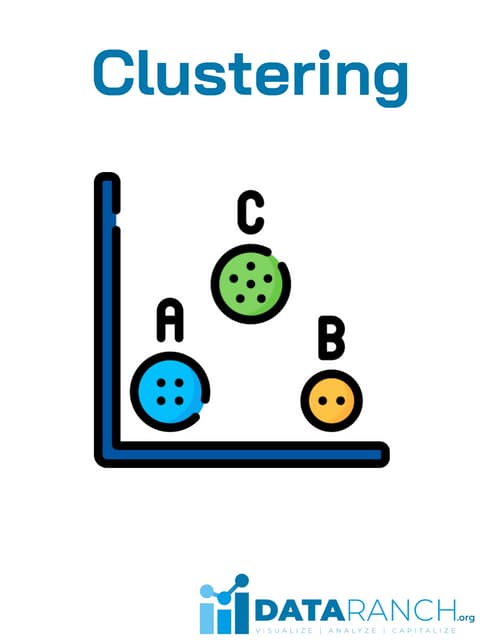
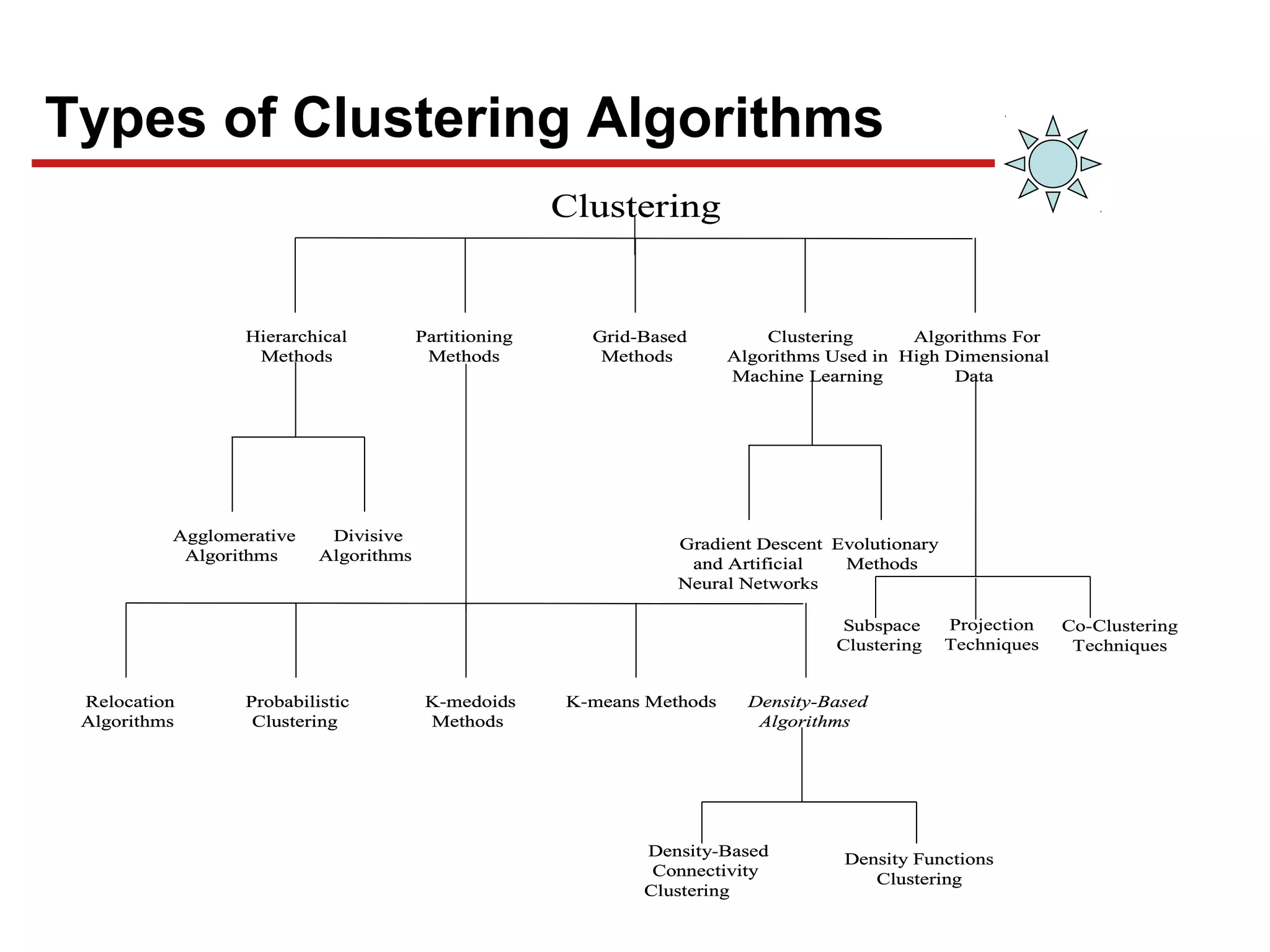
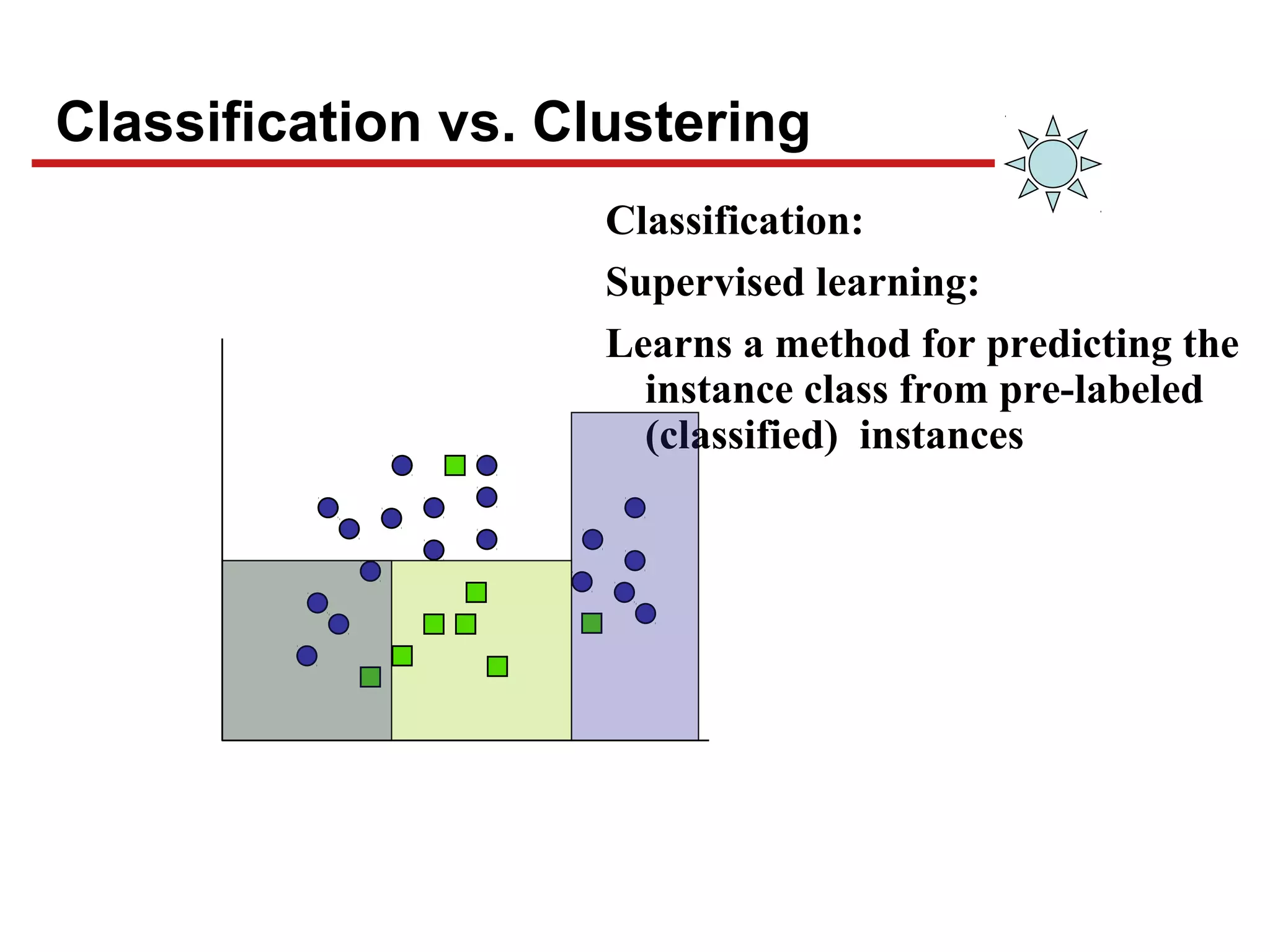
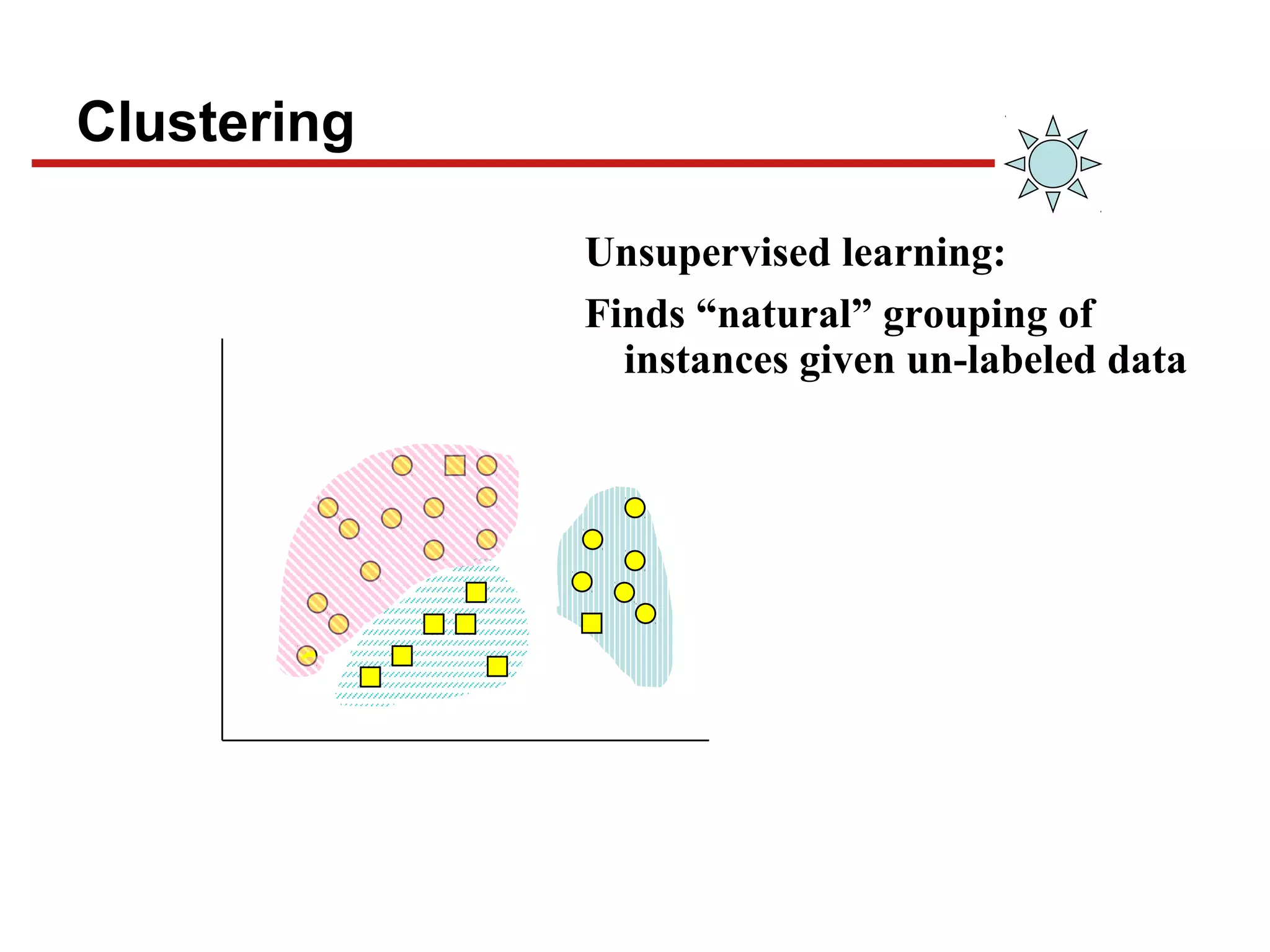
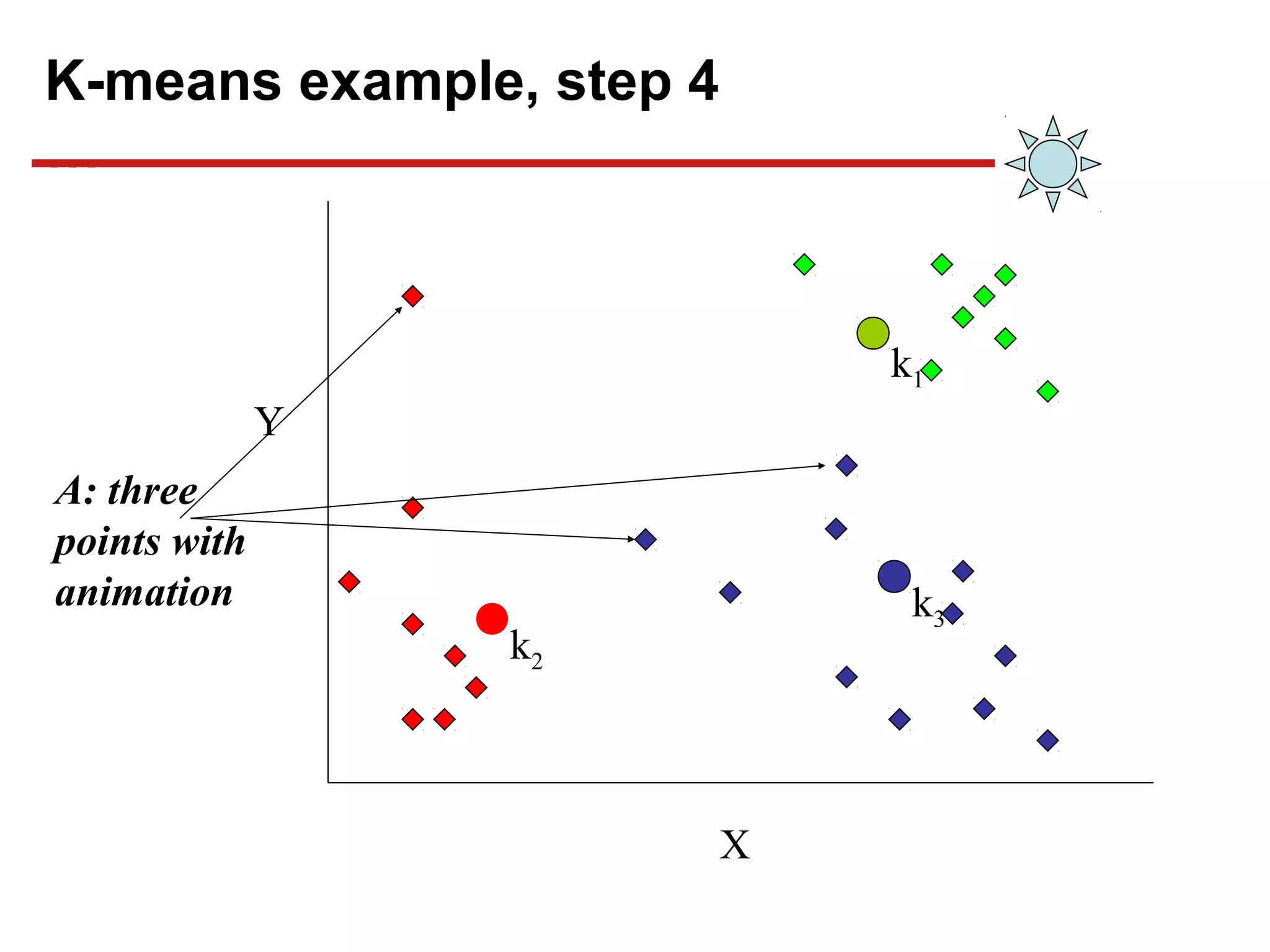
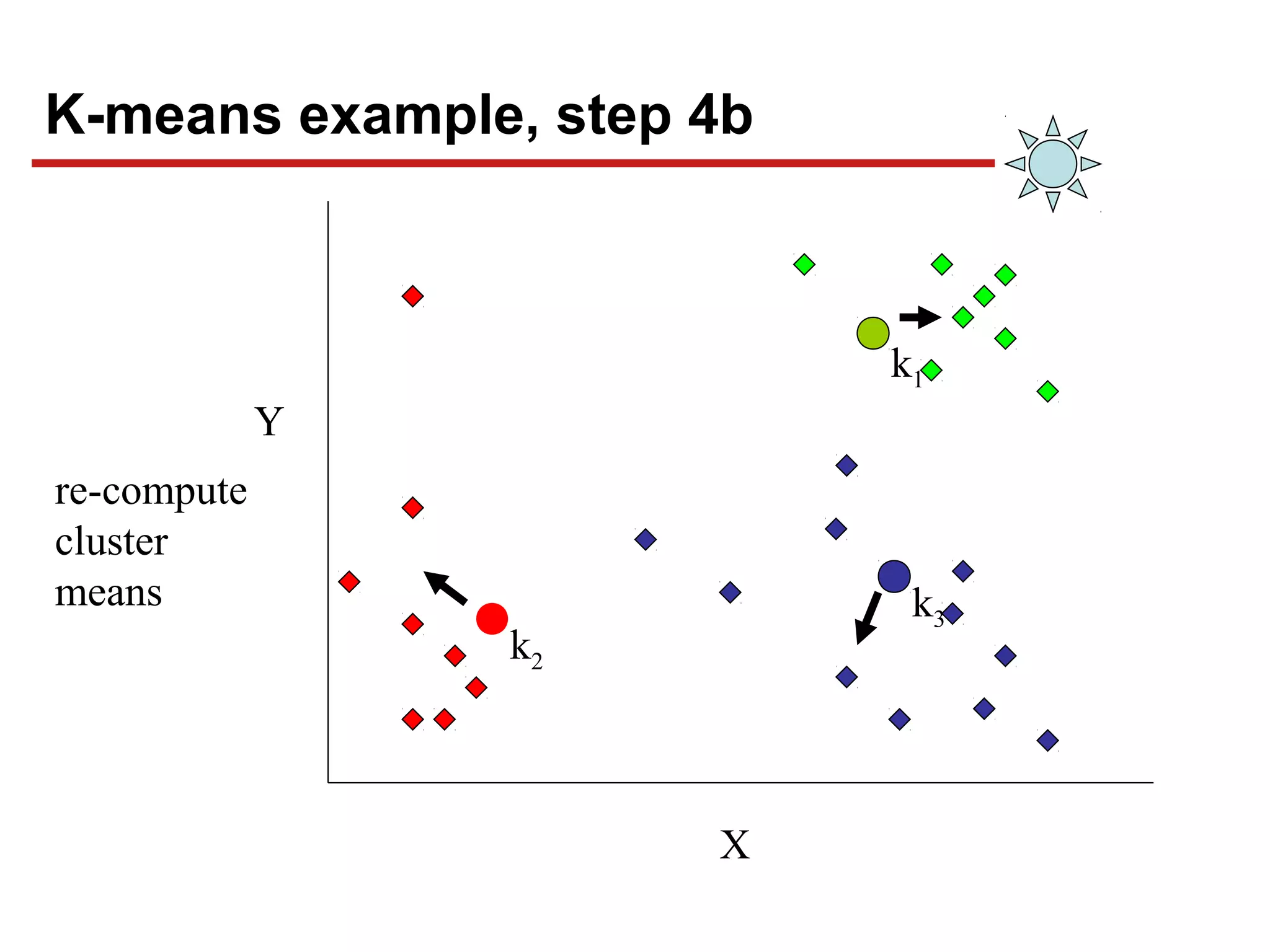
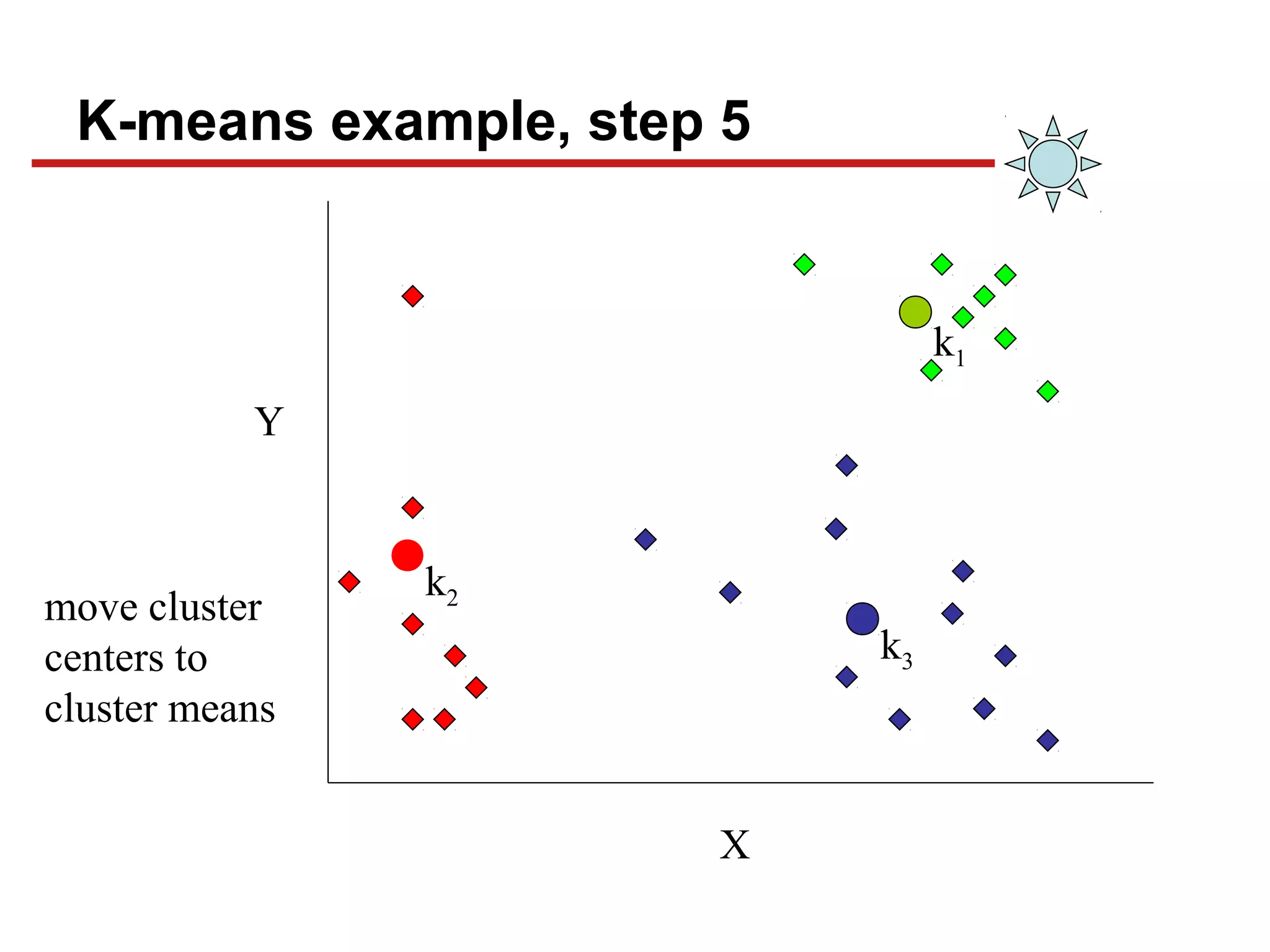
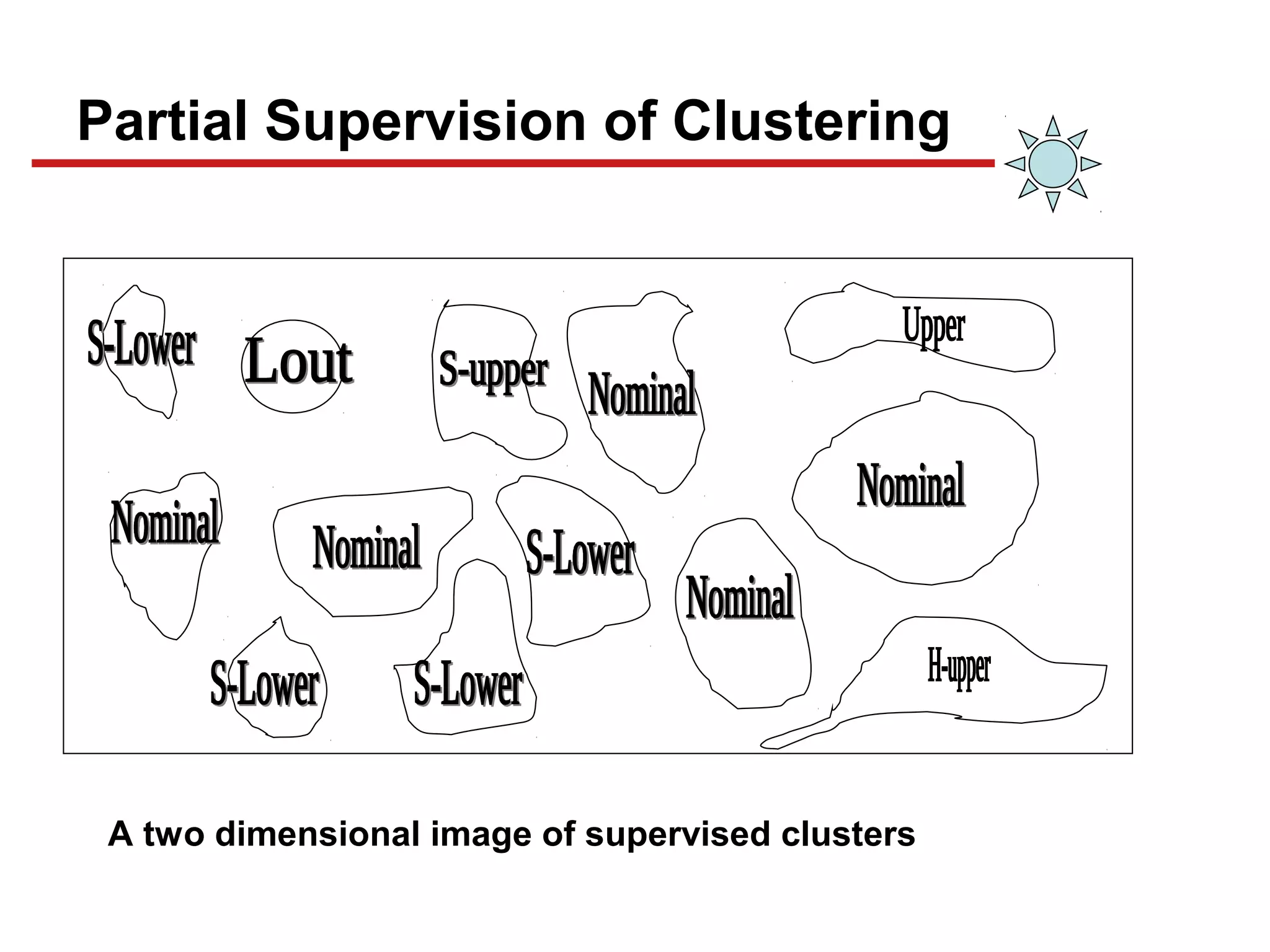
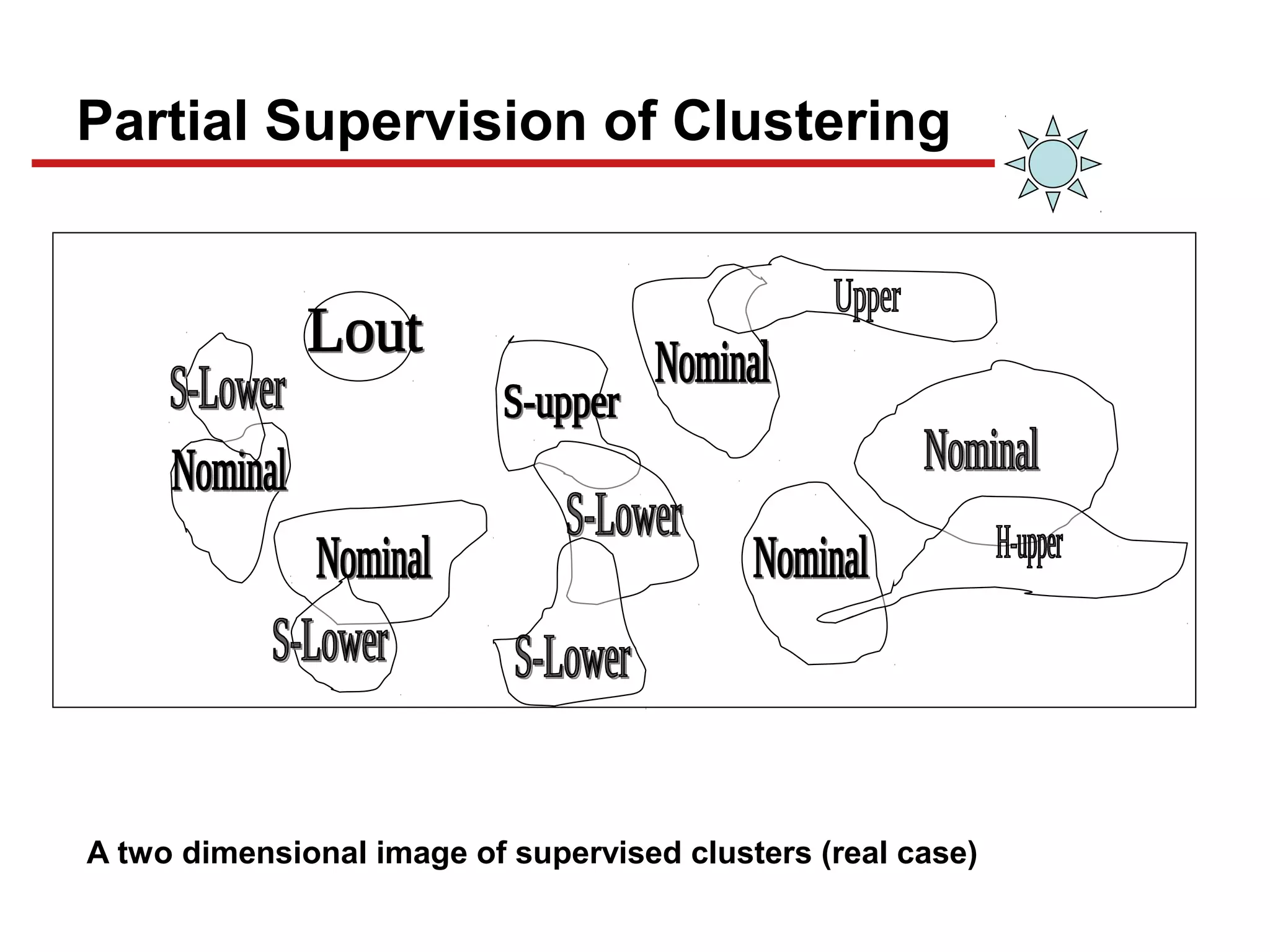
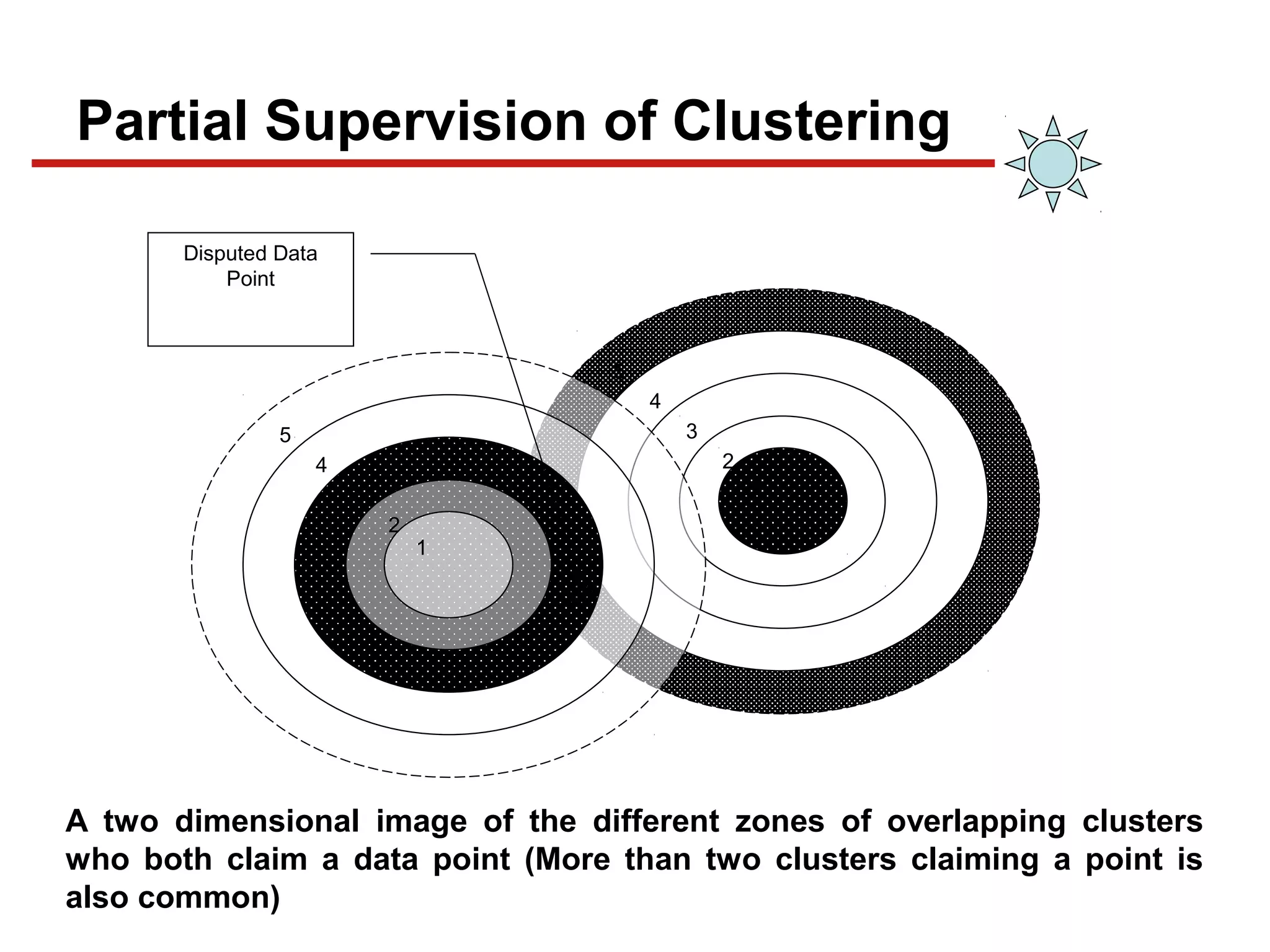
This document discusses unsupervised machine learning classification through clustering. It defines clustering as grouping similar items together with high intra-cluster similarity and low inter-cluster similarity. The document outlines common clustering algorithms like K-means and hierarchical clustering and discusses their applications in fields like marketing, astronomy, genomics. It also covers clustering evaluation methods and challenges like handling different data types and complex cluster shapes.









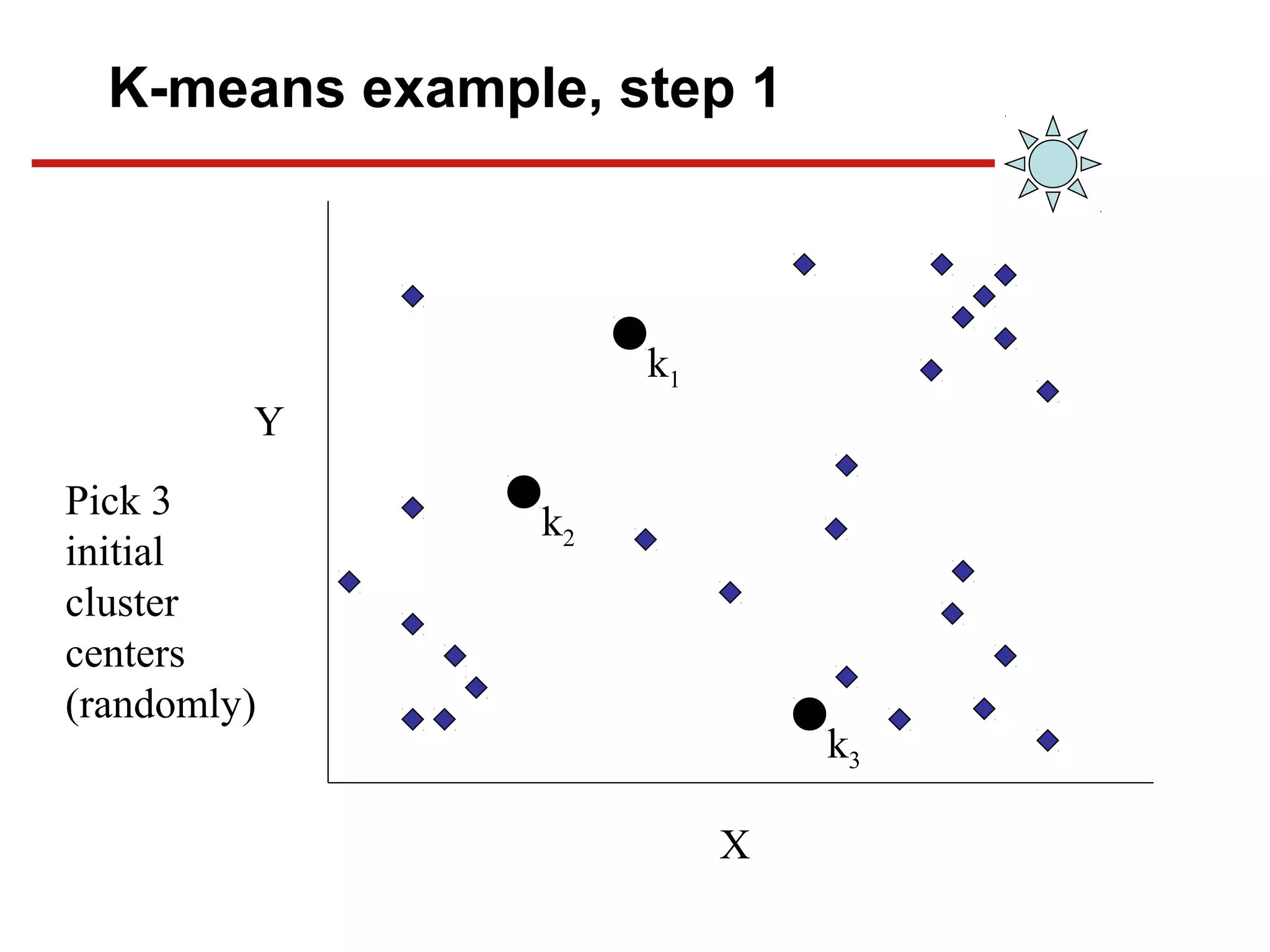
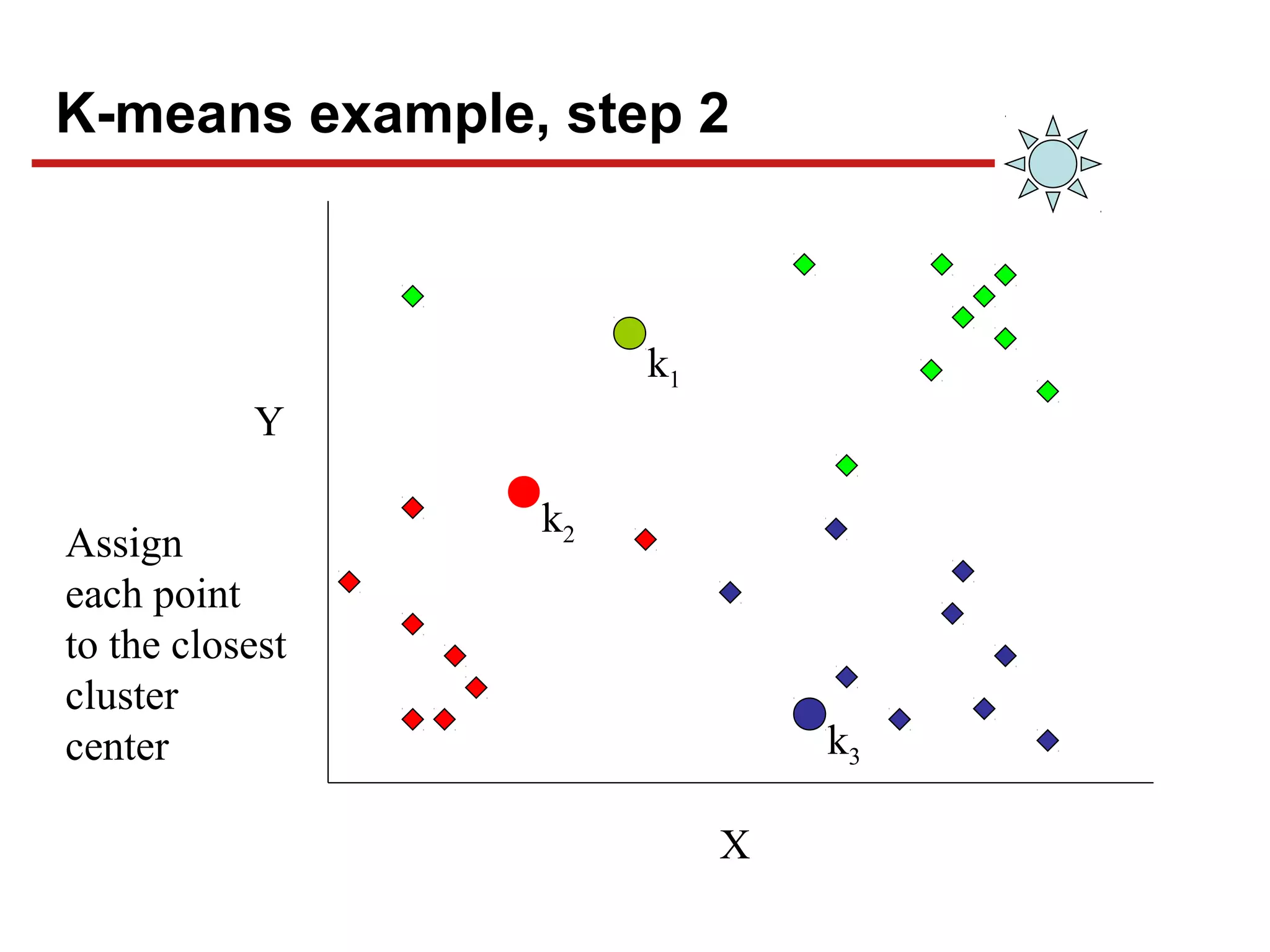
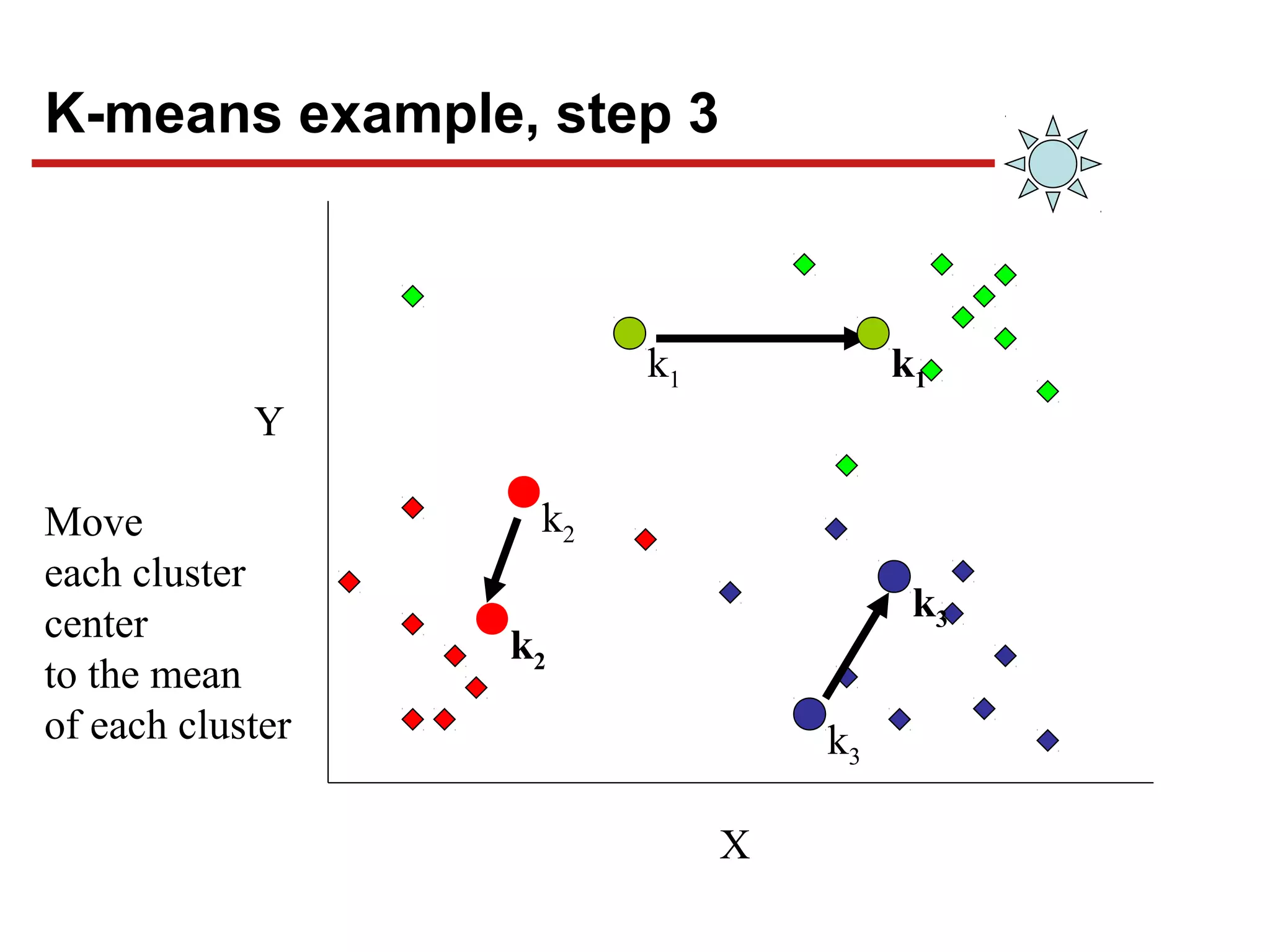
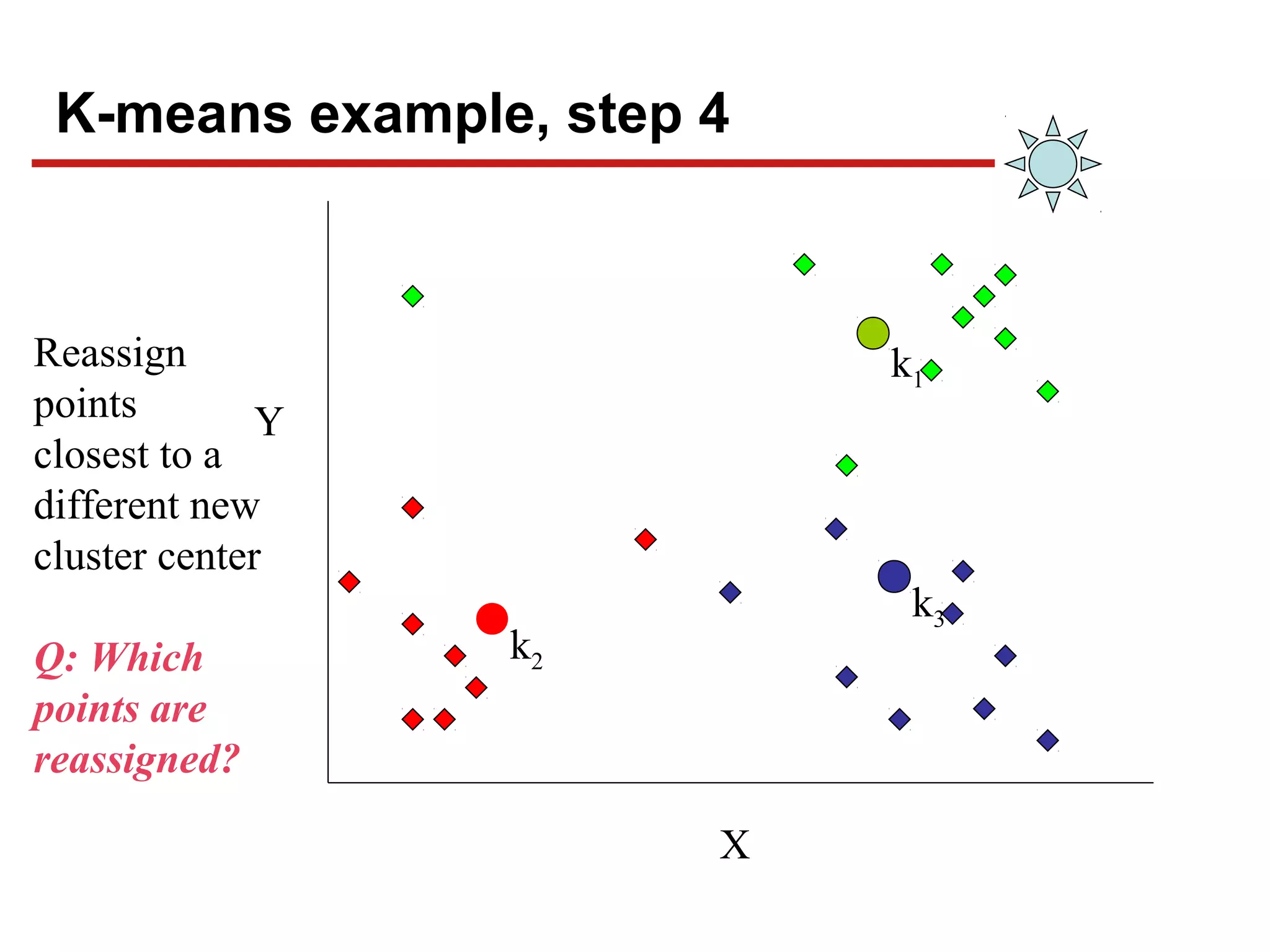



















![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)












![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)