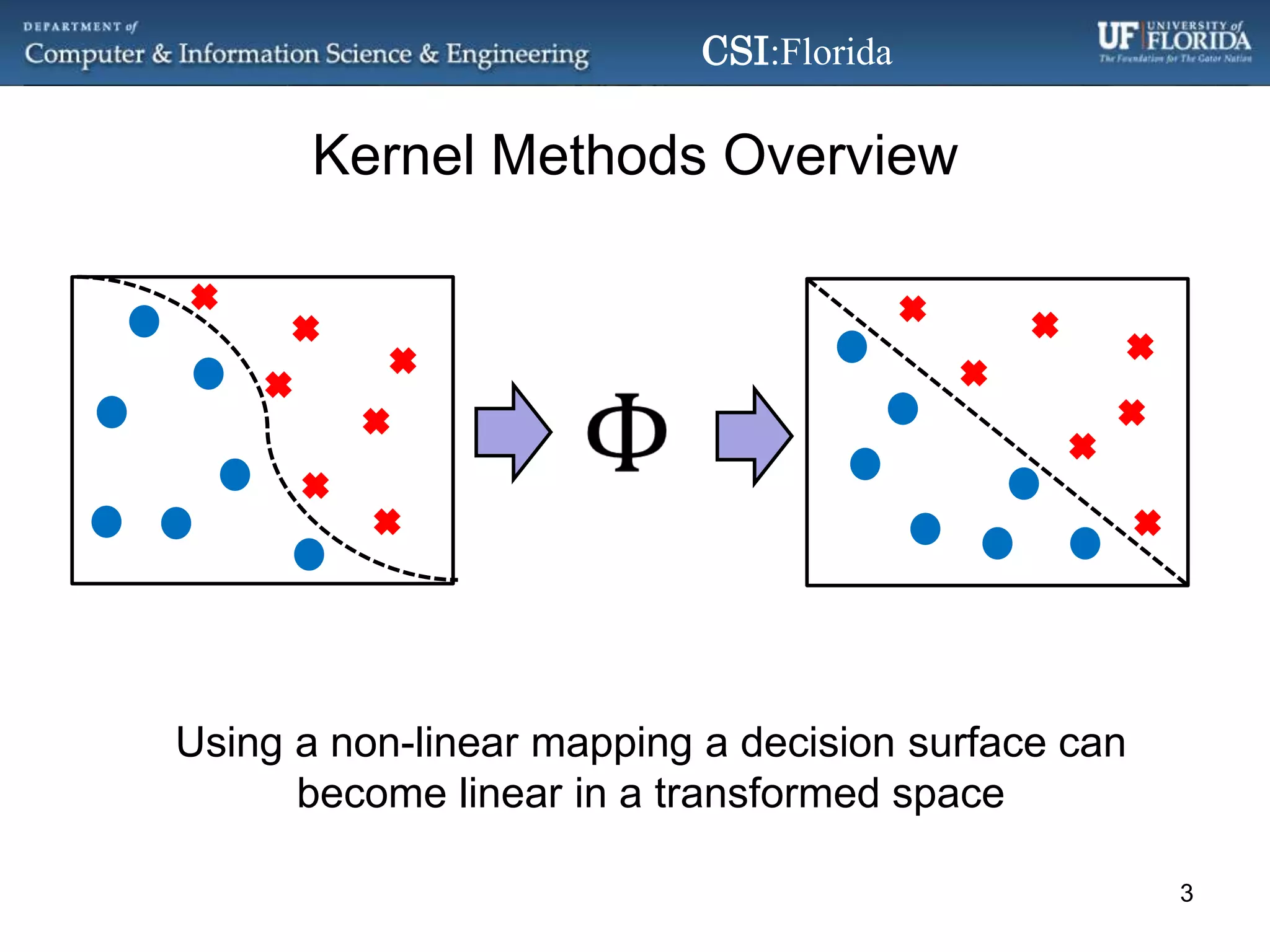
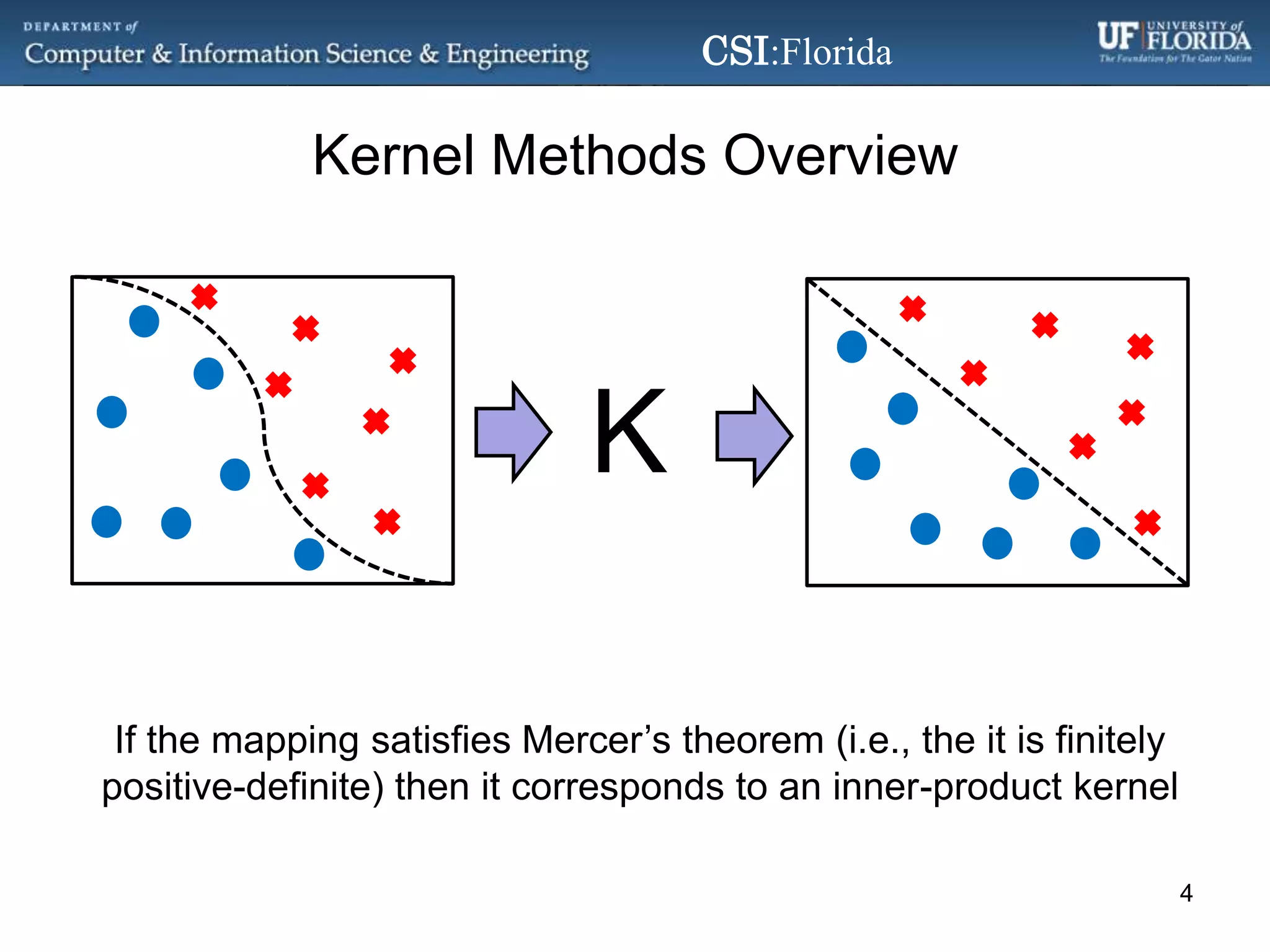
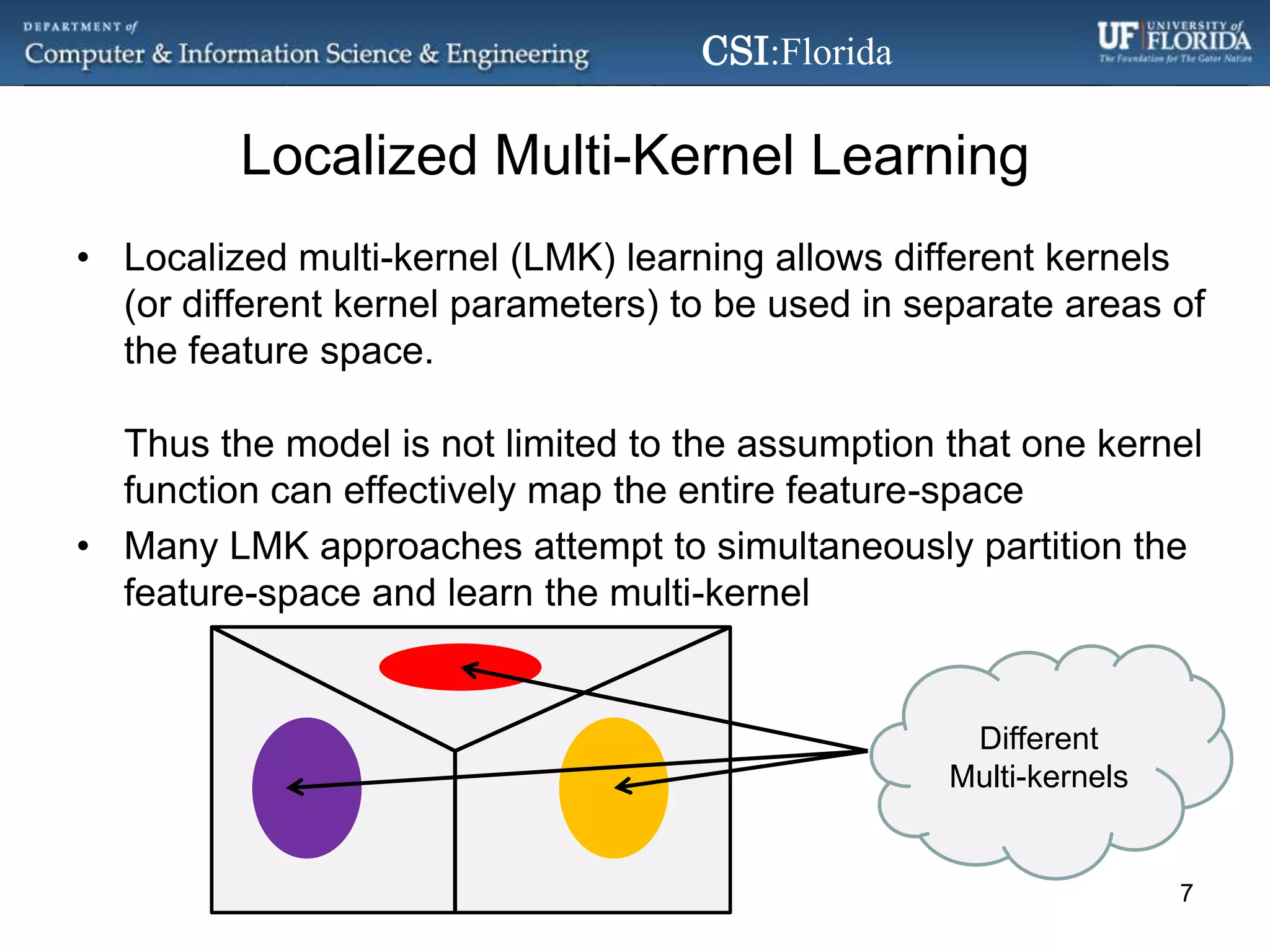
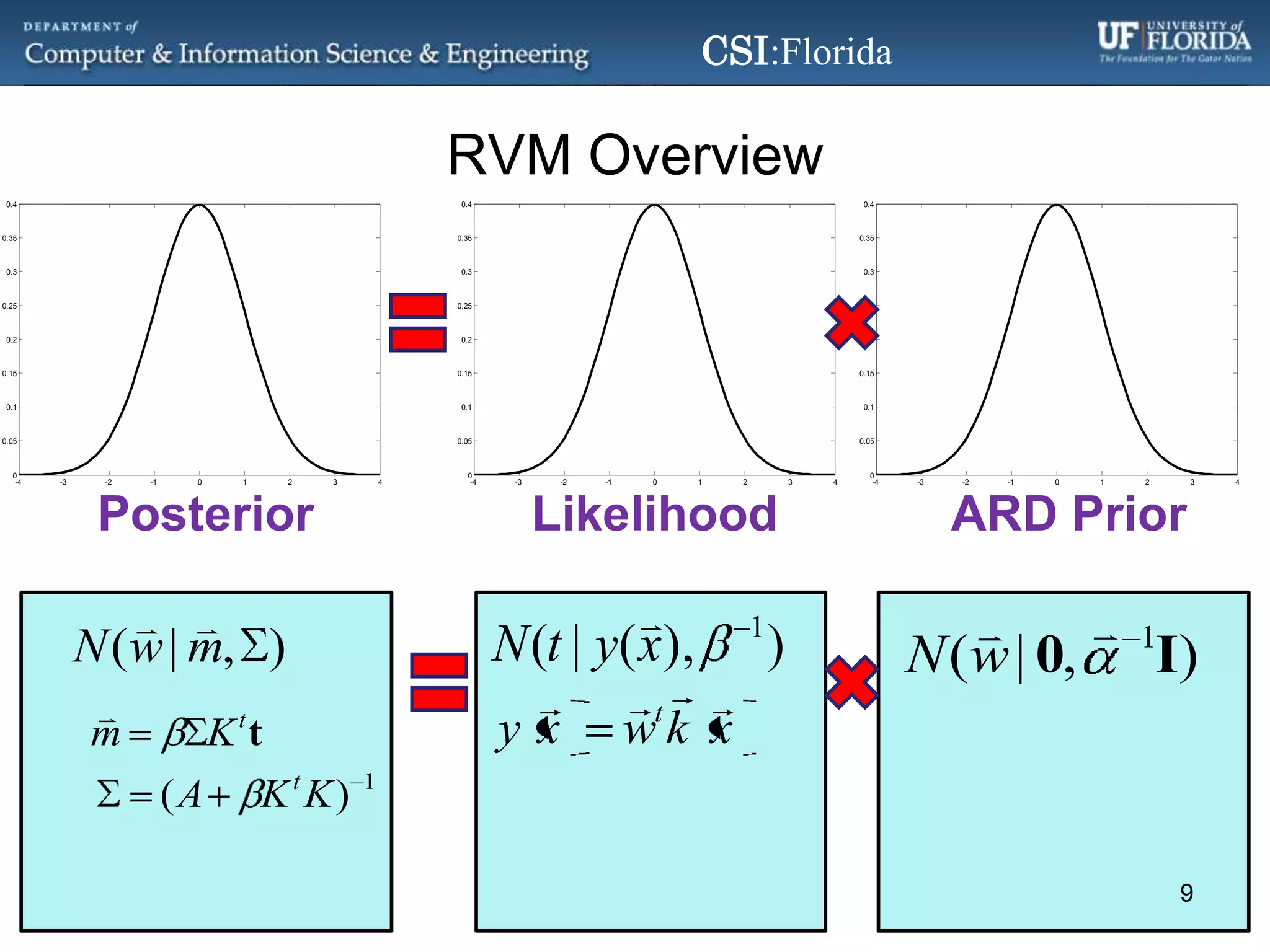
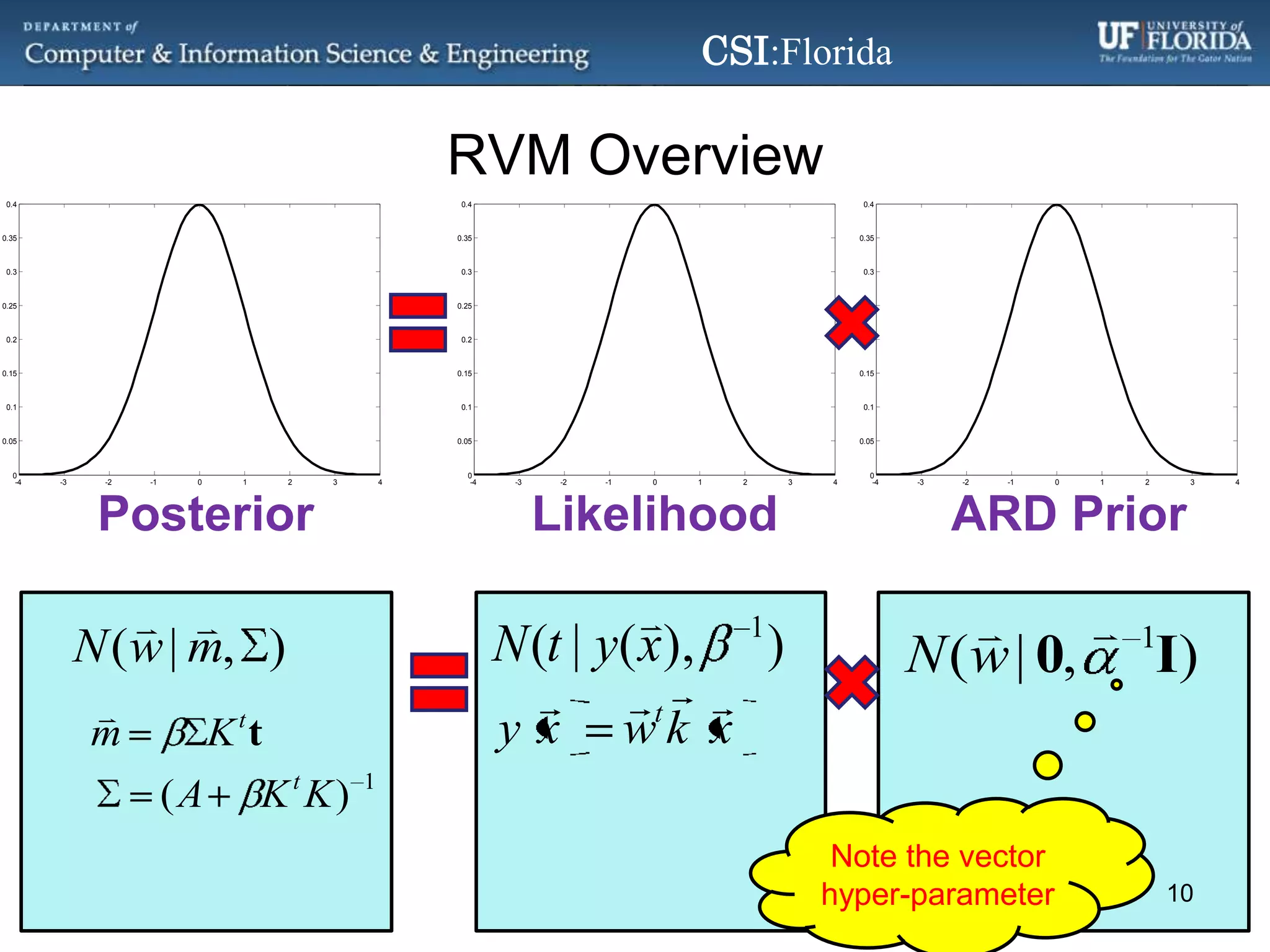
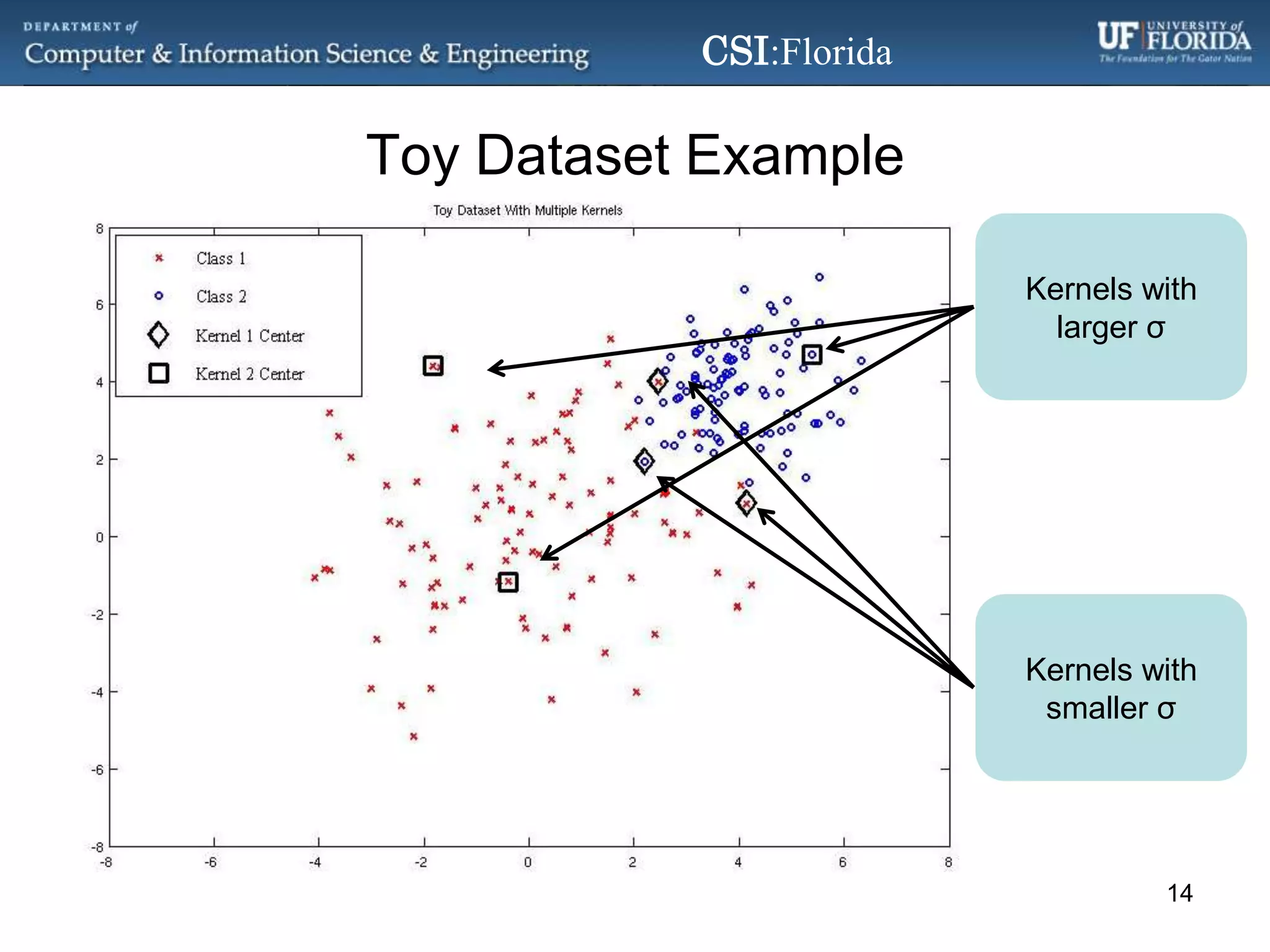
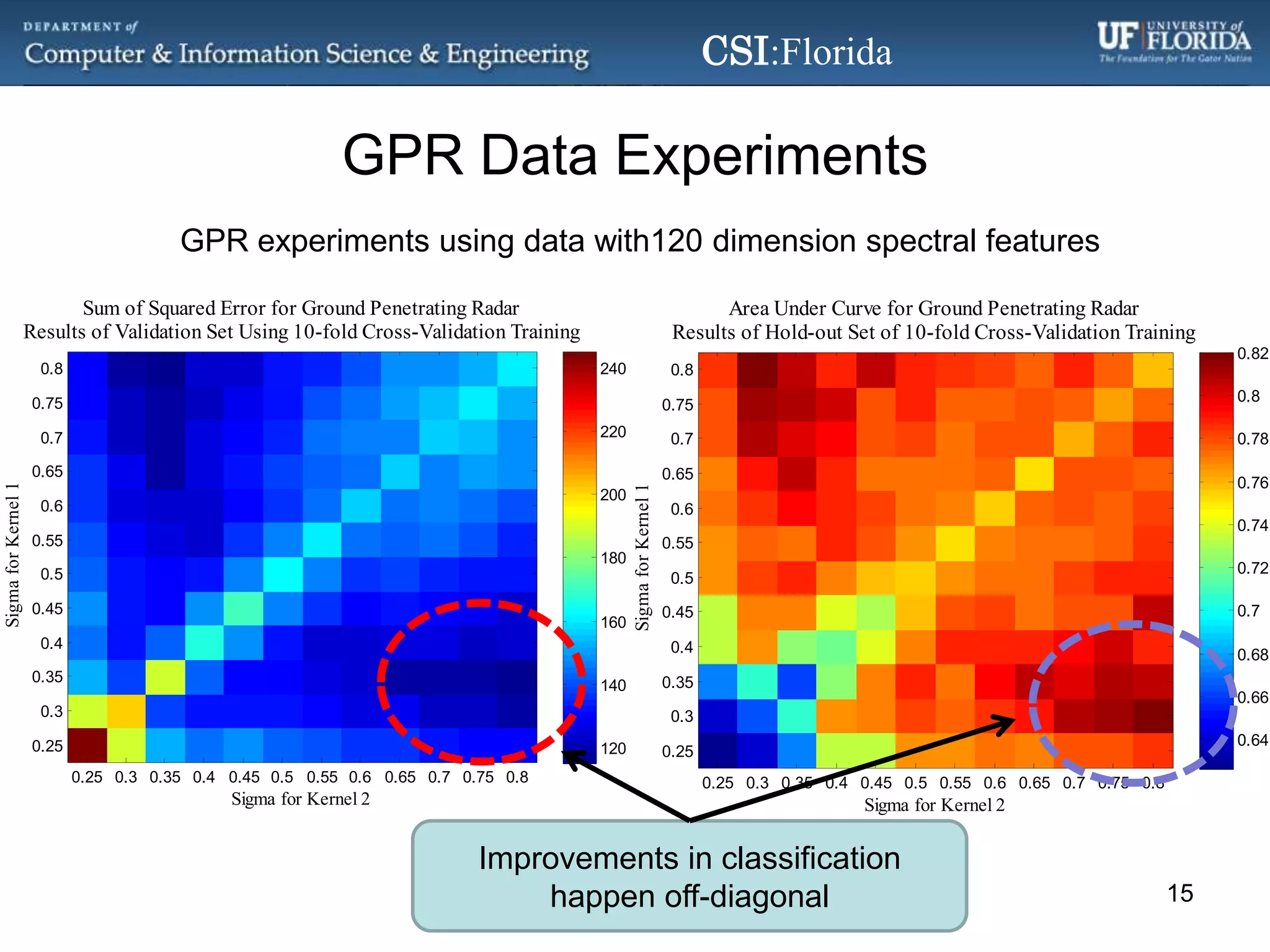
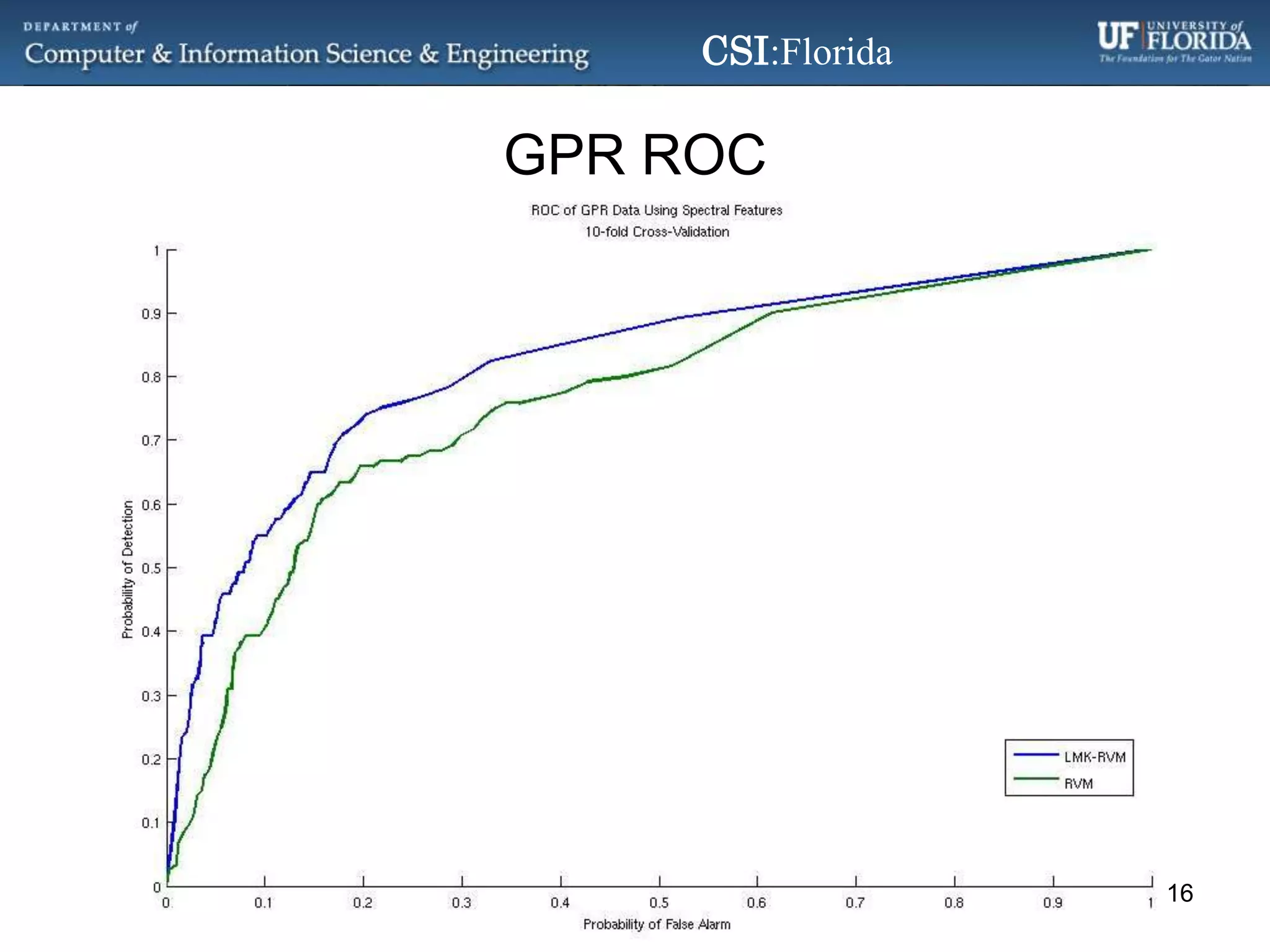
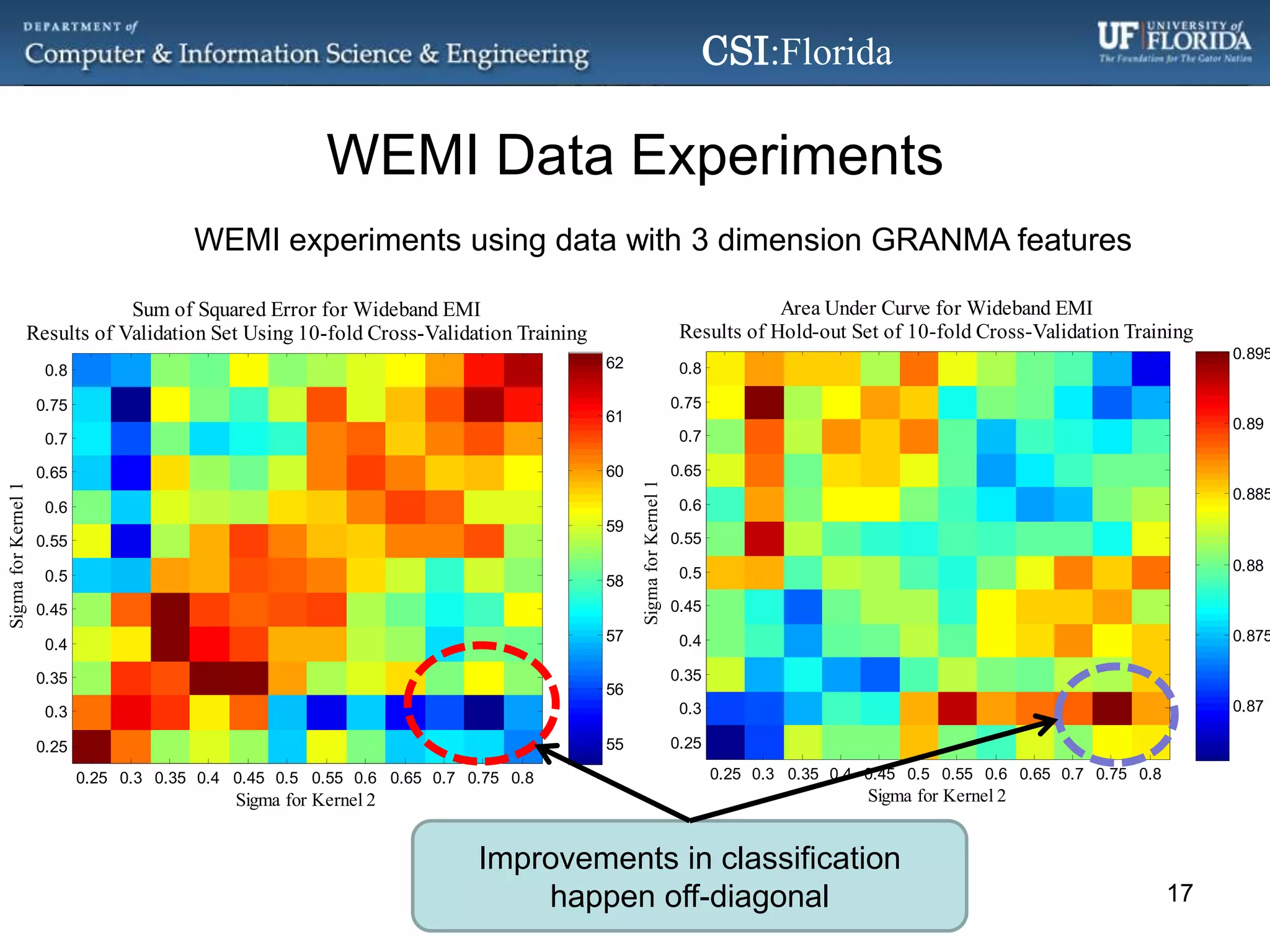
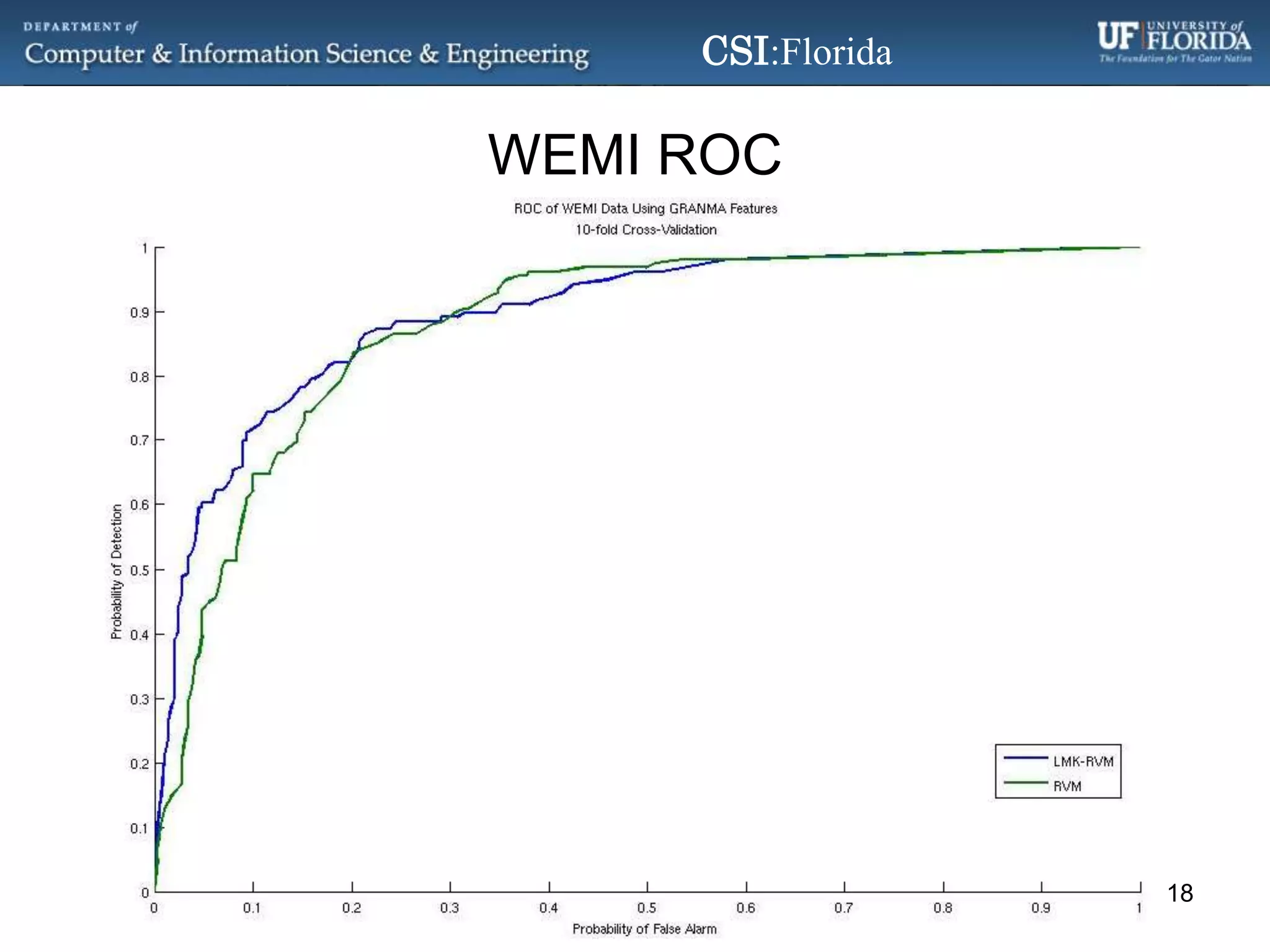
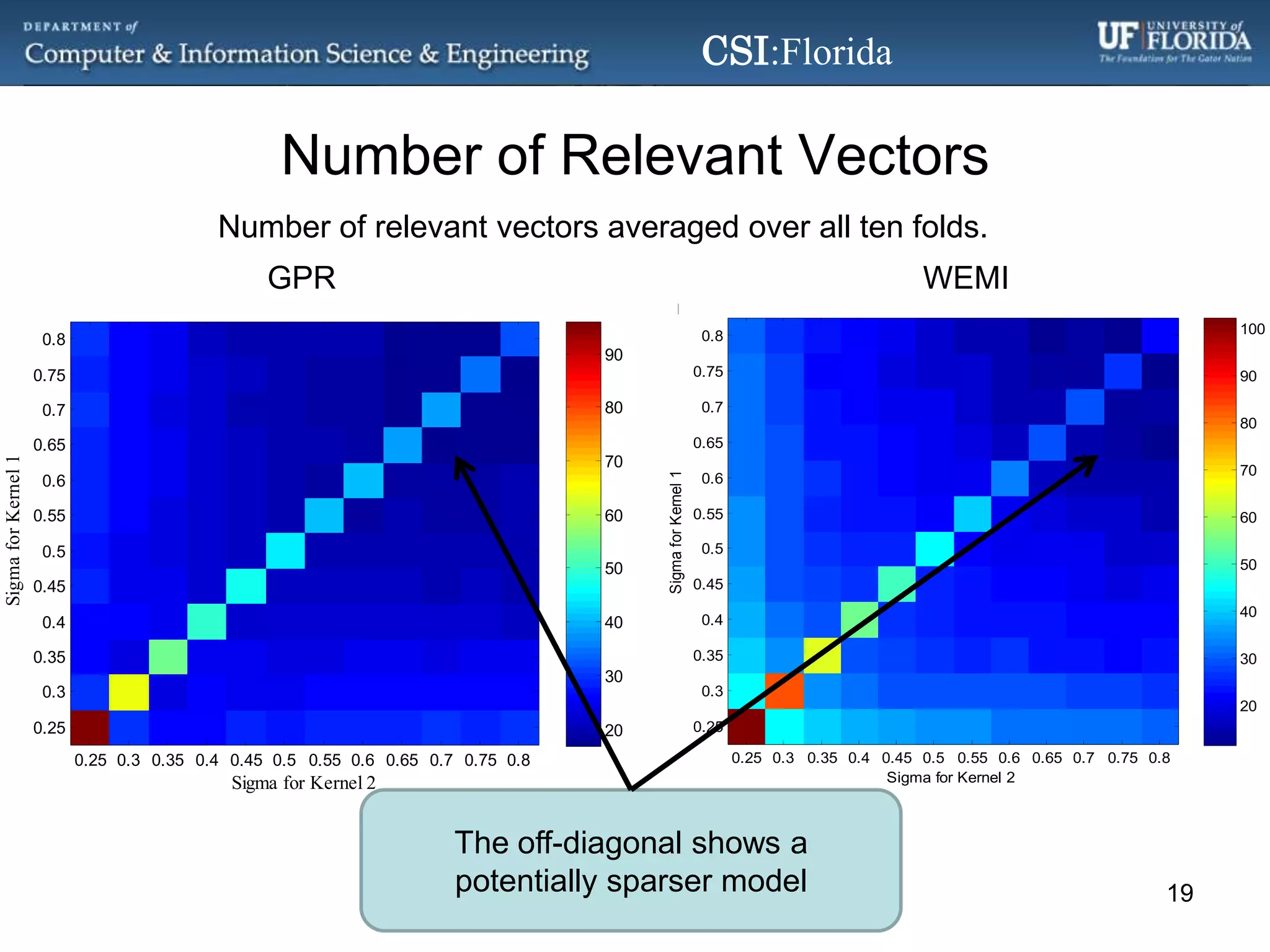
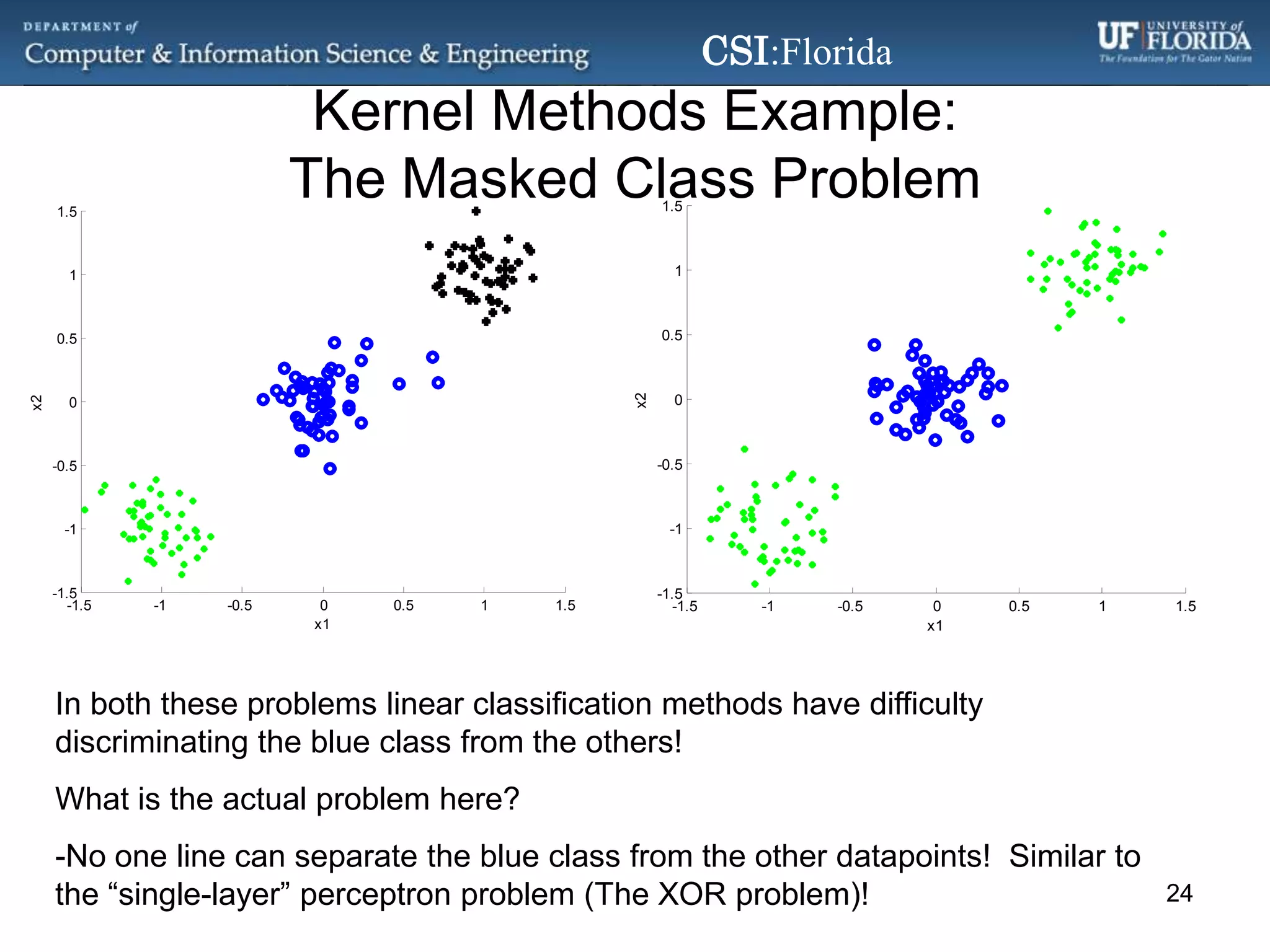
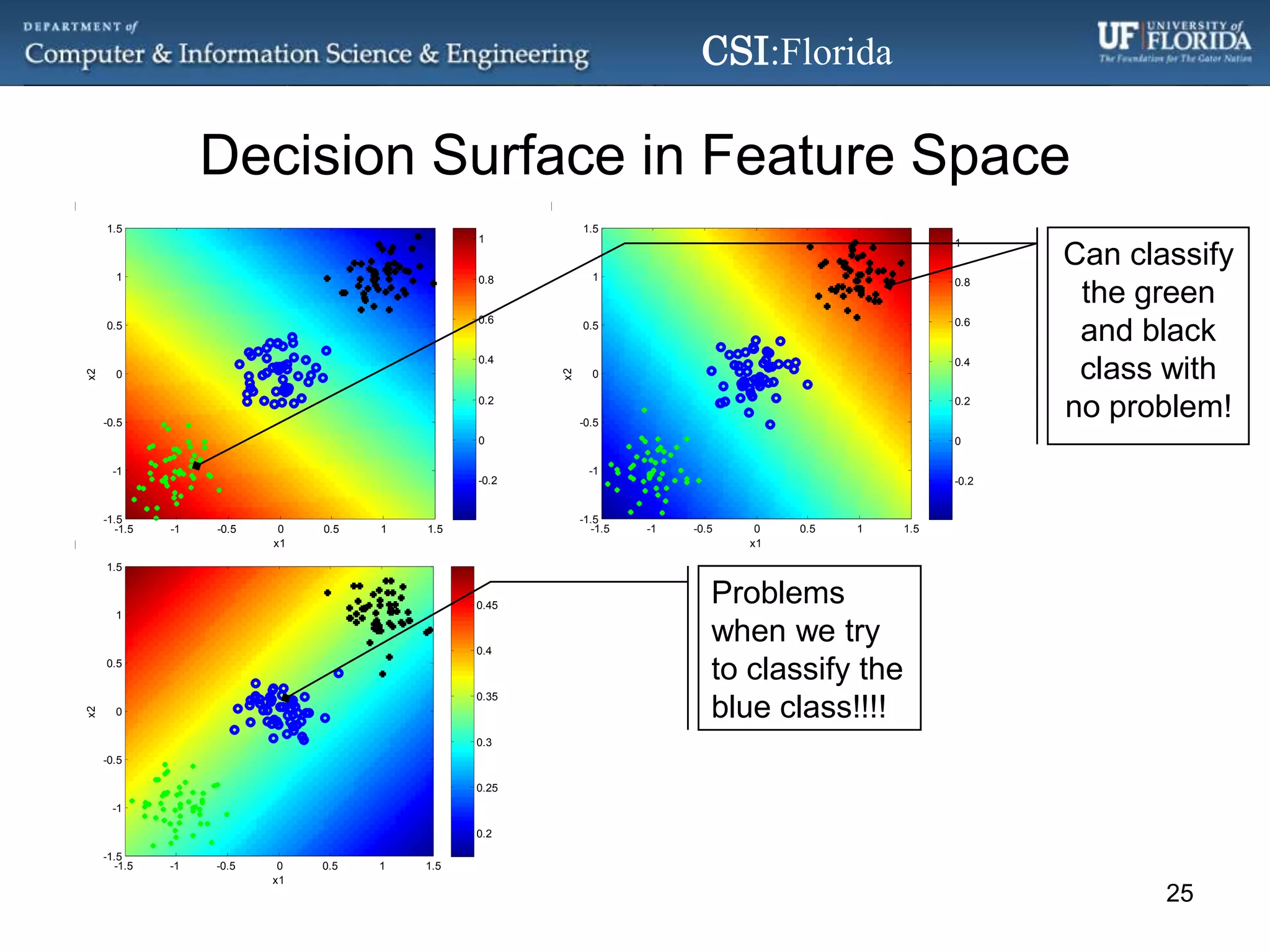
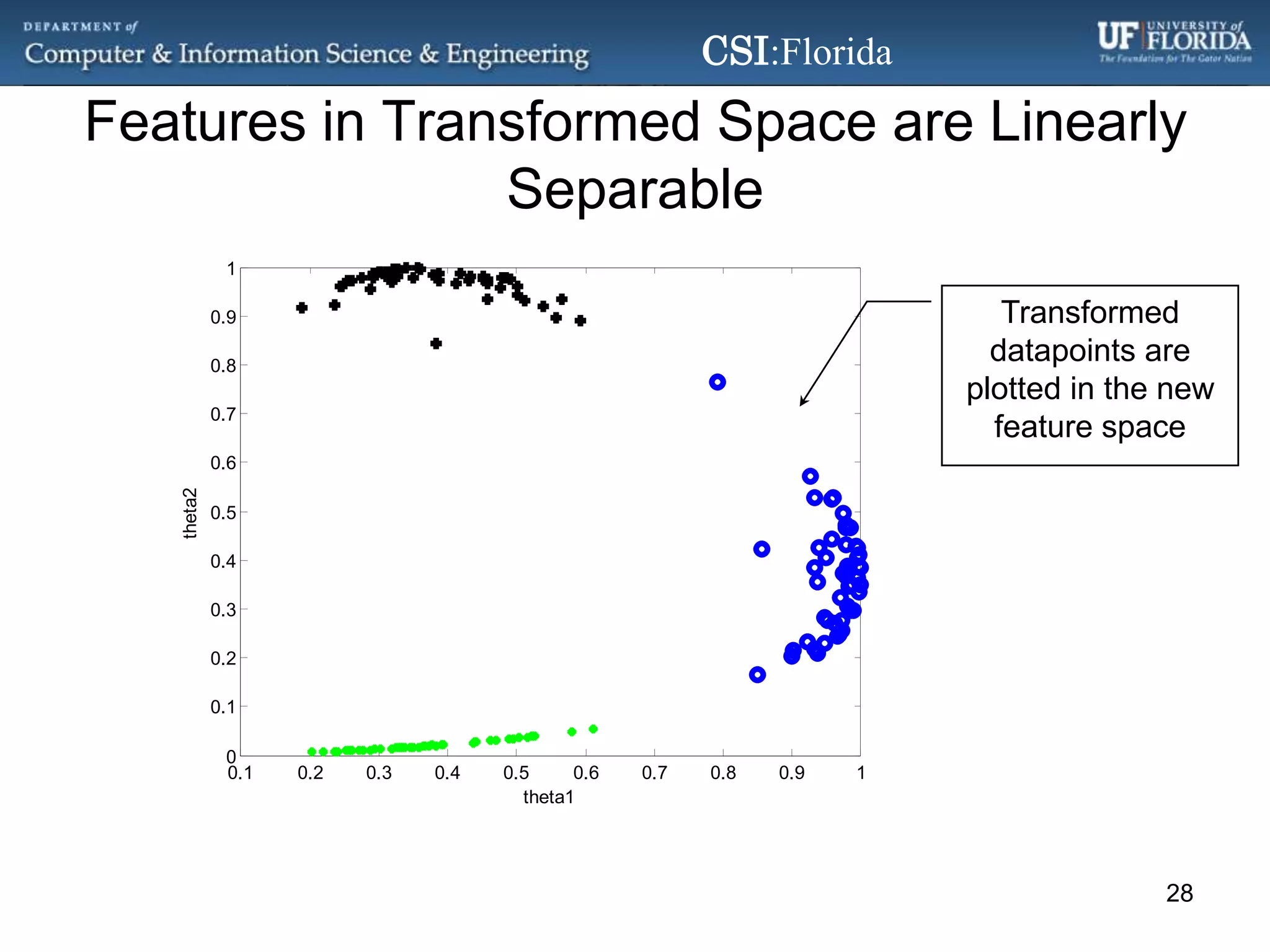
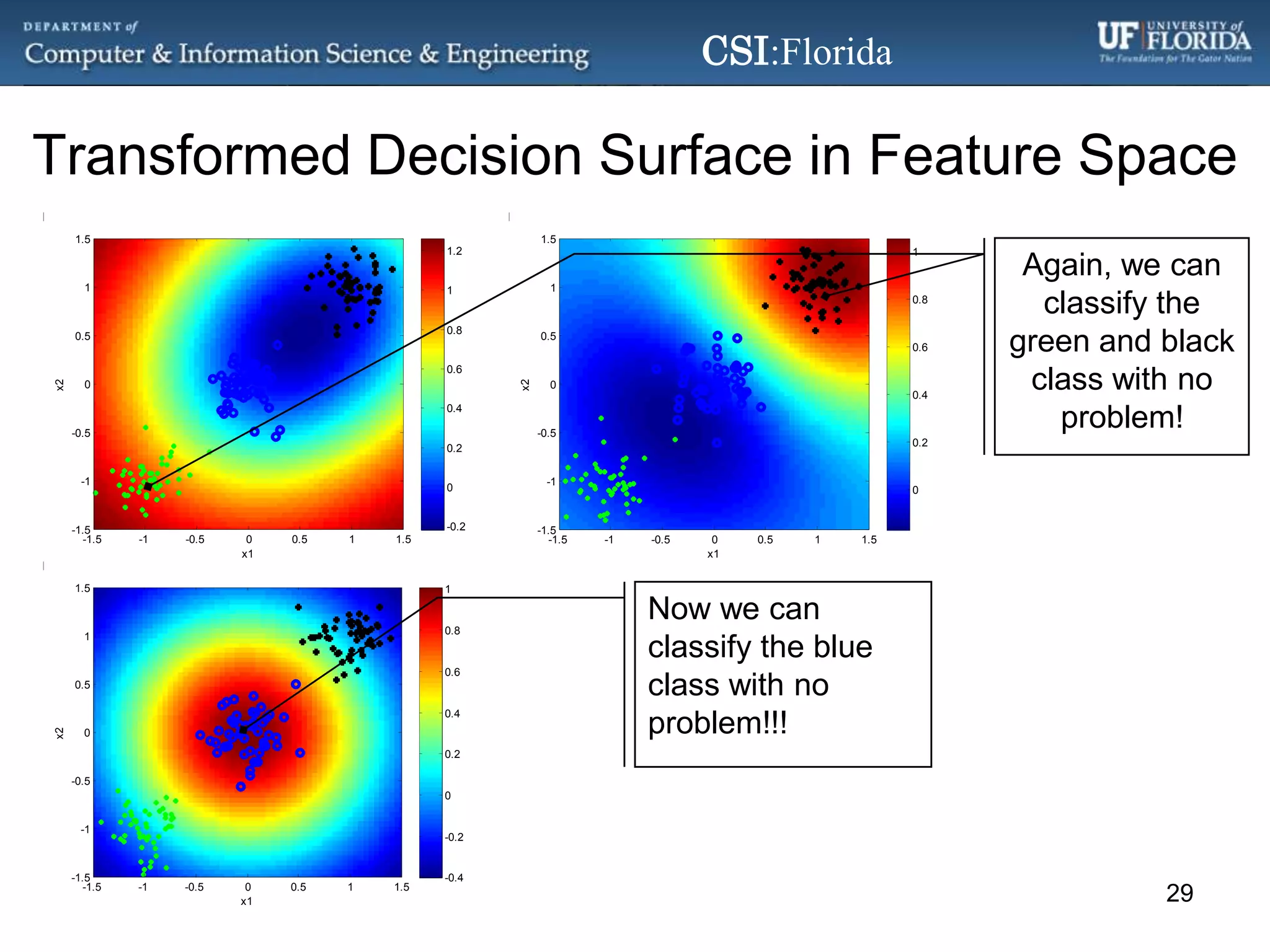
The document discusses a Bayesian approach called localized multi-kernel relevance vector machine (LMK-RVM) that uses multiple kernel functions to perform classification. LMK-RVM allows different kernel functions or parameters to be used in different areas of feature space, providing more flexibility than single-kernel models. It combines multi-kernel learning with the sparsity of the relevance vector machine (RVM) model. The document outlines LMK-RVM and provides examples showing it can improve classification accuracy and potentially provide sparser models compared to single-kernel approaches.









![References[1] F. R. Bach, et al., "Multiple Kernel Learning, Conic Duality, and the SMO Algorithm," in International Conference on Machine Learning, Banff, Canada, 2004.[2] T. Damoulas, et al., "Inferring Sparse Kernel Combinations and Relevance Vectors: An Application to Subcellular Localization of Proteins," in Machine Learning and Applications, 2008. ICMLA '08. Seventh International Conference on, 2008, pp. 577-582.[3] G. Camps-Valls, et al., "Nonlinear System Identification With Composite Relevance Vector Machines," Signal Processing Letters, IEEE, vol. 14, pp. 279-282, 2007.[4] B. Wu, et al., "A Genetic Multiple Kernel Relevance Vector Regression Approach," in Education Technology and Computer Science (ETCS), 2010 Second International Workshop on, 2010, pp. 52-55.[5] R. A. Jacobs, et al., "Adaptive Mixtures of Local Experts," Neural Computation, vol. 3, pp. 79-87, 1991.[6] C. E. Rasmussen and Z. Ghahramani, "Infinite Mixtures of Gaussian Process Experts," in Advances in Neural Information Processing Systems, 2002.21](https://image.slidesharecdn.com/abayesianapproachtolocalizedmultikernellearningusingtherelevancevectormachine-110726102451-phpapp02/75/ABayesianApproachToLocalizedMultiKernelLearningUsingTheRelevanceVectorMachine-pptx-21-2048.jpg)
![References[7] L. Yen-Yu, et al., "Local Ensemble Kernel Learning for Object Category Recognition," in Computer Vision and Pattern Recognition, 2007. CVPR '07. IEEE Conference on, 2007, pp. 1-8.[8] M. Gonen and E. Alpaydin, "Localized Multiple Kernel Learning," in 25th International Conference on Machine Learning, Helsinki, Finland, 2008.[9] M. Gonen and E. Alpaydin, "Localized Multiple Kernel Regression," in Pattern Recognition (ICPR), 2010 20th International Conference on, 2010, pp. 1425-1428.[10] M. E. Tipping, "The Relevance Vector Machine," Advances in Neural Information Processing Systems, vol. 12, pp. 652-658, 2000.[11] C. M. Bishop, "Relevance Vector Machines (Analysis of Sparsity)," in Pattern Recognition and Machine Learning, ed: Springer, 2007, pp. 349-353.[12] D. Tzikas, A. Likas, and N. Galatsanos. “Large Scale Multikernel Relevance Vector Machine for Object Detection,” International Journal on Artificial Intelligence Tools, 16(6):967-979, December 2007.[13] D. Tzikas, A. Likas, and N. Galatsanos, "Large Scale Multikernel RVM for Object Detection," presented at the Hellenic Conference on Artificial Intelligence, Heraclion, Crete, Greece, 2006.22](https://image.slidesharecdn.com/abayesianapproachtolocalizedmultikernellearningusingtherelevancevectormachine-110726102451-phpapp02/75/ABayesianApproachToLocalizedMultiKernelLearningUsingTheRelevanceVectorMachine-pptx-22-2048.jpg)




















































































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)


![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)







