Download as PDF, PPTX








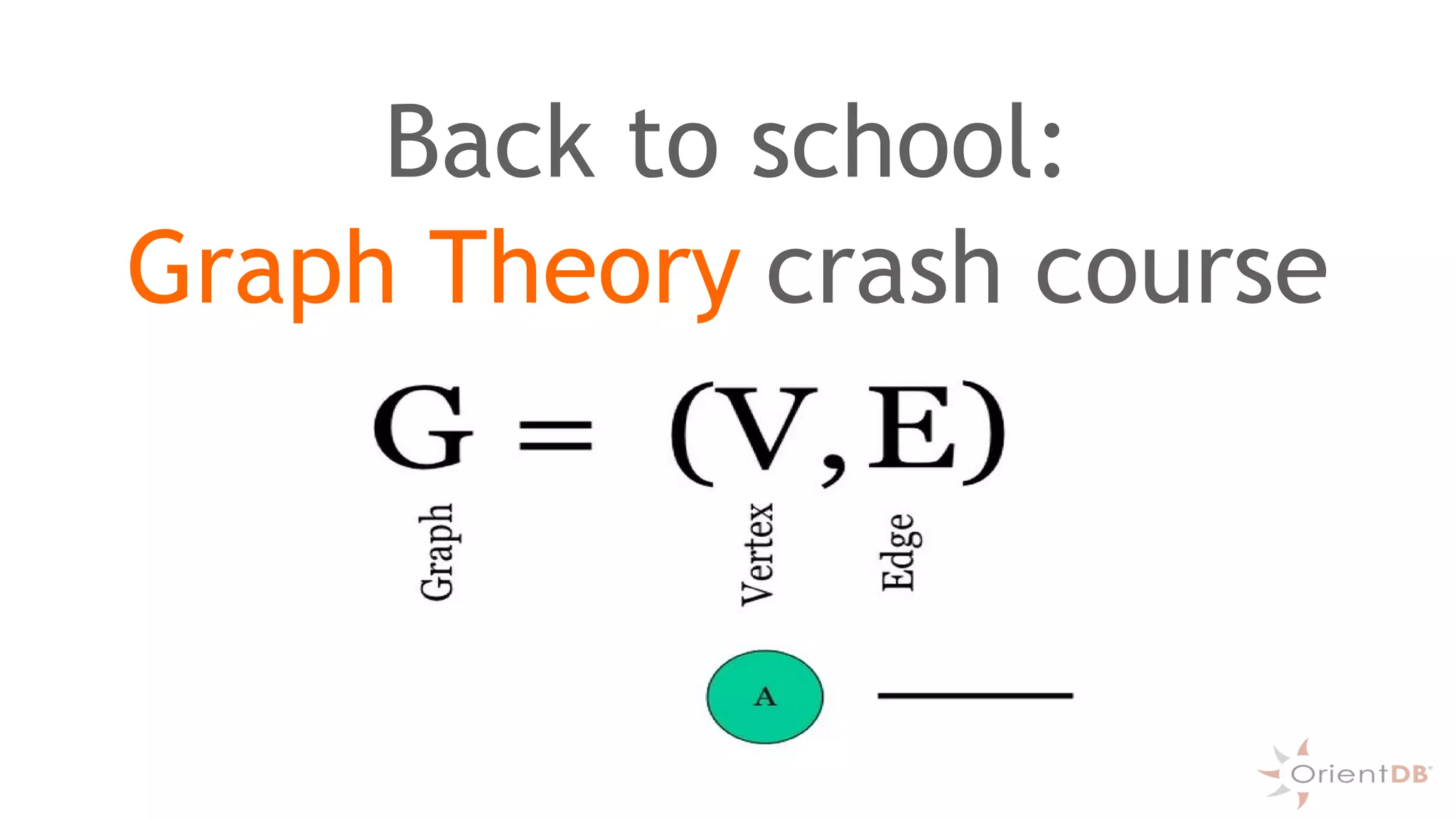












![Multi-field search
CREATE CLASS City EXTENDS V
CREATE PROPERTY City.name STRING
CREATE PROPERTY City.description STRING
CREATE PROPERTY City.size INTEGER
CREATE INDEX City.name_description_size
ON City(name, description,size) FULLTEXT ENGINE LUCENE METADATA {...}
SELECT FROM City
WHERE
SEARCH_CLASS ("name:cas* AND description:piemonte AND size:[20000 TO 40000]" = true](https://image.slidesharecdn.com/bigdatameetupto20170405-170405185655/75/OrientDB-The-2nd-generation-of-multi-model-NoSQL-36-2048.jpg)

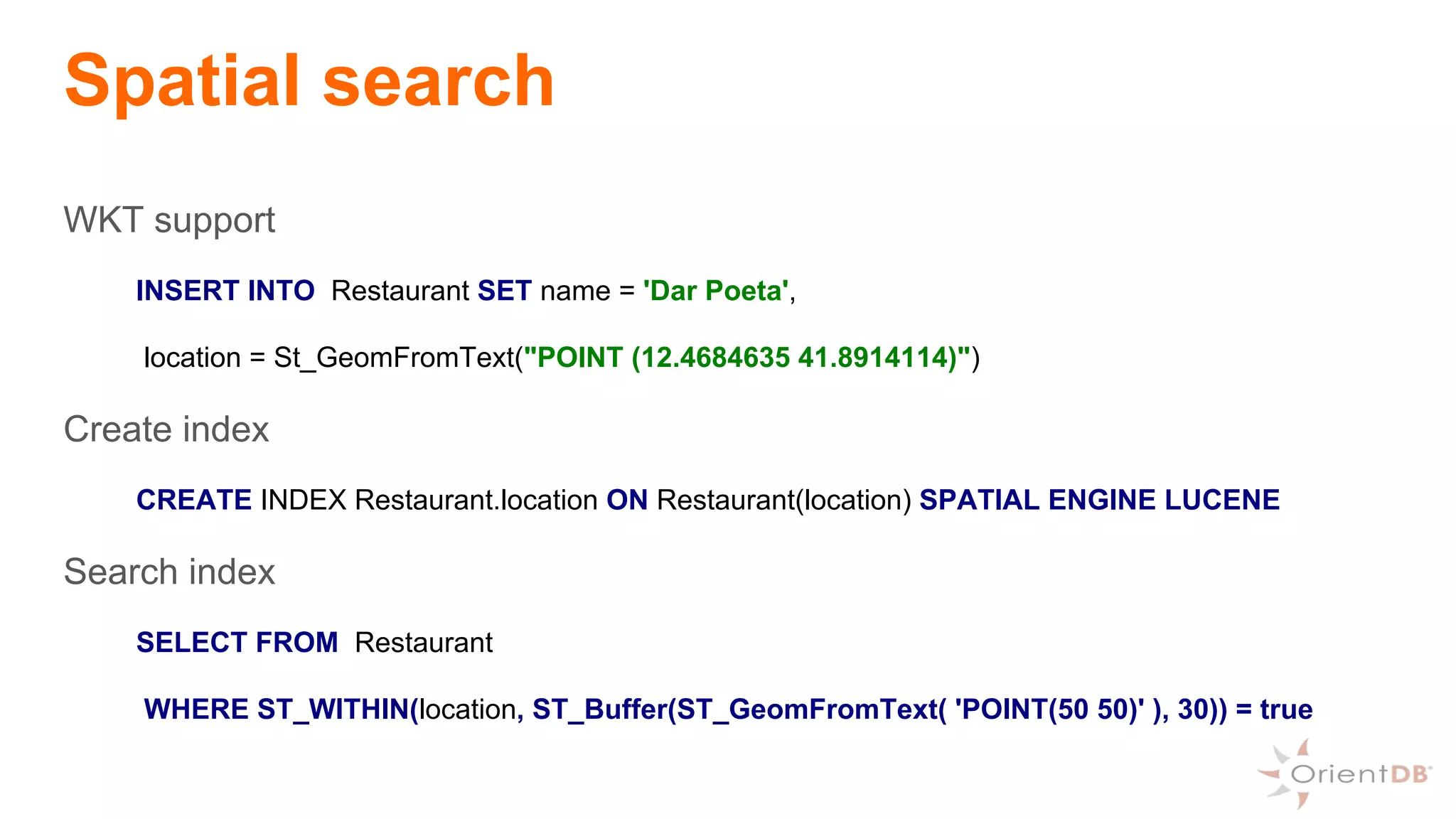
![Spatial search
Add location
CREATE class Restaurant
CREATE PROPERTY Restaurant.name STRING
CREATE PROPERTY Restaurant.location EMBEDDED OPoint
Insert
INSERT INTO Restaurant SET name = 'Dar Poeta',
location = {"@class": "OPoint","coordinates" : [12.4684635,41.8914114]}](https://image.slidesharecdn.com/bigdatameetupto20170405-170405185655/75/OrientDB-The-2nd-generation-of-multi-model-NoSQL-38-2048.jpg)

![Java
orientDB = new OrientDB("remote:localhost", "root", "root", OrientDBConfig.defaultConfig());
pool = new ODatabasePool(orientDB, "demodb", "admin", "admin");
db = pool.acquire();
OResultSet result = db.query(
"SELECT from ArchaeologicalSites where search_fields(['Name'],'foro') = true");
result.vertexStream() .forEach(v-> System.out.println("v = " + v.toJSON()));
db.close();
pool.close();
orientDB.close();](https://image.slidesharecdn.com/bigdatameetupto20170405-170405185655/75/OrientDB-The-2nd-generation-of-multi-model-NoSQL-41-2048.jpg)

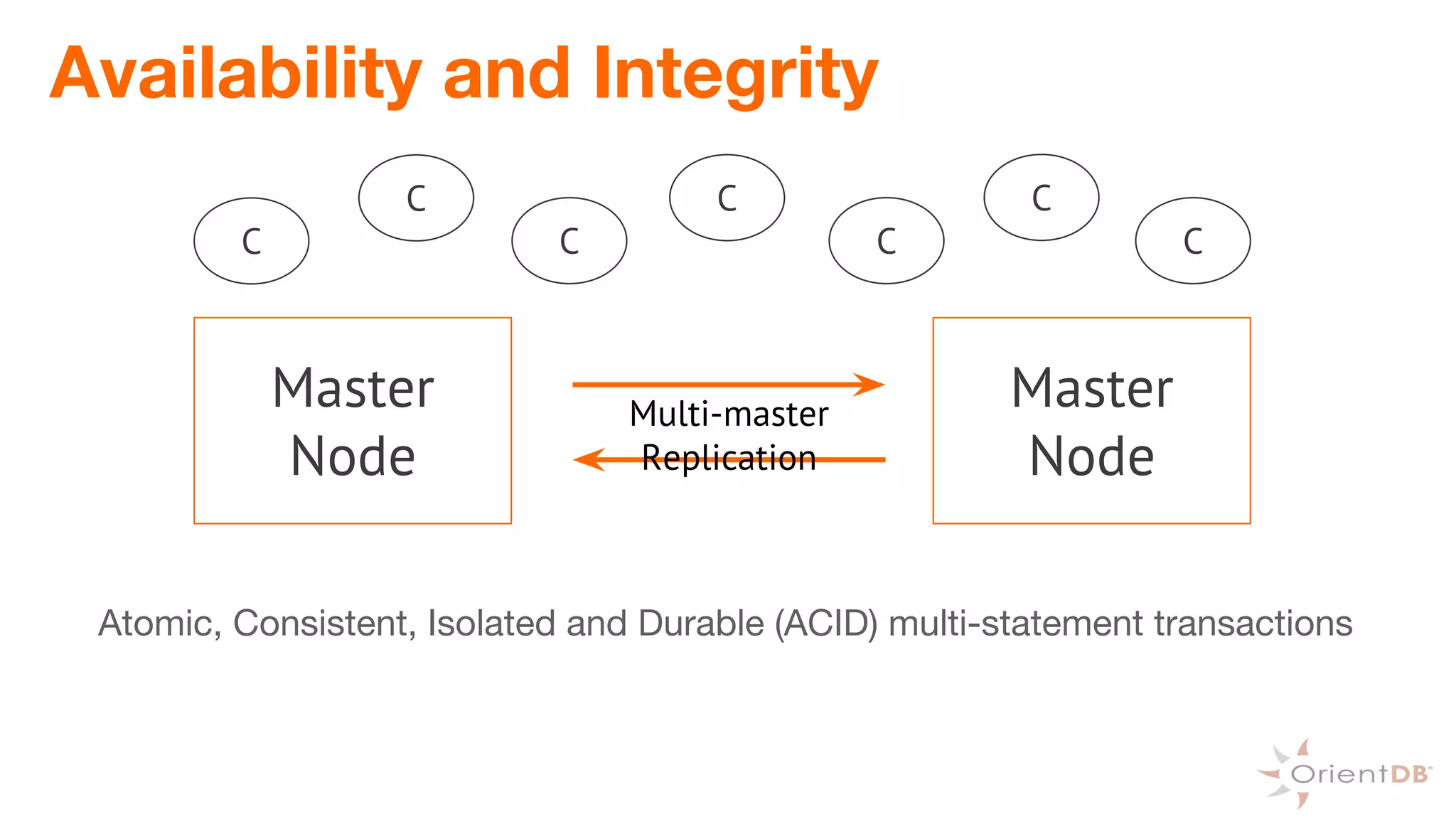
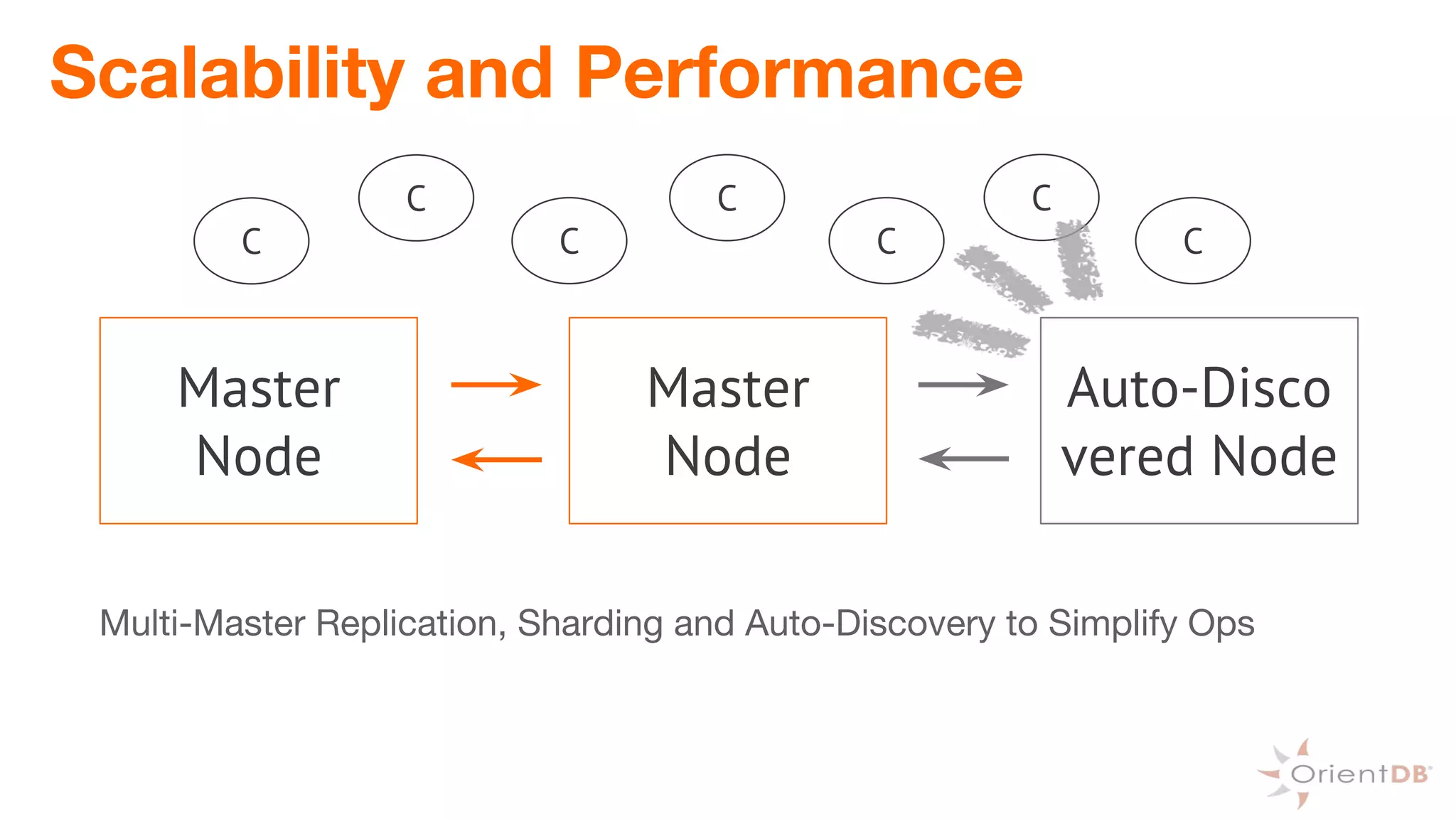
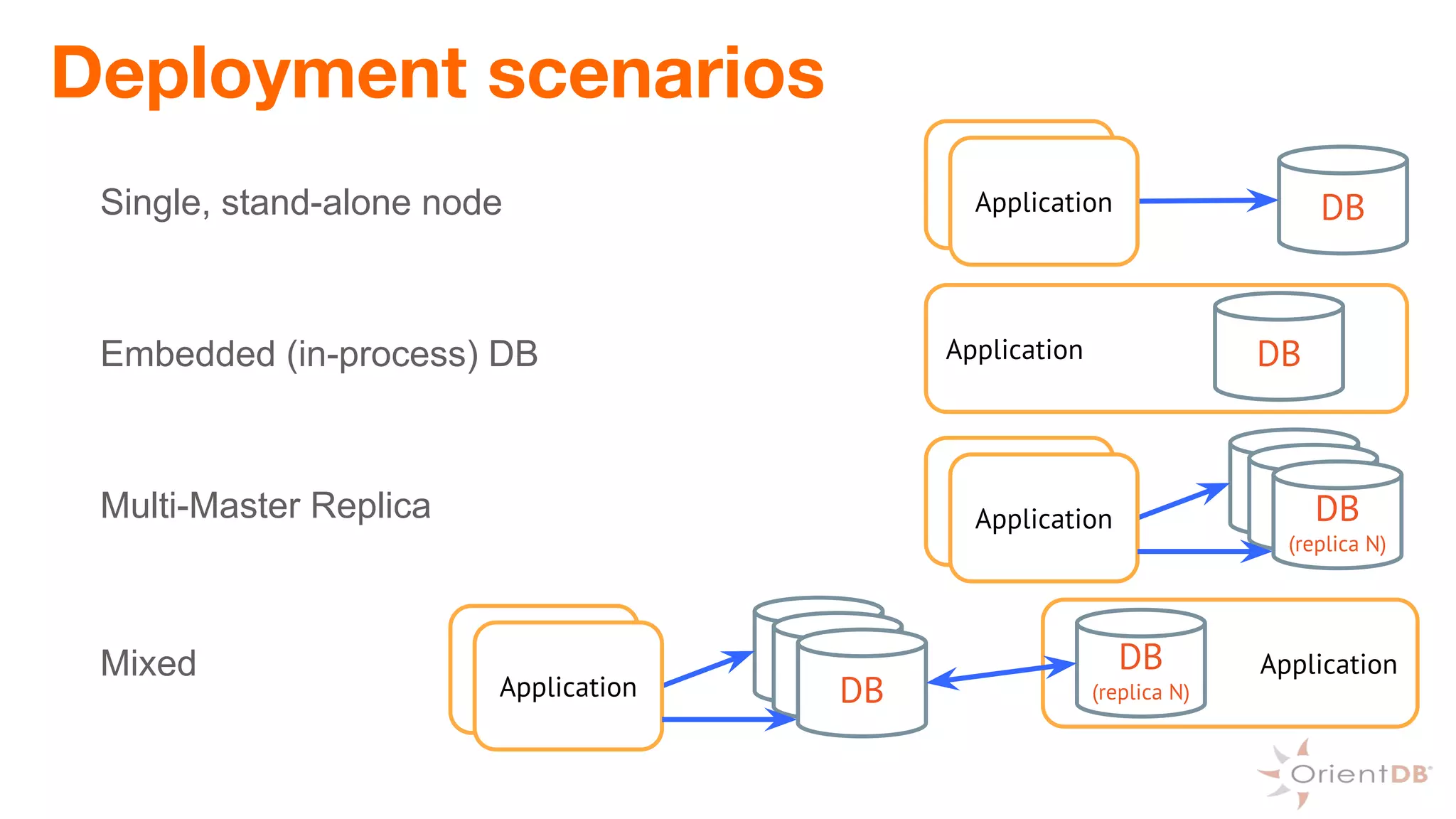

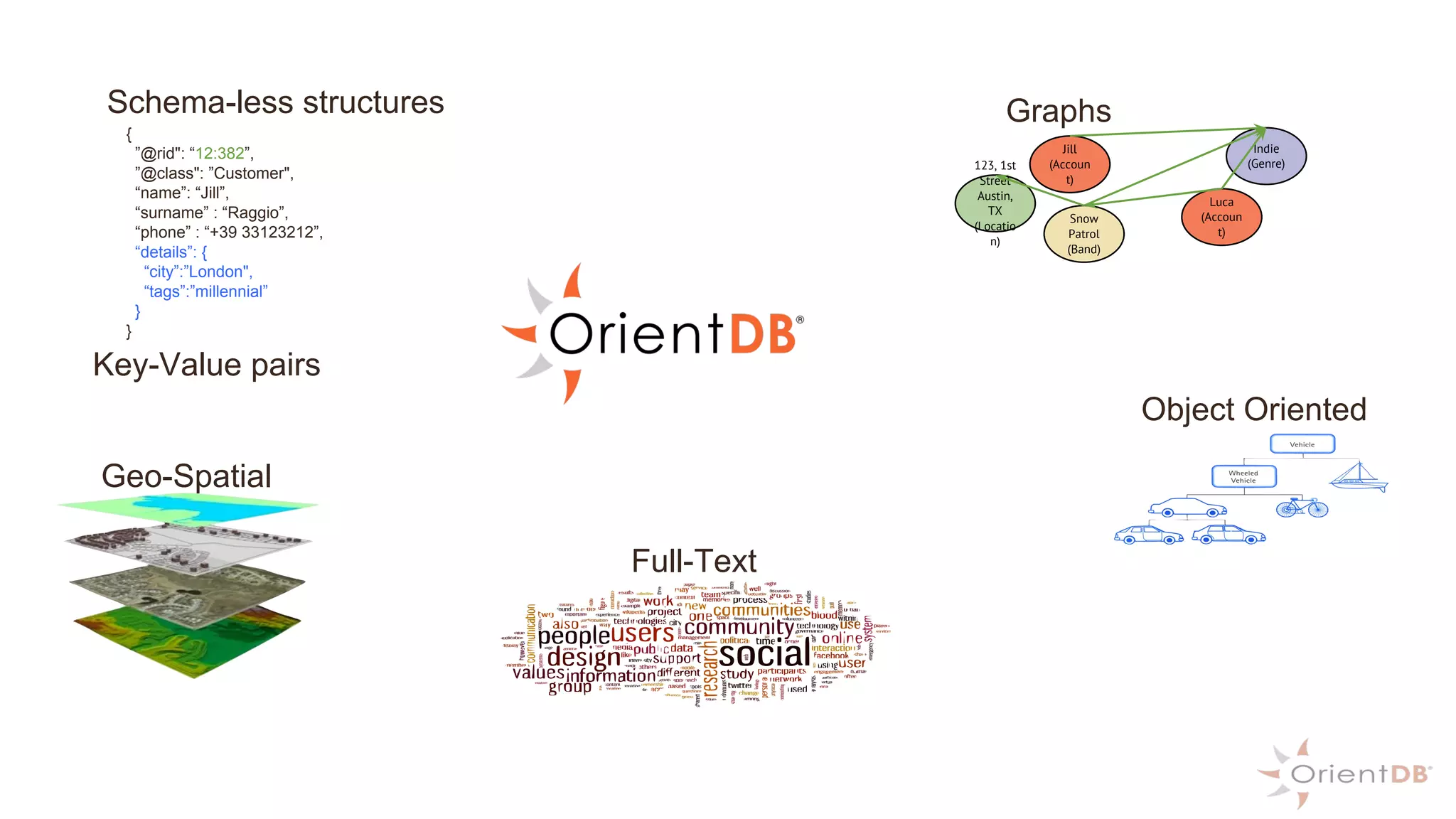
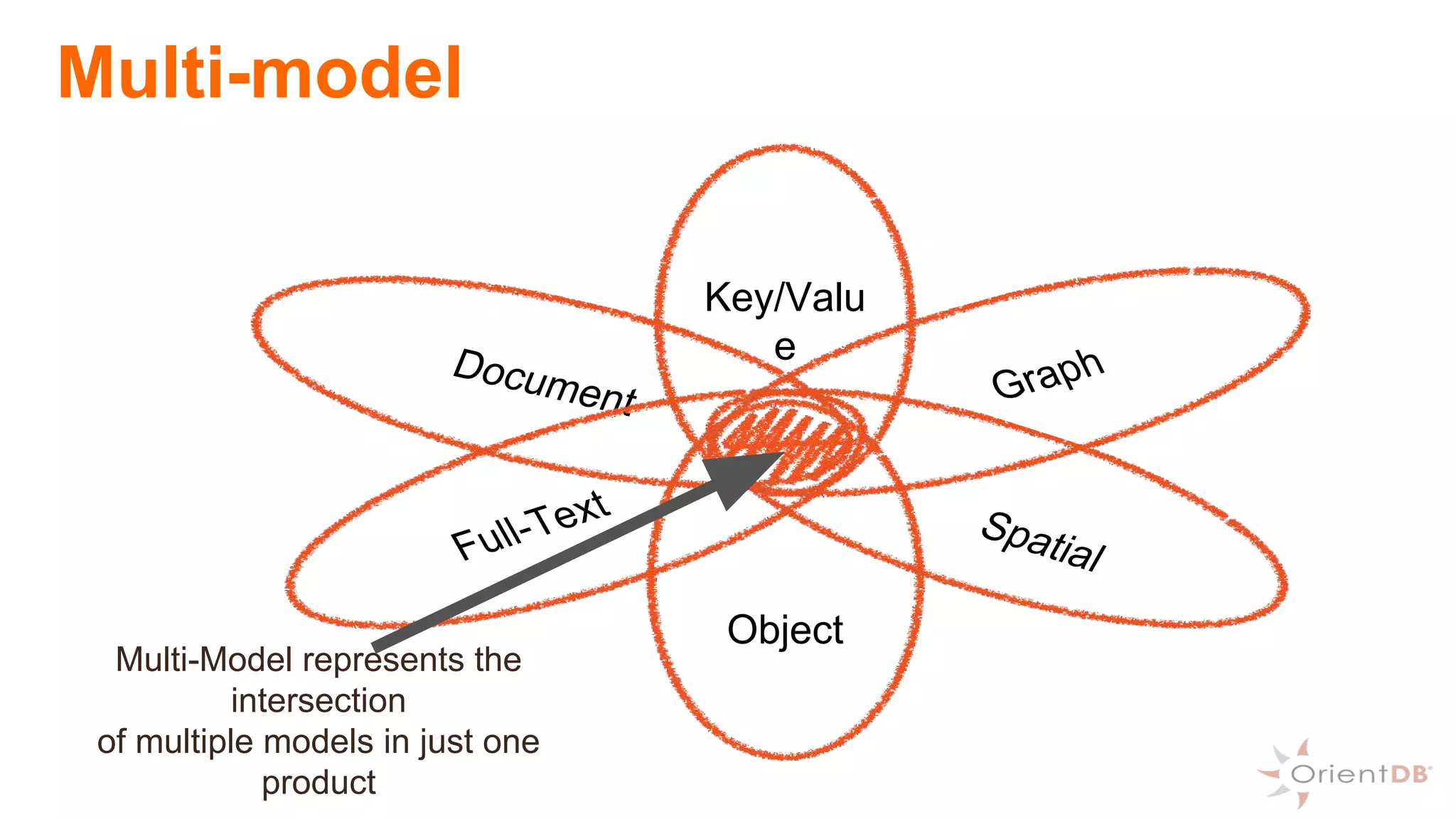








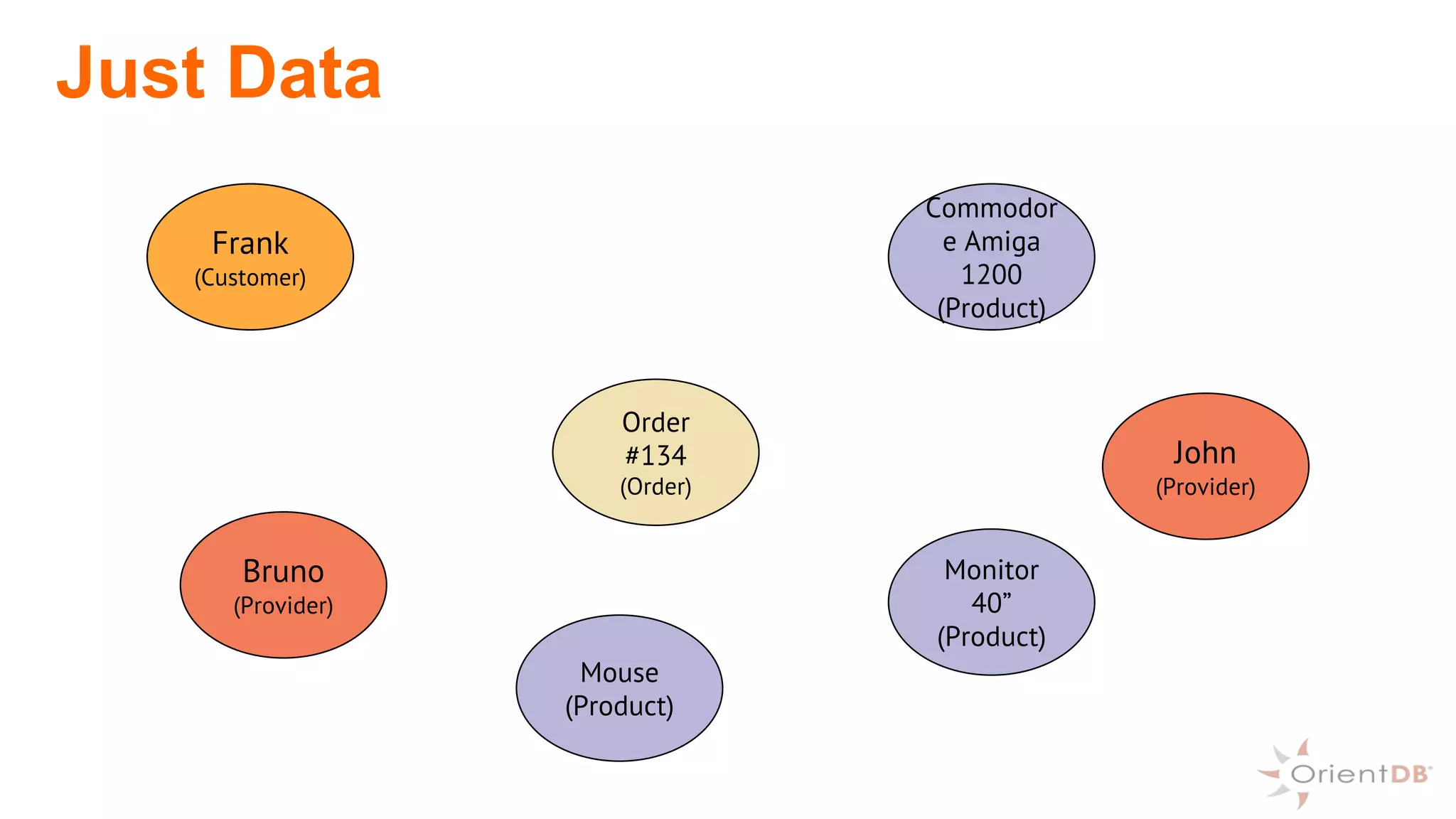
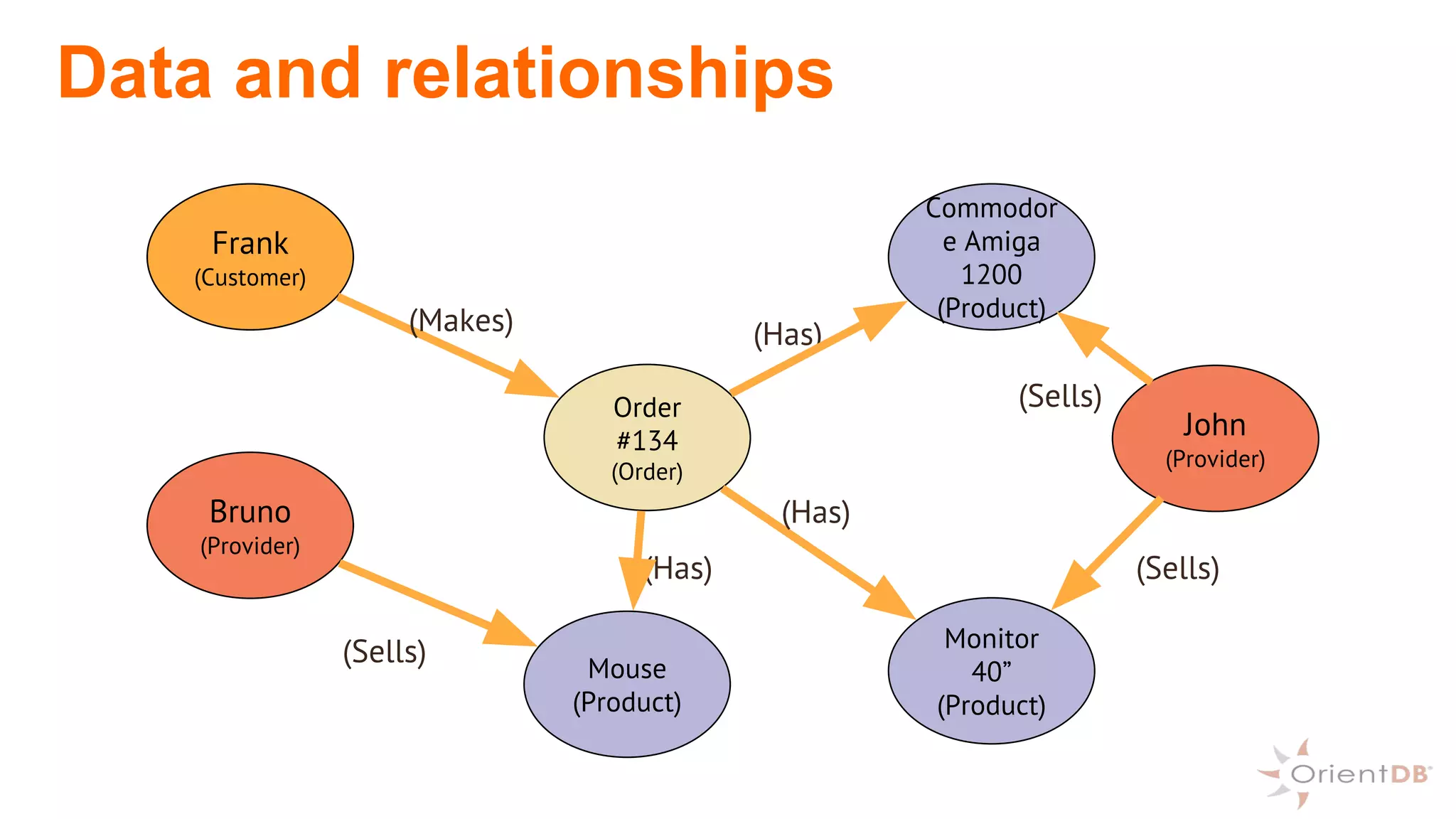
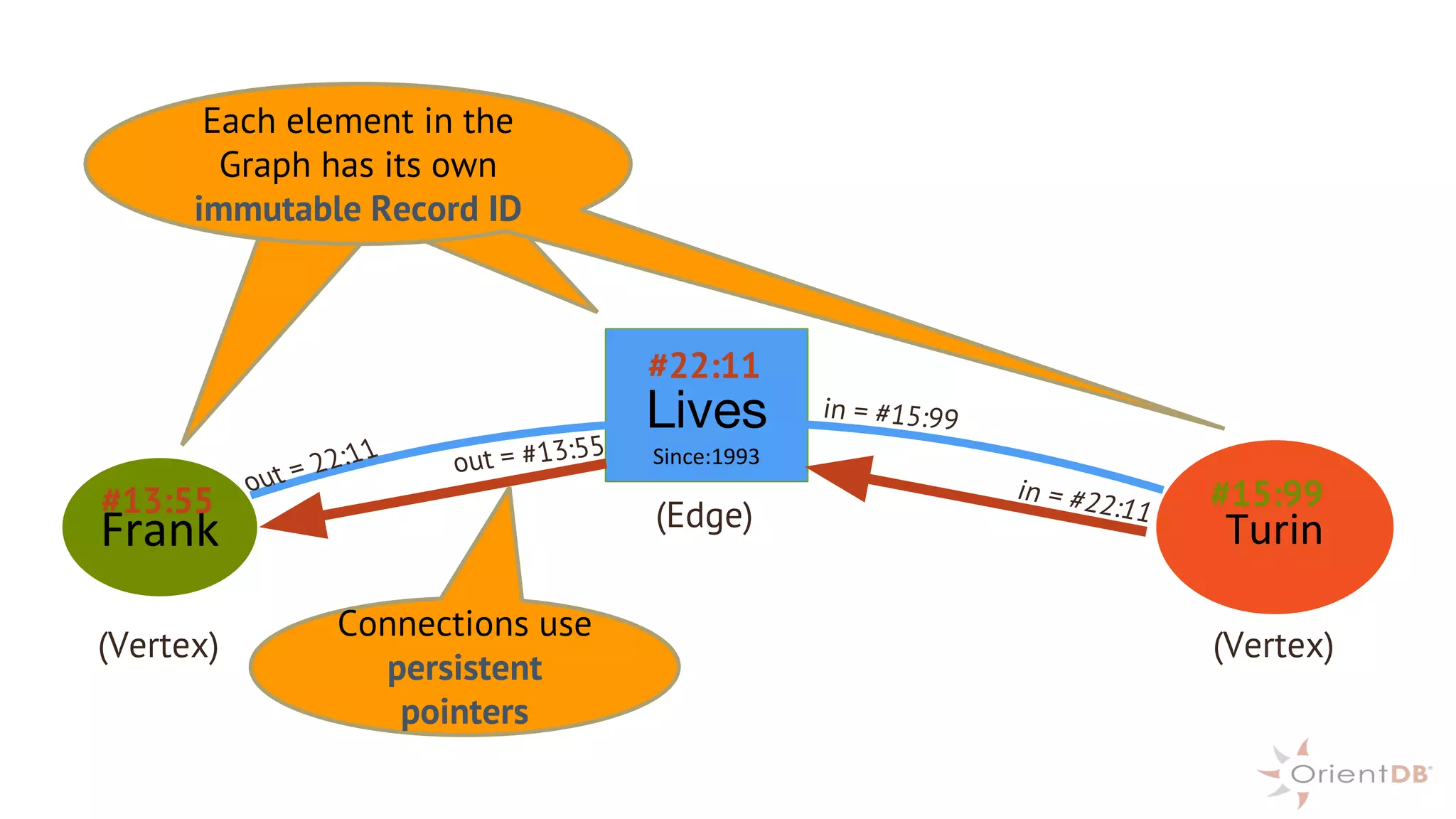
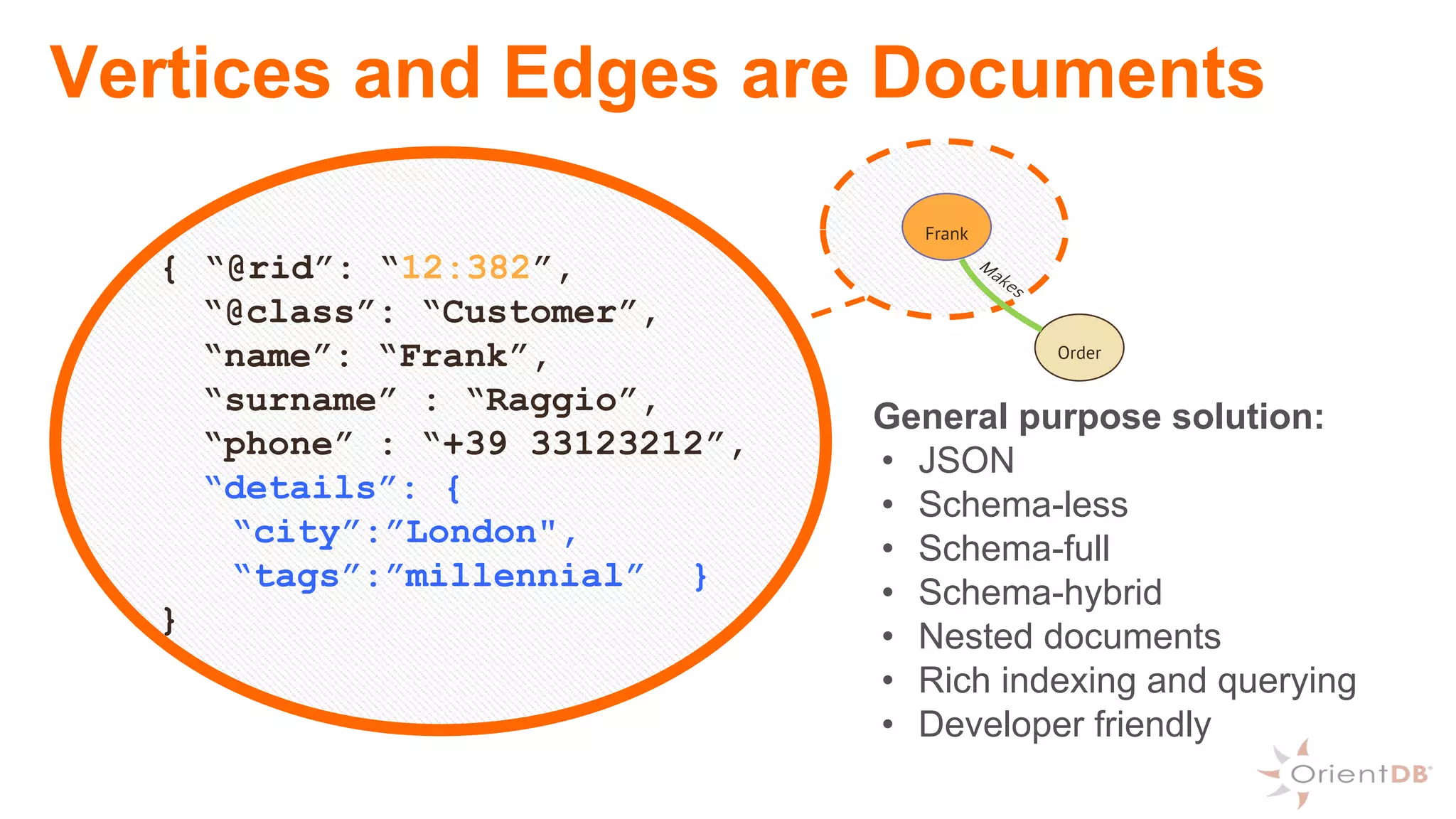
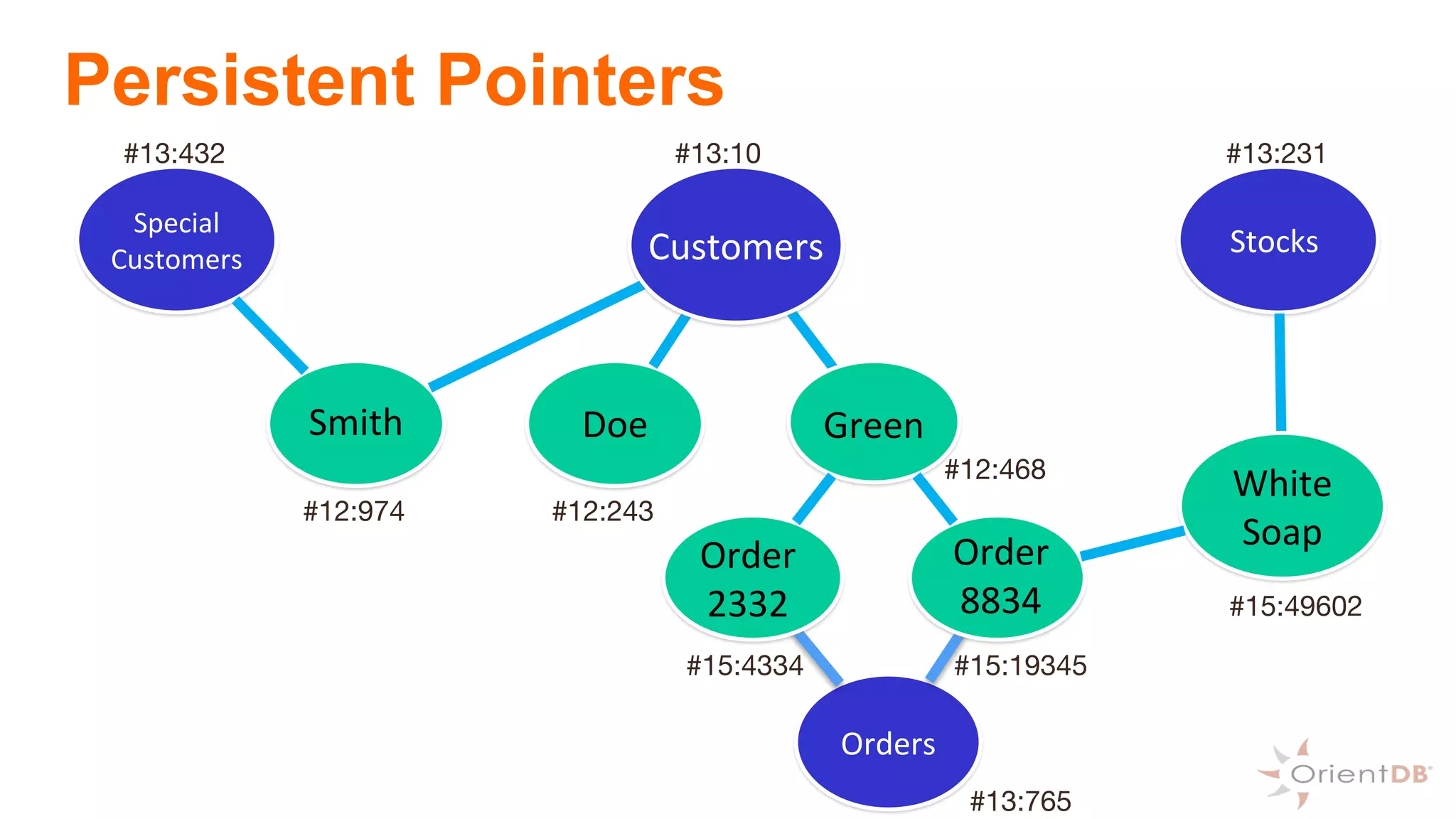
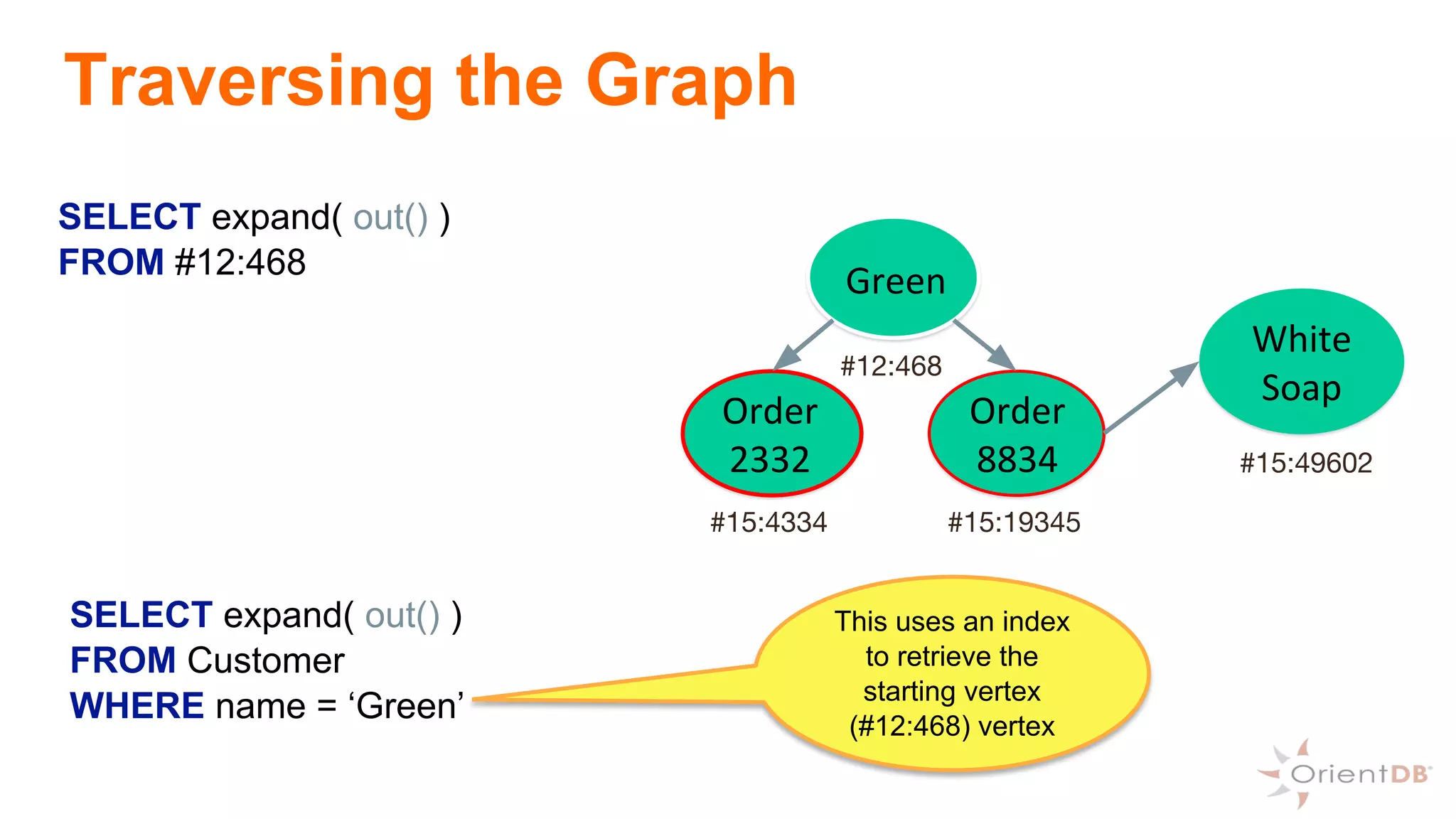
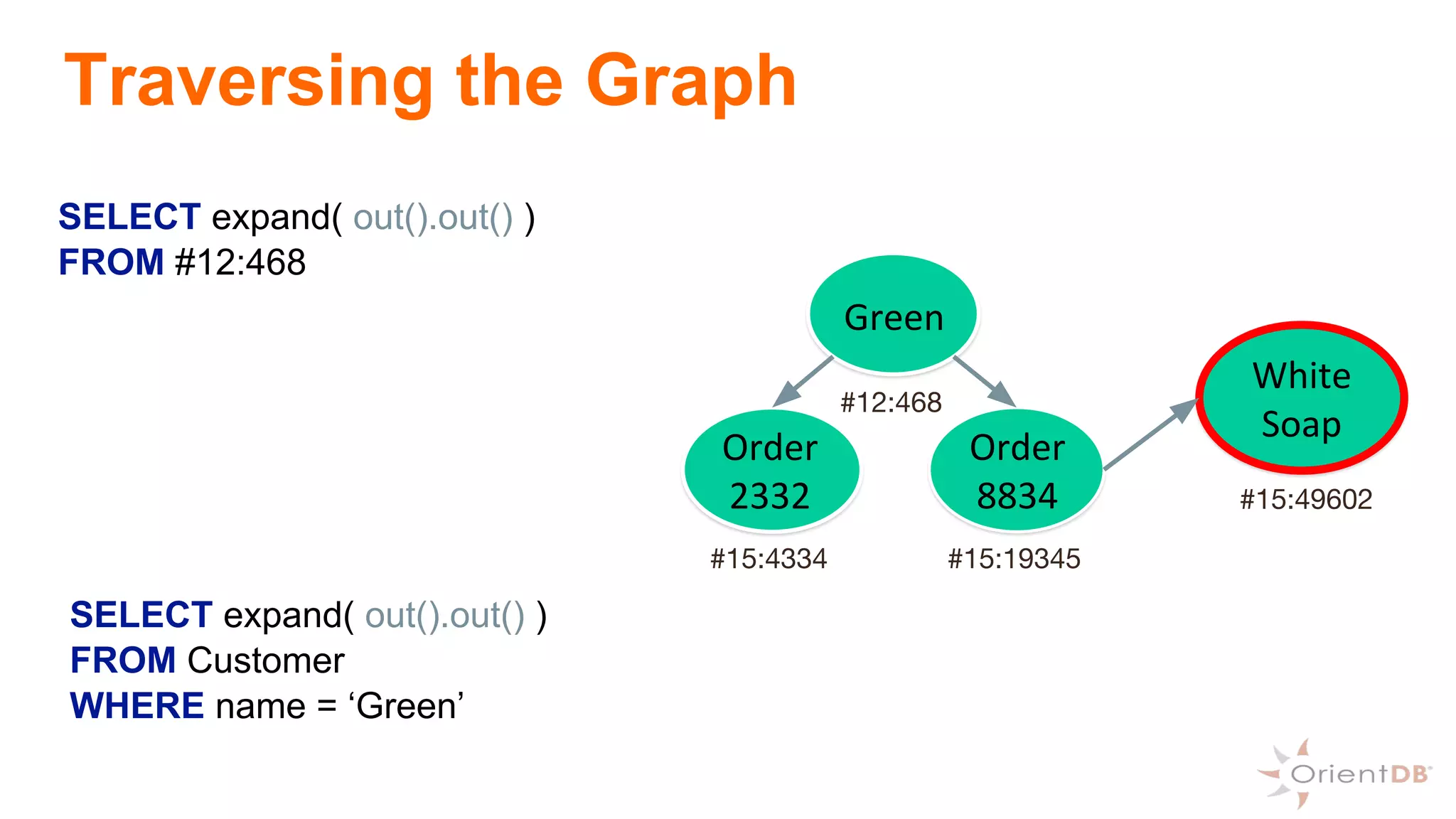
This document provides an overview of OrientDB, a multi-model database that combines features of document, graph, and other databases. It discusses data modeling and schema, querying and traversing graph data, full-text and spatial search, deployment scenarios, and APIs. Examples show creating classes and properties, inserting and querying graph data, and live reactive queries in OrientDB.






















![[Image Results] Java Build Tools: Part 2 - A Decision Maker's Guide Compariso...](https://cdn.slidesharecdn.com/ss_thumbnails/java-build-tools-part-2-maven-gradle-ant-ivy-140121040954-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















