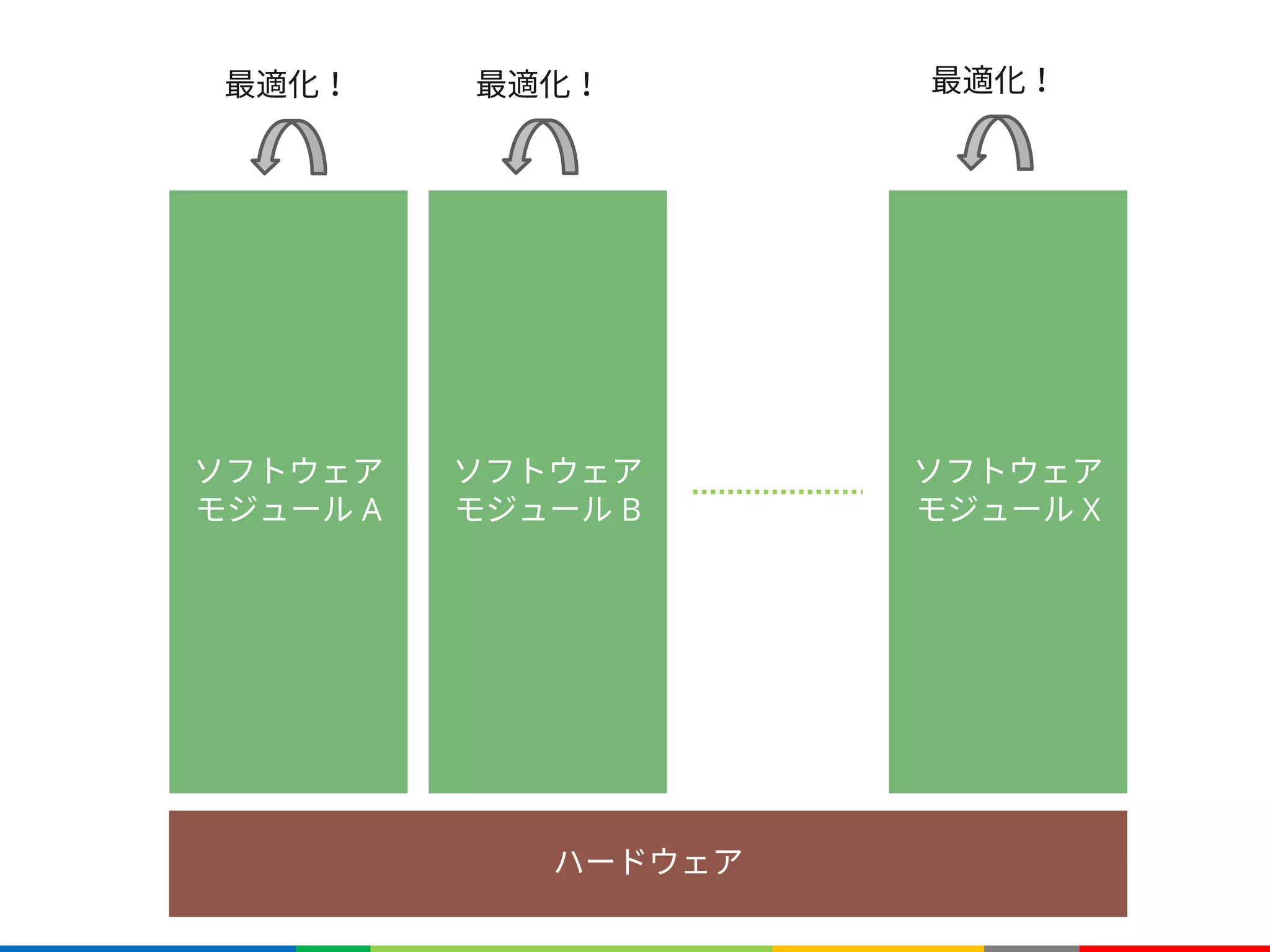
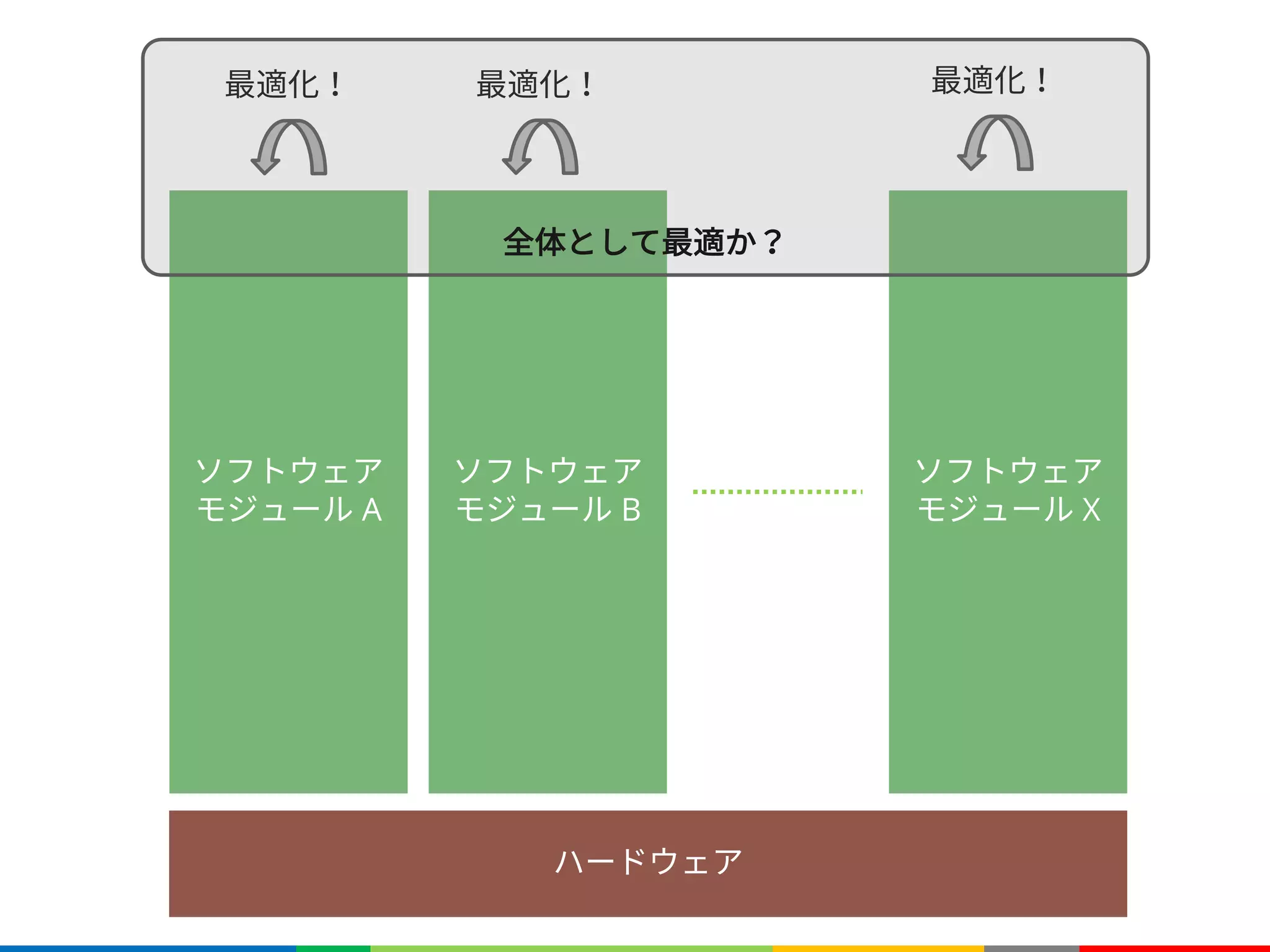
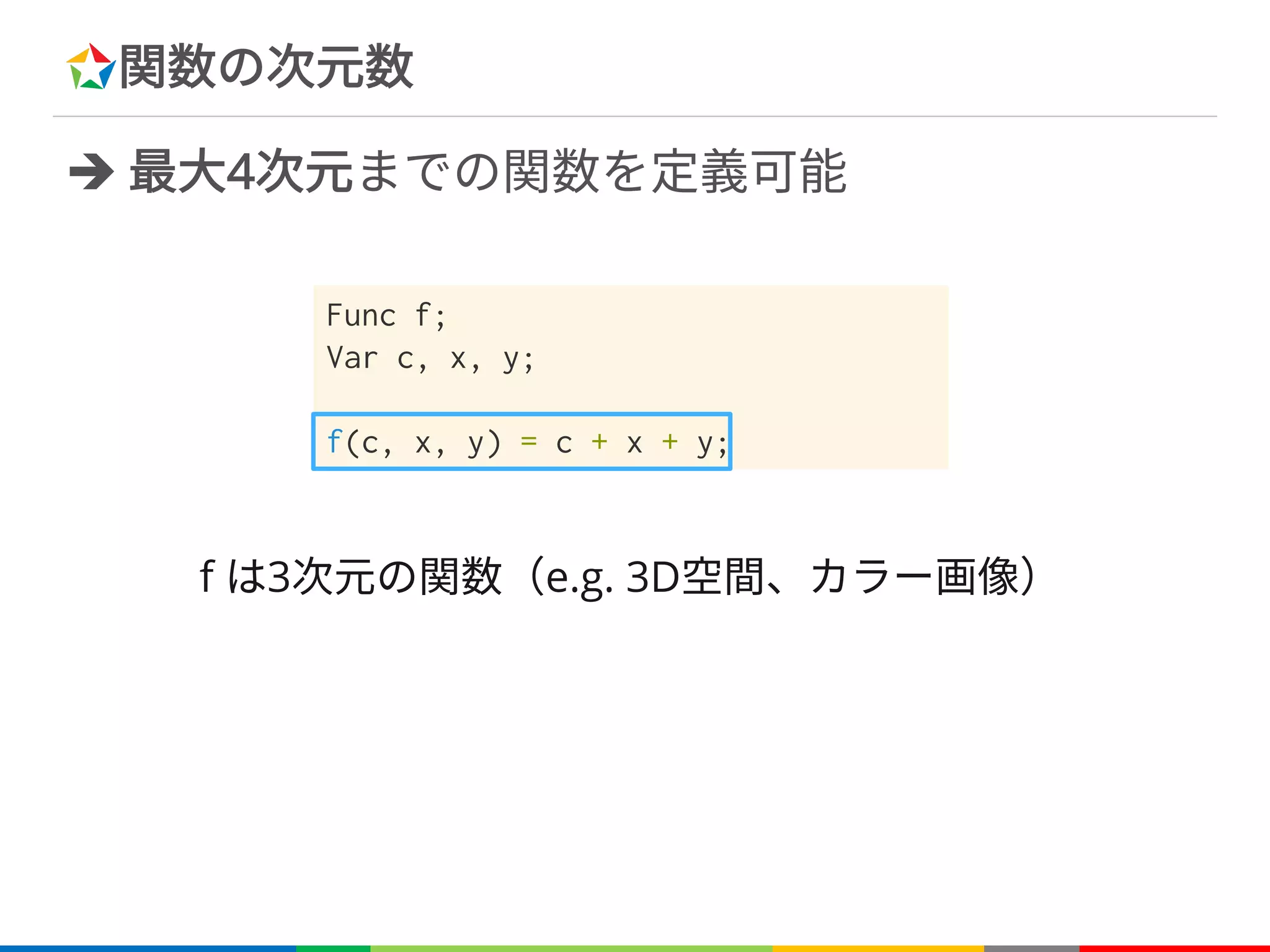
関数の次元数
è 最大4次元までの関数を定義可能
f は3次元の関数(e.g.3D空間、カラー画像)
f は4次元の関数
Func f;
Var c, x, y;
f(c, x, y) = c + x + y;
Func f;
Var c, x, y, z;
f(c, x, y, z) = c + x + y + z;
37.
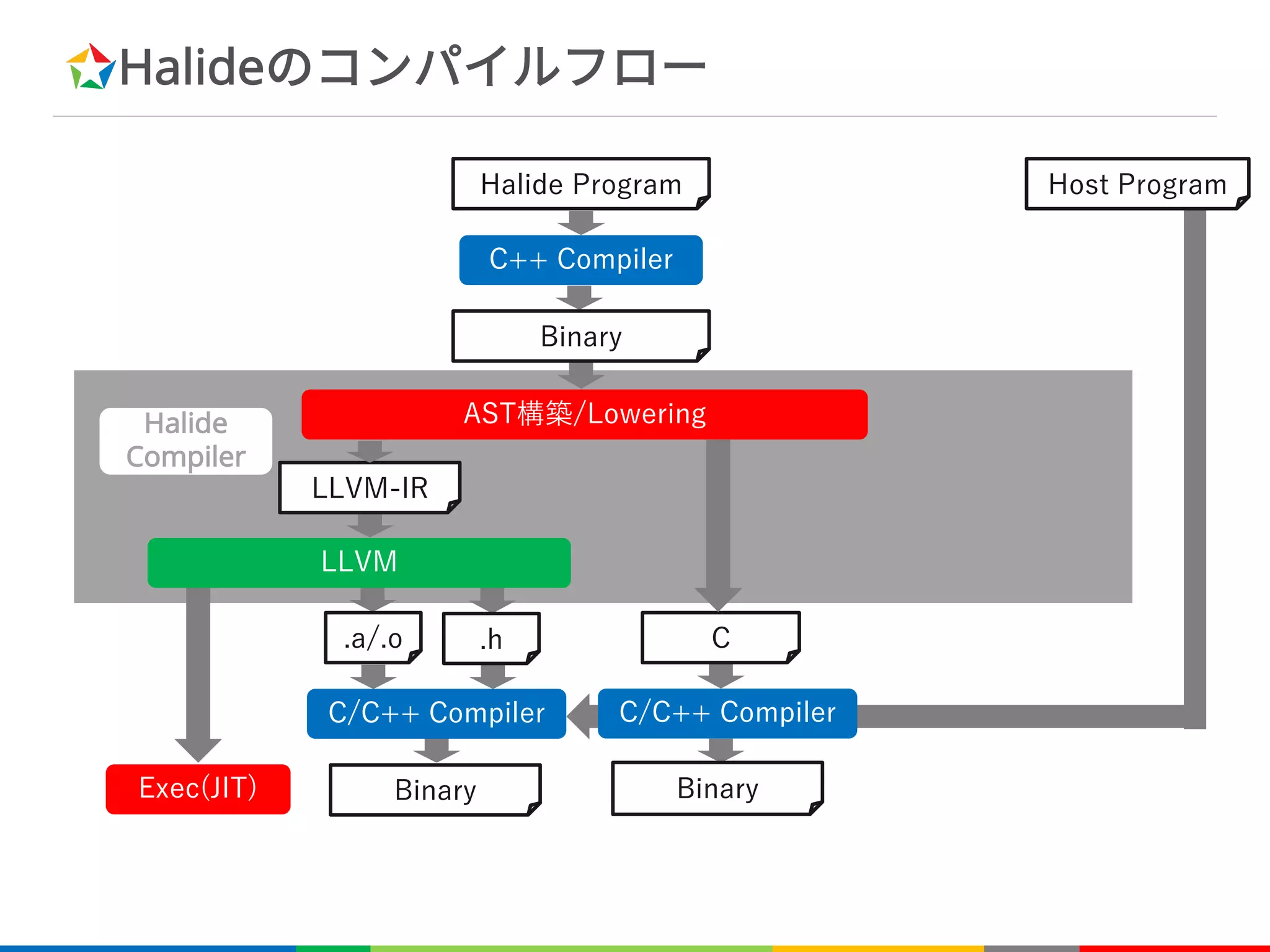
関数の参照
è 関数の右辺に定義された関数への参照
– 関数合成が可能
意味:関数 f2 は定義域 x, y に対して f1(x+y) を値域に持つ
Var x, y;
Func f1;
f1(x, y) = x + y;
Func f2;
f2(x, y) = f1(x, y);
Var x, y;
Func f2;
f2(x, y) = x + y;
38.
式
è 式はExpr型の変数として表される
– 関数:Func
– 誘導変数: Var
– 式: Expr
組み立てた計算式を、式としてとっておくことが出来る
Var x, y;
Expr e = x + y;
Func f;
f(x, y) = e;
Var x, y;
Func f;
f(x, y) = x + y;
39.
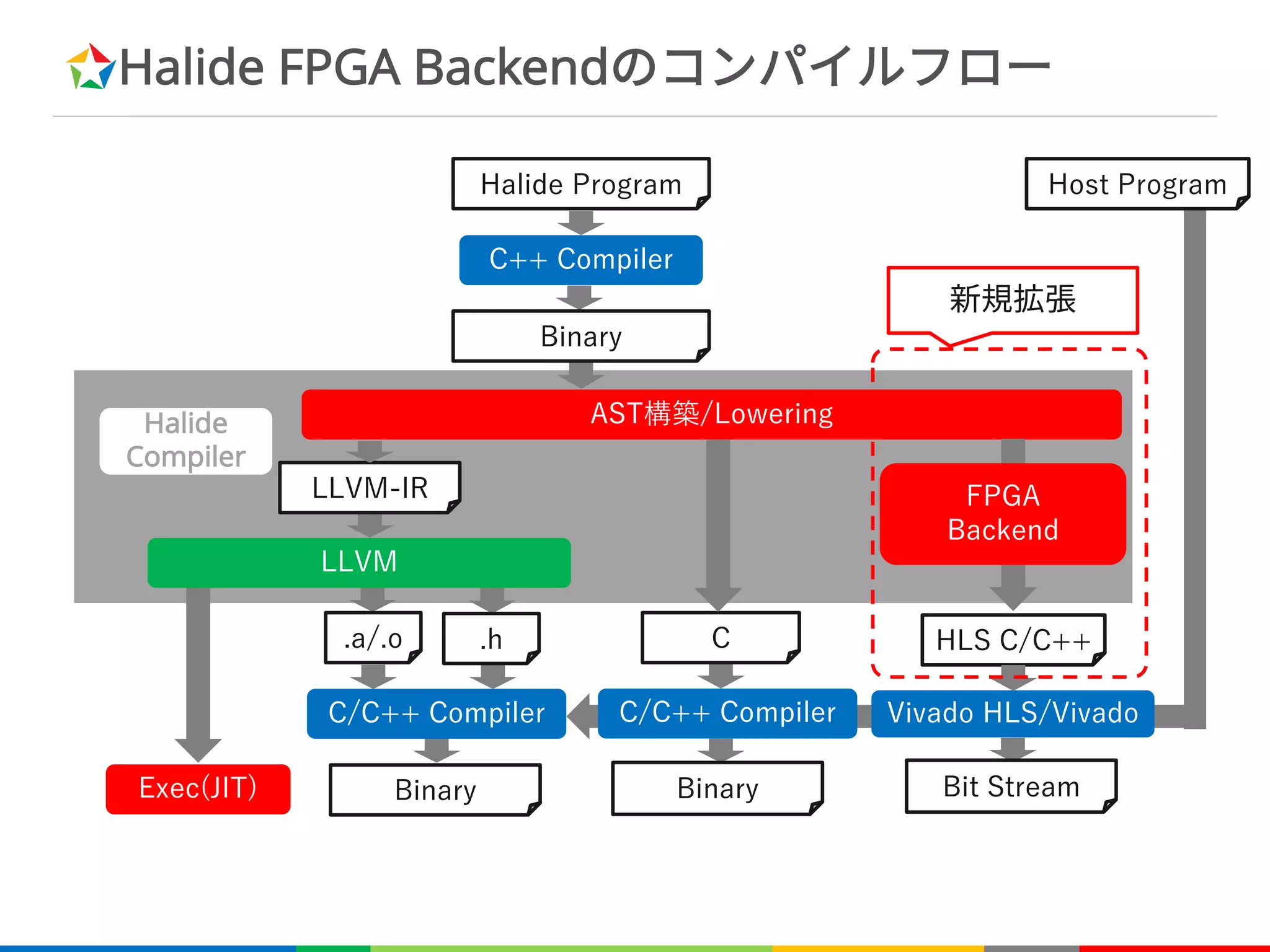
RDomと畳み込み関数
è 畳み込みを表すためのプリミティブ
– リダクションドメイン:RDom
– RDom(min, extent)
• 指定された次元で[min, min+extent-1]の領域を畳み込み
等価なC++ソースコード
rxは[-1, 1]を動く誘導変数
Var x;
Func f;
f(x) = x;
RDom rx(-1, 3);
Func g;
g(x) = sum(f(x + rx));
for (int x=0; x<width; x++) {
T sum = 0;
for (int rx=-1; rx<2; rx++) {
sum += x + rx;
}
g[x] = sum;
}
+
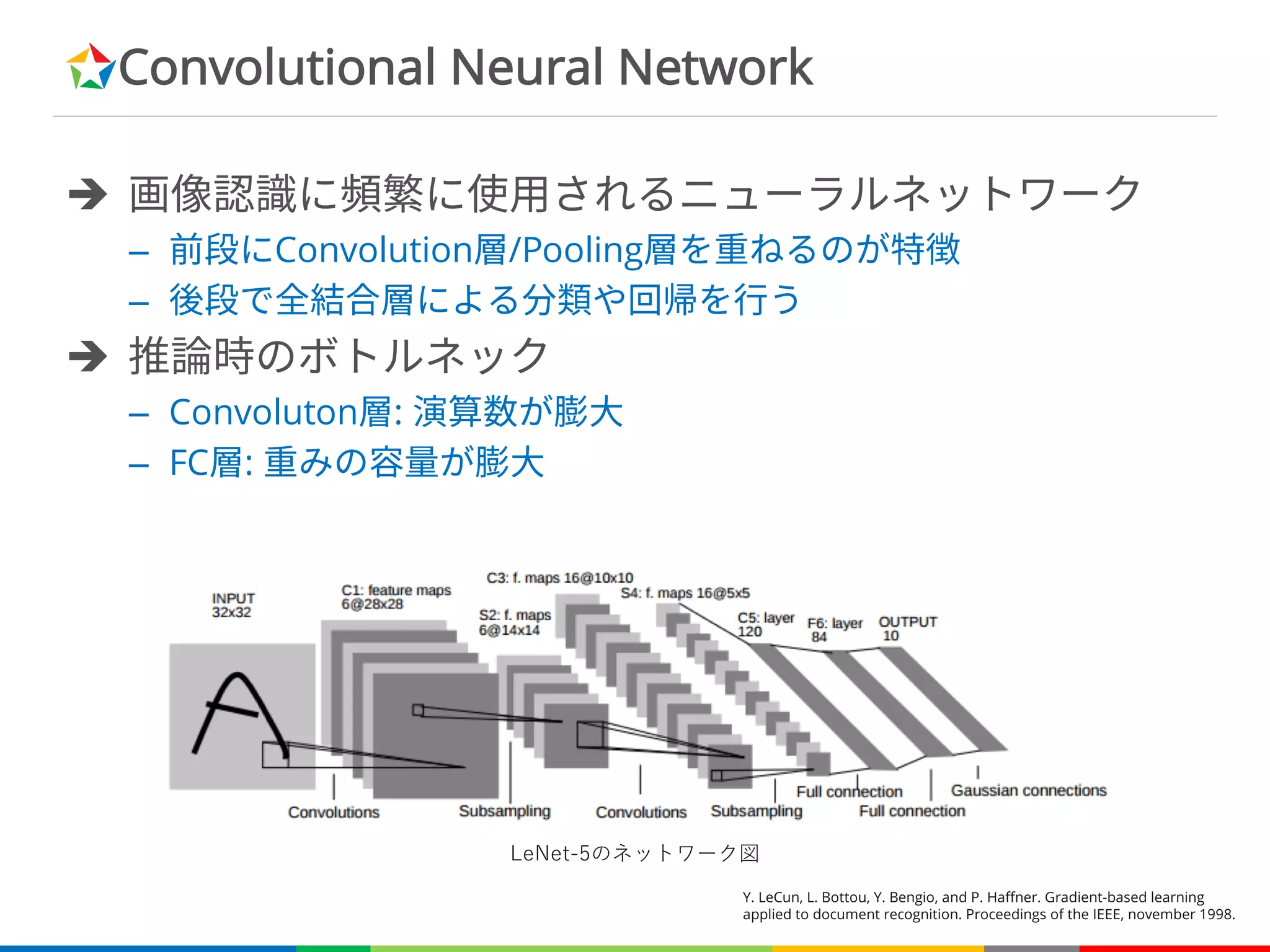
Convolutional Neural Network
è画像認識に頻繁に使用されるニューラルネットワーク
– 前段にConvolution層/Pooling層を重ねるのが特徴
– 後段で全結合層による分類や回帰を行う
è 推論時のボトルネック
– Convoluton層: 演算数が膨大
– FC層: 重みの容量が膨大
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning
applied to document recognition. Proceedings of the IEEE, november 1998.
FPGA向けアルゴリズム最適化: Log-based Quantization[2]
è初段・最終段のConv/FC層
–二値化すると精度の低下が激しい
è初段・最終段のConv/FC層の入力と重みを
対数量子化
– ラインバッファ・重みの容量を削減
– 積算がシフト演算で計算可能
• 今回はlog2-baseで量子化
Dataset Network
Accuracy
fixed-32 2-base log2-base
MNIST LeNet-5 98% 95% 98%
CIFAR-10 NIN 89% 66% 82%
[2] Miyashita, D. et al., “Convolutional Neural Networks using Logarithmic Data Representation”, https://arxiv.org/abs/1603.01025
61.
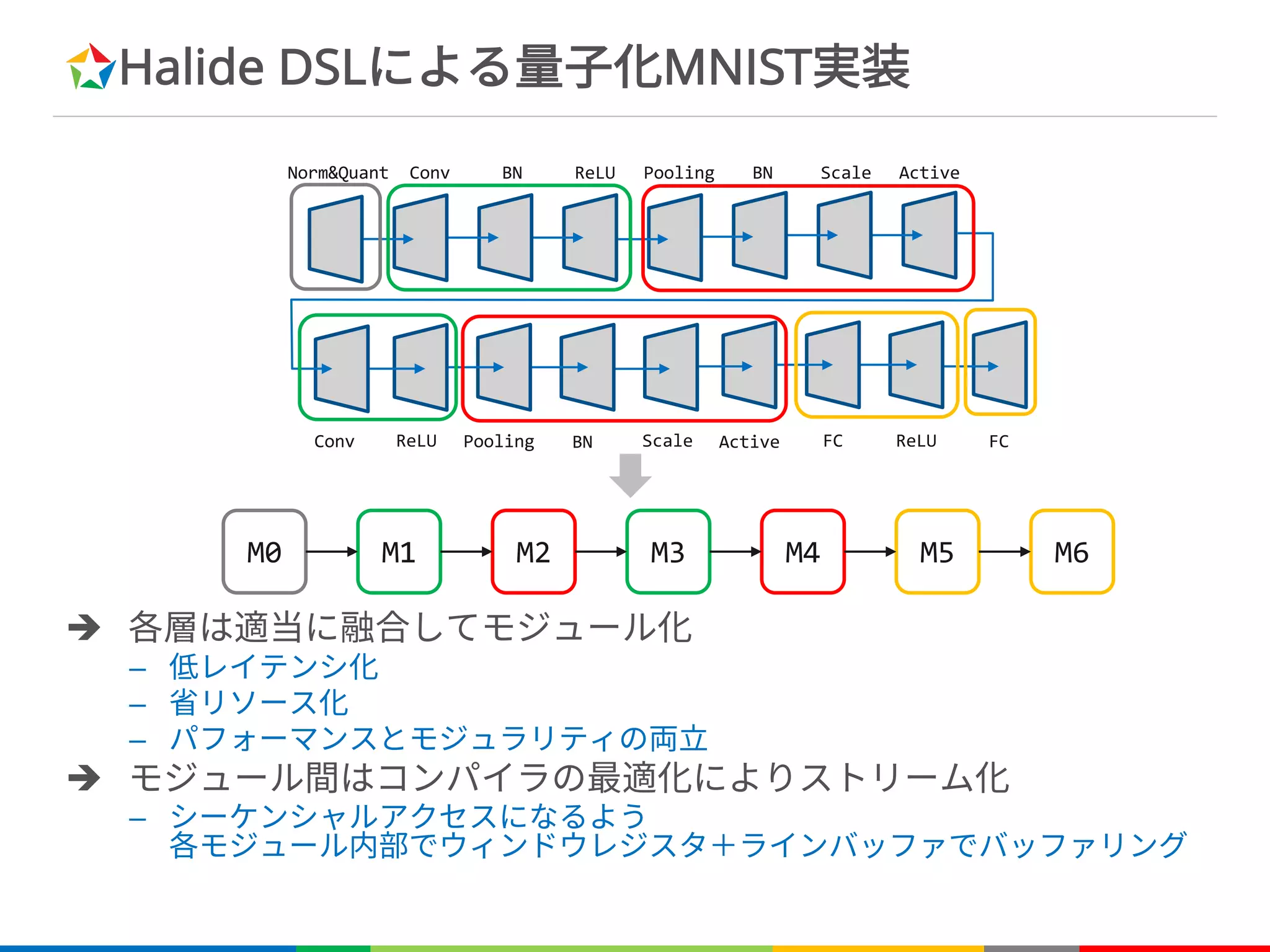
Halide DSLによる量子化MNIST実装
è 各層は適当に融合してモジュール化
–低レイテンシ化
– 省リソース化
– パフォーマンスとモジュラリティの両立
è モジュール間はコンパイラの最適化によりストリーム化
– シーケンシャルアクセスになるよう
各モジュール内部でウィンドウレジスタ+ラインバッファでバッファリング
Norm&Quant Conv BN ReLU Pooling BN
Conv ReLU Pooling
Scale Active
BN Scale Active FC ReLU FC
M0 M1 M2 M3 M4 M5 M6
62.
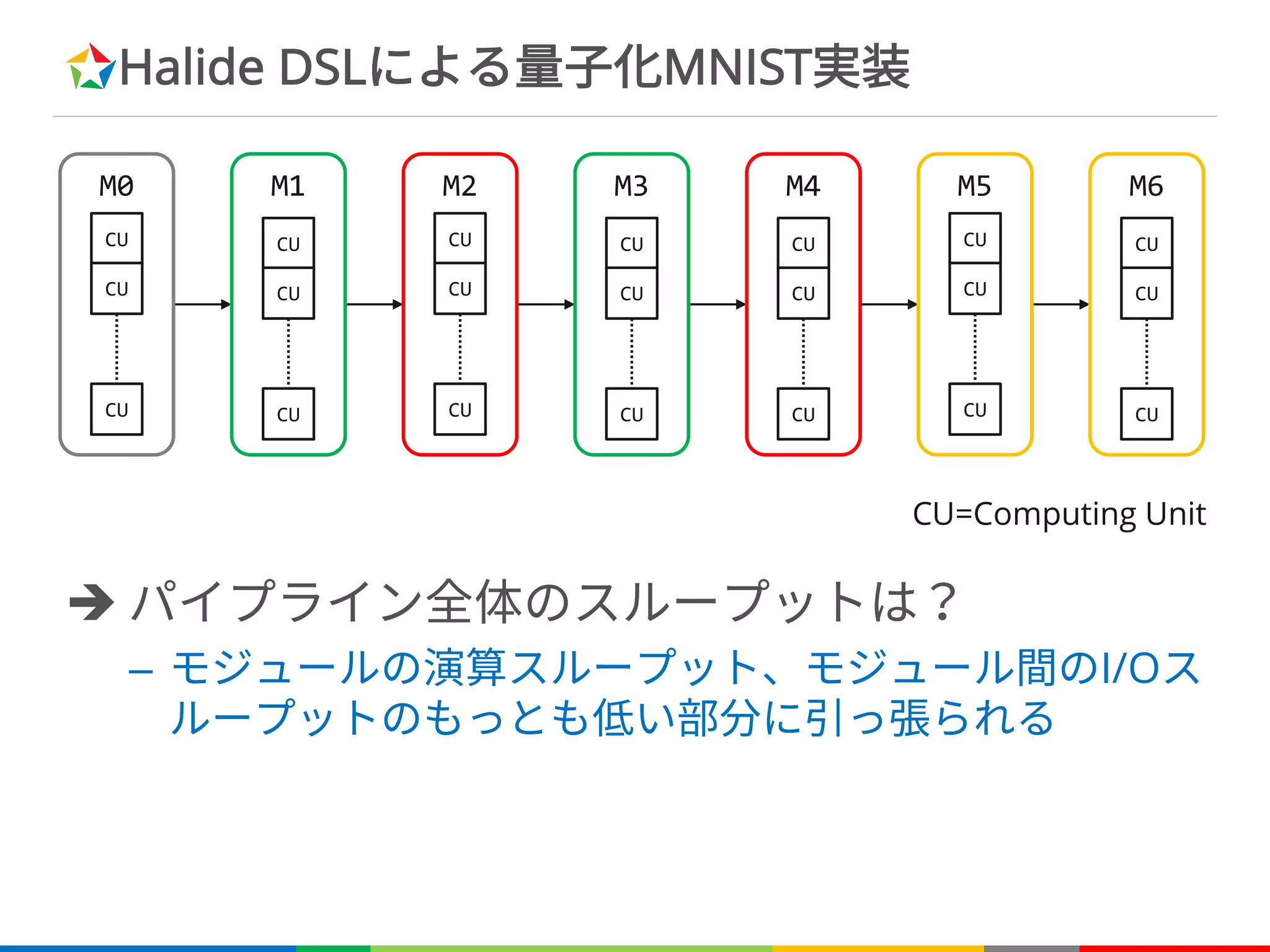
Halide DSLによる量子化MNIST実装
è パイプライン全体のスループットは?
–モジュールの演算スループット、モジュール間のI/Oス
ループットのもっとも低い部分に引っ張られる
M0
CU
CU
CU
M1
CU
CU
CU
M2
CU
CU
CU
M3
CU
CU
CU
M4
CU
CU
CU
M5
CU
CU
CU
M6
CU
CU
CU
CU=Computing Unit
63.
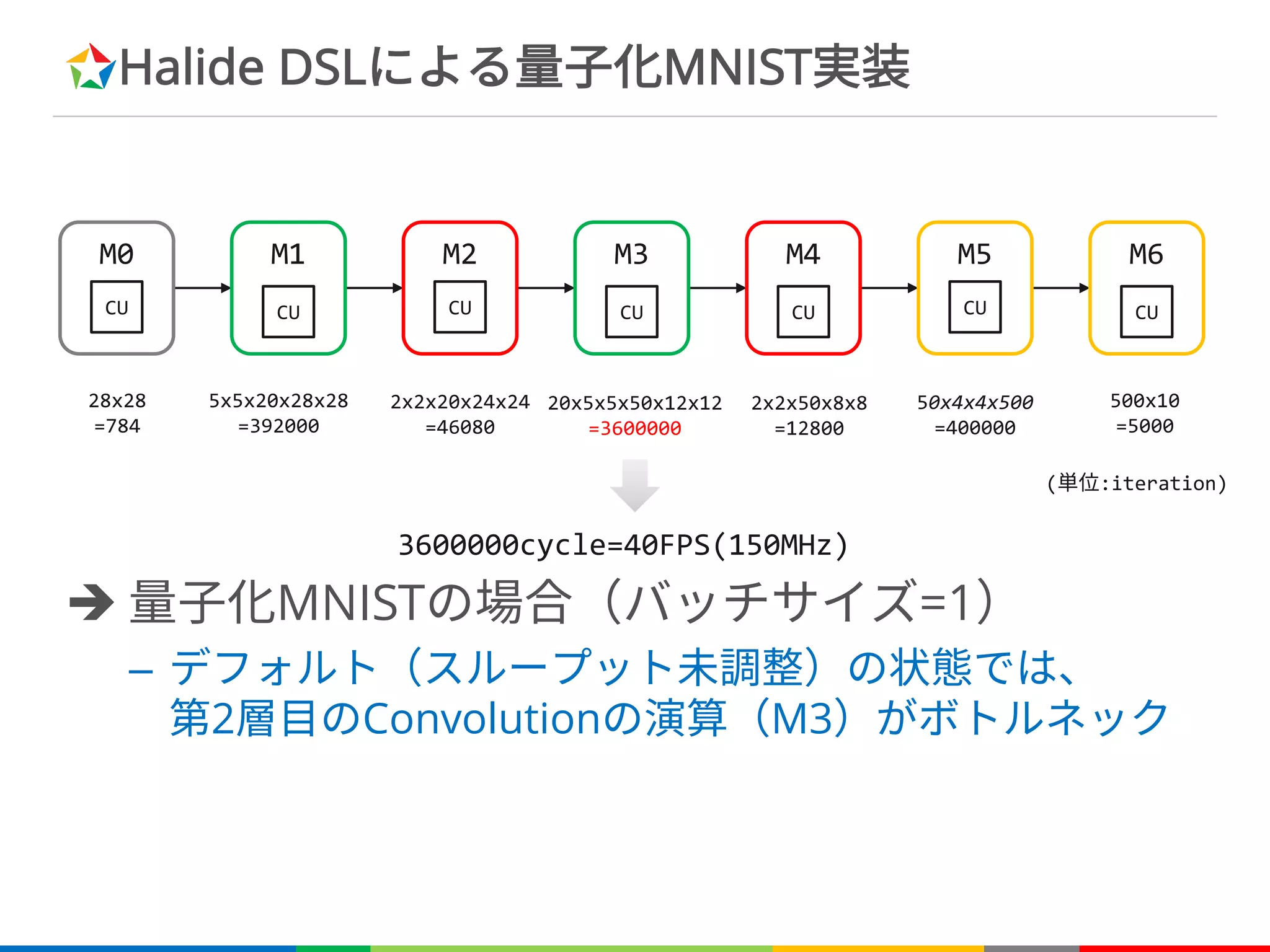
Halide DSLによる量子化MNIST実装
è 量子化MNISTの場合(バッチサイズ=1)
–デフォルト(スループット未調整)の状態では、
第2層目のConvolutionの演算(M3)がボトルネック
M0
CU
M1
CU
M2
CU
M3
CU
M4
CU
M5
CU
M6
CU
28x28
=784
5x5x20x28x28
=392000
2x2x20x24x24
=46080
20x5x5x50x12x12
=3600000
2x2x50x8x8
=12800
50x4x4x500
=400000
500x10
=5000
3600000cycle=40FPS(150MHz)
(単位:iteration)
64.
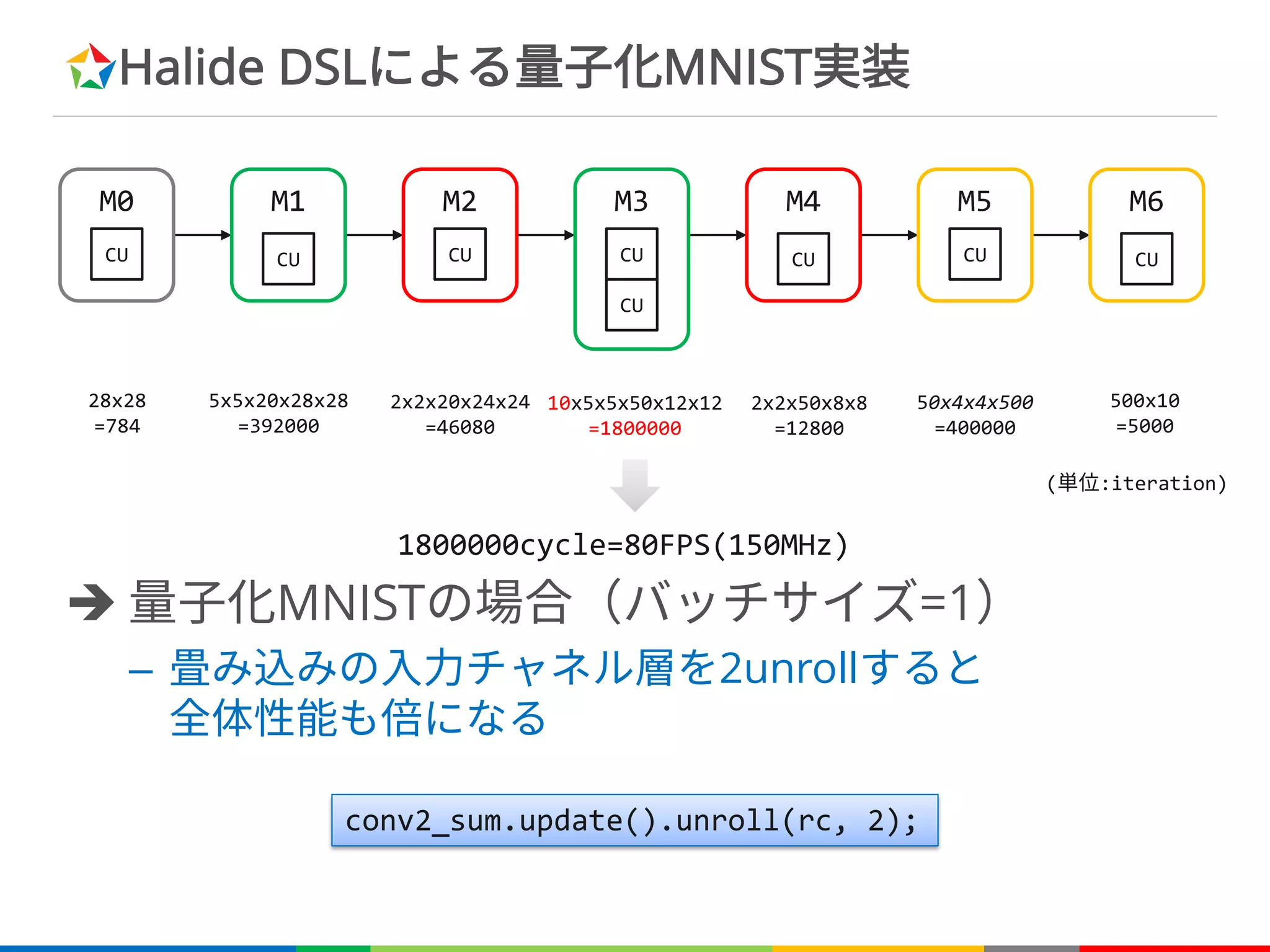
Halide DSLによる量子化MNIST実装
è 量子化MNISTの場合(バッチサイズ=1)
–畳み込みの入力チャネル層を2unrollすると
全体性能も倍になる
M0
CU
M1
CU
M2
CU
M3 M4
CU
M5
CU
M6
CU
28x28
=784
5x5x20x28x28
=392000
2x2x20x24x24
=46080
10x5x5x50x12x12
=1800000
2x2x50x8x8
=12800
50x4x4x500
=400000
500x10
=5000
CU
CU
conv2_sum.update().unroll(rc, 2);
1800000cycle=80FPS(150MHz)
(単位:iteration)
















![C++によるx86向け最適化コード
void box_filter_3x3(const Image &in, Image &blury) {
__m128i one_third = _mm_set1_epi16(21846);
#pragma omp parallel for
for (int yTile = 0; yTile < in.height(); yTile += 32) {
__m128i a, b, c, sum, avg;
__m128i blurx[(256/8)*(32+2)]; // allocate tile blurx array
for (int xTile = 0; xTile < in.width(); xTile += 256) {
__m128i *blurxPtr = blurx;
for (int y = -1; y < 32+1; y++) {
const uint16_t *inPtr = &(in[yTile+y][xTile]);
for (int x = 0; x < 256; x += 8) {
a = _mm_loadu_si128((__m128i*)(inPtr-1));
b = _mm_loadu_si128((__m128i*)(inPtr+1));
c = _mm_load_si128((__m128i*)(inPtr));
sum = _mm_add_epi16(_mm_add_epi16(a, b), c);
avg = _mm_mulhi_epi16(sum, one_third);
_mm_store_si128(blurxPtr++, avg);
inPtr += 8;
}
}
blurxPtr = blurx;
for (int y = 0; y < 32; y++) {
__m128i *outPtr = (__m128i *)(&(blury[yTile+y][xTile]));
for (int x = 0; x < 256; x += 8) {
a = _mm_load_si128(blurxPtr+(2*256)/8);
b = _mm_load_si128(blurxPtr+256/8);
c = _mm_load_si128(blurxPtr++);
sum = _mm_add_epi16(_mm_add_epi16(a, b), c);
avg = _mm_mulhi_epi16(sum, one_third);
_mm_store_si128(outPtr++, avg);
}
}
}
}
}](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-25-2048.jpg)
![C++によるx86向け最適化コード
void box_filter_3x3(const Image &in, Image &blury) {
__m128i one_third = _mm_set1_epi16(21846);
#pragma omp parallel for
for (int yTile = 0; yTile < in.height(); yTile += 32) {
__m128i a, b, c, sum, avg;
__m128i blurx[(256/8)*(32+2)]; // allocate tile blurx array
for (int xTile = 0; xTile < in.width(); xTile += 256) {
__m128i *blurxPtr = blurx;
for (int y = -1; y < 32+1; y++) {
const uint16_t *inPtr = &(in[yTile+y][xTile]);
for (int x = 0; x < 256; x += 8) {
a = _mm_loadu_si128((__m128i*)(inPtr-1));
b = _mm_loadu_si128((__m128i*)(inPtr+1));
c = _mm_load_si128((__m128i*)(inPtr));
sum = _mm_add_epi16(_mm_add_epi16(a, b), c);
avg = _mm_mulhi_epi16(sum, one_third);
_mm_store_si128(blurxPtr++, avg);
inPtr += 8;
}
}
blurxPtr = blurx;
for (int y = 0; y < 32; y++) {
__m128i *outPtr = (__m128i *)(&(blury[yTile+y][xTile]));
for (int x = 0; x < 256; x += 8) {
a = _mm_load_si128(blurxPtr+(2*256)/8);
b = _mm_load_si128(blurxPtr+256/8);
c = _mm_load_si128(blurxPtr++);
sum = _mm_add_epi16(_mm_add_epi16(a, b), c);
avg = _mm_mulhi_epi16(sum, one_third);
_mm_store_si128(outPtr++, avg);
}
}
}
}
}
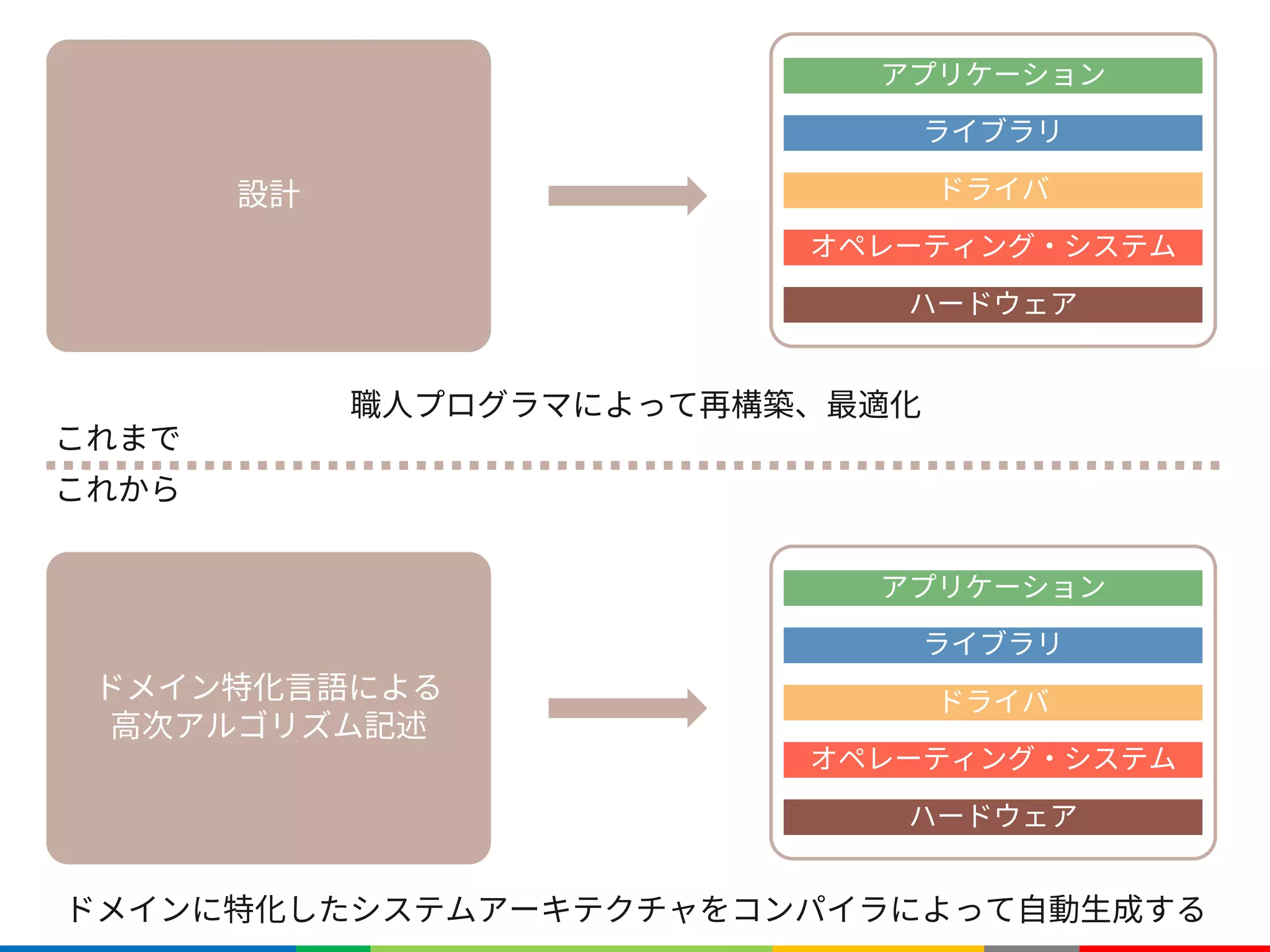
長くて色々つらい
ハードウェア変わると書き直し
アルゴリズム変わると書き直し](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-26-2048.jpg)




![関数の定義
è アルゴリズムは関数として定義される
– 関数: Halide::Func
– 誘導変数: Halide::Var
Halideソースコード 等価なC++ソースコード
意味: 関数 f は定義域 x, y に対して x+y を値域に持つ
名前空間Halide::は以下省略
Func f;
Var x, y;
f(x, y) = x + y;
for (int y=0; y<height; y++) {
for (int x=0; x<width; x++) {
f[y][x] = x + y;
}
}](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-34-2048.jpg)



![RDomと畳み込み関数
è 畳み込みを表すためのプリミティブ
– リダクションドメイン: RDom
– RDom(min, extent)
• 指定された次元で[min, min+extent-1]の領域を畳み込み
等価なC++ソースコード
rxは[-1, 1]を動く誘導変数
Var x;
Func f;
f(x) = x;
RDom rx(-1, 3);
Func g;
g(x) = sum(f(x + rx));
for (int x=0; x<width; x++) {
T sum = 0;
for (int rx=-1; rx<2; rx++) {
sum += x + rx;
}
g[x] = sum;
}
+](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-39-2048.jpg)

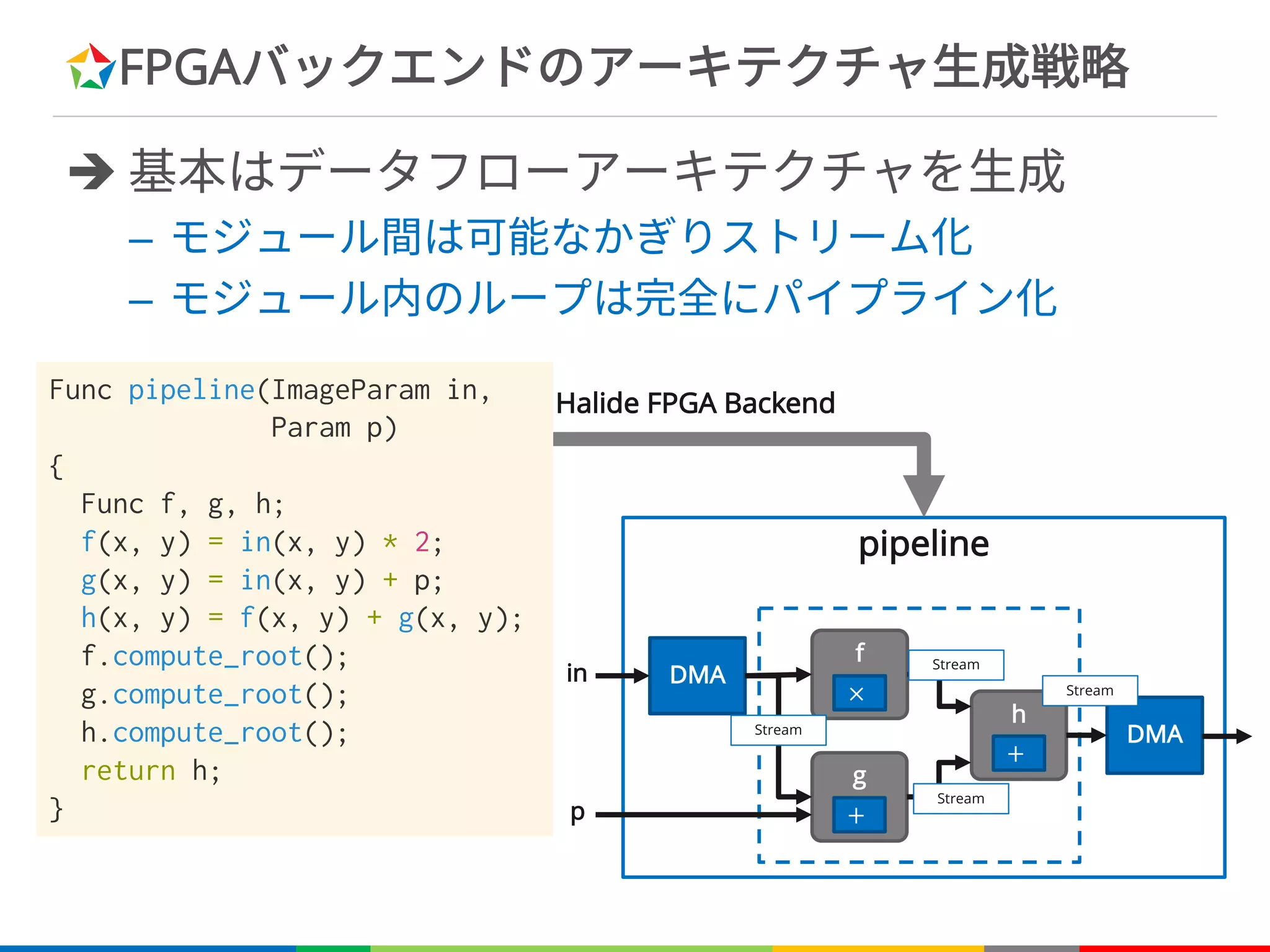
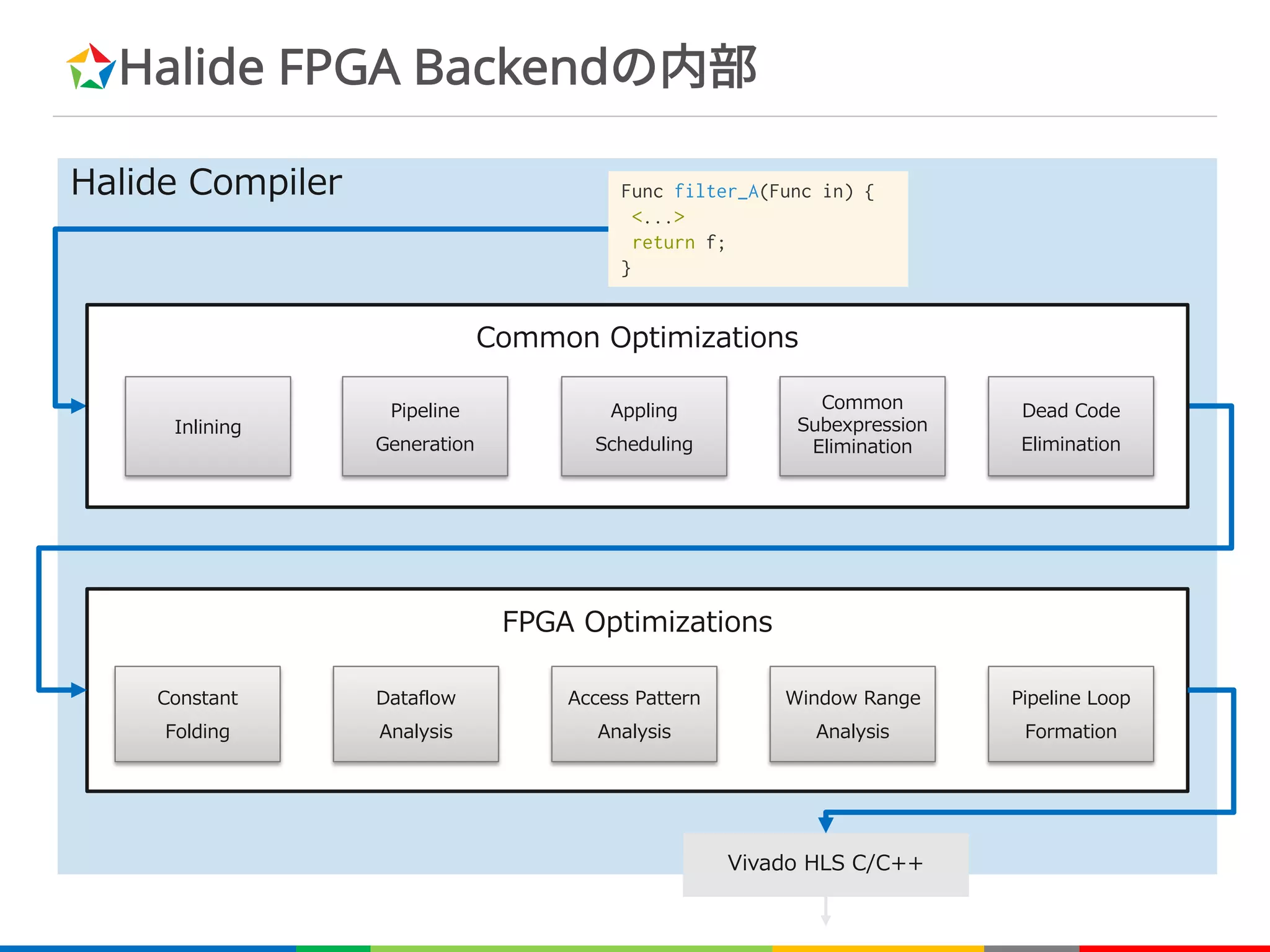
![FPGAバックエンドのアーキテクチャ生成戦略
è 3x3の畳み込みの場合
+
in_buffer f_buffer
in_port f_port
■ Shift Regs
■ Block RAM
等価なC++プログラム
=
Halide FPGA Backend
Func conv3x3(ImageParam in)
{
Var x, y;
RDom r{-1, 3, -1, 3};
Func f;
f(x, y) = sum(in(x+r.x, y+r.y));
f.compute_root();
return f;
}
for(y=0; y<height; y++)
for(x=0; x<width; x++) {
f[y][x]=0;
for(ry=-kh/2; ry<kh/2+1; ry++)
for(rx=-kw/2; rx<kw/2+1; rx++)
f[y][x]+=in[y+ry][x+rx];
}](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-42-2048.jpg)
![FPGAバックエンドのアーキテクチャ生成戦略
+
in_buffer f_buffer
in_port f_port
等価なC++プログラム
=
■ Shift Regs
■ Block RAM
Halide FPGA Backend
Func conv3x3(ImageParam in)
{
Var x, y;
RDom r{-1, 3, -1, 3};
Func f;
f(x, y) = sum(in(x+r.x, y+r.y));
f.compute_root();
return f;
}
for(y=0; y<height; y++)
for(x=0; x<width; x++) {
f[y][x]=0;
for(ry=-kh/2; ry<kh/2+1; ry++)
for(rx=-kw/2; rx<kw/2+1; rx++)
f[y][x]+=in[y+ry][x+rx];
}](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-43-2048.jpg)
![FPGAバックエンドのアーキテクチャ生成戦略
+
in_buffer f_buffer
in_port f_port
■ Shift Regs
■ Block RAM
等価なC++プログラム
=
Halide FPGA Backend
Func conv3x3(ImageParam in)
{
Var x, y;
RDom r{-1, 3, -1, 3};
Func f;
f(x, y) = sum(in(x+r.x, y+r.y));
f.compute_root();
return f;
}
for(y=0; y<height; y++)
for(x=0; x<width; x++) {
f[y][x]=0;
for(ry=-kh/2; ry<kh/2+1; ry++)
for(rx=-kw/2; rx<kw/2+1; rx++)
f[y][x]+=in[y+ry][x+rx];
}](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-44-2048.jpg)
![FPGAバックエンドのアーキテクチャ生成戦略
+
in_buffer f_buffer
in_port f_port
■ Shift Regs
■ Block RAM
等価なC++プログラム
=
Halide FPGA Backend
Func conv3x3(ImageParam in)
{
Var x, y;
RDom r{-1, 3, -1, 3};
Func f;
f(x, y) = sum(in(x+r.x, y+r.y));
f.compute_root();
return f;
}
for(y=0; y<height; y++)
for(x=0; x<width; x++) {
f[y][x]=0;
for(ry=-kh/2; ry<kh/2+1; ry++)
for(rx=-kw/2; rx<kw/2+1; rx++)
f[y][x]+=in[y+ry][x+rx];
}](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-45-2048.jpg)


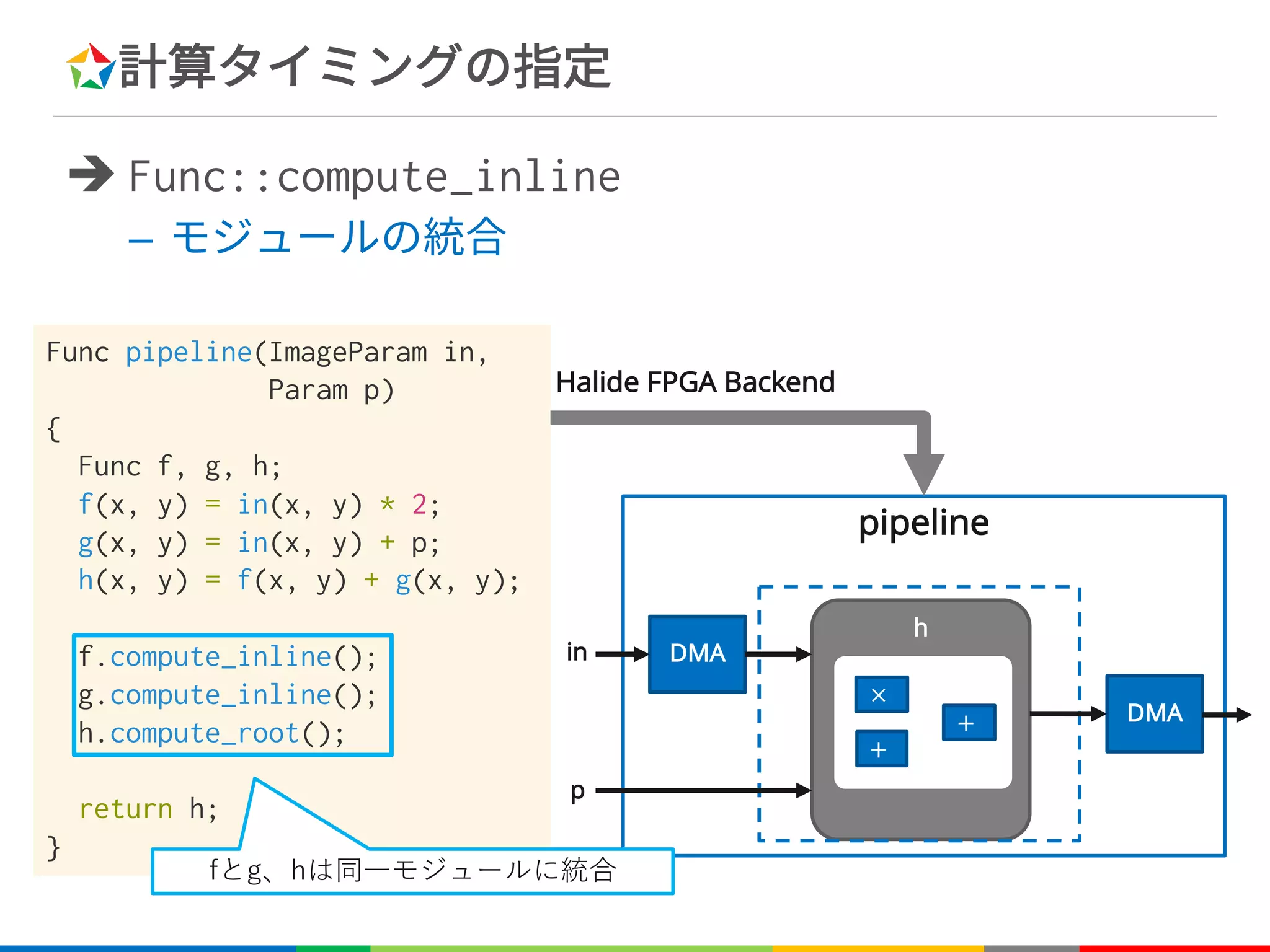
![計算タイミングの指定
è Func::compute_inline
– Funcをインライン展開する
• スケジューリング無指定の場合のデフォルトの挙動
C++
Var x, y;
Func blur_x;
blur_x(x, y) = in(x, y) + in(x+1, y);
Func blur_y;
blur_y(x, y) = (blur_x(x, y) +
blur_x(x, y+1)) / 4;
Var x, y;
Func blur_y;
blur_y(x, y) = (in(x, y) +
in(x+1, y) +
in(x, y+1) +
in(x+1, y+1)) / 4;
for (int y=0; y<height; y++) {
for (int x=0; x<width; x++) {
blur_y[y][x] =
(blur_x[y][x] + blur_x[y][x] +
blur_x[y+1][x] + blur_x[y+1][x]) / 4;
}
}](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-49-2048.jpg)
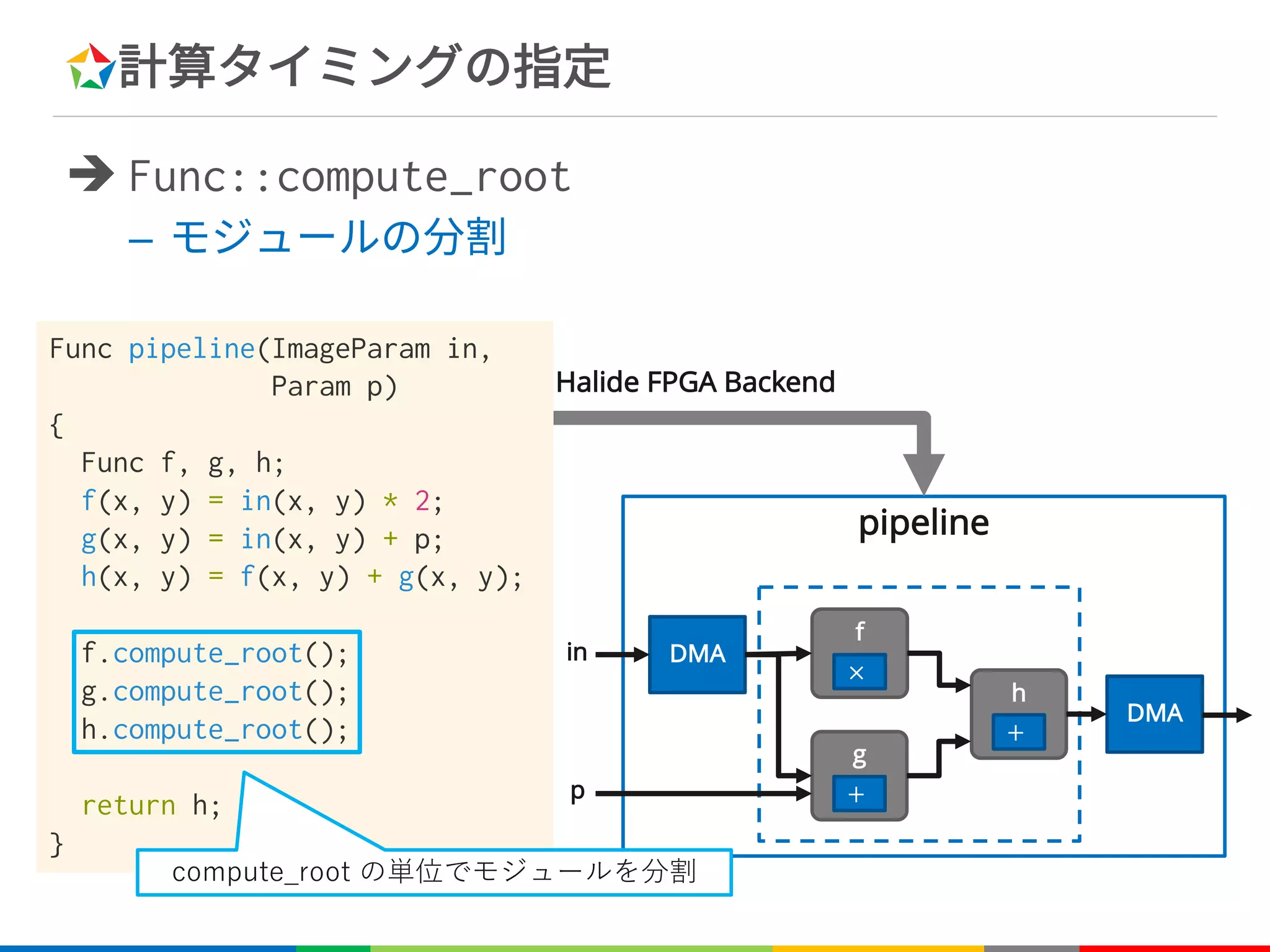
![計算タイミングの指定
è Func::compute_root
– ルートレベル(最外レベル)で当該Funcの計算を行う
C++
Var x, y;
Func blur_x;
blur_x(x, y) = in(x, y) + in(x+1, y);
Func blur_y;
blur_y(x, y) = (blur_x(x, y) +
blur_x(x, y+1)) / 4;
blur_x.compute_root();
for (int y=0; y<height; y++) {
for (int x=0; x<width; x++) {
blur_x[y][x] = in[y][x] + in[y][x+1];
}
}
for (int y=0; y<height; y++) {
for (int x=0; x<width; x++) {
blur_y[y][x] =
(blur_x[y][x] + blur_x[y+1][x]) / 4;
}
}](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-51-2048.jpg)
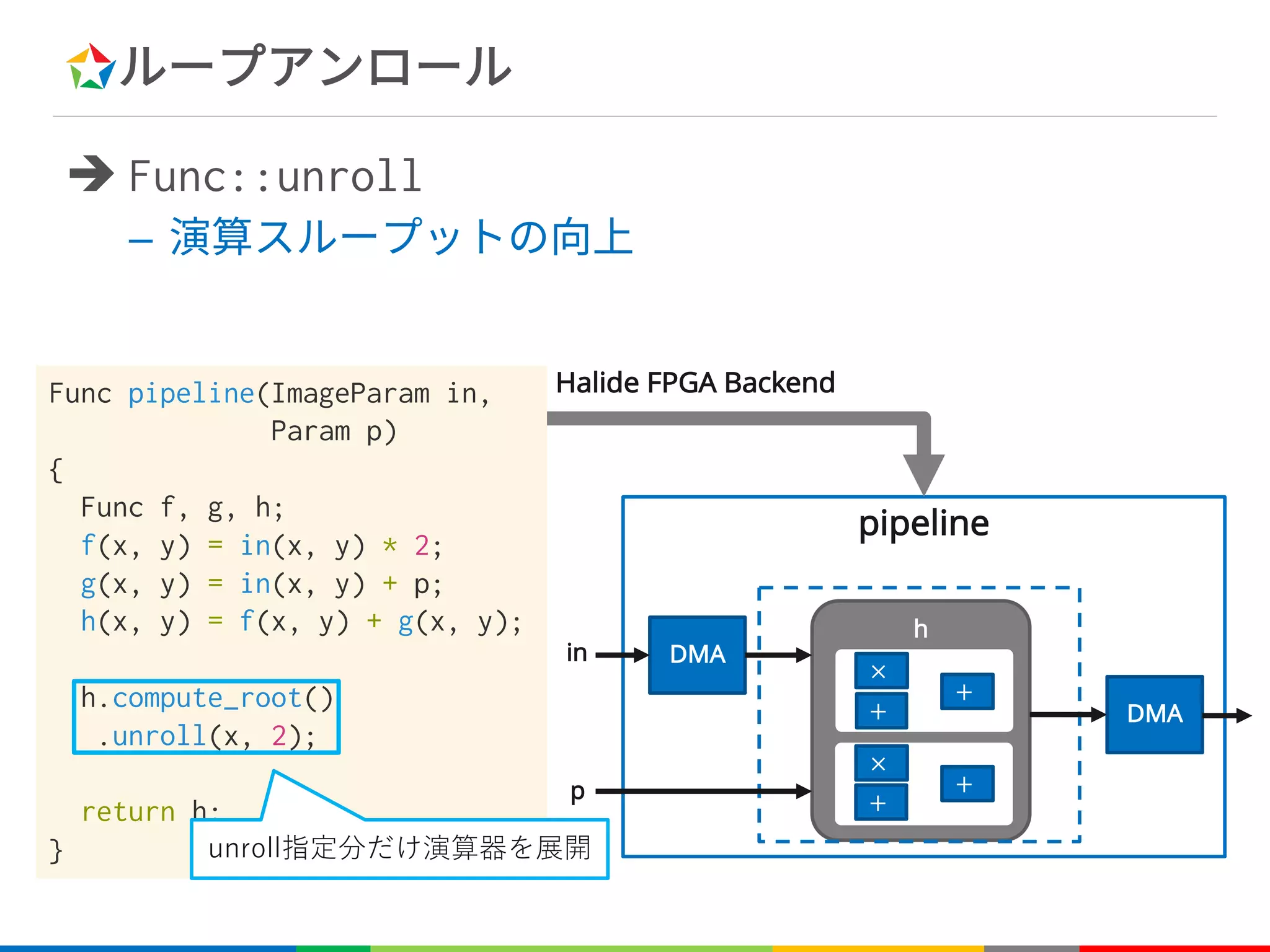
![ループアンロール
è Func::unroll
– 指定した次元に対してループ展開を行う
unroll C++
Var x, y;
Func f;
f(x, y) = x + y;
for (int y=0; y<height; y++)
for (int x=0; x<width; x++)
f[y][x] = x + y;](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-53-2048.jpg)
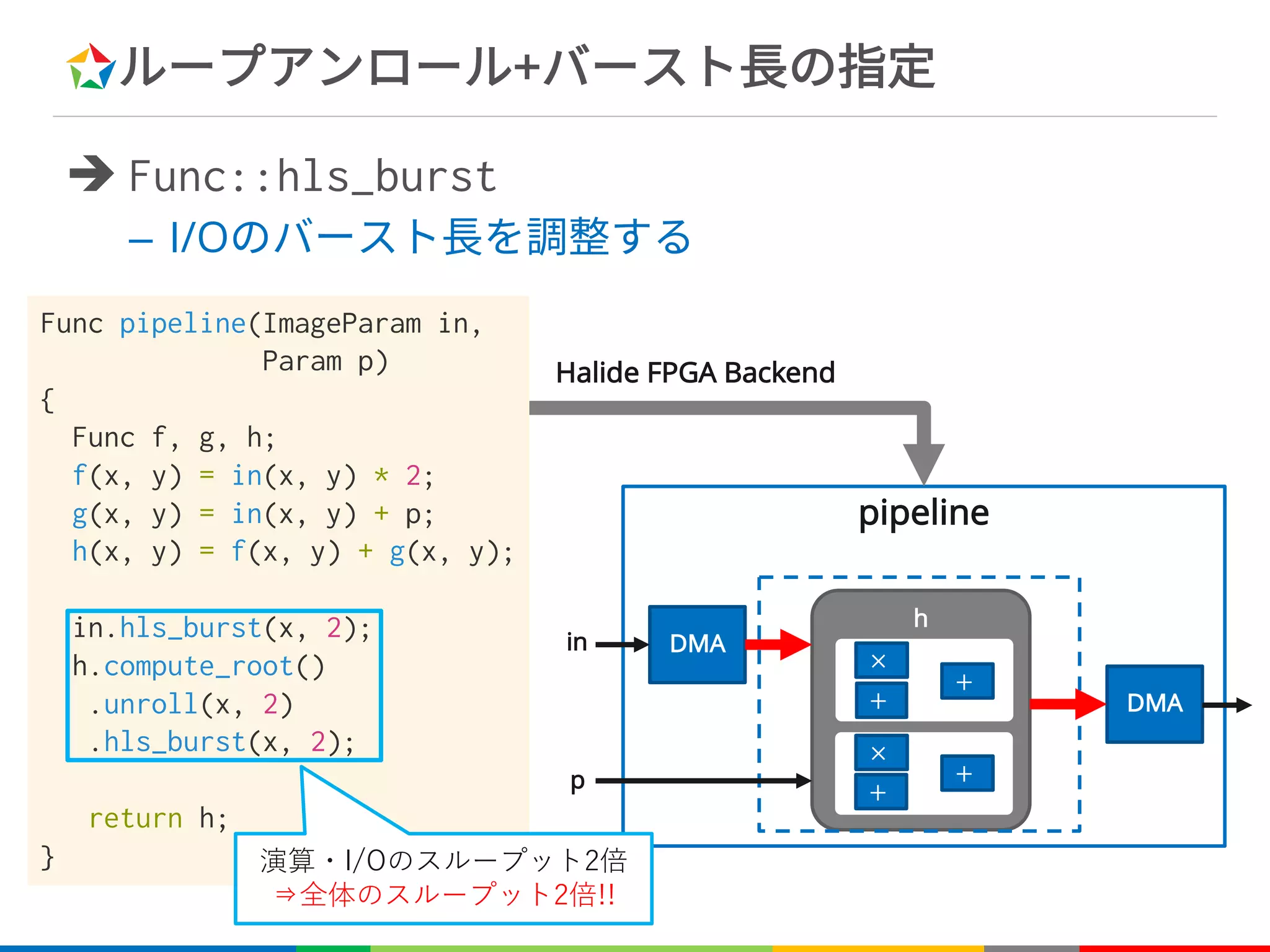
![ループアンロール
è Func::unroll
– 指定した次元に対してループ展開を行う
Unroll
Var x, y;
Func f;
f(x, y) = x + y;
f.unroll(x, 2);
for (int y=0; y<height; y++)
for (int x=0; x<width; x+=2) {
f[y][x] = x + y;
f[x+1][y] = x+1 + y;
}
Unroll C++
unroll C++
for (int y=0; y<height; y++)
for (int x=0; x<width; x++)
f[y][x] = x + y;](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-54-2048.jpg)

![FPGA向けアルゴリズム最適化: XNOR-Net[1]
è Conv層の入力 Iと重み W を二値化
– ラインバッファ・重みの容量を1/32に削減
– 積和がXNORとpopcountで演算可能
! ∗ # ≈ ( sign(!) ⊛ sign(# ) ○ -.
∗ : Convolution operator
⊛ : XNOR and popcount operator
○ : Element-wise product operator
-.: Scaling factor
+ - -
- + -
+ - +
- + -
+ + -
- + +
0 1 0
1 1 0
0 1 1
1 0 0
0 1 0
1 0 1
× 4.∗ ⊛
! # sign(!) sign(#)
binarize
[1] Rastegari, M. et al., “XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks”, https://arxiv.org/abs/1603.05279](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-59-2048.jpg)
![FPGA向けアルゴリズム最適化: Log-based Quantization[2]
è初段・最終段のConv/FC層
– 二値化すると精度の低下が激しい
è初段・最終段のConv/FC層の入力と重みを
対数量子化
– ラインバッファ・重みの容量を削減
– 積算がシフト演算で計算可能
• 今回はlog2-baseで量子化
Dataset Network
Accuracy
fixed-32 2-base log2-base
MNIST LeNet-5 98% 95% 98%
CIFAR-10 NIN 89% 66% 82%
[2] Miyashita, D. et al., “Convolutional Neural Networks using Logarithmic Data Representation”, https://arxiv.org/abs/1603.01025](https://image.slidesharecdn.com/fpgax-201802-180226011747/75/Halide-Domain-Specific-Architecture-60-2048.jpg)
















![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)



















































