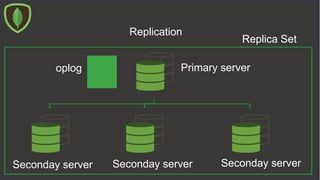
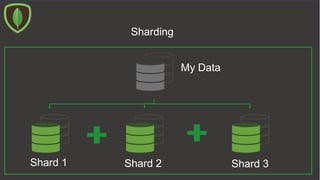
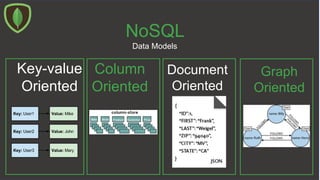
The document provides an overview of MongoDB, a NoSQL database management system, including its data models, CRUD operations, and schema-less data management. It details hands-on operations for creating databases, collections, and documents, as well as performing queries and updates. Additionally, it discusses indexing, replication, and sharding for database optimization and performance monitoring.





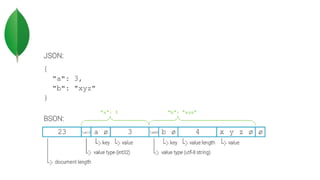
![Document
BSON – Binary JSON.
{
"_id": " 34058 ",
"first_name" : "Ikram",
"last_name": "MANSERI",
"PreferredColors" : ["Black", "White"],
"address" : {"street": 2 , "city" : "Birkhadem"}
}
Fast Scannability
Data Types
Bsonspec.org](https://image.slidesharecdn.com/mongodb-180720102347/85/NoSQL-with-MongoDB-6-320.jpg)
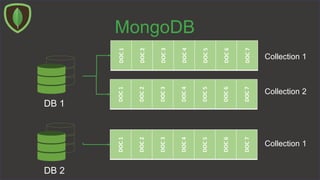
![MongoDB
Schooling
DOC1
DOC2
DOC3
DOC4
DOC5
DOC6
DOC7
Students
{
"_id": " 34058 ",
"first_name" : "Ikram",
"last_name": "MANSERI",
"PreferredColors" : ["Black", "White"],
"address" : {"street": 2 , "city" : "Birkhadem"}
}
{
"_id": " 34059 ",
"first_name" : " Akram",
"last_name": " Beli",
"PreferredColors" : [« Brown", "White"],
"address" : {"street": 3 , "city" : "Birkhadem"}
" Parents_situations " : " divorced " }](https://image.slidesharecdn.com/mongodb-180720102347/85/NoSQL-with-MongoDB-8-320.jpg)



![Visualize the content of your collection « students »:
> db.students.find().pretty()
Insert multiple documents at once in your collection « students » :
> db.students.insert([{“first_name” : “yours”,
“last_name” : “yours”},
{“first_name”: “Amine”, “last_name” : “Ali”, “age”
: 45}])](https://image.slidesharecdn.com/mongodb-180720102347/85/NoSQL-with-MongoDB-13-320.jpg)
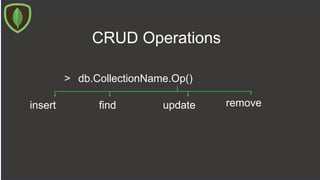
![CRUD Operations
> db.CollectionName.insert ({doc} / [{},{}],
…{writeConcern: {doc},
…ordered: true/false }
)](https://image.slidesharecdn.com/mongodb-180720102347/85/NoSQL-with-MongoDB-16-320.jpg)












![db.collection.ensureIndex({loc:”2dsphere”})
Geospatial indexes
db.collection.find({loc: {$near : {
geometry : {
{type : “Point”, coordinates : [2,3]},
spherique : true }
}
})](https://image.slidesharecdn.com/mongodb-180720102347/85/NoSQL-with-MongoDB-31-320.jpg)