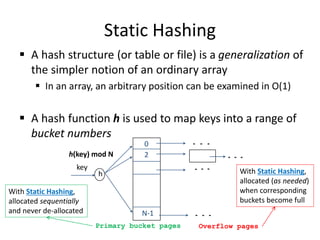
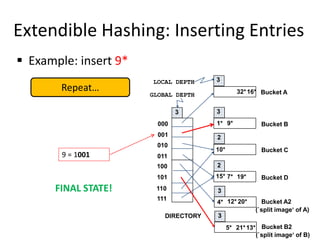
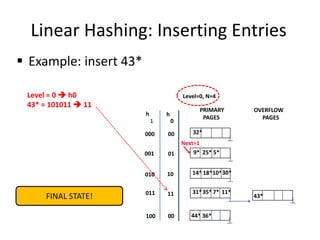
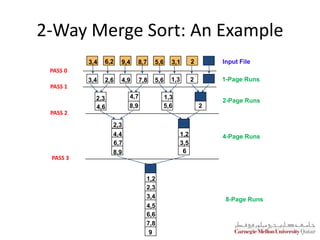
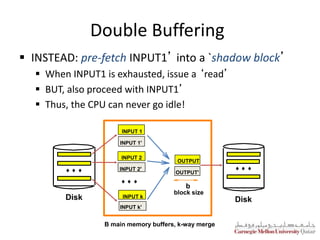
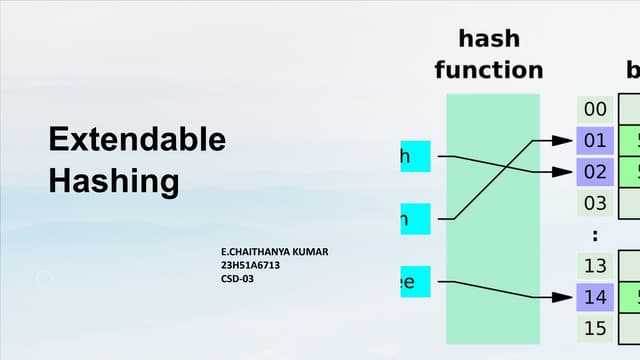
The document summarizes a lecture on DBMS internals including hash-based indexing and external sorting. It discusses static hashing which uses a fixed number of buckets and can develop long overflow chains. Extendible hashing is then introduced which uses a directory of pointers to buckets and dynamically doubles the directory and splits buckets as needed when inserting entries. The key aspects are that it can gracefully handle insertions and deletions without performance degradation and requires fewer disk I/Os than static hashing.