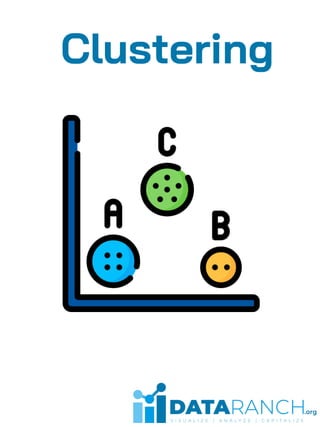
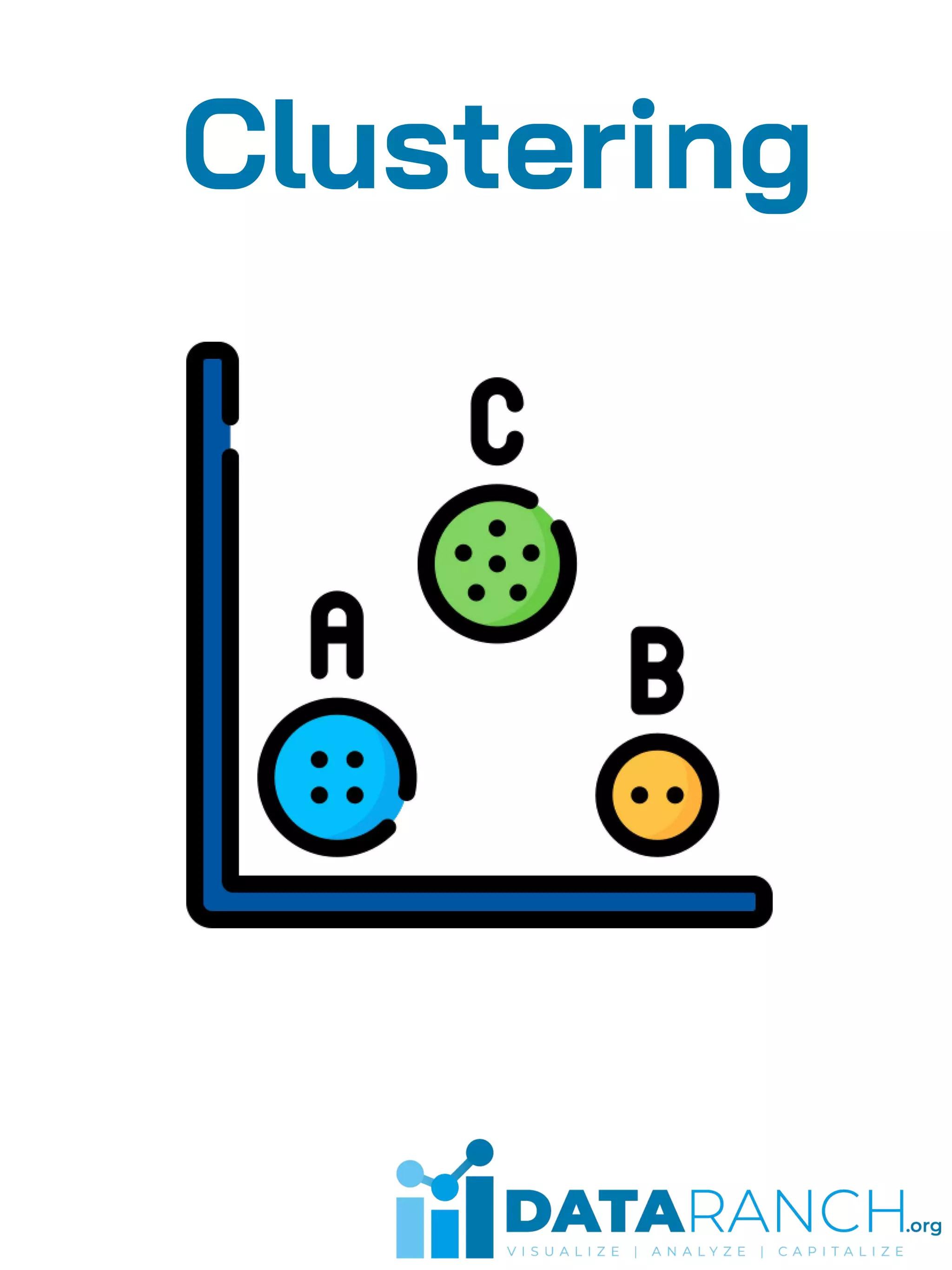
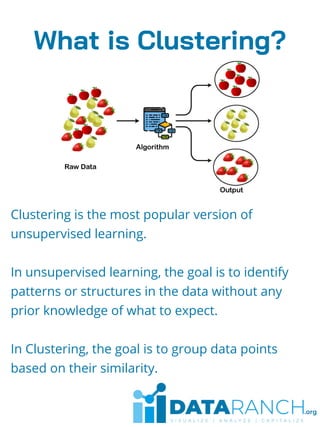
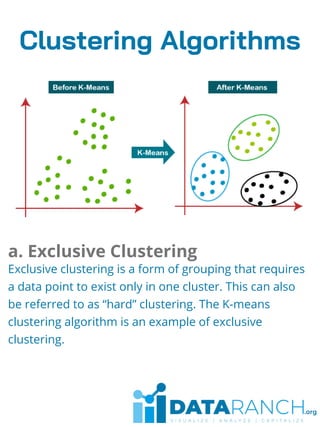
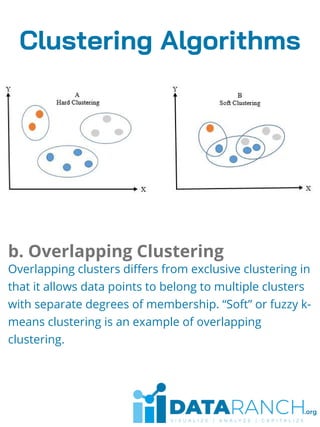
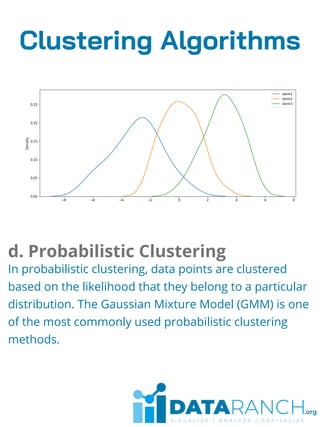
Clustering is an unsupervised learning technique used to group unlabeled data points based on their similarities. It is useful for segmenting customers into groups to develop targeted business strategies. Desirable properties of clustering algorithms include scalability, ability to handle different data types and noise, and interpretability. Common clustering algorithms are k-means for exclusive clustering, fuzzy c-means for overlapping clusters, hierarchical clustering using agglomerative or divisive approaches, and Gaussian mixture models for probabilistic clustering. Clustering has applications in marketing, biology, libraries, and city planning. Challenges include computational complexity, training time, inaccurate results, and lack of transparency.





































![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)



![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)


![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)




























