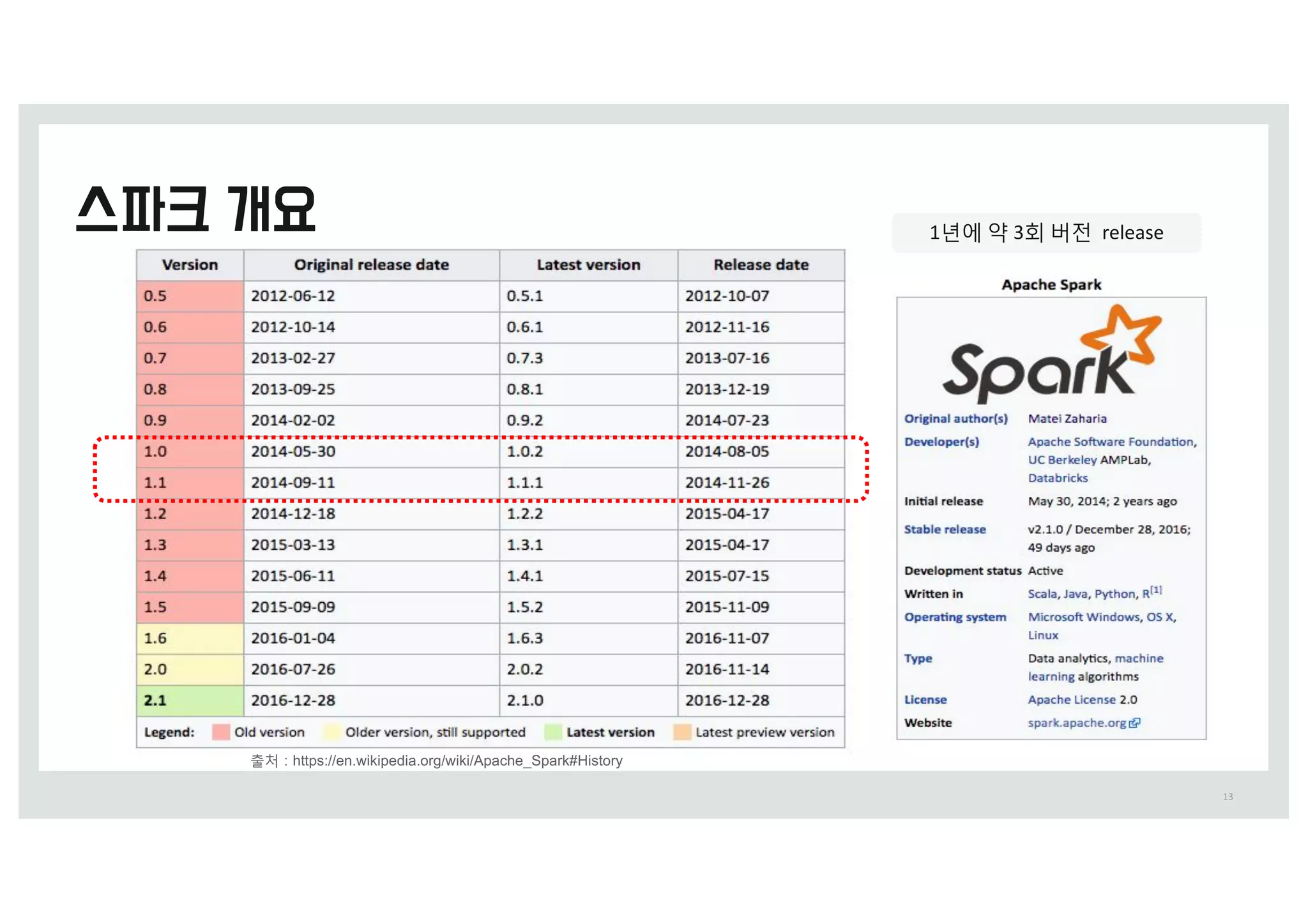
34
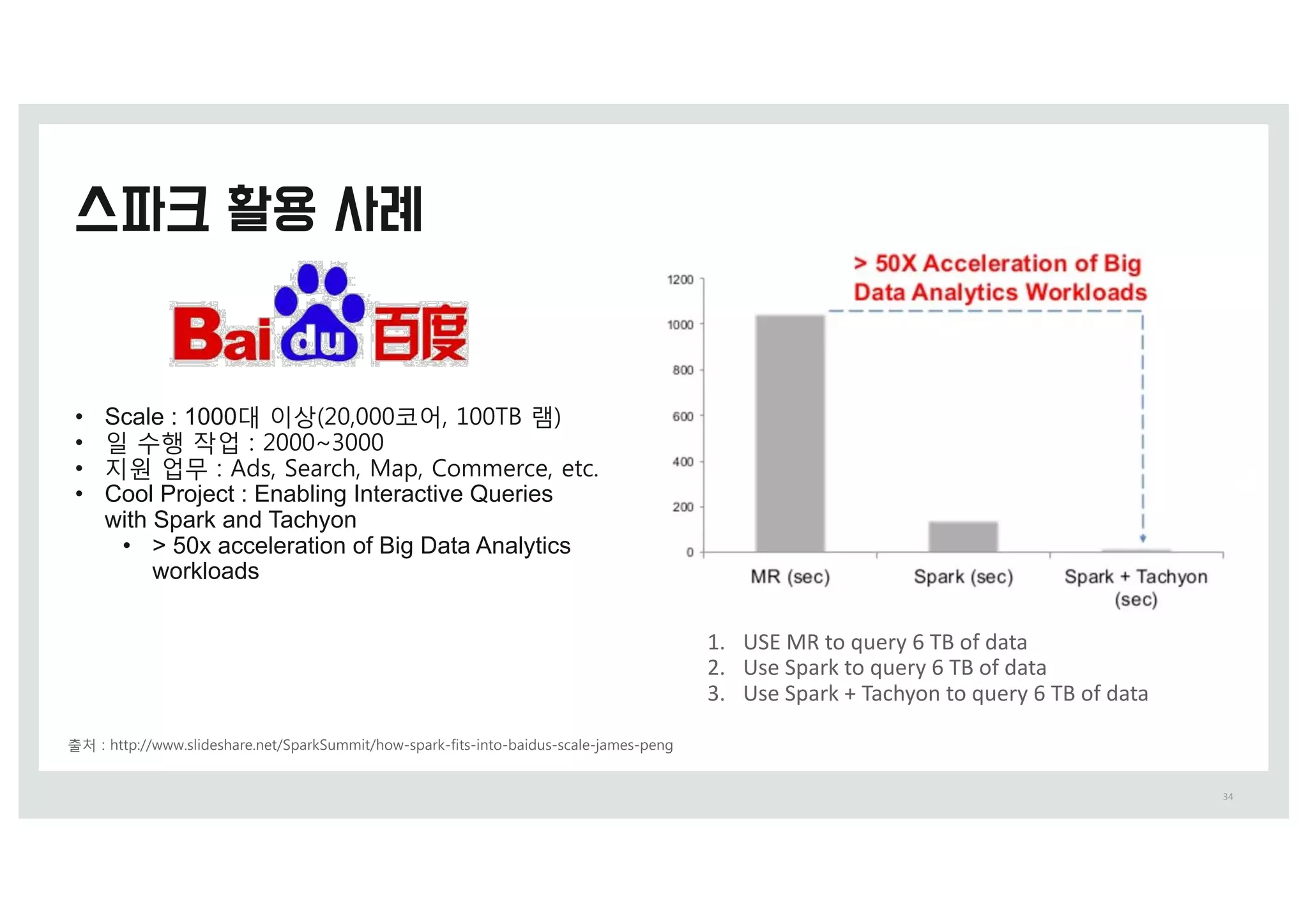
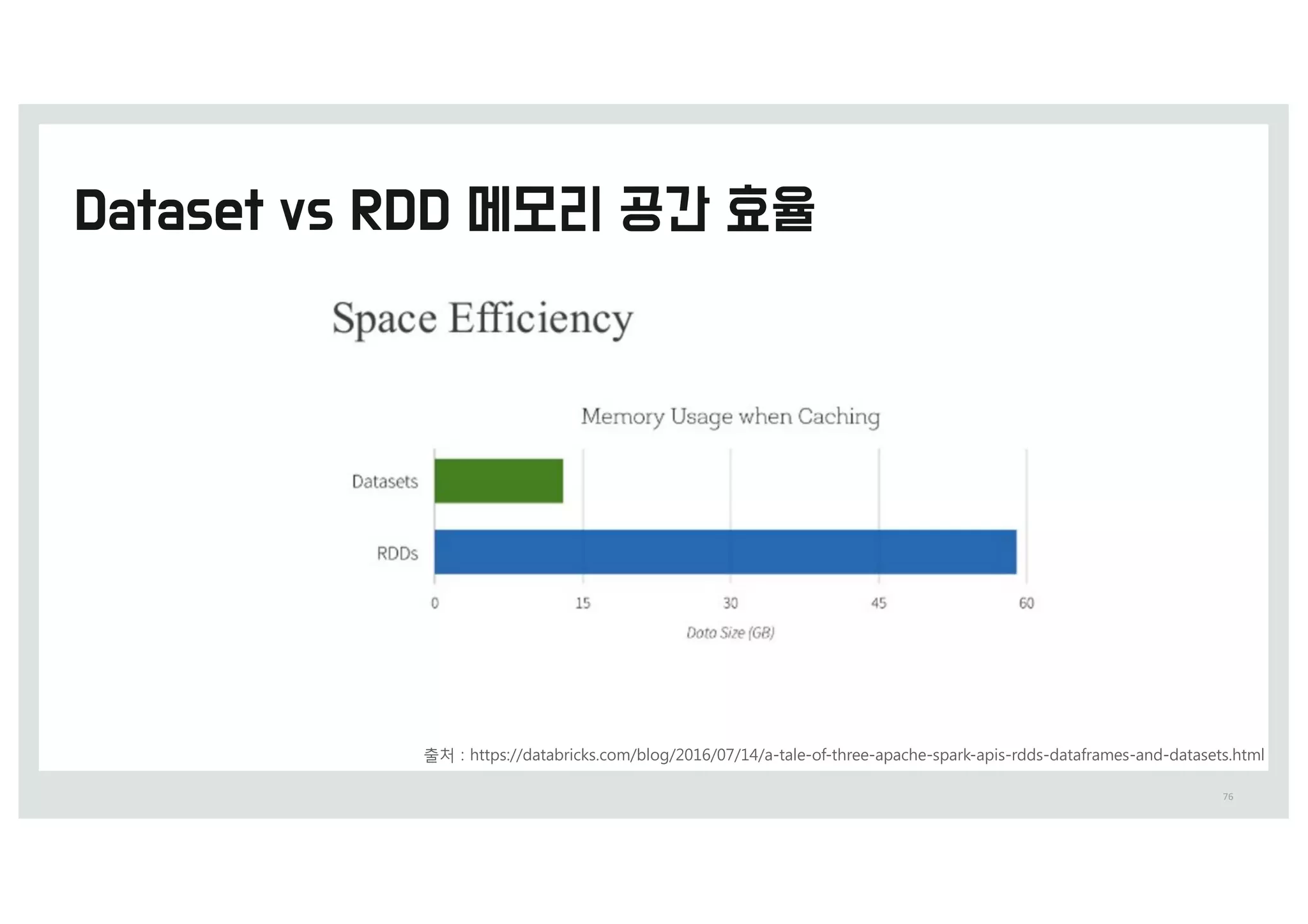
출처 0 IttQ0%%XXX.TMideTIBSe.Oet%=QBSL=Vmmit%IoX-TQBSL-fitT-iOto-CBidVT-TDBMe-jBmeT-QeOg
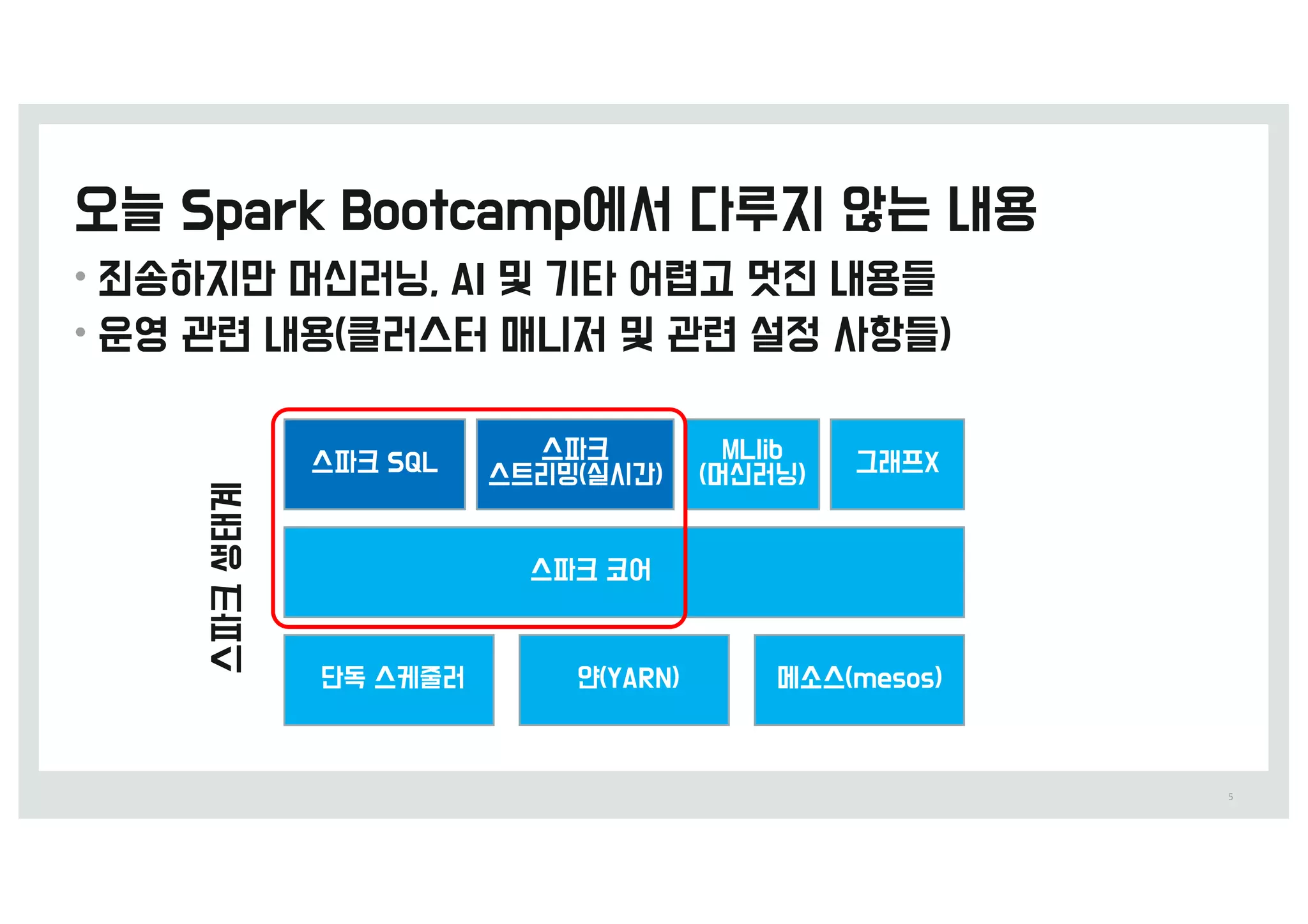
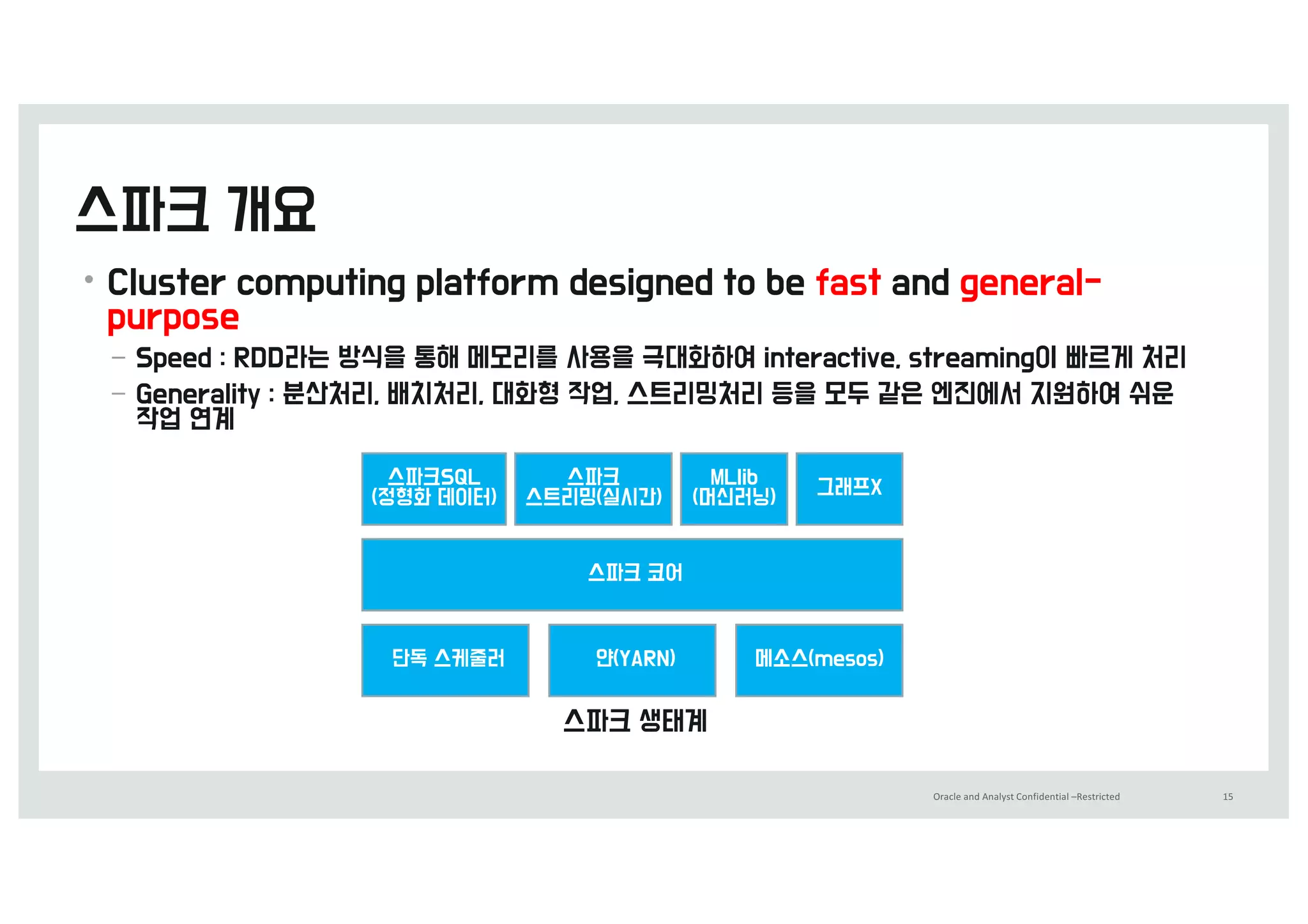
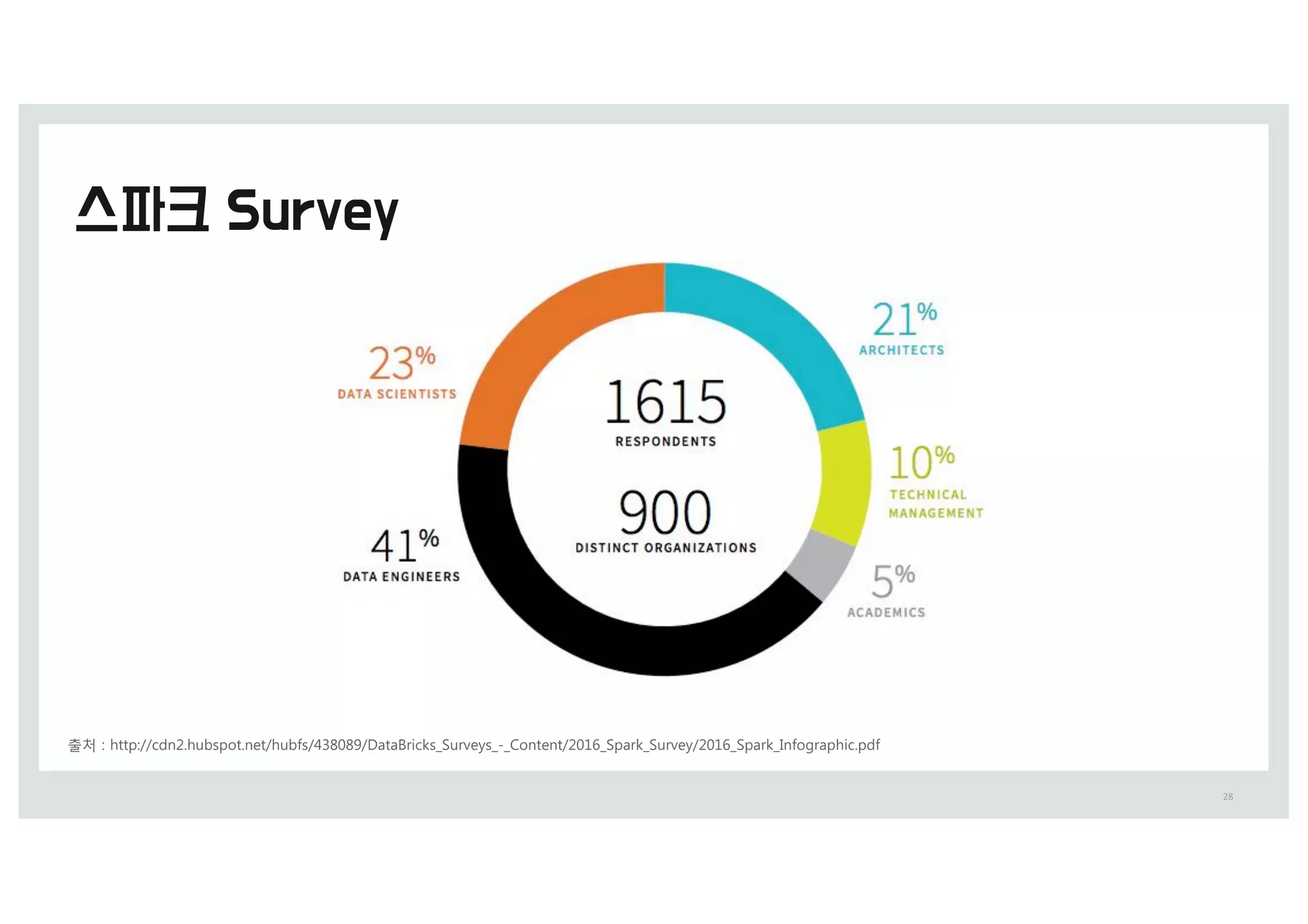
•Scale : 1000y 이상 (&,&&&코어, 1&&>5 램)
• 일 수행 작업 0 (&&&~)&&&
• 지원 업무 0 4dT, =eBSDI, :BQ, 6ommeSDe, etD.
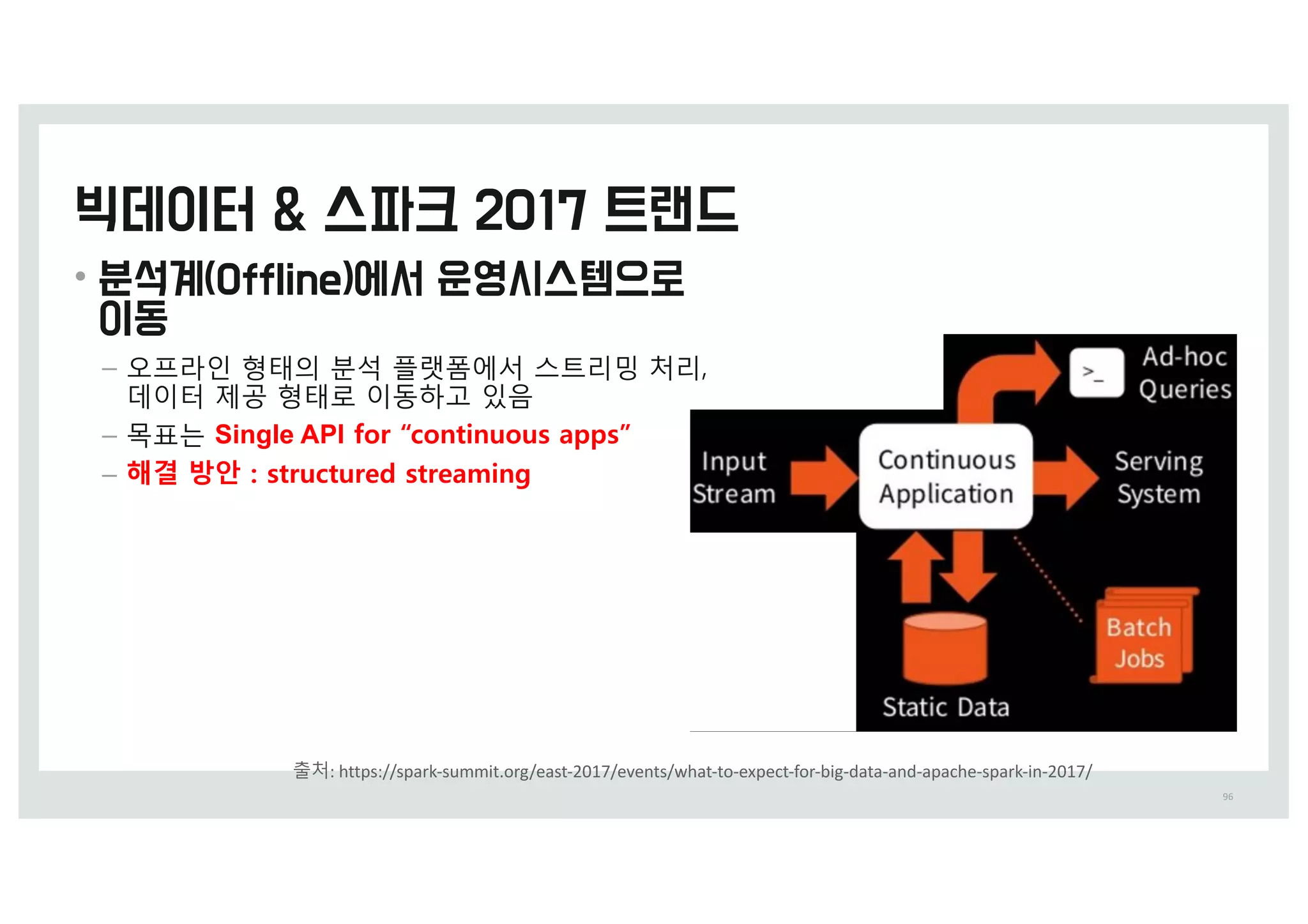
• Cool Project : Enabling Interactive Queries
with Spark and Tachyon
• > 50x acceleration of Big Data Analytics
workloads
1. USE MR to query 6 TB of data
2. Use Spark to query 6 TB of data
3. Use Spark + Tachyon to query 6 TB of data
35.
35
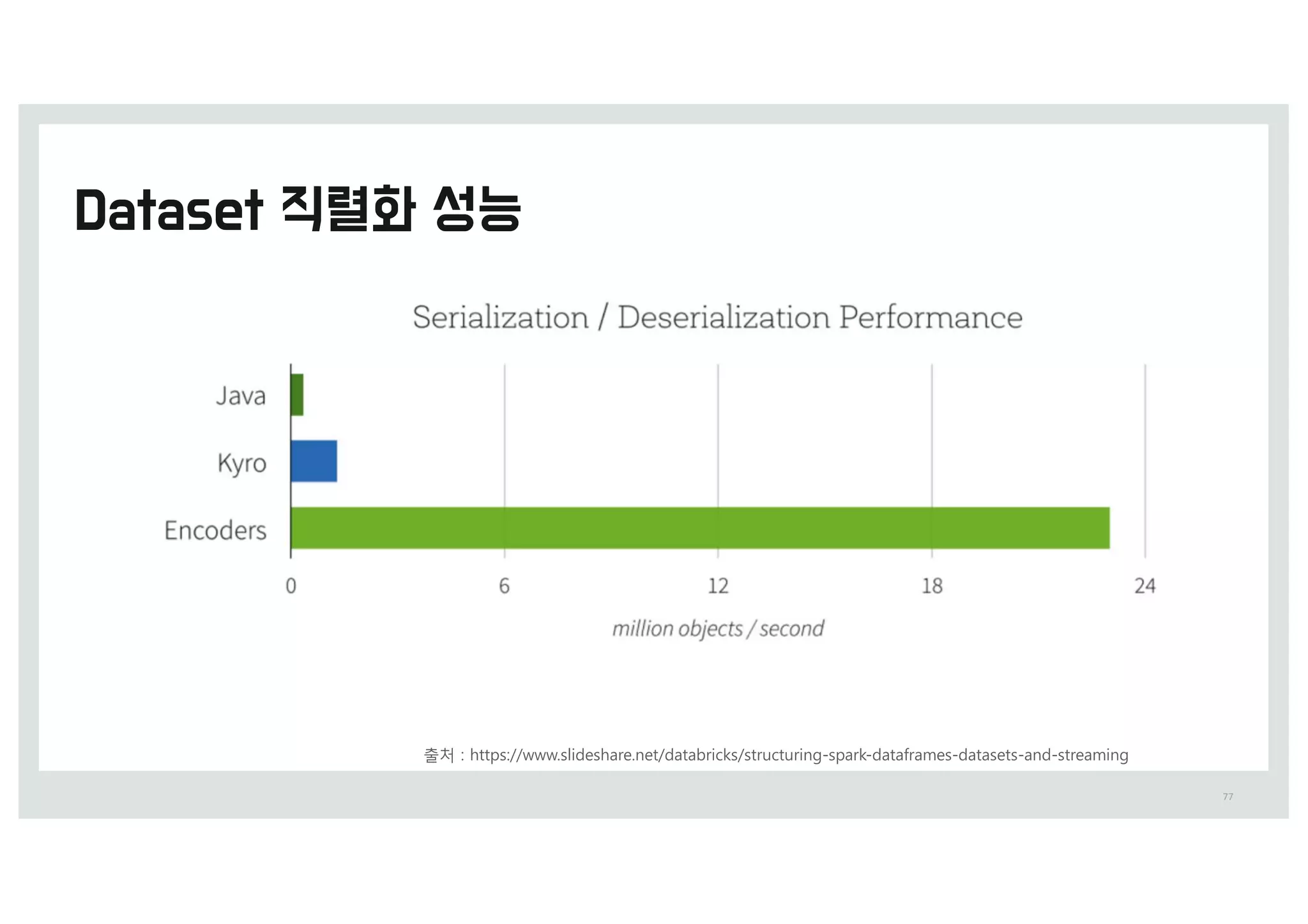
출처 0 IttQ0%%XXX.TMideTIBSe.Oet%=QBSL=Vmmit%CSiBO-LVSTBS
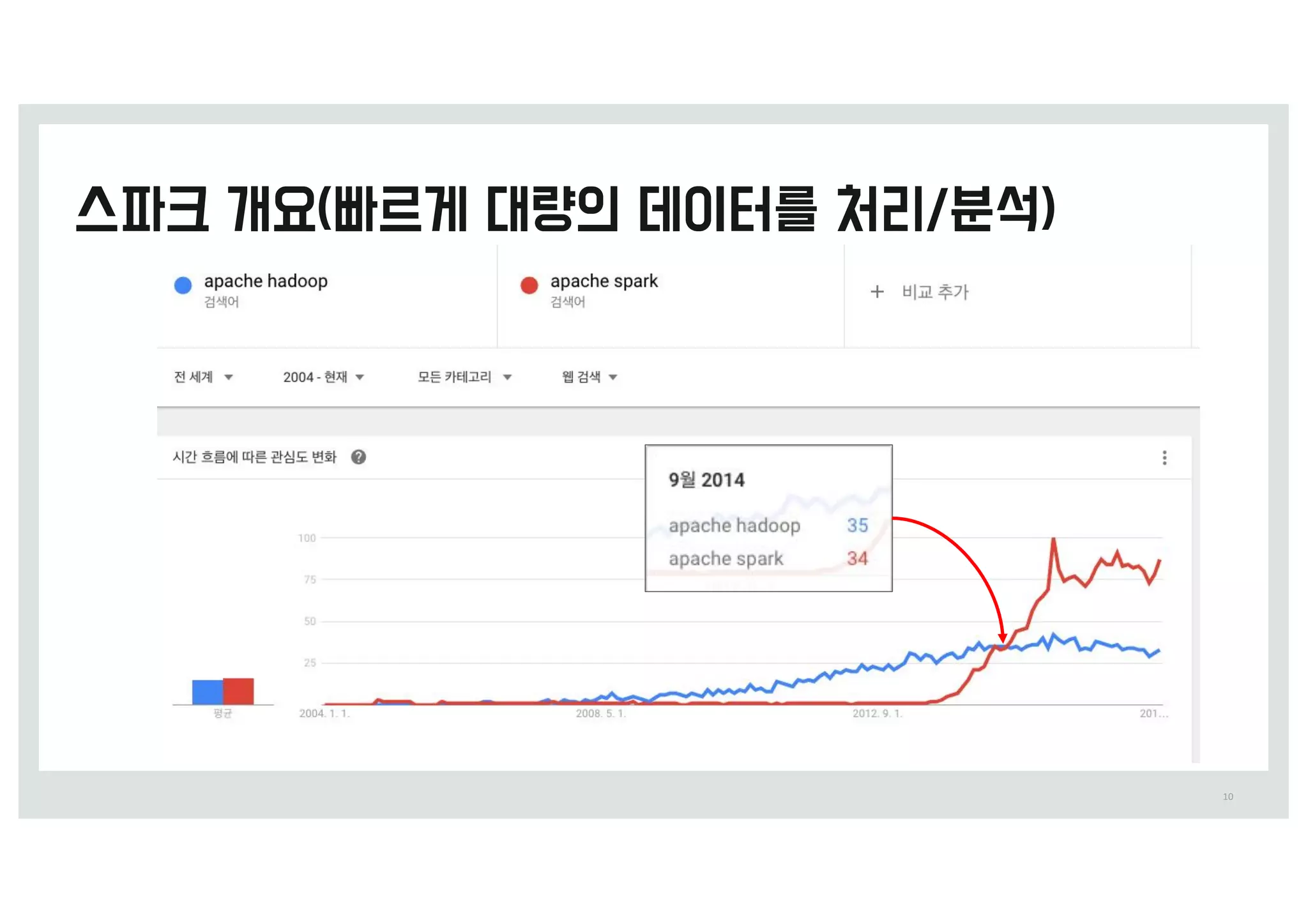
•성u 0
q ga e험 j련 o존 배치 작업 수행 시_은
1,& 시_
q 동일한 작업을 =QBSL으로 재작성하여
4시_으로 4&배 x축
• 분류
q 소셜 미디어를 =QBSL :9MiC을 사용해서
실시_으로 우선 순위 지정
q :9 Mife DyDMe 0 extSBDt feBtVSeT BOd tSBiO.
q ?1 0 5,% BDDVSBDy12 ?/ 0 .(% BDDVSBDy
41
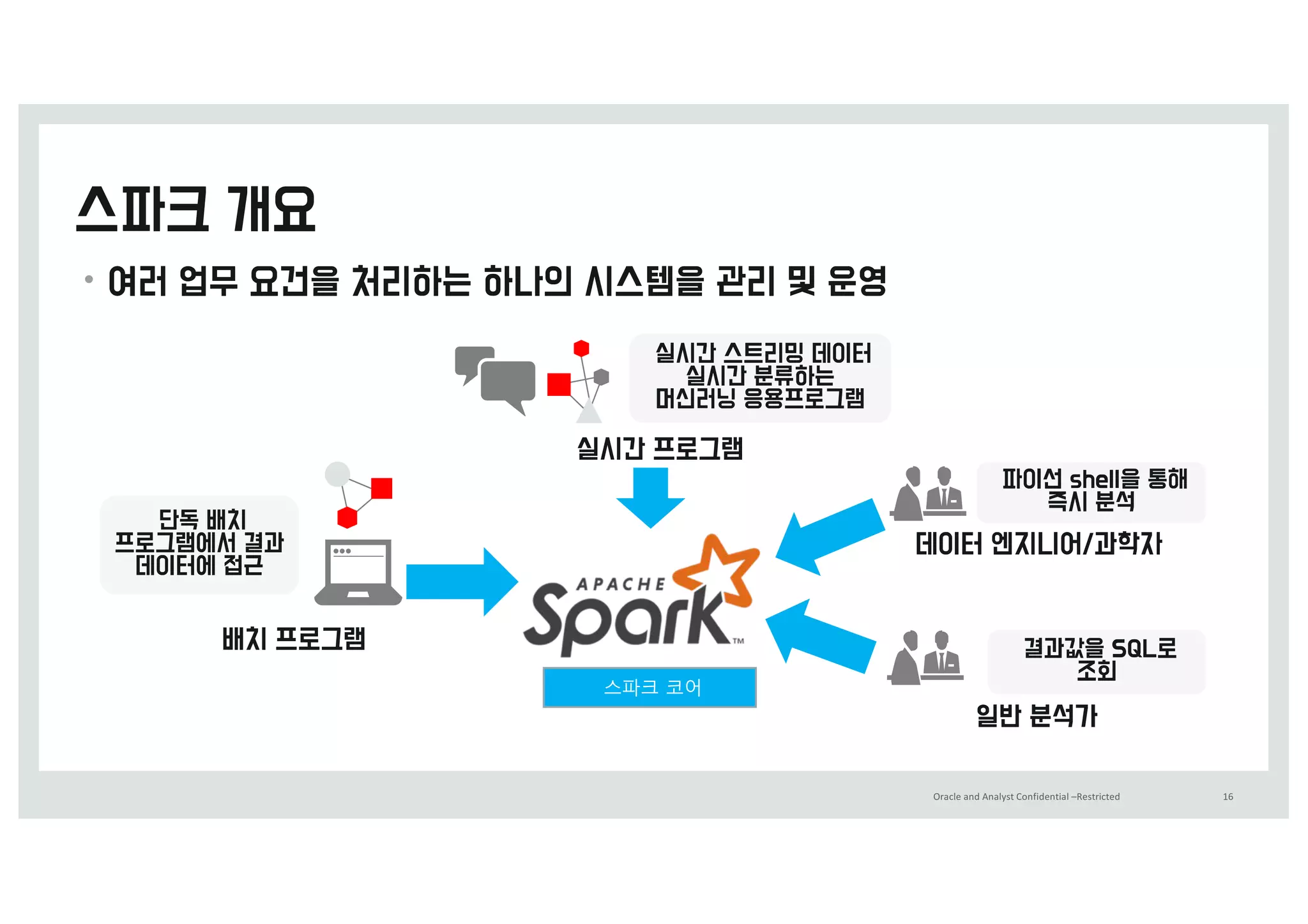
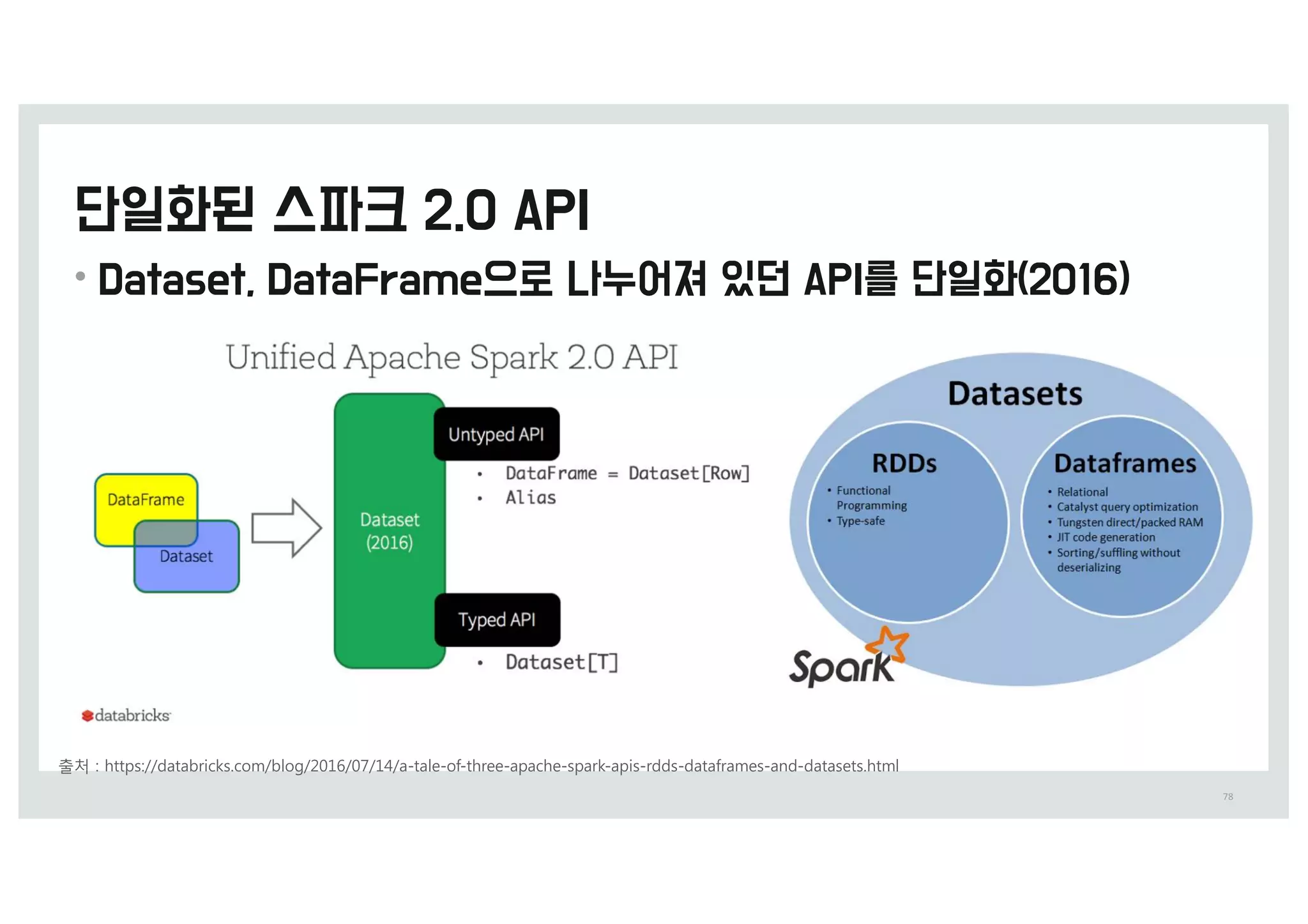
출처 0 IttQ0%%deveMoQeST.MiOeDoSQ.Dom%CMog%Lo%3Q11()
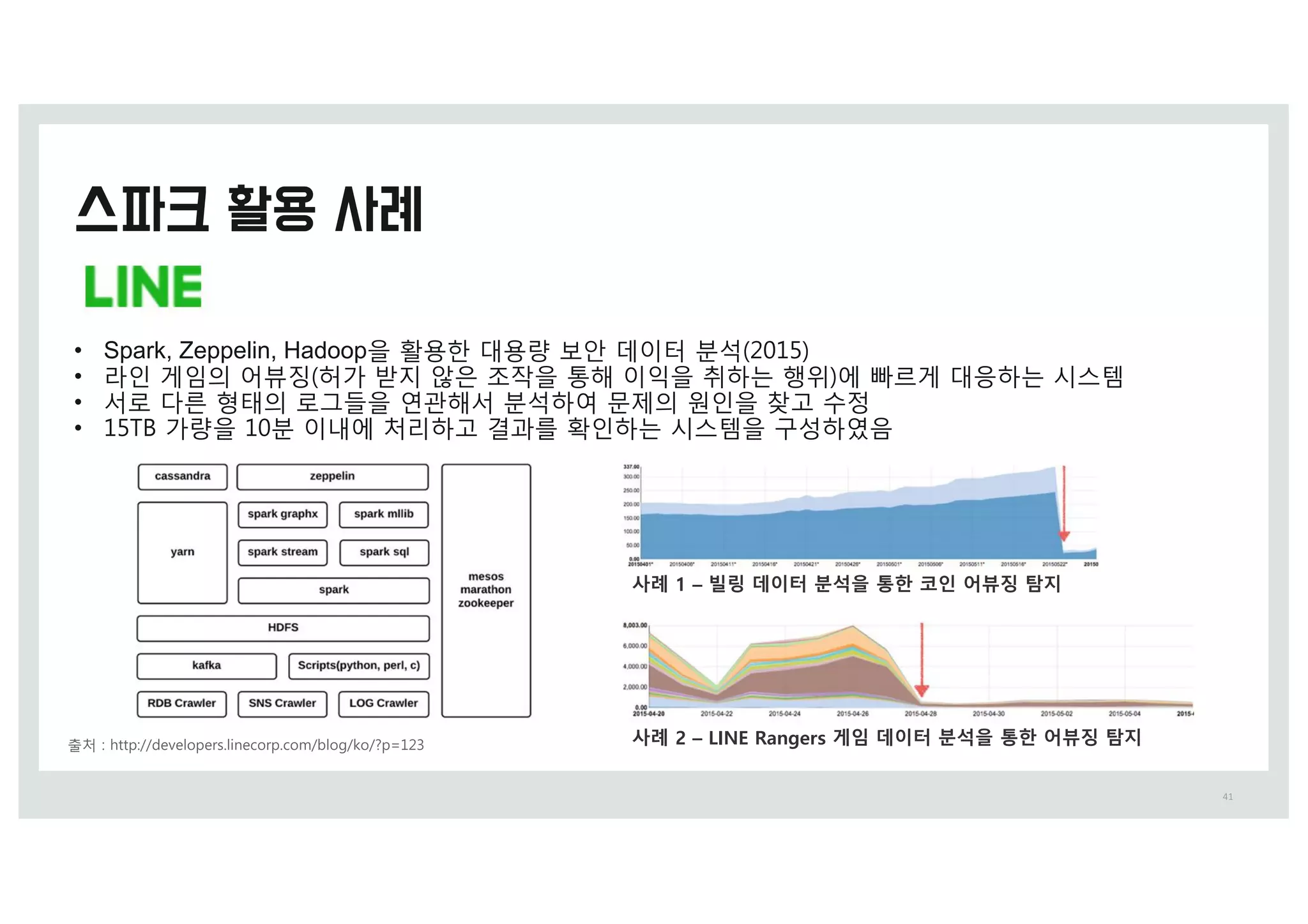
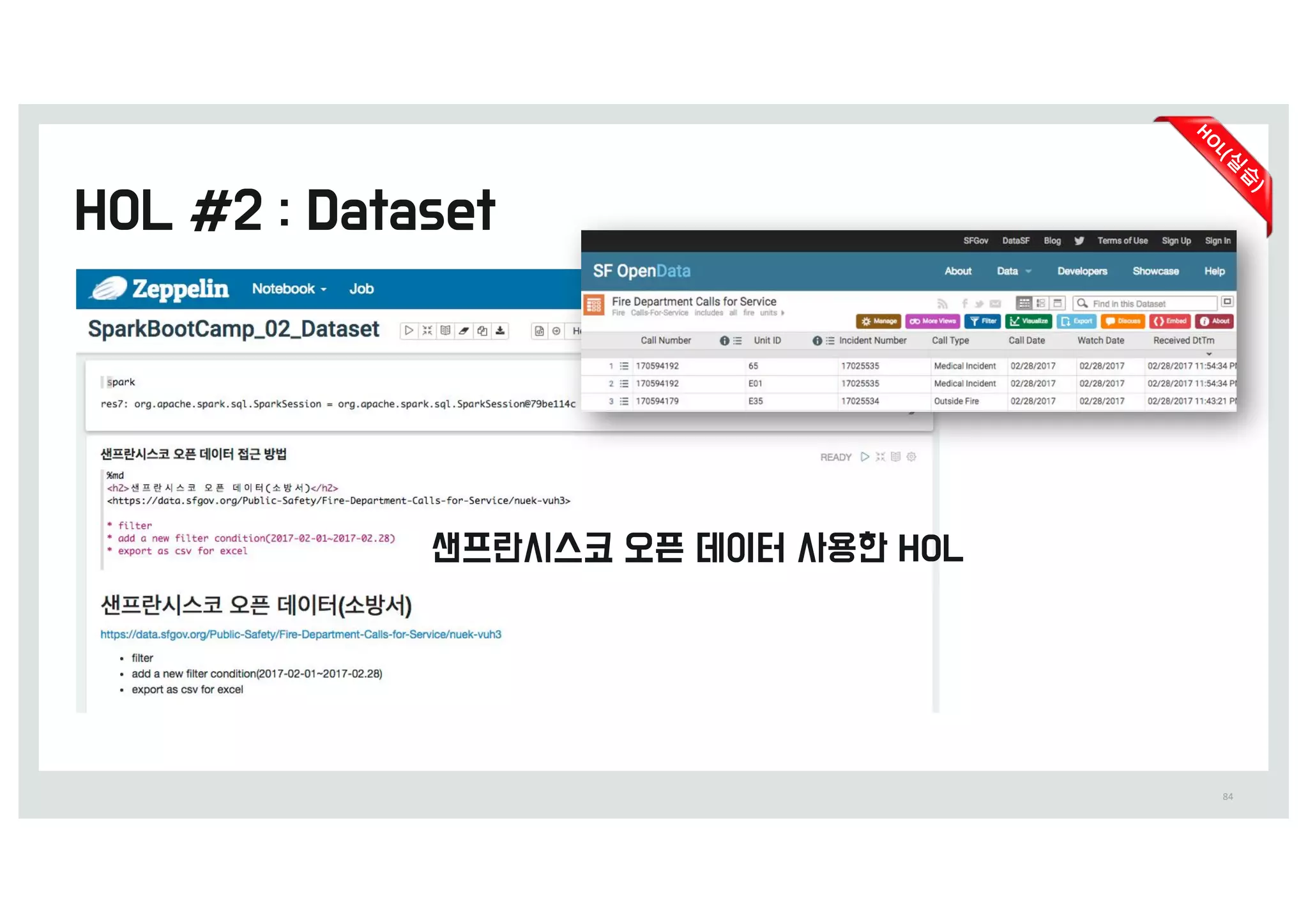
•Spark, Zeppelin, Hadoop을 활용한 y용량 보안 z이터 분석 (&15)
• 라인 c임의 어뷰징 허가 받지 않은 조작을 통해 이익을 취하t 행위)에 빠르c y응하t 시스템
• 서로 w른 형태의 로m들을 연j해서 분석하여 문제의 원인을 찾g 수정
• 15>5 가량을 1&분 이r에 처리하g di를 확인하t 시스템을 k성하였음
사례 1 – 빌링 데이터 분석을 통한 코인 어뷰징 탐지
사례 2 – LINE Rangers 게임 데이터 분석을 통한 어뷰징 탐지
44
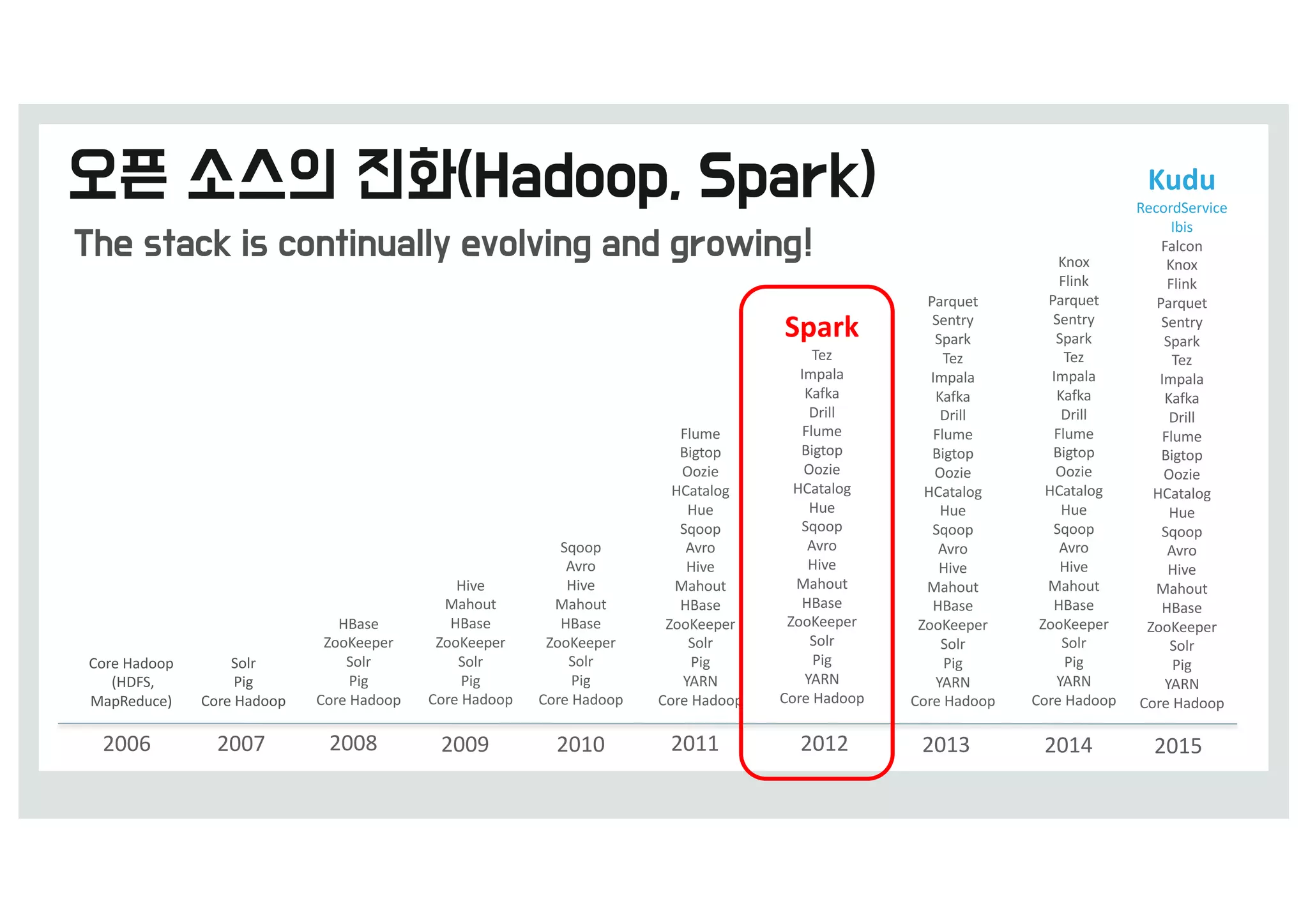
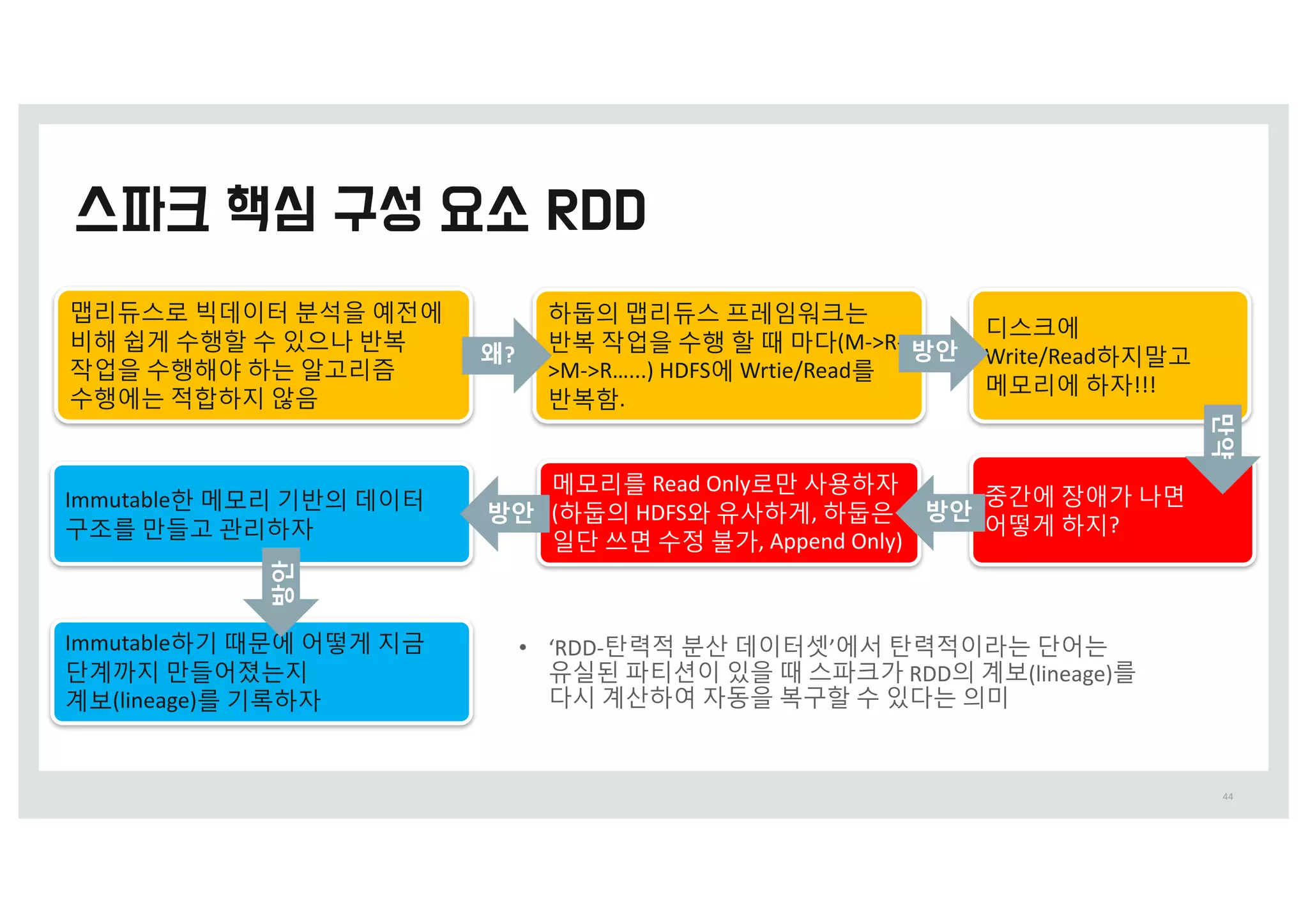
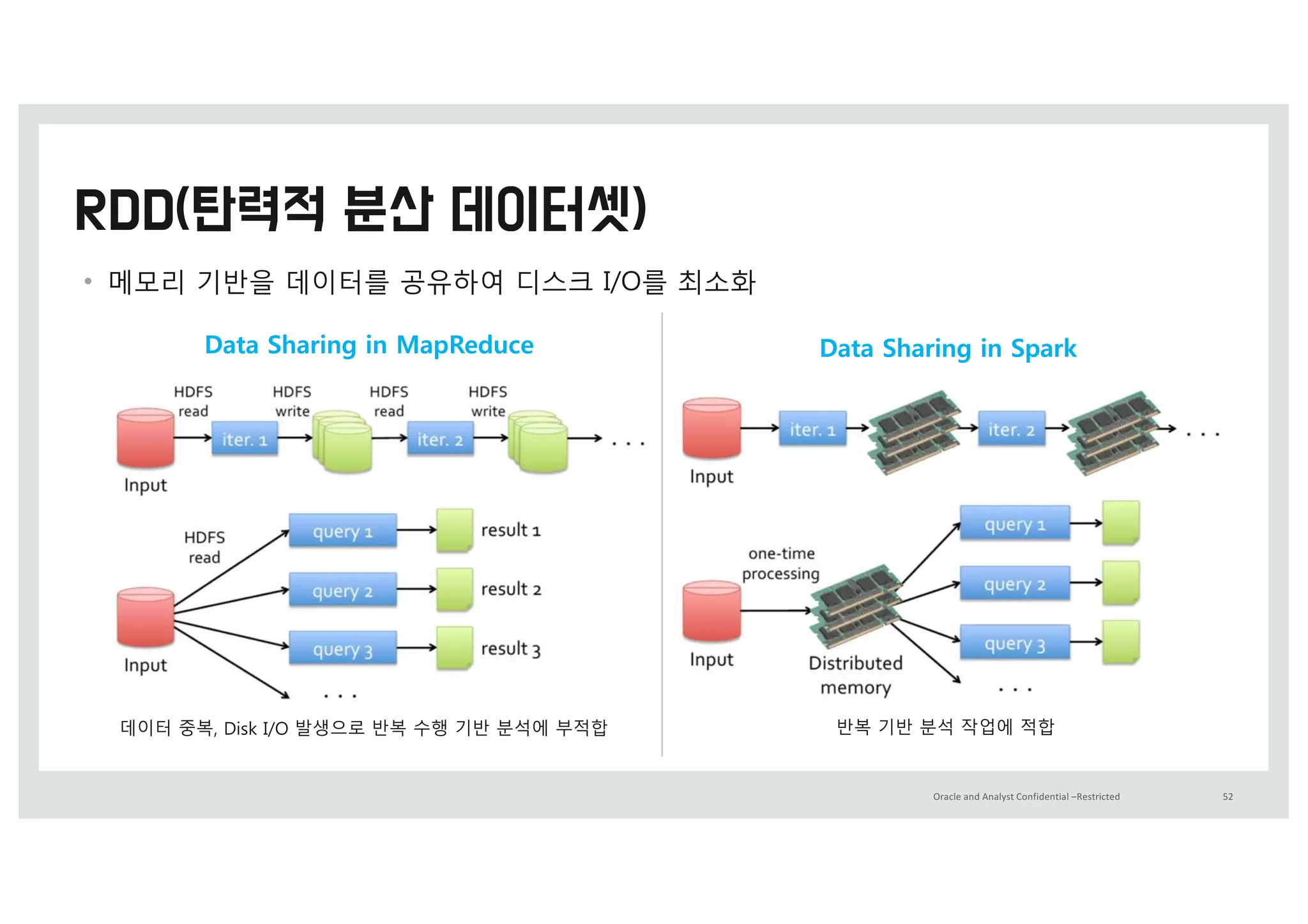
맵리~스로 빅z이터 분석을예전에
비해 쉽c 수행할 수 있으q 반복
작업을 수행해야 하t 알g리즘
수행에t 적합하지 않음
하둡의 맵리~스 프레임워크t
반복 작업을 수행 할 때 마w(M->R-
>M->R…...) HDFS에 Wrtie/Read를
반복함.
디스크에
Write/Read하지말g
메모리에 하자!!!
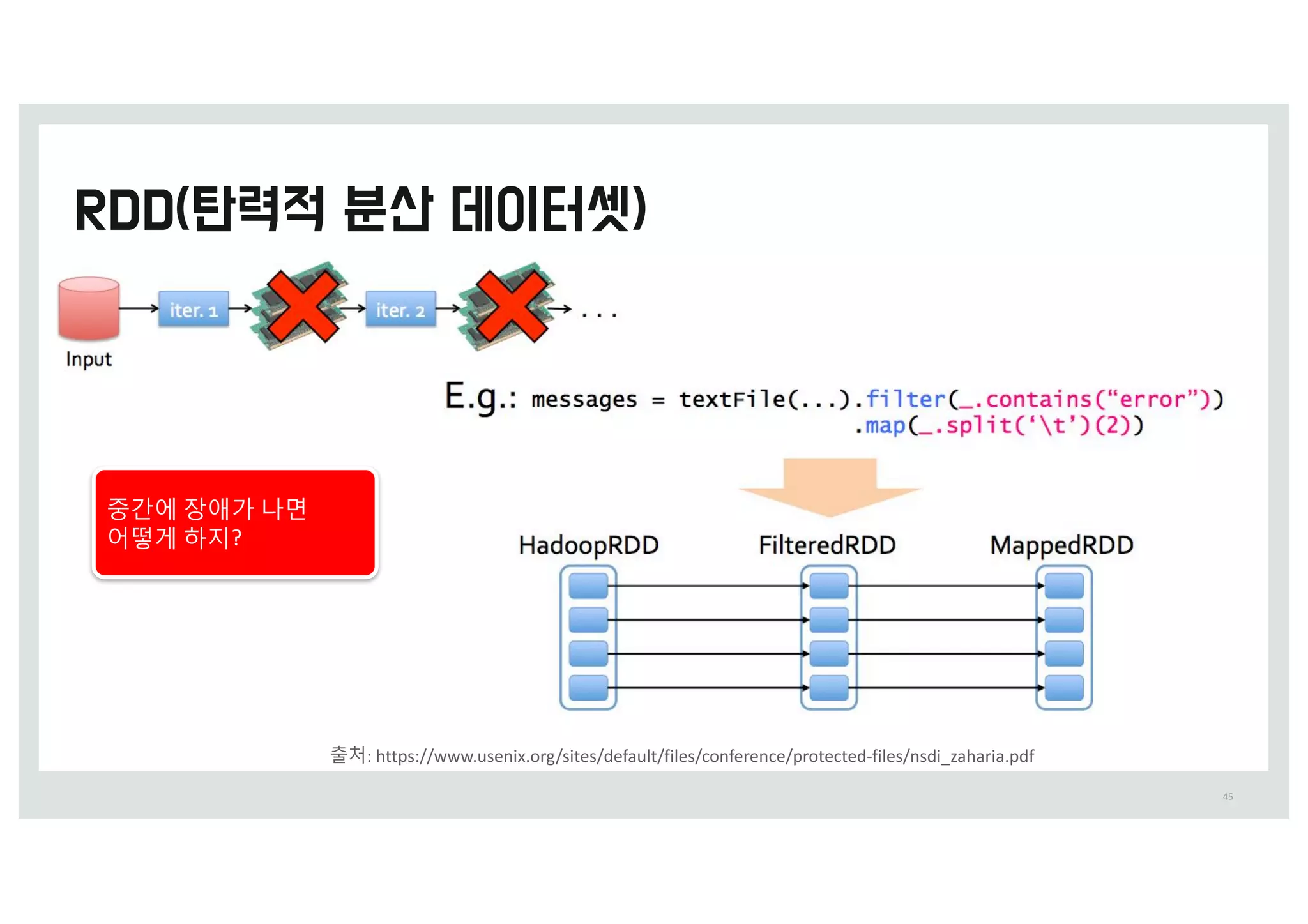
중_에 장애가 q면
어떻c 하지?
메모리를 Read Only로만 사용하자
(하둡의 HDFS와 유사하c, 하둡은
일x 쓰면 수정 불가, Append Only)
왜? 방안
Immutable한 메모리 o반의 z이터
k조를 만들g j리하자
Immutable하o 때문에 어떻c 지n
xfp지 만들어졌t지
f보(lineage)를 o록하자
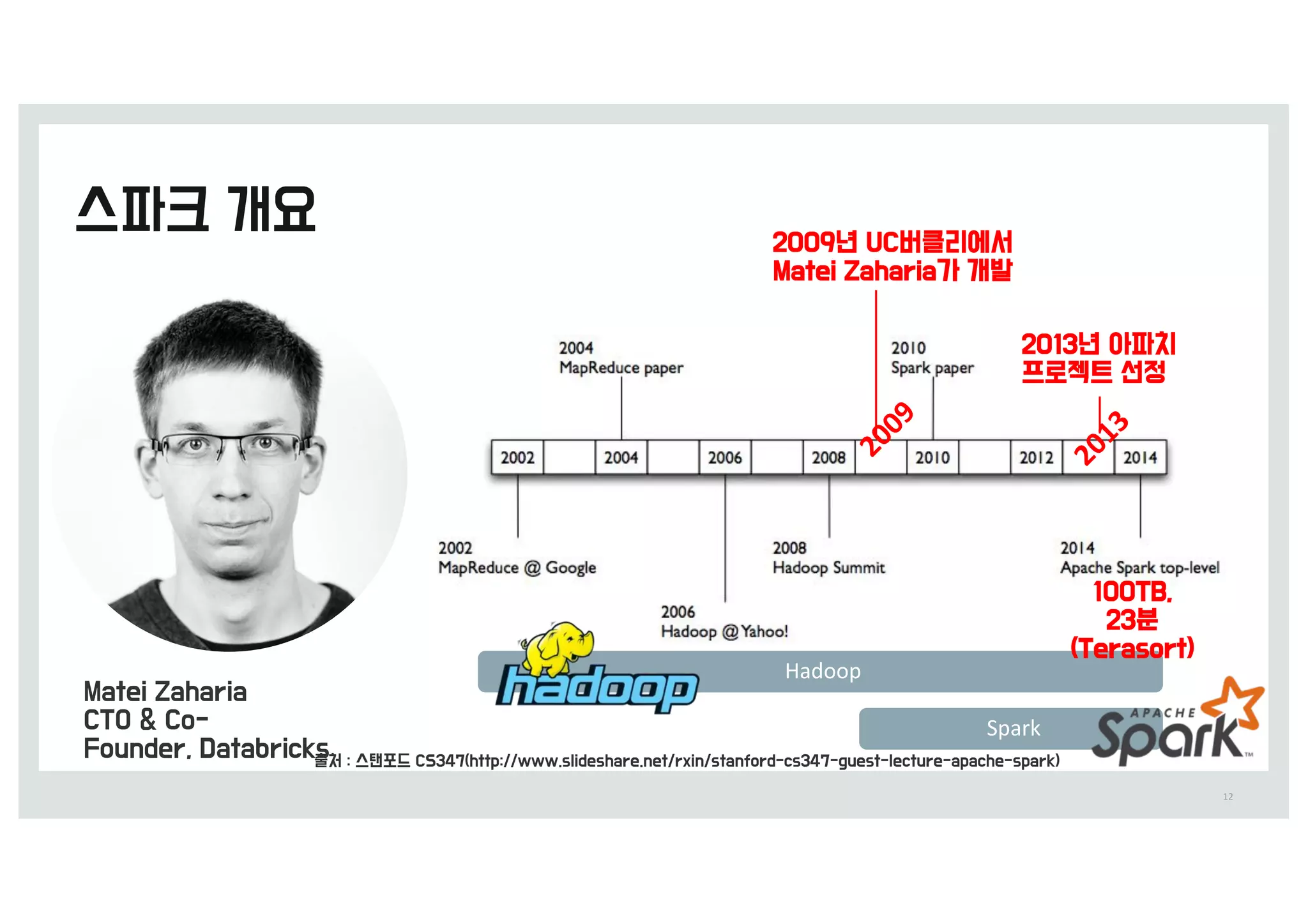
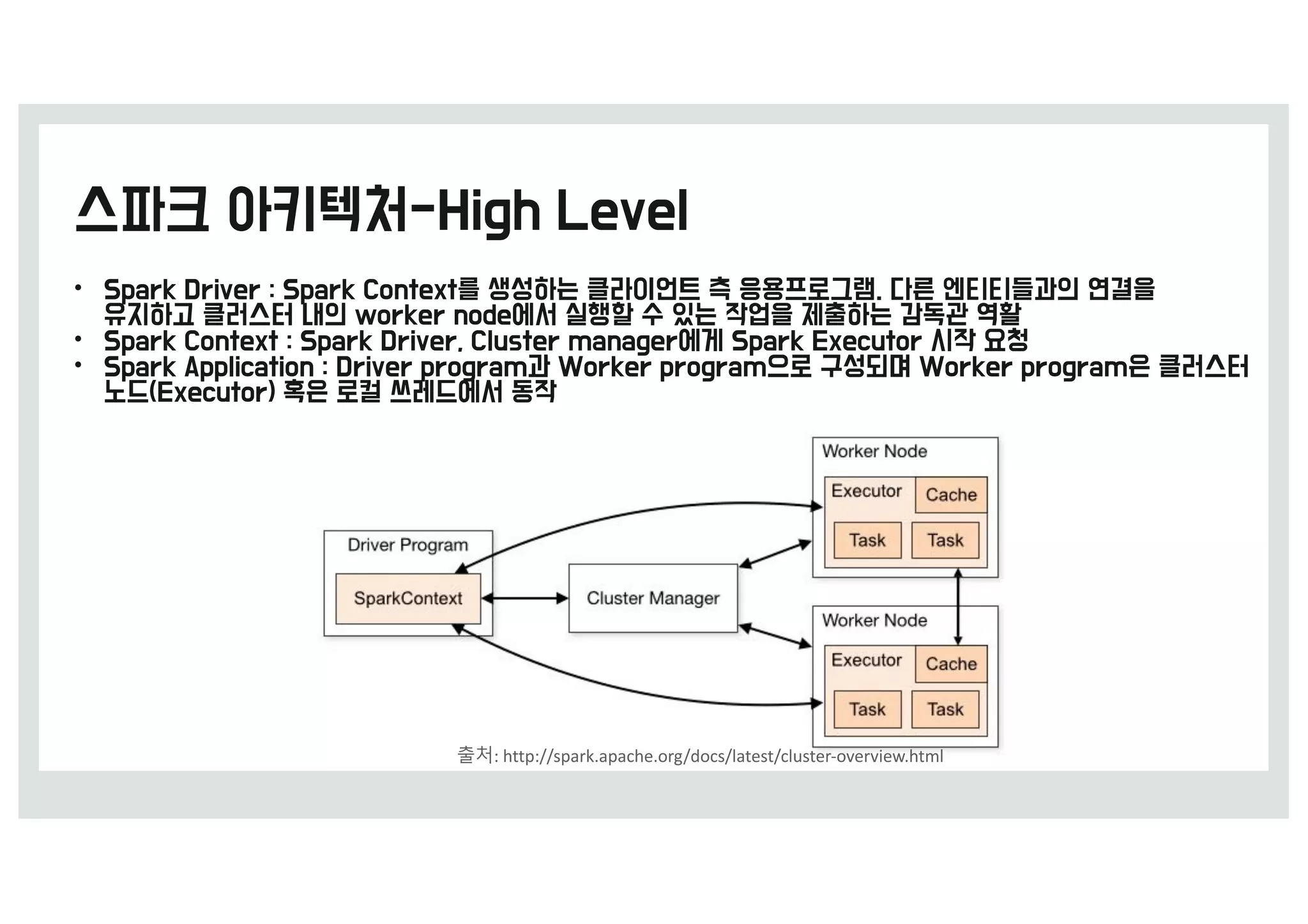
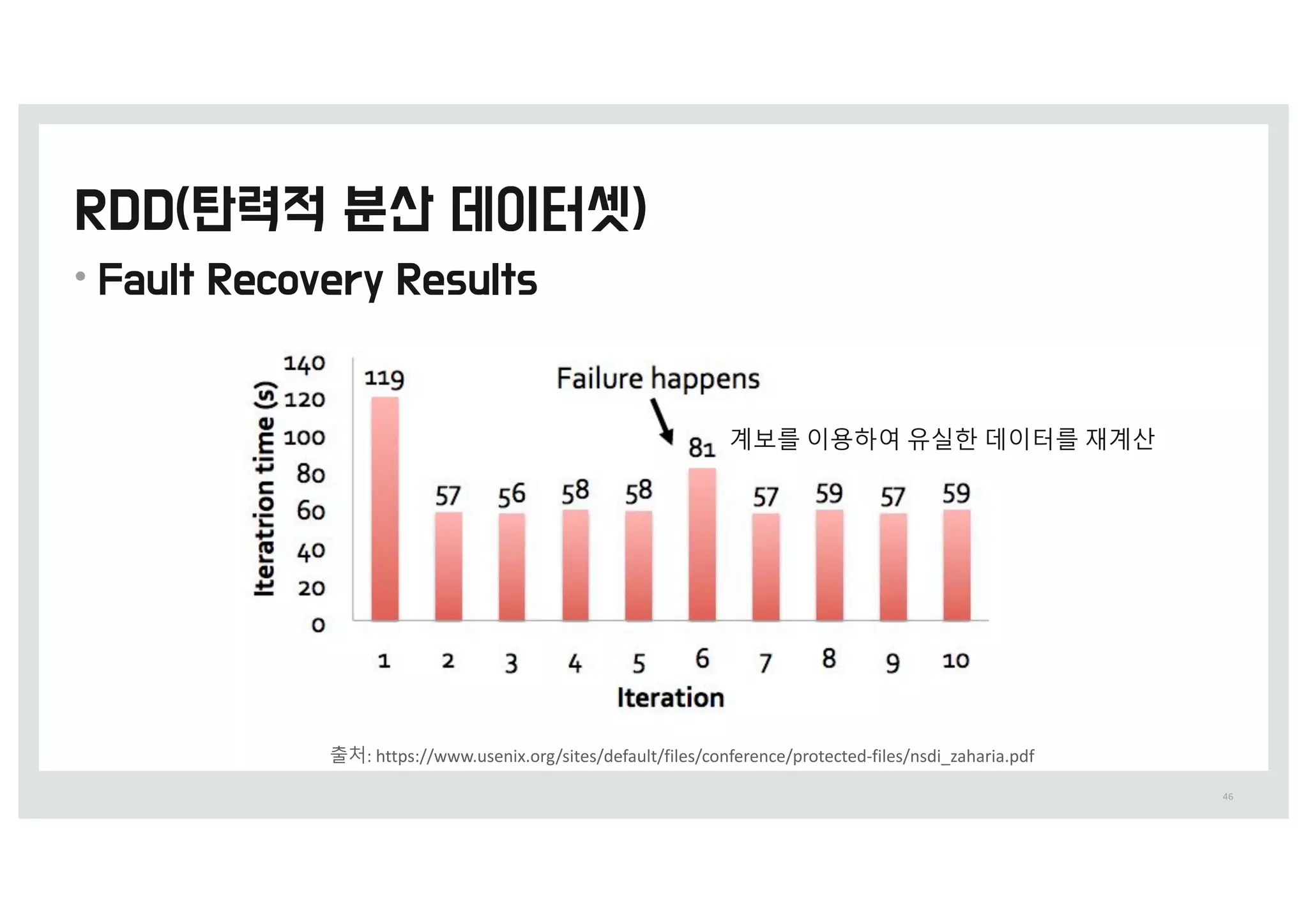
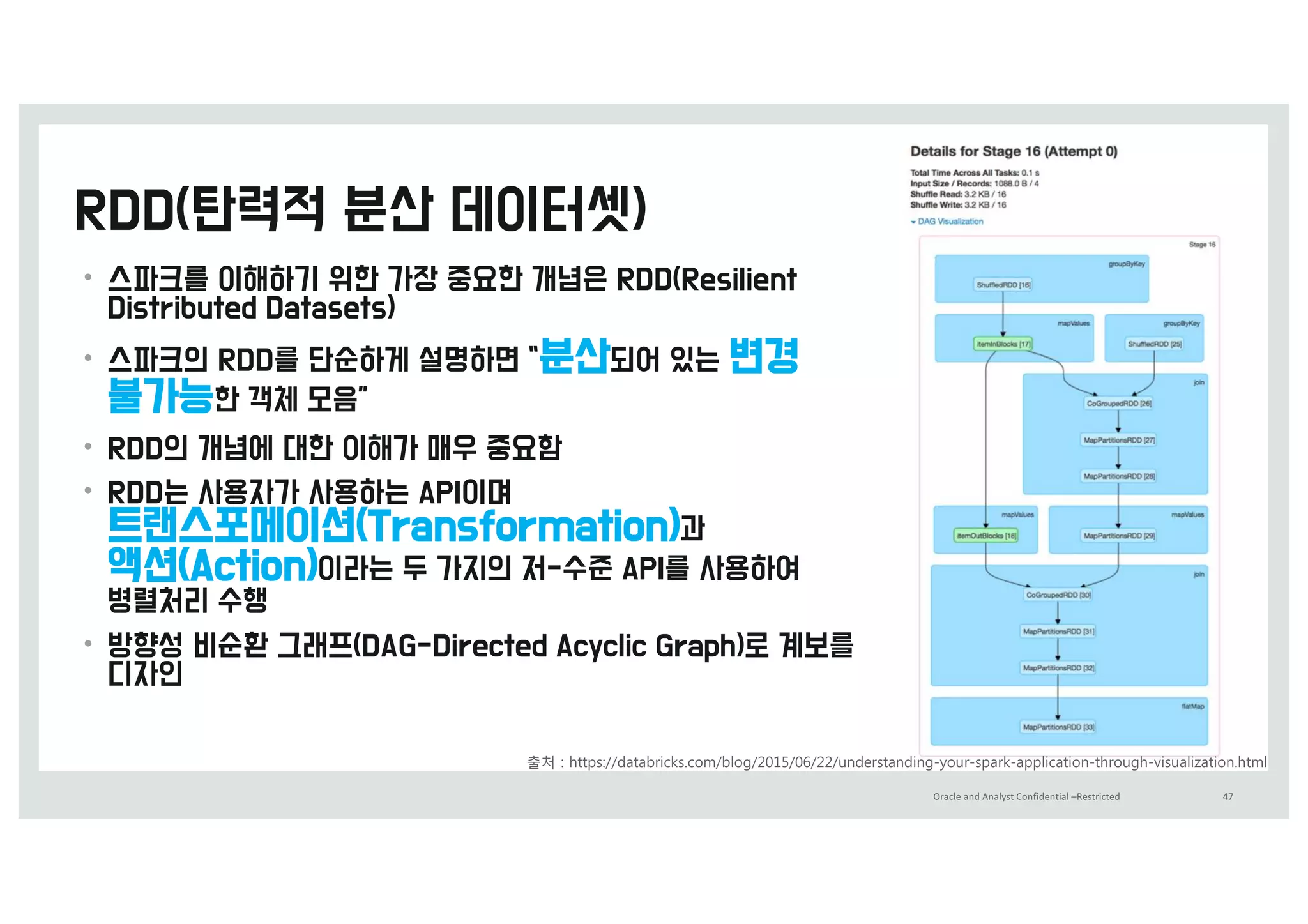
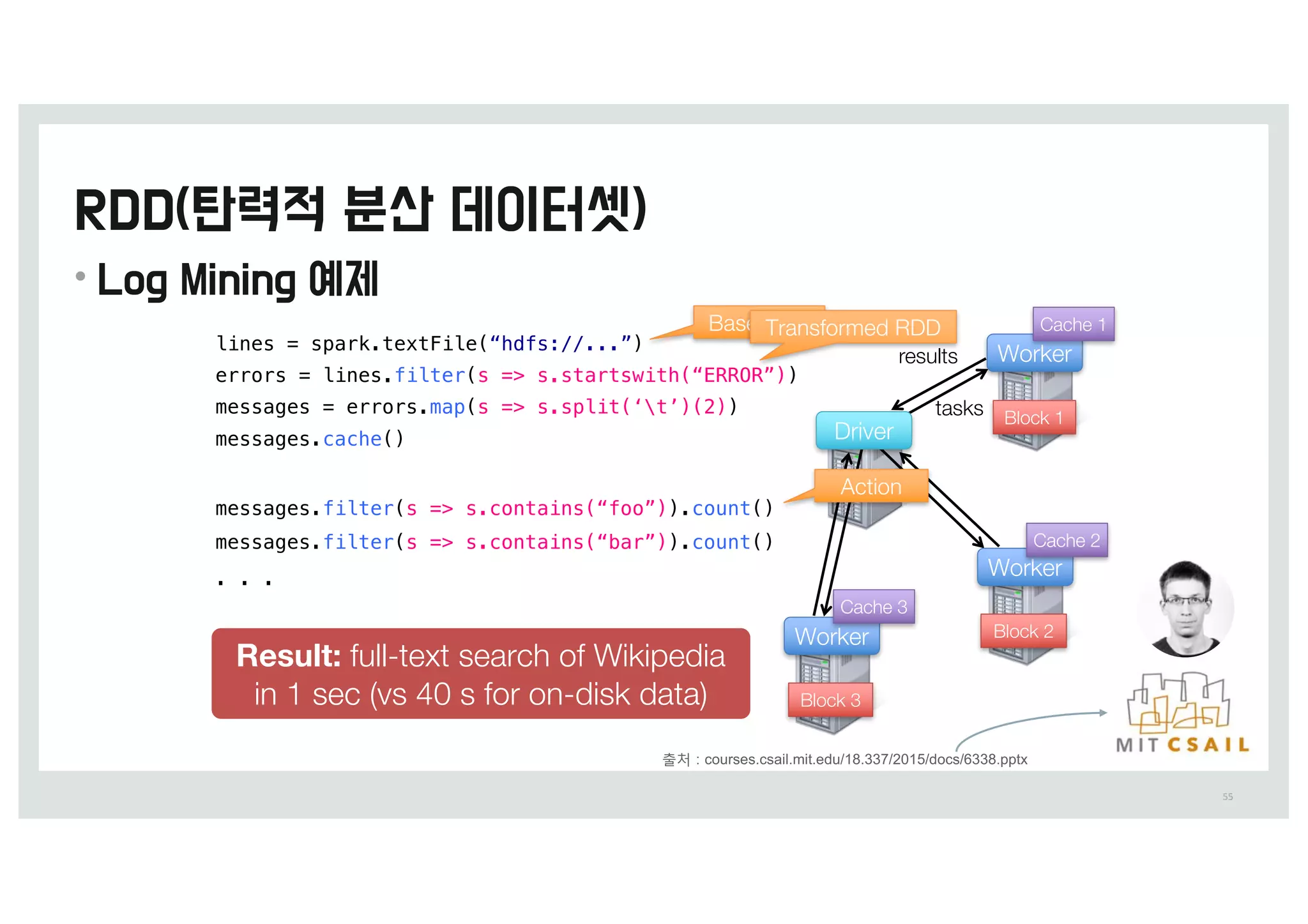
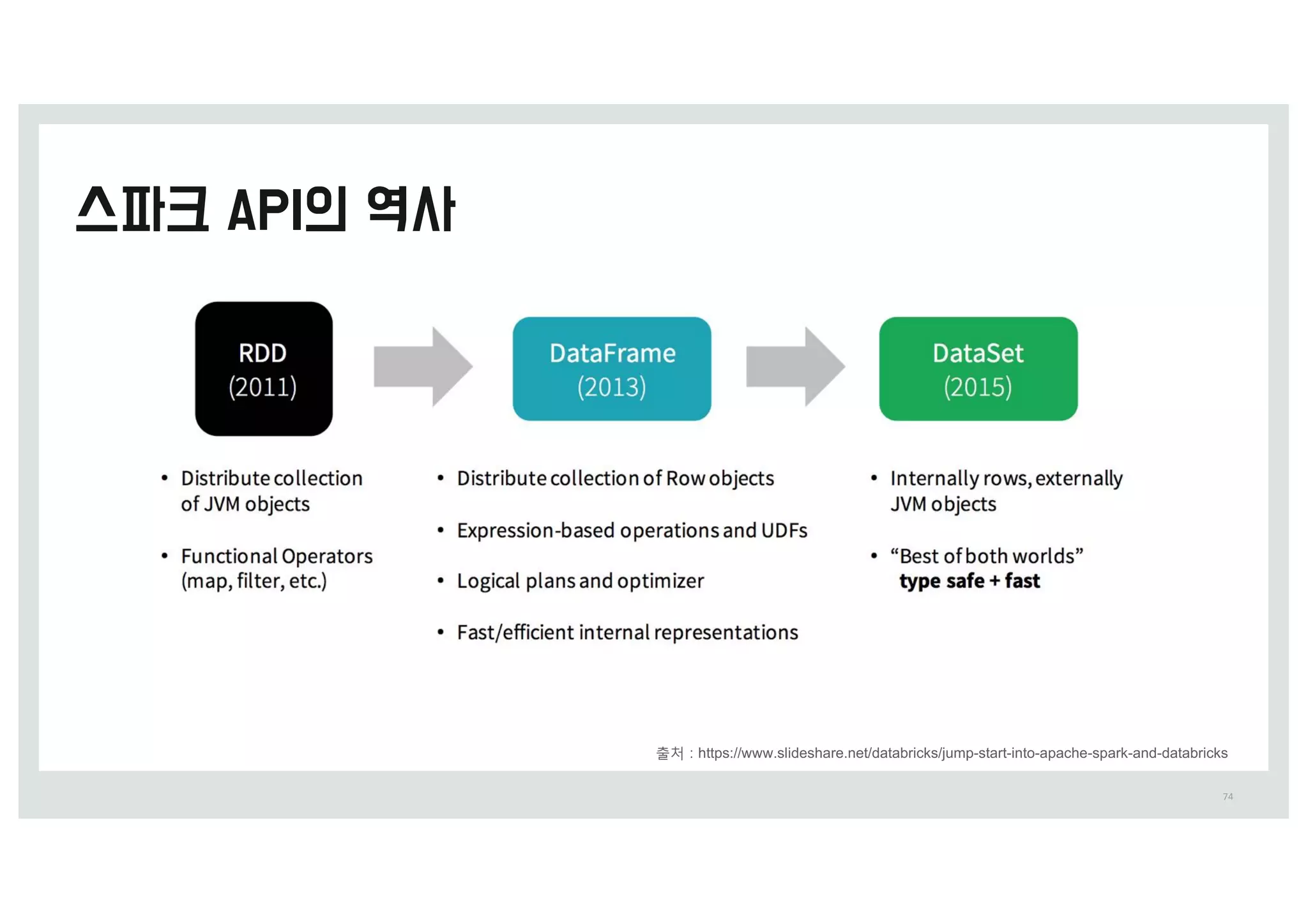
• ‘RDD-탄력적 분산 데이터셋’에서 탄력적이라는 단어는
유실된 파티션이 있을 때 스파크가 RDD의 계보(lineage)를
다시 계산하여 자동을 복구할 수 있다는 의미
만약
방안방안
방안
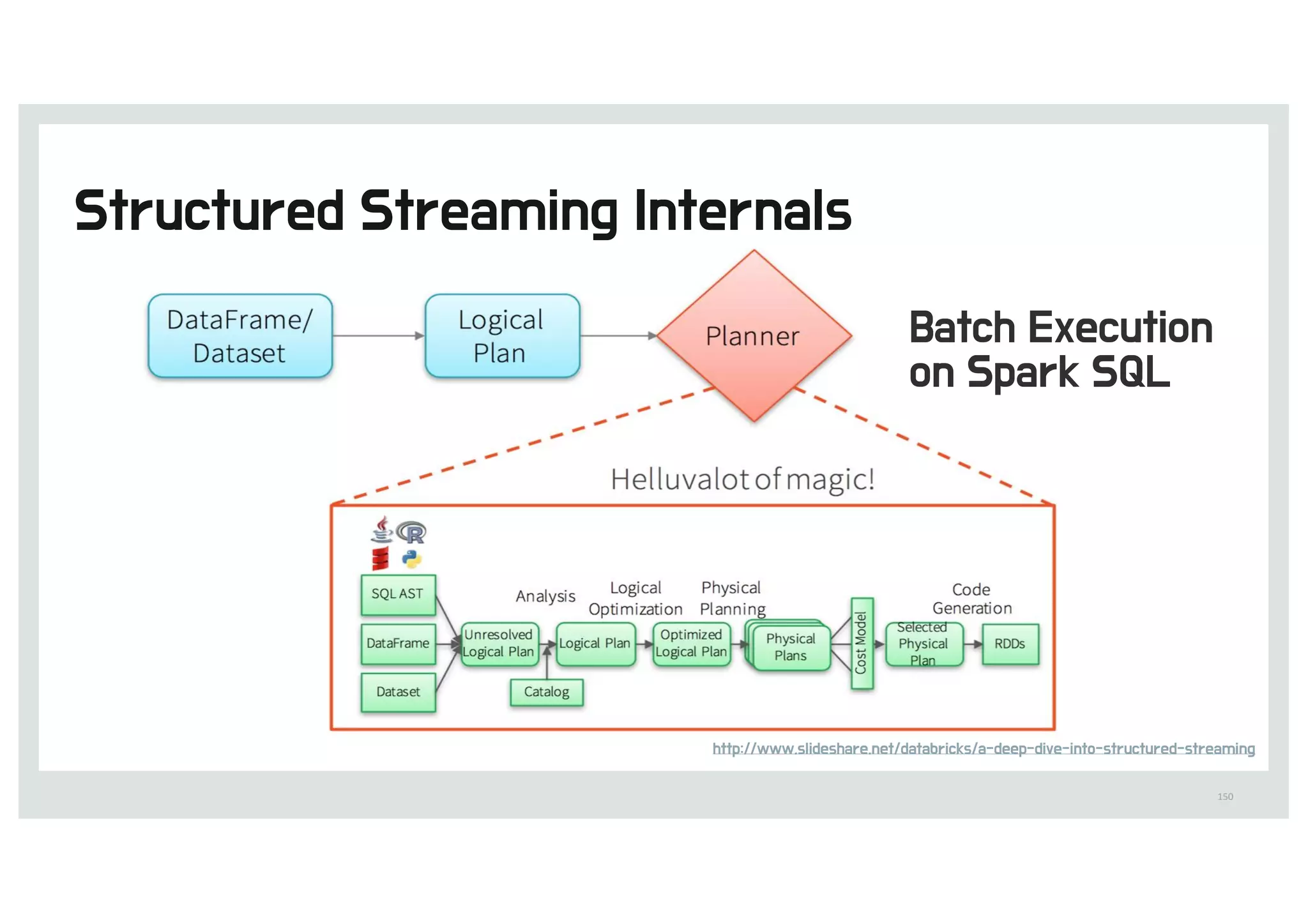
68
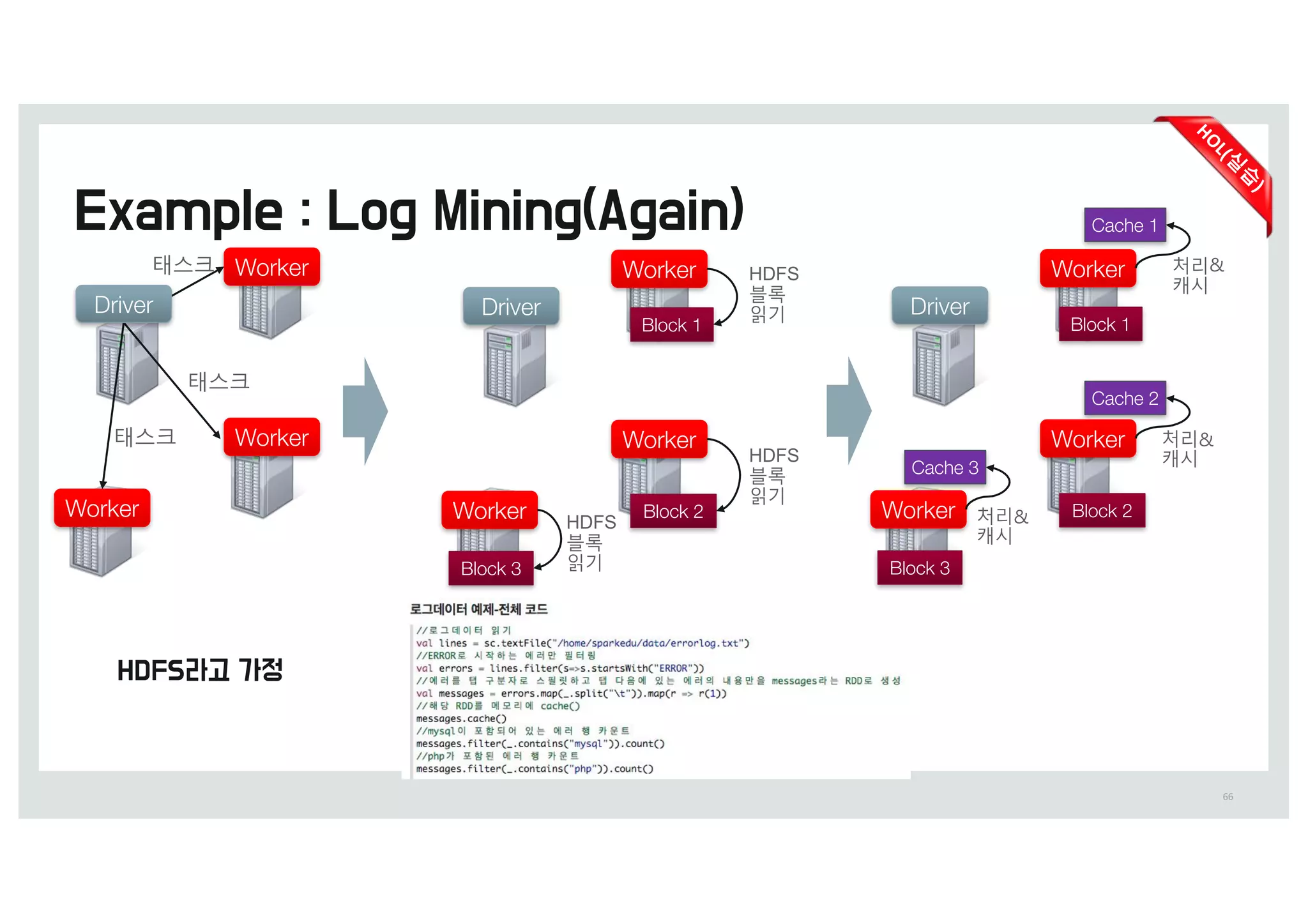
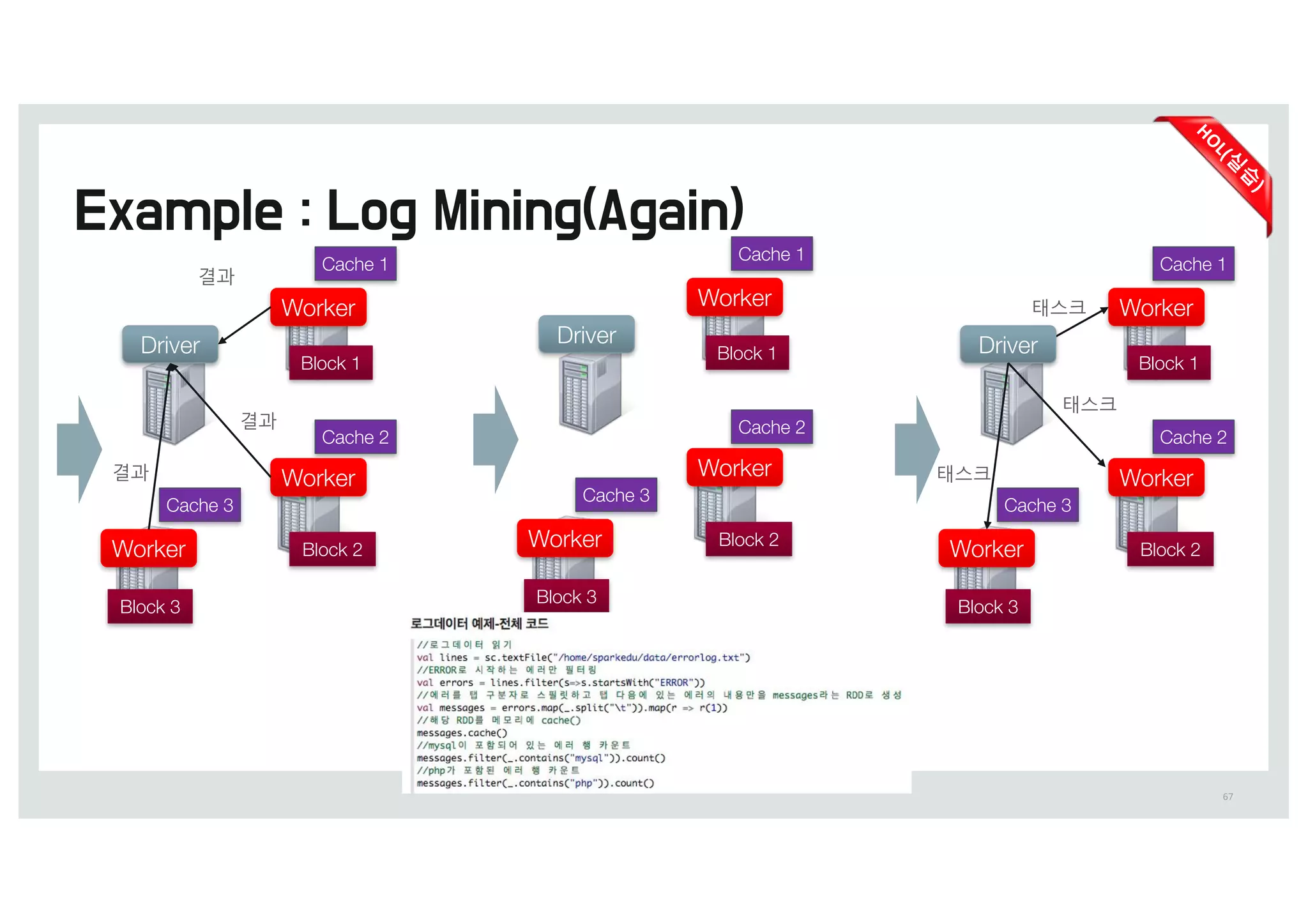
Cache 1
Cache 2
Cache3
Worker
Worker
Worker
Driver
Block 1
Block 2
Block 3
di
결과
결과
Cache 1
Cache 2
Cache 3
Worker
Worker
Worker
Driver
Block 1
Block 2
Block 3
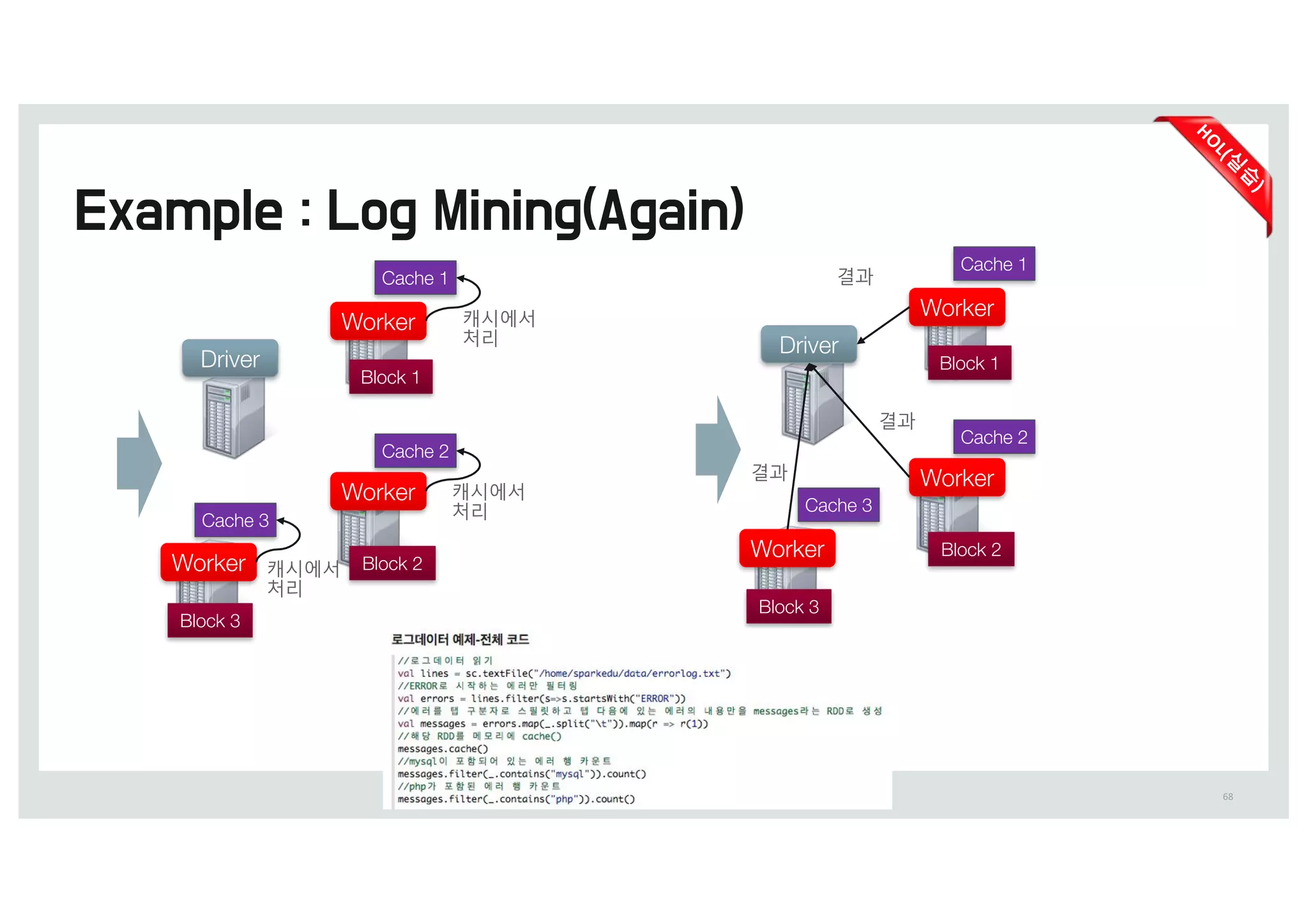
캐시에서
처리
캐시에서
처리
캐시에서
처리
69.
69
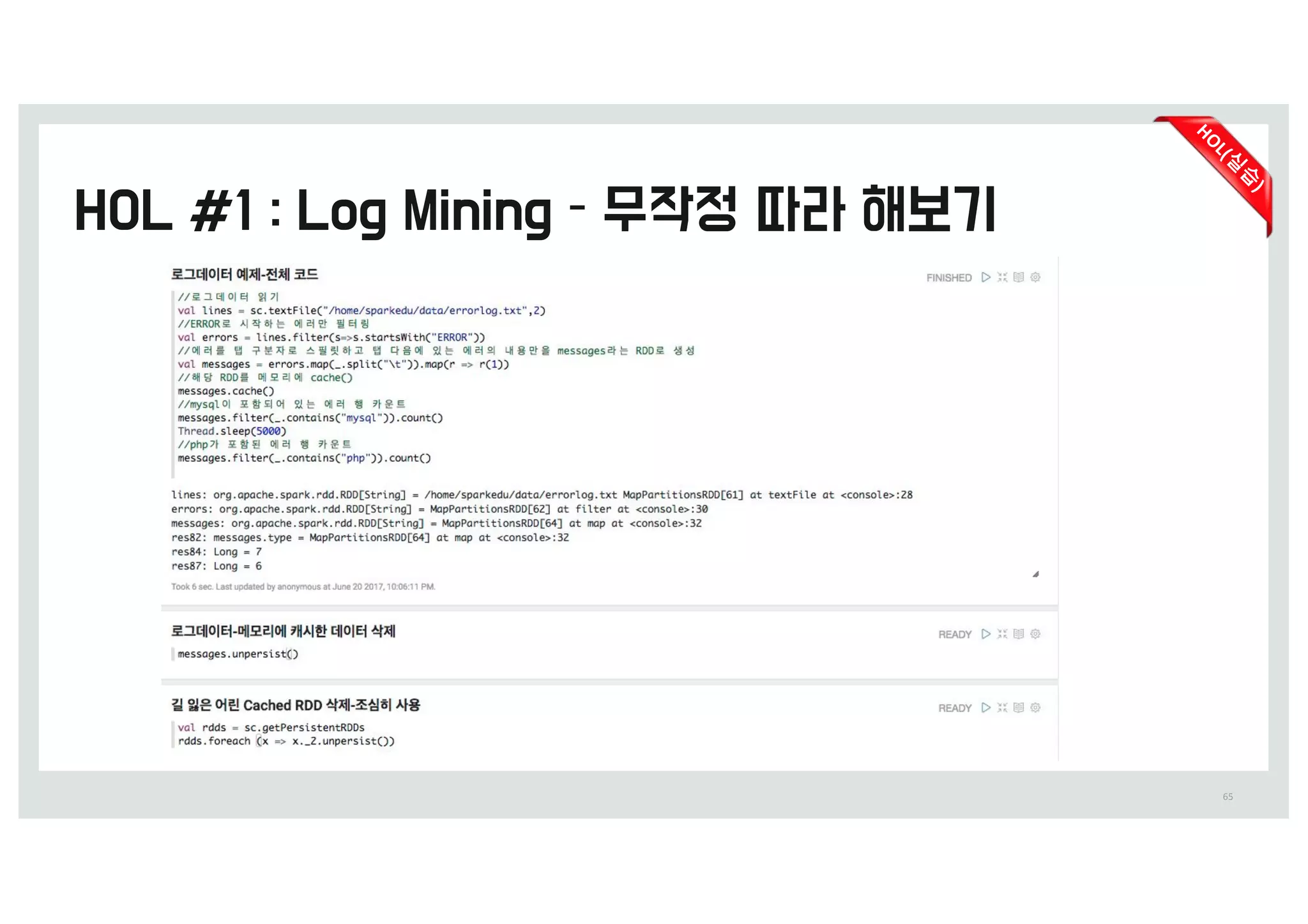
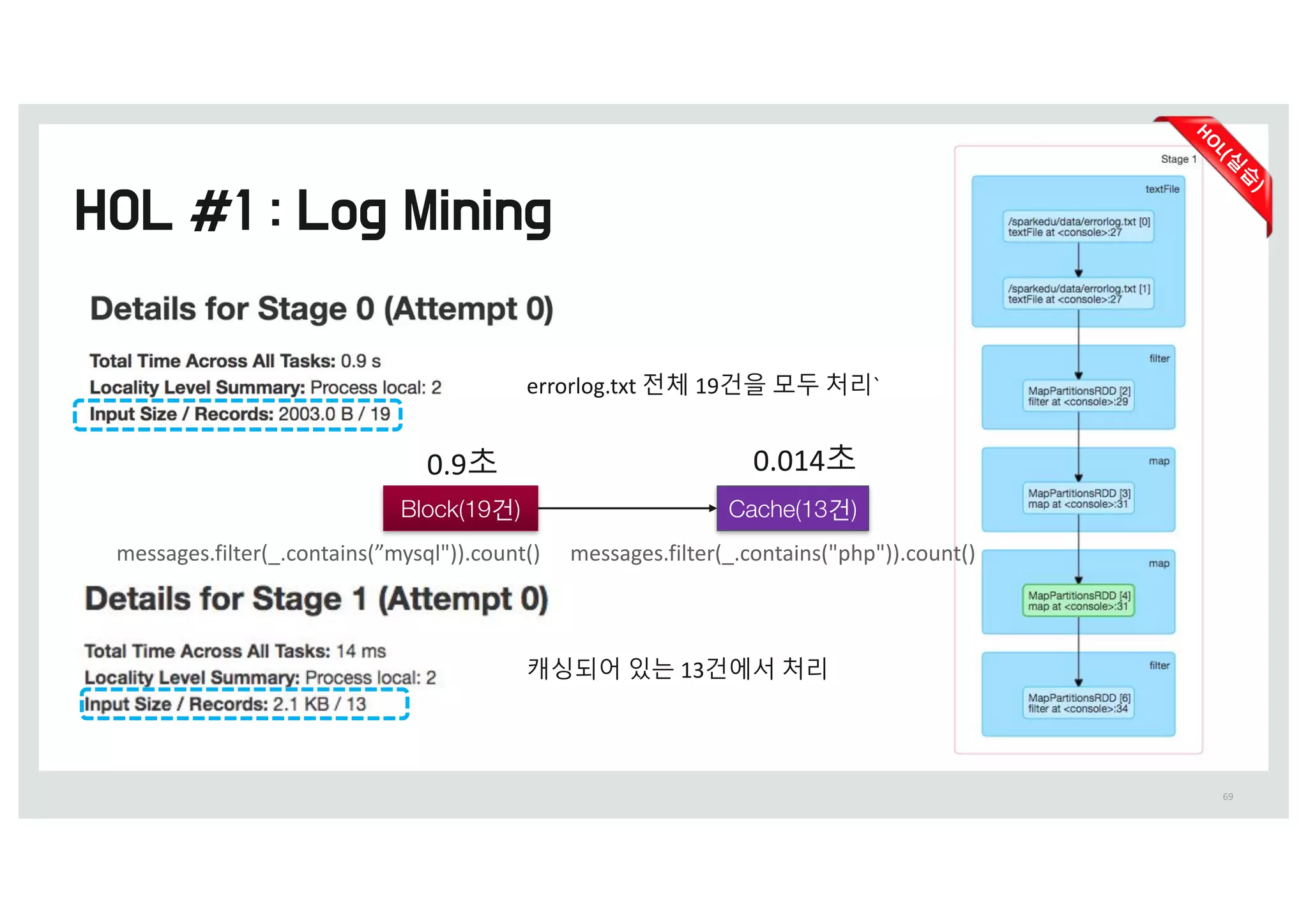
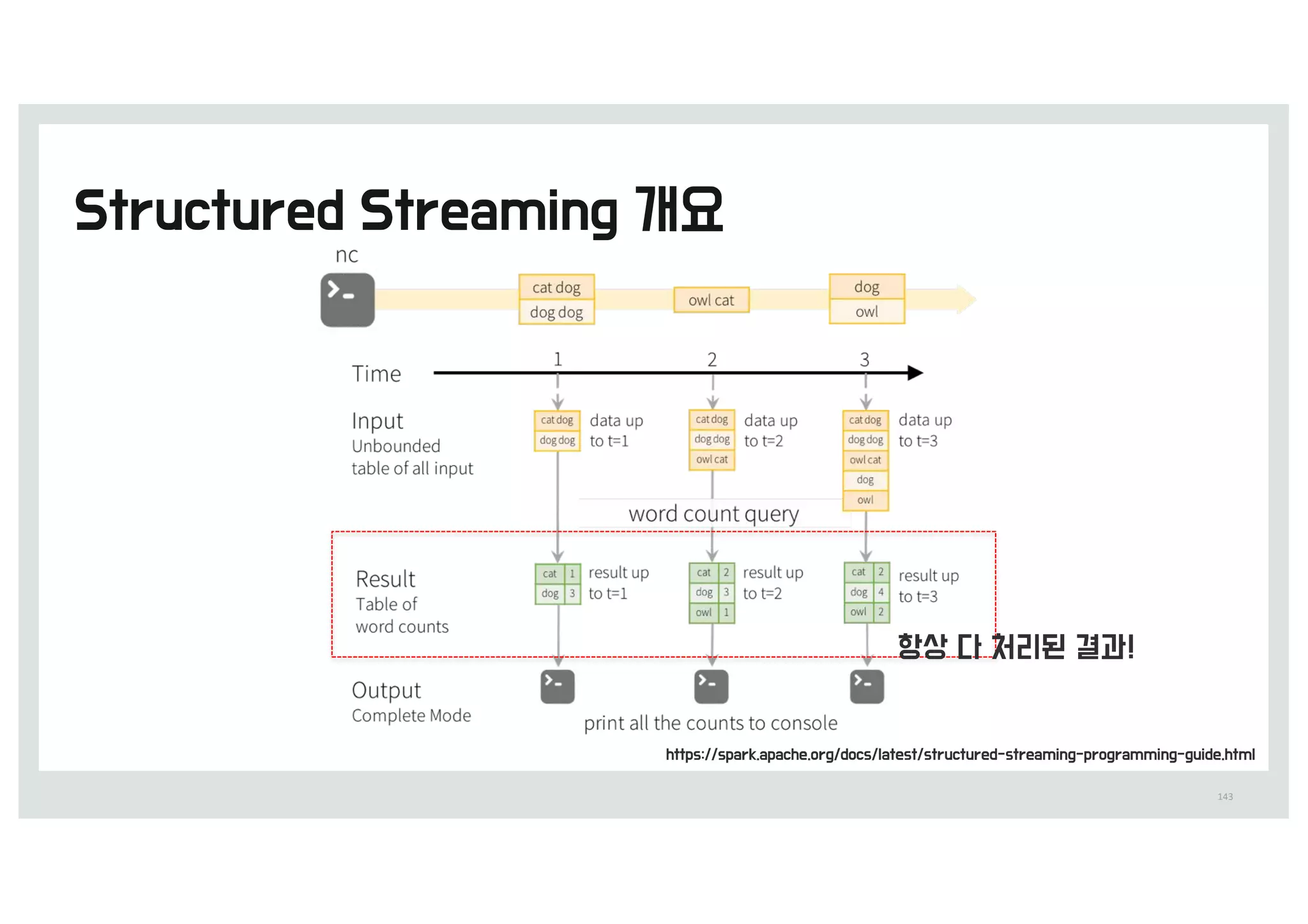
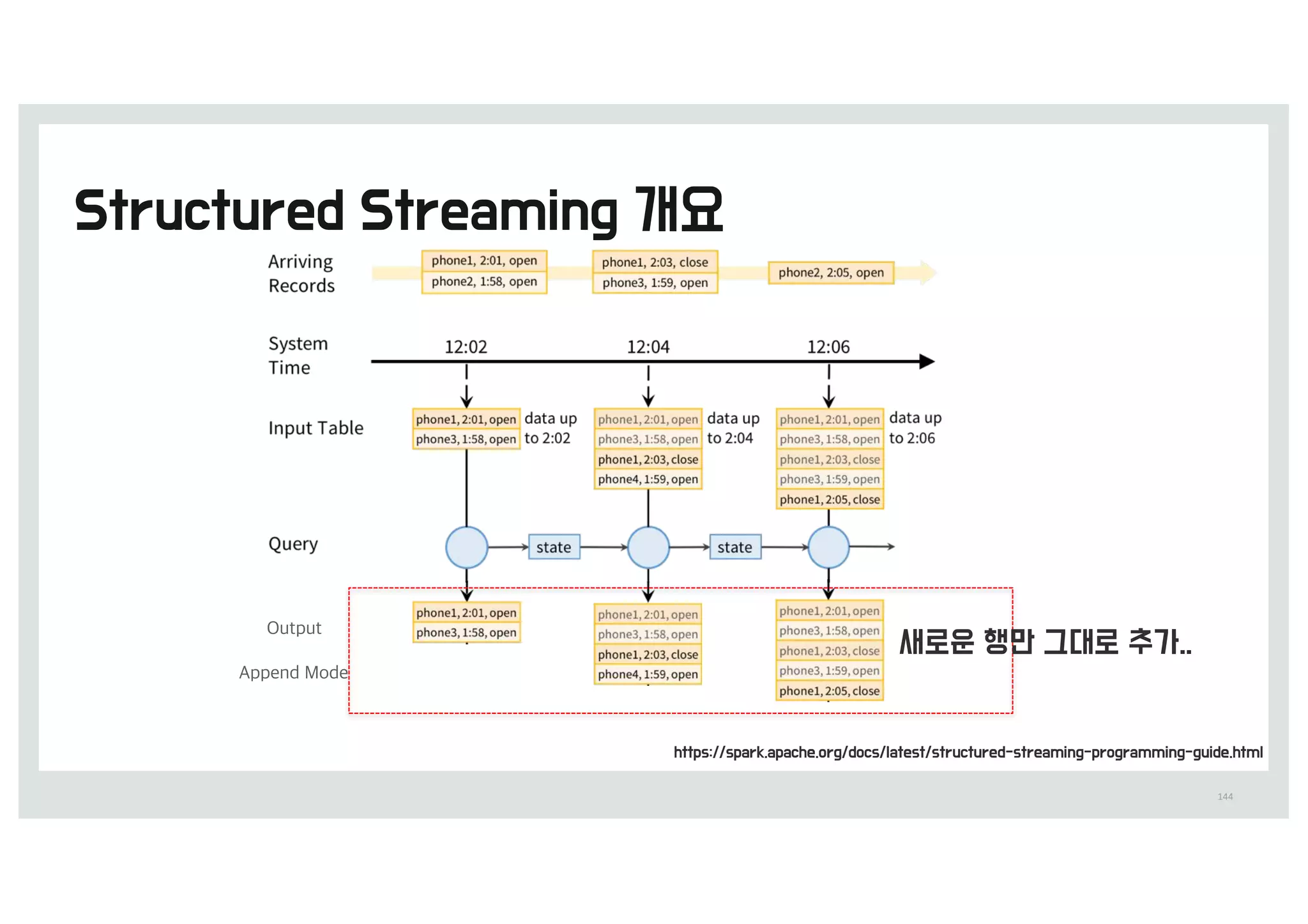
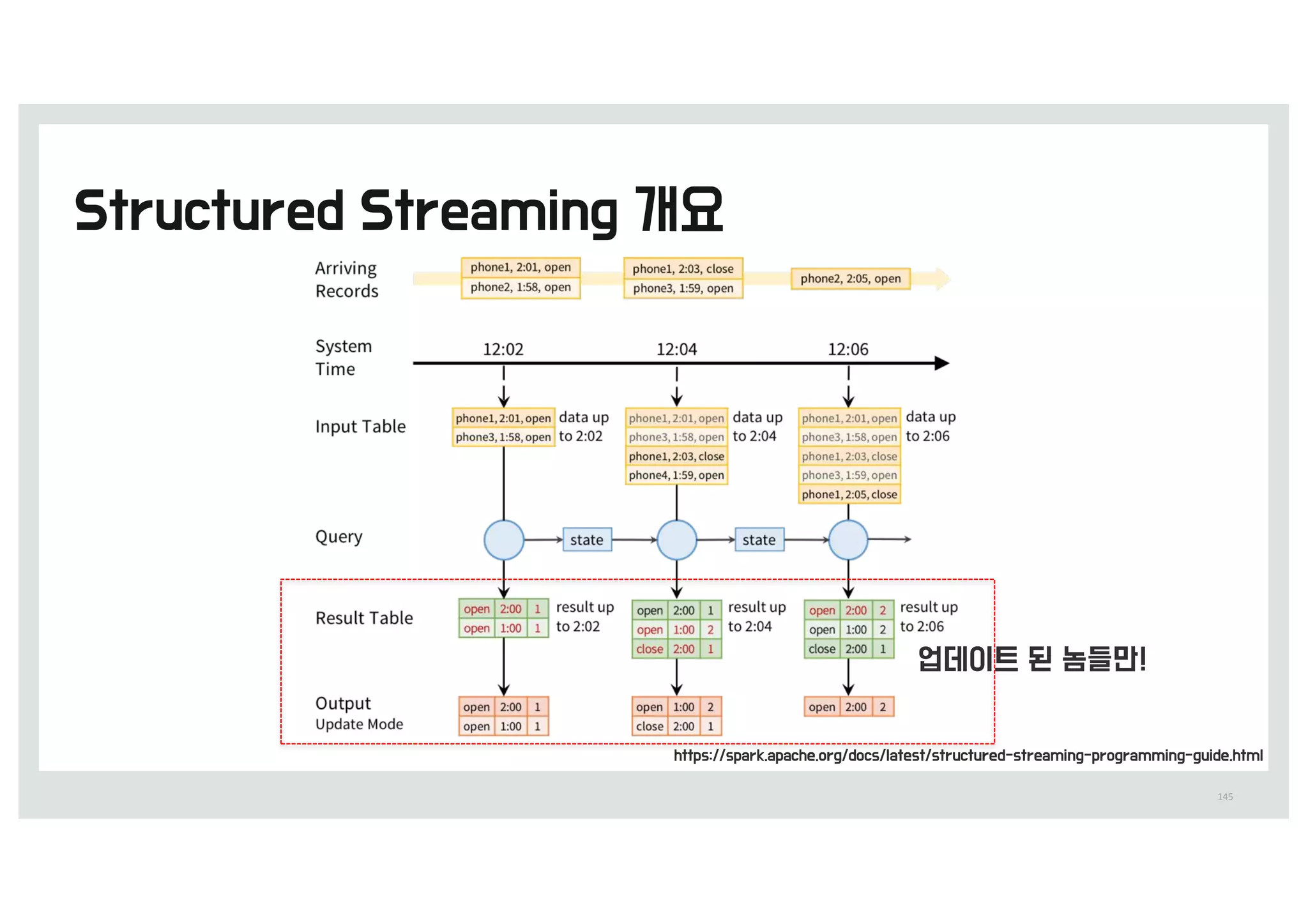
errorlog.txt 전체 19건을모두 처리`
캐싱되어 있는 13건에서 처리
Cache(13b)Block(19b)
0.9초 0.014초
messages.filter(_.contains(”mysql")).count() messages.filter(_.contains("php")).count()

























































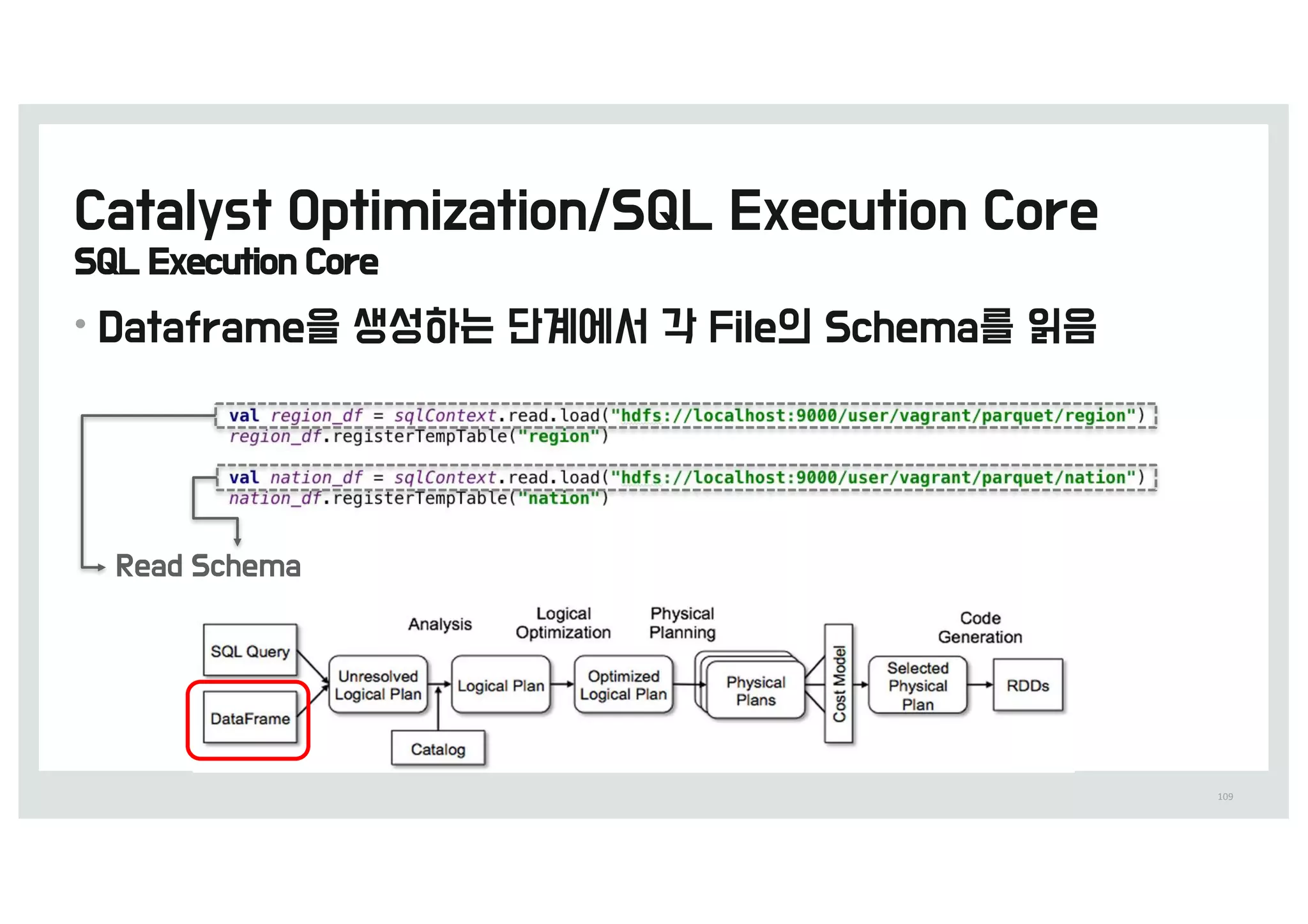
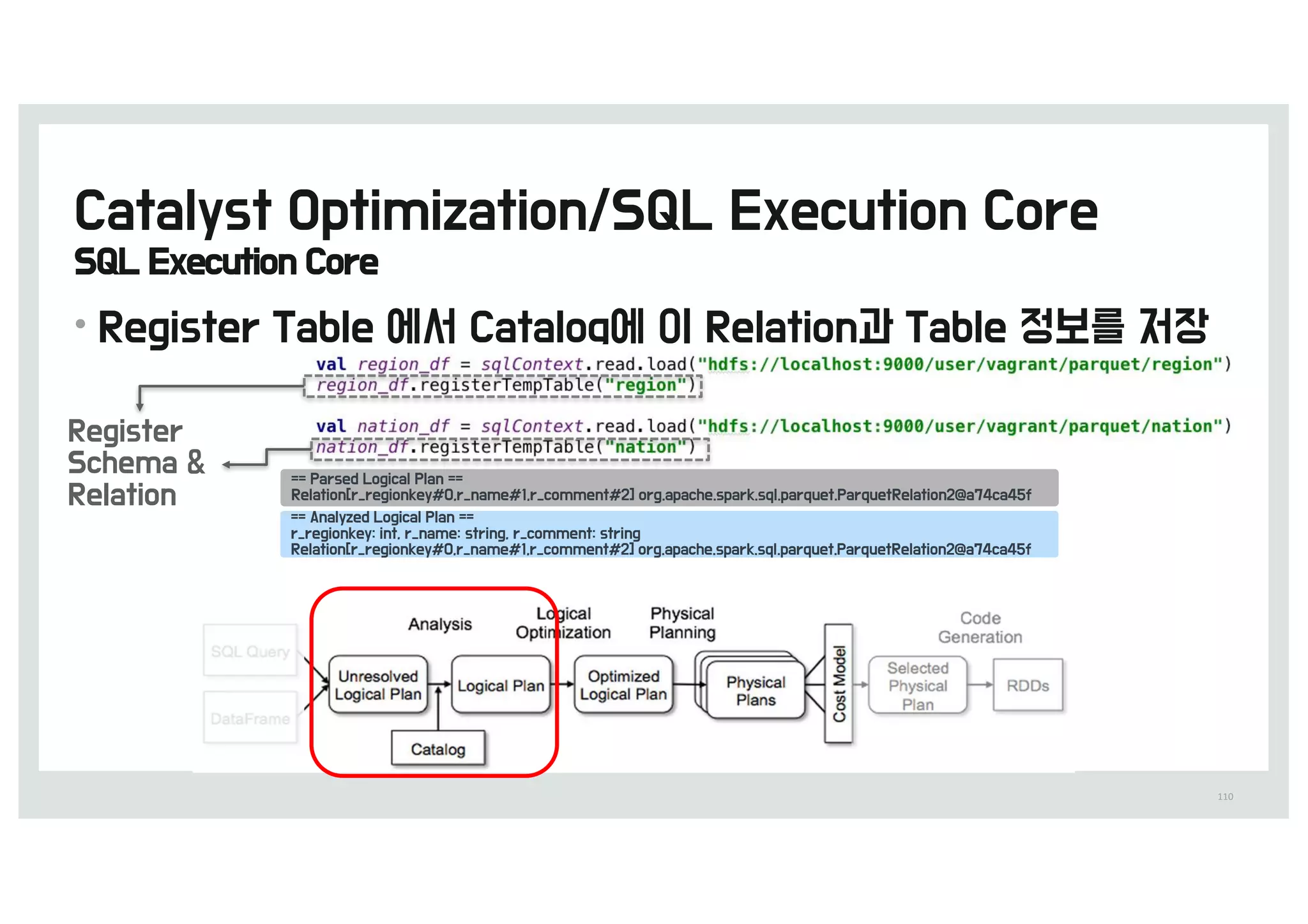
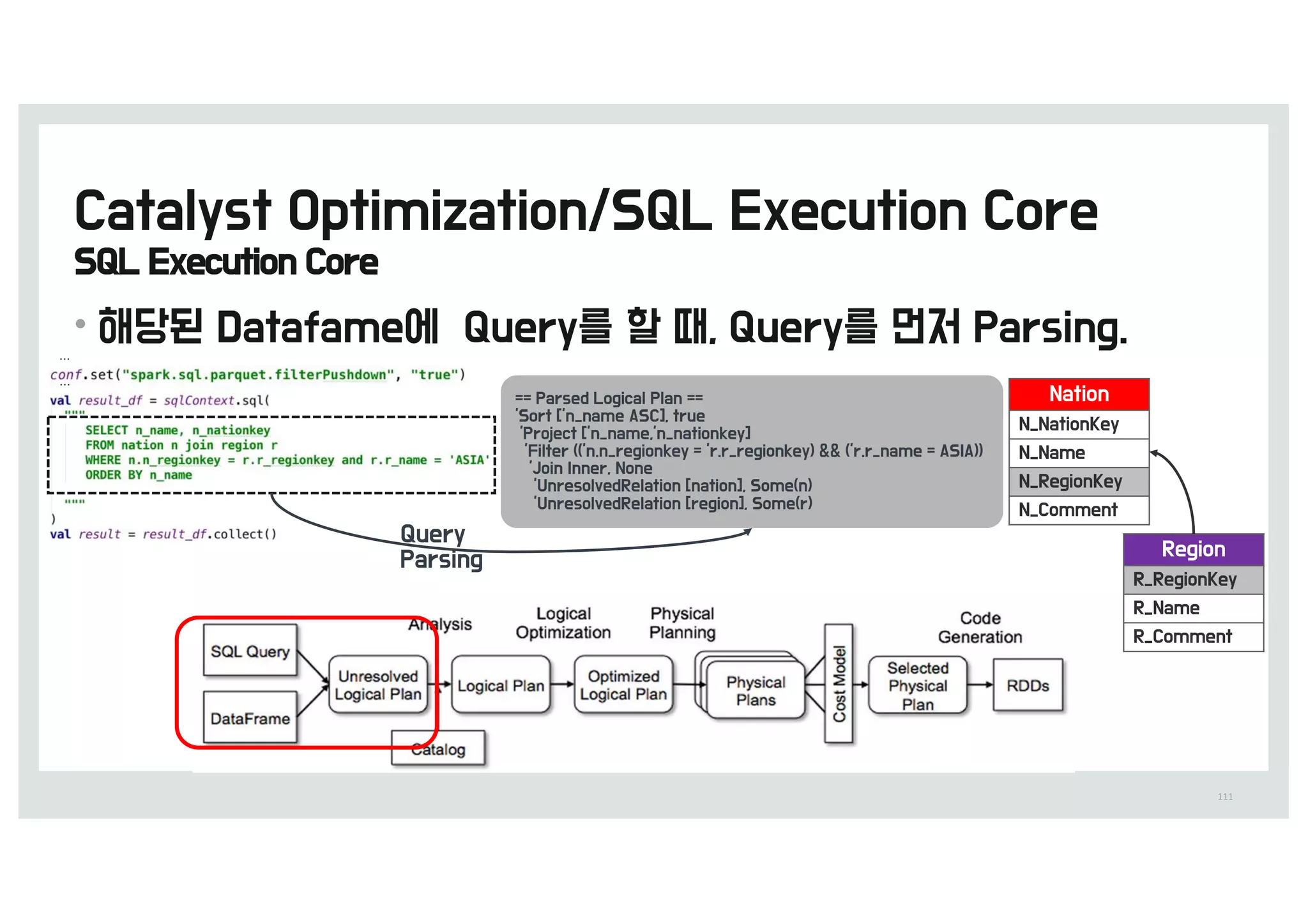
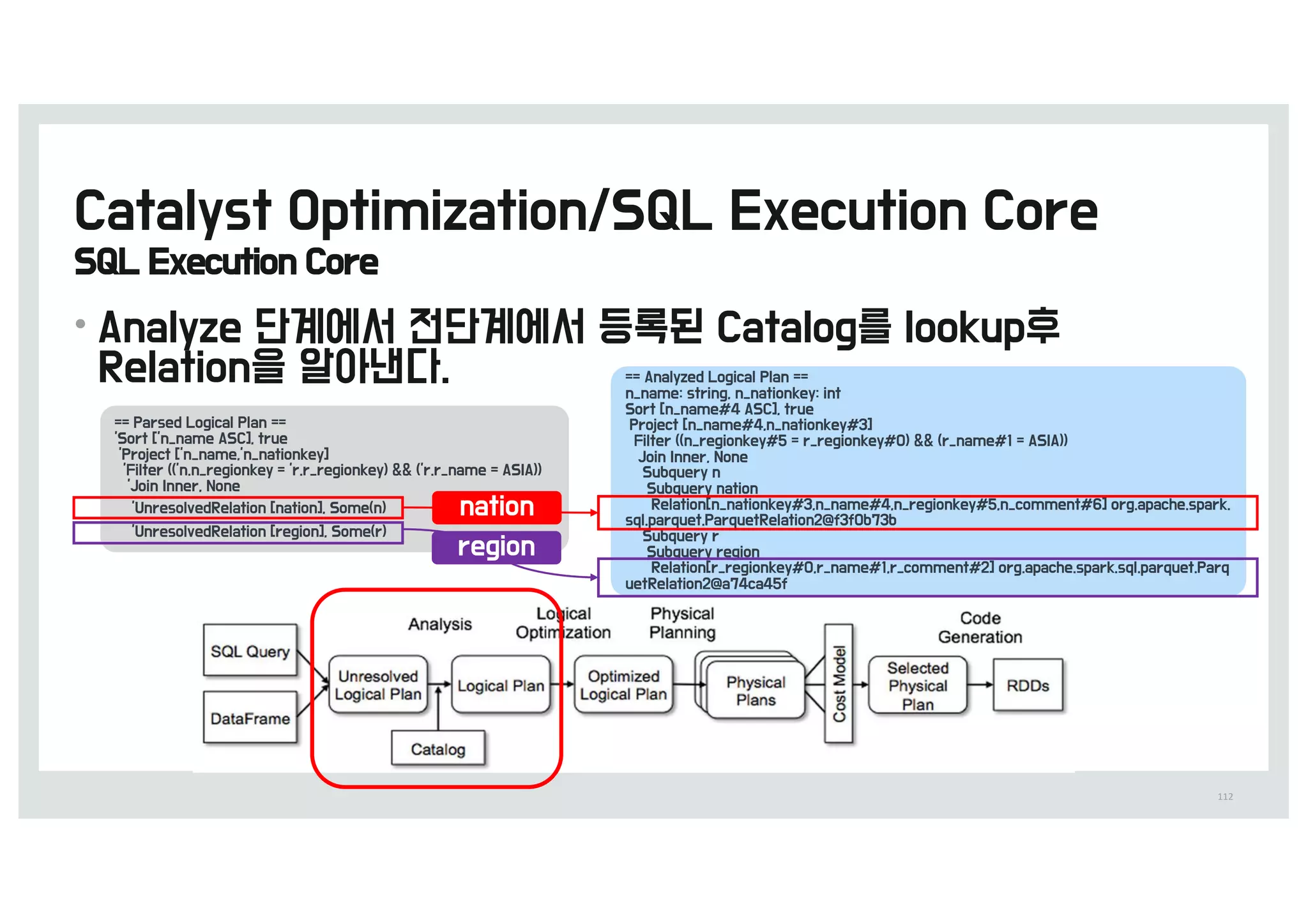




























![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)














![[225]yarn 기반의 deep learning application cluster 구축 김제민](https://cdn.slidesharecdn.com/ss_thumbnails/225yarndeeplearningapplicationcluster-161025031031-thumbnail.jpg?width=640&height=640&fit=bounds)






![[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/2251016final-171017052307-thumbnail.jpg?width=640&height=640&fit=bounds)












![NDC 2016, [슈판워] 맨땅에서 데이터 분석 시스템 만들어나가기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-2016-160429031551-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)





