실시간 빅 데이터기술 현황 및
Daum 활용 사례 소개
윤석찬
다음커뮤니케이션
channy@daumcorp.com
2.
Agenda
Daum의 대용량 분산기술
– 대용량 스토리지 제공 (Tenth)
– 폭증하는 소셜 데이터 (Santa/Wcache)
실시간 분석 기술 소개 및 동향
– 실시간 분석 및 SQL on Hadoop 기술 소개
Daum의 실시간 분석 활용 사례
– 미디어 다음 실시간 분석 사례
– 다음탑 실시간 분석 사례
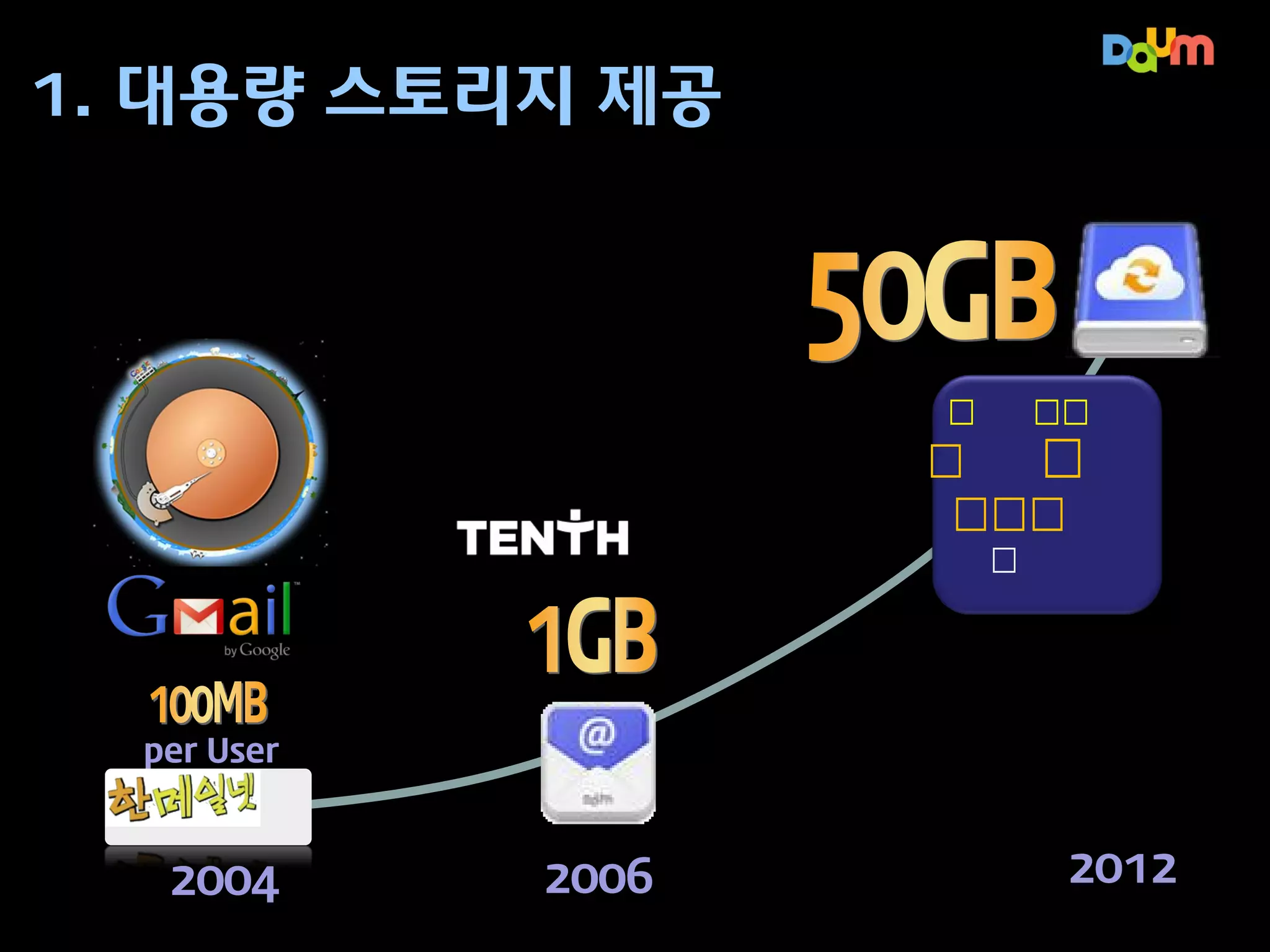
1. 대용량 스토리지제공
명실 상부한
국내 최대
저장용량
제공 중
per User
2004
2006
2012
5.
How to? Tenth(2005)프로젝트
대부분 첨부 파일은 30일이 지나면 안본다?
오래된 파일은 값싼 스토리지에 저장해 두고
사용자가 원할때 빨리 찾아주면 되지 않을까?
• 외부 분산 스토리지 기술
Google GFS (2003)
Yahoo HDFS (2007)
NHN OwFS (2010)
김남희(2008), Tenth: Daum의 대용량 분산 파일 시스템 소개
http://www.platformday.com/2008/files/tenth-daum.pdf
6.
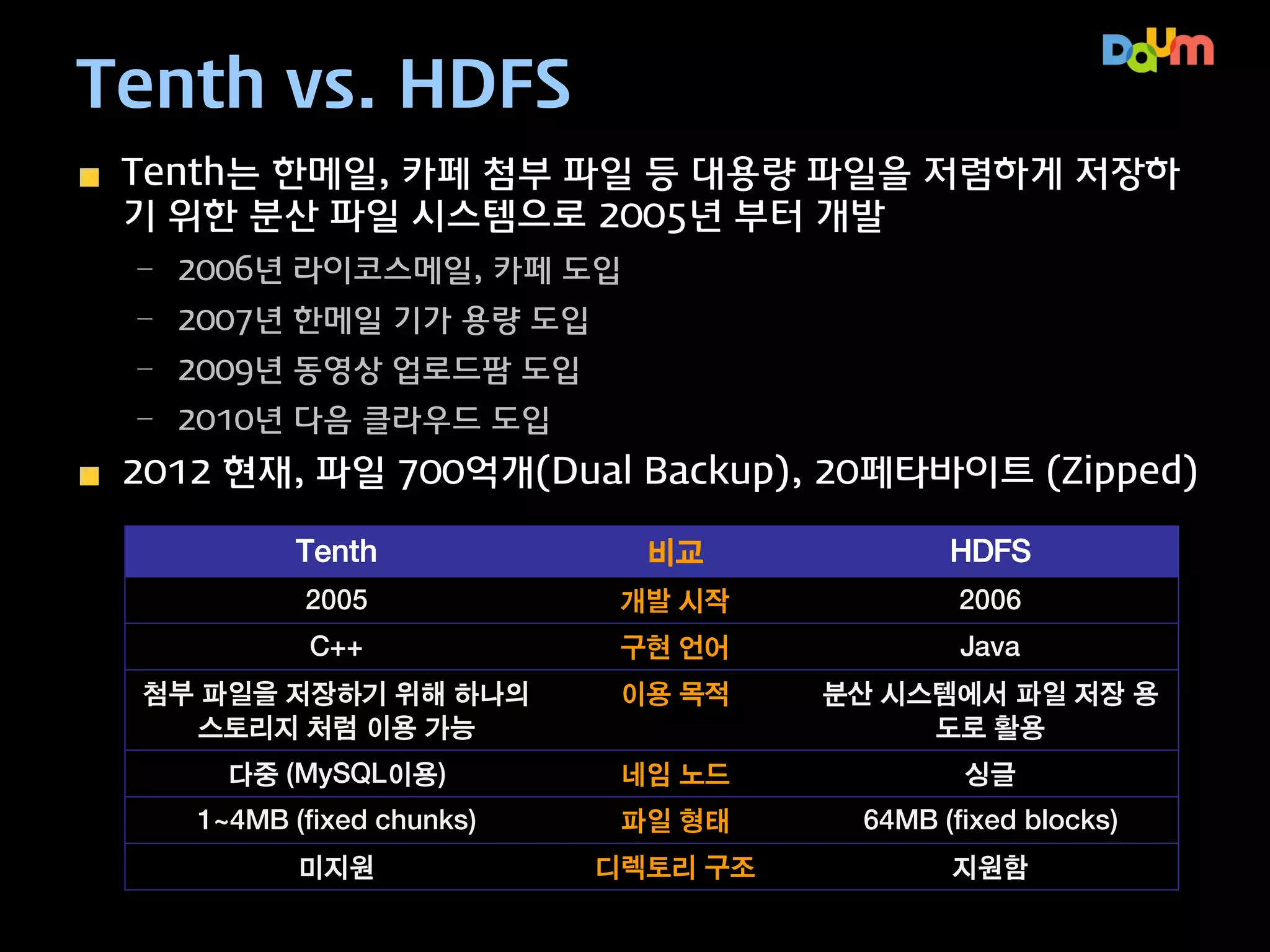
Tenth vs. HDFS
Tenth는한메일, 카페 첨부 파일 등 대용량 파일을 저렴하게 저장하
기 위한 분산 파일 시스템으로 2005년 부터 개발
– 2006년 라이코스메일, 카페 도입
– 2007년 한메일 기가 용량 도입
– 2009년 동영상 업로드팜 도입
– 2010년 다음 클라우드 도입
2013 현재, 파일 800억개(Dual Backup), 30페타바이트 (Zipped)
Tenth
비교
HDFS
2005
개발 시작
2006
C++
구현 언어
Java
첨부 파일을 저장하기 위해 하나의
스토리지 처럼 이용 가능
이용 목적
분산 시스템에서 파일 저장 용
도로 활용
다중 (MySQL이용)
네임 노드
싱글
1~4MB (fixed chunks)
파일 형태
64MB (fixed blocks)
미지원
디렉토리 구조
지원함
7.
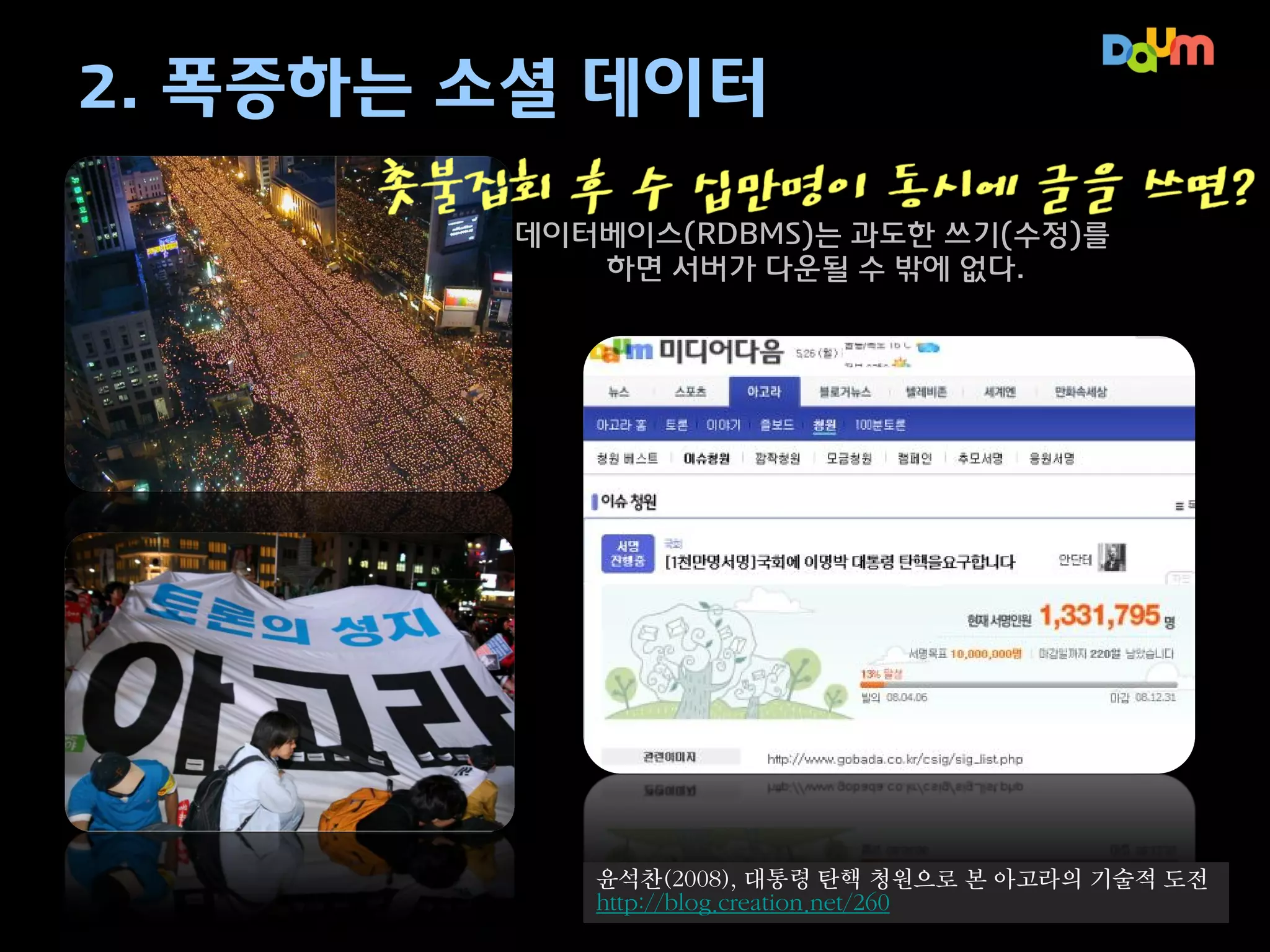
2. 폭증하는 소셜데이터
촛불집회 후 수 십만명이 동시에 글을 쓰면?
데이터베이스(RDBMS)는 과도한 쓰기(수정)를
하면 서버가 다운될 수 밖에 없다.
윤석찬(2008), 대통령 탄핵 청원으로 본 아고라의 기술적 도전
http://blog.creation.net/260
8.
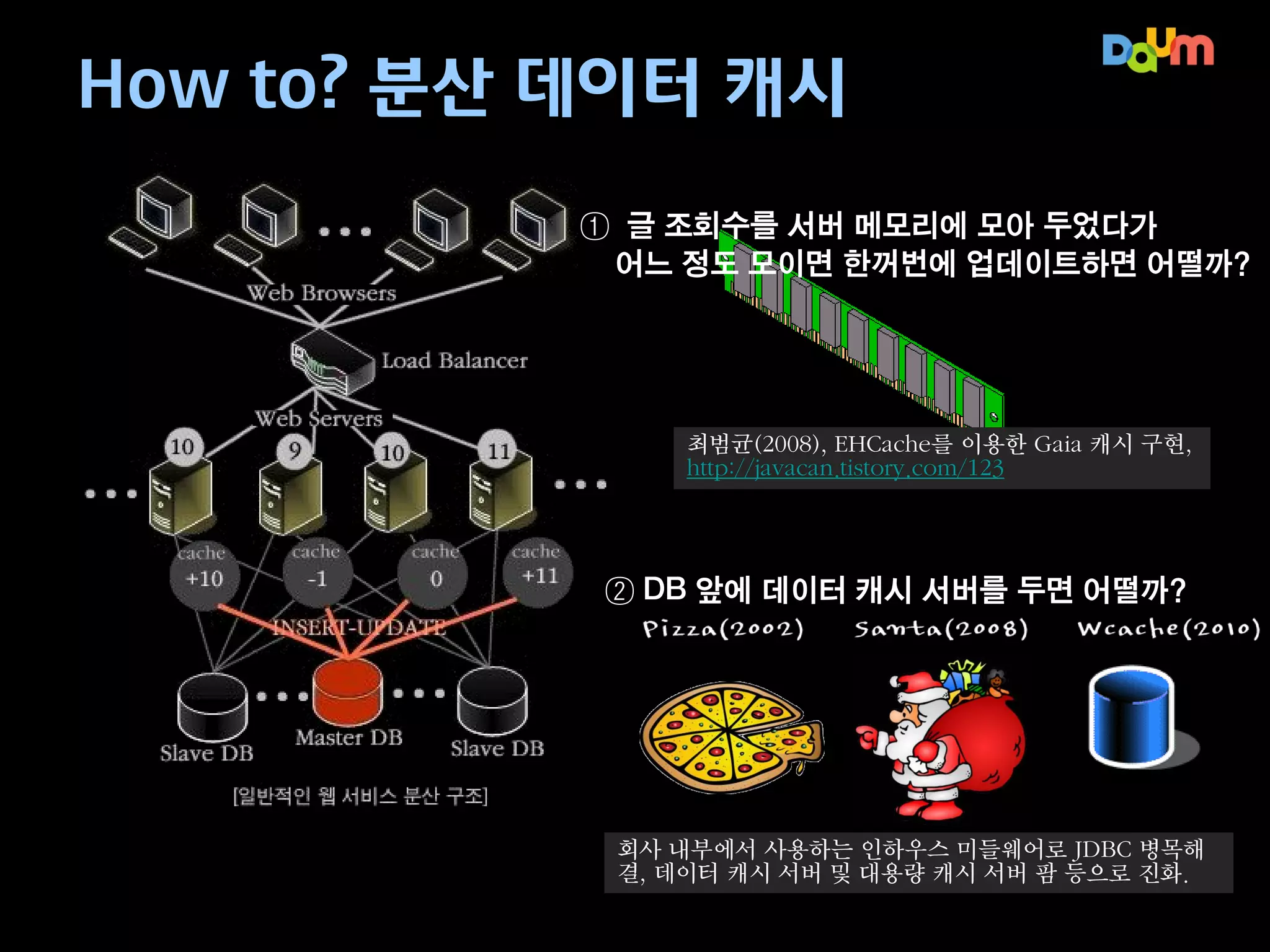
How to? 분산데이터 캐시
① 글 조회수를 서버 메모리에 모아 두었다가
어느 정도 모이면 한꺼번에 업데이트하면 어떨까?
최범균(2008), EHCache를 이용한 Gaia 캐시 구현,
http://javacan.tistory.com/123
② DB 앞에 데이터 캐시 서버를 두면 어떨까?
Pizza(2002)
Santa(2008)
Wcache(2010)
회사 내부에서 사용하는 인하우스 미들웨어로 JDBC 병목해
결, 데이터 캐시 서버 및 대용량 캐시 서버 팜 등으로 진화.
9.
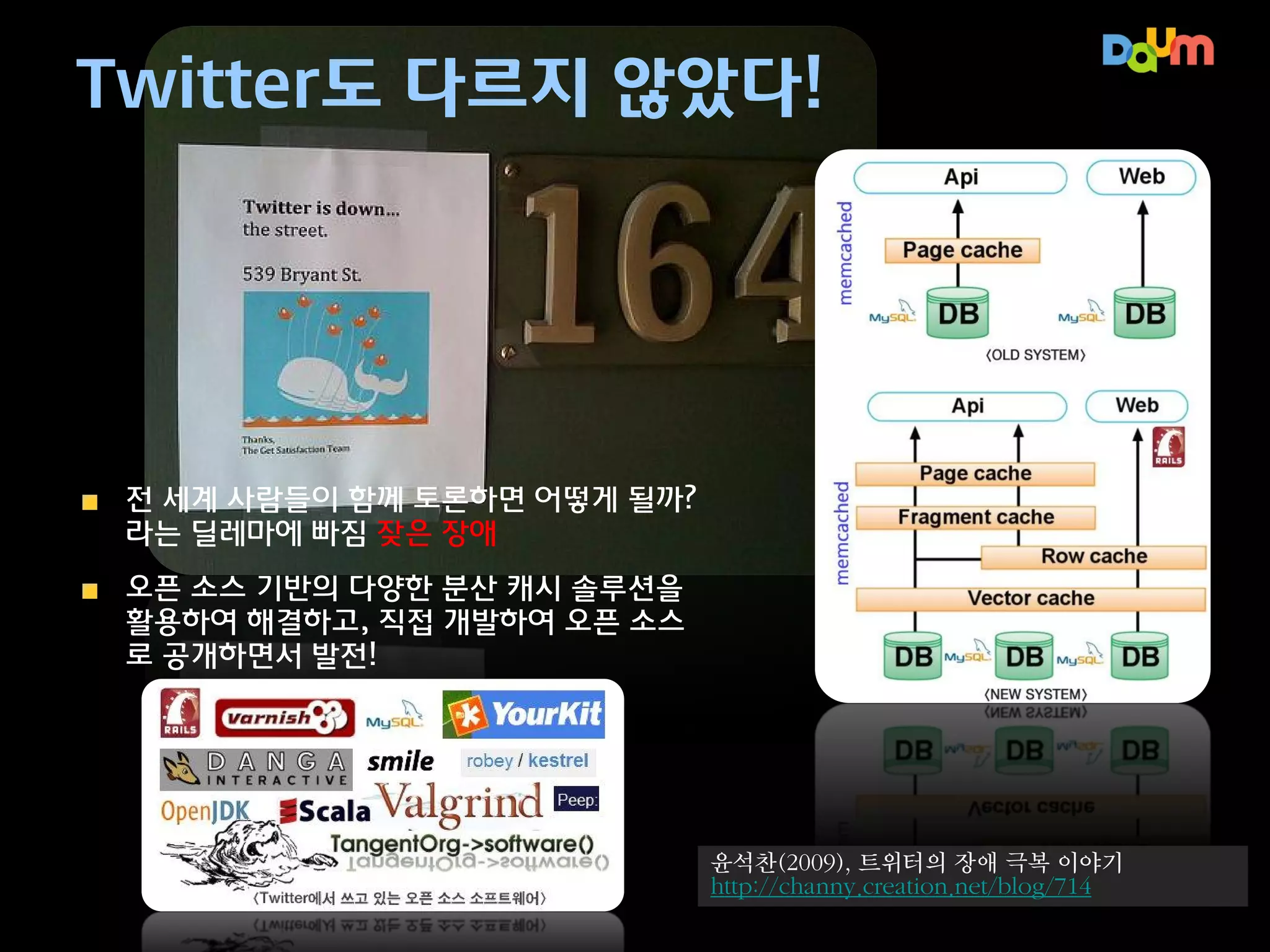
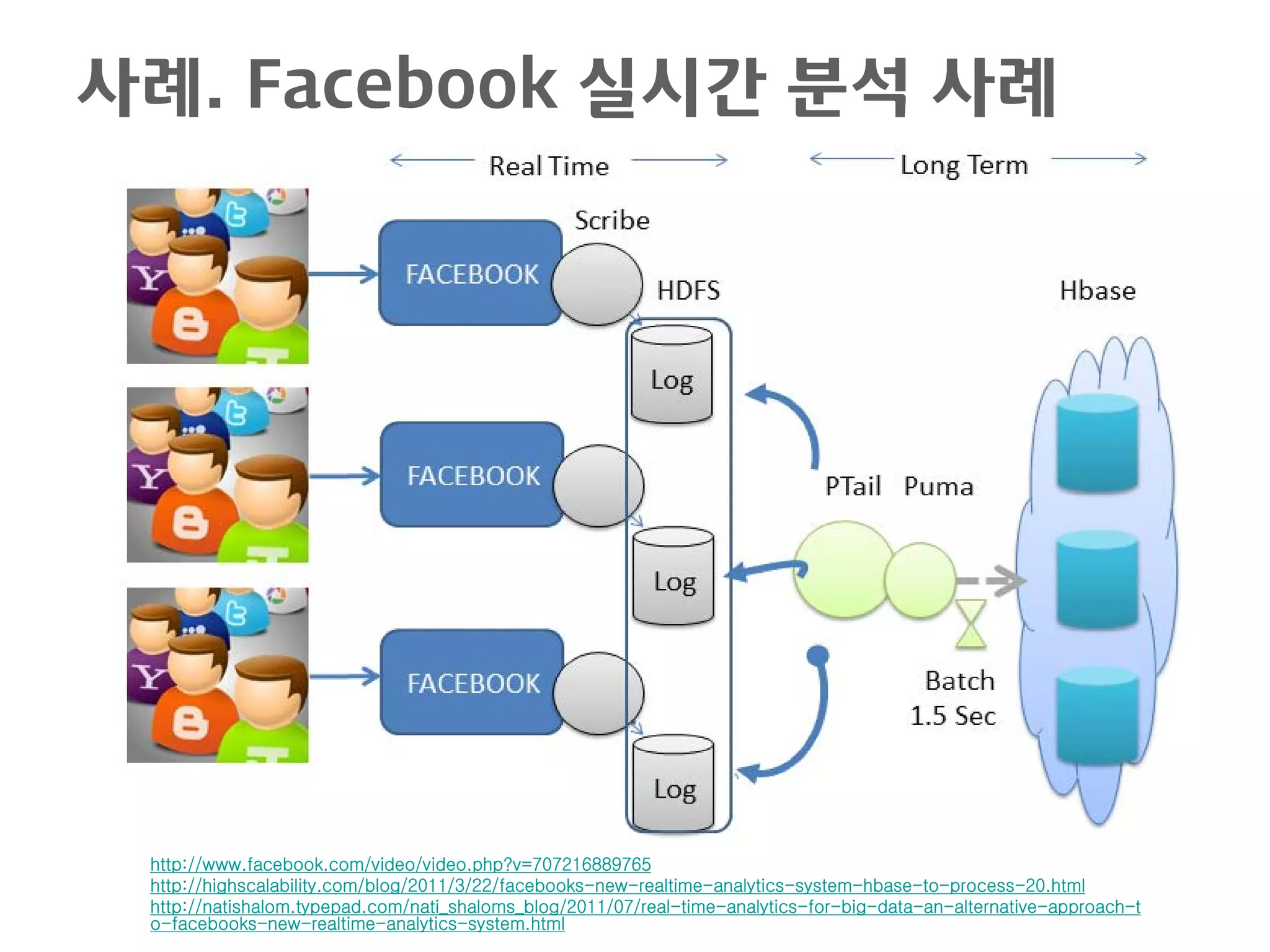
Twitter도 다르지 않았다!
전세계 사람들이 함께 토론하면 어떻
게 될까? 라는 딜레마에 빠짐 잦은 장애
윤석찬(2009), 트위터의 장애 극복 이야기
http://channy.creation.net/blog/714
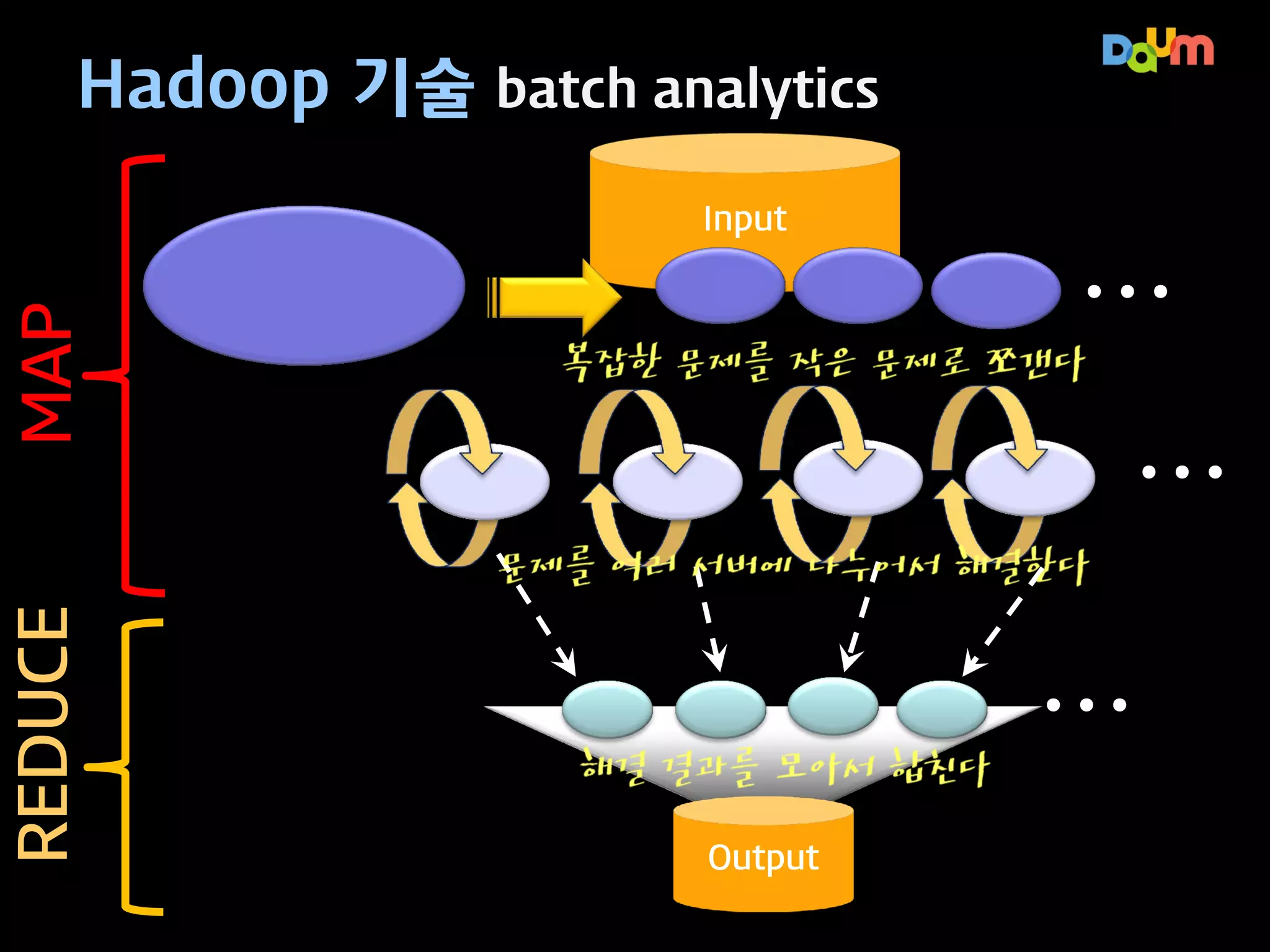
Hadoop 기술 batchanalytics
REDUCE
MAP
Input
…
복잡한 문제를 작은 문제로 쪼갠다
…
문제를 여러 서버에 나누어서 해결한다
결과를 모아서 합친다
Output
…
14.
Hadoop의 장단점
장점 :기존 분석 기술에 비해 저렴하게 데이터 분석 가능
– 데이터를 바라 보는 관점의 차이 (저렴한 처리 비용)
– 샘플링이 필요 없음 (대용량 처리 가능)
– 운영 비용이 적음 (인프라 운영이 관리 가능)
– 분석도구나 프로그래밍 언어에 독립적임
– 다양한 개발 도구 (오픈 소스 지원)
단점: 분석 방식의 변화 및 내재화 비용
– 개념의 변화가 필요 (Map/Reduce식 사고 전환 필요)
– Hadoop은 진화 중(벤더 배포판 사용 기회 늘어남)
– 아직 구현되지 않은 부분이 많음(버전 호환성이 낮은 편)
– 장애에 대한 대비 필요(메모리 및 네트웍 관련 시행착오)
– 실시간 분석에 대한 필요성 (대안 기술 선택적 사용)
15.
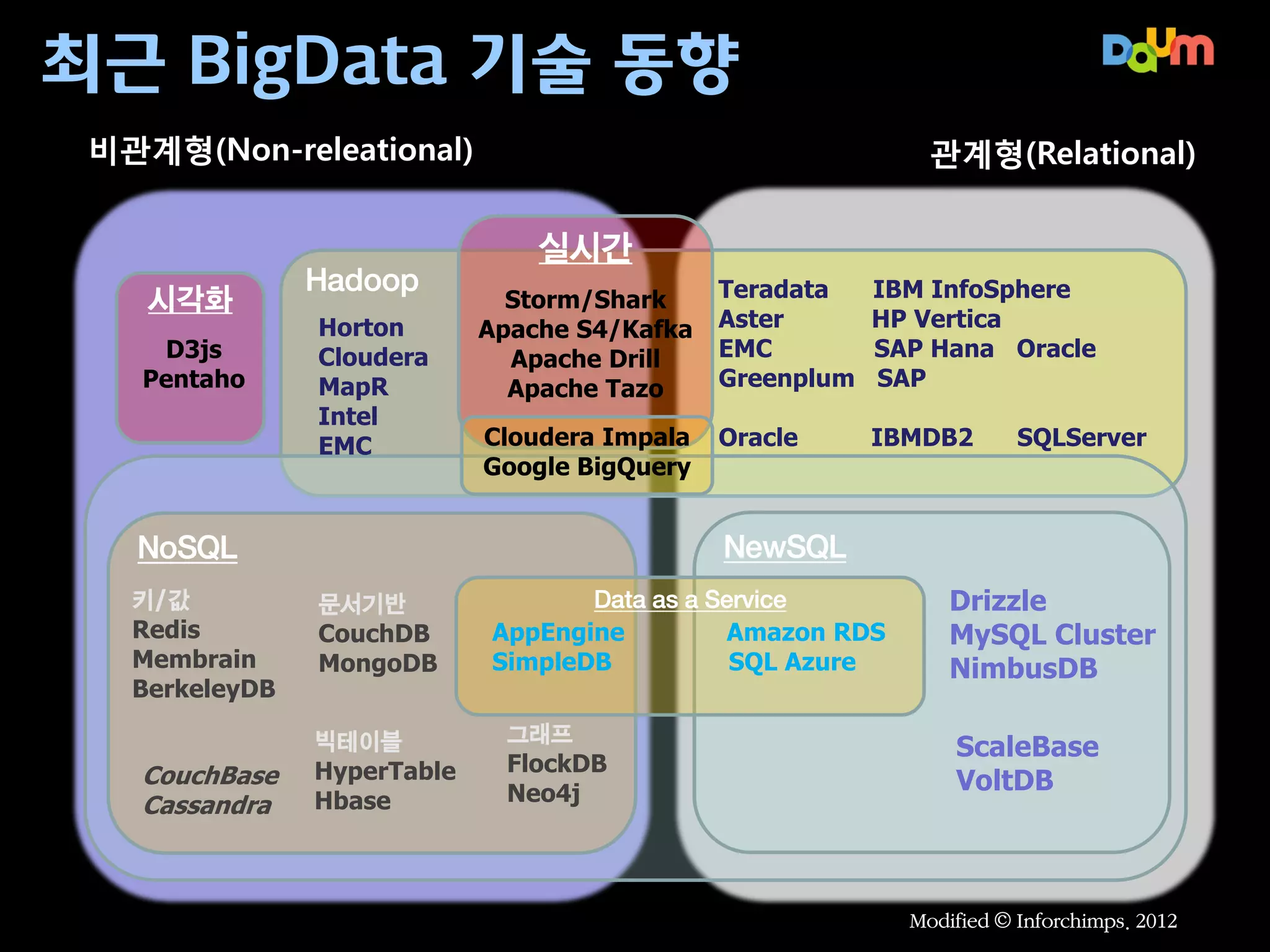
NoSQL Not OnlySQL
Yahoo! Research(2010), Cloud Serving Benchmark
http://research.yahoo.com/files/ycsb-v4.pdf
대용량 데이터 업데이트 및 조회 시,
기존 RDBMS에 비해 빠른 성능 제공
구조가 간단한 대량 이벤트 및 로그
데이터 저장 및 조회 시 유용
16.
NoSQL의 장단점
장점: 빠르고유연한 데이터 저장 및 조회 능력
– 데이터가 증가함에 따라서 노드의 갯수만 늘리면 됨(확장성과 가용성)
– Key-Value 형식으로 저장하므로 유연한 데이터 구조(Schemaless)
– 데이터 인덱싱으로 빠른 응답 가능(고성능)장점 : 기존 분석 기술에 비해
저렴하게 데이터 분석 가능
단점: 분석 방식의 변화 및 내재화 비용
– 스키마 설계, 서버 네트워크 구성, 메모리/IO 등에 시행착오
– 데이터 무결성(integrity)을 위한 처리 비용이 큼
• 트랜잭션과 같은 복잡한 처리에 적합하지 않음
• 장애시 데이터 복구에 드는 노력이 많이 듦
– Schemaless라서 Join 과 같은 복잡한 쿼리 사용 어려움
• MongoDB 같은 경우, 빠른 인덱싱 및 SQL 친화적인 지원 가능
17.
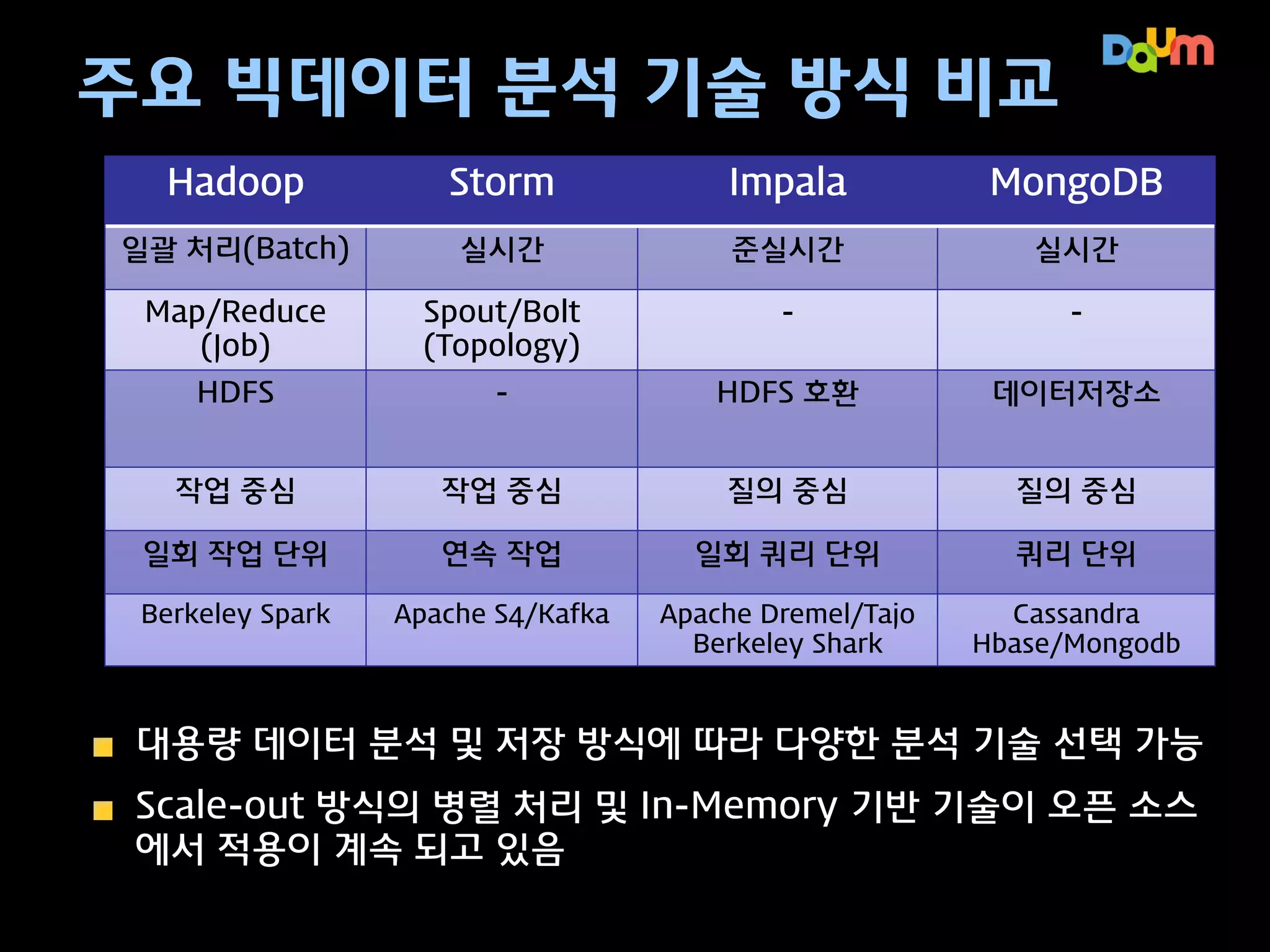
Realtime
Event-streaming
분석에 포함 되지못하는 실시간 데이터 파악
오픈소스
기술명
구현 방식
구현 언어
문서화
즉시 Rule
추가 기능
성숙도
커뮤
니티
Scaleout
방식
Esper
선언적 SQL
Like
Java
매우 좋음
가능
높음
중간
Droools
Fusion
선언적 SQL
Like 및 Rule
Java
좋음
가능
높음
작음
Storm
Scaleup
방식
Job 설계
Cloujure
있음
Zoopkeeper
이용
중간
빠르게
성장중
Apache S4
Job 설계
Java
평균
Zoopkeeper
이용
낮음
중간
Apache
Kafka
Job 설계
Java
좋음
Zoopkeeper
이용
중간
작음
김병곤(2013), 데이터를 실시간으로 모아서 처리하는 다양한 기법
http://www.youtube.com/watch?v=HmVegCGWbsU
18.
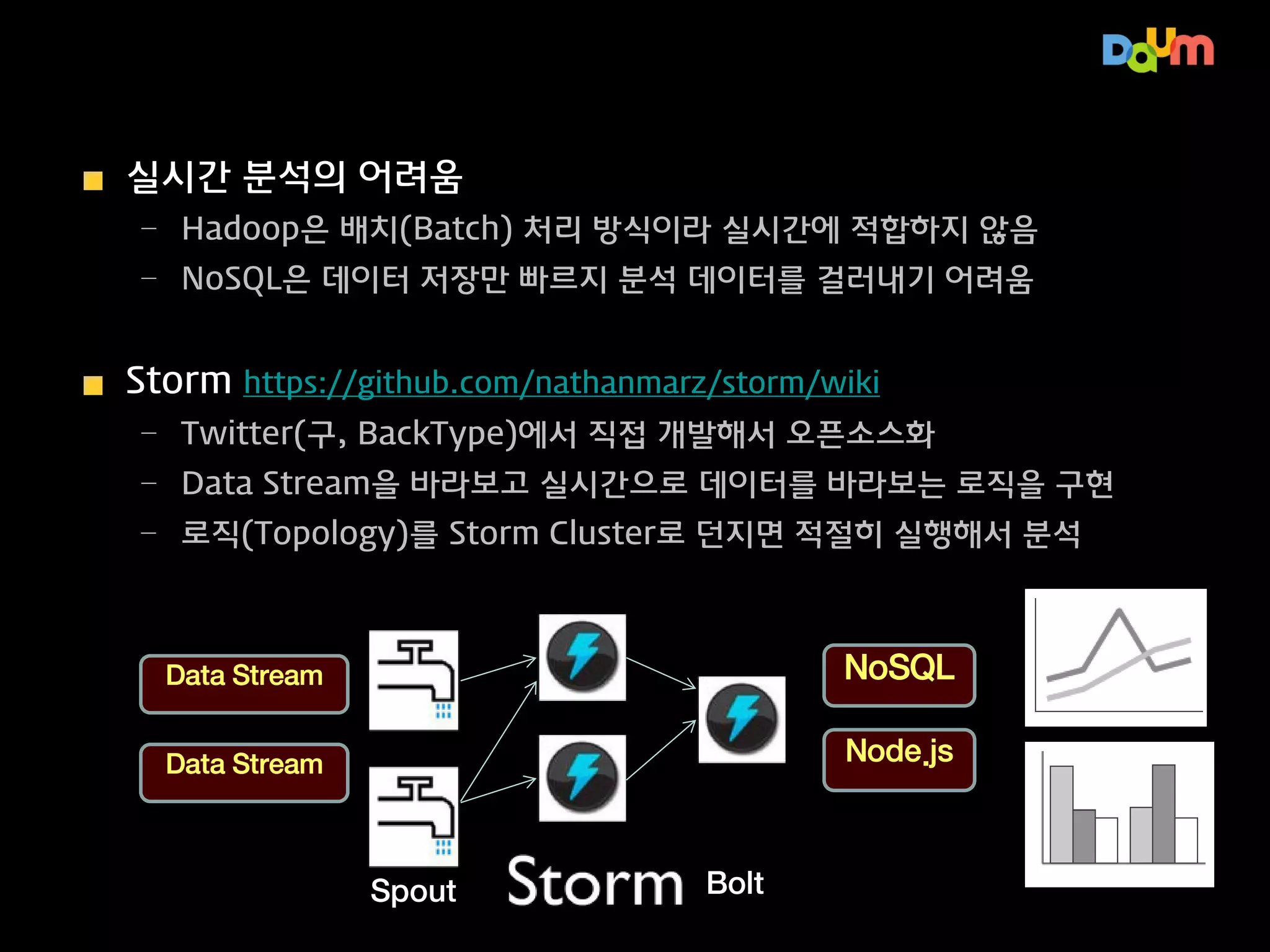
실시간 분석의 어려움
–Hadoop은 배치(Batch) 처리 방식이라 실시간에 적합하지 않음
– NoSQL은 데이터 저장만 빠르지 분석 데이터를 걸러내기 어려움
Storm
https://github.com/nathanmarz/storm/wiki
– Twitter(구, BackType)에서 직접 개발해서 오픈소스화
– Data Stream을 바라보고 실시간으로 데이터를 바라보는 로직을 구현
– 로직(Topology)를 Storm Cluster로 던지면 적절히 실행해서 분석
Data Stream
NoSQL
Data Stream
Node.js
Spout
Bolt
19.
SQL on Hadoop
분석전처리 작업 없이 데이터 현황 파악 필요 시
– 인메모리/파일 기반 분산 기술을 활용한 쿼리 엔진
– Map/Reduce를 사용할 필요가 없는 질의 조건일 때 활용
주요 오픈 소스 기술
– Impala: Cloudera Hadoop 배포판 및 HiveQL 호환
– Apache Tajo: HDFS 지원 및 표준 SQL 호환
– Apache Dremel: MapR에서 주도하며, 아직 초기 개발 단계
상용 서비스: Google BigQuery
– Dremel 기술을 활용한 상용 서비스
Cloudera Impala
Horton Hawq
MapR Stinger
Apache Tajo
Apache Drill
20.
Berkeley Stack
주요 특징
–
–
인메모리기반의 새로운 오픈소스 분석 기술로 특정
데이터의 경우, Haoop에 비해 수 십배 빠른 처리 속도
기존 Hadoop 기술과 호환성 극대화하여 개발자 지원,
But 인메모리 가지는 한계 있음
Spark http://spark-project.org
–
–
–
스토리지 In/Out 대신 주요 데이터셋을 메모리에 올려
서 Iteration에 최적화 시킴 (머신러닝/그래프 탐색)
Interactive Data Mining에 대한 최적화
(R/Excel/Python 등)
기존 HDFS 호환 및 Scala, Java, Python 기반 프로
그래밍 가능
Spark Streaming
–
스트리밍 데이터에 대한 분석 기능 제공
Shark http://shark.cs.berkeley.edu/
–
HiveQL 기반의 분석 기능 제공
UC BERKELEY
SQL on Hadoop100배, 200배 성능의 진실
http://jaso.co.kr/480
현재 SQL-On-Hadoop 진영에서 제시하는 대부분의 성능 수치는 일반적인 질
의나 전체 질의에 대해서 평균 몇 배 빠르다가 아닌 자신들이 유리한 조건
에서 테스트한 결과만을 언급하는 경우가 많다. 필자의 테스트 결과
를 보면 대략 평균 3 ~ 5배 정도이고 질의의 종류에 따라 수 십배 정도 빠를 수
도 있고, 더 느릴 수도 있다.
자신의 데이터 속성과 질의 속성에 맞는 플랫폼을 선택하는 안
목이 필요할 때이다. 미국산 벤더, 블로그, 언론에서 제시한 수치라고 맹신하
는 것은 금물이다.
SQL on Hadoop 100배, 200배 성능의 진실 (김형준) 중에서…
23.
Daum 빅데이터 활용사례
•
–
–
–
–
–
–
•
쇼핑 하우 상품 클릭 분석 사례
다음 Top 토픽 분석 및 추천 서비스
UCC 문서의 스팸 유저 필터링
사물 검색 이미지 역색인
자연어 처리 텍스트 분석
모바일 광고 데이터별 매체 분석 등
연구 개발 사례
–
–
이미지 유사성 매칭 분석
대용량 시맨틱 웹 검색 엔진 개발
•
마이 아고라
검색 광고 노출 최적화
최근 방문 카페 저장
사내 캐시 서버(Redis)
사내 Git 저장소(Redis)
데이터 처리 (Hbase)
•
•
•
•
검색 엔진 색인 문서 저장
서버 모니터링 데이터 저장
로그인 로그 저장
카페 방문 로그 저장
윤석찬(2012), Daum 빅 데이터 기술 활용 사례
http://www.slideshare.net/Channy/daums-hadoop-usecases
http://devon.daum.net/2012/session/o1
이미 공유 많이 했어요!!
찾아보세요~~
서비스 적용 (MongoDB/카산드라)
•
•
•
•
•
전사 로그를 통한 통계 분석
광고 로그 분석을 통한 타겟팅
검색 품질 랭킹 분석 및 개선
광고 및 클릭 로그 분석을 통한 타켓팅
카페 로그 분석을 통한 사용자 카페 추천
게임 서버 로그 분석 등
데이터 분석 사례
–
–
–
–
–
–
•
•
로그 분석 사례
김용우, 이선호(2012), Hadoop 실전 사용기
http://devon.daum.net/2012/session/o2
유응섭, 최준건(2012), 알고쓰자! NoSQL
http://devon.daum.net/2012/session/o3
안세준(2012), 삽질로 일궈낸 카산드라 사용기
http://devon.daum.net/2012/session/o4
윤석찬(2012), Daum 빅 데이터 비지니스 분석 사례
http://www.slideshare.net/Channy/daum-bigdata-analytics-usecases
24.
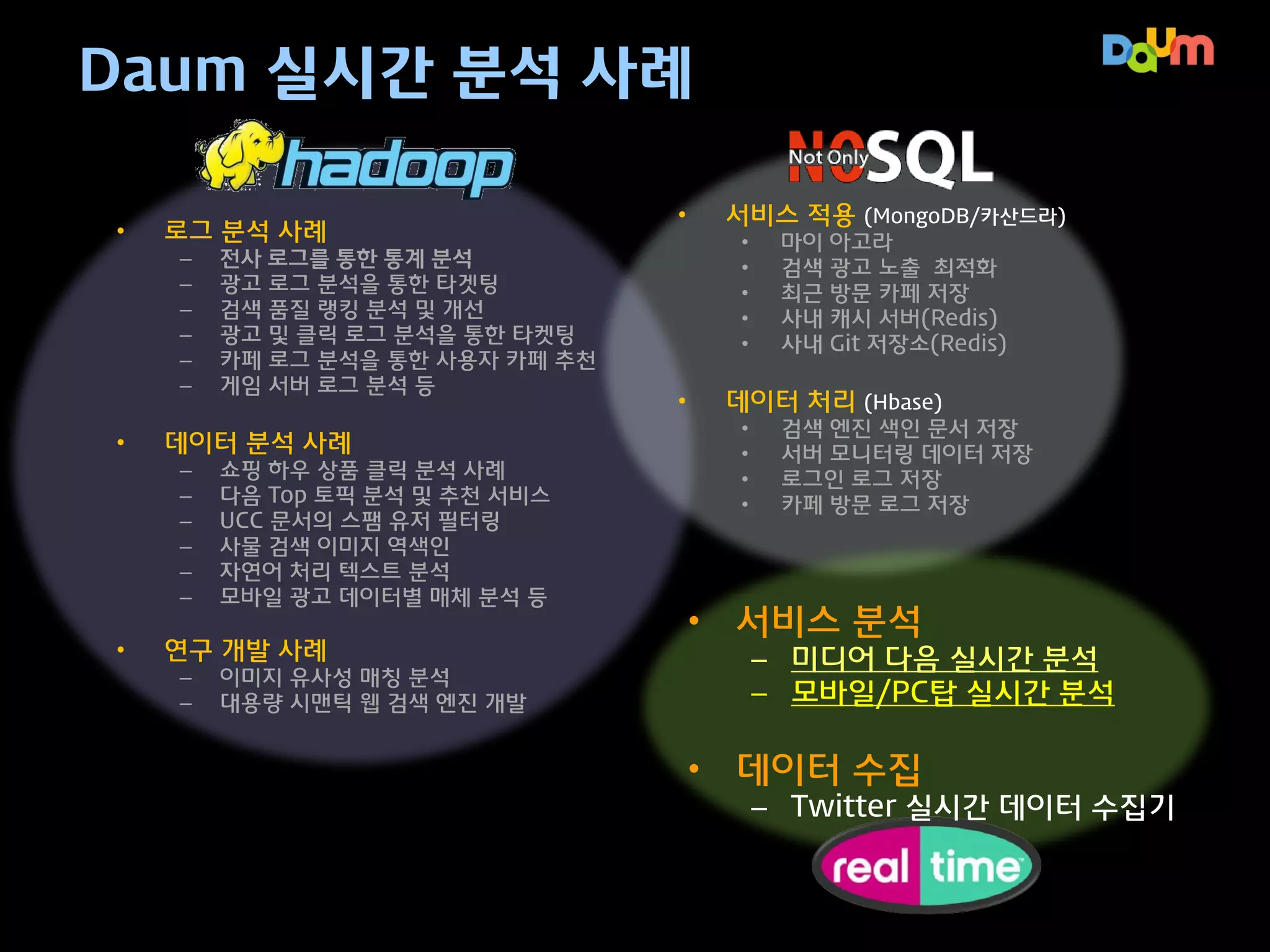
Daum 실시간 분석사례
•
로그 분석 사례
–
–
–
–
–
–
•
데이터 분석 사례
–
–
–
–
–
–
•
전사 로그를 통한 통계 분석
광고 로그 분석을 통한 타겟팅
검색 품질 랭킹 분석 및 개선
광고 및 클릭 로그 분석을 통한 타켓팅
카페 로그 분석을 통한 사용자 카페 추천
게임 서버 로그 분석 등
쇼핑 하우 상품 클릭 분석 사례
다음 Top 토픽 분석 및 추천 서비스
UCC 문서의 스팸 유저 필터링
사물 검색 이미지 역색인
자연어 처리 텍스트 분석
모바일 광고 데이터별 매체 분석 등
연구 개발 사례
–
–
이미지 유사성 매칭 분석
대용량 시맨틱 웹 검색 엔진 개발
•
서비스 적용 (MongoDB/카산드라)
•
•
•
•
•
•
마이 아고라
검색 광고 노출 최적화
최근 방문 카페 저장
사내 캐시 서버(Redis)
사내 Git 저장소(Redis)
데이터 처리 (Hbase)
•
•
•
•
검색 엔진 색인 문서 저장
서버 모니터링 데이터 저장
로그인 로그 저장
카페 방문 로그 저장
• 서비스 분석
– 미디어 다음 실시간 분석
– 모바일/PC탑 실시간 분석
• 데이터 수집
– Twitter 실시간 데이터 수집기
실시간 분석이 필요할때…
활용 대상 영역
– 쇼핑몰 사이트의 사용자 클릭 스트림을 통해 실시간 개인화
– 사용자 위치 정보 기반 광고 및 추천 기능
– 시스템 이벤트를 이용한 실시간 보안 감시
– 차량 추적 및 위치 정보 수집을 이용한 도로 교통 상황 파악
– 사용자의 액션 수집을 이용한 이상 행위 탐지
기획자의 요구 사항
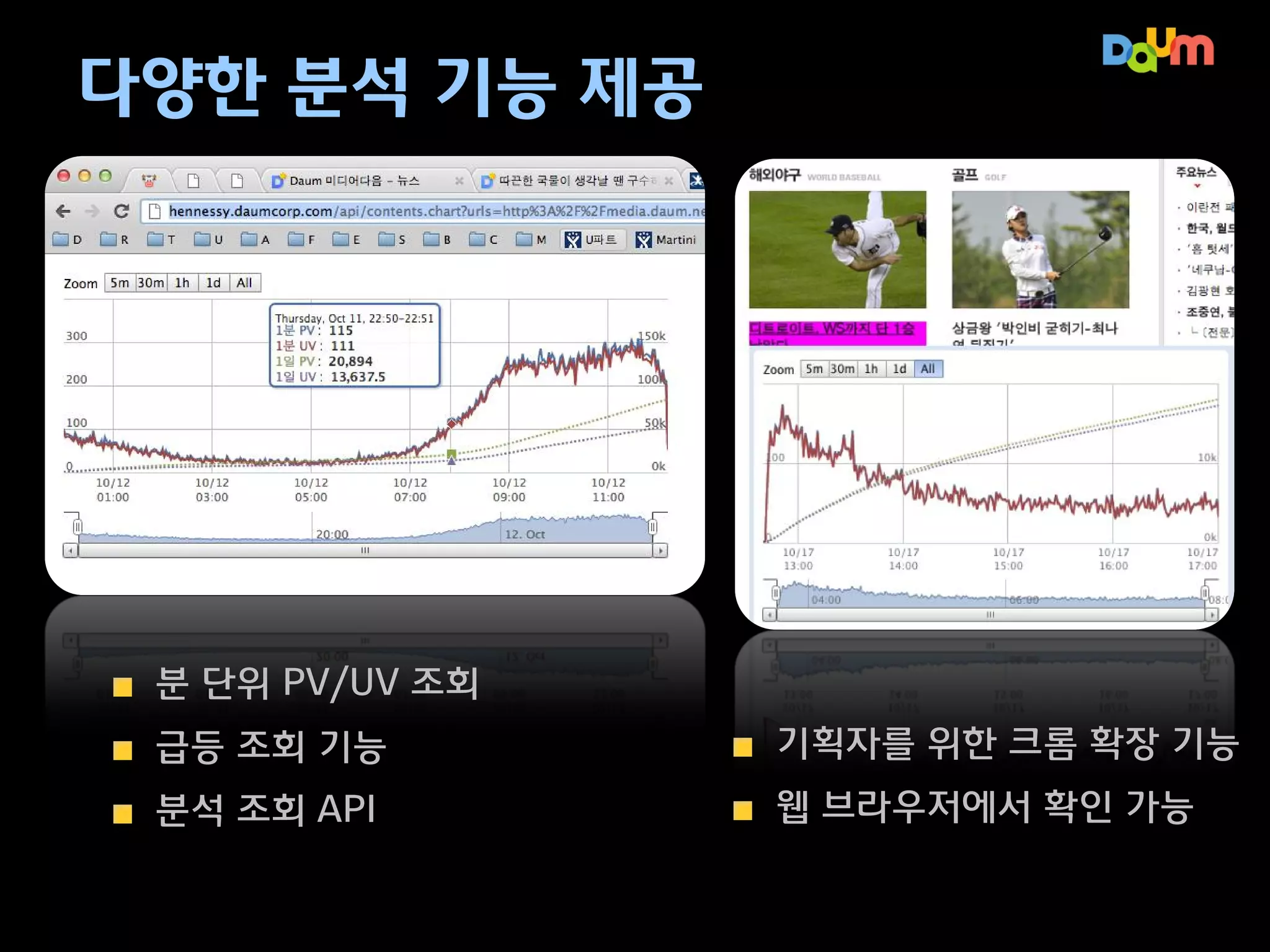
– 데이터가 변화되는 모습을 화면에서 바로 보고 싶다!
– 간결한 차트와 선택 및 실시간 변화를 보고 싶다!
기술 요구 사항
– 로그 수집, 실시간 분석 및 장기 분석을 위한 저장소 필요
– 주기적 차트 생성 및 쿼리에 대한 브라우저 기반 기능도 구현 필요
27.
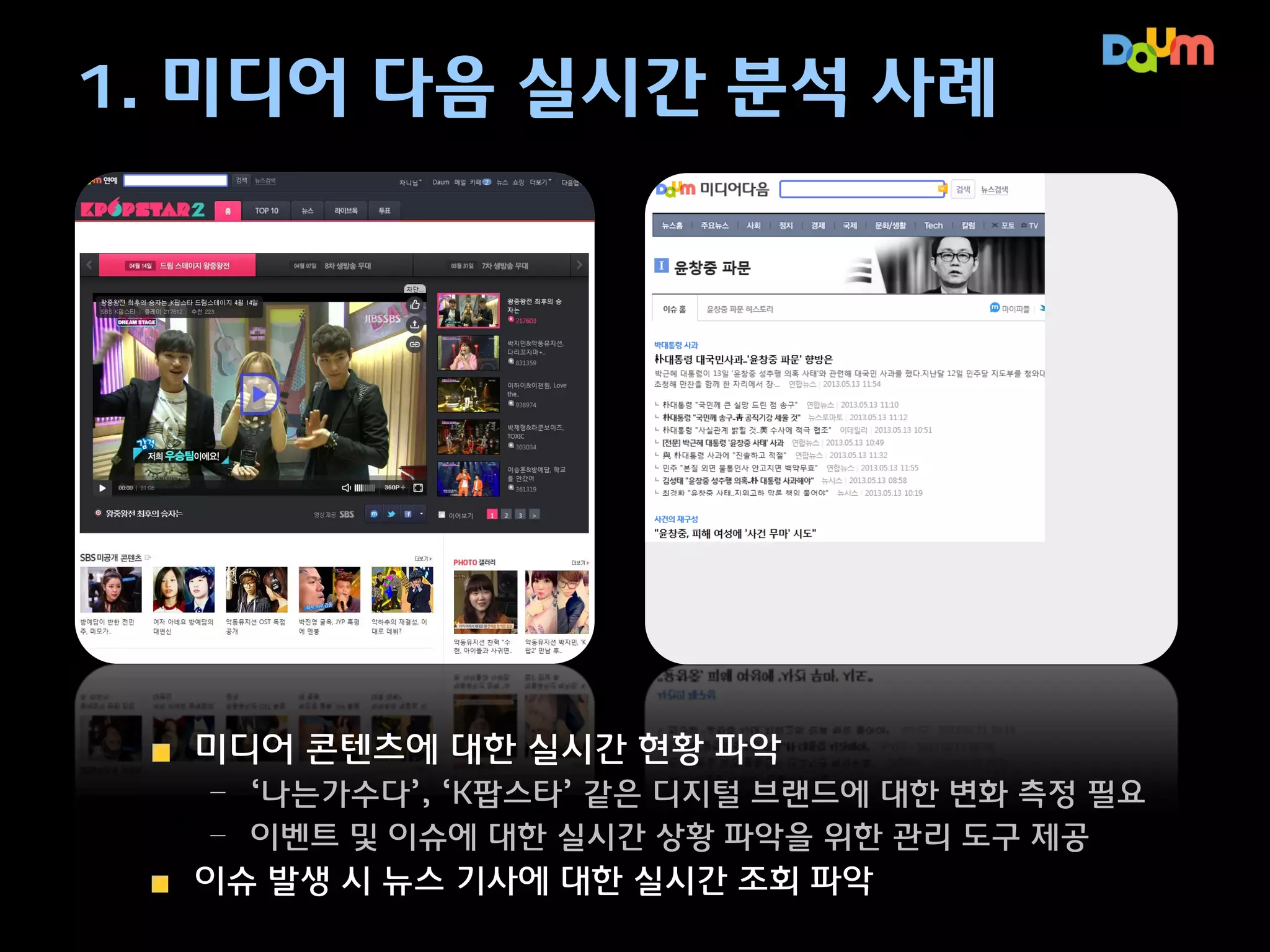
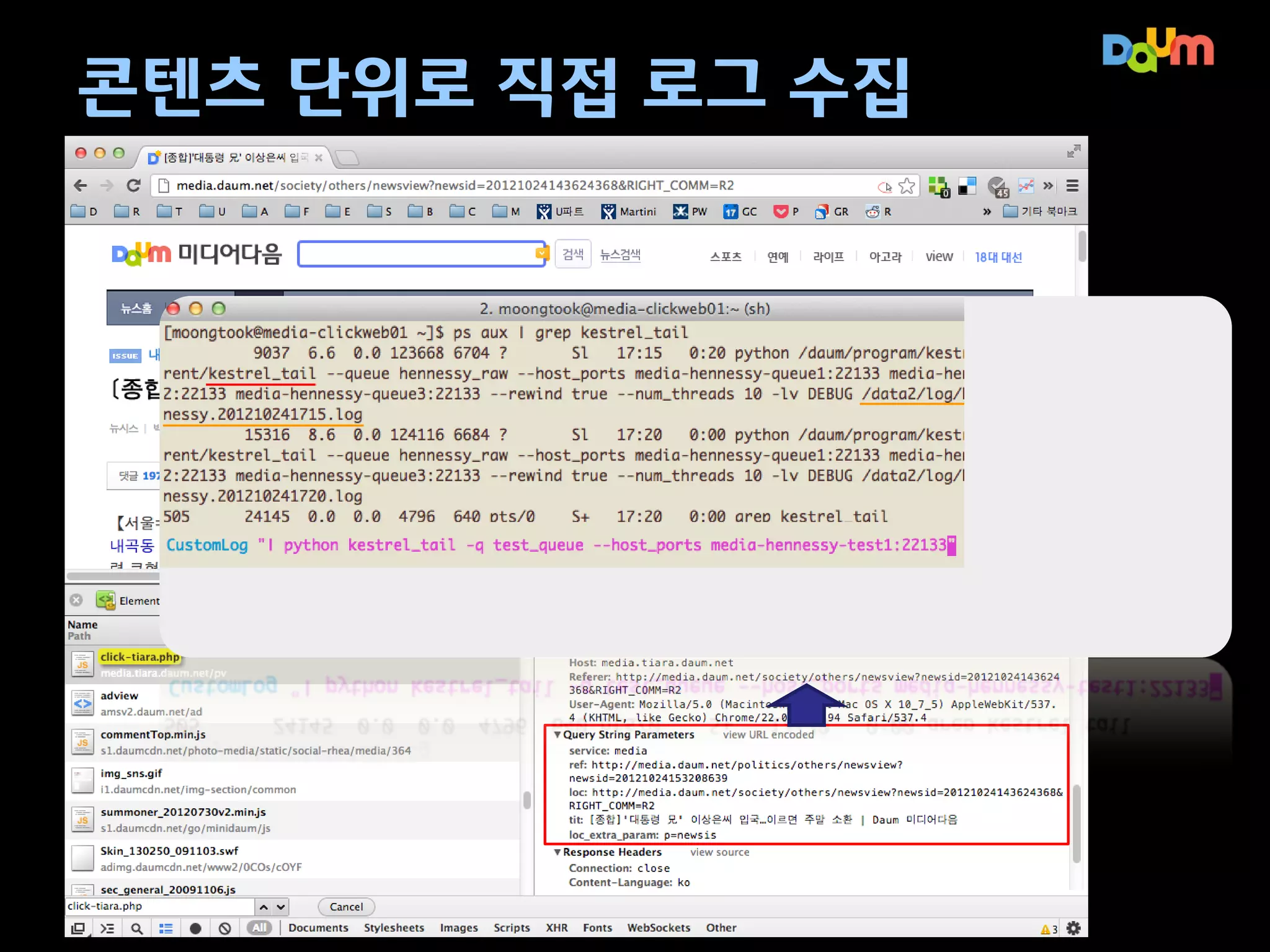
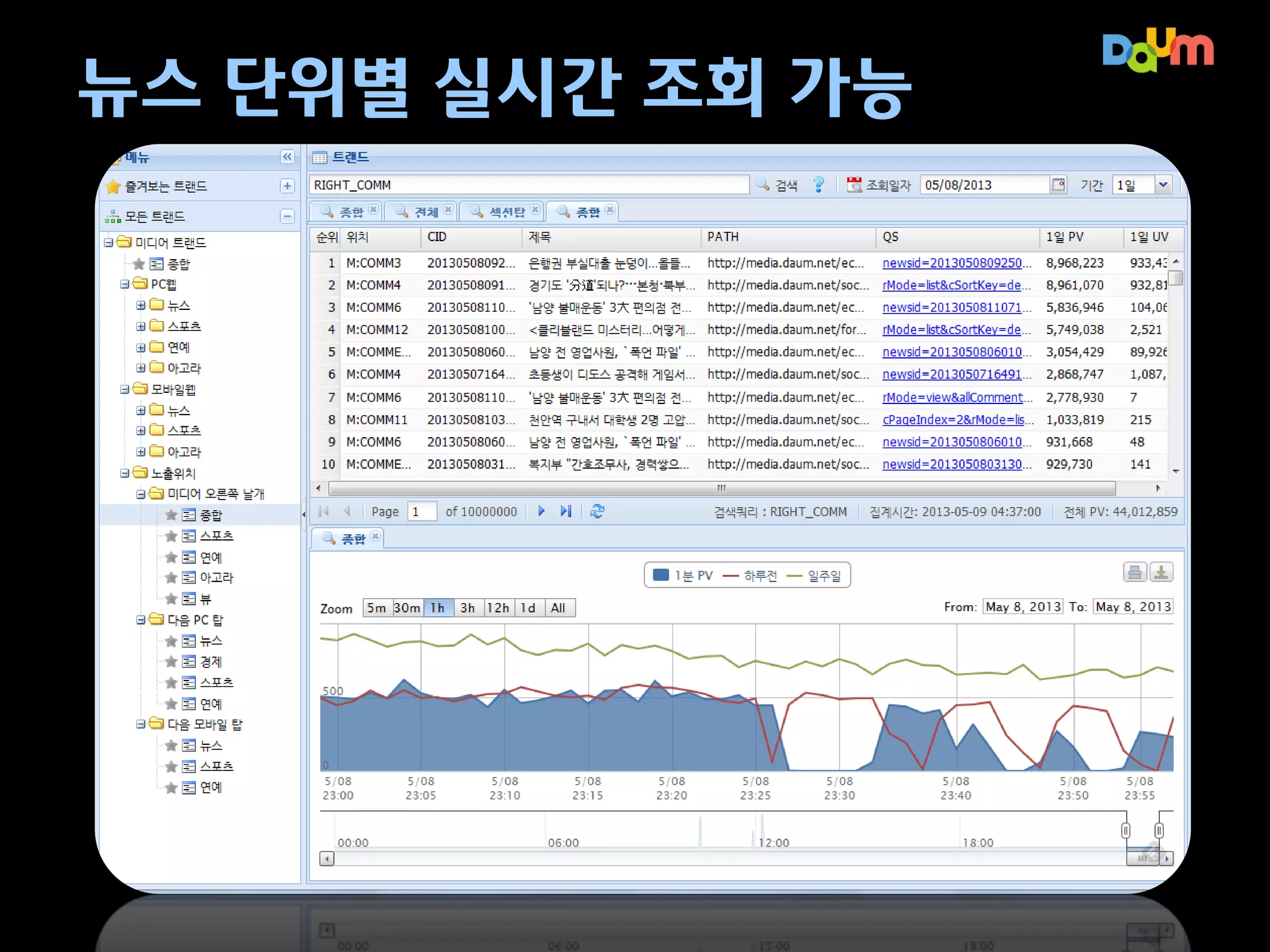
1. 미디어 다음실시간 분석 사례
미디어 콘텐츠에 대한 실시간 현황 파악
– 이슈에 대한 실시간 상황 파악을 위한 관리 도구 제공
미디어 콘텐츠에 대한 실시간 현황 파악
– ‘나는가수다’, ‘K팝스타’ 같은 디지털 브랜드에 대한 변화 측정 필요
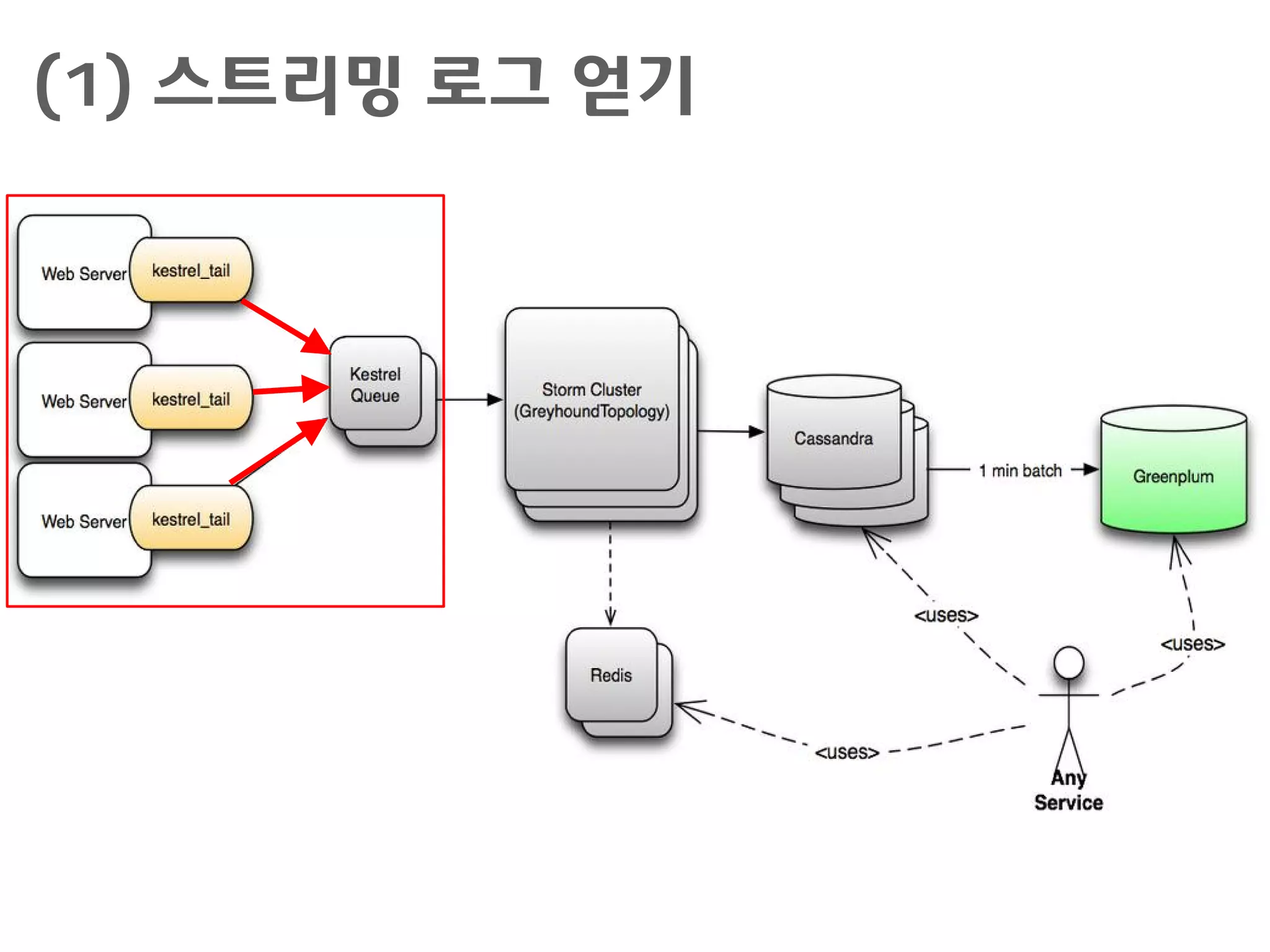
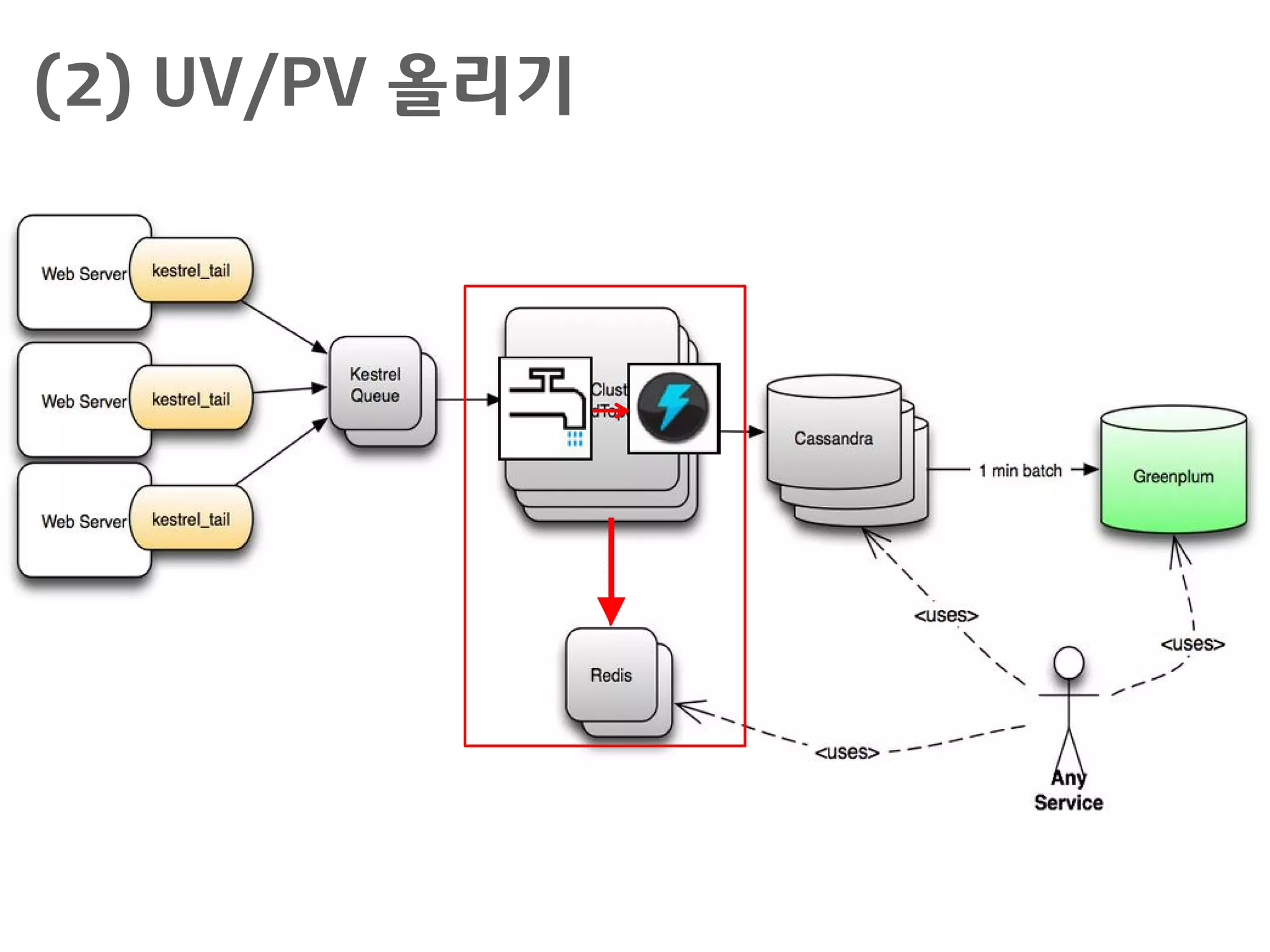
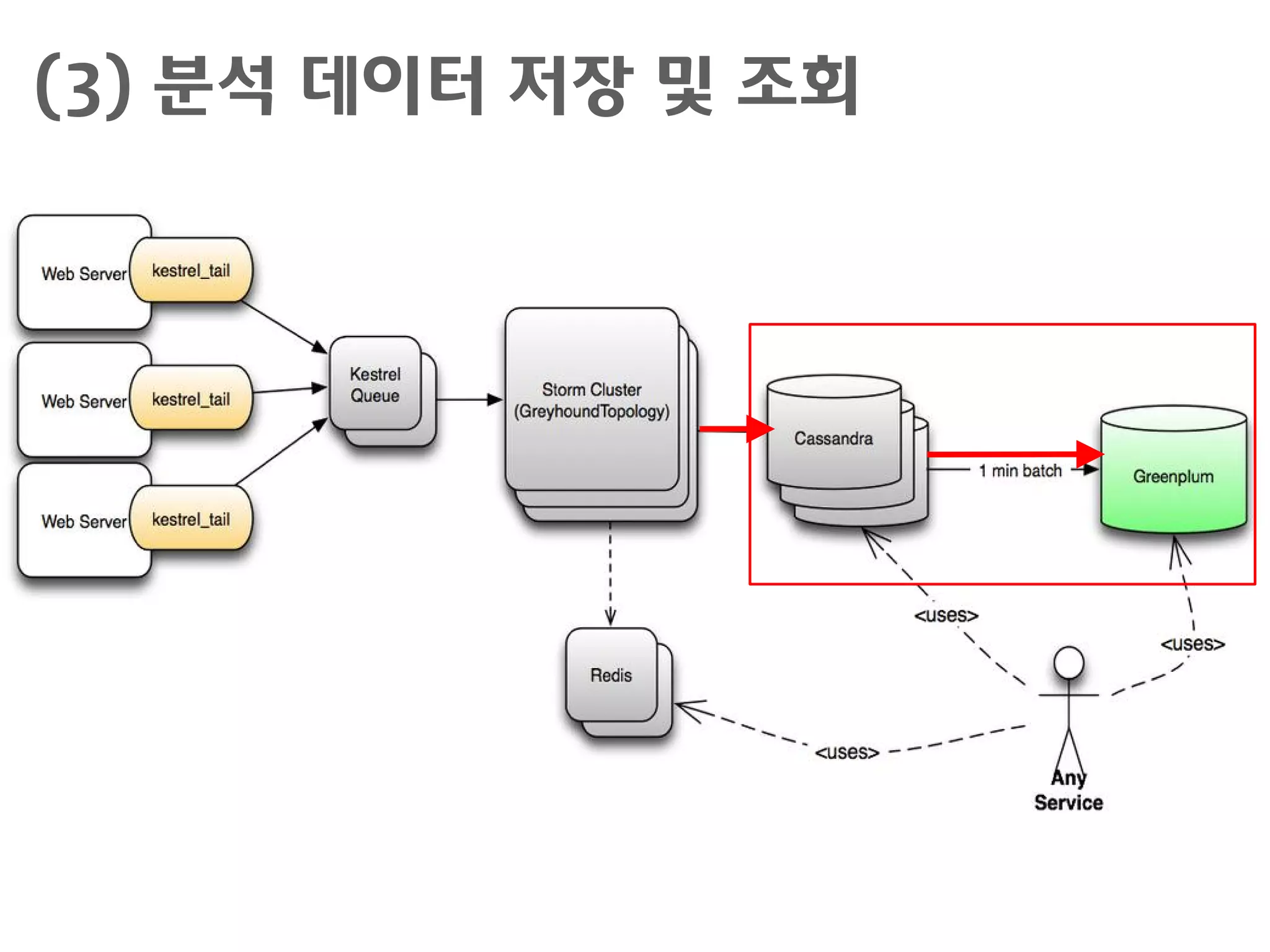
서비스 구현 시활용 기술
Kestrel
– http://robey.github.io/kestrel/
– Blaine Cook의 "starling"을 기반한 JVM 분산 메시지 큐 서버로
서, memcached 및 thrift 프로토콜을 지원
Storm
– https://github.com/nathanmarz/storm/wiki
– 데이터 스트림에 대한 분석 기능을 담당
Redis
– http://redis.io/
– 디스크 I/O 없이 빠르게 처리하기 위해서 in-memory key-value
store로서 임시 분석값을 저장
Cassandra
– http://cassandra.apache.org/
– 많이 이용되는 NoSQL 서버로서 분석값의 영구 저장소로서, Hbase
나 MySQL 등이 활용되기도 함
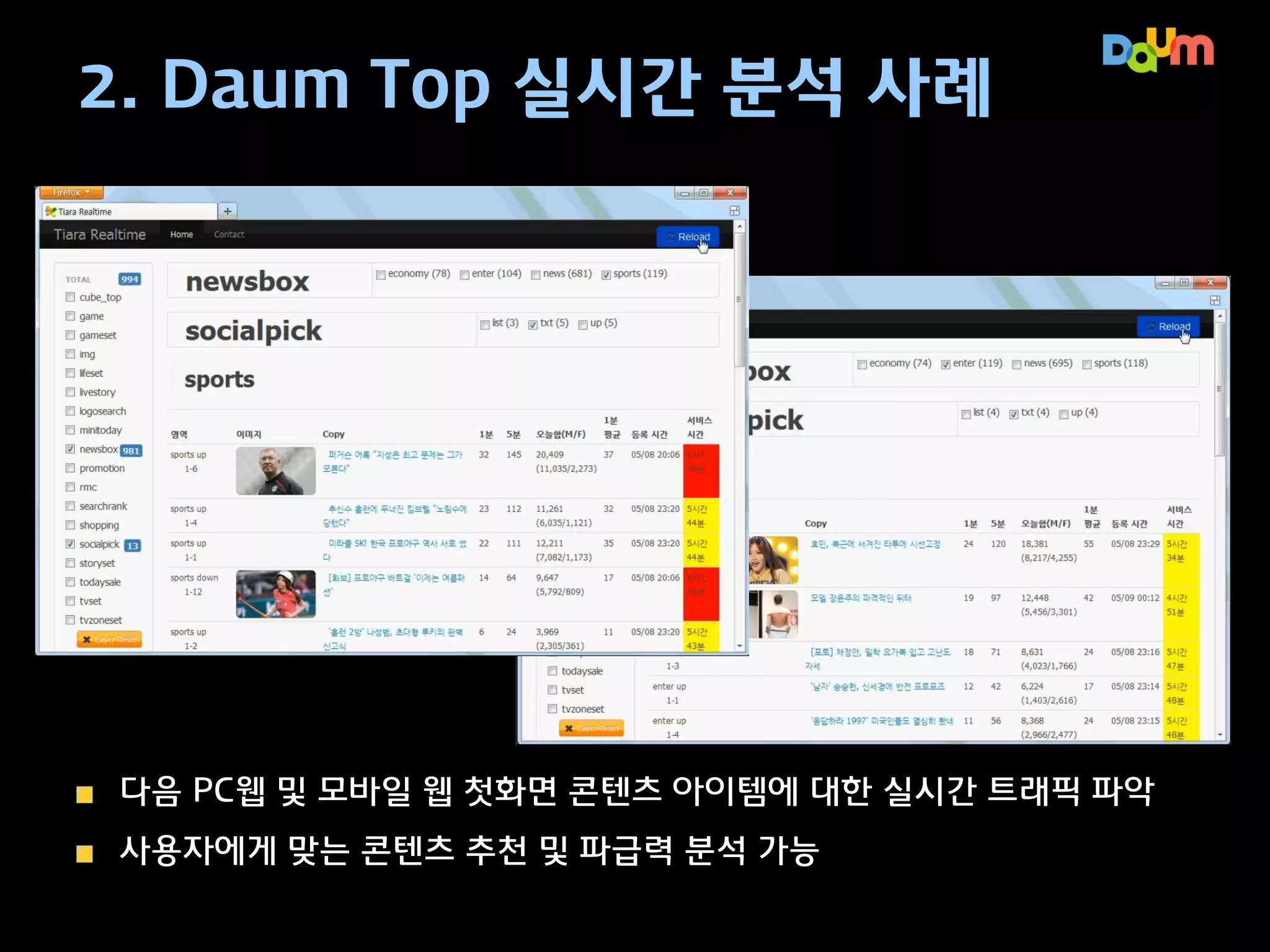
2. Daum Top실시간 분석 사례
다음 PC웹 및 모바일 웹 첫화면 콘텐츠 아이템에 대한 실시간 트래픽 파악
사용자에게 맞는 콘텐츠 추천 및 파급력 분석 가능
39.
3. Twitter 실시간데이터 수집기
Twitter, 티스토리로 부터 오는 Stream Data 저장소
실시간 검색 인덱스를 위한 데이터 수집 및 제공
40.
c.f. 모바일 앱크래시 통계
모바일 앱 디버깅 방식
– 실시간으로 Crashing 데
이터 수집 필요
(Storm/HBase?)
• WebView에서 나는 오류도
많음 빠르게 수정 필요
– 특정 크래시와 관련 버그에
대한 학습 방법이 필요함
(Spark/Shark?)
• 버그와 크래쉬 사이의 관계
최종 사용 기술
– Hbase M/R
오버 엔지니어링은 금물!
41.
실시간 분석 구축시 유의 사항
정말 필요한가?
– Storm/S4 같은 기술을 도입 전 정말 필요한지 확인 해야 함
– 실시간 분석은 명확한 업무 정의가 된 경우에만 수행 해야 함
– 기술 선택 (Batch/Realtime/Query)에 대한 이해 파악 필요
고난을 각오해라!
– 잘 알려진 케이스는 많으나 실제로 구현하다 보면 어려움 봉착
– 시스템 엔지니어링 운영 기술 및 대용량 메모리(~98GB) 기반 서
버팜 등이 필요함
역시 오픈 소스!
– 오픈 소스 커뮤니티의 규모와 문서화 케이스 등으로 지원 가능한
지 확인 후에 진입하는 것이 좋다.
42.
References
1.
김병곤(2013), 데이터를 실시간으로모아서 처리하는 다양한 기법
–
http://www.youtube.com/watch?v=HmVegCGWbsU
–
http://readme.skplanet.com/?p=4605
2.
권동훈(2013), Hadoop에서의 실시간 SQL 질의: Impala
–
3.
http://helloworld.naver.com/helloworld/246342
김우승(2012), 실시간 빅 데이터(Real-time Big Data) 프로세싱 맛보기
–
4.
http://kimws.wordpress.com/2012/03/07/%EC%8B%A4%EC%8B%9C%EA%B0%84
-%EB%B9%85-%EB%8D%B0%EC%9D%B4%ED%84%B0real-time-big-data/
하호진(2012), Storm과 Esper로 실시간 분석 샘플 사용기
–
5.
http://mimul.com/pebble/default/2012/03/14/1331718971671.html
심탁길(2012), 실시간 대용량 데이터 분석 기술과 적용 사례
–
http://www.ktcloudware.com/resources/platform/07.pdf
43.
Daum에는
데이터도 많고 전문가도많습니다!
http://recruit.daum.net
@channyun
channy@daumcorp.com

































![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)














![[Open Technet Summit 2014] 쓰기 쉬운 Hadoop 기반 빅데이터 플랫폼 아키텍처 및 활용 방안](https://cdn.slidesharecdn.com/ss_thumbnails/open-technet-summit-2014-140313001107-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[코세나, kosena] 빅데이터 구축 및 제안 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/random-161220075637-thumbnail.jpg?width=640&height=640&fit=bounds)




![[중소기업형 인공지능/빅데이터 기술 심포지엄] 대용량 거래데이터 분석을 위한 서버인프라 활용 사례](https://cdn.slidesharecdn.com/ss_thumbnails/6-180918045307-thumbnail.jpg?width=640&height=640&fit=bounds)


![[경북] I'mcloud openlight](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudopenlight-151105091914-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[경북] I'mcloud opensight](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudopensight-151105092004-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)













![[다운로드] 한국 웹20주년 기념 소책자](https://cdn.slidesharecdn.com/ss_thumbnails/www20krbook-171013042831-thumbnail.jpg?width=640&height=640&fit=bounds)









