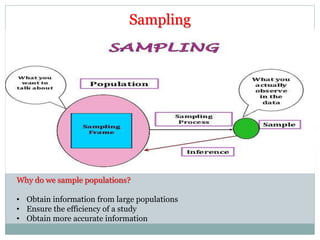
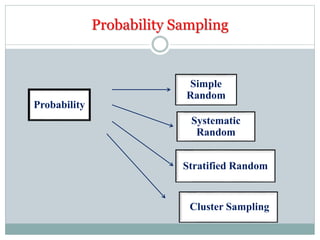
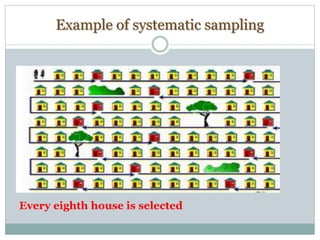
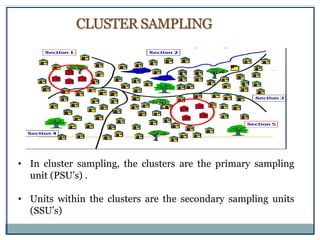
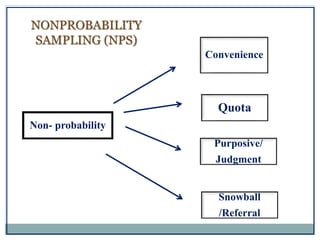
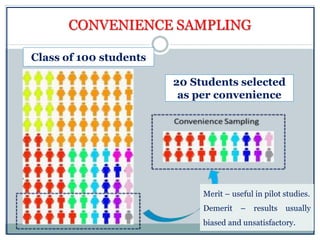
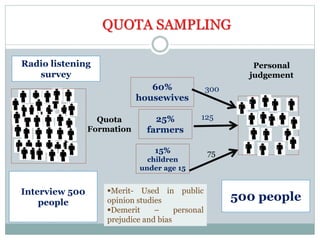
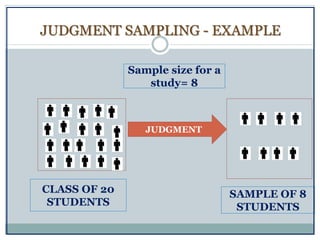
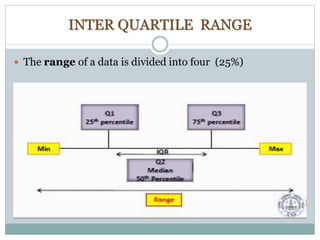
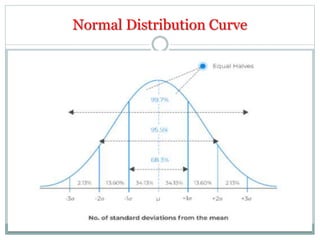
The document defines key concepts in sampling and summarizes different sampling methods. It discusses sampling as a procedure to select a subset of a population to make inferences about the whole population. Probability sampling methods like simple random sampling, systematic sampling, stratified sampling and cluster sampling are described. Non-probability sampling techniques such as convenience sampling, quota sampling, purposive sampling, and snowball sampling are also outlined.