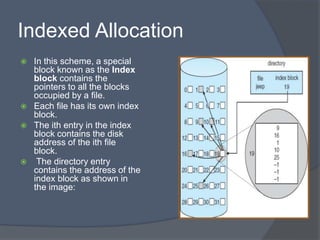
The document discusses different methods for implementing directories and allocating disk space for files in a file system. There are two main directory implementation methods - linear list and hash table. Linear list allows simple programming but slow searches, while hash table can greatly decrease search time through mapping file names to list locations. For file allocation, contiguous allocation groups file blocks together but causes fragmentation, while linked and indexed allocation scatter blocks but require seeking between blocks. Indexed allocation supports direct access through a file index block but has higher overhead than linked allocation.