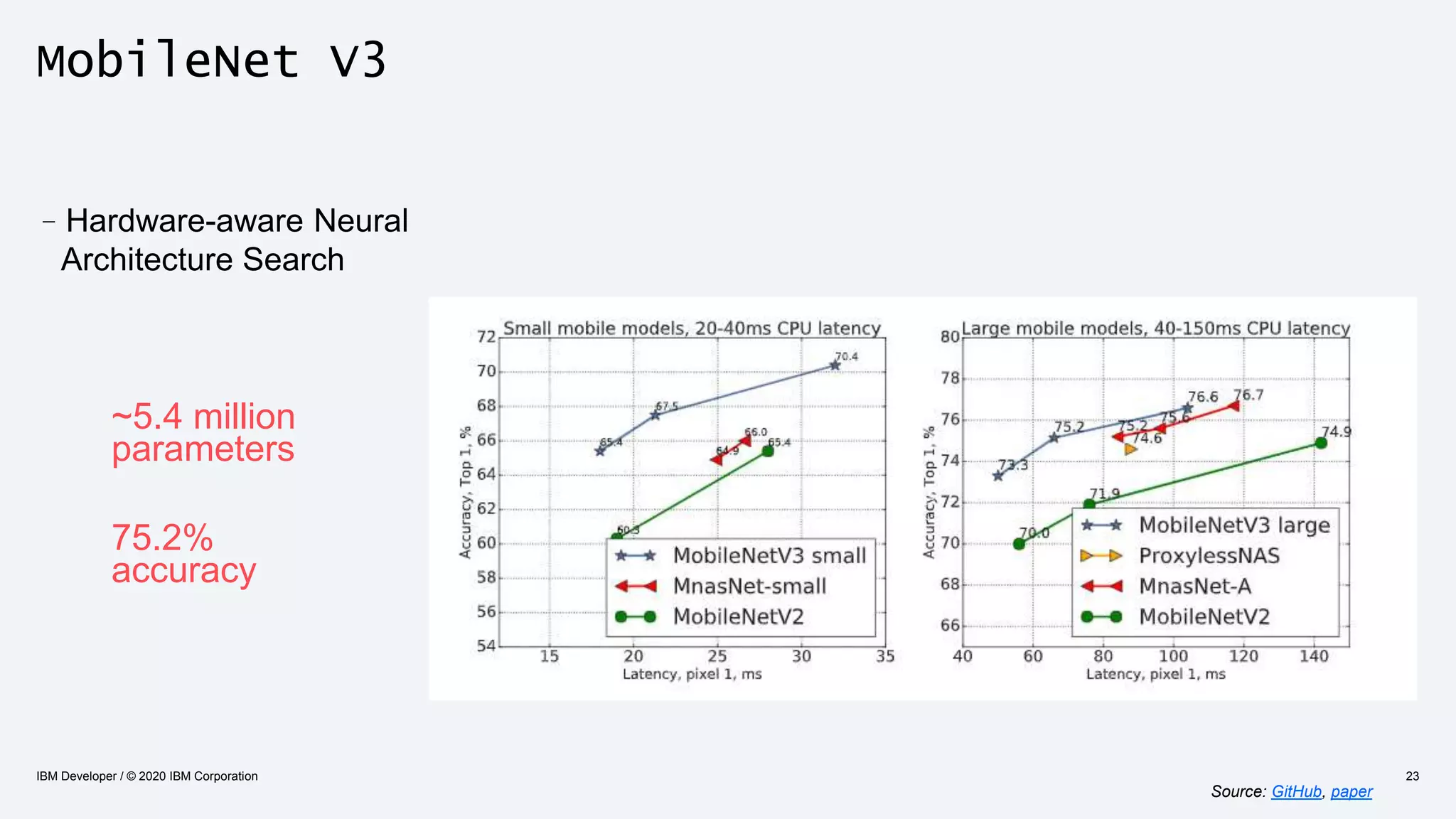
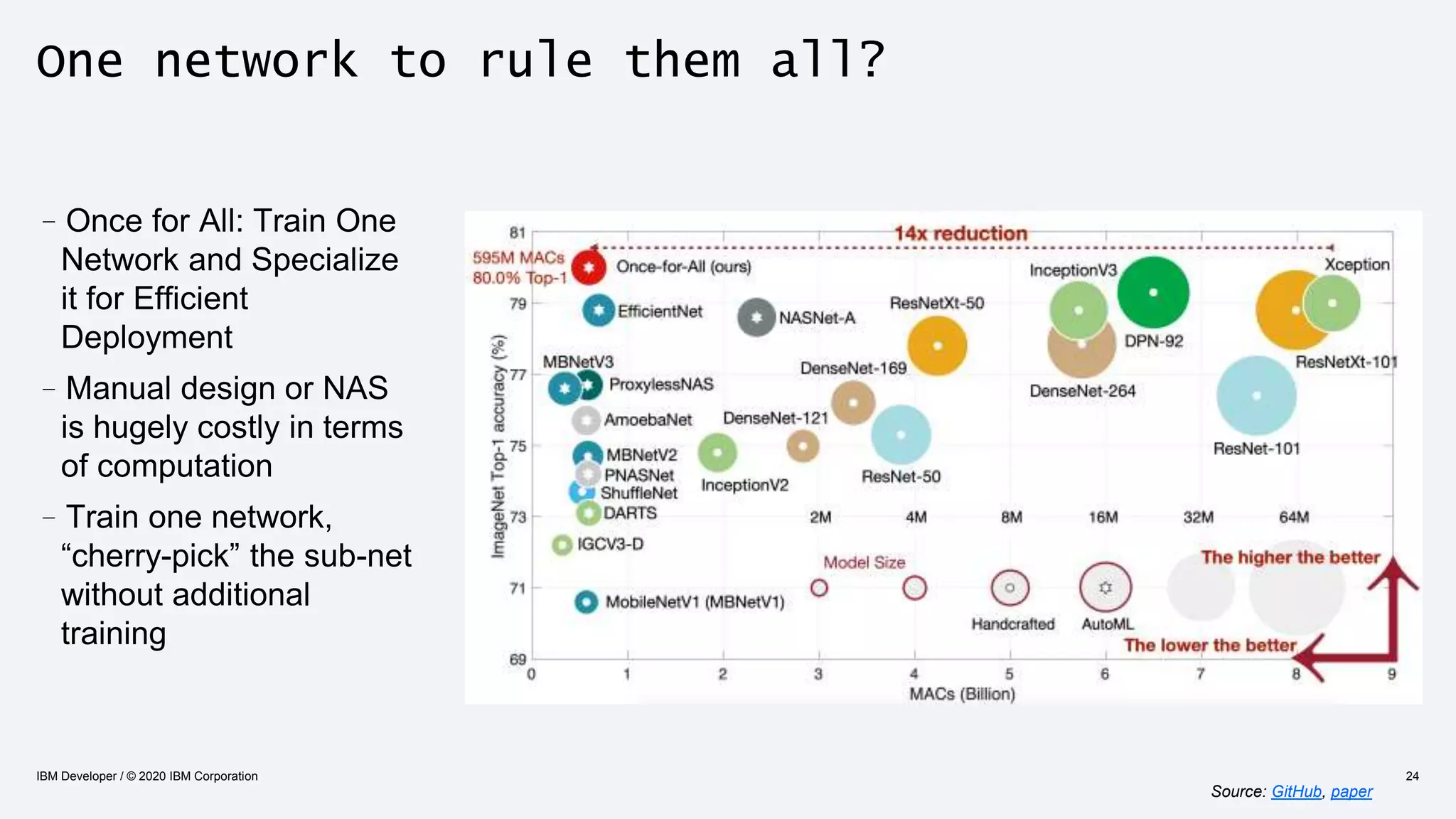
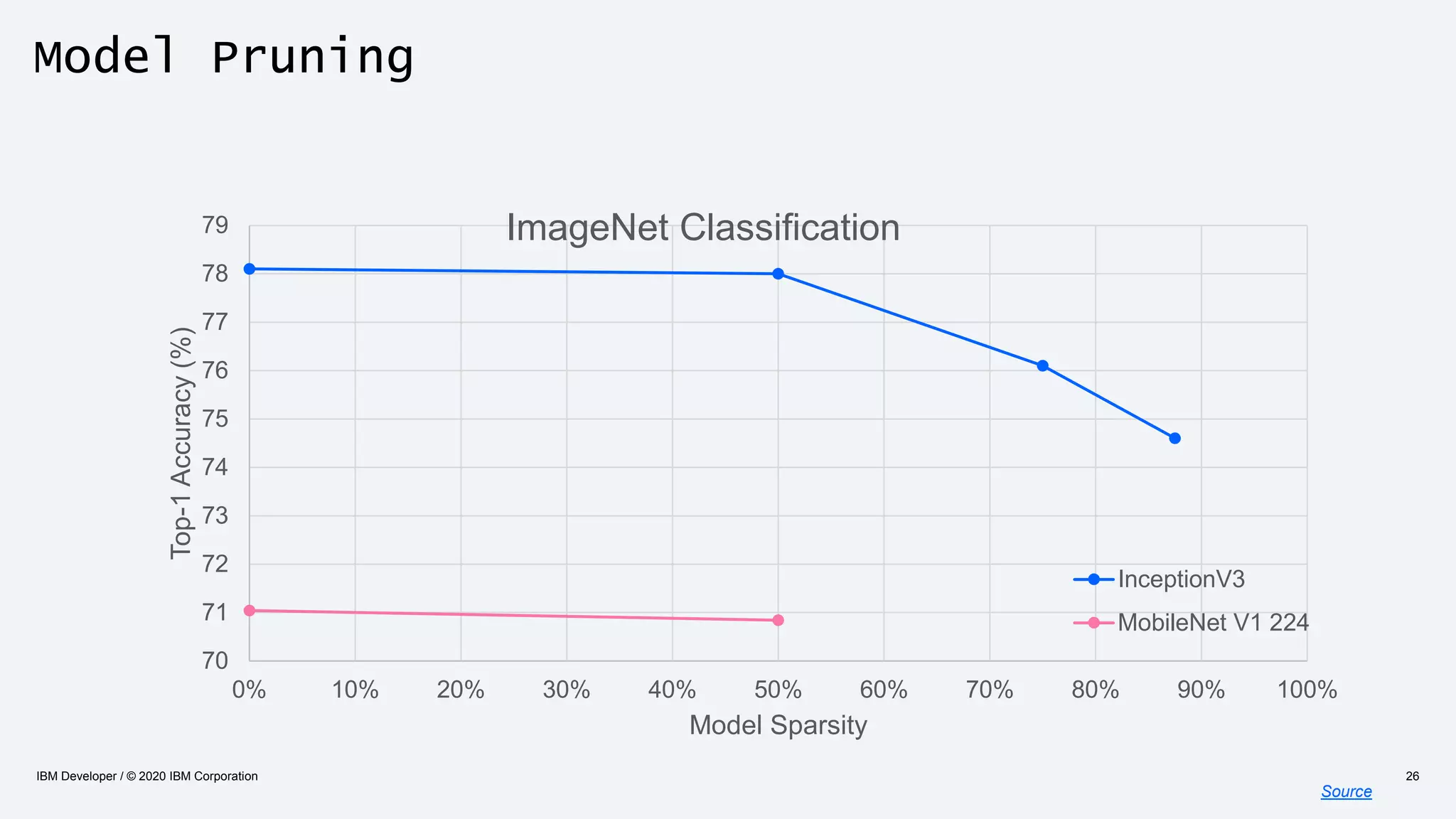
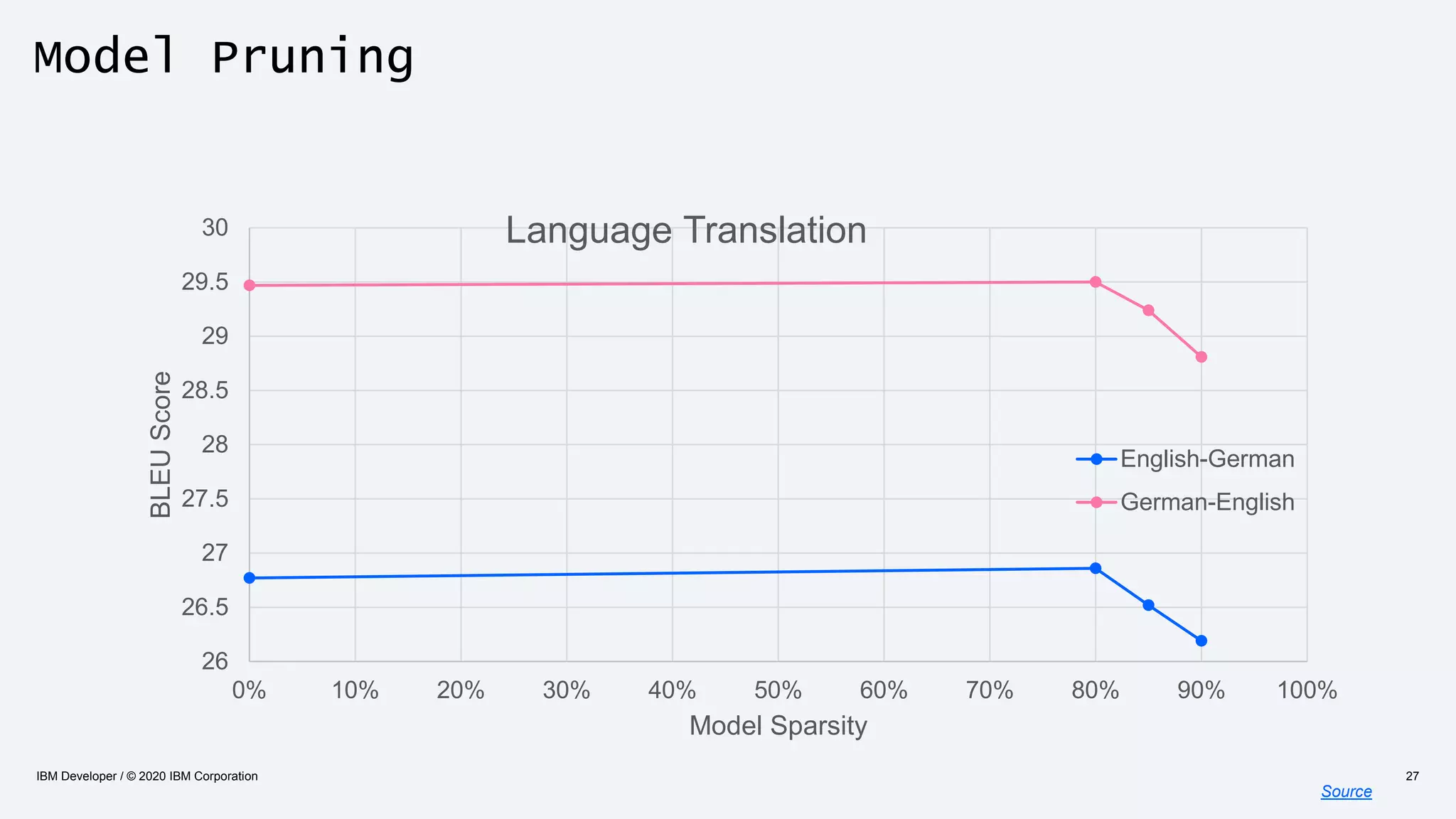
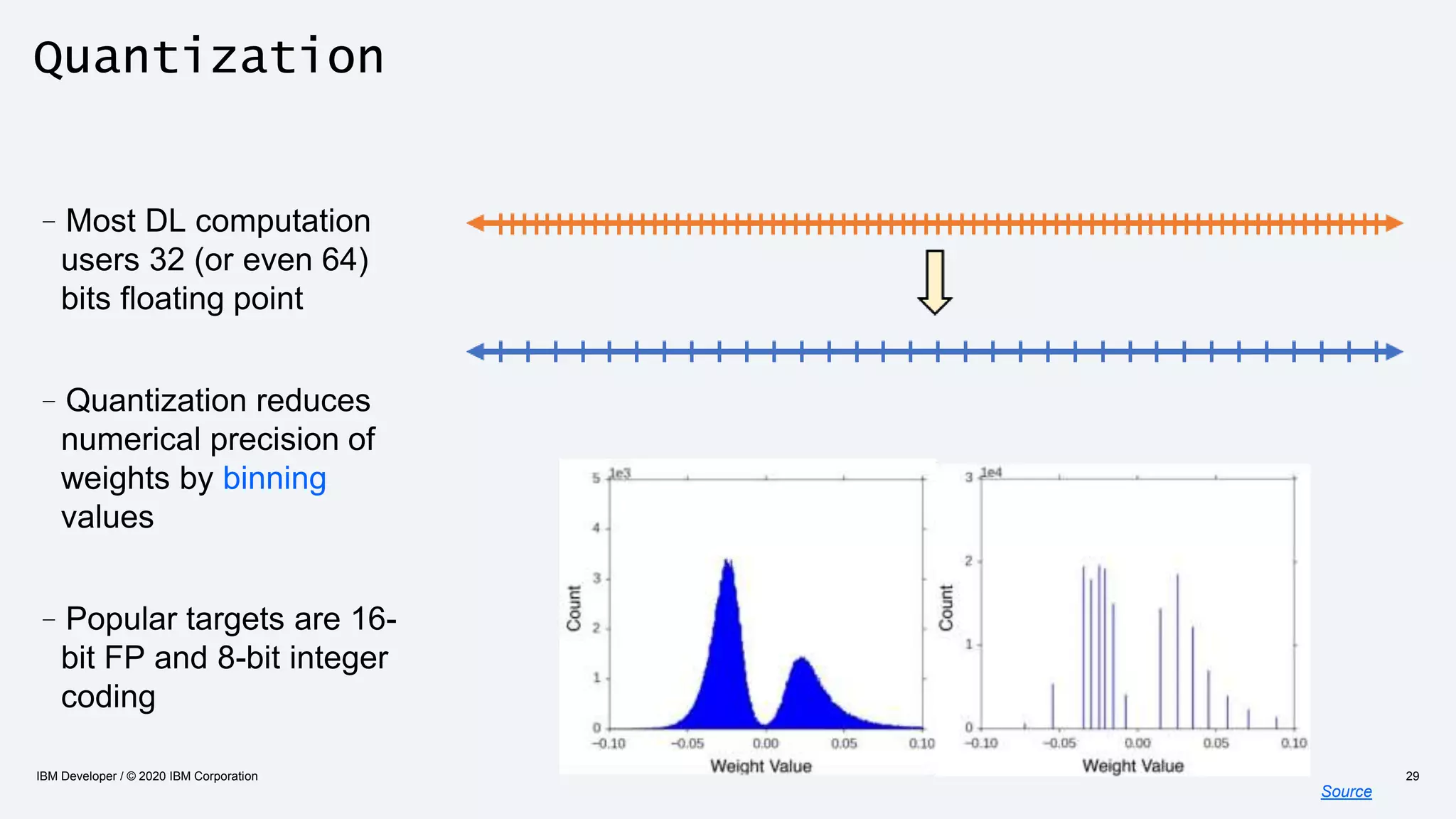
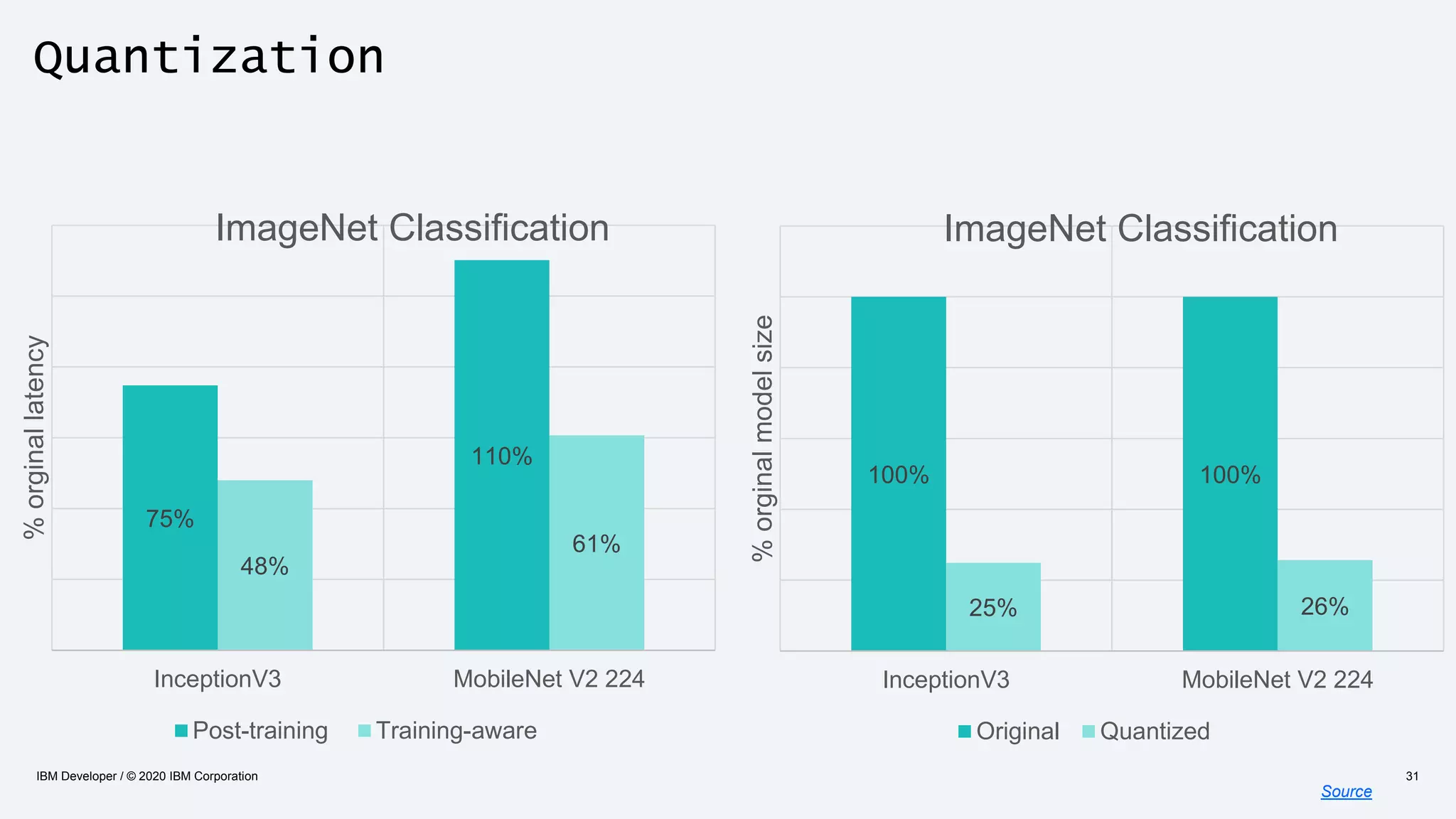
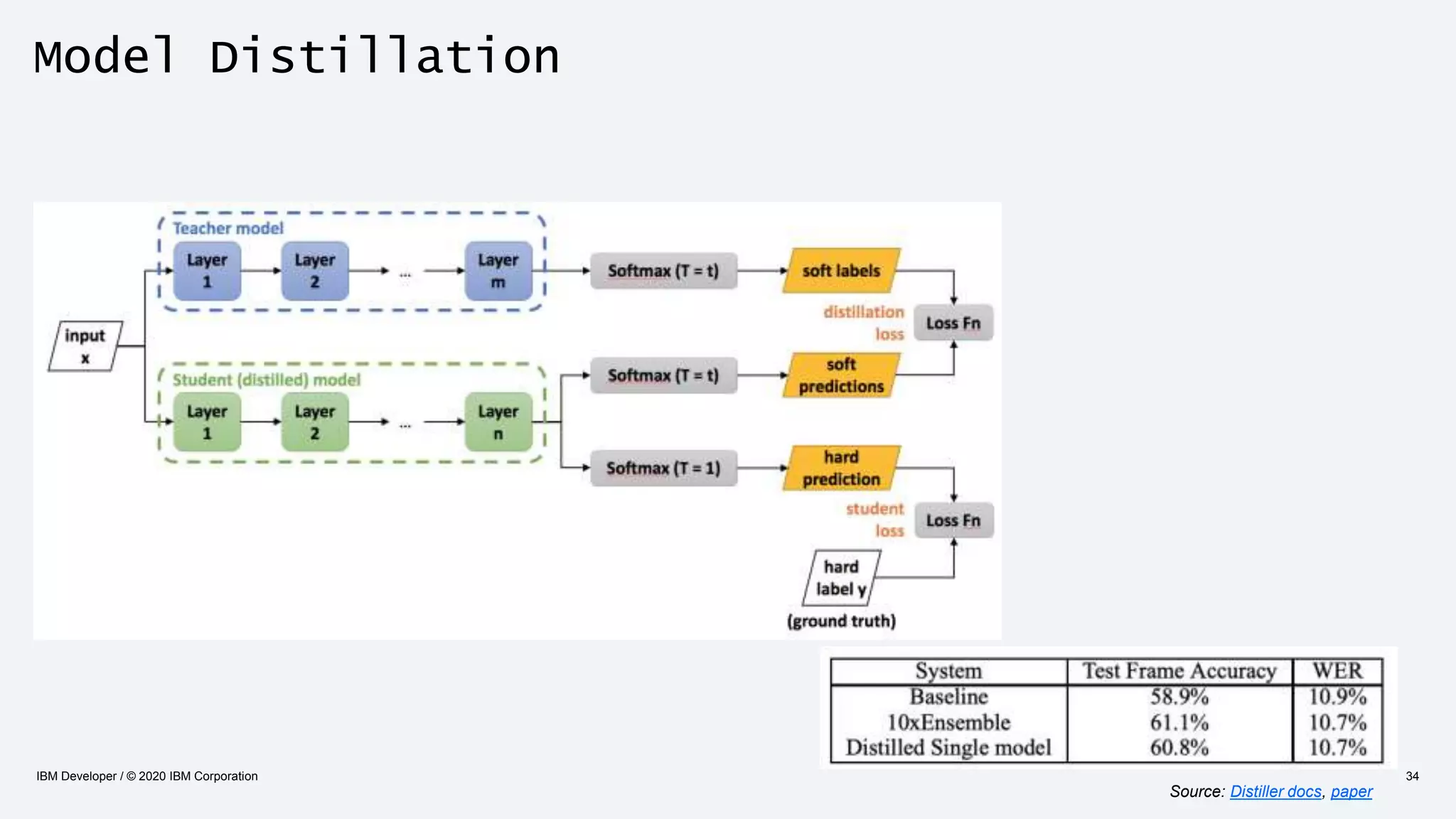
The document discusses strategies for enhancing the efficiency of deep learning workflows, focusing on model architectures, model compression, and model distillation. It highlights the importance of adapting machine learning models for deployment on resource-constrained environments like edge devices while maintaining computational efficiency. Techniques such as quantization and pruning are presented as methods to optimize model performance and reduce resource requirements.





















































![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
