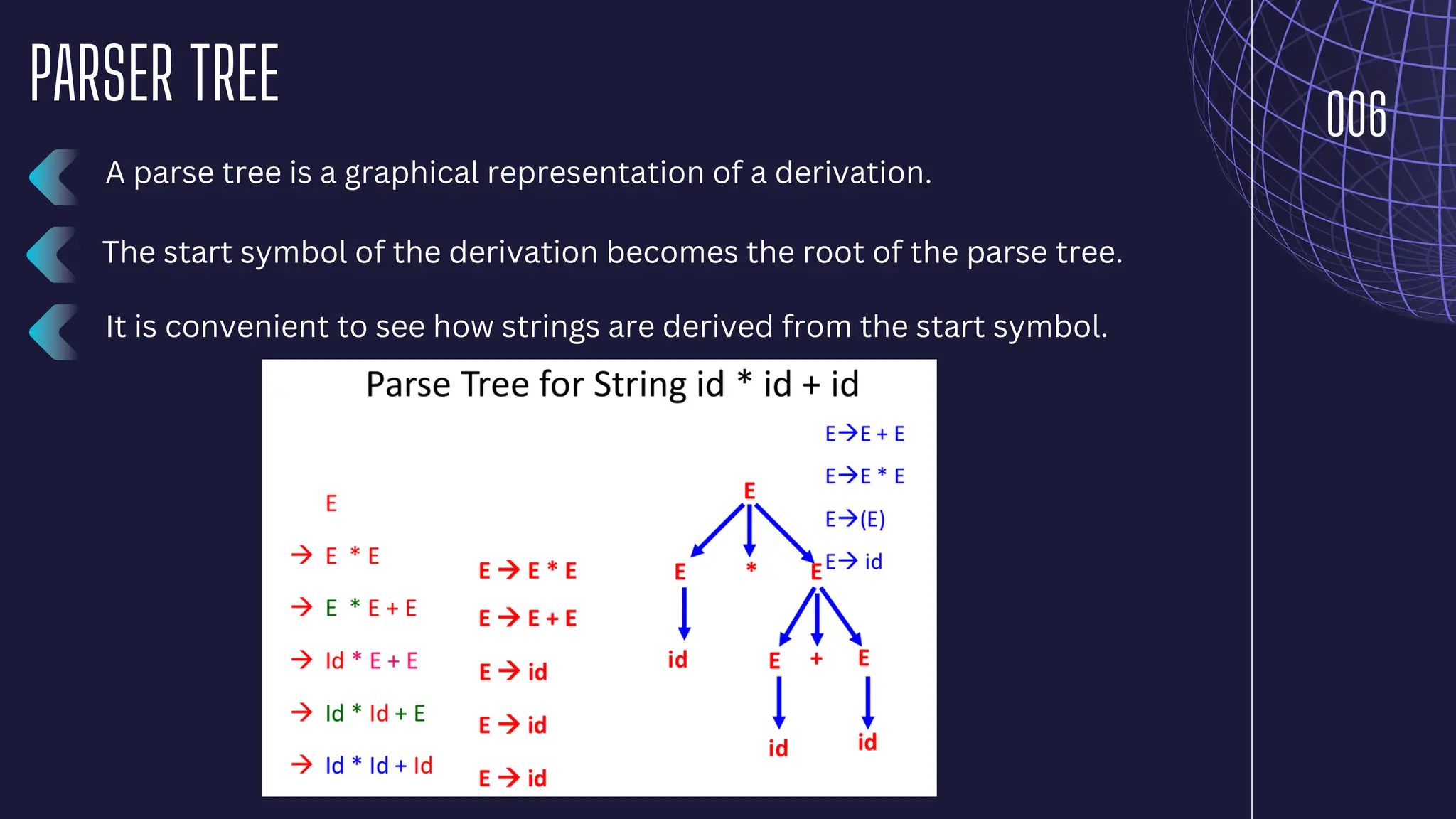
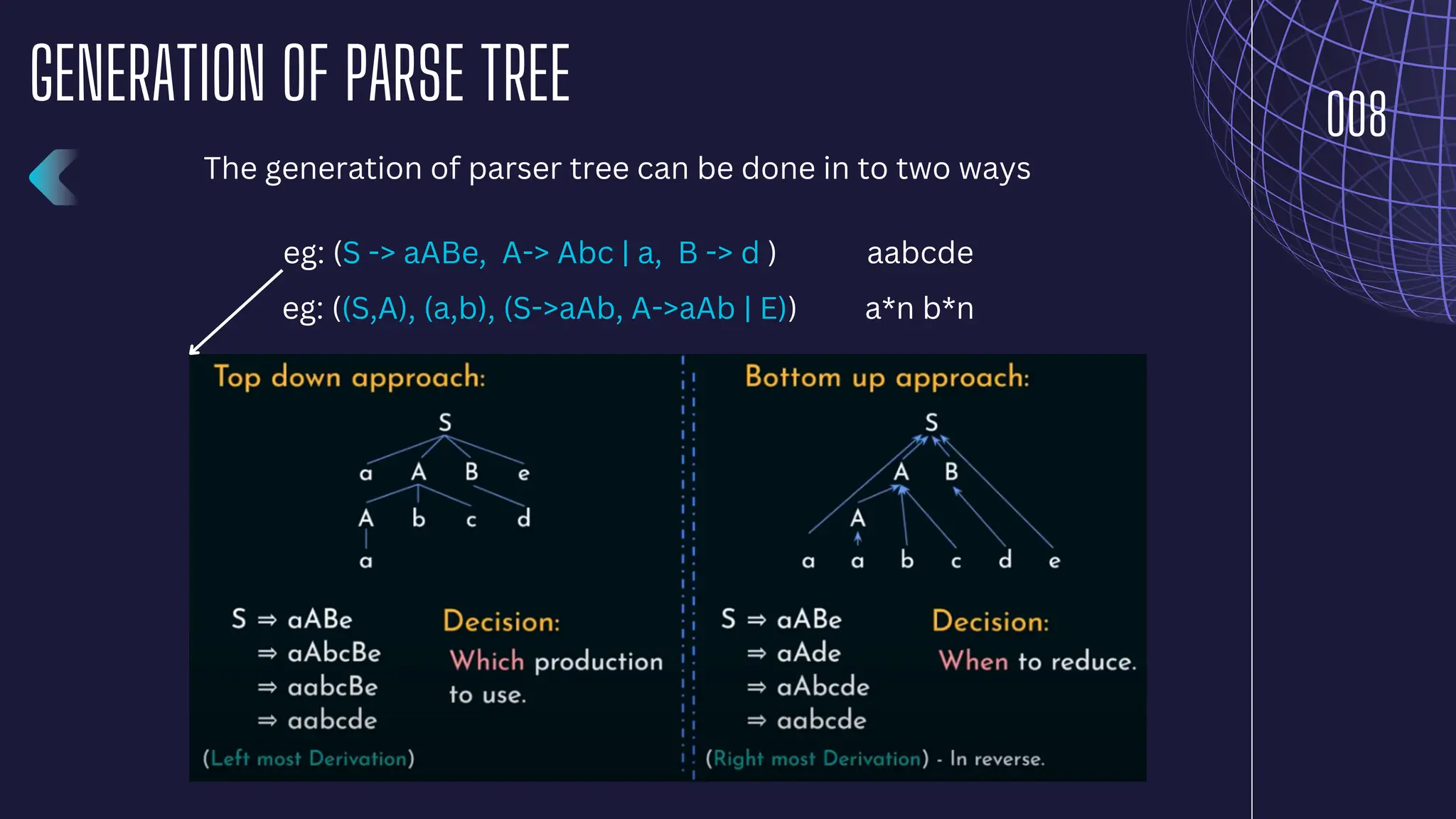
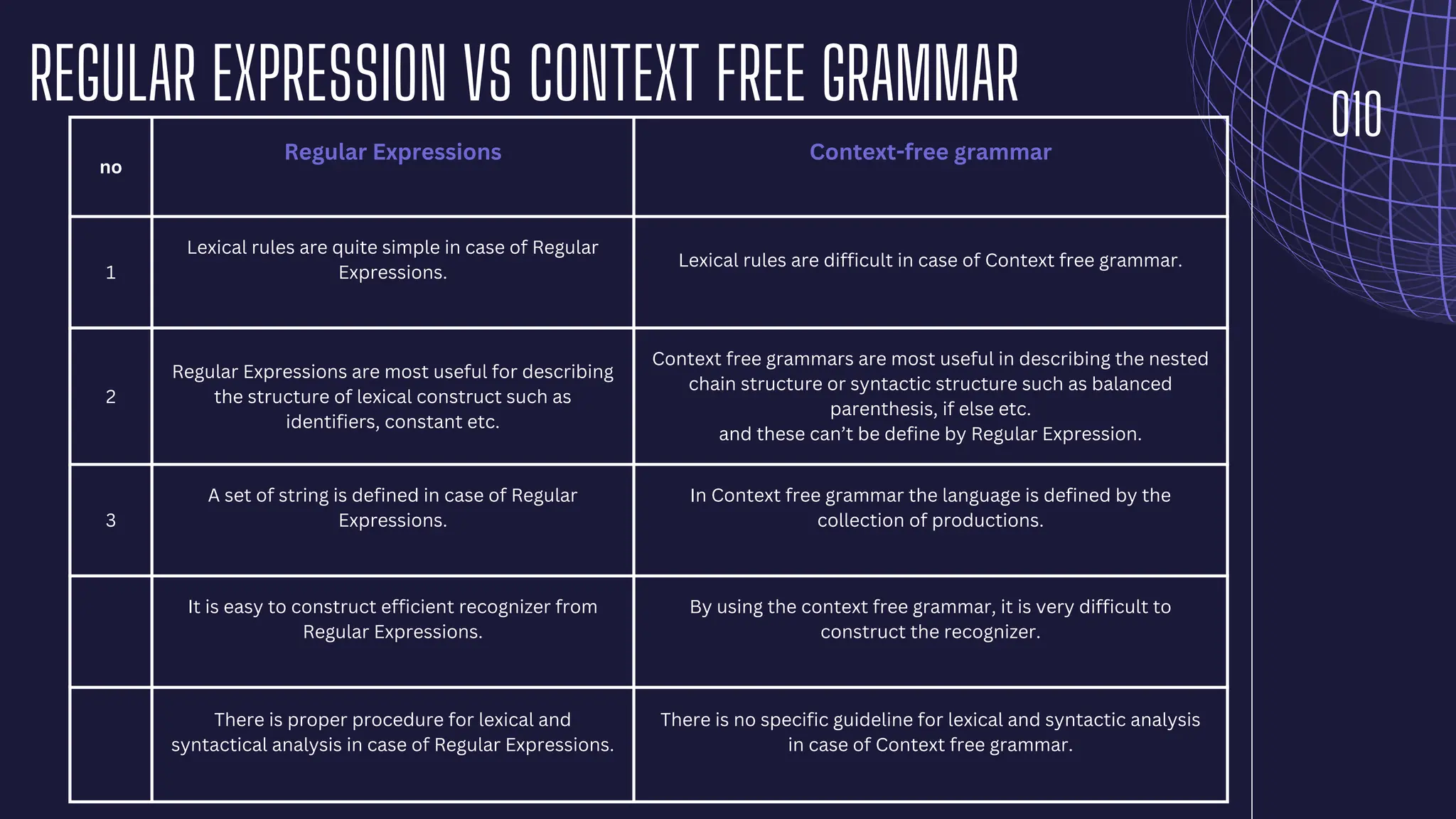
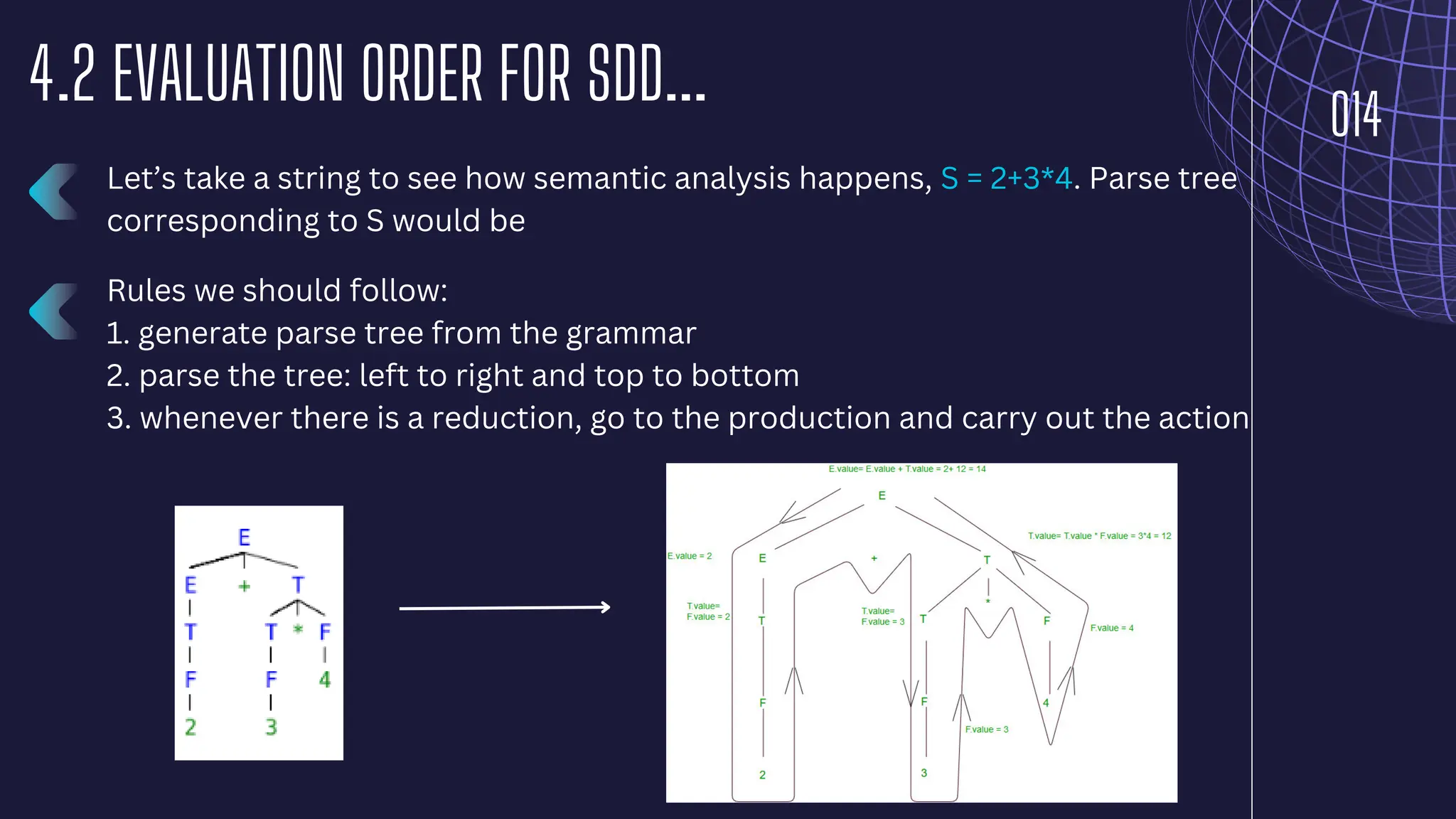
The document discusses parsing and syntax analysis in compiler design, detailing techniques like top-down and bottom-up parsing, the role of context-free grammar (CFG), and the generation of parse trees. It explains syntax-directed translation (SDT), describing the combination of grammar specifications with semantic actions for translation and validation of programs, and outlines types of attributes used in parsing. Additionally, it contrasts regular expressions with context-free grammars in terms of their utility in defining lexical and syntactic structures.