This document provides information about MongoDB, including:
- MongoDB is a non-SQL database that stores data as flexible documents rather than rows and tables. It is suitable for large, unstructured datasets.
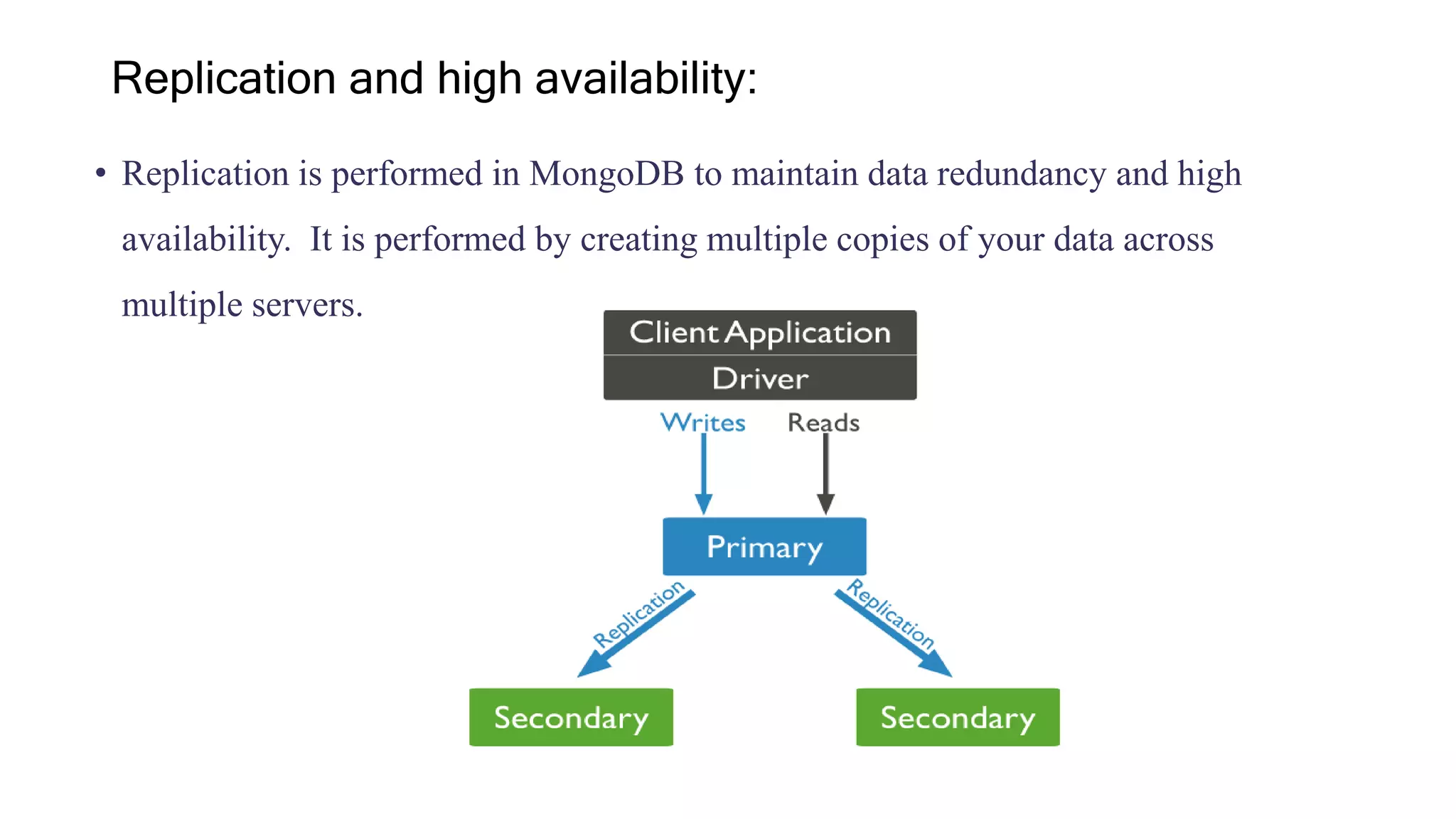
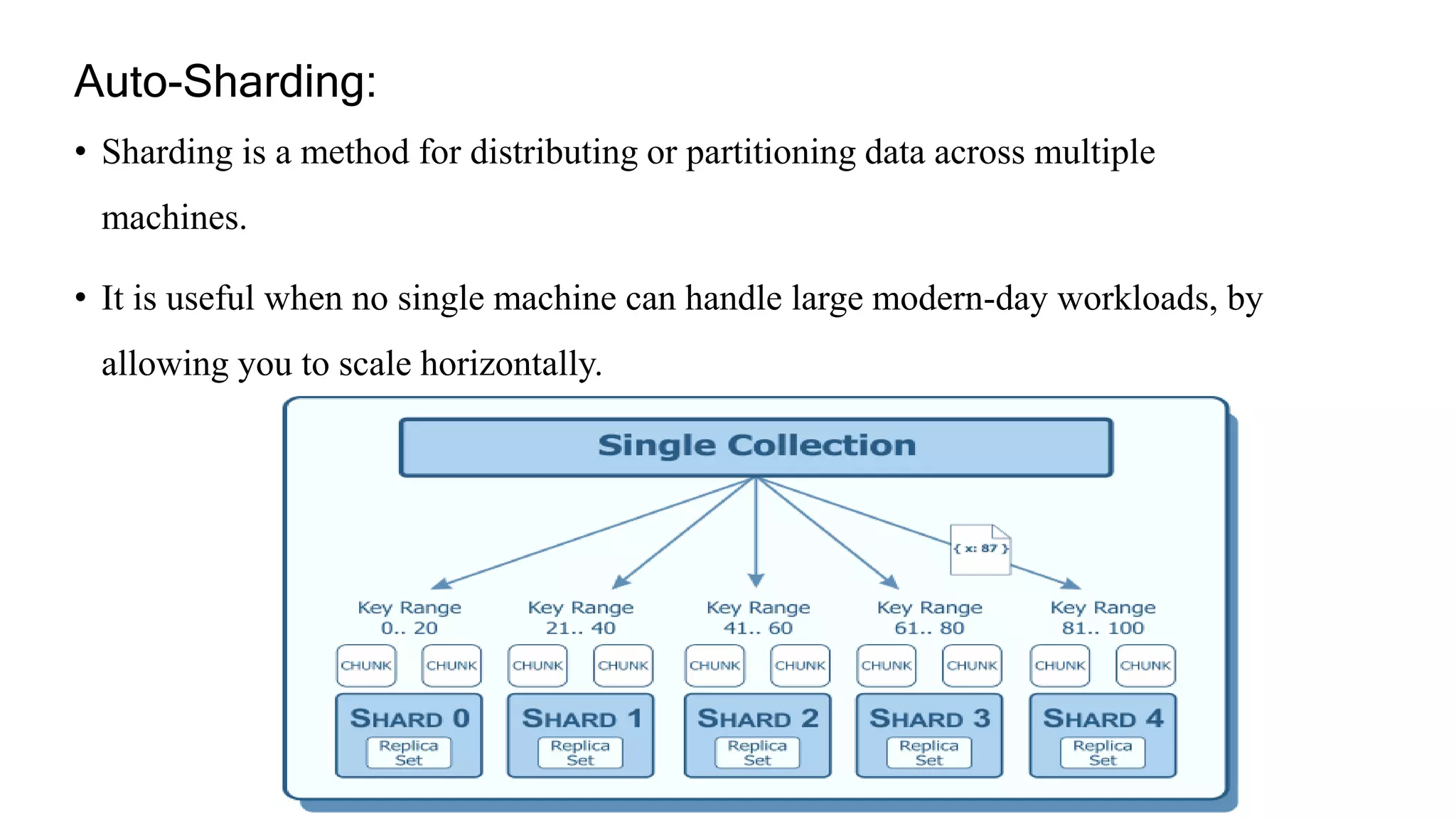
- Key features include document-oriented storage, full indexing support, replication for high availability, auto-sharding for scalability, and querying capabilities.
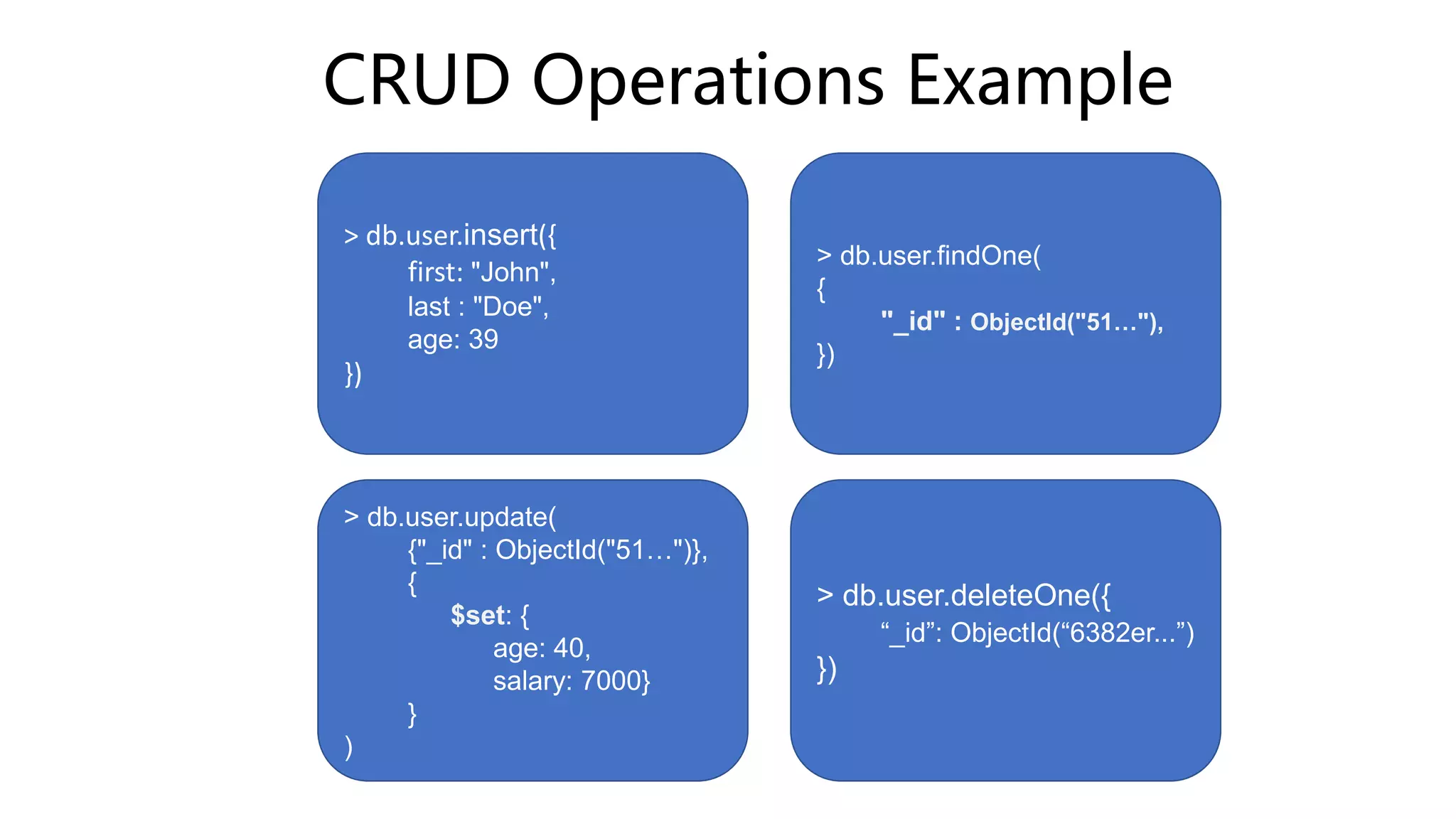
- CRUD operations like insert, find, update, and delete can be performed on MongoDB collections and documents using methods like db.collection.insert() and db.collection.find(). Aggregation operations allow computing results by processing documents.
![MongoDB
{
By:
[
“Shirish Kulkarni”,
“Sagar Pol”
]
}](https://image.slidesharecdn.com/mongodbppt-230404172647-98b88135/75/MongoDB_ppt-pptx-1-2048.jpg)







![Example of Document
> db.user.findOne({age:39})
{
"_id" : ObjectId("5114e0bd42…"),
"first" : "John",
"last" : "Doe",
"age" : 39,
"interests" : [
"Reading",
"Mountain Biking ]
"favorites": {
"color": "Blue",
"sport": "Soccer"}
}](https://image.slidesharecdn.com/mongodbppt-230404172647-98b88135/75/MongoDB_ppt-pptx-12-2048.jpg)


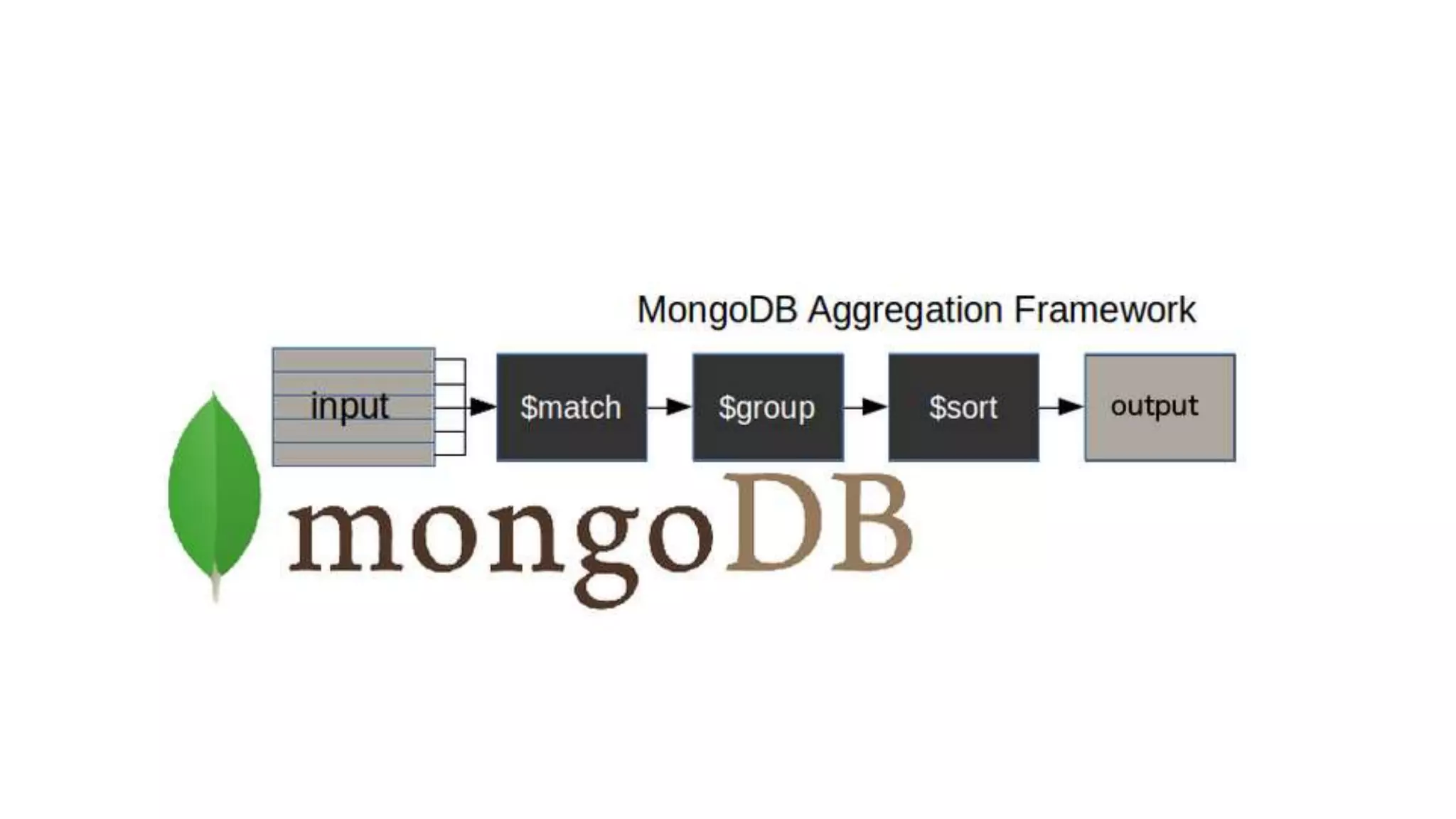
![Aggregation Syntax
Basic syntax of aggregate() method is as follows −
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
Example:
db.collection.aggregate([ {stage1}, {stage2}, {stage3}...])
• There is a set of possible stages and each of those is taken as a set of documents
as an input and produces a resulting set of documents (or the final resulting JSON
document at the end of the pipeline)](https://image.slidesharecdn.com/mongodbppt-230404172647-98b88135/75/MongoDB_ppt-pptx-17-2048.jpg)


















































