Download as PDF, PPTX



![JavaScript Object Literals
JSON serializable
values (aka JSON
Infoset)
{
"locations":
[
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarter": "Belgium",
"exports":[{ "city": "Moscow" },{ "city": "Athens"}]
}
locations headquarter exports
0 1
country
Germany
city
Berlin
country
France
city
Paris
city
Moscow
city
Athens
Belgium 0 1
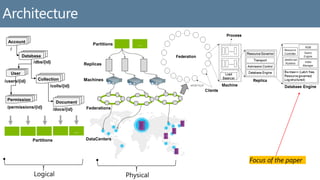
• Automatic indexing of document trees without
requiring schema or secondary indices
• SQL and JavaScript query processing on the trees
• Lazy materialization of JavaScript values from the
instances of trees
JSON document as tree
Schema-agnostic indexing](https://image.slidesharecdn.com/p1668-shukla-presentation-150902085842-lva1-app6891/85/Schema-Agnostic-Indexing-with-Azure-DocumentDB-5-320.jpg)
![Query
{
"results":
[
{
"locations":
[
{"country":"Germany","city":"Berlin"},
{"country":"France","city":"Paris"}
]
}
]
}
{ "locations":
[ { "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarter": "Belgium",
"exports": [{ "city": "Moscow" }, { "city": "Athens" }]
}
{ "locations": [{ "country": "Germany", "city": "Bonn", "revenue": 200 } ],
"headquarter": "Italy",
"exports": [ { "city": "Berlin","dealers": [{"name": "Hans"}] }, { "city": "Athens" }
]
}
locations headquarter exports
0 1
country
Germany
city
Berlin
country
France
city
Paris
city
Moscow
city
Athens
Belgium
locations headquarter
0
country
Germany
city
Bonn
revenue
200
Italy
0 1
exports
city
Berlin
city
Athens
0
1
dealers
0
Hans
name
0
locations
0 1
country
Germany
city
Berlin
country
France
city
Paris
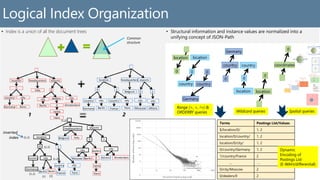
SELECT C.locations
FROM company C
WHERE C.headquarter = "Belgium"
results
Query result
Input documents
function businessLogic() {
var country = "Belgium";
__.filter(function(x){return x.headquarter===country;});}
SQL JavaScript](https://image.slidesharecdn.com/p1668-shukla-presentation-150902085842-lva1-app6891/85/Schema-Agnostic-Indexing-with-Azure-DocumentDB-7-320.jpg)

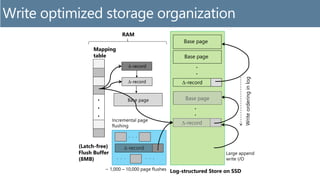



- DocumentDB is a fully managed NoSQL database service that provides automatic indexing of JSON documents without requiring schemas (schema agnostic). - It uses a logical index that maps JSON paths to postings lists containing document identifiers. This index is implemented using a physical write-optimized architecture with blind updates and value merging to support high write volumes. - The physical index uses a log-structured storage approach with delta records, mapping tables, and page stubs to allow for highly concurrent updates while minimizing I/O overhead during index maintenance.






![[PASS Summit 2016] Azure DocumentDB: A Deep Dive into Advanced Features](https://cdn.slidesharecdn.com/ss_thumbnails/passdocdbadvfeatures-161029023827-thumbnail.jpg?width=640&height=640&fit=bounds)


































































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)


