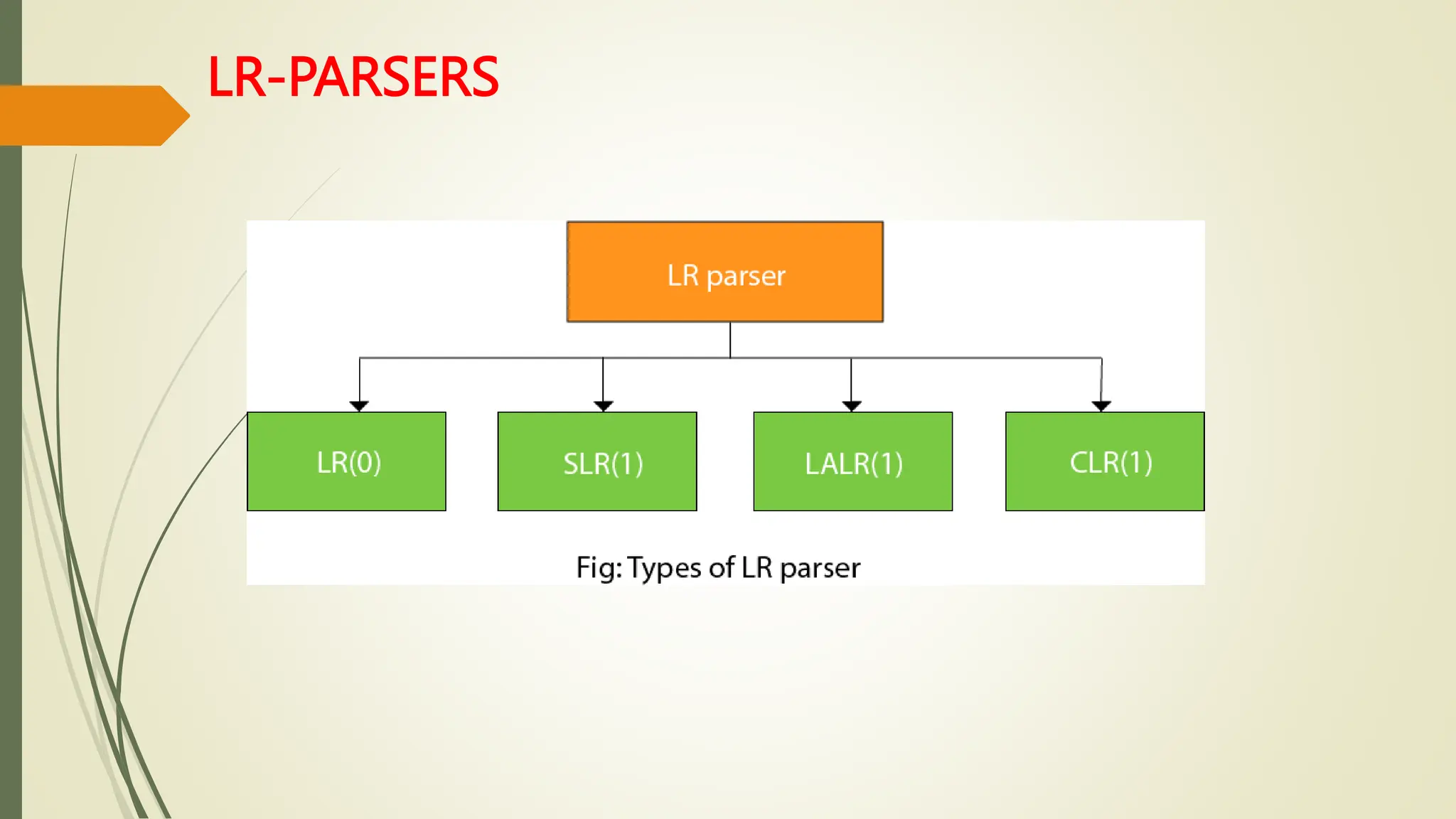
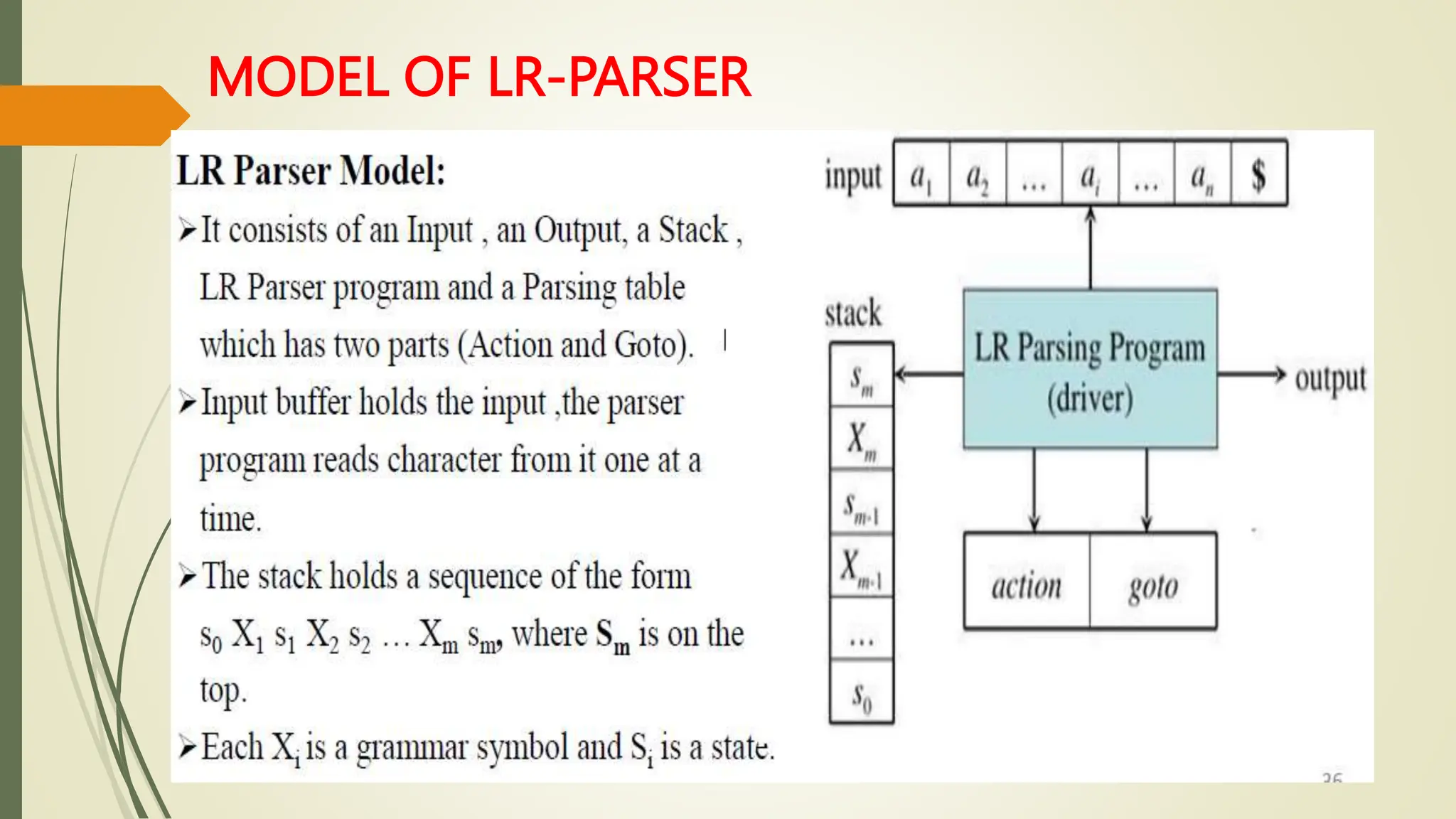
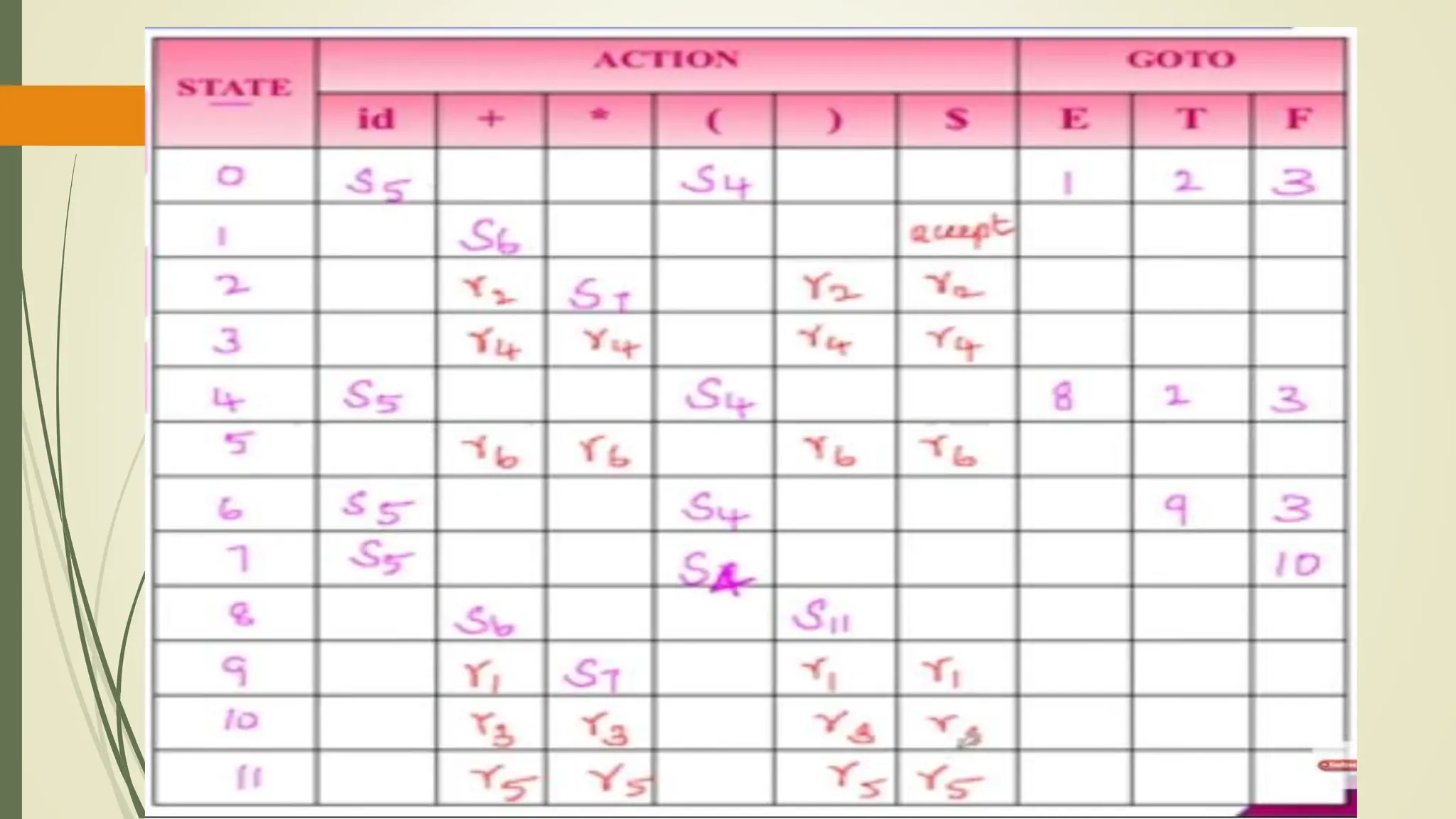
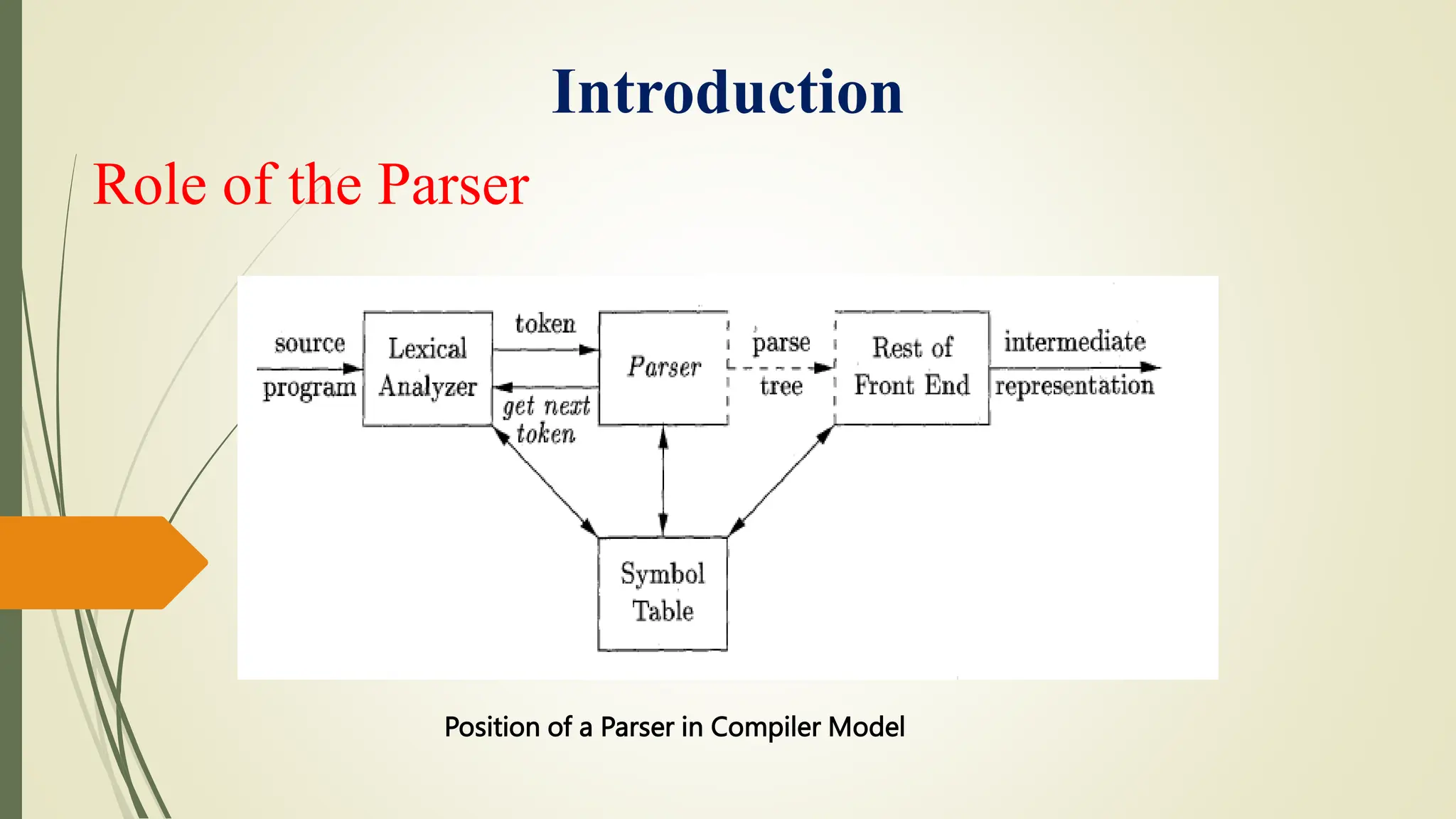
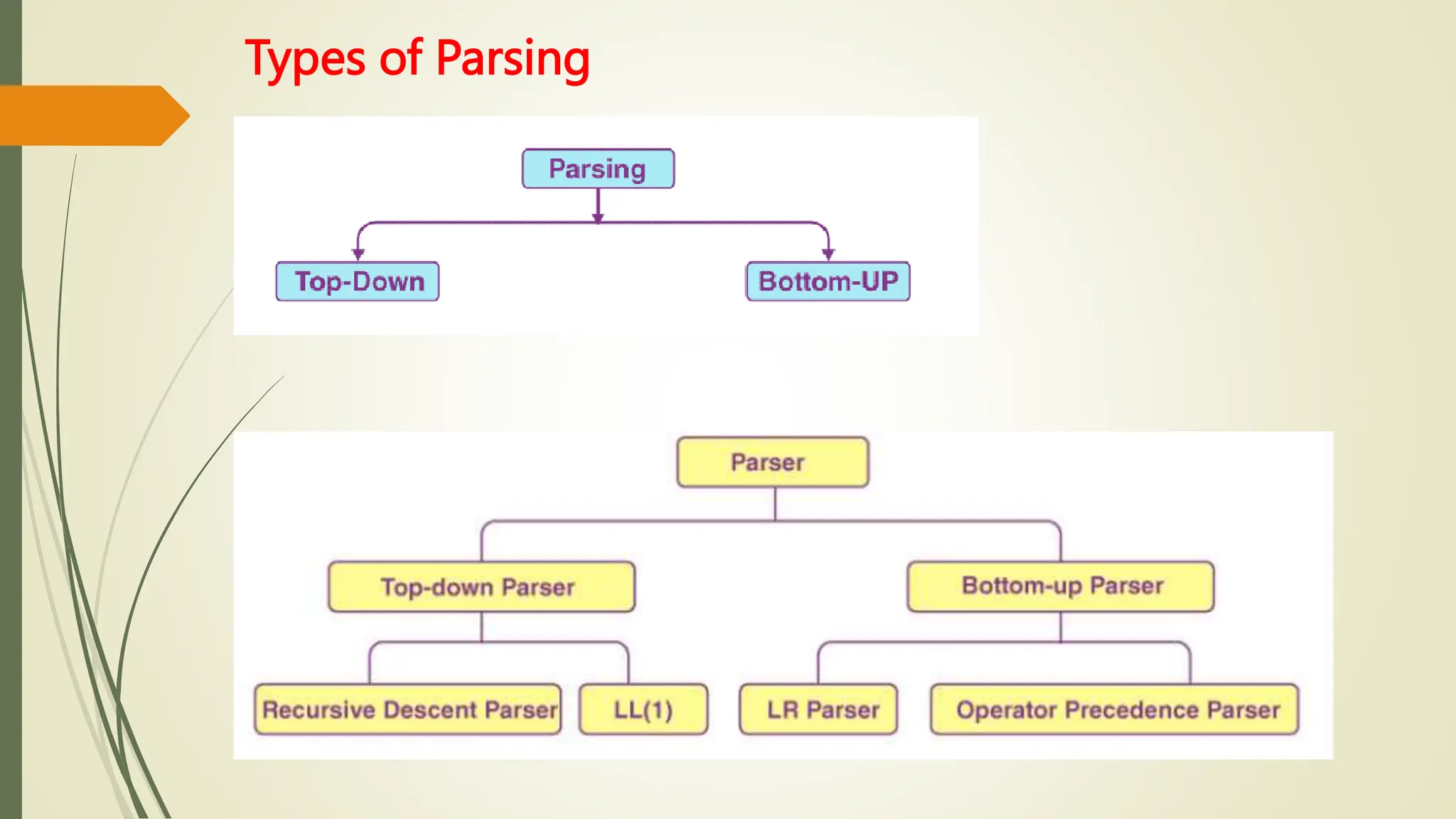
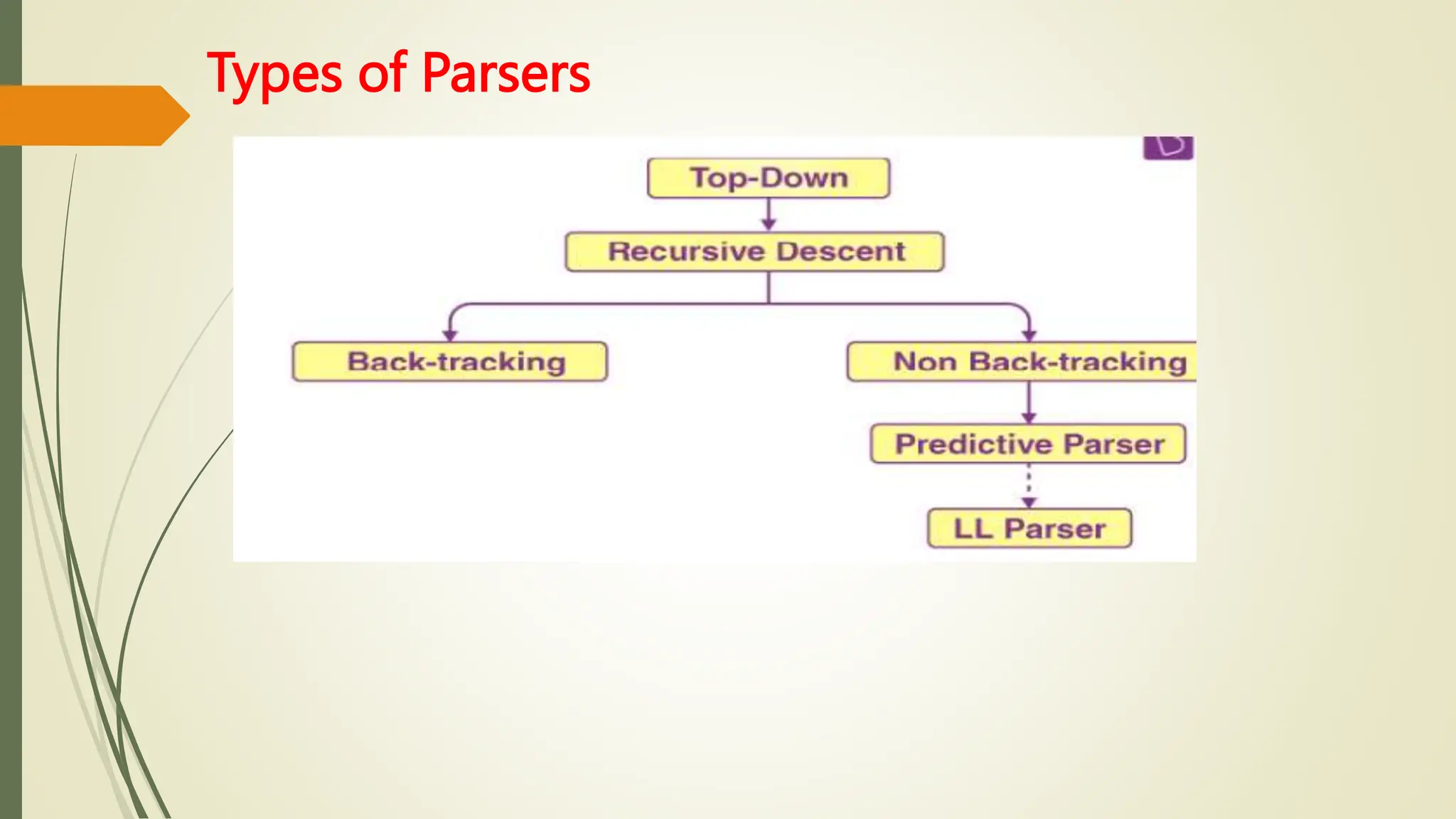
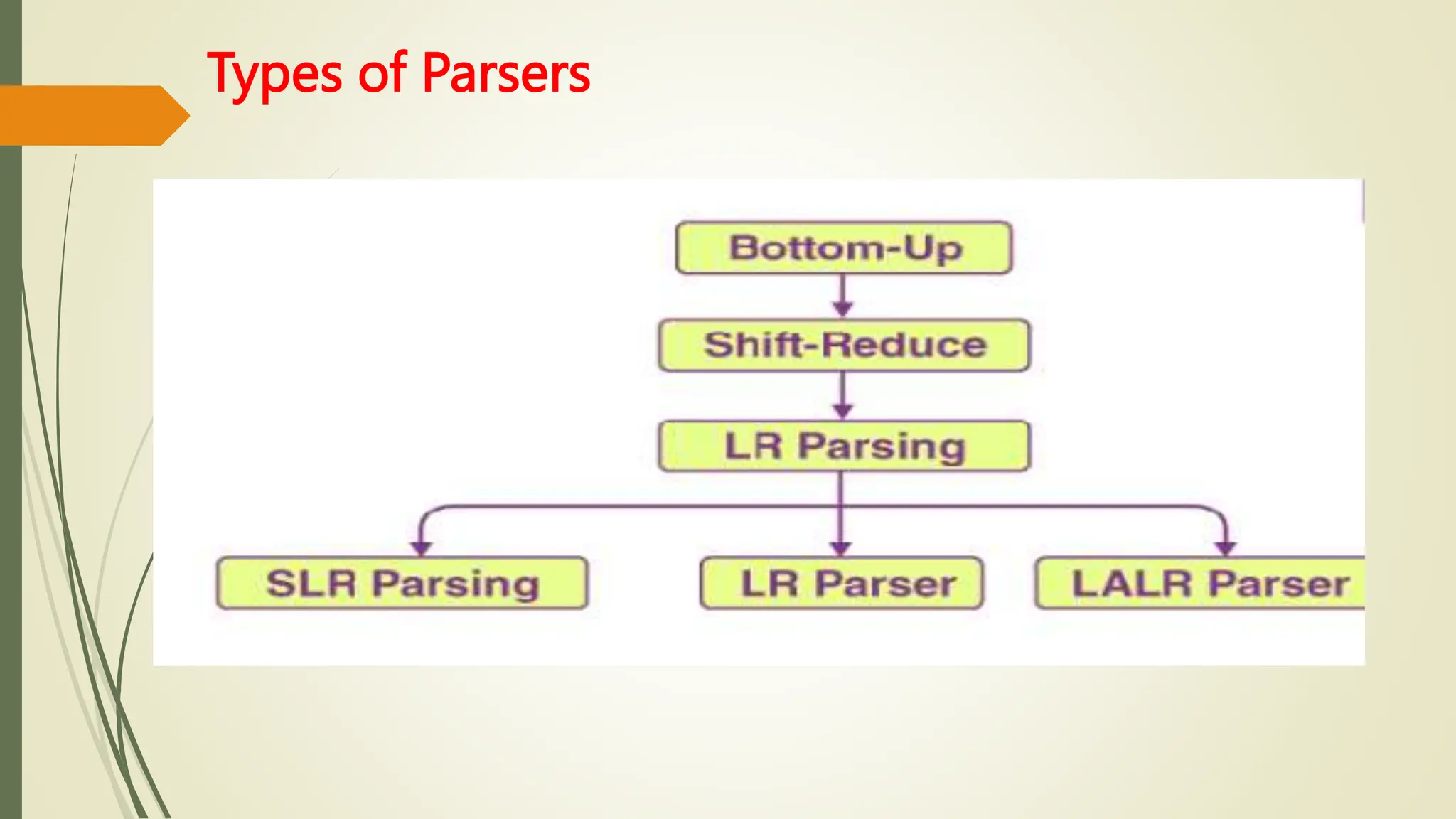
This document provides an overview of syntax analysis, a key phase in compiler design, explaining the roles and types of parsers, as well as error handling strategies during parsing. It outlines the formal definition of context-free grammars and the distinction between context-free grammars and regular expressions in describing programming languages. Additionally, it discusses the methods of parsing including top-down and bottom-up approaches, and various parser types, particularly highlighting the advantages and limitations of LR parsers.





















































































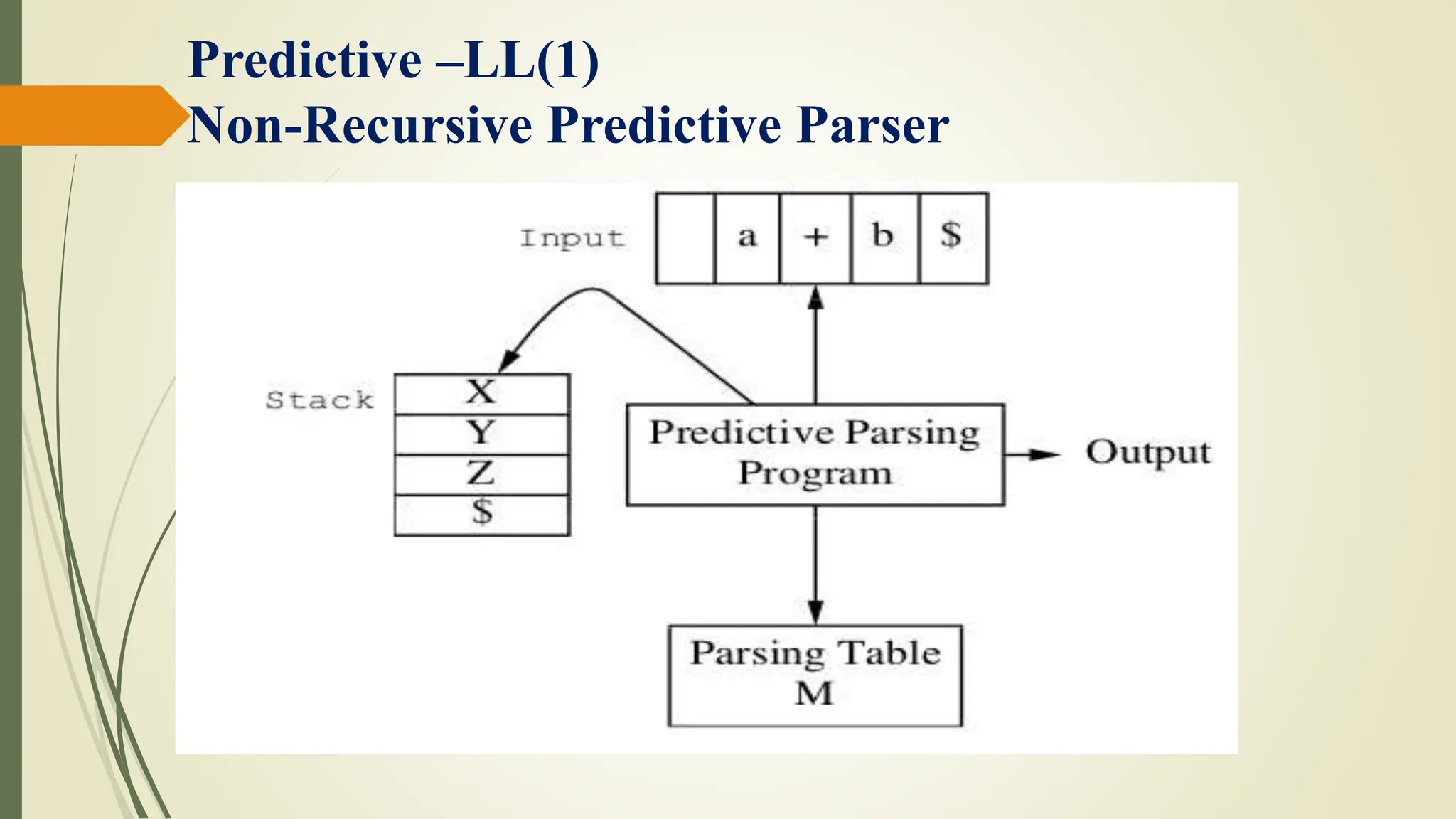

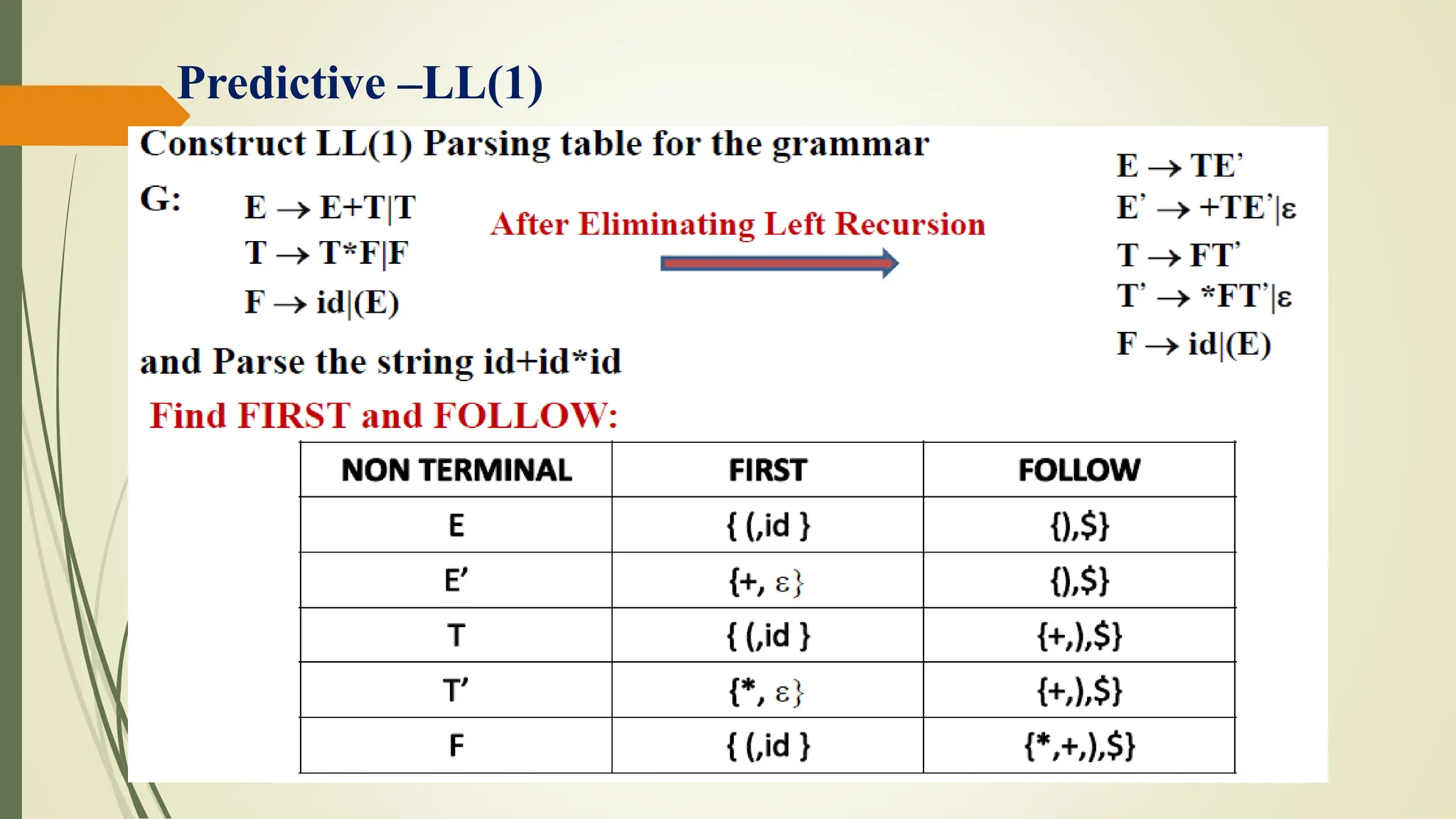
![Predictive –LL(1)
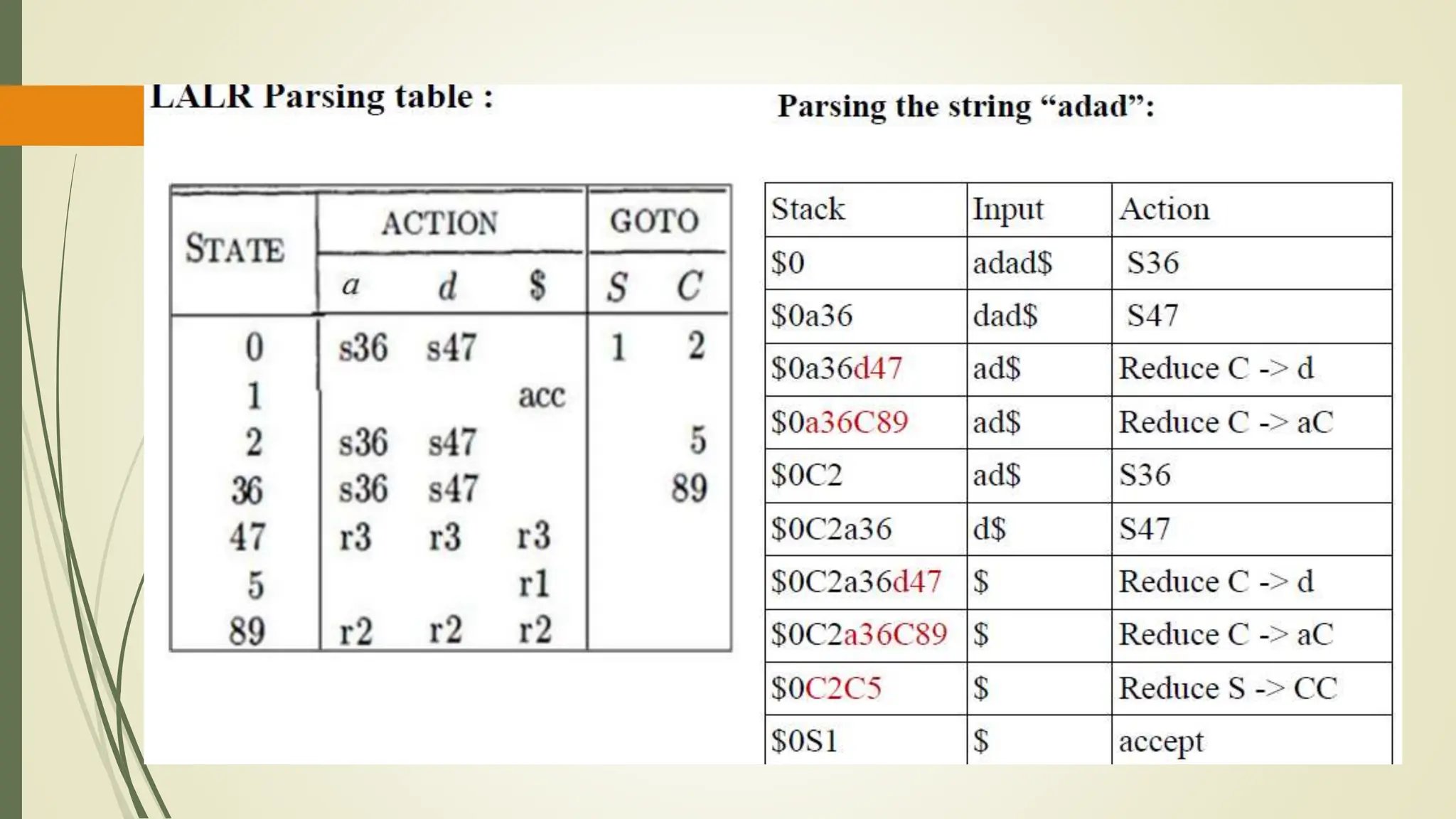
The parsing table is a two dimensional array M[A ,a], where A is
a nonterminal, and a is a terminal or the symbol $.
The parser is controlled by a program that behaves as follows:
The program determines X, the symbol on top of the stack, and a
the current input symbol.
These two symbols determine the action of the parser.](https://image.slidesharecdn.com/cd-unit-2st-240509013051-1b0c4217/75/COMPILER-DESIGN-LECTURES-UNIT-2-ST-pptx-92-2048.jpg)

![If X is a nonterminal, the program consults entry M[X, a] of the
parsing table M.
This entry will be either an X-production of the grammar or an
error entry.
If M[X, a] = {X → UVW}, the parser replaces X on top of the
stack by WVU (with U on top).
If M[X, a] = error, the parser calls an error recovery routine
Predictive –LL(1)](https://image.slidesharecdn.com/cd-unit-2st-240509013051-1b0c4217/75/COMPILER-DESIGN-LECTURES-UNIT-2-ST-pptx-94-2048.jpg)