Downloaded 11 times

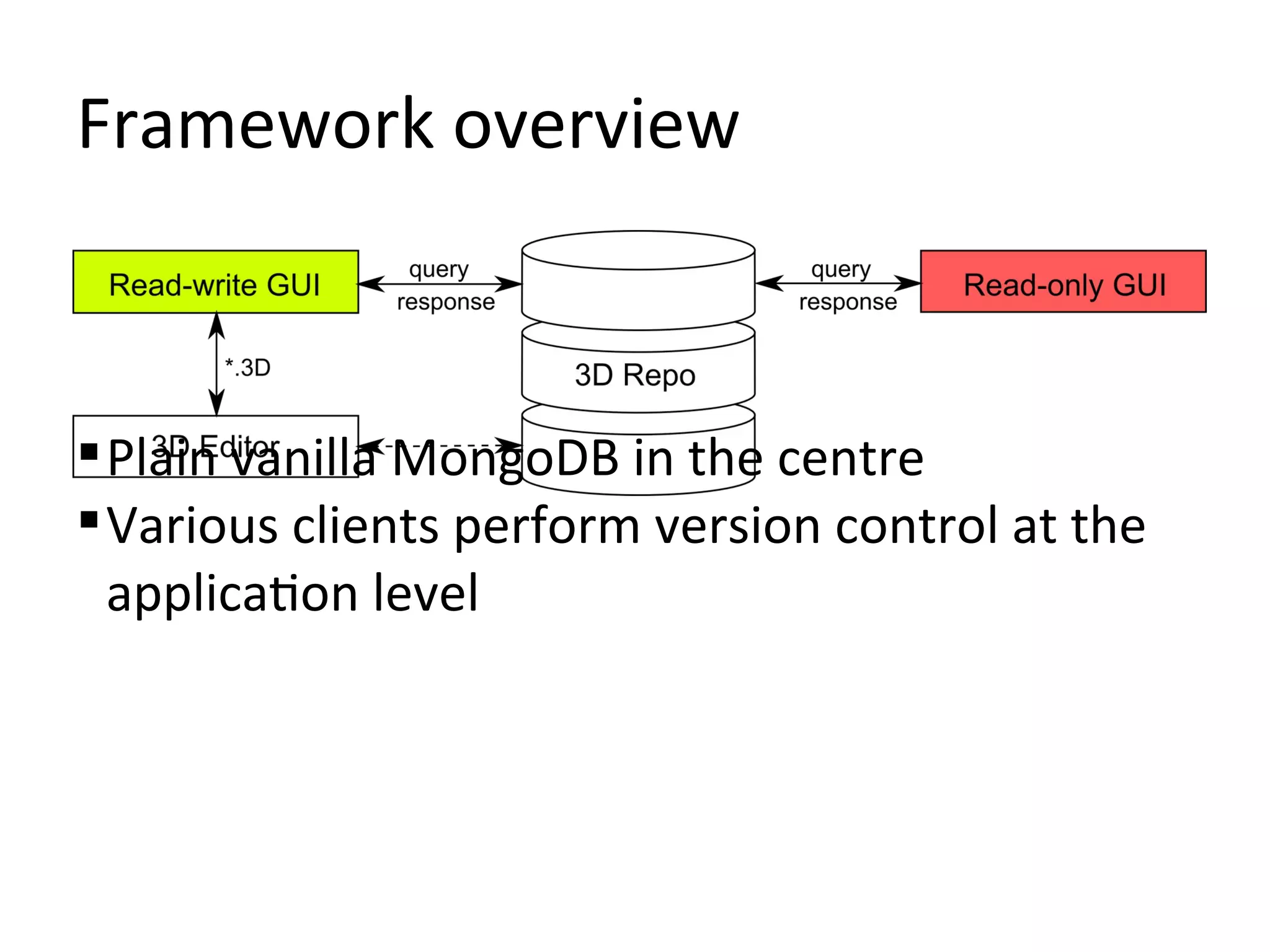
![3D Repo framework
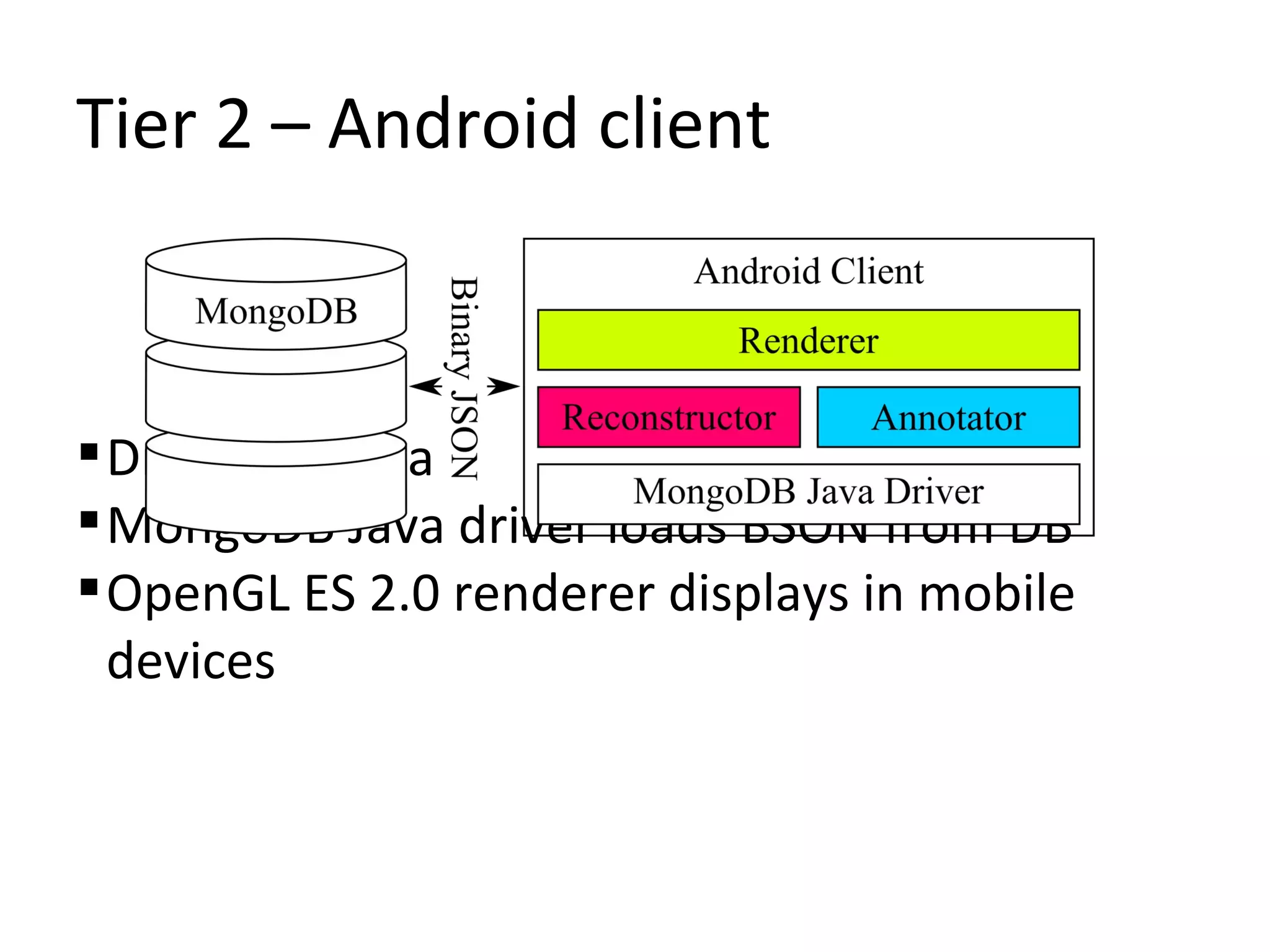
Is an array of clients: [C++, WebGL, Android]
Uses MongoDB as a repository to store:
Scene graph components
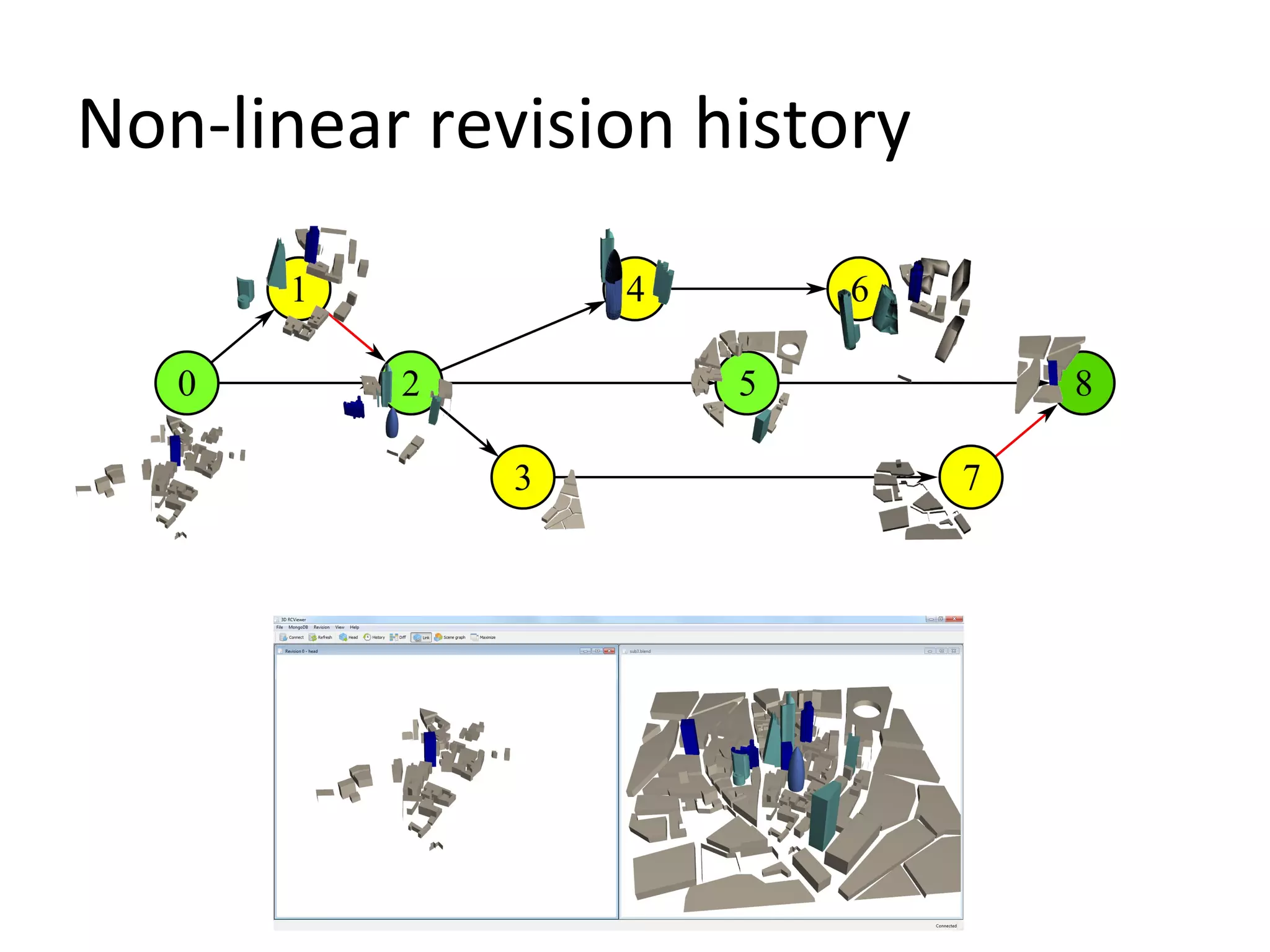
Non-linear revision history
Supports wide range of 3D assets
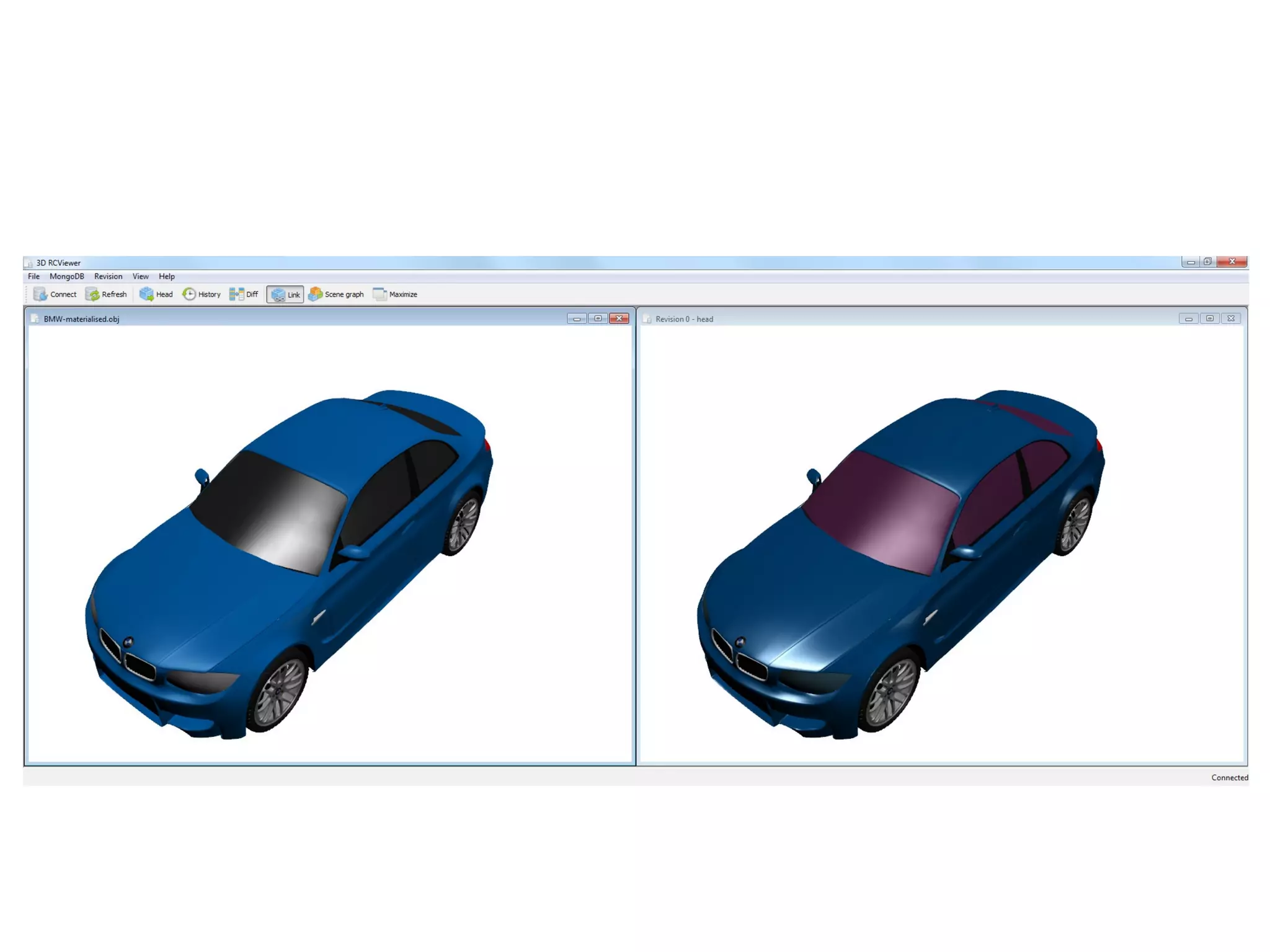
Provides powerful 3D Diff tool
Offers sub-object retrieval](https://image.slidesharecdn.com/3drepo-121101072800-phpapp01/75/3DRepo-2-2048.jpg)







![Nested sets [Celko 2004]
Representation: two integers as boundaries
Insertion: re-indexing of all the nodes
Sub-graph retrieval: 1 query
Fixed by using reals as quotients [Hazel 2008]
Each node has exactly one parent (trees)](https://image.slidesharecdn.com/3drepo-121101072800-phpapp01/75/3DRepo-14-2048.jpg)

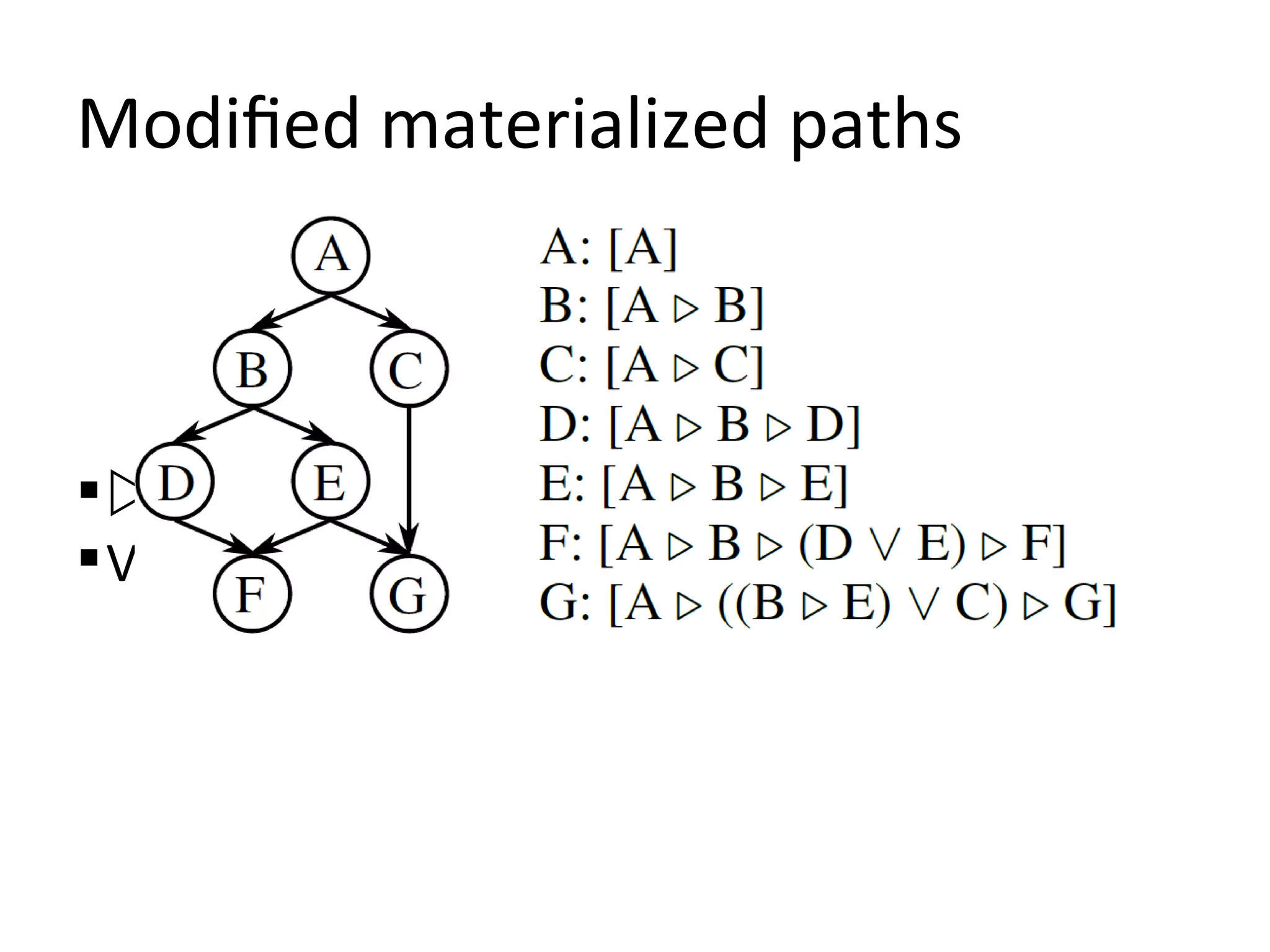
![Modified materialized paths
Representation: full path from root to node
Insertion: 1 update if leaf, partial re-indexing
otherwise
Sub-graph retrieval: 1 query
As a context-free grammar:
G = {{S, A},{n, n_root, ɛ}, P, S}
S → [n_root A]
A → ɛ |n|(A)|A A | (A V A)](https://image.slidesharecdn.com/3drepo-121101072800-phpapp01/75/3DRepo-16-2048.jpg)
![Transformation object (SG)
{
"_id" : BinData(3,"JGdmZwYAAAAAAAAAAAAAAQ=="),
"type" : "aiNode",
"revision" : 0,
"path" : [BinData(3,"NSVykEkAAAAAAA")…],
"mName" : "Sphere",
"mNumMeshes" : 1,
"mMeshes" : [0],
"mTransformation" :
[
[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]
]
}](https://image.slidesharecdn.com/3drepo-121101072800-phpapp01/75/3DRepo-18-2048.jpg)
![Mesh object (SG)
{
"_id" : BinData(3,"dodAEUAAAAAAAAAAAAAAAg=="),
"revision" : 0,
"type" : "aiMesh",
"path" : [BinData(3,"NQaYYQkAAAAAAAAAA")…],
"mName" : "mesh 2",
"index" : 2,
"mPrimitiveTypes" : 4,
"mNumVertices" : 24,
"mVertices" : BinData(0,"AACAwAAAgD8AAIA/…"),
"mNumFaces" : 12,
"facesArraySize" : 48,
"mFaces" : BinData(0,"AwAAAAAAAAABAAAAAg…"),
"mNormals" : BinData(0,"AACAvwAAAAAAAACAAACAv")
}](https://image.slidesharecdn.com/3drepo-121101072800-phpapp01/75/3DRepo-19-2048.jpg)
![Material object (SG)
{
"_id" : BinData(3,"F1NiSWQAAAAAAAAAAAAAAw=="),
"revision" : 0,
"type" : "aiMaterial",
"path" : [BinData(3,“MKFYHTkAAAAAAAAAA")…],
"AI_MATKEY_NAME" : "Material.004", "index" : 3,
"AI_MATKEY_COLOR_DIFFUSE" : [ 1, 0, 1, 0 ],
"AI_MATKEY_COLOR_SPECULAR" : [ 1, 1, 1, 1 ],
"AI_MATKEY_COLOR_AMBIENT" : [ 1, 0, 0, 0 ],
"AI_MATKEY_SHININESS" : 384.313720703125
}](https://image.slidesharecdn.com/3drepo-121101072800-phpapp01/75/3DRepo-20-2048.jpg)
![Revision object (RH)
{
"_id" : BinData(3,"l55gEB0OQ5edDjOXHQ4zlw=="),
"revision" : 0,
"author" : "jozef",
"path" : [BinData(3,“OPDMTdAADFAAAAAA")…],
"timestamp" : ISODate("2012-10-30T15:02:09Z"),
"message" : "The very first commit."
}](https://image.slidesharecdn.com/3drepo-121101072800-phpapp01/75/3DRepo-21-2048.jpg)


![Revision retrieval
function() {
var arr = db.nodes.distinct('uuid');
var results = new Array();
for (var i = 0; i $lt arr.length; i++) {
var cursor = db.nodes.find({
'uuid':arr[i],
'revision':{$in: {0:0}}
}).sort({'revision':-1}).limit(1);
results[i] = cursor[0];
}
return results;
}](https://image.slidesharecdn.com/3drepo-121101072800-phpapp01/75/3DRepo-24-2048.jpg)
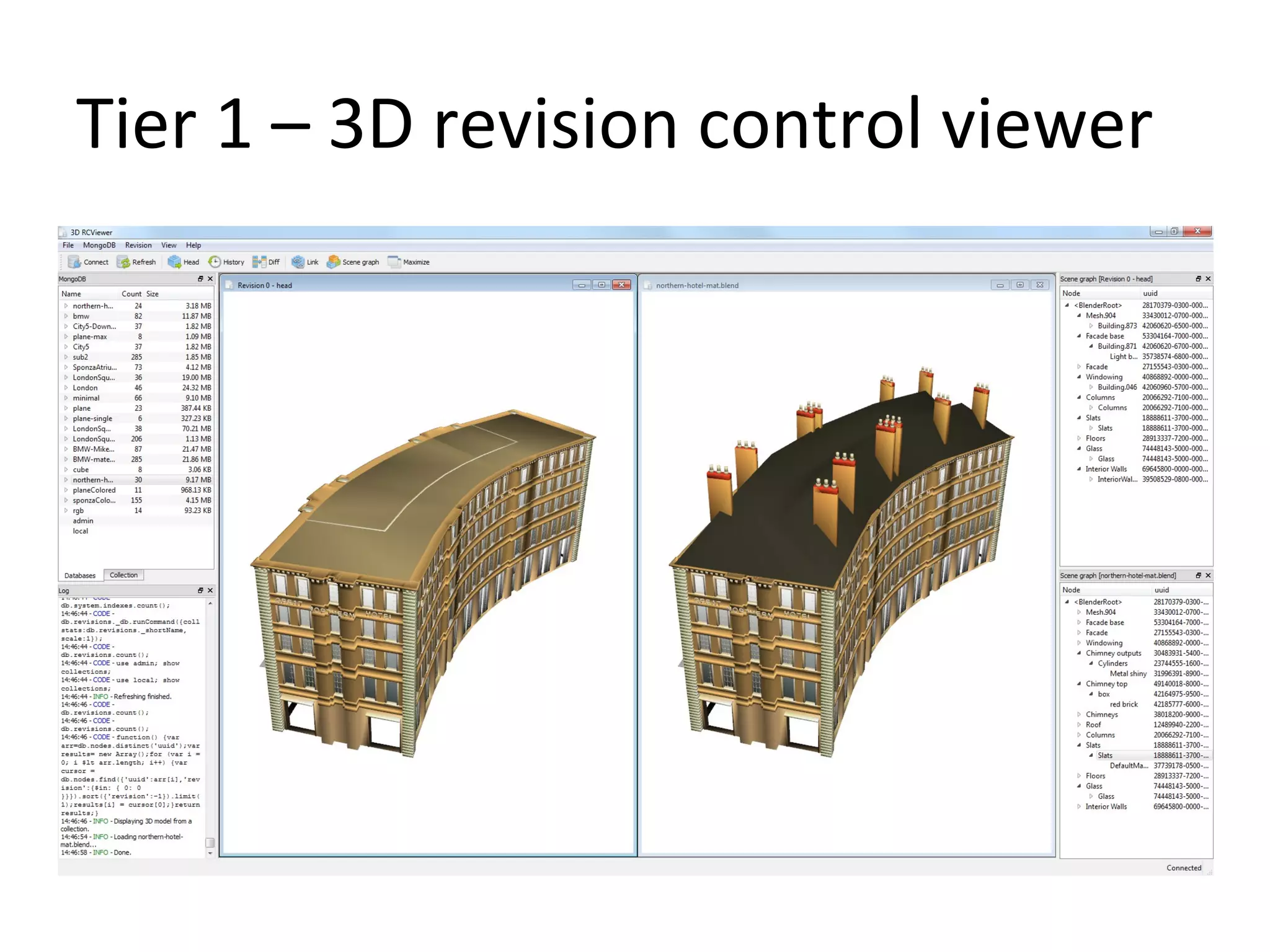

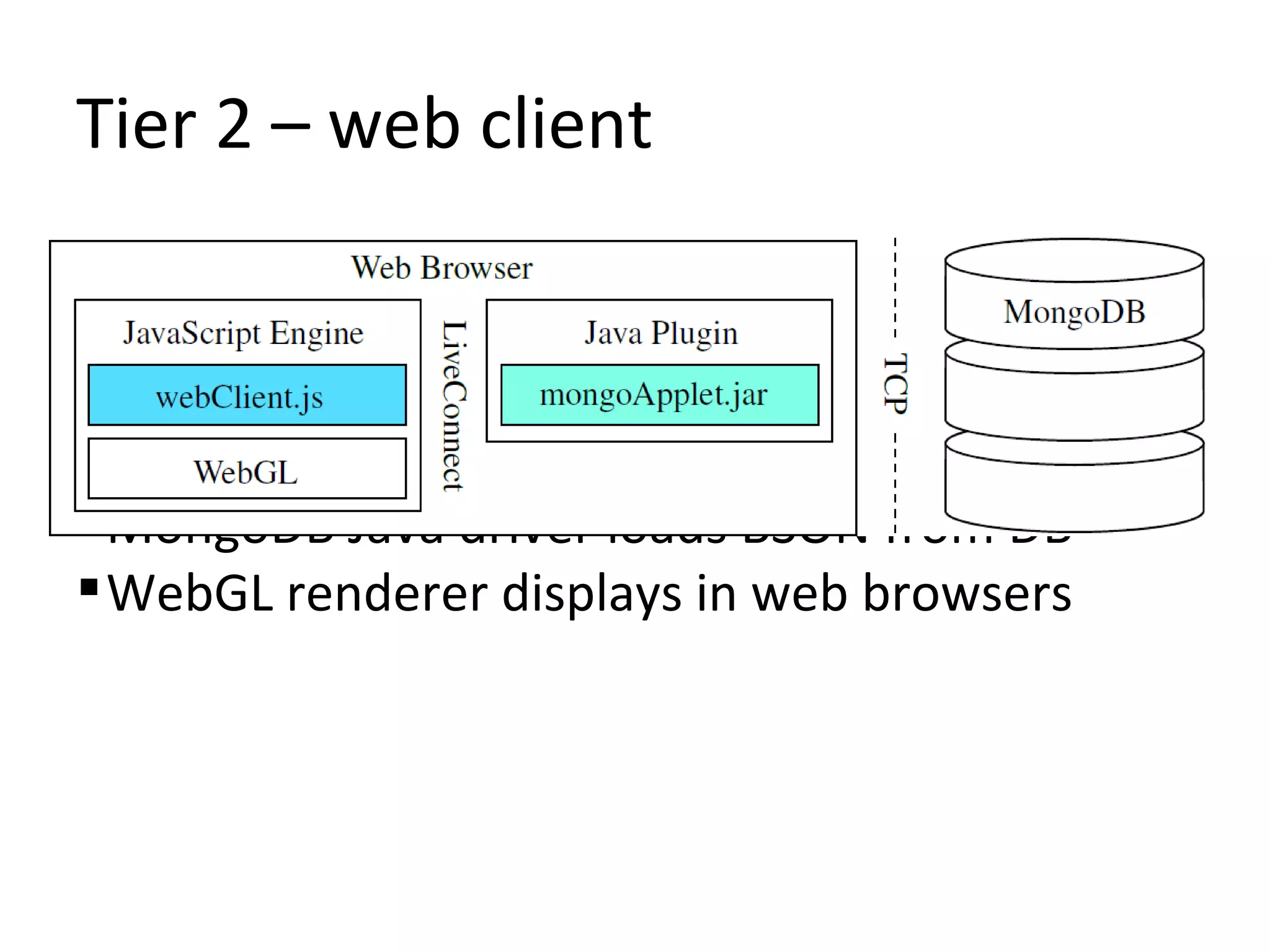

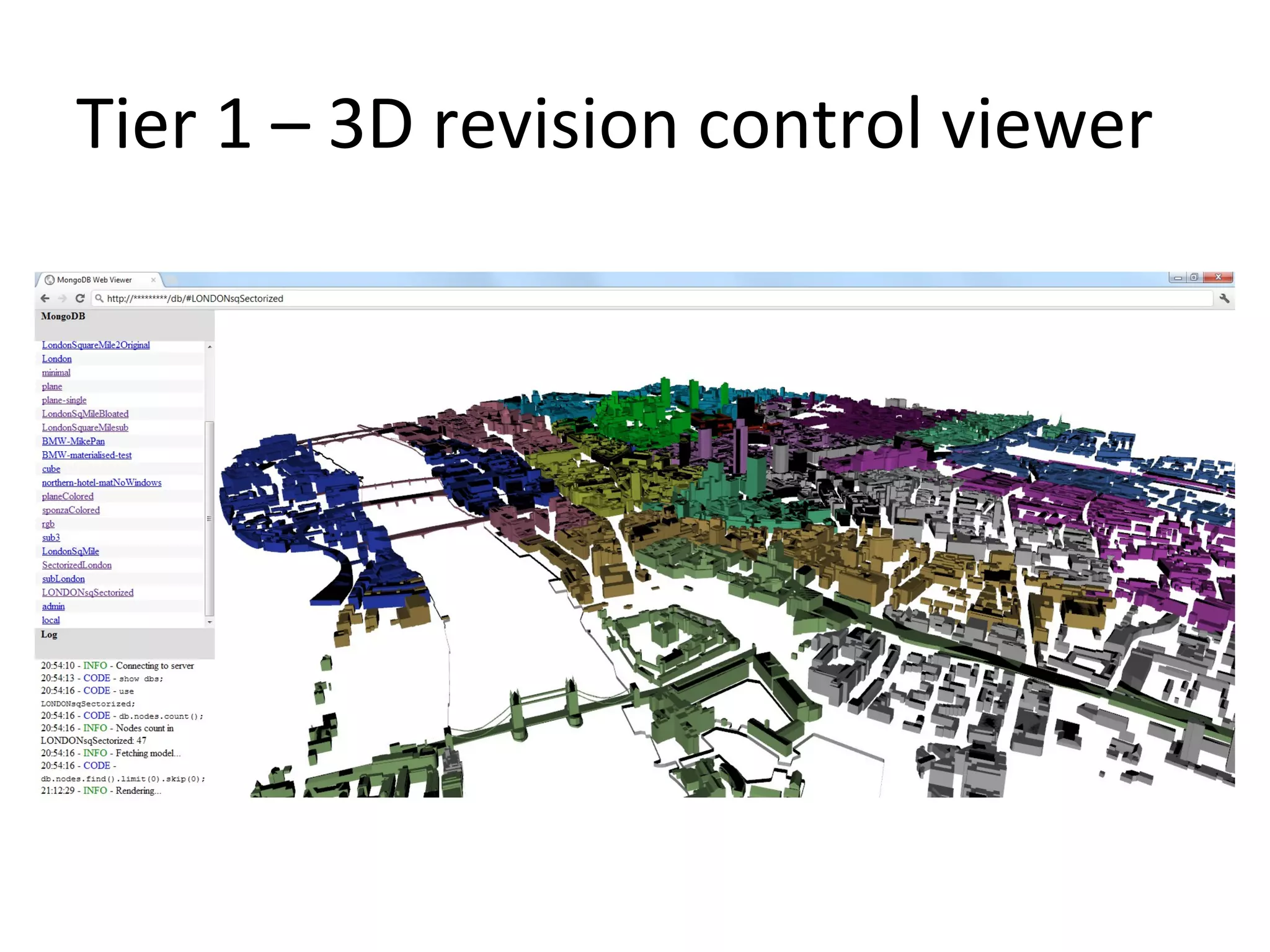
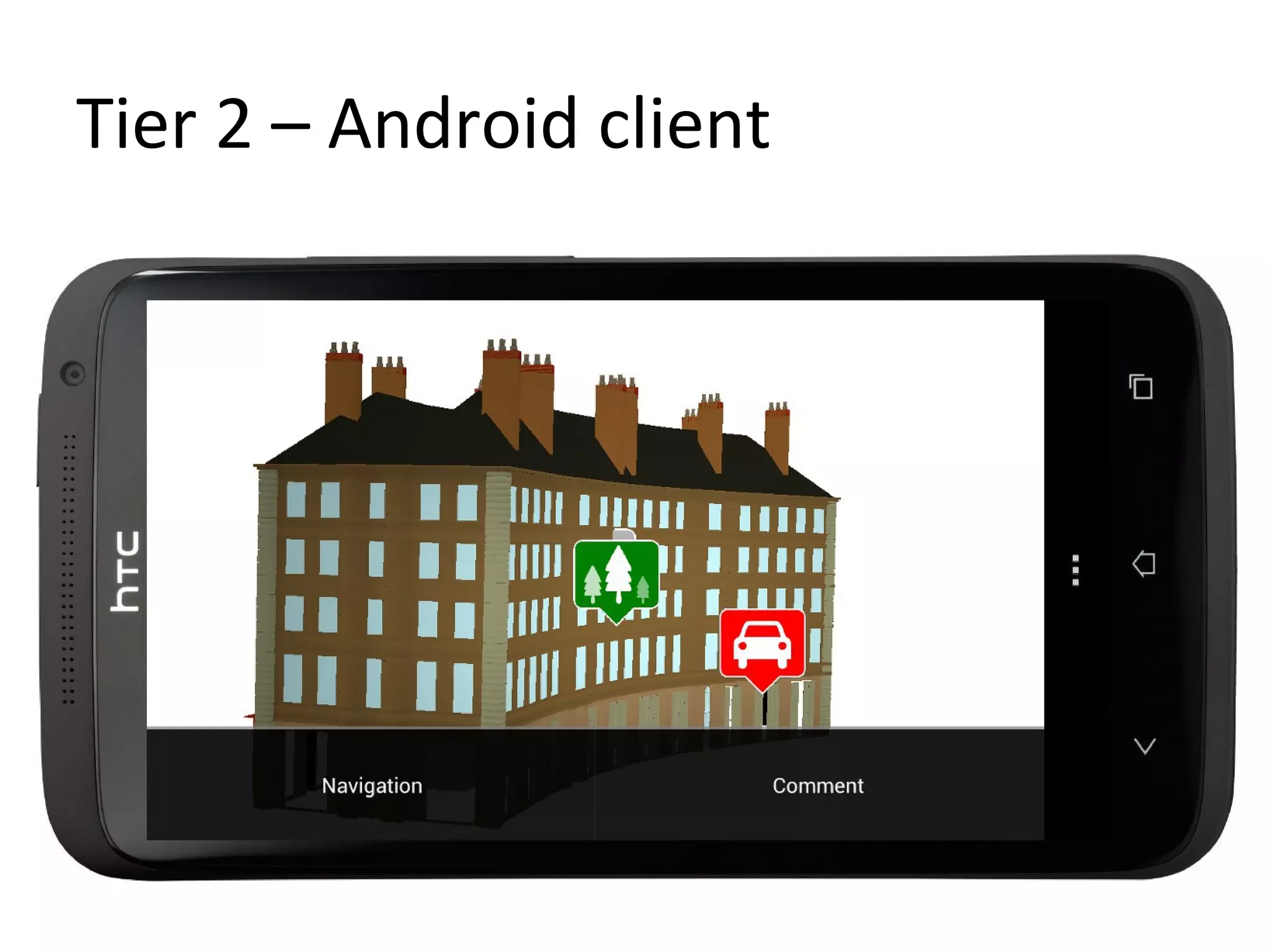
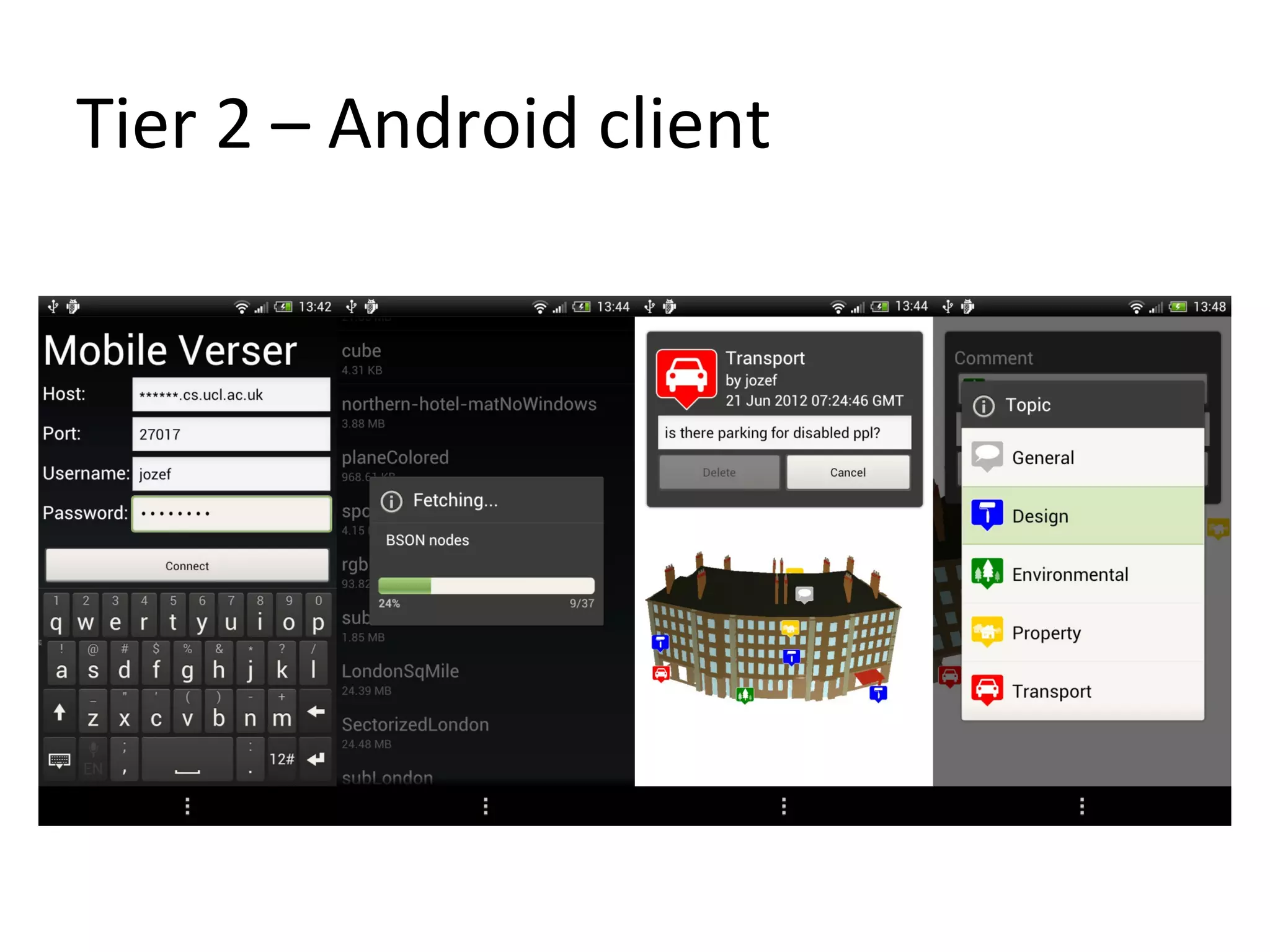






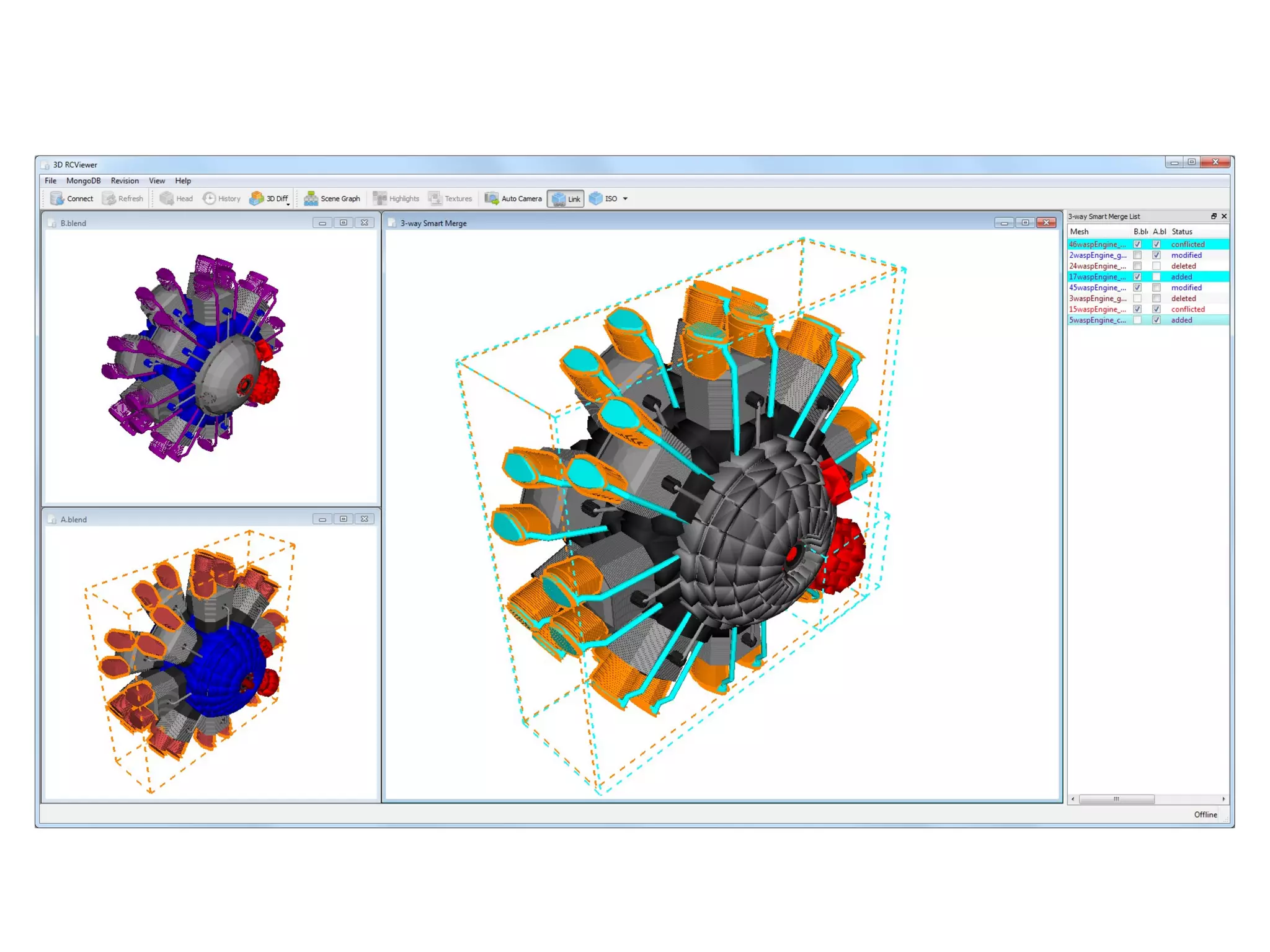
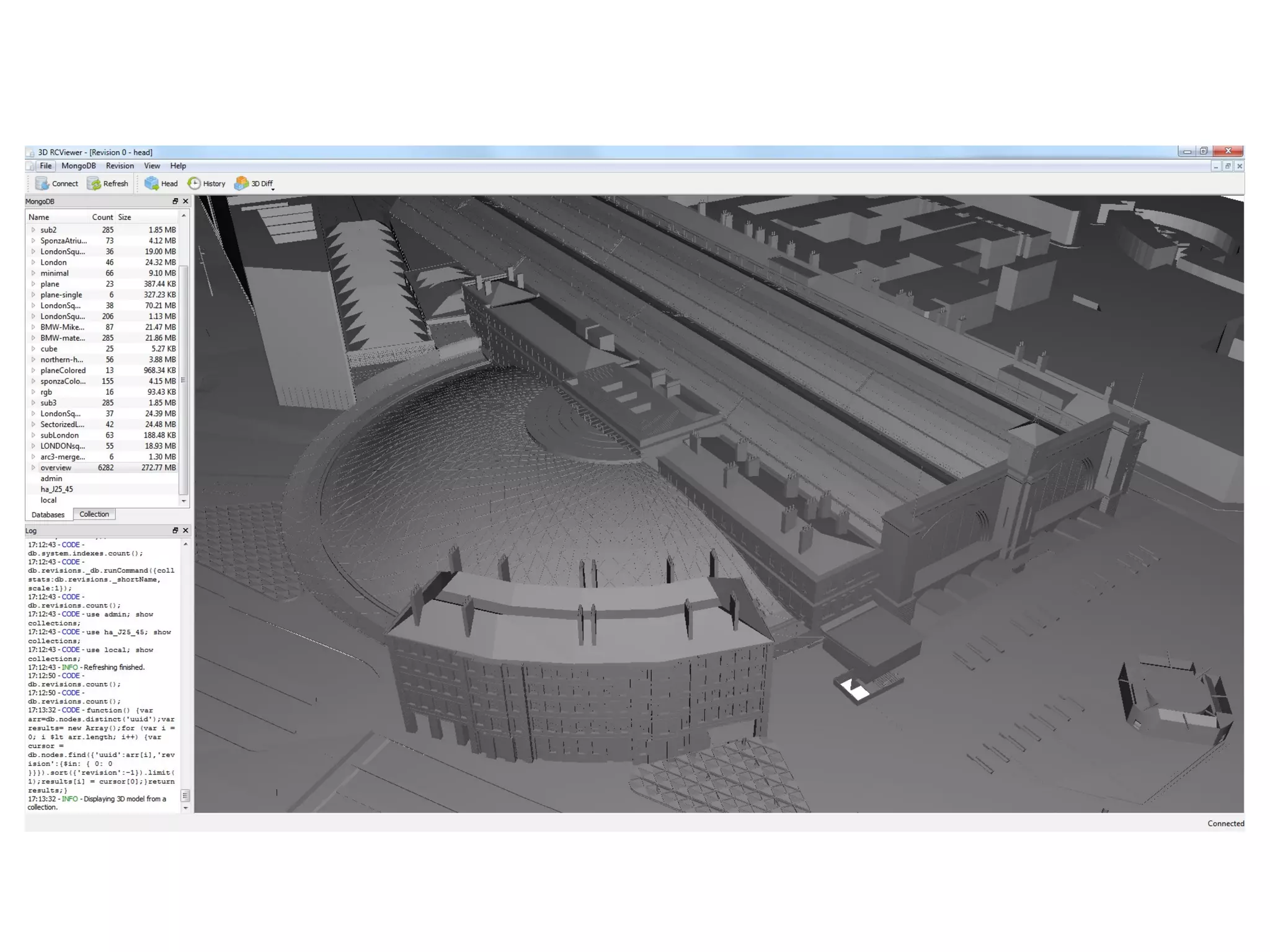


The document presents a 3D revision control framework that uses MongoDB as a central repository to store and retrieve scene graph components and their non-linear revision history. It supports various clients including C++, WebGL, and Android applications. Scene graphs and revision histories are stored as documents in MongoDB collections in a schema that embeds metadata and component data or references binary data. The framework enables collaborative editing of 3D models through version control of hierarchical scene graphs.



















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)

































