Downloaded 94 times

























![REFERENCES.
[1] R. 1. Anderson, Syntax-directed recognition of handprinted mathematics., CA: Symposium, 1967.
[2] K. Cho, A. Courville and Y. Bengio, "Describing Multimedia Content Using Attention-Based Encoder-Decoder Networks," in IEEE, CA, 2015.
[3] A. K. a. E. Learned-Miller, "Learning on the Fly: Font-Free Approaches to Difficult OCR Problems," MA, 2000.
[4] D. Lopresti, "Optical Character Recognition Errors and Their Effects on Natural Language Processing," International Journal on Document Analysis and Recognition, 19 12
[5] WILDML, "WILDML," [Online]. Available: http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/.
[6] S. a. S. J. Hochreiter, "Long Short-Term Memory. Neural Computation," 1997.
[7] S. Yan, "Understanding LSTM and its diagrams," Software engineer & wantrepreneur. Interested in computer graphics, bitcoin and deep learning., 13 03 2016. [Online]. [1]
https://medium.com/@shiyan/understanding-lstm-and-its-diagrams-37e2f46f1714.
[8] C. R. a. D. P. W. Ellis, "FEED-FORWARD NETWORKS WITH ATTENTION CAN SOLVE SOME LONG-TERM MEMORY PROBLEMS," ICLR, 2016.
[9] a. F.-F. L. Karpathy, Image captioning., 2015.
[10] F. A. Gers, N. N. Schraudolph and J. Schmidhuber, "Learning Precise Timing with LSTM Recurrent Networks," Journal of Machine Learning Reserach, 8 2002.](https://image.slidesharecdn.com/thesisppt2-180112190155/85/Convolutional-Neural-Network-and-RNN-for-OCR-problem-94-320.jpg)



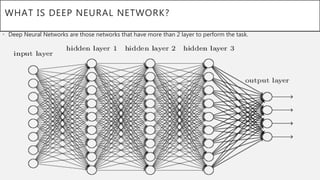
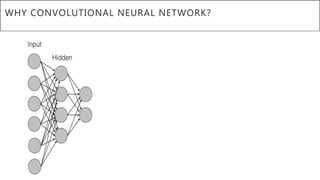
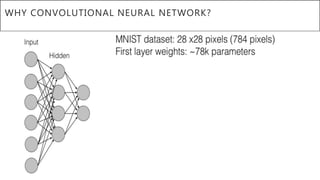
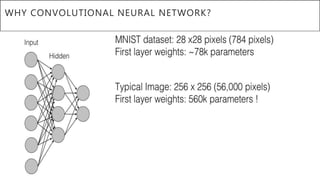
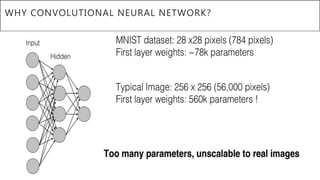
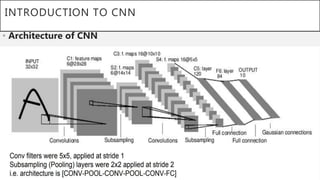
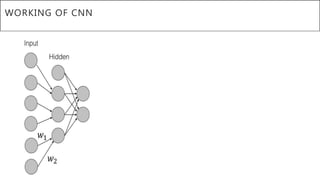
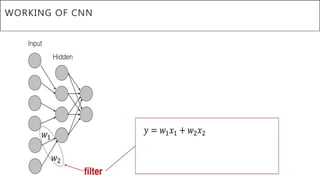
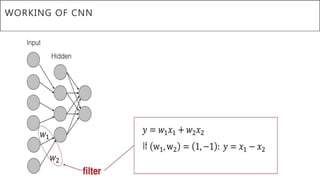
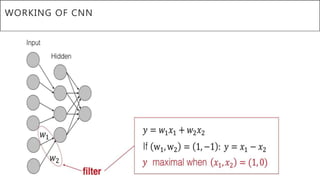
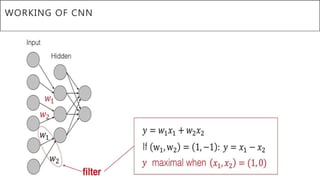
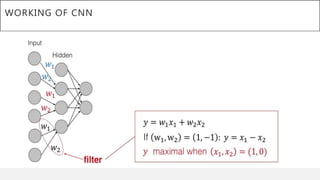
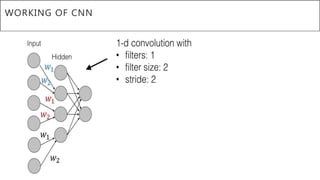
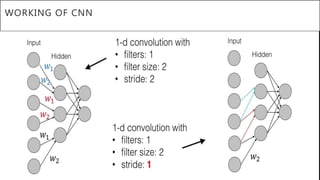
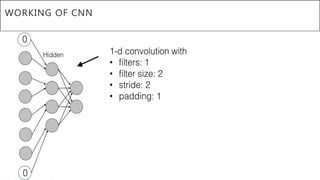
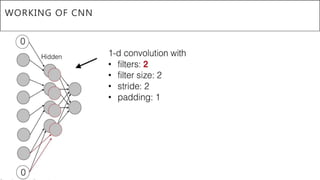
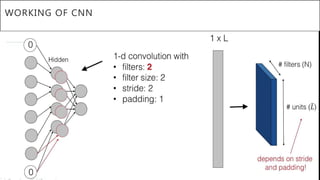
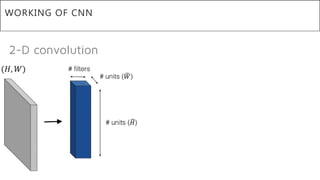
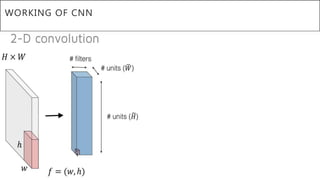
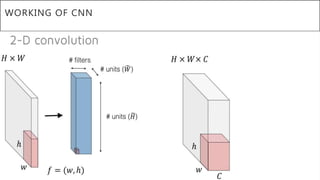
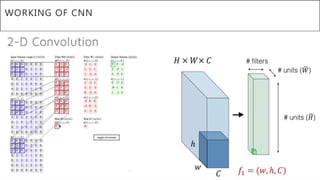
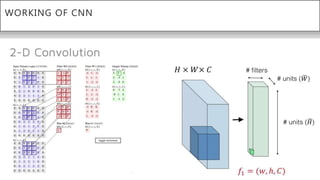
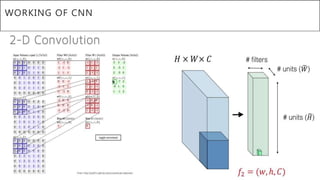
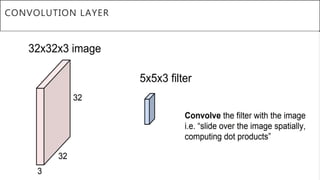
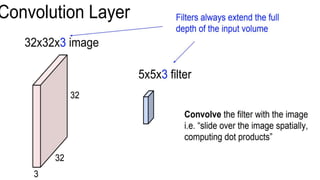
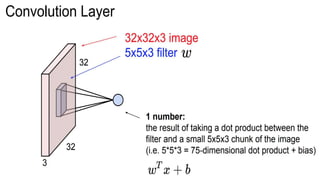
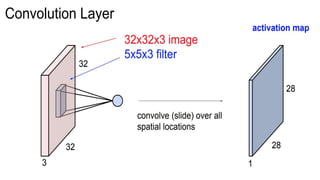
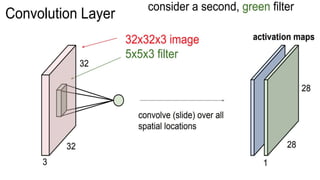
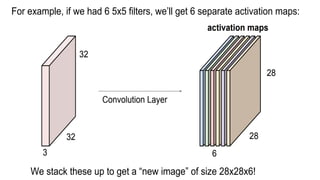
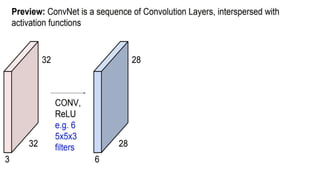
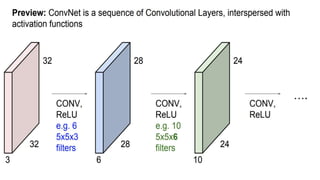
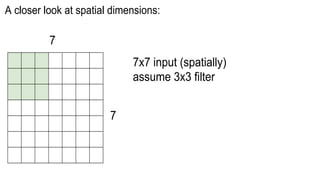
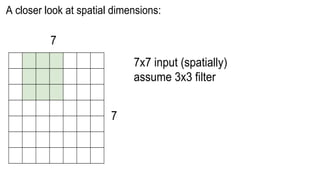
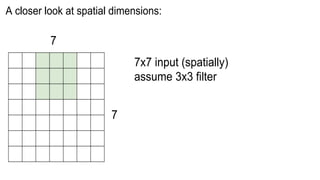
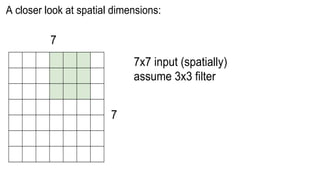
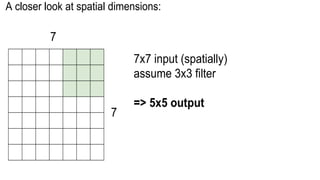
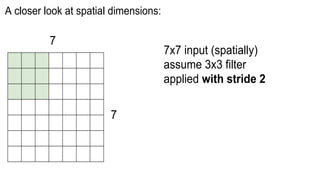
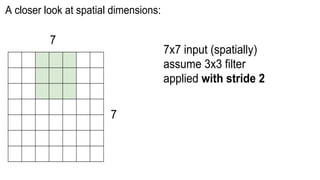
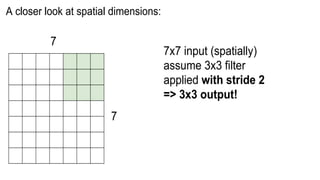
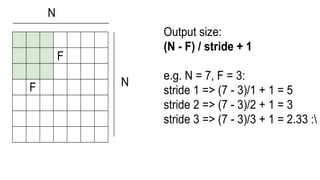
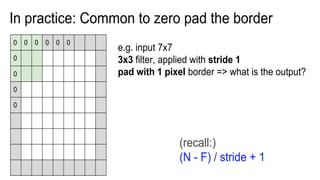
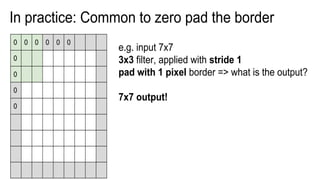
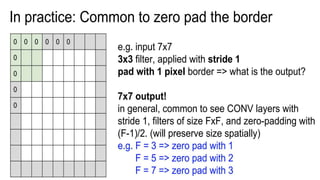
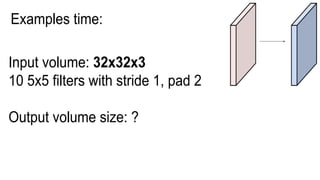
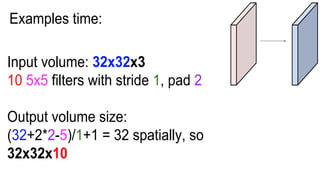
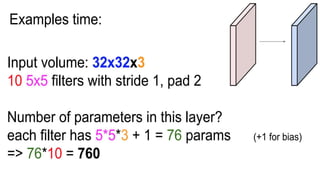
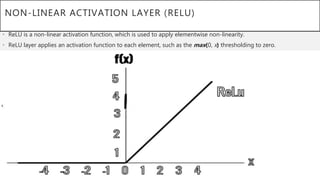
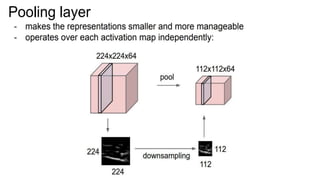
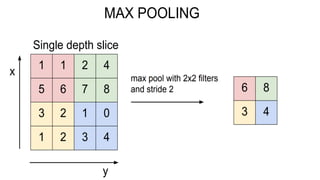
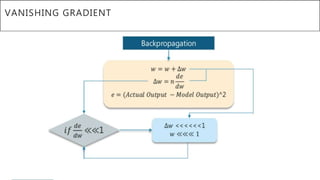
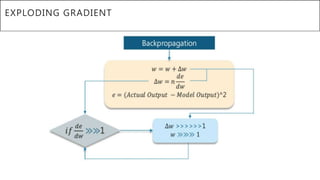
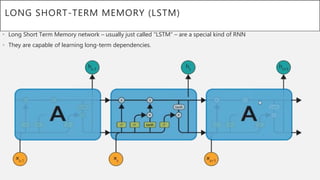
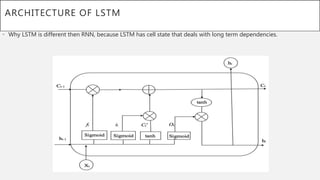
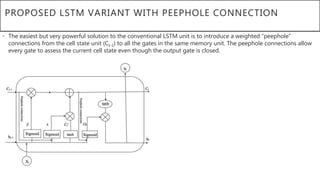
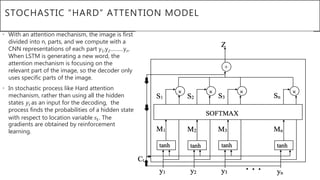
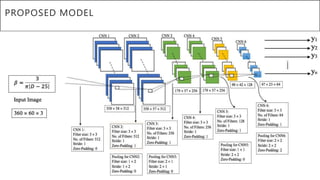
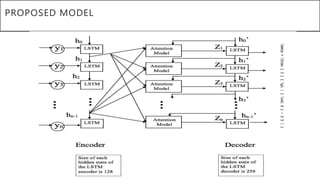
This document presents a thesis on using sequence-to-sequence learning with deep learning techniques for optical character recognition. The author aims to convert images of mathematical equations into LaTeX representations. Convolutional neural networks, recurrent neural networks, long short-term memory networks, and attention models are discussed as approaches. Details are provided on the architecture and workings of CNNs, RNNs, and LSTMs. The thesis will propose a model and discuss results and future work.
























































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)










