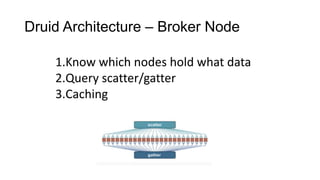
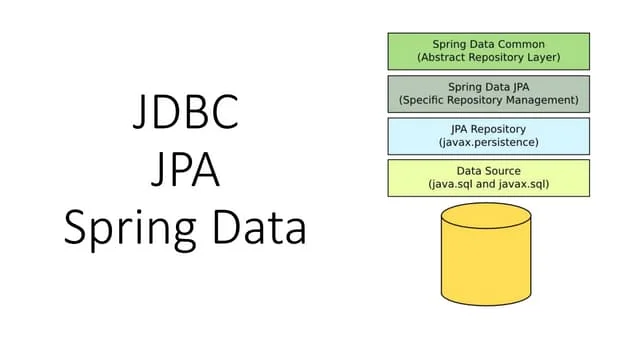
OLAP 구축의 어려움
1.데이터의 양이 굉장히 많아 질 수 있음.
2. 분석을 위해선 데이터를 slice/dice 할 수 있어야 함.
3. High dimensionality
4. 과거 데이터 뿐만 아니라 현재 업데이트 되고 있는 데이터도 함께 질의 결과에
포함되어야 함.
5. adhoc query 성능 향상을 위해 precomputing을 해둬야 하는데 이때 만들어야 하는
경우의 수가 굉장히 많음.
6. 많은 유저가 동시에 쿼리를 수행할 수 있어야 함.
5.
Druid란?
Druid is anopen-source data store designed for sub-second queries on real-time and
historical data. It is primarily used for business intelligence (OLAP) queries on event
data. Druid provides low latency (real-time) data ingestion, flexible data exploration, and
fast data aggregation. Existing Druid deployments have scaled to trillions of events and
petabytes of data. Druid is most commonly used to power user-facing analytic
applications.
Druid is a high-performance, column-oriented, distributed
database.
6.
왜 Druid인가?
1. Column-orientedData store
2. Low latency ingestion from streams
3. Adhoc query
4. Exact and approximate algorithm
5. Keep a lot of history
6. Designed for interactive applications
7. Real-time and historical supports at the same time
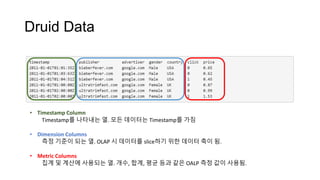
Druid Data
• TimestampColumn
Timestamp를 나타내는 열. 모든 데이터는 Timestamp를 가짐
• Dimension Columns
측정 기준이 되는 열. OLAP 시 데이터를 slice하기 위한 데이터 축이 됨.
• Metric Columns
집계 및 계산에 사용되는 열. 개수, 합계, 평균 등과 같은 OALP 측정 값이 사용됨.
14.
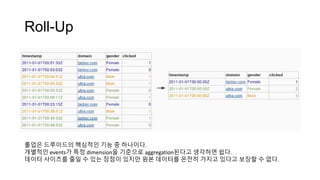
Roll-Up
롤업은 드루이드의 핵심적인기능 중 하나이다.
개별적인 events가 특정 dimension을 기준으로 aggregation된다고 생각하면 쉽다.
데이터 사이즈를 줄일 수 있는 장점이 있지만 원본 데이터를 온전히 가지고 있다고 보장할 수 없다.
15.
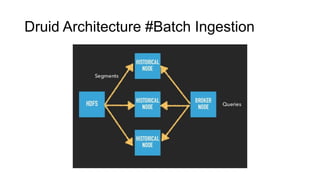
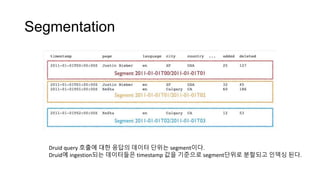
Segmentation
Druid query 호출에대한 응답의 데이터 단위는 segment이다.
Druid에 ingestion되는 데이터들은 timestamp 값을 기준으로 segment단위로 분할되고 인덱싱 된다.
16.
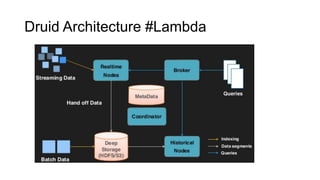
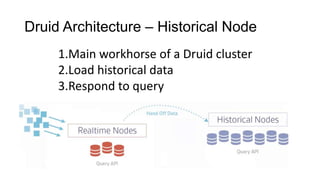
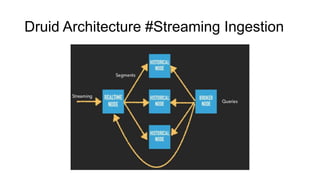
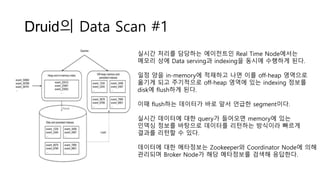
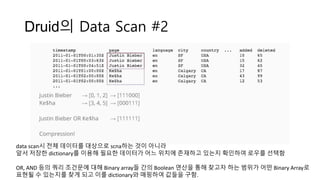
Druid의 Data Scan#1
실시간 처리를 담당하는 에이전트인 Real Time Node에서는
메모리 상에 Data serving과 indexing을 동시에 수행하게 된다.
일정 양을 in-memory에 적재하고 나면 이를 off-heap 영역으로
옮기게 되고 주기적으로 off-heap 영역에 있는 indexing 정보를
disk에 flush하게 된다.
이때 flush하는 데이터가 바로 앞서 언급한 segment이다.
실시간 데이터에 대한 query가 들어오면 memory에 있는
인덱싱 정보를 바탕으로 데이터를 리턴하는 방식이라 빠르게
결과를 리턴할 수 있다.
데이터에 대한 메타정보는 Zookeeper와 Coordinator Node에 의해
관리되며 Broker Node가 해당 메타정보를 검색해 응답한다.
17.
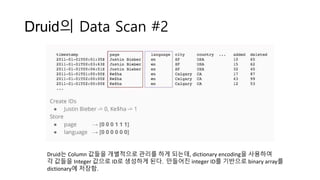
Druid의 Data Scan#2
Druid는 Column 값들을 개별적으로 관리를 하게 되는데, dictionary encoding을 사용하여
각 값들을 Integer 값으로 ID로 생성하게 된다. 만들어진 integer ID를 기반으로 binary array를
dictionary에 저장함.
18.
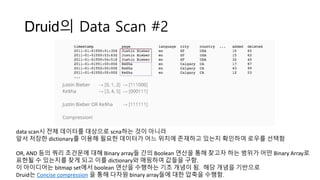
Druid의 Data Scan#2
data scan시 전체 데이터를 대상으로 scna하는 것이 아니라
앞서 저장한 dictionary를 이용해 필요한 데이터가 어느 위치에 존재하고 있는지 확인하여 로우를 선택함
OR, AND 등의 쿼리 조건문에 대해 Binary array들 간의 Boolean 연산을 통해 찾고자 하는 범위가 어떤 Binary Array로
표현될 수 있는지를 찾게 되고 이를 dictionary와 매핑하여 값들을 구함.
19.
Druid의 Data Scan#2
data scan시 전체 데이터를 대상으로 scna하는 것이 아니라
앞서 저장한 dictionary를 이용해 필요한 데이터가 어느 위치에 존재하고 있는지 확인하여 로우를 선택함
OR, AND 등의 쿼리 조건문에 대해 Binary array들 간의 Boolean 연산을 통해 찾고자 하는 범위가 어떤 Binary Array로
표현될 수 있는지를 찾게 되고 이를 dictionary와 매핑하여 값들을 구함.
이 아이디어는 bitmap set에서 boolean 연산을 수행하는 기초 개념이 됨. 해당 개념을 기반으로
Druid는 Concise compression 을 통해 다차원 binary array들에 대한 압축을 수행함.
Druid 한계점
1. YARN리소스 사용 불가
2. Join 기능을 부분적으로만 지원함(대규모 Join 사용 불가)
3. Zookeeper에 의존적임. Zookeeper가 죽더라도 메모리상에 있는 데이터들을 읽을 수 있으나 새로운 segment에
해당하는 데이터들을 읽을 수 없음.
4. Druid ingestion 시 사용하는 원본데이터를 별도로 저장하고 있어야 함.
25.
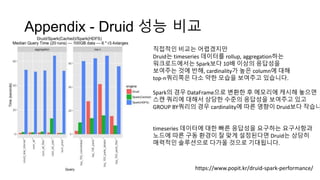
Appendix - Druid성능 비교
https://www.popit.kr/druid-spark-performance/
직접적인 비교는 어렵겠지만
Druid는 timeseries 데이터를 rollup, aggregation하는
워크로드에서는 Spark보다 10배 이상의 응답성을
보여주는 것에 반해, cardinality가 높은 column에 대해
top-n쿼리쪽은 다소 약한 모습을 보여주고 있습니다.
Spark의 경우 DataFrame으로 변환한 후 메모리에 캐시해 놓으면
스캔 쿼리에 대해서 상당한 수준의 응답성을 보여주고 있고
GROUP BY쿼리의 경우 cardinality에 따른 영향이 Druid보다 작습니
timeseries 데이터에 대한 빠른 응답성을 요구하는 요구사항과
노드에 따른 구동 환경이 잘 맞게 설정된다면 Druid는 상당히
매력적인 솔루션으로 다가올 것으로 기대됩니다.
26.
Appendix - Reference
1.Druid 논문
http://static.druid.io/docs/druid.pdf
2. Concise compression 논문
https://pdfs.semanticscholar.org/e660/5a8c82e93c0809720e0927972f23e62c94b3.pdf
3. druid 관련 한글 포스팅
https://www.popit.kr/?s=time+series+olap
4. Hive를 이용한 Druid ingestion
https://cwiki.apache.org/confluence/display/Hive/Druid+Integration
https://hortonworks.com/blog/apache-hive-druid-part-1-3/
5. Airbnb | DataEngConf SF '17 발표 영상
https://www.youtube.com/watch?v=W_Sp4jo1ACg
Editor's Notes
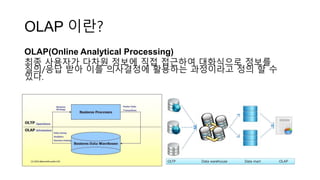
#3 OLTP 시스템은 정보를 트랜잭션단위로 수집하고 분류, 저장, 유지보수, 갱신, 검색하는 기능을 빈번히 일어나는 수행 하는 시스템들입니다.
생산한 물건을 도매시장으로 모두 옮겼듯이, OLTP에서 발생한 데이터들을 모두 DW(Data Warehouse)라는 곳에 저장 합니다. DM은 사용자의 의사결정을 지원하기 위해 축적한 많은 데이터를 사용자 관점에서 주제별로 통합하여 아래와 같이 별도의 장소에 저장해 놓은 데이터베이스 입니다.
http://www.sqler.com/498994
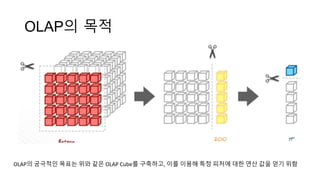
OLAP과 OLTP의 근본적인 차이점은 무엇일까요?
좋은 데이터베이스는 어딘가에 데이터를 저장해야합니다. 데이터가 저장되는 방식이 상기 데이터베이스의 가능한 사용에 크게 반영된다는 것은 놀라운 일이 아닙니다. 데이터는 대개 하드 드라이브에 저장됩니다. 하드 드라이브를 실제로 읽고 쓸 수있는 매우 넓은 용지라고 생각합시다. 읽기와 쓰기를 체계적으로 구성하여 효율성과 속도를 높일 수있는 두 가지 방법이 있습니다.
한 가지 방법 은 전화 번호부 와 같은 책을 만드는 것 입니다 . 책의 각 페이지에는 특정 사용자에 관한 정보가 저장됩니다. 이제는 특정 사용자의 정보를 쉽게 찾을 수 있습니다. 그냥 페이지로 이동! 우리는 원한다면 사용자가 어떤 페이지인지 알려주기 위해 특별 페이지를 시작할 수도 있습니다. 그러나 다른 한편으로, 우리가 얼마나 많은 돈을 사용자가 소비했는지를 찾고 싶다면 모든 페이지를 읽어야합니다. 전체 책! 행 기반의 책 / 데이터베이스 (OLTP)가 될 것입니다. 처음에는 옵션 페이지가 색인이됩니다.
큰 용지 한 장을 사용하는 또 다른 방법 은 회계 책 을 만드는 것 입니다 . 나는 회계사가 아니지만 "지출", "구매"...에 대한 페이지를 가지고 있다고 상상해보십시오. 이제는 "총 수익"을 매우 빨리 (단지 "구매" "페이지). 우리는 "나에게 상위 10 개 제품을 팔아라"와 같이 더 많은 것들을 요구할 수 있으며 여전히 만족스러운 성능을 가지고 있습니다. 그러나 이제는 특정 사용자에 대한 지출을 찾는 것이 얼마나 고통 스러운지 고려하십시오. 당신은 모든 사람들의 지출 목록 전체를 거쳐 그 특정 사용자의 항목을 걸러 내야 만 할 것입니다. 기본적으로 "전체 책"을 다시 읽습니다. 이는 열 기반 데이터베이스 (OLAP)입니다.
#4 OLTP 시스템은 정보를 트랜잭션단위로 수집하고 분류, 저장, 유지보수, 갱신, 검색하는 기능을 빈번히 일어나는 수행 하는 시스템들입니다.
생산한 물건을 도매시장으로 모두 옮겼듯이, OLTP에서 발생한 데이터들을 모두 DW(Data Warehouse)라는 곳에 저장 합니다. DM은 사용자의 의사결정을 지원하기 위해 축적한 많은 데이터를 사용자 관점에서 주제별로 통합하여 아래와 같이 별도의 장소에 저장해 놓은 데이터베이스 입니다.
http://www.sqler.com/498994
OLAP과 OLTP의 근본적인 차이점은 무엇일까요?
좋은 데이터베이스는 어딘가에 데이터를 저장해야합니다. 데이터가 저장되는 방식이 상기 데이터베이스의 가능한 사용에 크게 반영된다는 것은 놀라운 일이 아닙니다. 데이터는 대개 하드 드라이브에 저장됩니다. 하드 드라이브를 실제로 읽고 쓸 수있는 매우 넓은 용지라고 생각합시다. 읽기와 쓰기를 체계적으로 구성하여 효율성과 속도를 높일 수있는 두 가지 방법이 있습니다.
한 가지 방법 은 전화 번호부 와 같은 책을 만드는 것 입니다 . 책의 각 페이지에는 특정 사용자에 관한 정보가 저장됩니다. 이제는 특정 사용자의 정보를 쉽게 찾을 수 있습니다. 그냥 페이지로 이동! 우리는 원한다면 사용자가 어떤 페이지인지 알려주기 위해 특별 페이지를 시작할 수도 있습니다. 그러나 다른 한편으로, 우리가 얼마나 많은 돈을 사용자가 소비했는지를 찾고 싶다면 모든 페이지를 읽어야합니다. 전체 책! 행 기반의 책 / 데이터베이스 (OLTP)가 될 것입니다. 처음에는 옵션 페이지가 색인이됩니다.
큰 용지 한 장을 사용하는 또 다른 방법 은 회계 책 을 만드는 것 입니다 . 나는 회계사가 아니지만 "지출", "구매"...에 대한 페이지를 가지고 있다고 상상해보십시오. 이제는 "총 수익"을 매우 빨리 (단지 "구매" "페이지). 우리는 "나에게 상위 10 개 제품을 팔아라"와 같이 더 많은 것들을 요구할 수 있으며 여전히 만족스러운 성능을 가지고 있습니다. 그러나 이제는 특정 사용자에 대한 지출을 찾는 것이 얼마나 고통 스러운지 고려하십시오. 당신은 모든 사람들의 지출 목록 전체를 거쳐 그 특정 사용자의 항목을 걸러 내야 만 할 것입니다. 기본적으로 "전체 책"을 다시 읽습니다. 이는 열 기반 데이터베이스 (OLAP)입니다.
#5 OLTP 시스템은 정보를 트랜잭션단위로 수집하고 분류, 저장, 유지보수, 갱신, 검색하는 기능을 빈번히 일어나는 수행 하는 시스템들입니다.
생산한 물건을 도매시장으로 모두 옮겼듯이, OLTP에서 발생한 데이터들을 모두 DW(Data Warehouse)라는 곳에 저장 합니다. DM은 사용자의 의사결정을 지원하기 위해 축적한 많은 데이터를 사용자 관점에서 주제별로 통합하여 아래와 같이 별도의 장소에 저장해 놓은 데이터베이스 입니다.
http://www.sqler.com/498994
OLAP과 OLTP의 근본적인 차이점은 무엇일까요?
좋은 데이터베이스는 어딘가에 데이터를 저장해야합니다. 데이터가 저장되는 방식이 상기 데이터베이스의 가능한 사용에 크게 반영된다는 것은 놀라운 일이 아닙니다. 데이터는 대개 하드 드라이브에 저장됩니다. 하드 드라이브를 실제로 읽고 쓸 수있는 매우 넓은 용지라고 생각합시다. 읽기와 쓰기를 체계적으로 구성하여 효율성과 속도를 높일 수있는 두 가지 방법이 있습니다.
한 가지 방법 은 전화 번호부 와 같은 책을 만드는 것 입니다 . 책의 각 페이지에는 특정 사용자에 관한 정보가 저장됩니다. 이제는 특정 사용자의 정보를 쉽게 찾을 수 있습니다. 그냥 페이지로 이동! 우리는 원한다면 사용자가 어떤 페이지인지 알려주기 위해 특별 페이지를 시작할 수도 있습니다. 그러나 다른 한편으로, 우리가 얼마나 많은 돈을 사용자가 소비했는지를 찾고 싶다면 모든 페이지를 읽어야합니다. 전체 책! 행 기반의 책 / 데이터베이스 (OLTP)가 될 것입니다. 처음에는 옵션 페이지가 색인이됩니다.
큰 용지 한 장을 사용하는 또 다른 방법 은 회계 책 을 만드는 것 입니다 . 나는 회계사가 아니지만 "지출", "구매"...에 대한 페이지를 가지고 있다고 상상해보십시오. 이제는 "총 수익"을 매우 빨리 (단지 "구매" "페이지). 우리는 "나에게 상위 10 개 제품을 팔아라"와 같이 더 많은 것들을 요구할 수 있으며 여전히 만족스러운 성능을 가지고 있습니다. 그러나 이제는 특정 사용자에 대한 지출을 찾는 것이 얼마나 고통 스러운지 고려하십시오. 당신은 모든 사람들의 지출 목록 전체를 거쳐 그 특정 사용자의 항목을 걸러 내야 만 할 것입니다. 기본적으로 "전체 책"을 다시 읽습니다. 이는 열 기반 데이터베이스 (OLAP)입니다.
#7 OLTP 시스템은 정보를 트랜잭션단위로 수집하고 분류, 저장, 유지보수, 갱신, 검색하는 기능을 빈번히 일어나는 수행 하는 시스템들입니다.
생산한 물건을 도매시장으로 모두 옮겼듯이, OLTP에서 발생한 데이터들을 모두 DW(Data Warehouse)라는 곳에 저장 합니다. DM은 사용자의 의사결정을 지원하기 위해 축적한 많은 데이터를 사용자 관점에서 주제별로 통합하여 아래와 같이 별도의 장소에 저장해 놓은 데이터베이스 입니다.
http://www.sqler.com/498994
OLAP과 OLTP의 근본적인 차이점은 무엇일까요?
좋은 데이터베이스는 어딘가에 데이터를 저장해야합니다. 데이터가 저장되는 방식이 상기 데이터베이스의 가능한 사용에 크게 반영된다는 것은 놀라운 일이 아닙니다. 데이터는 대개 하드 드라이브에 저장됩니다. 하드 드라이브를 실제로 읽고 쓸 수있는 매우 넓은 용지라고 생각합시다. 읽기와 쓰기를 체계적으로 구성하여 효율성과 속도를 높일 수있는 두 가지 방법이 있습니다.
한 가지 방법 은 전화 번호부 와 같은 책을 만드는 것 입니다 . 책의 각 페이지에는 특정 사용자에 관한 정보가 저장됩니다. 이제는 특정 사용자의 정보를 쉽게 찾을 수 있습니다. 그냥 페이지로 이동! 우리는 원한다면 사용자가 어떤 페이지인지 알려주기 위해 특별 페이지를 시작할 수도 있습니다. 그러나 다른 한편으로, 우리가 얼마나 많은 돈을 사용자가 소비했는지를 찾고 싶다면 모든 페이지를 읽어야합니다. 전체 책! 행 기반의 책 / 데이터베이스 (OLTP)가 될 것입니다. 처음에는 옵션 페이지가 색인이됩니다.
큰 용지 한 장을 사용하는 또 다른 방법 은 회계 책 을 만드는 것 입니다 . 나는 회계사가 아니지만 "지출", "구매"...에 대한 페이지를 가지고 있다고 상상해보십시오. 이제는 "총 수익"을 매우 빨리 (단지 "구매" "페이지). 우리는 "나에게 상위 10 개 제품을 팔아라"와 같이 더 많은 것들을 요구할 수 있으며 여전히 만족스러운 성능을 가지고 있습니다. 그러나 이제는 특정 사용자에 대한 지출을 찾는 것이 얼마나 고통 스러운지 고려하십시오. 당신은 모든 사람들의 지출 목록 전체를 거쳐 그 특정 사용자의 항목을 걸러 내야 만 할 것입니다. 기본적으로 "전체 책"을 다시 읽습니다. 이는 열 기반 데이터베이스 (OLAP)입니다.
#14 OLTP 시스템은 정보를 트랜잭션단위로 수집하고 분류, 저장, 유지보수, 갱신, 검색하는 기능을 빈번히 일어나는 수행 하는 시스템들입니다.
생산한 물건을 도매시장으로 모두 옮겼듯이, OLTP에서 발생한 데이터들을 모두 DW(Data Warehouse)라는 곳에 저장 합니다. DM은 사용자의 의사결정을 지원하기 위해 축적한 많은 데이터를 사용자 관점에서 주제별로 통합하여 아래와 같이 별도의 장소에 저장해 놓은 데이터베이스 입니다.
http://www.sqler.com/498994
OLAP과 OLTP의 근본적인 차이점은 무엇일까요?
좋은 데이터베이스는 어딘가에 데이터를 저장해야합니다. 데이터가 저장되는 방식이 상기 데이터베이스의 가능한 사용에 크게 반영된다는 것은 놀라운 일이 아닙니다. 데이터는 대개 하드 드라이브에 저장됩니다. 하드 드라이브를 실제로 읽고 쓸 수있는 매우 넓은 용지라고 생각합시다. 읽기와 쓰기를 체계적으로 구성하여 효율성과 속도를 높일 수있는 두 가지 방법이 있습니다.
한 가지 방법 은 전화 번호부 와 같은 책을 만드는 것 입니다 . 책의 각 페이지에는 특정 사용자에 관한 정보가 저장됩니다. 이제는 특정 사용자의 정보를 쉽게 찾을 수 있습니다. 그냥 페이지로 이동! 우리는 원한다면 사용자가 어떤 페이지인지 알려주기 위해 특별 페이지를 시작할 수도 있습니다. 그러나 다른 한편으로, 우리가 얼마나 많은 돈을 사용자가 소비했는지를 찾고 싶다면 모든 페이지를 읽어야합니다. 전체 책! 행 기반의 책 / 데이터베이스 (OLTP)가 될 것입니다. 처음에는 옵션 페이지가 색인이됩니다.
큰 용지 한 장을 사용하는 또 다른 방법 은 회계 책 을 만드는 것 입니다 . 나는 회계사가 아니지만 "지출", "구매"...에 대한 페이지를 가지고 있다고 상상해보십시오. 이제는 "총 수익"을 매우 빨리 (단지 "구매" "페이지). 우리는 "나에게 상위 10 개 제품을 팔아라"와 같이 더 많은 것들을 요구할 수 있으며 여전히 만족스러운 성능을 가지고 있습니다. 그러나 이제는 특정 사용자에 대한 지출을 찾는 것이 얼마나 고통 스러운지 고려하십시오. 당신은 모든 사람들의 지출 목록 전체를 거쳐 그 특정 사용자의 항목을 걸러 내야 만 할 것입니다. 기본적으로 "전체 책"을 다시 읽습니다. 이는 열 기반 데이터베이스 (OLAP)입니다.
#15 OLTP 시스템은 정보를 트랜잭션단위로 수집하고 분류, 저장, 유지보수, 갱신, 검색하는 기능을 빈번히 일어나는 수행 하는 시스템들입니다.
생산한 물건을 도매시장으로 모두 옮겼듯이, OLTP에서 발생한 데이터들을 모두 DW(Data Warehouse)라는 곳에 저장 합니다. DM은 사용자의 의사결정을 지원하기 위해 축적한 많은 데이터를 사용자 관점에서 주제별로 통합하여 아래와 같이 별도의 장소에 저장해 놓은 데이터베이스 입니다.
http://www.sqler.com/498994
OLAP과 OLTP의 근본적인 차이점은 무엇일까요?
좋은 데이터베이스는 어딘가에 데이터를 저장해야합니다. 데이터가 저장되는 방식이 상기 데이터베이스의 가능한 사용에 크게 반영된다는 것은 놀라운 일이 아닙니다. 데이터는 대개 하드 드라이브에 저장됩니다. 하드 드라이브를 실제로 읽고 쓸 수있는 매우 넓은 용지라고 생각합시다. 읽기와 쓰기를 체계적으로 구성하여 효율성과 속도를 높일 수있는 두 가지 방법이 있습니다.
한 가지 방법 은 전화 번호부 와 같은 책을 만드는 것 입니다 . 책의 각 페이지에는 특정 사용자에 관한 정보가 저장됩니다. 이제는 특정 사용자의 정보를 쉽게 찾을 수 있습니다. 그냥 페이지로 이동! 우리는 원한다면 사용자가 어떤 페이지인지 알려주기 위해 특별 페이지를 시작할 수도 있습니다. 그러나 다른 한편으로, 우리가 얼마나 많은 돈을 사용자가 소비했는지를 찾고 싶다면 모든 페이지를 읽어야합니다. 전체 책! 행 기반의 책 / 데이터베이스 (OLTP)가 될 것입니다. 처음에는 옵션 페이지가 색인이됩니다.
큰 용지 한 장을 사용하는 또 다른 방법 은 회계 책 을 만드는 것 입니다 . 나는 회계사가 아니지만 "지출", "구매"...에 대한 페이지를 가지고 있다고 상상해보십시오. 이제는 "총 수익"을 매우 빨리 (단지 "구매" "페이지). 우리는 "나에게 상위 10 개 제품을 팔아라"와 같이 더 많은 것들을 요구할 수 있으며 여전히 만족스러운 성능을 가지고 있습니다. 그러나 이제는 특정 사용자에 대한 지출을 찾는 것이 얼마나 고통 스러운지 고려하십시오. 당신은 모든 사람들의 지출 목록 전체를 거쳐 그 특정 사용자의 항목을 걸러 내야 만 할 것입니다. 기본적으로 "전체 책"을 다시 읽습니다. 이는 열 기반 데이터베이스 (OLAP)입니다.