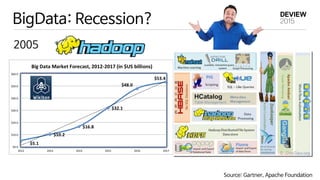
Hadoop’s Uncomfortable Fitin HPC
Why?
1. Hadoop is an invader!
2. Running Java applications (Hadoop) on supercomputer looks funny
3. Hadoop reinvents HPC technologies poorly
4. HDFS is very slow and very obtuse
Source: G. K. Lockwood, HPCwire Image Source: solar-citrus.tumblr.com
15.
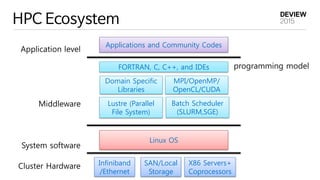
HPC Ecosystem
Application level
Middleware
Systemsoftware
Cluster Hardware
Applications and Community Codes
FORTRAN, C, C++, and IDEs
Domain Specific
Libraries
programming model
Lustre (Parallel
File System)
MPI/OpenMP/
OpenCL/CUDA
Batch Scheduler
(SLURM,SGE)
Linux OS
Infiniband
/Ethernet
SAN/Local
Storage
X86 Servers+
Coprocessors
16.
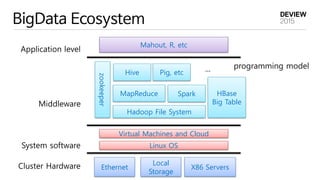
BigData Ecosystem
Application level
Middleware
Systemsoftware
Cluster Hardware
Mahout, R, etc
MapReduce
programming model
Hadoop File System
HBase
Big Table
Linux OS
Ethernet
Local
Storage
X86 Servers
zookeeper Spark
Hive Pig, etc ...
Virtual Machines and Cloud
17.
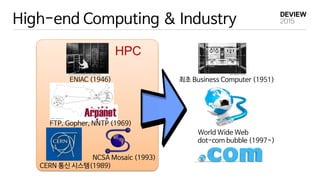
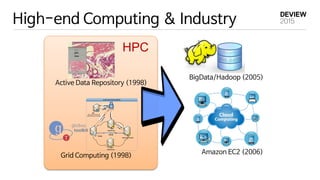
ADR vs MapReduce
-Data Intensive Computing Framework
- Scientific Datasets 처리
1998 Active Data Repository (ADR)
Processing Remotely Sensed Data
NOAA Tiros-N
w/ AVHRR sensor
AVHRR Level 1 DataAVHRR Level 1 Data
• As the TIROS-N satellite orbits, the
Advanced Very High Resolution Radiometer (AVHRR)
sensor scans perpendicular to the satellite’s track.
• At regular intervals along a scan line measurements
are gathered to form an instantaneous field of view
(IFOV).
• Scan lines are aggregated into Level 1 data sets.
A single file of Global Area
Coverage (GAC) data
represents:
• ~one full earth orbit.
• ~110 minutes.
• ~40 megabytes.
• ~15,000 scan lines.
One scan line is 409 IFOV’s
Source: Chaos project: U.Maryland, College Park
18.
DataCutter vs Dryad,Spark
2000 DataCutter
- Workflow 지원 Component Framework
- Pipelined components (filter)
- Stream based communication
class MyFilter : public Filter_Base {
public:
int init( int argc, char * argv[] )
{ ... };
int process( stream_t st[] ) { ... };
int finalize( void ) { ... };
}
Source: Chaos project: U.Maryland, College Park
19.
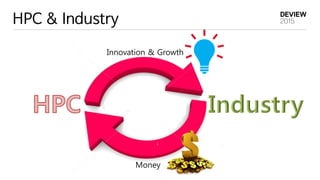
HPC & BigData
HPC와 BigData 의 공통 해결 과제
1. High-performance interconnect technologies
2. Energy efficient circuit, power, and cooling technologies
3. Power and Failure-aware resilient scalable system software
4. Advanced memory technologies
5. Data management- volume, velocity, and diversity of data
6. Programming models
7. Scale-up? Scale-out?
20.
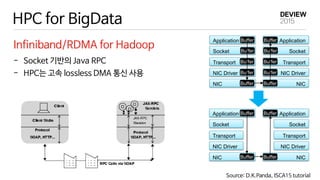
HPC for BigData
Infiniband/RDMAfor Hadoop
- Wide adoption of RDMA
- Message Passing Interface (MPI) for HPC
- Parallel File Systems
- Lustre
- GPFS
- Delivering excellent performance
- (latency, bandwidth and CPU Utilization)
- Delivering excellent scalability
21.
HPC for BigData
Infiniband/RDMAfor Hadoop
- Socket 기반의 Java RPC
- HPC는 고속 lossless DMA 통신 사용
Application
Socket
Transport
NIC Driver
NIC
Application
Socket
Transport
NIC Driver
NIC
Buffer
Buffer
Buffer
Buffer
Buffer
Buffer
Buffer
Buffer
Buffer
Buffer
Application
Socket
Transport
NIC Driver
NIC
Application
Socket
Transport
NIC Driver
NIC
Buffer
Buffer
Buffer
Buffer
Source: D.K.Panda, ISCA15 tutorial
22.
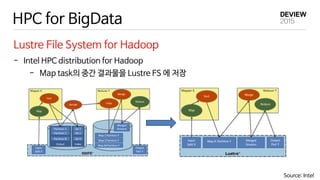
HPC for BigData
LustreFile System for Hadoop
- Intel HPC distribution for Hadoop
- Map task의 중간 결과물을 Lustre FS 에 저장
Source: Intel
23.
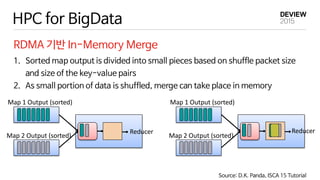
HPC for BigData
RDMA기반 In-Memory Merge
Source: D.K. Panda, ISCA 15 Tutorial
Map 1 Output (sorted)
Map 2 Output (sorted)
Reducer
Map 1 Output (sorted)
Map 2 Output (sorted)
Reducer
1. Sorted map output is divided into small pieces based on shuffle packet size
and size of the key-value pairs
2. As small portion of data is shuffled, merge can take place in memory
24.
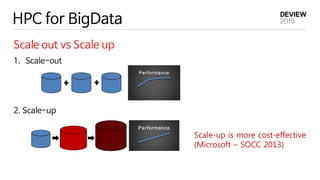
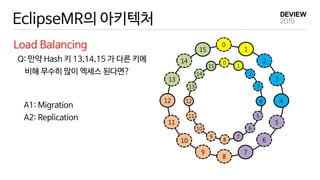
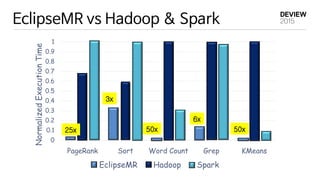
HPC for BigData
Scaleout vs Scale up
1. Scale-out
2. Scale-up
Performance
Performance
Scale-up is more cost-effective
(Microsoft – SOCC 2013)
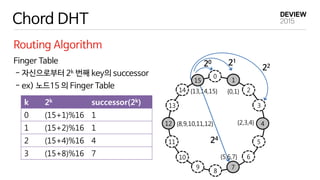
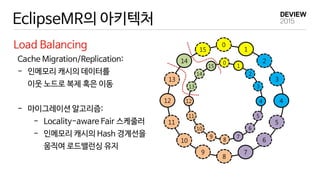
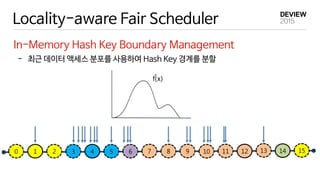
- 최근 데이터액세스 분포를 사용하여 Hash Key 경계를 분할
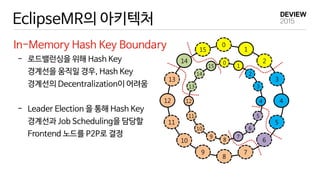
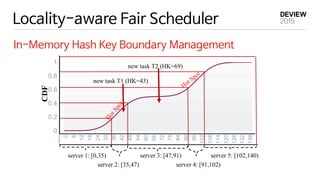
Locality-aware Fair Scheduler
In-Memory Hash Key Boundary Management
14 150 1 2 3 4 5 6 7 8 9 10 11 12 13
49.
Locality-aware Fair Scheduler
In-MemoryHash Key Boundary Management
0
0.2
0.4
0.6
0.8
1
0
6
12
18
24
30
36
42
48
54
60
66
72
78
84
90
96
102
108
114
120
126
132
138
CDF
server 1: [0,35)
server 2: [35,47)
server 3: [47,91)
server 4: [91,102)
server 5: [102,140)
new task T1 (HK=43)
new task T2 (HK=69)
50.
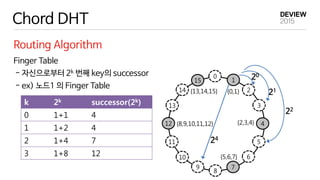
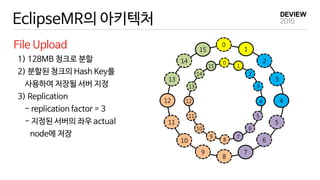
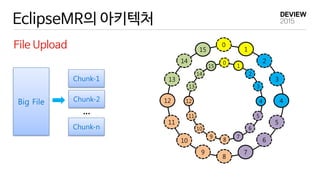
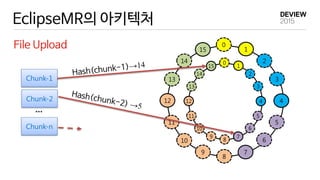
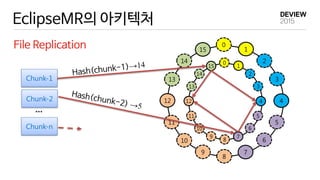
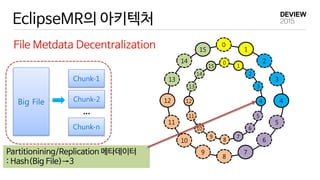
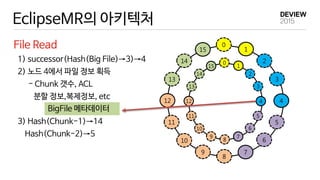
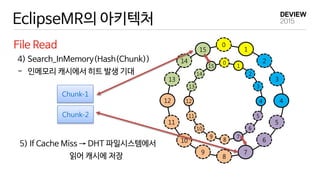
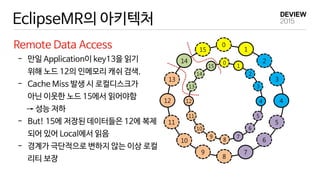
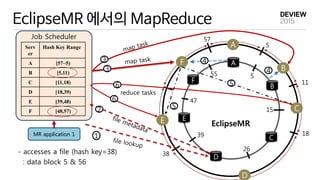
EclipseMR 에서의 MapReduce
JobScheduler
A
A
B
C
D
E
F
B
C
D
E
F
5
5
11
15
18
26
38
39
47
57
55
EclipseMR
MR application 1 1
2
3
4
4
5
5
3
6
reduce tasks
6
Serv
er
Hash Key Range
A [57~5)
B [5,11)
C [11,18)
D [18,39)
E [39,48)
F [48,57)
- accesses a file (hash key=38)
: data block 5 & 56
Ongoing Works
MachineLearning onEclipseMR
- GPU ML 패키지와 EclipseMR의 통합
Hadoop에서 GPU를
쓰는건 너무 어려워요.
WORLD'S LARGEST ARTIFICIAL
NEURAL NETWORKS WITH GPU
Source: Stanford Al Lab
54.
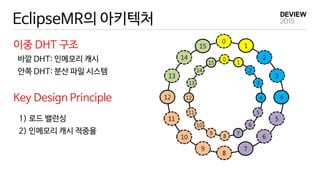
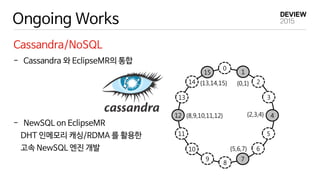
Ongoing Works
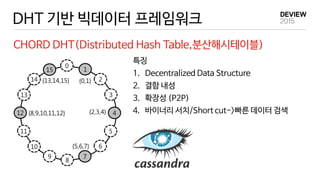
Cassandra/NoSQL
- Cassandra와 EclipseMR의 통합
- NewSQL on EclipseMR
DHT 인메모리 캐싱/RDMA 를 활용한
고속 NewSQL 엔진 개발
14
15
0
1
2
3
4
5
6
7
8
9
10
11
12
13
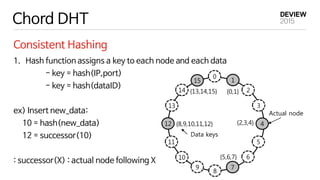
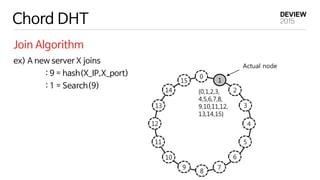
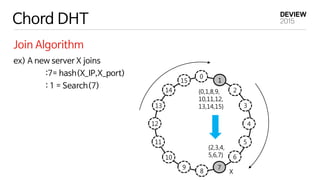
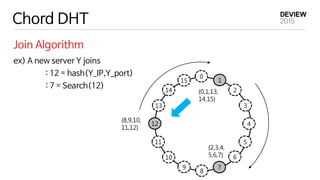
{13,14,15} {0,1}
{2,3,4}
{5,6,7}
{8,9,10,11,12}












![DataCutter vs Dryad, Spark
2000 DataCutter
- Workflow 지원 Component Framework
- Pipelined components (filter)
- Stream based communication
class MyFilter : public Filter_Base {
public:
int init( int argc, char * argv[] )
{ ... };
int process( stream_t st[] ) { ... };
int finalize( void ) { ... };
}
Source: Chaos project: U.Maryland, College Park](https://image.slidesharecdn.com/223-150915022242-lva1-app6891/85/232-18-320.jpg)












![[244] 분산 환경에서 스트림과 배치 처리 통합 모델](https://cdn.slidesharecdn.com/ss_thumbnails/244-150915025618-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[241] Storm과 Elasticsearch를 활용한 로깅 플랫폼의 실시간 알람 시스템 구현](https://cdn.slidesharecdn.com/ss_thumbnails/83713-150915040003-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[231]운영체제 수준에서의 데이터베이스 성능 분석과 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/231-171017003147-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2A1]Line은 어떻게 글로벌 메신저 플랫폼이 되었는가](https://cdn.slidesharecdn.com/ss_thumbnails/2a1line-140929191515-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/2251016final-171017052307-thumbnail.jpg?width=640&height=640&fit=bounds)
![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2] java 애플리케이션 트러블 슈팅 사례 & pinpoint](https://cdn.slidesharecdn.com/ss_thumbnails/d2javapinpoint-150522091509-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]네트워크 모니터링 시스템(nms)을 지탱하는 기술](https://cdn.slidesharecdn.com/ss_thumbnails/244nms-171017030833-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]rye, 샤딩을 지원하는 오픈소스 관계형 dbms](https://cdn.slidesharecdn.com/ss_thumbnails/223ryedbms-171016104435-thumbnail.jpg?width=640&height=640&fit=bounds)
![[264] large scale deep-learning_on_spark](https://cdn.slidesharecdn.com/ss_thumbnails/246large-scaledeeplearningonspark-150915055051-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.](https://cdn.slidesharecdn.com/ss_thumbnails/35-171016061446-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D2]thread dump 분석기법과 사례](https://cdn.slidesharecdn.com/ss_thumbnails/d2threaddump-150522063949-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[261] 실시간 추천엔진 머신한대에 구겨넣기](https://cdn.slidesharecdn.com/ss_thumbnails/216-150915054828-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




![[빅데이터 컨퍼런스 전희원]](https://cdn.slidesharecdn.com/ss_thumbnails/random-120412212952-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







![[234] 산업 현장을 위한 증강 현실 기기 daqri helmet 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/243daqrihelmet-150915022636-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223] h base consistent secondary indexing](https://cdn.slidesharecdn.com/ss_thumbnails/232hbaseconsistentsecondaryindexing-150915010743-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[231] the simplicity of cluster apps with circuit](https://cdn.slidesharecdn.com/ss_thumbnails/213thesimplicityofclusterappswithcircuit-150915022150-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224] 번역 모델 기반_질의_교정_시스템](https://cdn.slidesharecdn.com/ss_thumbnails/242-150915010843-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[252] 증분 처리 플랫폼 cana 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/225cana-150915052201-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[263] s2graph large-scale-graph-database-with-hbase-2](https://cdn.slidesharecdn.com/ss_thumbnails/236s2graph-large-scale-graph-database-with-hbase-2-150915055019-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] turning data into value](https://cdn.slidesharecdn.com/ss_thumbnails/234turningdataintovalue-150915052705-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[253] apache ni fi](https://cdn.slidesharecdn.com/ss_thumbnails/235apachenifi-150915053924-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242] wifi를 이용한 실내 장소 인식하기](https://cdn.slidesharecdn.com/ss_thumbnails/224wifi-150915025827-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] level 2 network programming using packet ngin rtos](https://cdn.slidesharecdn.com/ss_thumbnails/233level2networkprogrammingusingpacketnginrtos-150915022357-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[262] netflix 빅데이터 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/226netflix-150915054913-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212] large scale backend service develpment](https://cdn.slidesharecdn.com/ss_thumbnails/221largescalebackendservicedevelpment-150915001346-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245] presto 내부구조 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/245presto-150915054242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[211] 네이버 검색과 데이터마이닝](https://cdn.slidesharecdn.com/ss_thumbnails/211-150915001301-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[222]대화 시스템 서비스 동향 및 개발 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222-150915011307-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] data science with apache zeppelin](https://cdn.slidesharecdn.com/ss_thumbnails/241datasciencewithapachezeppelin-150915001420-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] ethereum](https://cdn.slidesharecdn.com/ss_thumbnails/231ethereum-150915024025-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[251] implementing deep learning using cu dnn](https://cdn.slidesharecdn.com/ss_thumbnails/215implementingdeeplearningusingcudnn-150915052020-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[221] docker orchestration](https://cdn.slidesharecdn.com/ss_thumbnails/212dockerorchestration-150915010646-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[113] lessons from realm](https://cdn.slidesharecdn.com/ss_thumbnails/113lessonsfromrealm-150913114250-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






![[246] foursquare데이터라이프사이클 설현준](https://cdn.slidesharecdn.com/ss_thumbnails/246foursquare-161025031706-thumbnail.jpg?width=640&height=640&fit=bounds)













![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)