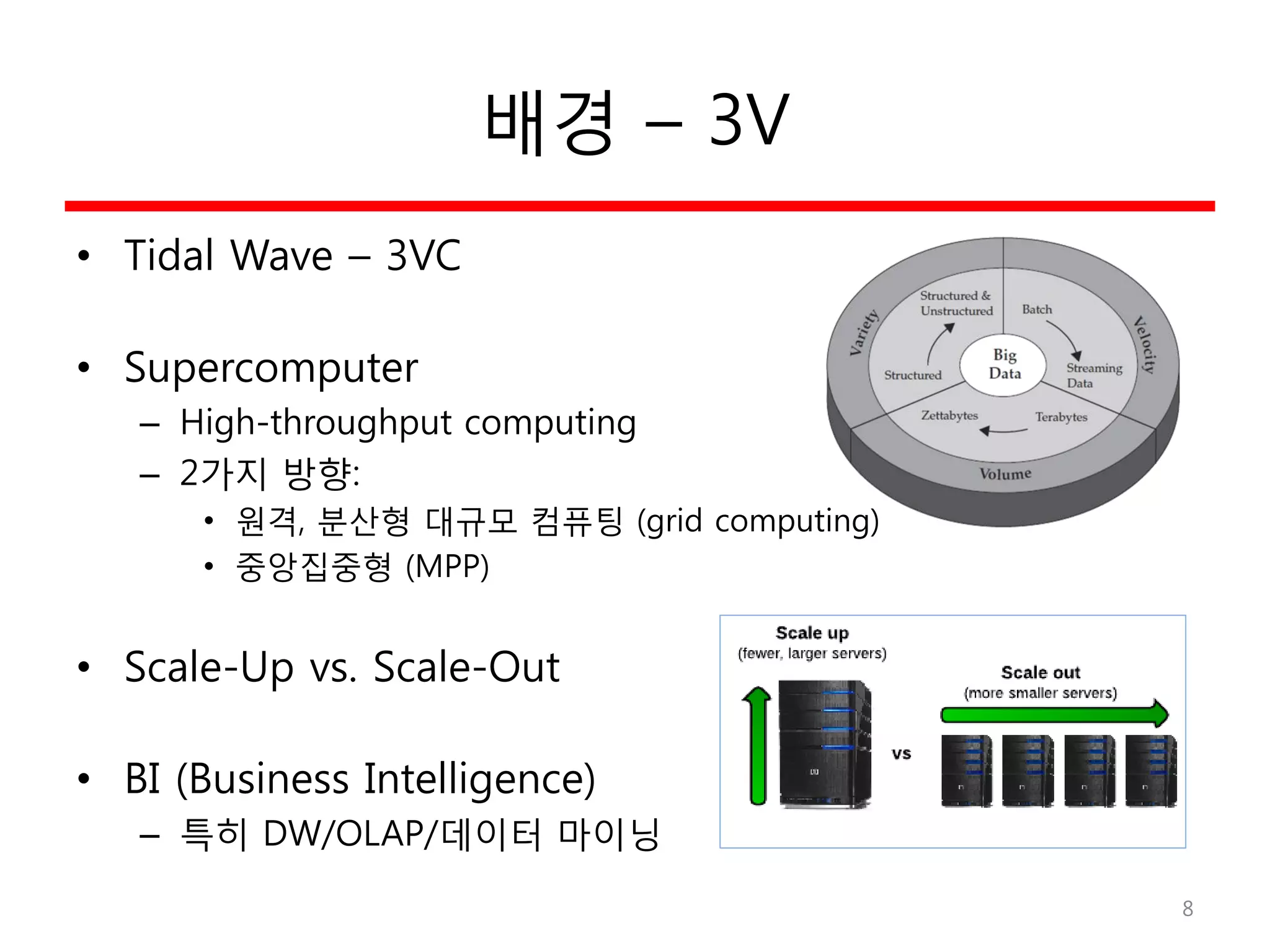
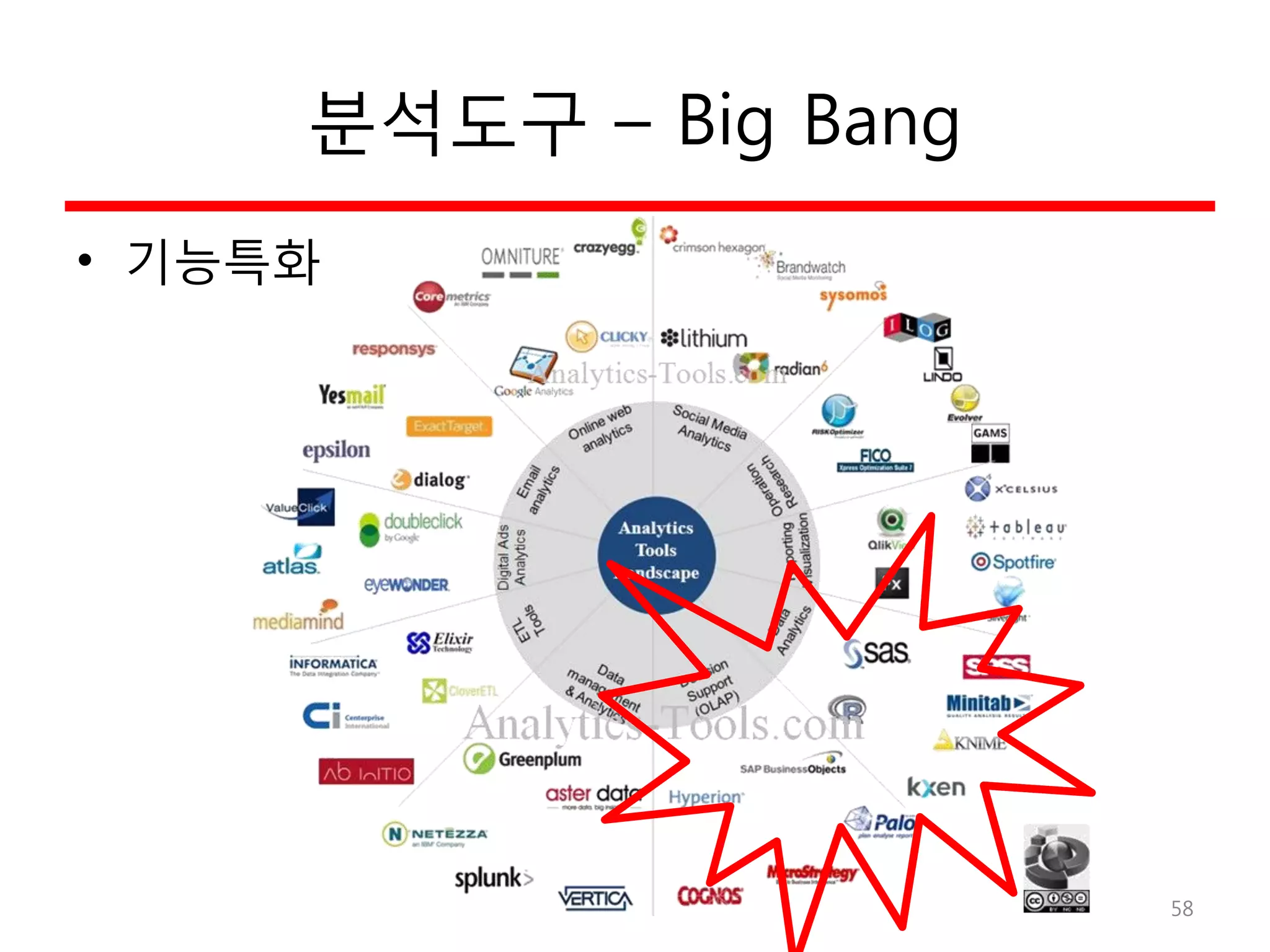
배경 – 3V
•Tidal Wave – 3VC
• Supercomputer
– High-throughput computing
– 2가지 방향:
• 원격, 분산형 대규모 컴퓨팅 (grid computing)
• 중앙집중형 (MPP)
• Scale-Up vs. Scale-Out
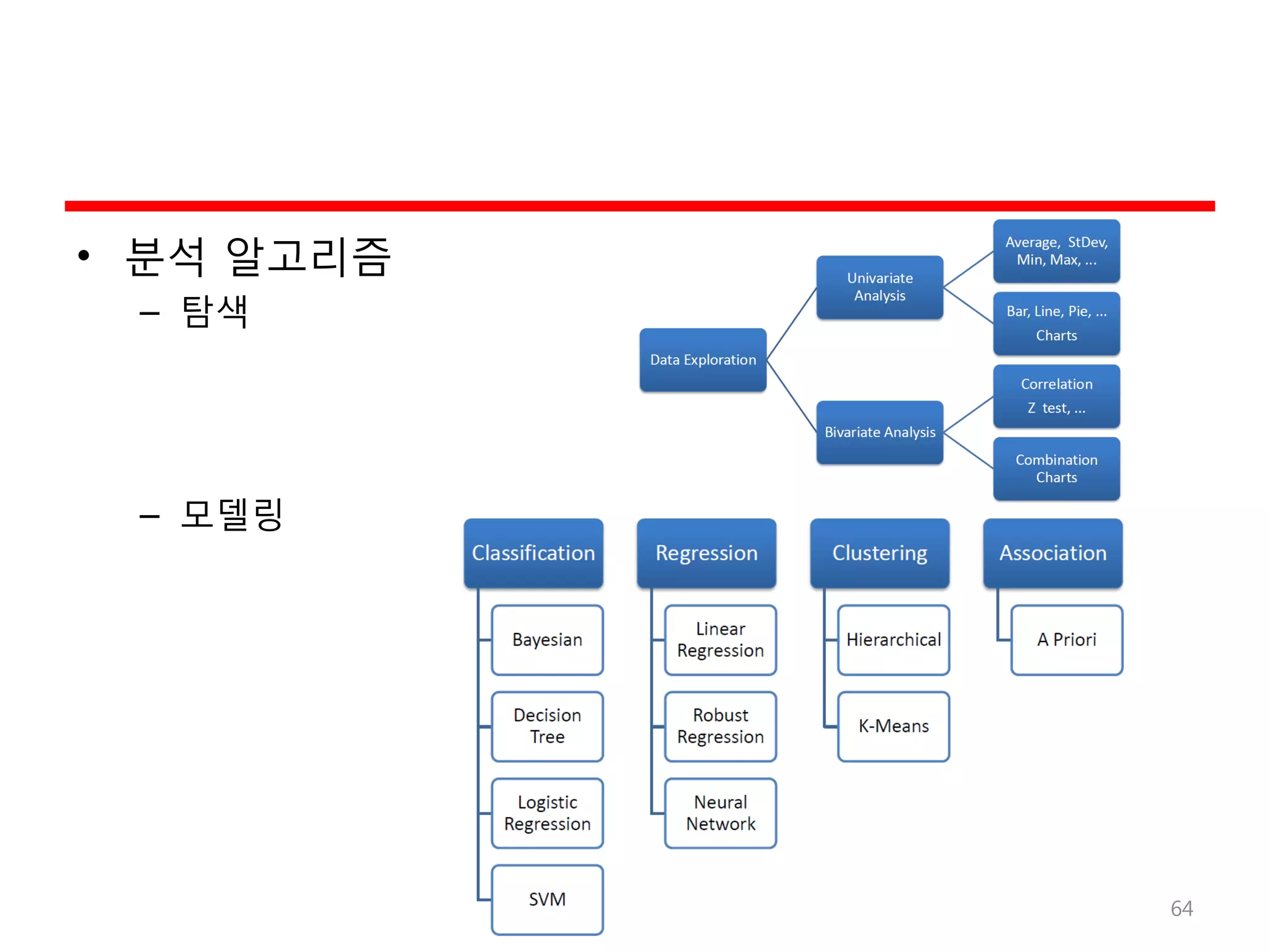
• BI (Business Intelligence)
– 특히 DW/OLAP/데이터 마이닝
8
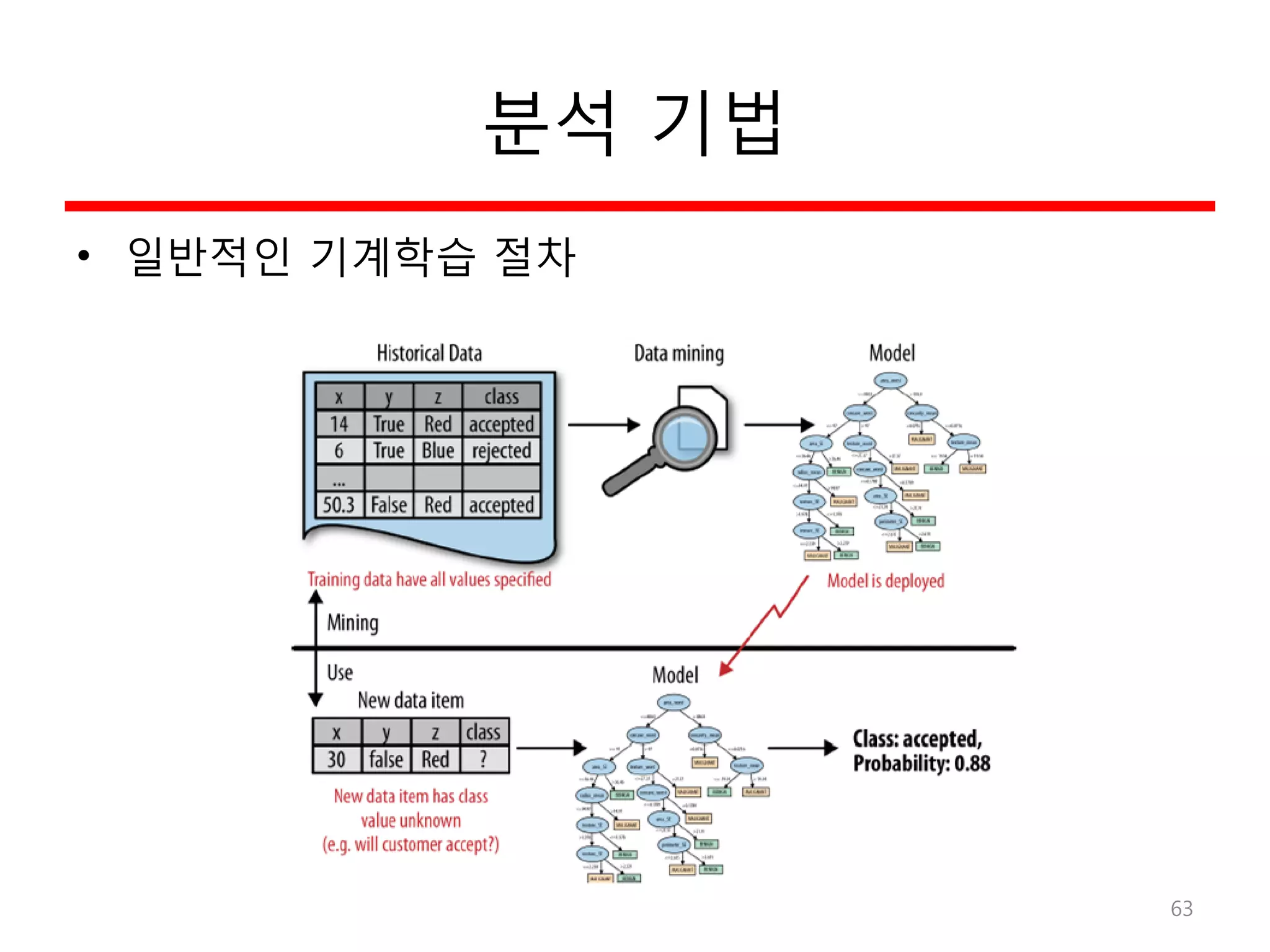
9.
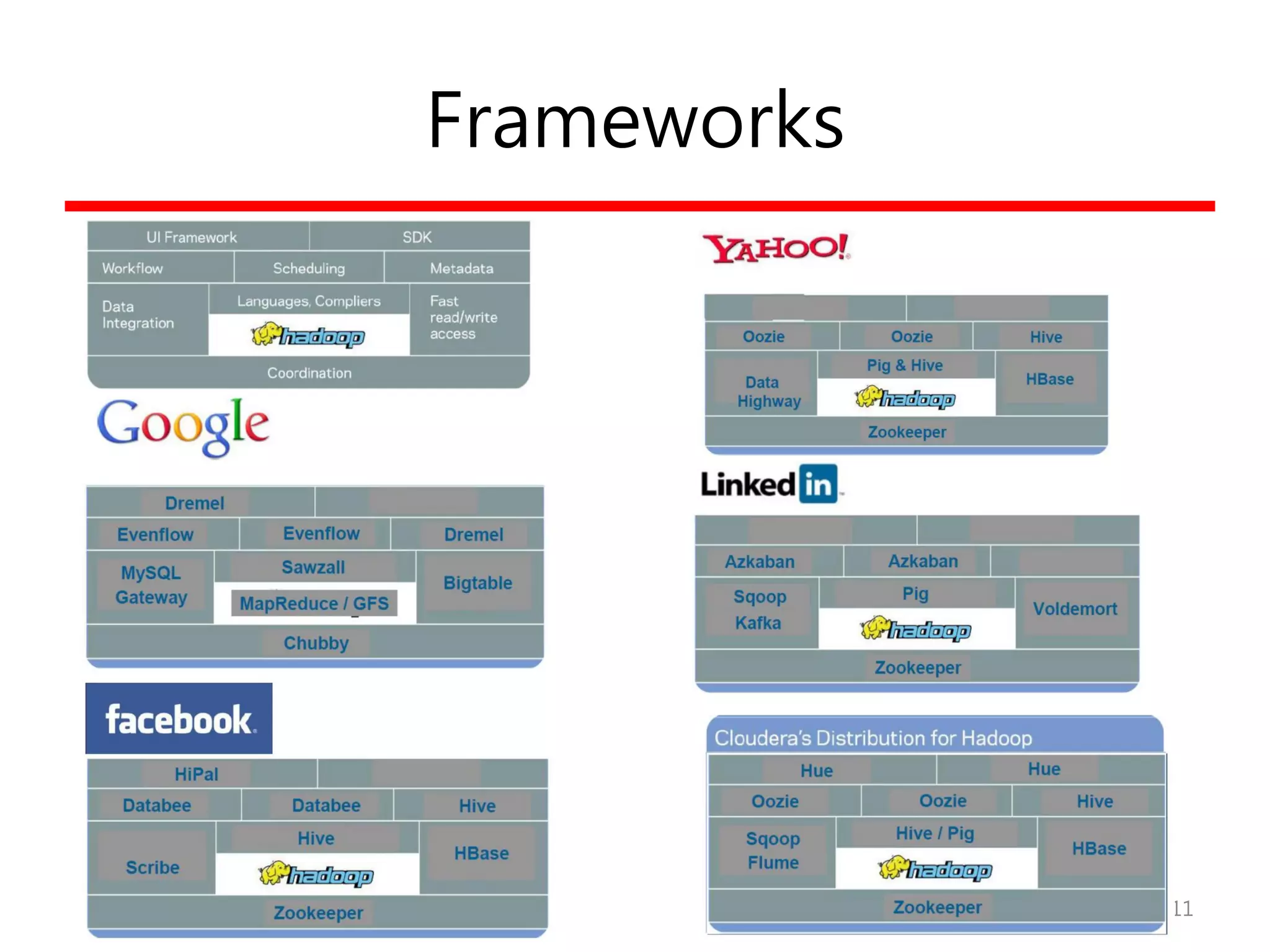
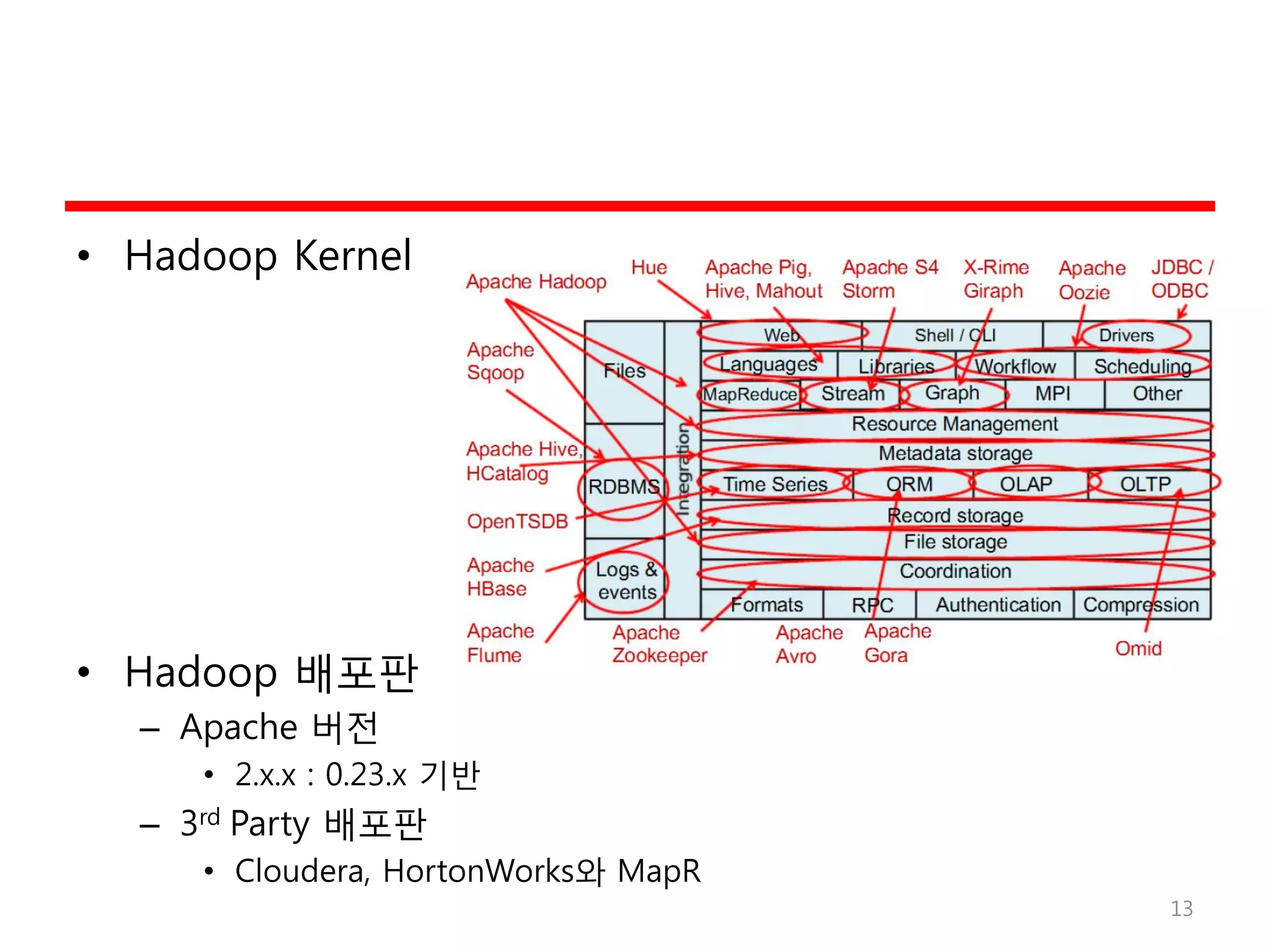
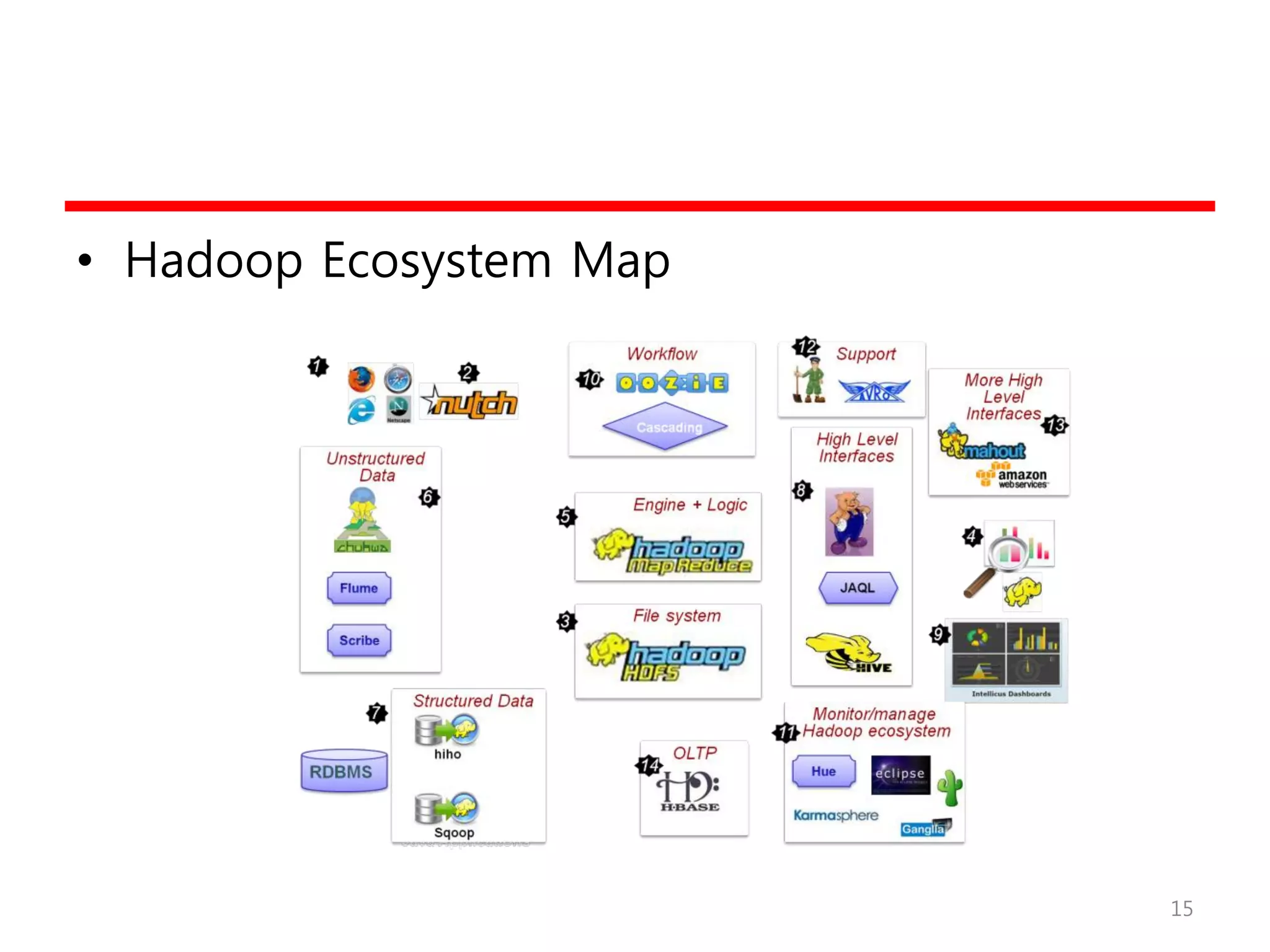
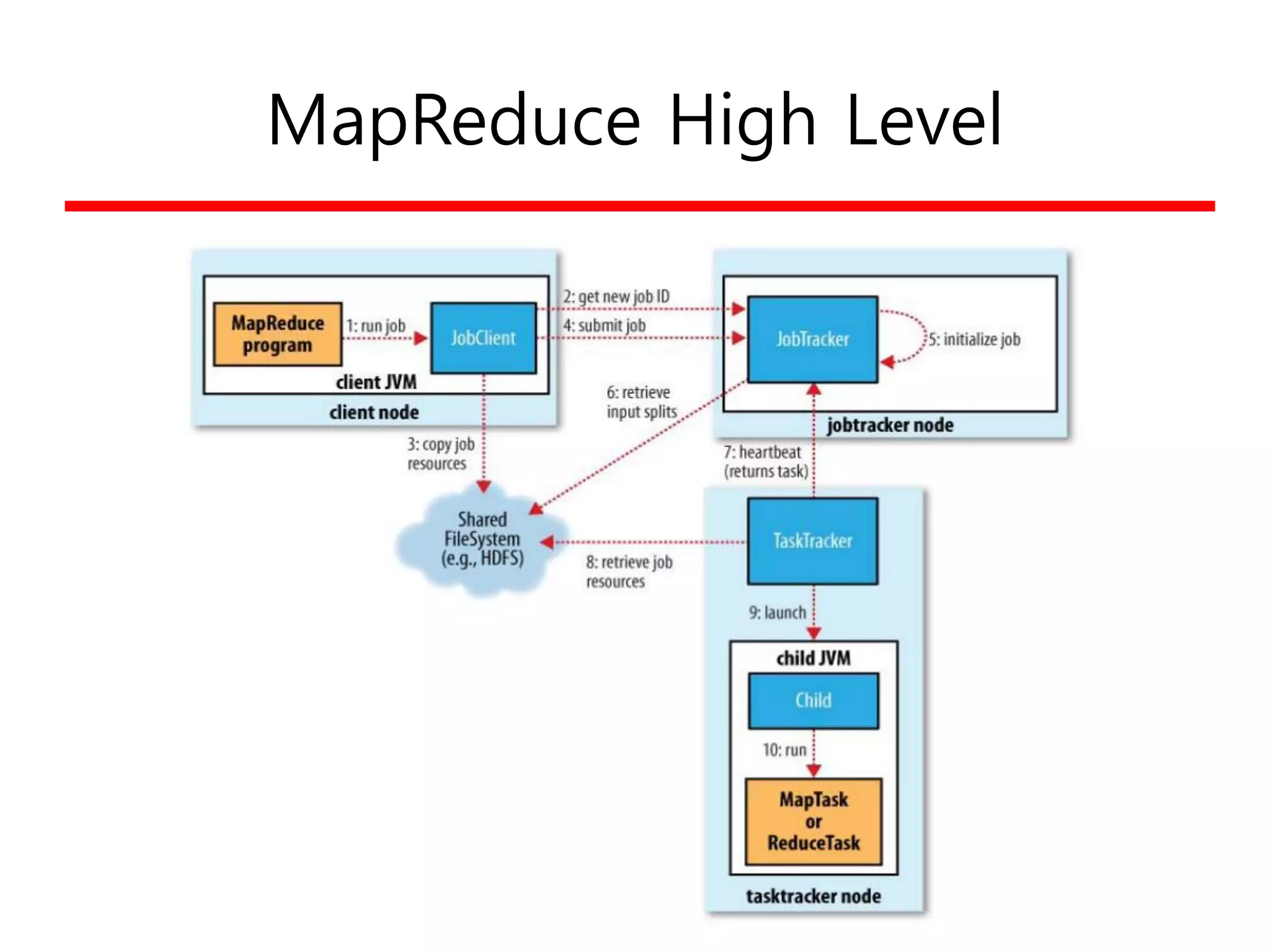
Hadoop
• Hadoop의 탄생?
–배경
• Google!
• Nutch/Lucene 프로젝트에서 2006년 독립
– Doug Cutting
– Apache의 top-level 오픈소스 프로젝트
– 특징
• 대용량 데이터 분산처리 프레임워크
– http://hadoop.apache.org – 순수 S/W
• 프로그래밍 모델의 단순화로 선형 확장성 (Flat linearity)
– “function-to-data model vs. data-to-function” (Locality)
– KVP (Key-Value Pair)
9
10.
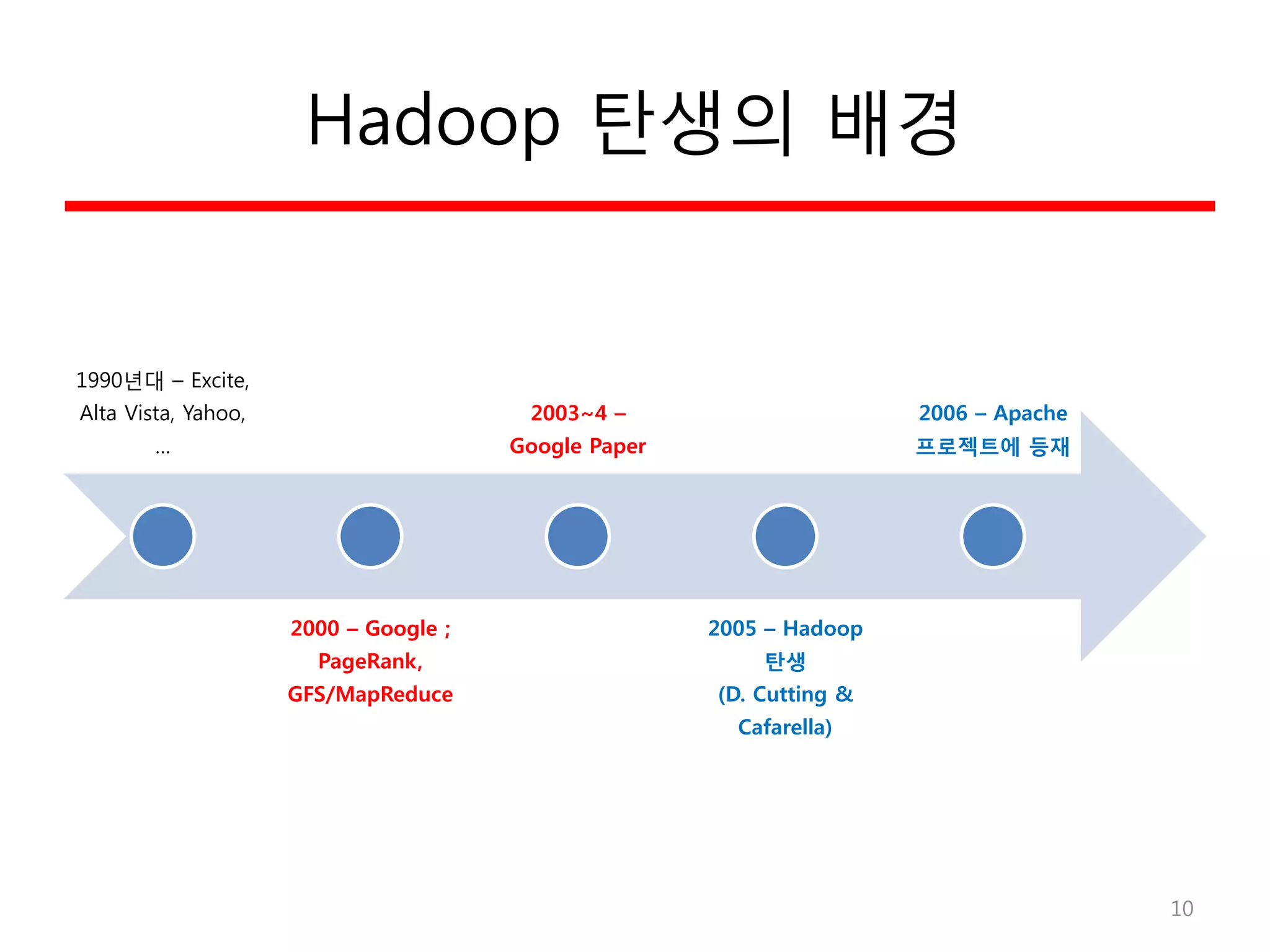
Hadoop 탄생의 배경
1990년대– Excite,
Alta Vista, Yahoo,
…
2000 – Google ;
PageRank,
GFS/MapReduce
2003~4 –
Google Paper
2005 – Hadoop
탄생
(D. Cutting &
Cafarella)
2006 – Apache
프로젝트에 등재
10
요구사항
• Commodity hardware
–잦은 고장은 당연한 일
• 수 많은 대형 파일
– 수백 GB or TB
– 대규모 streaming reads – Not random access
• “Write-once, read-many-times”
• High throughput 이 low latency보다 더 중요
• “Modest” number of HUGE files
– Just millions; Each > 100MB & multi-GB files typical
• Large streaming reads
– …
19.
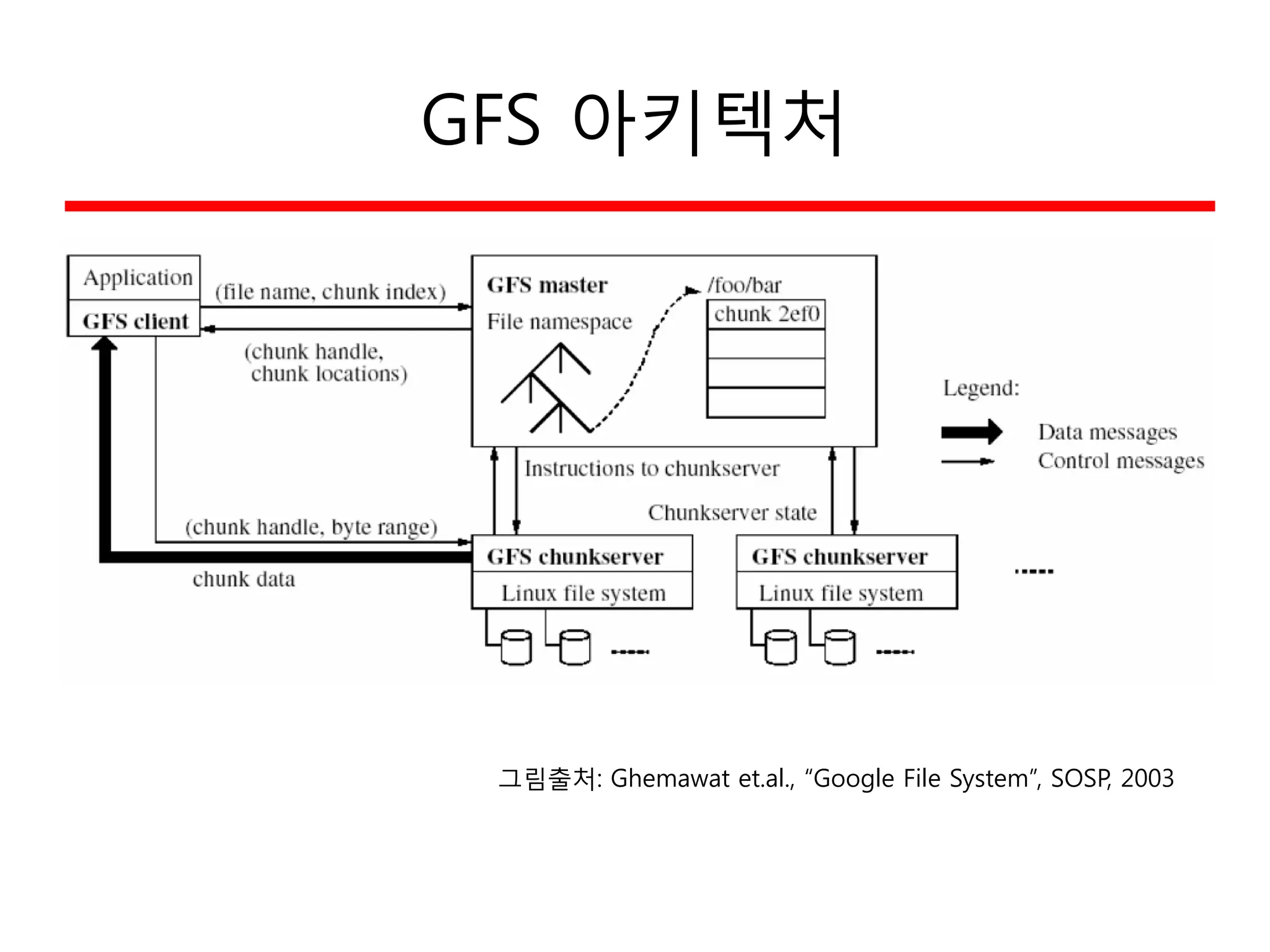
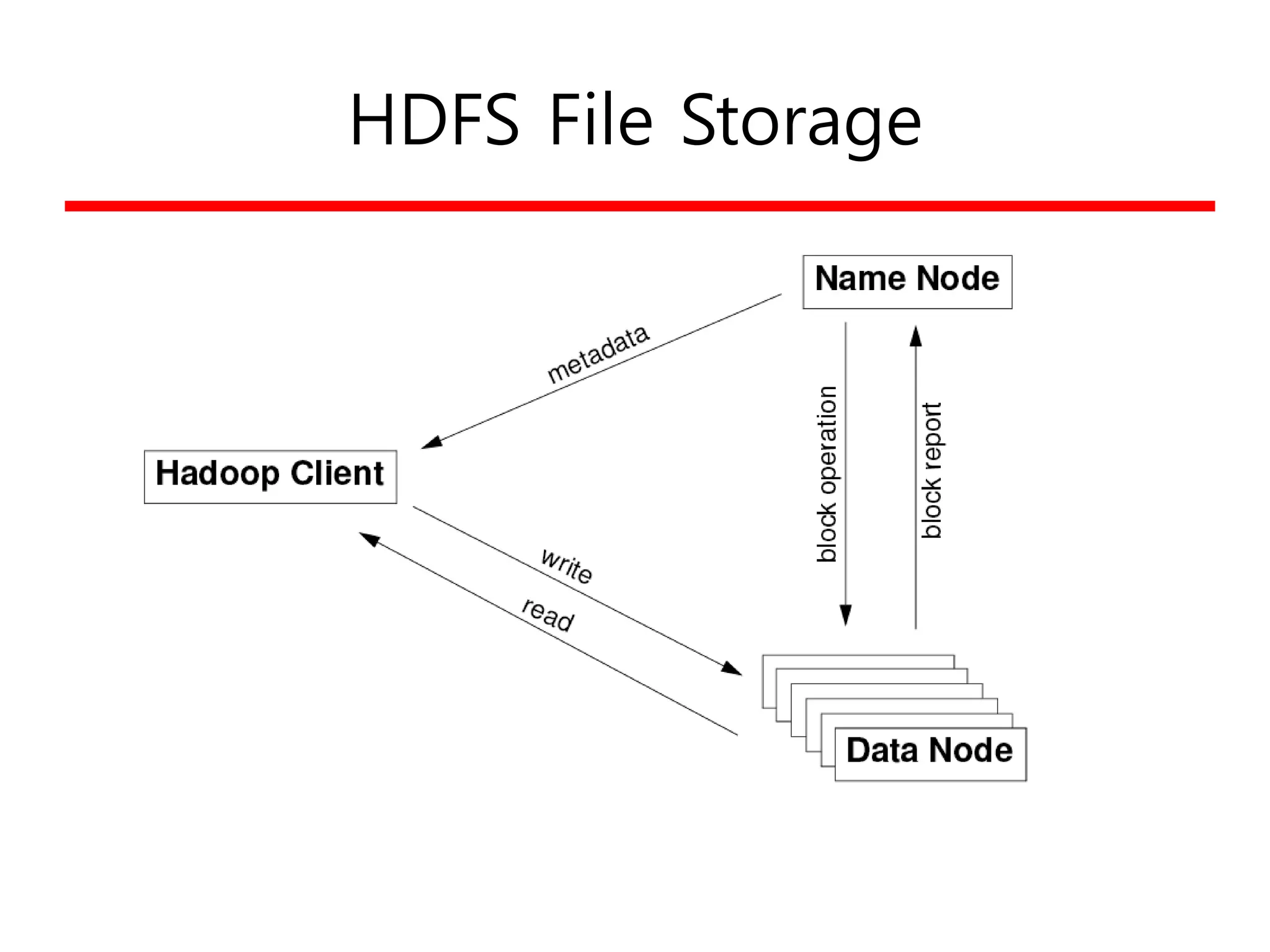
HDFS의 해결책
• 파일을block 단위로 저장
– 통상의 파일시스템 (default: 64MB)보다 훨씬 커짐
• Replication 을 통한 신뢰성 증진
– Each block replicated across 3+ DataNodes
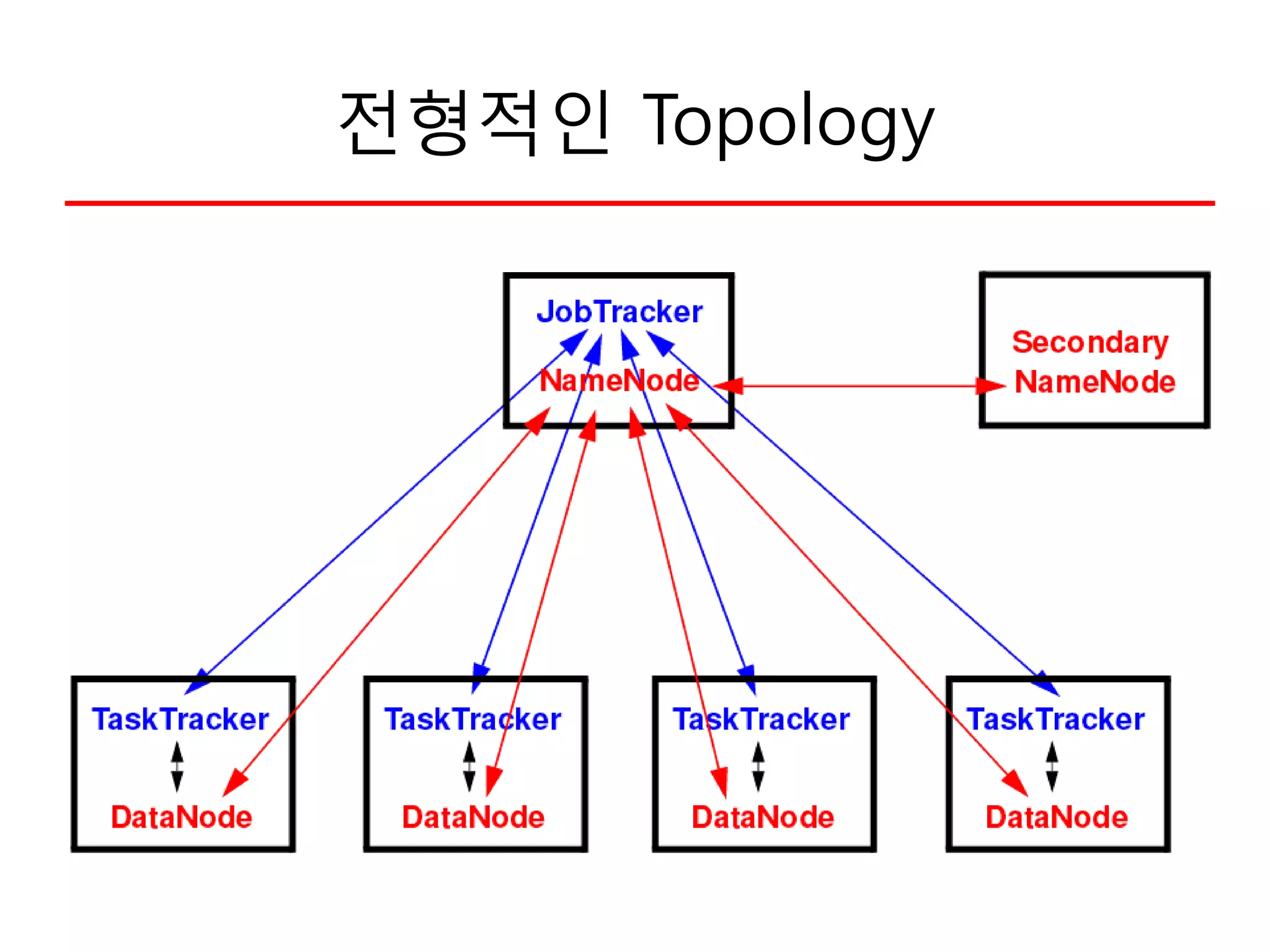
• Single master (NameNode) coordinates access,
metadata
– 단순화된 중앙관리
• No data caching
– Streaming read의 경우 별 도움이 안됨
• Familiar interface, but customize the API
– 문제를 단순화하고 분산 솔루션에 주력
HDFS 이용환경
• 명령어Interface
• Java API
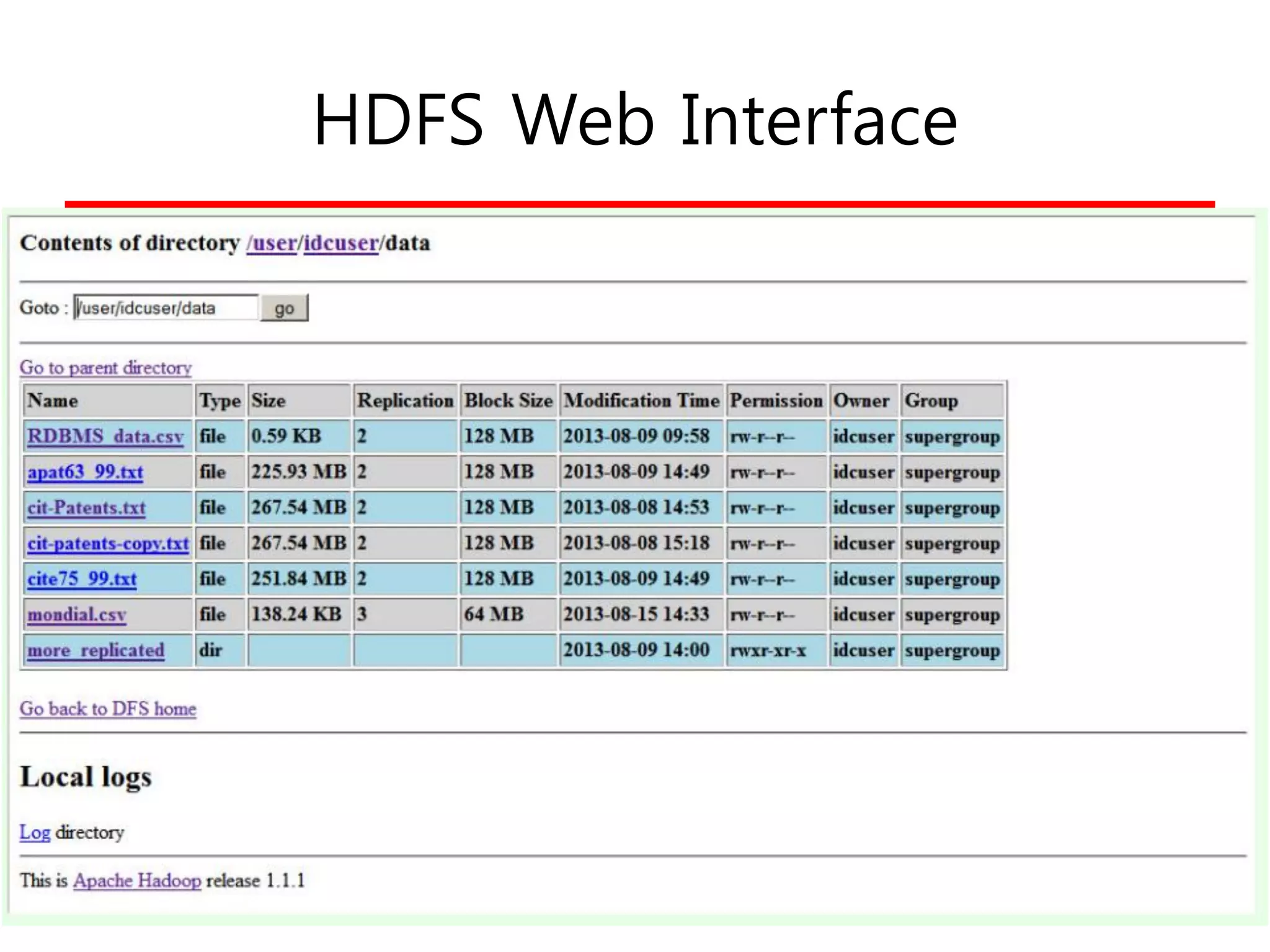
• Web Interface
• REST Interface (WebHDFS REST API)
• HDFS를 mount하여 사용
23.
HDFS 명령어 Interface
•Create a directory
$ hadoop fs -mkdir /user/idcuser/data
• Copy a file from the local filesystem to HDFS
$ hadoop fs -copyFromLocal cit-Patents.txt
/user/idcuser/data/.
• List all files in the HDFS file system
$ hadoop fs -ls data/*
• Show the end of the specified HDFS file
$ hadoop fs -tail /user/idcuser/data/cit-patents-
copy.txt
• Append multiple files and move them to HDFS (via
stdin/pipes)
$ cat /data/ita13-tutorial/pg*.txt | hadoop fs -
put- data/all_gutenberg.txt
24.
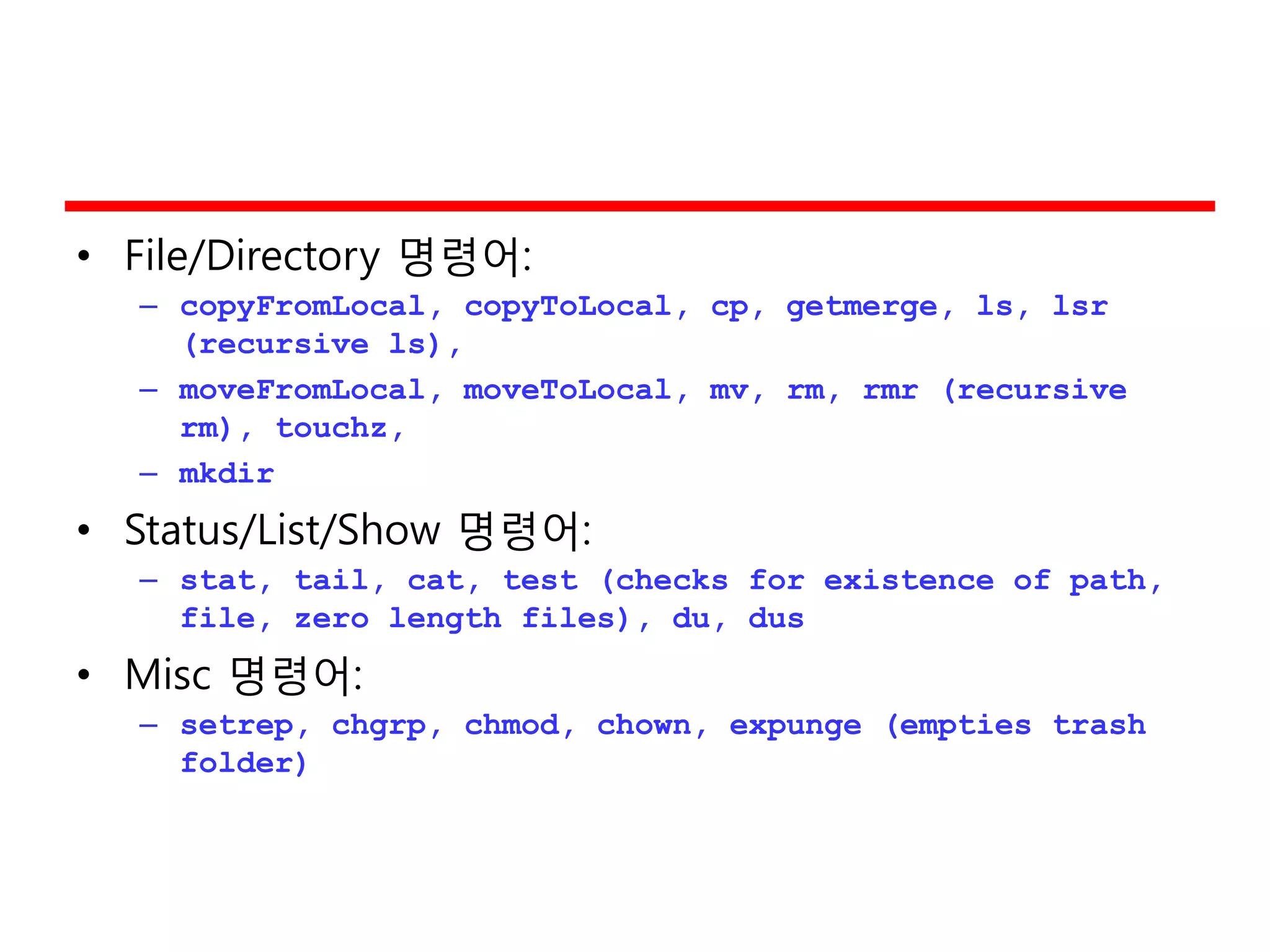
• File/Directory 명령어:
–copyFromLocal, copyToLocal, cp, getmerge, ls, lsr
(recursive ls),
– moveFromLocal, moveToLocal, mv, rm, rmr (recursive
rm), touchz,
– mkdir
• Status/List/Show 명령어:
– stat, tail, cat, test (checks for existence of path,
file, zero length files), du, dus
• Misc 명령어:
– setrep, chgrp, chmod, chown, expunge (empties trash
folder)
25.
HDFS Java API
•Listing files/directories (globbing)
• Open/close inputstream
• Copy bytes (IOUtils)
• Seeking
• Write/append data to files
• Create/rename/delete files
• Create/remove directory
• Reading Data from HDFS
org.apache.hadoop.fs.FileSystem (abstract)
org.apache.hadoop.hdfs.DistributedFileSystem
org.apache.hadoop.fs.LocalFileSystem
org.apache.hadoop.fs.s3.S3FileSystem
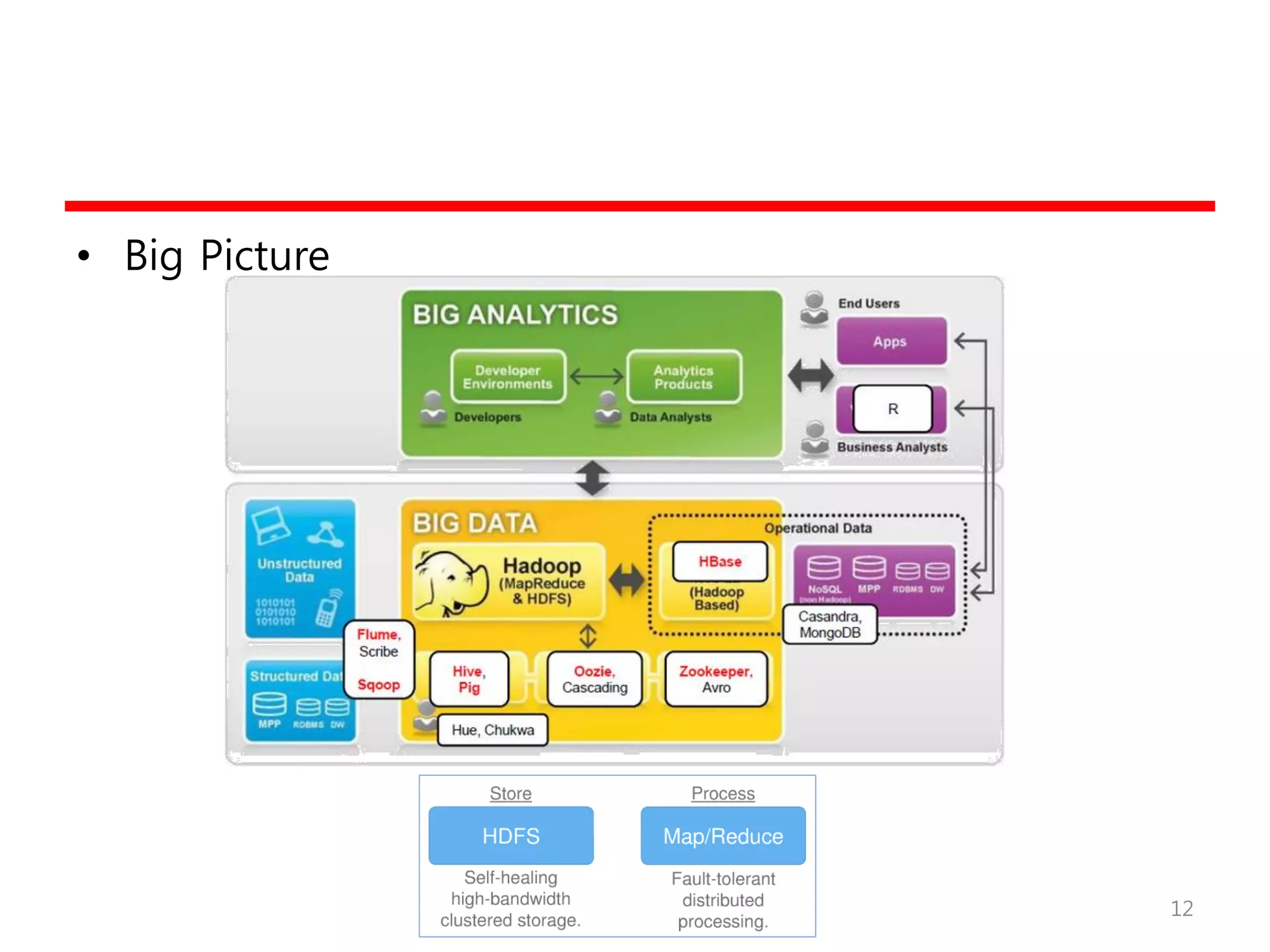
HDFS 정리
• 다수의저가 H/W 위에서 대규모 작업에 중점
– 잦은 고장에 대처
– 대형 파일 (주로 appended and read)에 중점
– 개발자들에 촛점맞춘 filesystem interface
• Scale-out & Batch Job
– 최근 여러 보완 프로젝트
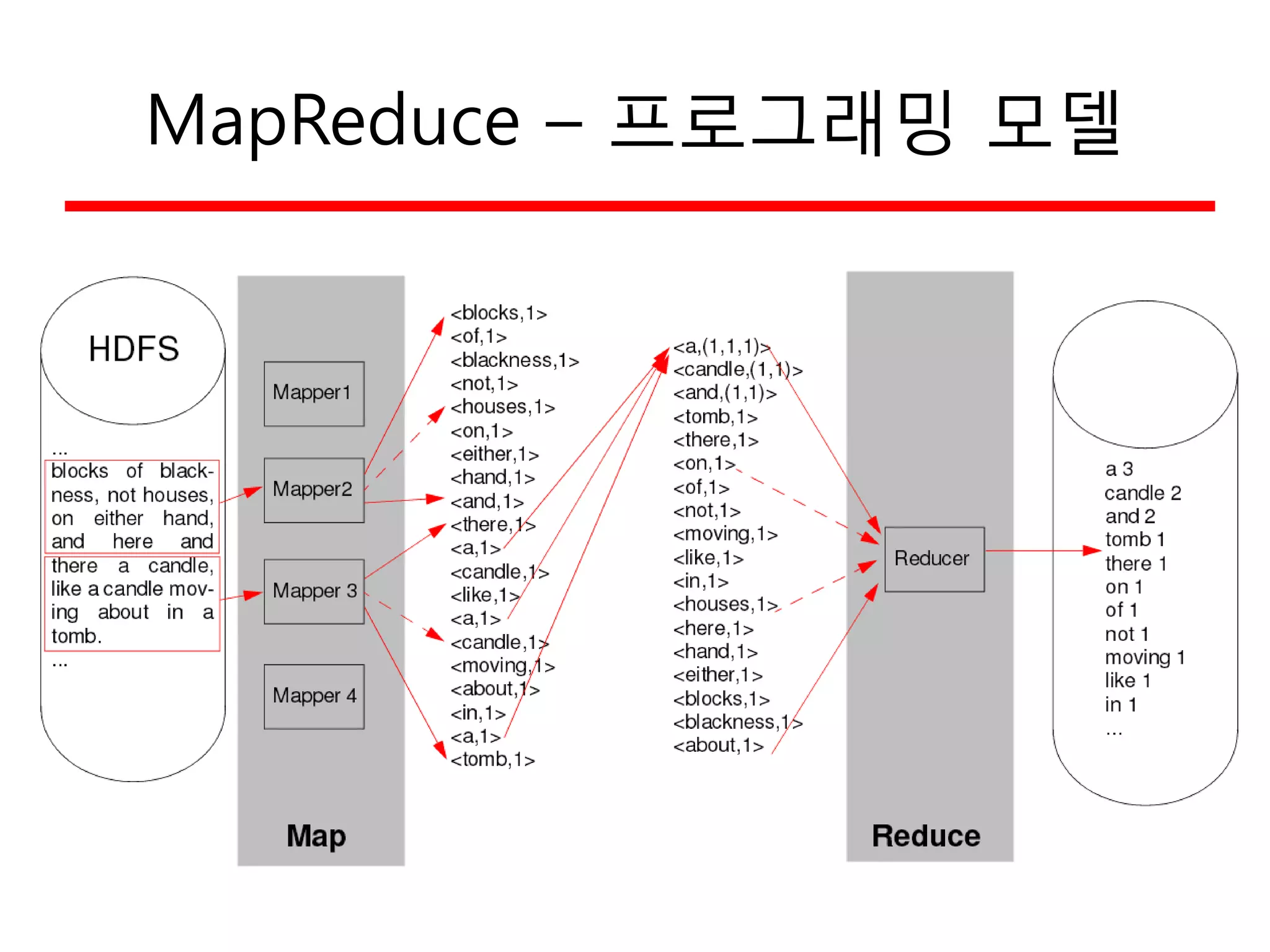
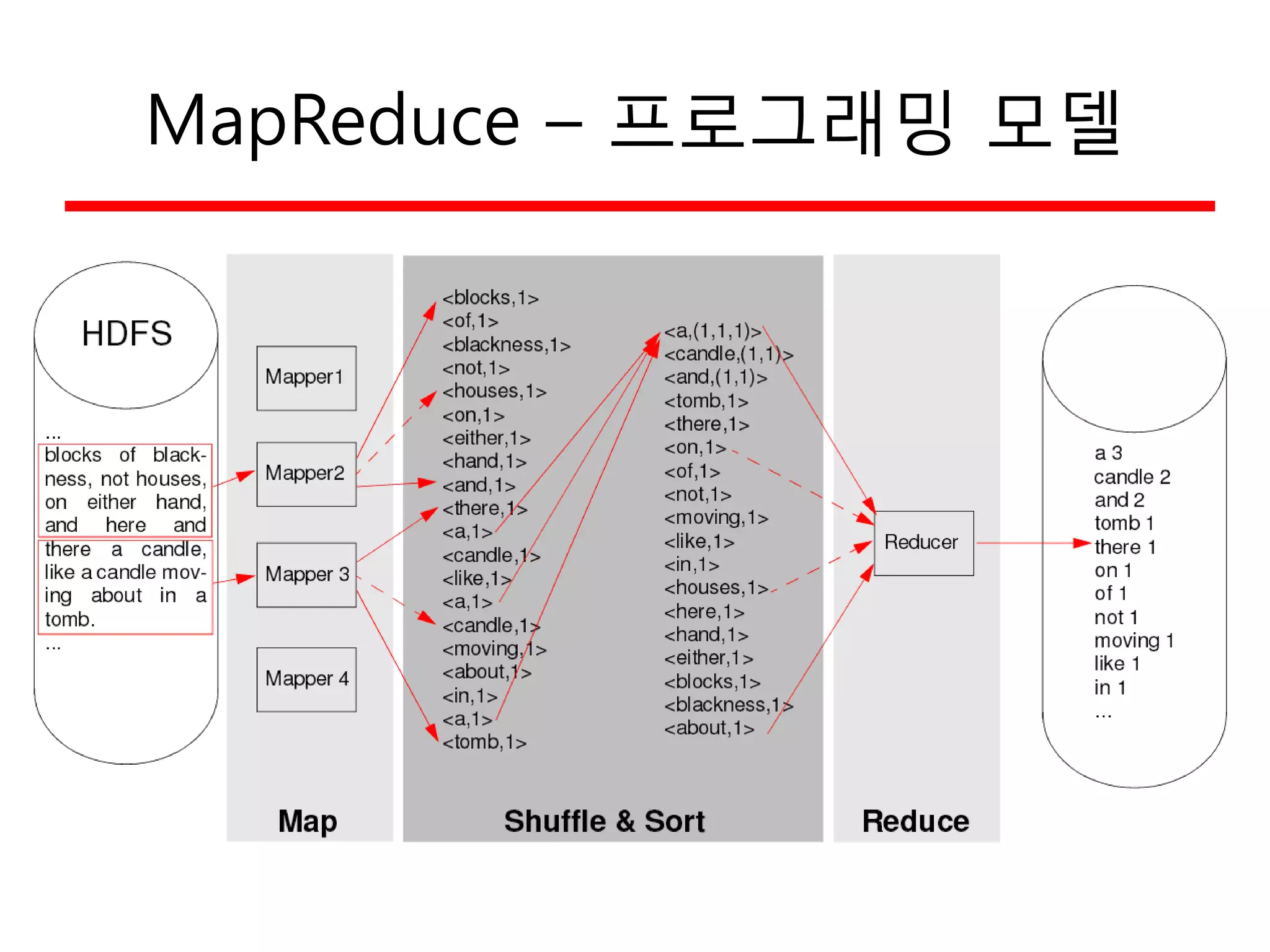
WordCount 예의 개선
•문제: 단 한 개의 reducer가 병목을 일으킴
– Work can be distributed over multiple nodes
(work balance 개선)
– All the input data has to be sorted before processing
– Question: Which data should be send to which reducer ?
• 해결책:
– Arbitrary distributed, based on a hash function (default mode)
– Partitioner Class, to determine for every output tuple the
corresponding reducer
35.
unix 명령어와 StreamingAPI
• Question: How many cities has each country ?
hadoop jar /mnt/biginsights/opt/ibm/biginsights/pig/test/e2e/
pig/lib/hadoop-streaming.jar
-input input/city.csv
-output output
-mapper "cut -f2 -d,"
-reducer "uniq -c"
-numReduceTasks 5
• Explanation:
cut -f2 -d, # Extract 2nd col. in a CSV
uniq -c # Filter adjacent matches matching lines from INPUT,
# -c: prefix lines by the number of occurrences
additional remark: # numReduceTasks=0: no shuffle & sort phase!!
Hadoop의 장단점과 대응
•Haddop의 장점
– commodity h/w
– scale-out
– fault-tolerance
– flexibility by MR
• Hadoop의 단점
– MR!
– Missing! - schema와
optimizer, index, view, ...
– 기존 tool과의 호환성 결여
• 해결책: Hive
– SQL to MR
– Compiler + Execution 엔진
– Pluggable storage layer
(SerDes)
• 미해결 숙제: Hive
– ANSI SQL, UDF, ...
– MR Latency overhead
– 계속 작업 중...!
38
39.
SQL-on-MapReduce
• 방향
– SQL로HDFS에 저장된 데이터를 빠르게 조회하고, 분석
– MR을 사용하지 않는 (low latency) 실시간 분석을 목표
– 대규모 batch 및 실시간 interactive 분석에 사용
– HDFS, 기타 데이터에 대한 ETL, Ad-hoc 쿼리, 온라인통합
• New Architecture for SQL on Hadoop
– Data Locality
– (MR대신) Real-timer Query
– Schema-on-Read
– SQL ecosystem과 tight 통합
40.
• SQL onHadoop 프로젝트 예
– Google Dremel
– Apache Drill
– Cloudera Impala
– Citus Data
• Tajo
– 2013년 3월 Apache Incubator Project에 선정
• APL V2.0
– 국내기업 적용 – SK텔레콤 등
40
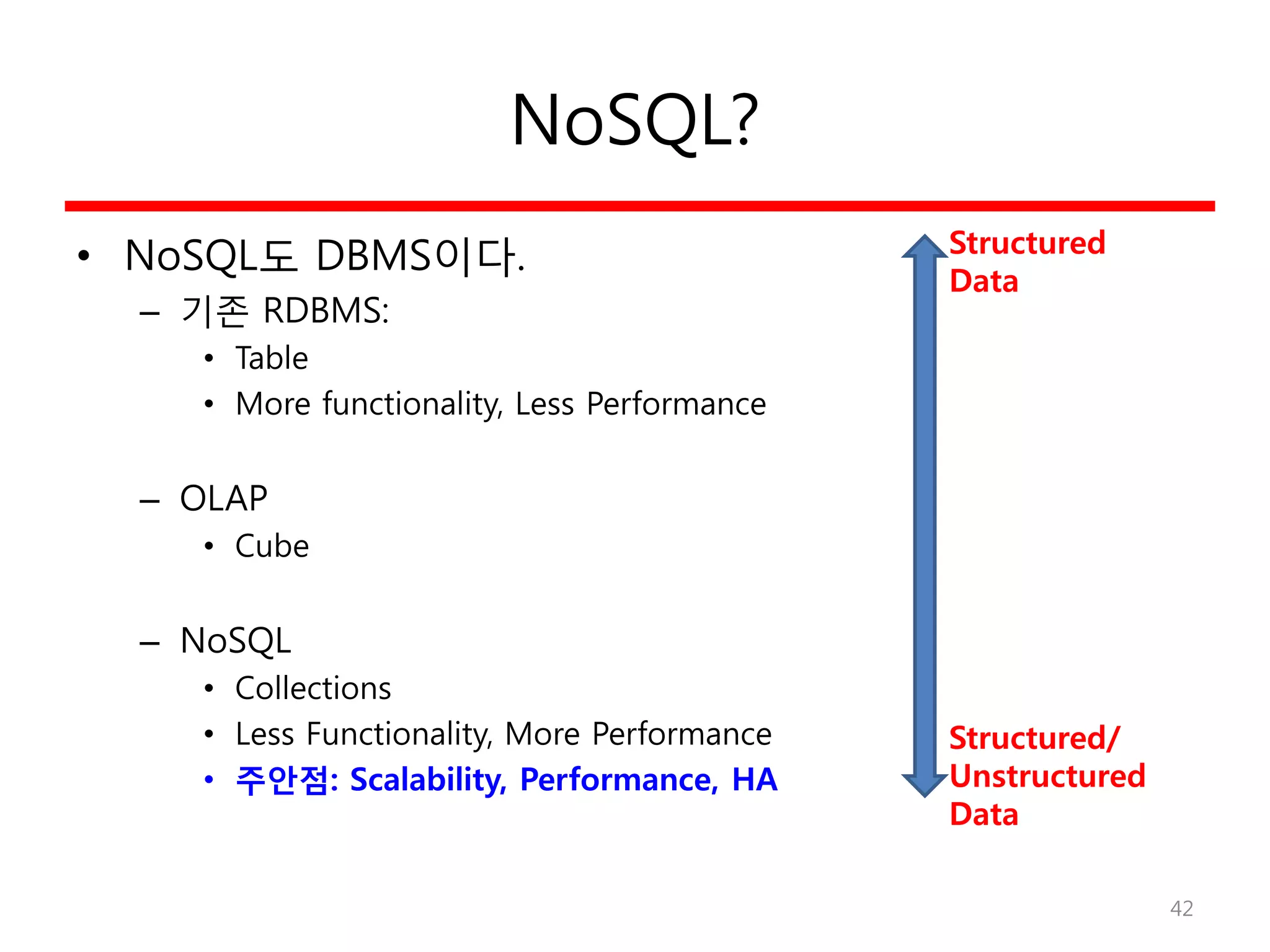
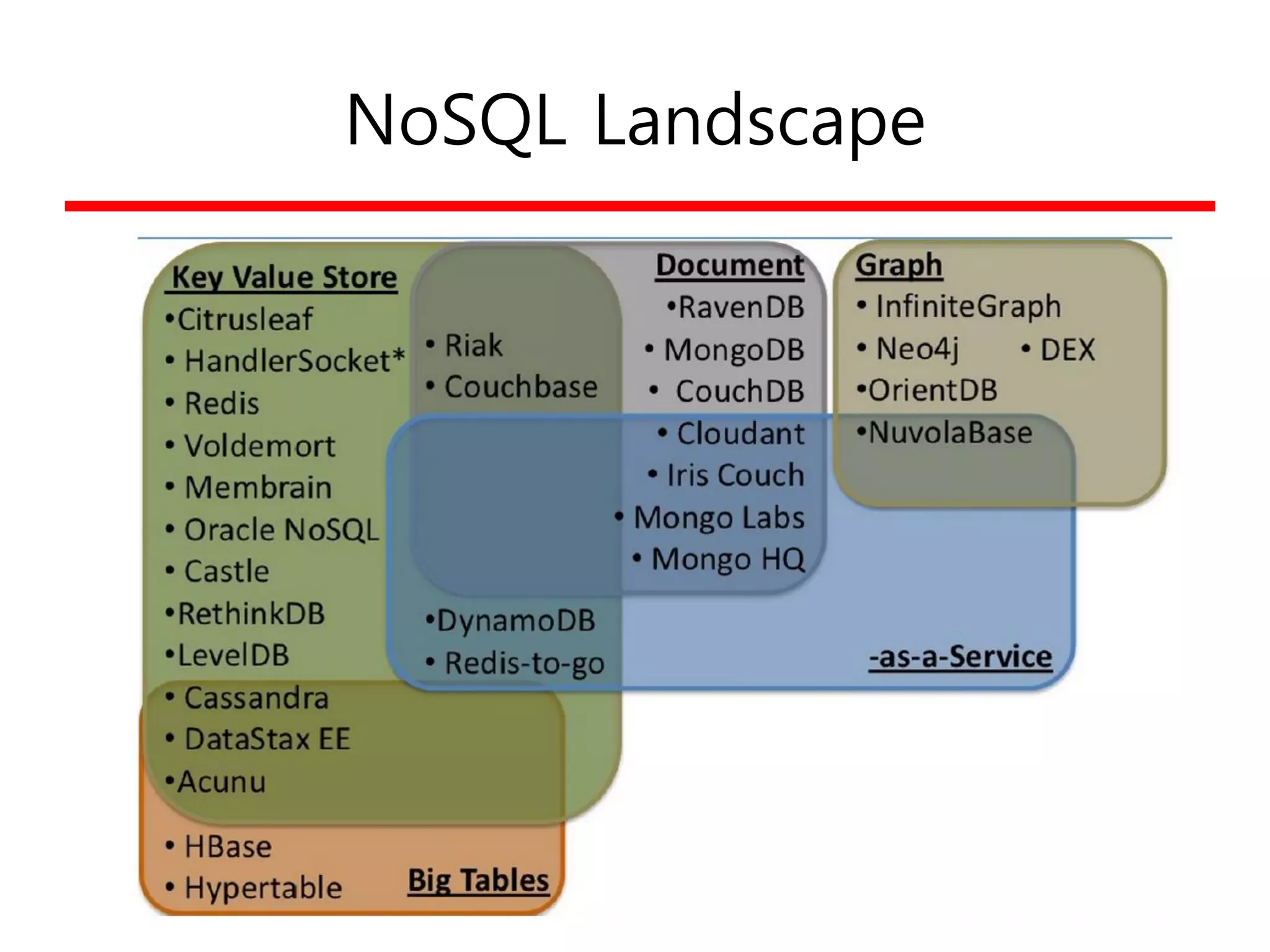
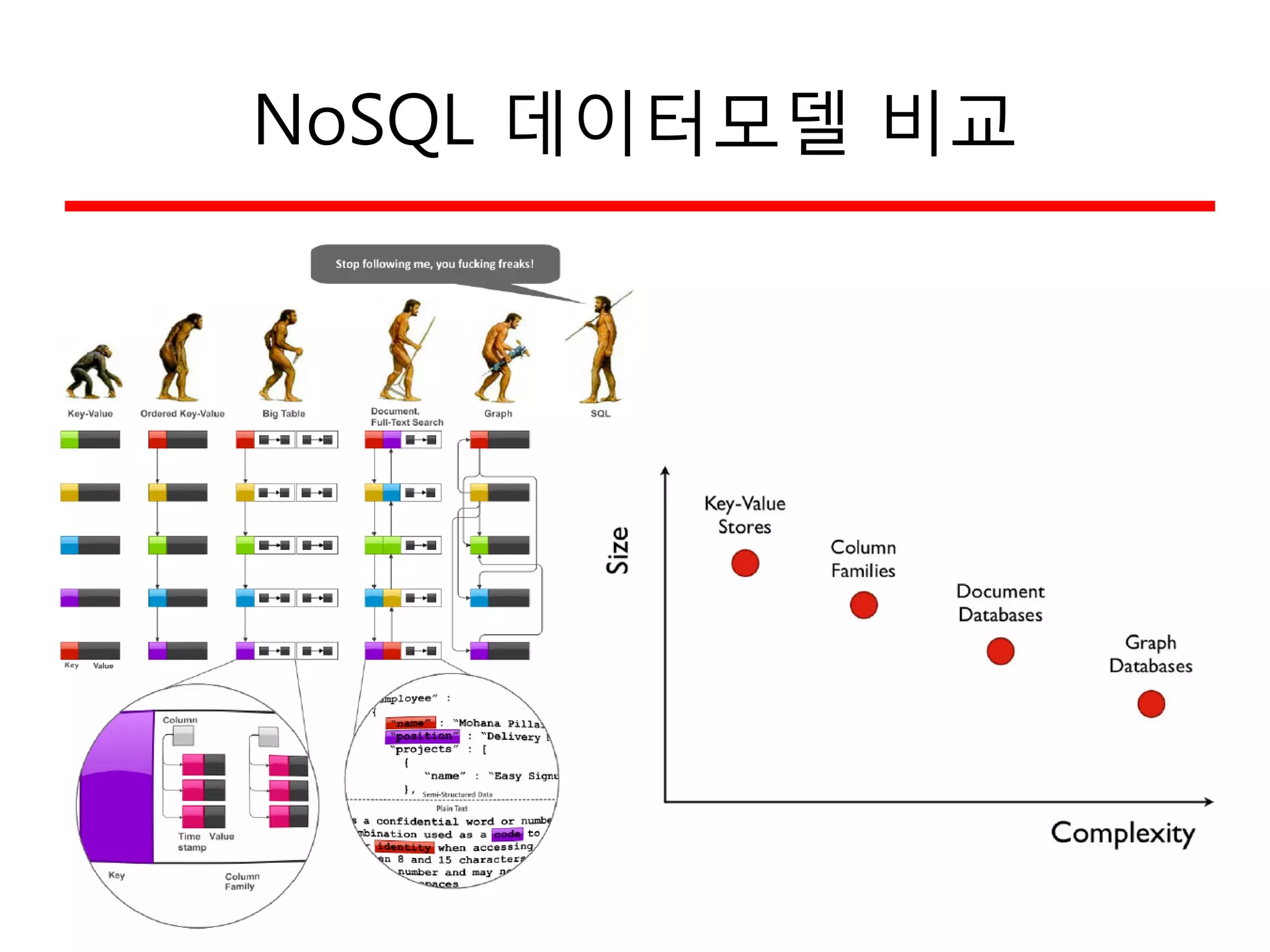
NoSQL 특징
• Missing?
–Joins 지원 없음
– Complex Transaction 지원 없음 (ACID)
– Constraint 지원 없음
• Available?
– Query Langauge
– 높은 성능
– Horizontal Scalability
NoSQL
SQL
성능
기능
47.
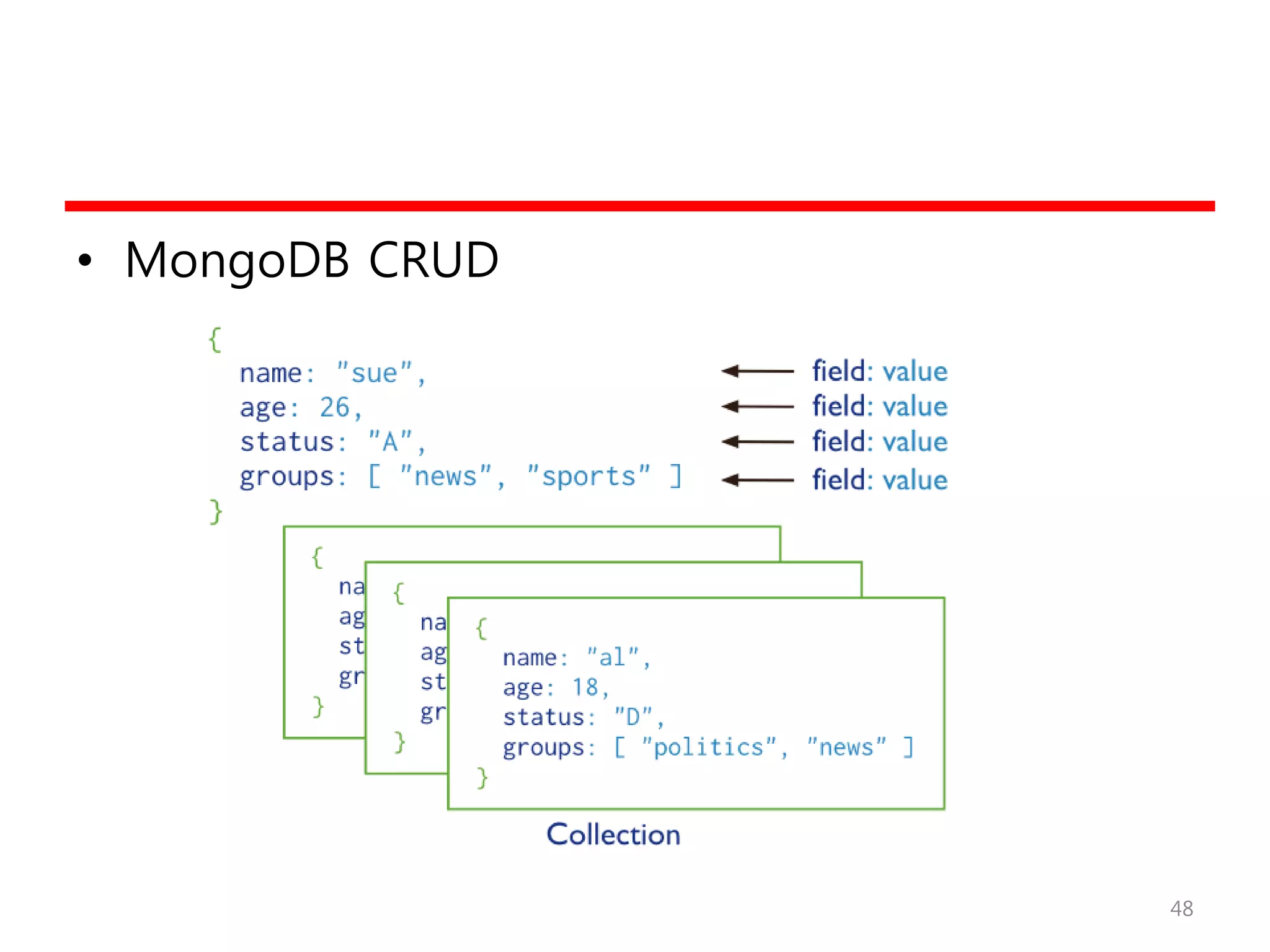
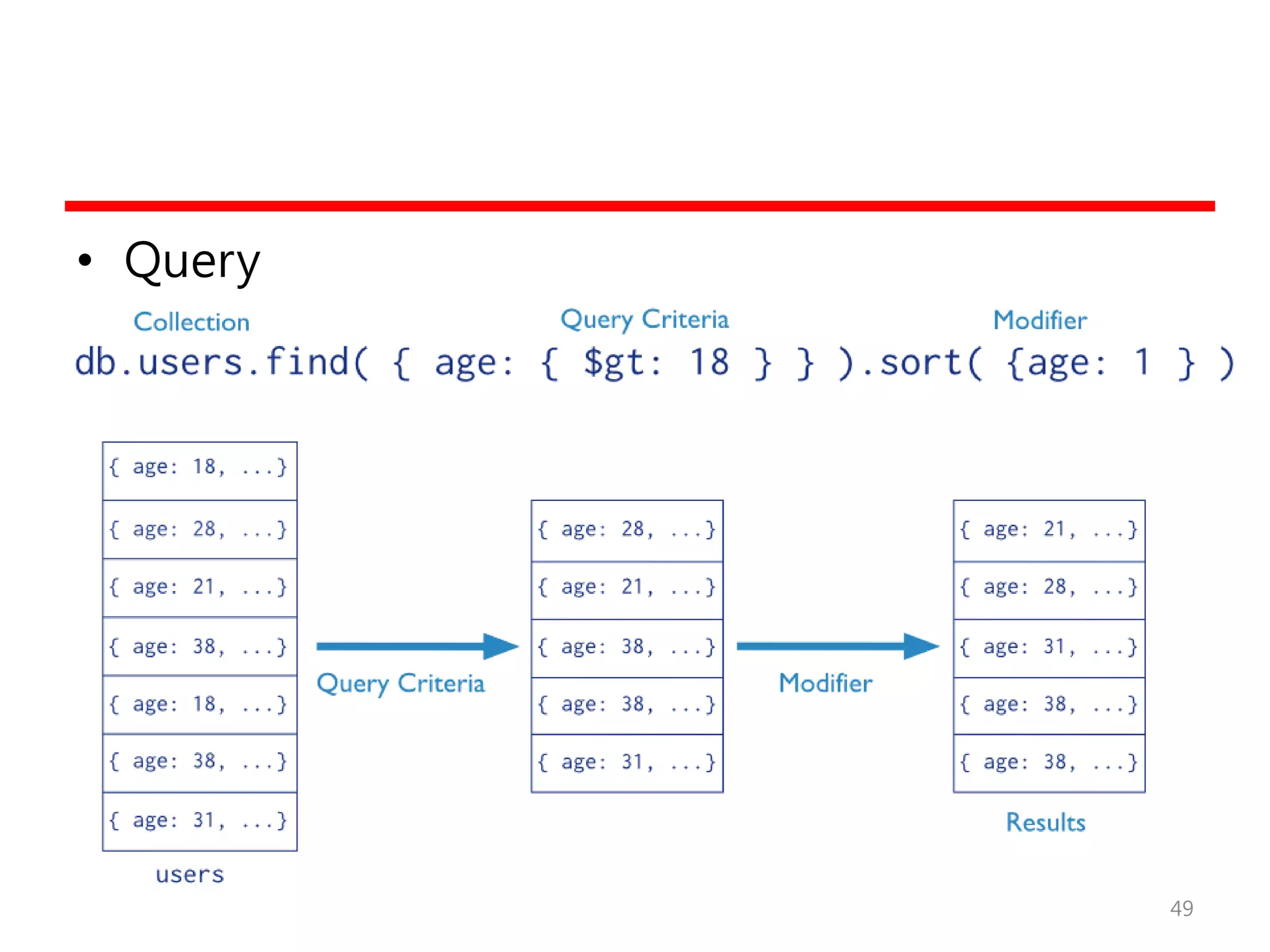
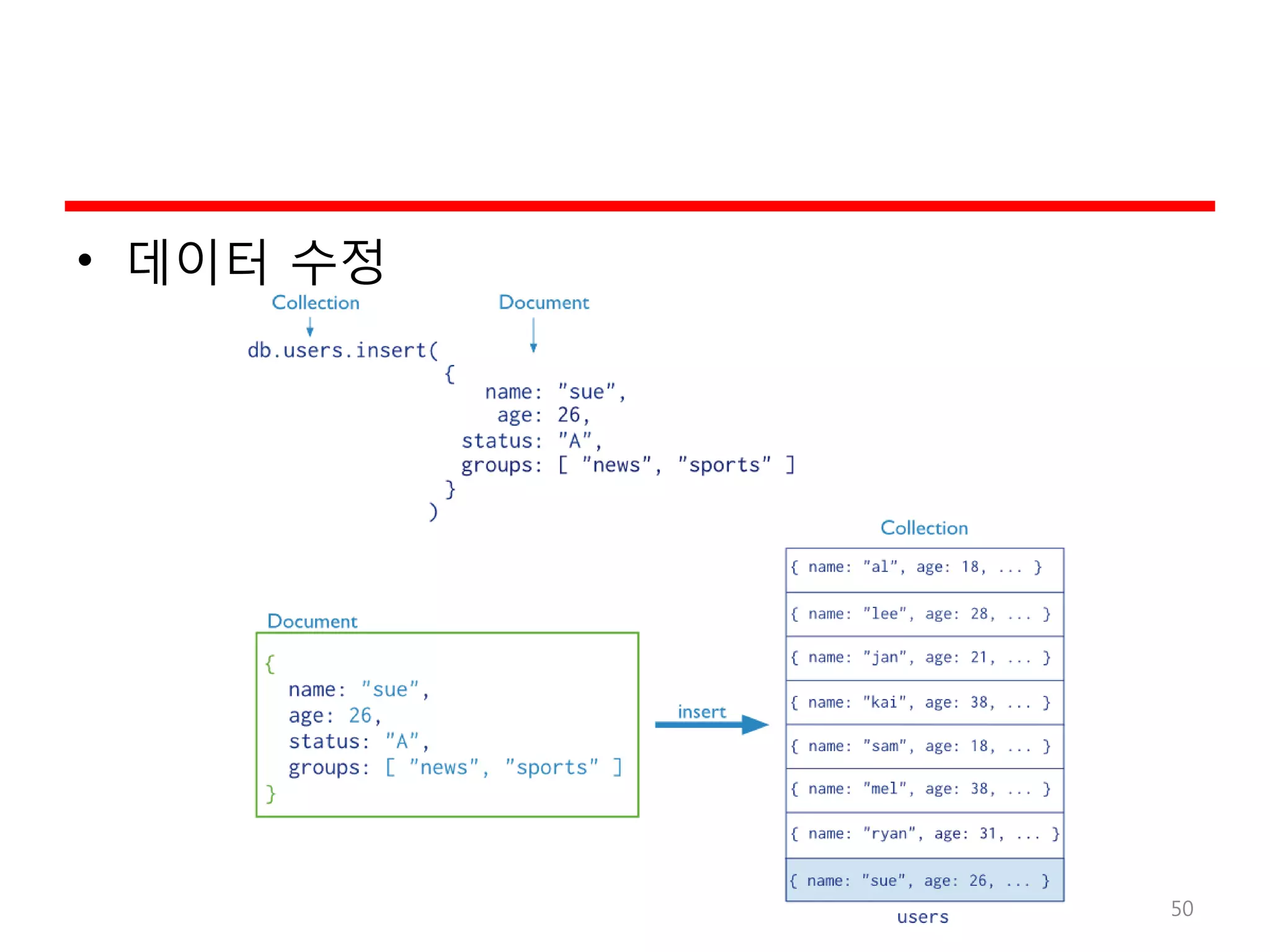
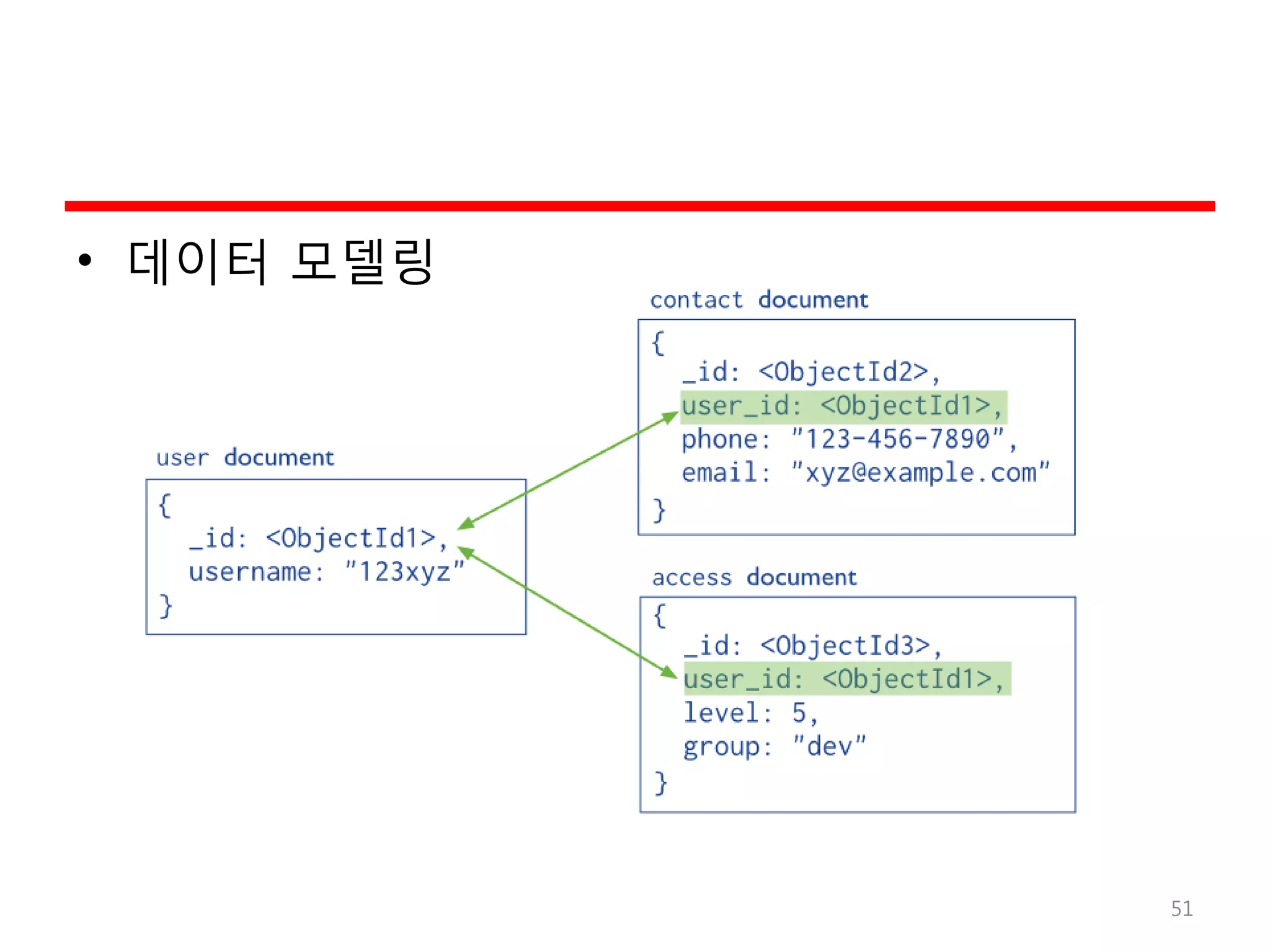
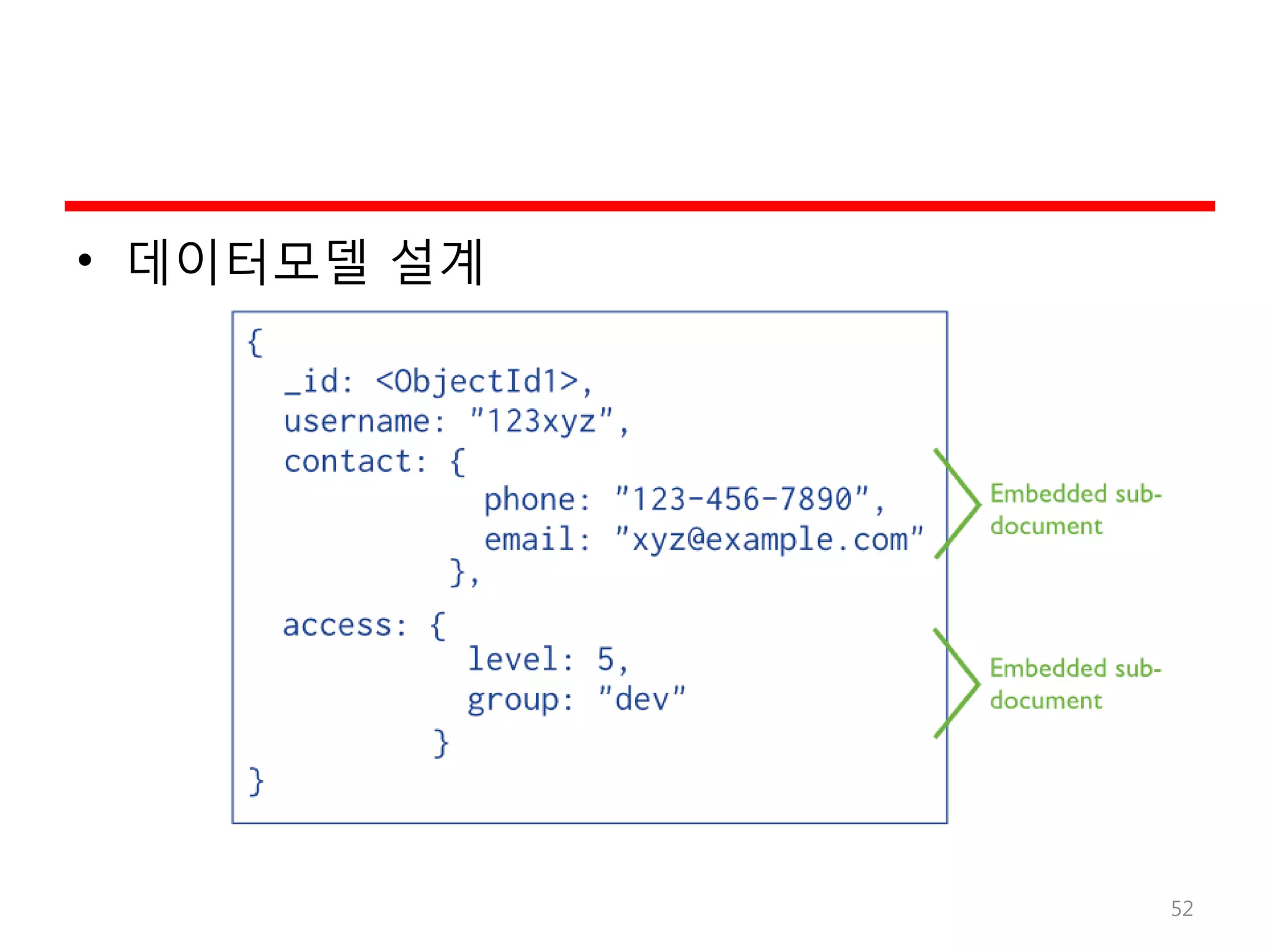
MongoDB의 예
• MongoDBpackages
– mongodb-org
– mongodb-org-server
– mongodb-org-mongos
– mongodb-org-shell
– mongodb-org-tools
• 설치
– sudo yum install -y mongodb-org
• 수행과 정지
– sudo service mongod start
– sudo service mongod stop
47
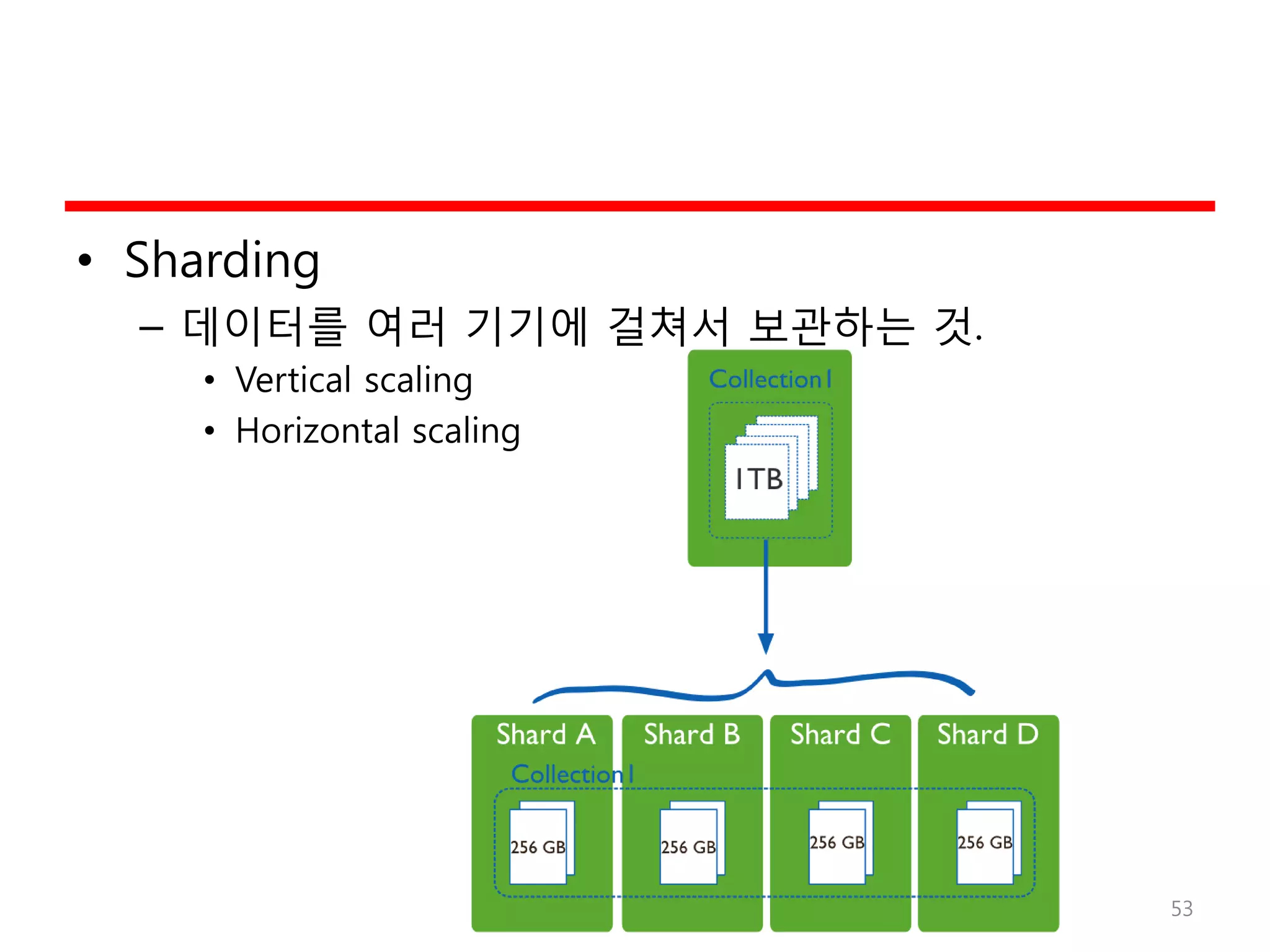
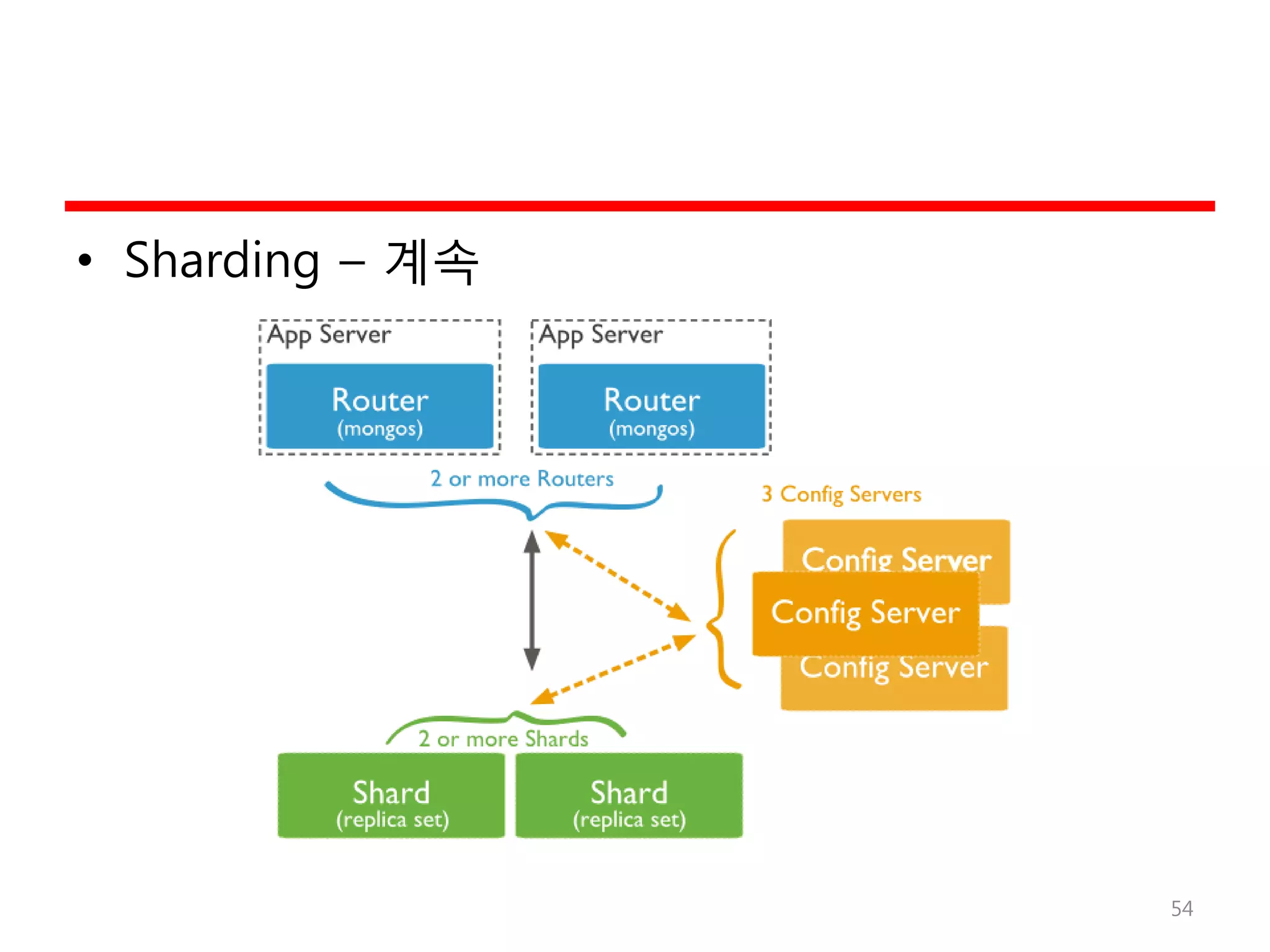
NoSQL 사용 –When?
• 대용량 데이터
• Element간의 relationship이 중요치 않을 때
• 비정형 데이터 (log, 는, twitter, blog, …)
• 신속한 prototyping
• 데이터의 변경이 빠를 때
• Business Logic을 DBMS가 아닌 Application에서 구현
55
56.
NoSQL 결론
• 특징
–기존 RDB 제한을 완화하여 단순화, 성능향상, 유연화
• 현황
– 2014.1월 현재 150여 종
56
R
• open-source 수리/통계분석도구 및 프로그래밍 언어
– S 언어에서 기원하였으며 수 많은 package
• CRAN: http://cran.r-project.org/
• 현재 > 5,100 packages
– 뛰어난 성능과 시각화 (visualization) 기능
62
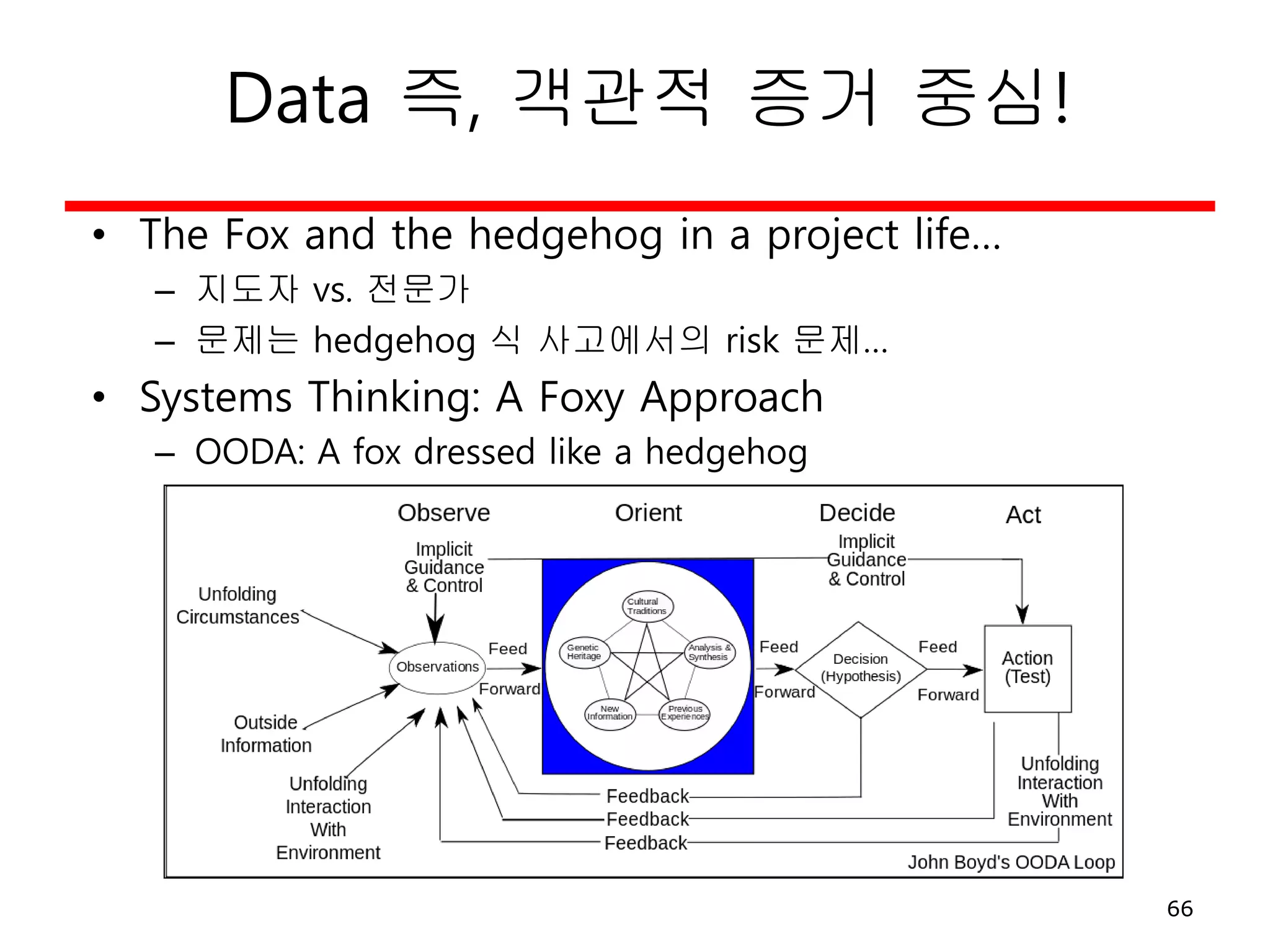
Data 즉, 객관적증거 중심!
• The Fox and the hedgehog in a project life…
– 지도자 vs. 전문가
– 문제는 hedgehog 식 사고에서의 risk 문제…
• Systems Thinking: A Foxy Approach
– OODA: A fox dressed like a hedgehog
66
67.
맺음말
• “Big Datais All Data”
• 개방성의 문제
– 오픈소스, Naver vs. Google
• 교육
– 교육 일반, BD 교육 (www.coursera.org/course/mmds )
• 빅데이터 4V vs. 4P's (hurdles)
– Practicality, privacy, power, Privilege
• 기타
– 복잡계 이론, System Dynamics, 데이터 잔해 (Data Exhaust)
67




































![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)















![[SSA] 01.bigdata database technology (2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/01-140225072202-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Open Technet Summit 2014] 쓰기 쉬운 Hadoop 기반 빅데이터 플랫폼 아키텍처 및 활용 방안](https://cdn.slidesharecdn.com/ss_thumbnails/open-technet-summit-2014-140313001107-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













![[논문작성팁]형용사를 나열한 명사구에서 쉼표의 사용](https://cdn.slidesharecdn.com/ss_thumbnails/random-140903033142-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[대구Mbc 시사톡톡] 대구경북 청년유출에 대한 빅데이터 분석](https://cdn.slidesharecdn.com/ss_thumbnails/mbc20141103-141110224806-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)


































