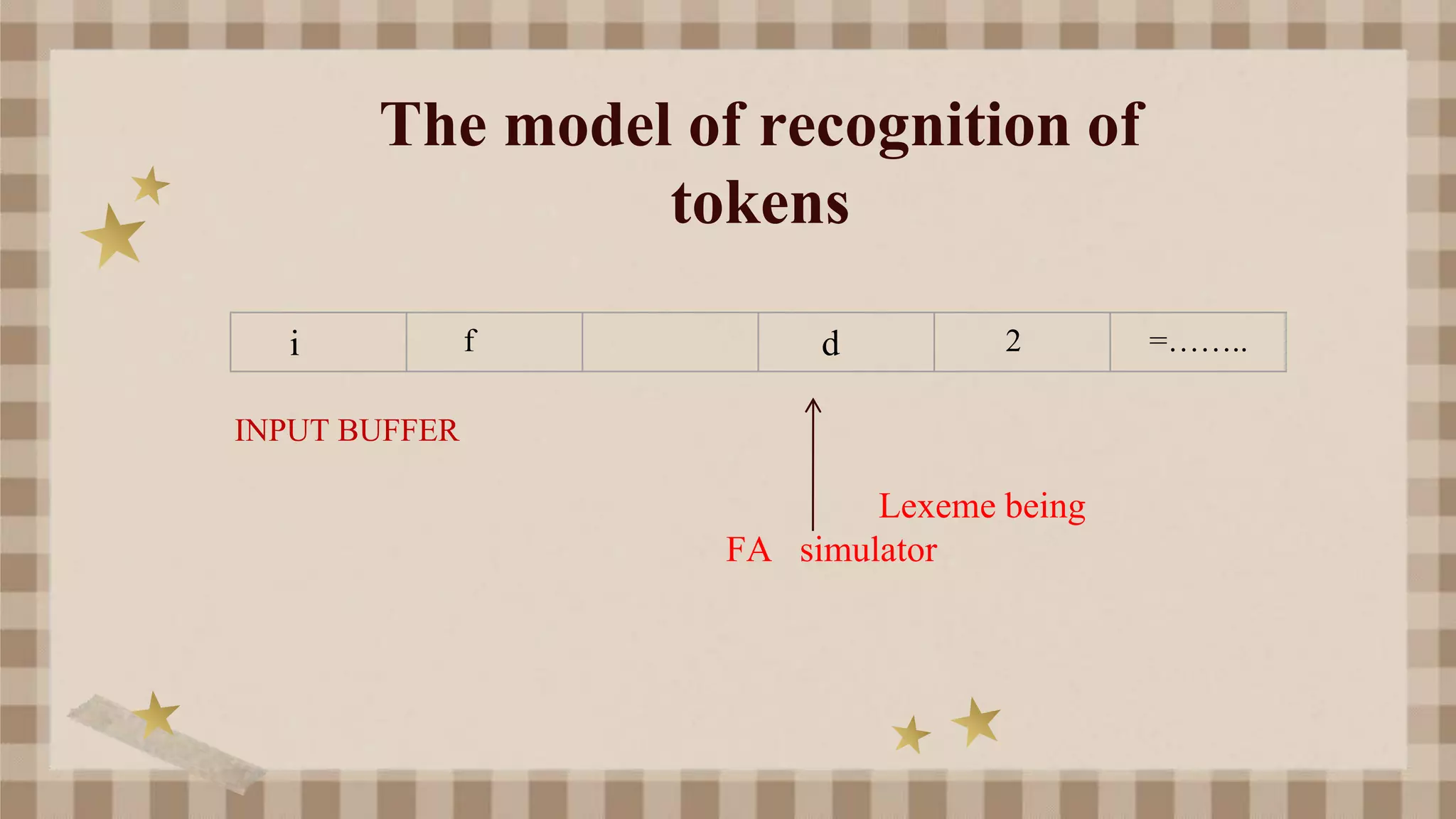
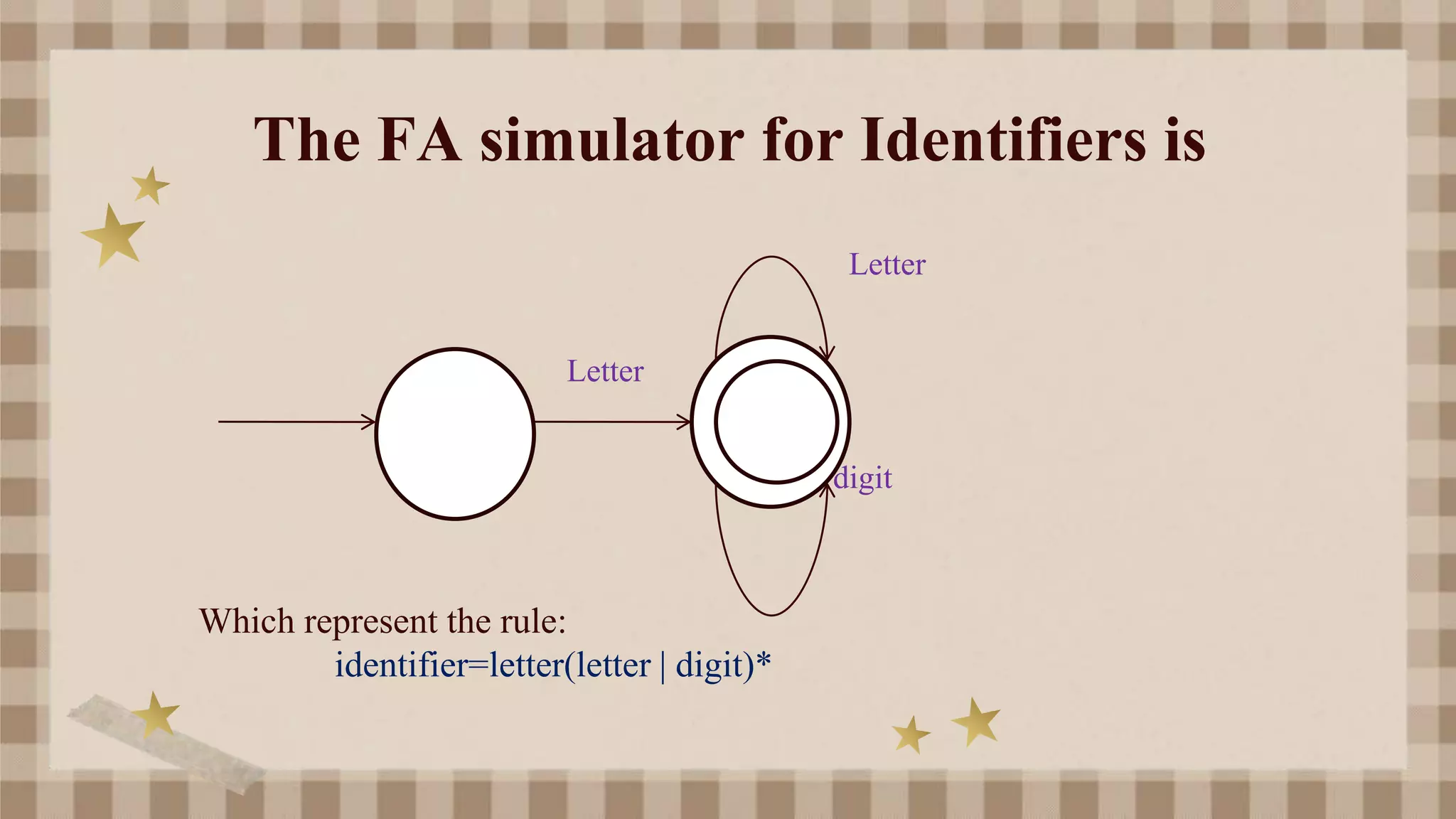
The document outlines a straightforward method for designing lexical analyzers, which involves creating token structure diagrams and converting them into token-finding programs. It discusses the use of regular expressions to specify tokens and the transition diagram for both deterministic and non-deterministic finite automata. Additionally, it covers the processes involved in lexical analysis, such as error message correlation and pattern matching techniques.









![Notational Short-hands
a)One or more instances
( r ) digit+
b)Zero or one instance
r? is a shorthand for r| (E(+|-)?digits)?
c)Character classes
[a-z] denotes a|b|c|…|z
[A-Za-z] [A-Za-z0-9]](https://image.slidesharecdn.com/asimpleapproachoflexicalanalyzers-211217053900/75/A-simple-approach-of-lexical-analyzers-10-2048.jpg)