Downloaded 123 times






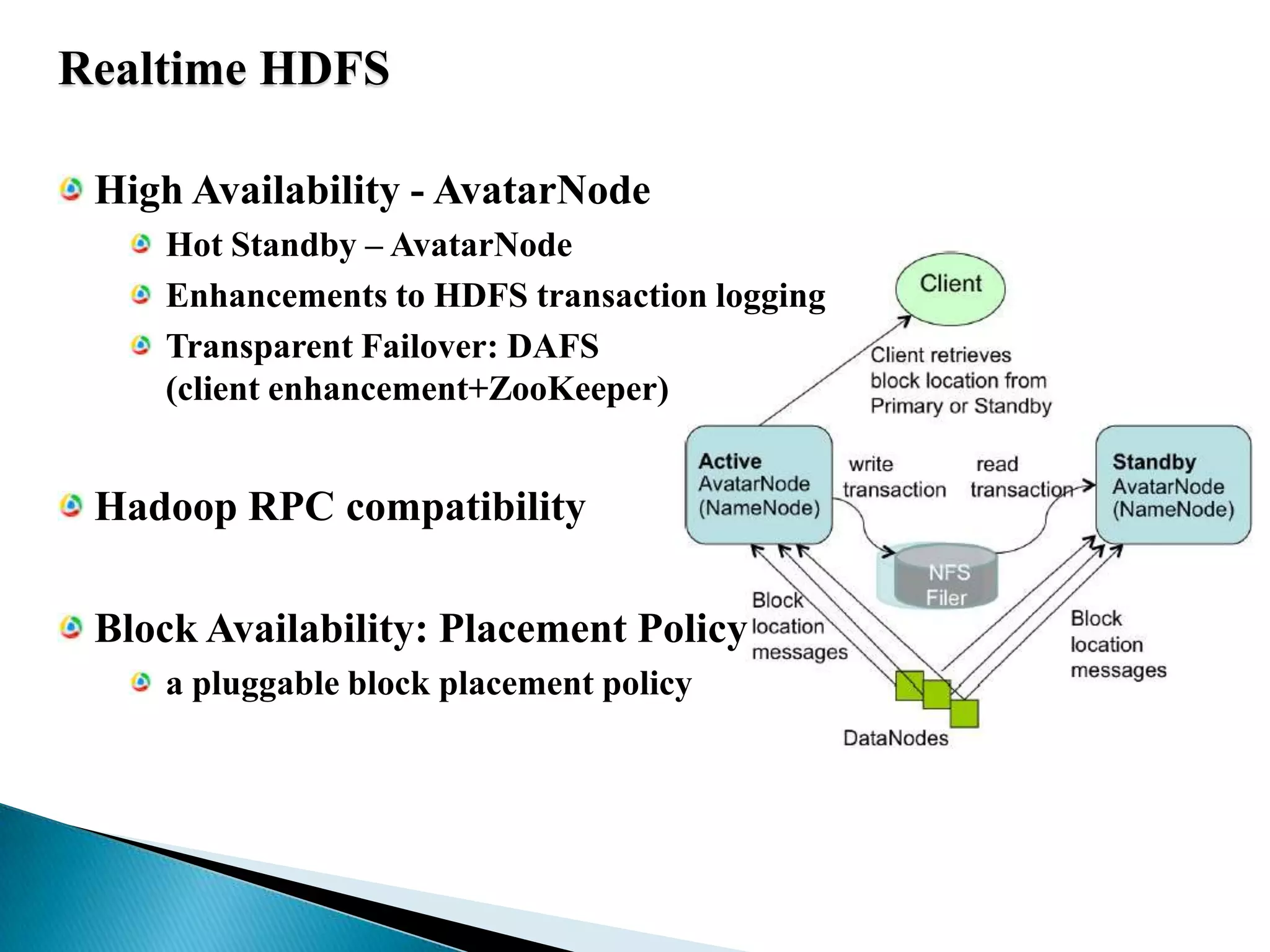





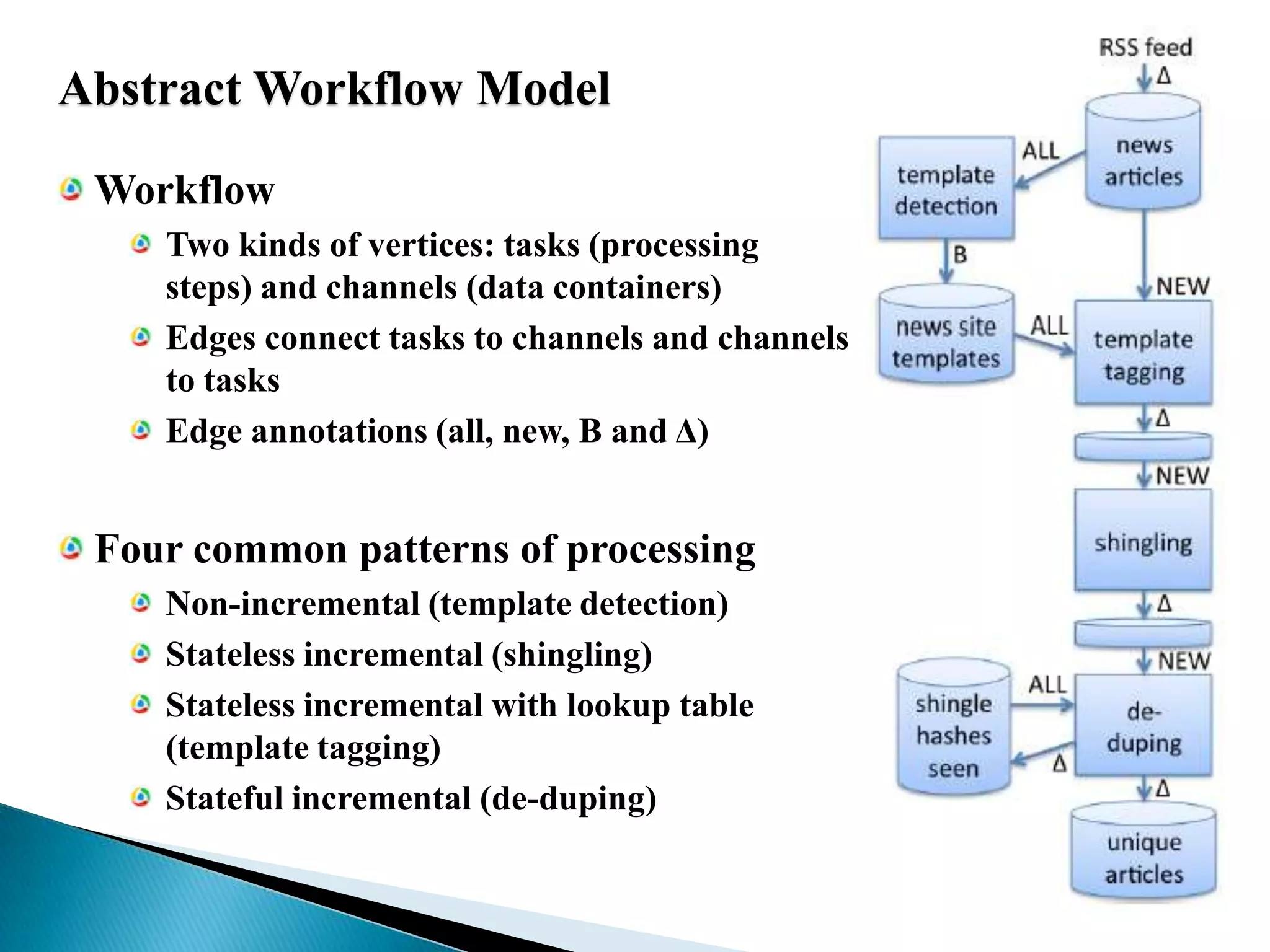

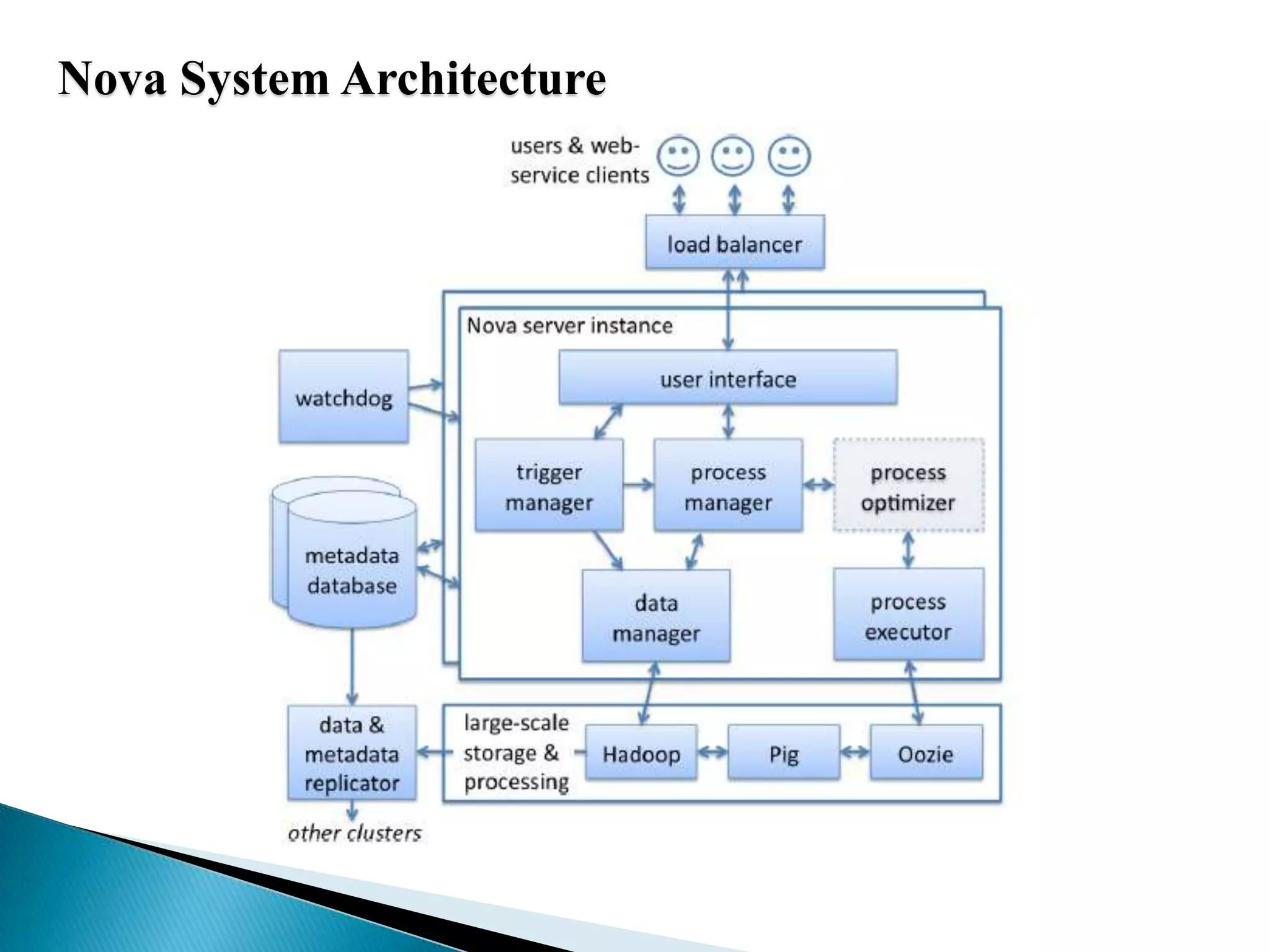


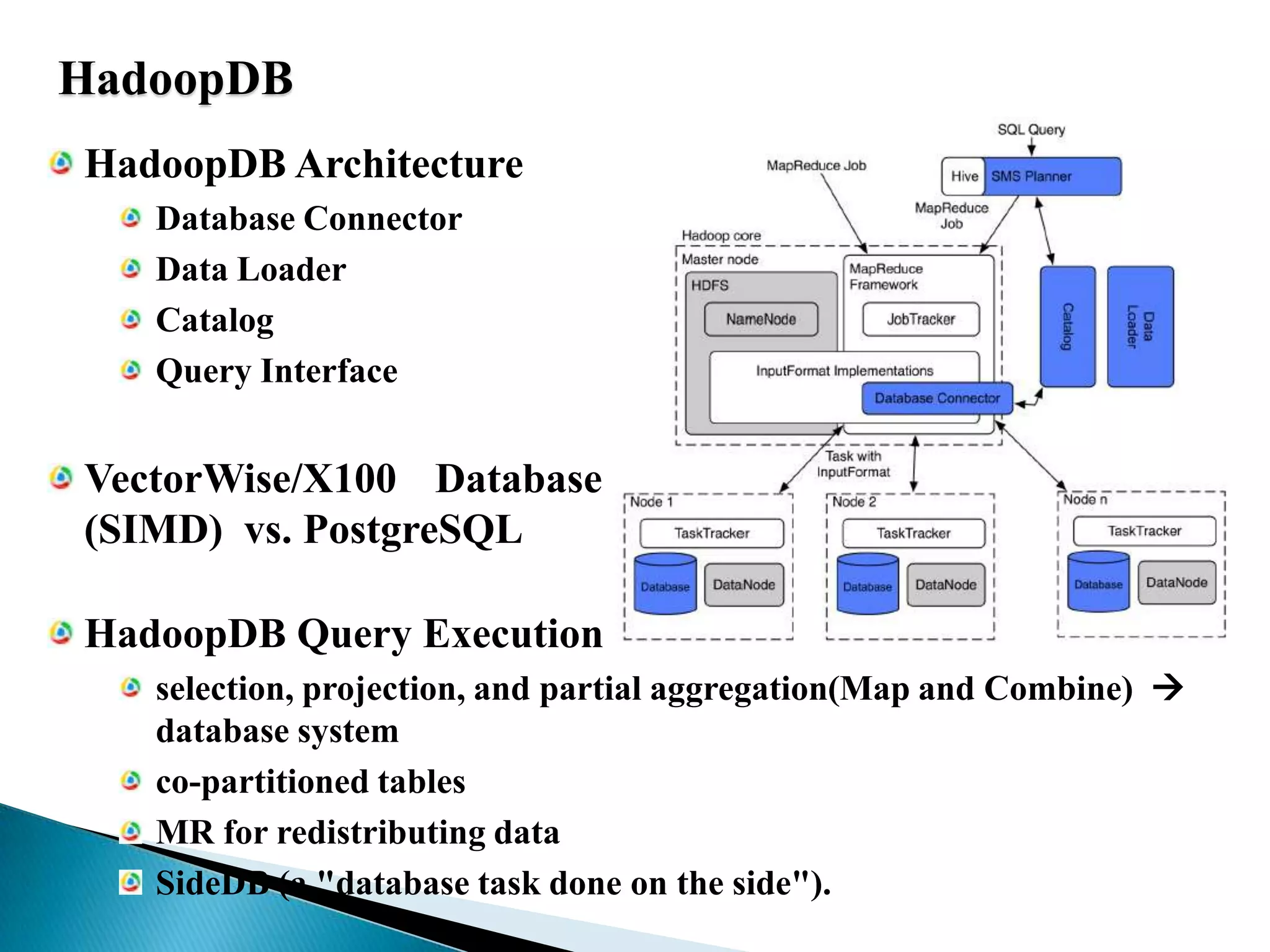


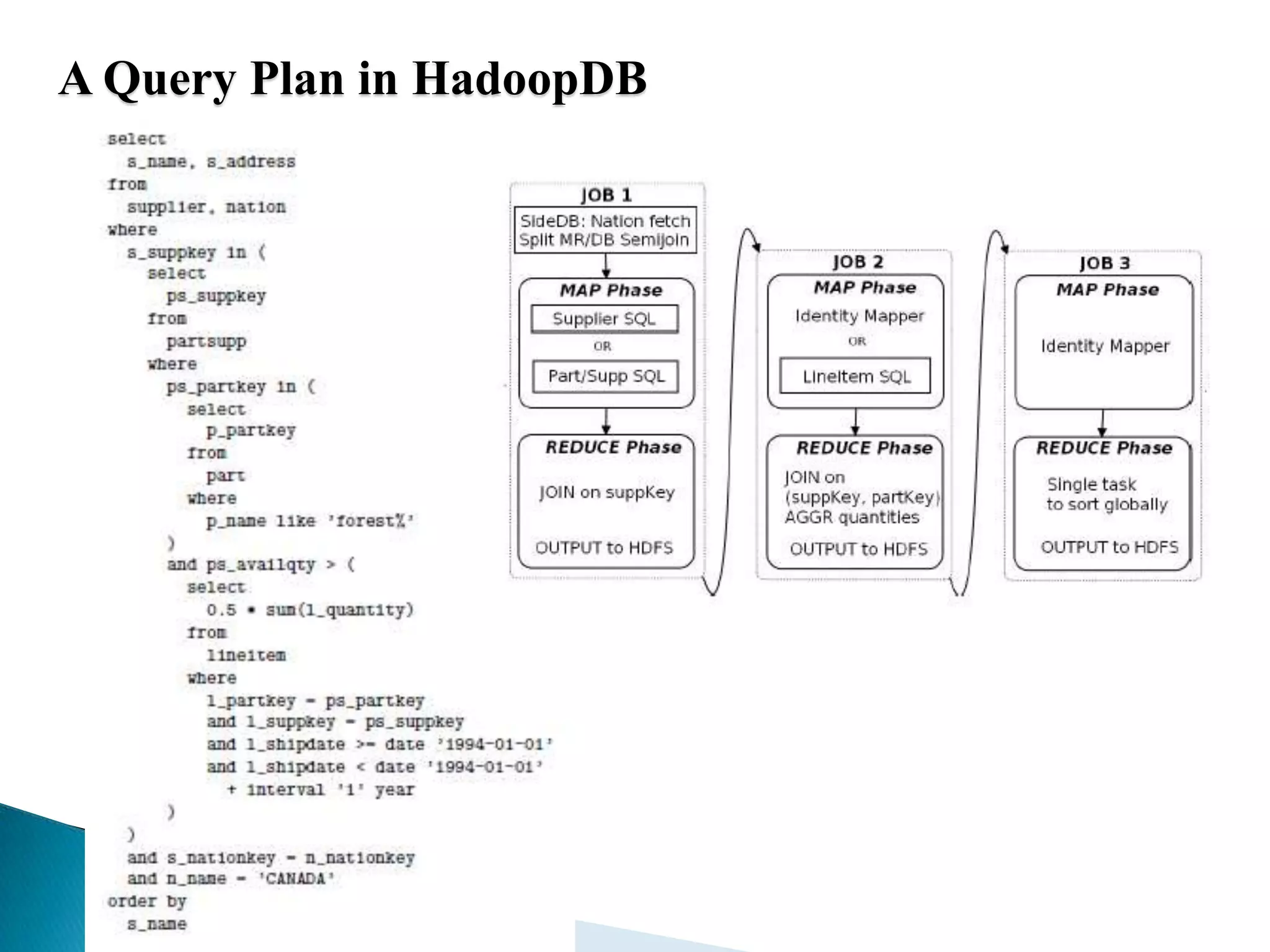
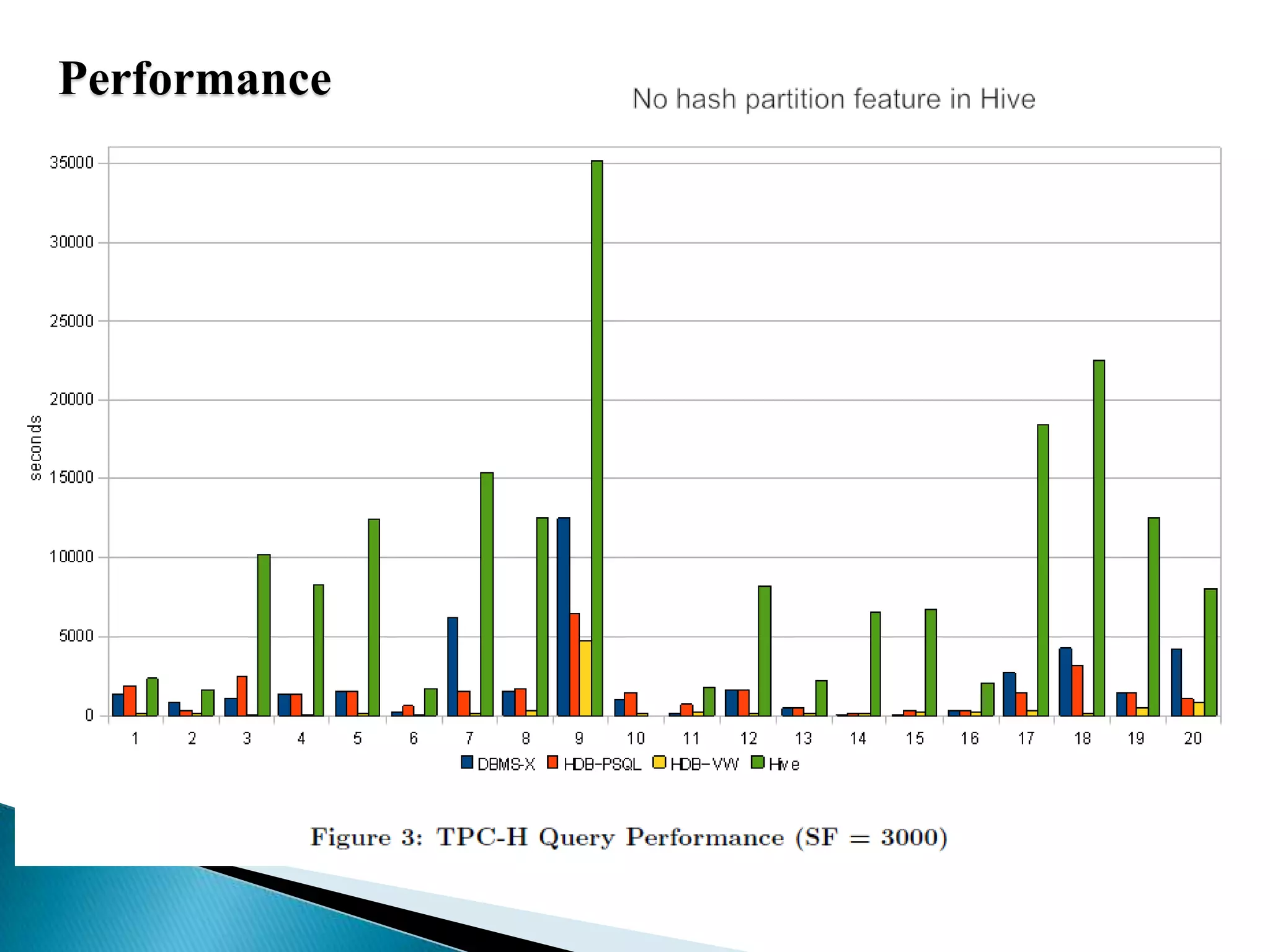

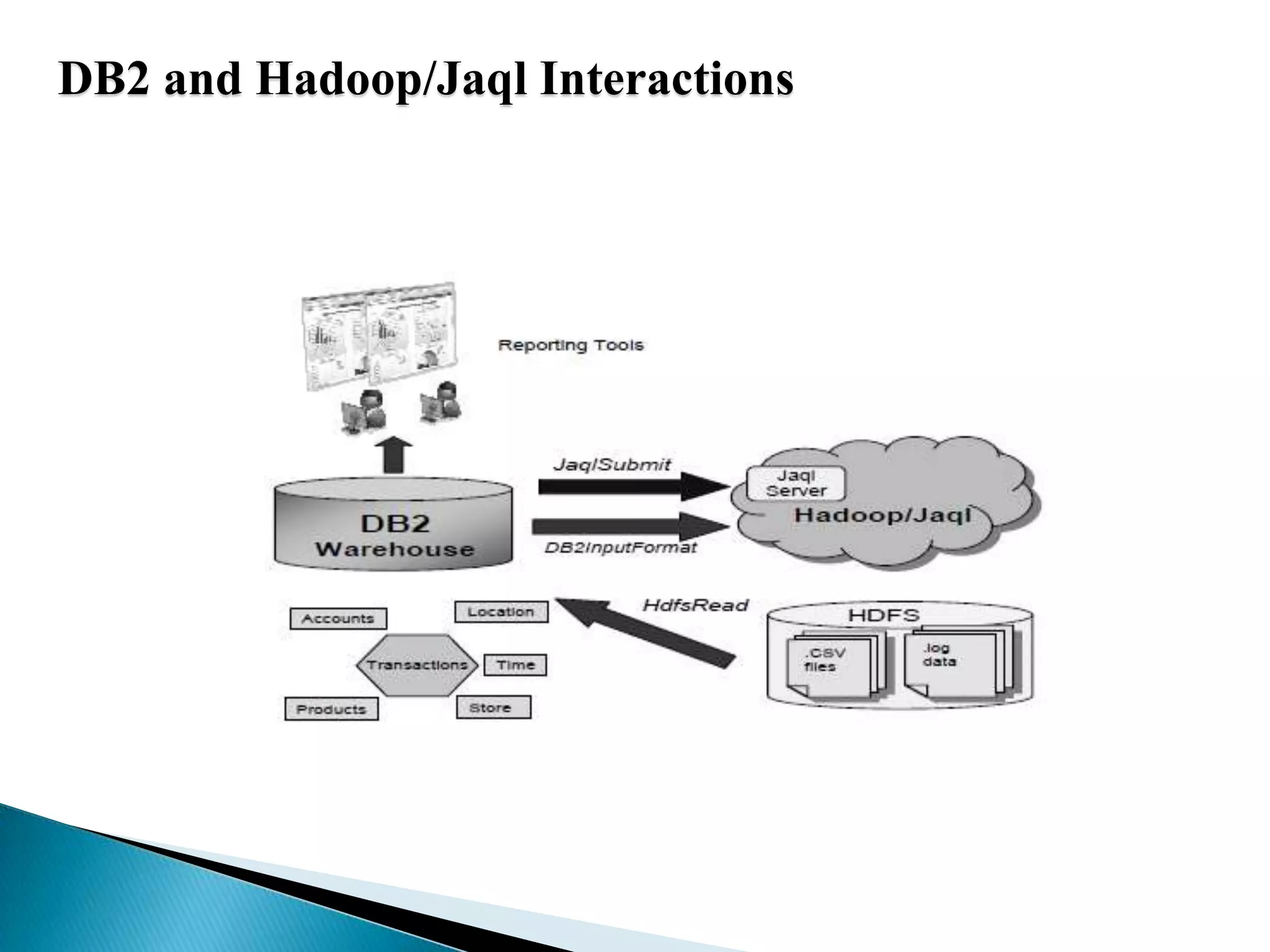




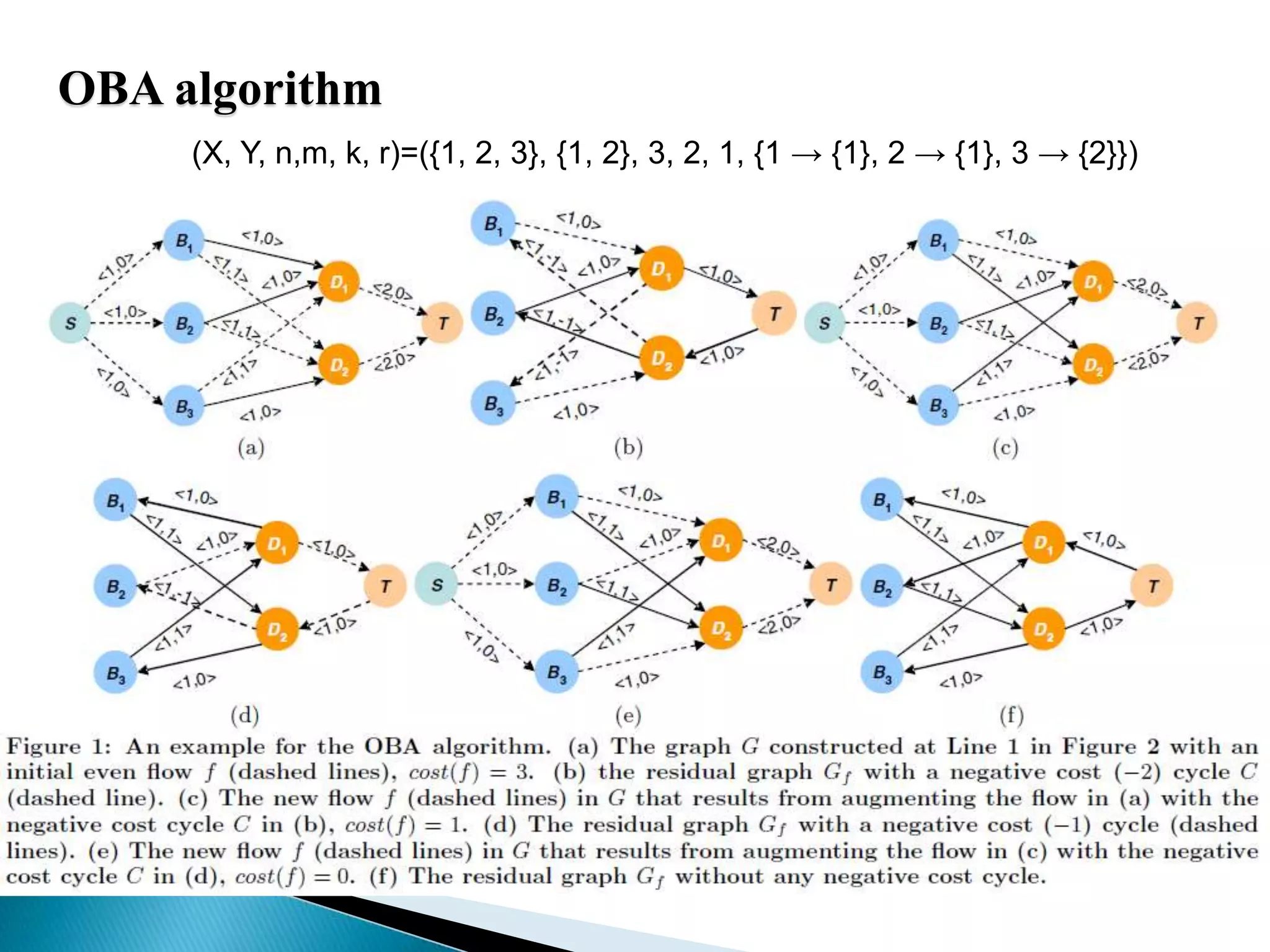

The document summarizes several papers presented at SIGMOD 2011 related to Hadoop and distributed data processing. It then provides more detail on Apache Hadoop's real-time capabilities at Facebook, the Nova system for continuous Pig/Hadoop workflows, and an approach for loading data from Hadoop into parallel data warehouses more efficiently.






























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











