About ME
우육빛깔 까칠행원
fromkakaoBank
절대 깨지지 않는 견고한 서비스를 지향하는 국내 최초(아마도) 은행 오픈소스 데이터베이스 엔지니어
(KT하이텔 > 티몬 > 카카오 > 한국카카오은행)
http://gywn.net
https://www.facebook.com/dongchan.sung
3.
CONTENTS
1. MySQL inBanking Service
2. Stability with MySQL
3. Scale-Out
4. As an open source dba
final..
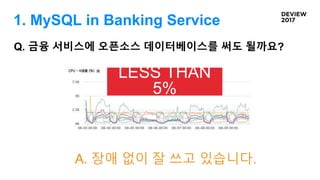
Q. 트래픽은 어때요?
초당트래픽
5,000 DML, 10,000
QUERIES
10,000 DML, 20,000
QUERIES
A. 엄청 들어와요. 화들짝 놀랐어요.
1. MySQL in Banking Service
10.
Q. 그래서 써도된다고요?
금융 서비스에 잘 쓰고 있고
중요 서비스에 잘 활용되고 있고
트래픽도 엄청 많이 들어옵니다
A. 네, 쓰세요. 대신 잘 쓰셔야 해요.
(지금부터 잘 쓰기 위해 우리가 고민했던 이야기 풀어보겠습니다.)
1. MySQL in Banking Service
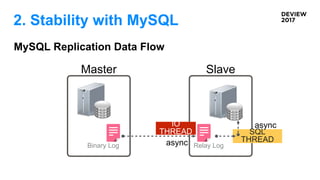
2. Stability withMySQL
MHA
30초 이내로 데이터 유실없이 복구한다.
(Master High Availability)
24.
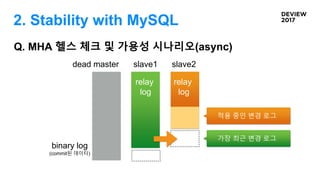
Q. MHA 헬스체크 및 가용성 시나리오
2. Stability with MySQL
MASTER
MHA MANAGER
Fail!
Fail!
Fail!
3초마다 마스터 DB 헬스 체크
CONNECT / SELECT / INSERT
헬스 체크 3회 실패 시, 장애 인지
페일오버 시작
1
2
3
25.
Q. MHA 헬스체크 및 가용성 시나리오(async)
2. Stability with MySQL
dead master slave1 slave2
binary log
(commit된 데이터)
relay
log
relay
log
가장 최근 변경 로그
적용 중인 변경 로그
26.
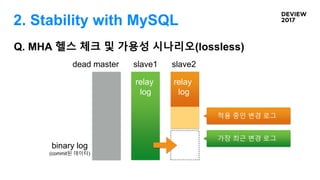
Q. MHA 헬스체크 및 가용성 시나리오(lossless)
2. Stability with MySQL
dead master slave1 slave2
relay
log
relay
log
binary log
(commit된 데이터)
가장 최근 변경 로그
적용 중인 변경 로그
27.
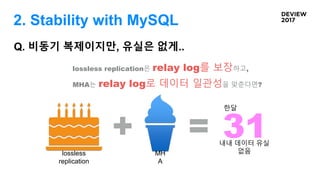
Q. 비동기 복제이지만,유실은 없게..
2. Stability with MySQL
31+ =
lossless
replication
MH
A
한달
내내 데이터 유실
없음
lossless replication은 relay log를 보장하고,
MHA는 relay log로 데이터 일관성을 맞춘다면?
28.
Q. 하나 더얻은 값진 효과!
DISK
2. Stability with MySQL
디스크 의존성 탈피
리플리케이션에서는
데이터 유실 없다
29.
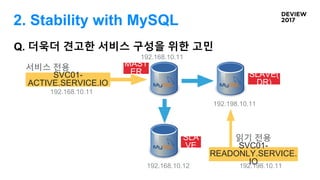
Q. 더욱더 견고한서비스 구성을 위한 고민
Domain Failover
VIP Failover
2. Stability with MySQL
30.
Q. 더욱더 견고한서비스 구성을 위한 고민
MAST
ER
SLA
VE
SLAVE(
DR)
192.168.10.12
192.198.10.11
읽기 전용
192.198.10.11
SVC01-
READONLY.SERVICE.
IO
SVC01-
ACTIVE.SERVICE.IO
192.168.10.11
서비스 전용
192.168.10.11
2. Stability with MySQL
31.
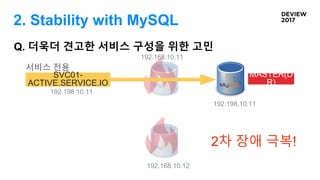
Q. 더욱더 견고한서비스 구성을 위한 고민
192.168.10.12
192.198.10.11
SLAVE(
DR)
MAST
ERSVC01-
ACTIVE.SERVICE.IO
192.168.10.12
서비스 전용
1차 장애 극복!
192.168.10.11
2. Stability with MySQL
32.
Q. 더욱더 견고한서비스 구성을 위한 고민
192.168.10.12
192.198.10.11
MASTER(D
R)
2차 장애 극복!
SVC01-
ACTIVE.SERVICE.IO
192.198.10.11
서비스 전용
192.168.10.11
2. Stability with MySQL
33.
Q. 주의할 점!
하나.서비스 도메인의 TTL은 0으로 설정합니다.
둘. DNS 캐싱을 하지않도록, 자바 구동 옵션을 줍니다.
-Dsun.net.inetaddr.ttl=0
http://gywn.net/2017/01/install_powerdns_with_mysql_backend/
(powerDNS를 내부 정책에 따라 도입을 못했으나, 초반에 이런 식의 활용도 고민했습니다)
셋. 서비스는 되도록이면 커넥션 풀로 동작해야 합니다.
2. Stability with MySQL
3. Scale-Out
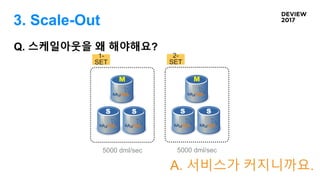
Q. 스케일아웃을왜 해야해요?
M
S S
1-
SET
5000 dml/sec
M
S S
2-
SET
5000 dml/sec
A. 서비스가 커지니까요.
37.
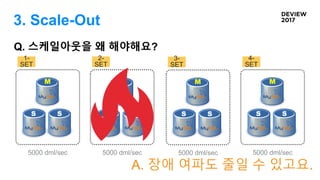
3. Scale-Out
Q. 스케일아웃을왜 해야해요?
M
S S
3-
SET
5000 dml/sec
M
S S
4-
SET
5000 dml/sec
M
S S
2-
SET
5000 dml/sec
M
S S
1-
SET
5000 dml/sec
A. 장애 여파도 줄일 수 있고요.
38.
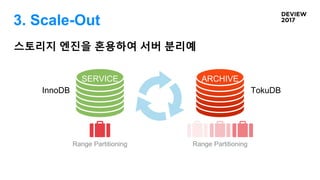
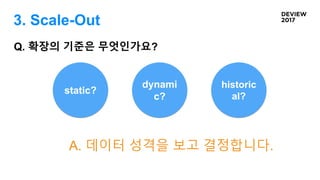
3. Scale-Out
Q. 확장의기준은 무엇인가요?
거의 변경 없
음
사용자가 생성하는
변경이 잦거나
로그 성격 데이터
STA
TIC
DYNA
MIC
HISTORI
CAL
39.
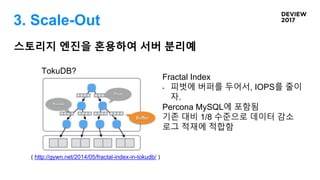
3. Scale-Out
Q. 확장의기준은 무엇인가요?
STA
TIC
사용자가 생성하는
변경이 잦거나
로그 성격 데이터
DYNA
MIC
HISTORI
CAL
Cache Cache Cache
‣캐시가 느리면, DB가 대처
‣DB가 흔들리면, 캐시가 대응





















































![[2018] MySQL 이중화 진화기](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra03-190131073325-thumbnail.jpg?width=640&height=640&fit=bounds)








![[오픈소스컨설팅]Day #1 MySQL 엔진소개, 튜닝, 백업 및 복구, 업그레이드방법](https://cdn.slidesharecdn.com/ss_thumbnails/day1mysqlintroduction-141212003401-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)










![[115]14일만에 깃헙 스타 1,000개 받은 차트 오픈소스 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/15141000-171016060341-thumbnail.jpg?width=640&height=640&fit=bounds)

![[131]chromium binging 기술을 node.js에 적용해보자](https://cdn.slidesharecdn.com/ss_thumbnails/31chromiumbingdingfinal-171015225736-thumbnail.jpg?width=640&height=640&fit=bounds)
![[111]open, share, enjoy 네이버의 오픈소스 활동](https://cdn.slidesharecdn.com/ss_thumbnails/11openshareenjoy-171016004935-thumbnail.jpg?width=640&height=640&fit=bounds)
![[141]네이버랩스의 로보틱스 연구 소개](https://cdn.slidesharecdn.com/ss_thumbnails/41-171015225628-thumbnail.jpg?width=640&height=640&fit=bounds)
![[124]자율주행과 기계학습](https://cdn.slidesharecdn.com/ss_thumbnails/124-171016052833-thumbnail.jpg?width=640&height=640&fit=bounds)

![[123]동네 커피샵도 사이렌 오더를 쓸 수 있을까](https://cdn.slidesharecdn.com/ss_thumbnails/23-171016044352-thumbnail.jpg?width=640&height=640&fit=bounds)
![[125] 머신러닝으로 쏟아지는 유저 cs 답변하기](https://cdn.slidesharecdn.com/ss_thumbnails/25cs-171016061055-thumbnail.jpg?width=640&height=640&fit=bounds)
![[132]웨일 브라우저 1년 그리고 미래](https://cdn.slidesharecdn.com/ss_thumbnails/321-171016021602-thumbnail.jpg?width=640&height=640&fit=bounds)
![[143]알파글래스의 개발과정으로 알아보는 ar 스마트글래스 광학 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/43ar-171016045445-thumbnail.jpg?width=640&height=640&fit=bounds)
![[141] 오픈소스를 쓰려는 자, 리베이스의 무게를 견뎌라](https://cdn.slidesharecdn.com/ss_thumbnails/141deview2017-171016055311-thumbnail.jpg?width=640&height=640&fit=bounds)

![[112]clova platform 인공지능을 엮는 기술](https://cdn.slidesharecdn.com/ss_thumbnails/12clovaplatform-171016022611-thumbnail.jpg?width=640&height=640&fit=bounds)
![[113]how can realm_make_efficient_mobile_database](https://cdn.slidesharecdn.com/ss_thumbnails/13howcanrealmmakeefficientmobiledatabase2-171016050029-thumbnail.jpg?width=640&height=640&fit=bounds)
![[142] 생체 이해에 기반한 로봇 – 고성능 로봇에게 인간의 유연함과 안전성 부여하기](https://cdn.slidesharecdn.com/ss_thumbnails/142-171016082840-thumbnail.jpg?width=640&height=640&fit=bounds)


![[216]네이버 검색 사용자를 만족시켜라! 의도파악과 의미검색](https://cdn.slidesharecdn.com/ss_thumbnails/216-171017052320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]big models without big data using domain specific deep networks in data-...](https://cdn.slidesharecdn.com/ss_thumbnails/212bigmodelswithoutbigdatausingdomain-specificdeepnetworksindata-scarcesettings-171017003514-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWS Builders] 우리 워크로드에 맞는 데이터베이스 찾기](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws201webinardatabasejuyeonpark-190306072417-thumbnail.jpg?width=640&height=640&fit=bounds)




![[2015 07-06-윤석준] Oracle 성능 최적화 및 품질 고도화 4](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-06-oracle4-150702090606-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




![[오픈소스컨설팅]Day #3 MySQL Monitoring, Trouble Shooting](https://cdn.slidesharecdn.com/ss_thumbnails/day3mysqlmonitoringtroubleshooting-141215041202-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)









![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)