Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Sang-bae Lim
PDF, PPTX
1,274 views
Cloudera session seoul - Spark bootcamp
클라우데라 세션 스파크 교육자료 Cloudera Session Seoul Spark bootcamp
Technology
◦
Related topics:
Data Analysis Insights
•
Apache Spark
•
Read more
10
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 47
2
/ 47
3
/ 47
4
/ 47
5
/ 47
6
/ 47
7
/ 47
8
/ 47
9
/ 47
10
/ 47
11
/ 47
12
/ 47
13
/ 47
14
/ 47
15
/ 47
16
/ 47
17
/ 47
18
/ 47
19
/ 47
20
/ 47
21
/ 47
22
/ 47
23
/ 47
24
/ 47
25
/ 47
26
/ 47
27
/ 47
28
/ 47
29
/ 47
30
/ 47
31
/ 47
32
/ 47
33
/ 47
34
/ 47
35
/ 47
36
/ 47
37
/ 47
38
/ 47
39
/ 47
40
/ 47
41
/ 47
42
/ 47
43
/ 47
44
/ 47
45
/ 47
46
/ 47
47
/ 47
More Related Content
PPTX
Apache spark 소개 및 실습
by
동현 강
PDF
Spark Day 2017 Machine Learning & Deep Learning With Spark
by
SangHoon Lee
PDF
Spark_Overview_qna
by
현철 박
PPTX
Hadoop cluster os_tuning_v1.0_20170106_mobile
by
상연 최
PPTX
[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제
by
NAVER D2
PPTX
Spark machine learning & deep learning
by
hoondong kim
PDF
왜 Spark 와 infinispan 왜 같이 쓰지
by
Un Gi Jung
PDF
Spark Day 2017@Seoul(Spark Bootcamp)
by
Sang-bae Lim
Apache spark 소개 및 실습
by
동현 강
Spark Day 2017 Machine Learning & Deep Learning With Spark
by
SangHoon Lee
Spark_Overview_qna
by
현철 박
Hadoop cluster os_tuning_v1.0_20170106_mobile
by
상연 최
[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제
by
NAVER D2
Spark machine learning & deep learning
by
hoondong kim
왜 Spark 와 infinispan 왜 같이 쓰지
by
Un Gi Jung
Spark Day 2017@Seoul(Spark Bootcamp)
by
Sang-bae Lim
What's hot
PDF
Zeppelin(Spark)으로 데이터 분석하기
by
SangWoo Kim
PDF
[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기
by
NAVER D2
PPTX
(Apacje Spark)아파치 스파크 개요, 소개, 스파크란?
by
탑크리에듀(구로디지털단지역3번출구 2분거리)
PPTX
2.apache spark 실습
by
동현 강
PDF
Spark 소개 2부
by
Jinho Yoo
PDF
Spark + S3 + R3를 이용한 데이터 분석 시스템 만들기
by
AWSKRUG - AWS한국사용자모임
PDF
[NDC 2018] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산처리 자동화 인프라 구축
by
Juhong Park
PDF
Spark로 알아보는 빅데이터 처리
by
Jeong-gyu Kim
PDF
[225]yarn 기반의 deep learning application cluster 구축 김제민
by
NAVER D2
PPTX
분산저장시스템 개발에 대한 12가지 이야기
by
NAVER D2
PPTX
Apache Spark 입문에서 머신러닝까지
by
Donam Kim
PPTX
빅데이터 구축 사례
by
Taehyeon Oh
PDF
Zeppelin notebook 만들기
by
Soo-Kyung Choi
PDF
인공지능추천시스템 airs개발기_모델링과시스템
by
NAVER D2
PDF
Spark & Zeppelin을 활용한 머신러닝 실전 적용기
by
Taejun Kim
PDF
Spark overview 이상훈(SK C&C)_스파크 사용자 모임_20141106
by
SangHoon Lee
PDF
Spark은 왜 이렇게 유명해지고 있을까?
by
KSLUG
PDF
스타트업 사례로 본 로그 데이터 분석 : Tajo on AWS
by
Matthew (정재화)
PDF
하둡 알아보기(Learn about Hadoop basic), NetApp FAS NFS Connector for Hadoop
by
SeungYong Baek
PDF
Auto Scalable 한 Deep Learning Production 을 위한 AI Serving Infra 구성 및 AI DevOps...
by
hoondong kim
Zeppelin(Spark)으로 데이터 분석하기
by
SangWoo Kim
[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기
by
NAVER D2
(Apacje Spark)아파치 스파크 개요, 소개, 스파크란?
by
탑크리에듀(구로디지털단지역3번출구 2분거리)
2.apache spark 실습
by
동현 강
Spark 소개 2부
by
Jinho Yoo
Spark + S3 + R3를 이용한 데이터 분석 시스템 만들기
by
AWSKRUG - AWS한국사용자모임
[NDC 2018] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산처리 자동화 인프라 구축
by
Juhong Park
Spark로 알아보는 빅데이터 처리
by
Jeong-gyu Kim
[225]yarn 기반의 deep learning application cluster 구축 김제민
by
NAVER D2
분산저장시스템 개발에 대한 12가지 이야기
by
NAVER D2
Apache Spark 입문에서 머신러닝까지
by
Donam Kim
빅데이터 구축 사례
by
Taehyeon Oh
Zeppelin notebook 만들기
by
Soo-Kyung Choi
인공지능추천시스템 airs개발기_모델링과시스템
by
NAVER D2
Spark & Zeppelin을 활용한 머신러닝 실전 적용기
by
Taejun Kim
Spark overview 이상훈(SK C&C)_스파크 사용자 모임_20141106
by
SangHoon Lee
Spark은 왜 이렇게 유명해지고 있을까?
by
KSLUG
스타트업 사례로 본 로그 데이터 분석 : Tajo on AWS
by
Matthew (정재화)
하둡 알아보기(Learn about Hadoop basic), NetApp FAS NFS Connector for Hadoop
by
SeungYong Baek
Auto Scalable 한 Deep Learning Production 을 위한 AI Serving Infra 구성 및 AI DevOps...
by
hoondong kim
Viewers also liked
PDF
AWS와 Open Source - 윤석찬 (OSS개발자 그룹)
by
Amazon Web Services Korea
PDF
대용량 로그분석 Bigquery로 간단히 사용하기 (20170215 T아카데미)
by
Jaikwang Lee
PPTX
Gruter TECHDAY 2014 MelOn BigData
by
Gruter
PDF
[SSA] 01.bigdata database technology (2014.02.05)
by
Steve Min
PPTX
Bigdata
by
Jongmyoung Kim
PPTX
Ethics of Big Data
by
Matti Vesala
PDF
Sdpc 포트폴리오모음(lr)
by
saewoo me
PDF
기술8기 2조
by
Kangwook Lee
PDF
Hnavi-HDFS based log aggregater with HDFS Browser
by
LINE+
PDF
Enterprise conference 2013 Microsoft BigData 사례발표자료
by
환태 김
PDF
2017대선 빅데이터 분석
by
지승 한
PDF
2017 tensor flow dev summit
by
Tae Young Lee
PPTX
It trends 2015 3 q-totoro4
by
SangSu Jeon
PPTX
빅데이터와 로봇 (Big Data in Robotics)
by
Hong-Seok Kim
PPTX
It Trends 2015-2H-totoro4
by
SangSu Jeon
PDF
New ICT Trends in CES 2016
by
Jonathan Jeon
PDF
빅데이터 환경에서 지능형 로그 관리 플랫폼으로 진화하는 보안 정보&이벤트 관리 동향
by
Donghan Kim
AWS와 Open Source - 윤석찬 (OSS개발자 그룹)
by
Amazon Web Services Korea
대용량 로그분석 Bigquery로 간단히 사용하기 (20170215 T아카데미)
by
Jaikwang Lee
Gruter TECHDAY 2014 MelOn BigData
by
Gruter
[SSA] 01.bigdata database technology (2014.02.05)
by
Steve Min
Bigdata
by
Jongmyoung Kim
Ethics of Big Data
by
Matti Vesala
Sdpc 포트폴리오모음(lr)
by
saewoo me
기술8기 2조
by
Kangwook Lee
Hnavi-HDFS based log aggregater with HDFS Browser
by
LINE+
Enterprise conference 2013 Microsoft BigData 사례발표자료
by
환태 김
2017대선 빅데이터 분석
by
지승 한
2017 tensor flow dev summit
by
Tae Young Lee
It trends 2015 3 q-totoro4
by
SangSu Jeon
빅데이터와 로봇 (Big Data in Robotics)
by
Hong-Seok Kim
It Trends 2015-2H-totoro4
by
SangSu Jeon
New ICT Trends in CES 2016
by
Jonathan Jeon
빅데이터 환경에서 지능형 로그 관리 플랫폼으로 진화하는 보안 정보&이벤트 관리 동향
by
Donghan Kim
Similar to Cloudera session seoul - Spark bootcamp
PDF
sparklyr을 활용한 R 분산 처리
by
Sang-bae Lim
PDF
데브시스터즈 데이터 레이크 구축 이야기 : Data Lake architecture case study (박주홍 데이터 분석 및 인프라 팀...
by
Amazon Web Services Korea
PDF
빅데이터 기술 현황과 시장 전망(2014)
by
Channy Yun
PDF
Apache Spark
by
ssuser09ca0c1
PDF
Learning spark ch1-2
by
HyeonSeok Choi
PDF
SPARK SQL
by
Juhui Park
PDF
RUCK 2017 - 강병엽 - Spark와 R을 연동한 빅데이터 분석
by
r-kor
PDF
고성능 빅데이터 수집 및 분석 솔루션 - 티맥스소프트 허승재 팀장
by
eungjin cho
PDF
Spark 의 핵심은 무엇인가? RDD! (RDD paper review)
by
Yongho Ha
PDF
『9가지 사례로 익히는 고급 스파크 분석(2판) 』 맛보기
by
복연 이
PPT
빅데이터 기본개념
by
현주 유
PPTX
Spark sql
by
동현 강
PPTX
What is spark
by
jaeho kang
PPTX
Spark streaming tutorial
by
Minho Kim
PDF
Flamingo (FEA) Spark Designer
by
BYOUNG GON KIM
PPTX
Start spark
by
ssuser31a17d
PPTX
Hybrid & Logical Data Warehouse
by
Heungsoon Yang
PPT
Big Data Overview
by
Keeyong Han
PPTX
Hadoop설명
by
Ji Hoon Lee
PDF
『9가지 사례로 익히는 고급 스파크 분석』 - 맛보기
by
복연 이
sparklyr을 활용한 R 분산 처리
by
Sang-bae Lim
데브시스터즈 데이터 레이크 구축 이야기 : Data Lake architecture case study (박주홍 데이터 분석 및 인프라 팀...
by
Amazon Web Services Korea
빅데이터 기술 현황과 시장 전망(2014)
by
Channy Yun
Apache Spark
by
ssuser09ca0c1
Learning spark ch1-2
by
HyeonSeok Choi
SPARK SQL
by
Juhui Park
RUCK 2017 - 강병엽 - Spark와 R을 연동한 빅데이터 분석
by
r-kor
고성능 빅데이터 수집 및 분석 솔루션 - 티맥스소프트 허승재 팀장
by
eungjin cho
Spark 의 핵심은 무엇인가? RDD! (RDD paper review)
by
Yongho Ha
『9가지 사례로 익히는 고급 스파크 분석(2판) 』 맛보기
by
복연 이
빅데이터 기본개념
by
현주 유
Spark sql
by
동현 강
What is spark
by
jaeho kang
Spark streaming tutorial
by
Minho Kim
Flamingo (FEA) Spark Designer
by
BYOUNG GON KIM
Start spark
by
ssuser31a17d
Hybrid & Logical Data Warehouse
by
Heungsoon Yang
Big Data Overview
by
Keeyong Han
Hadoop설명
by
Ji Hoon Lee
『9가지 사례로 익히는 고급 스파크 분석』 - 맛보기
by
복연 이
Cloudera session seoul - Spark bootcamp
1.
1© Cloudera, Inc.
All rights reserved. SEOUL Spark Bootcamp 2017 임상배 부장(sangbae Lim)| Principal Sales Consultant Data Analytics Team/Oracle July 11, 2017 Cloudera Sessions
2.
2© Cloudera, Inc.
All rights reserved. • 스파크 개요 • 스파크 아키텍처 • 스파크의 핵심 RDD • 스파크 SQL ü HOL : SF Open Data 탐색 • 스파크 Streaming • FAQ로 정리해보는 스파크 Agenda 30 mins
3.
3© Cloudera, Inc.
All rights reserved. • 개발자(C/S, Web) -> SI 일꾼-> Vendor 일꾼(Sybase-SAP, Oracle) • 현재는 Oracle에서 빅데이터 관련 PoC, BMT, 기술 세미나, 아키텍처 관련 업무를 하고 있음 • 데이터에 관련된 다양한 기술에 관심(하둡, 스파크, R, TensorFlow) • 스사모(스파크 사용자 모임)는 2014년 10월 부터 활동 • 하둡 완벽 가이드(4판) 번역 참여 Who am I?
4.
4© Cloudera, Inc.
All rights reserved. • Spark Bootcamp는 스파크 초보자를 위한 시간입니다. • Spark Bootcamp는 스파크 코어, 스파크 SQL에 대해 다룹니다(지금은 모르셔도 됩니다). • 간단한 데모를 통해 스파크를 활용하는 방법을 설명합니다. • 슬라이드 위치 : https://www.slideshare.net/SangbaeLim/ Spark Bootcamp에서 설명할 범위
5.
5© Cloudera, Inc.
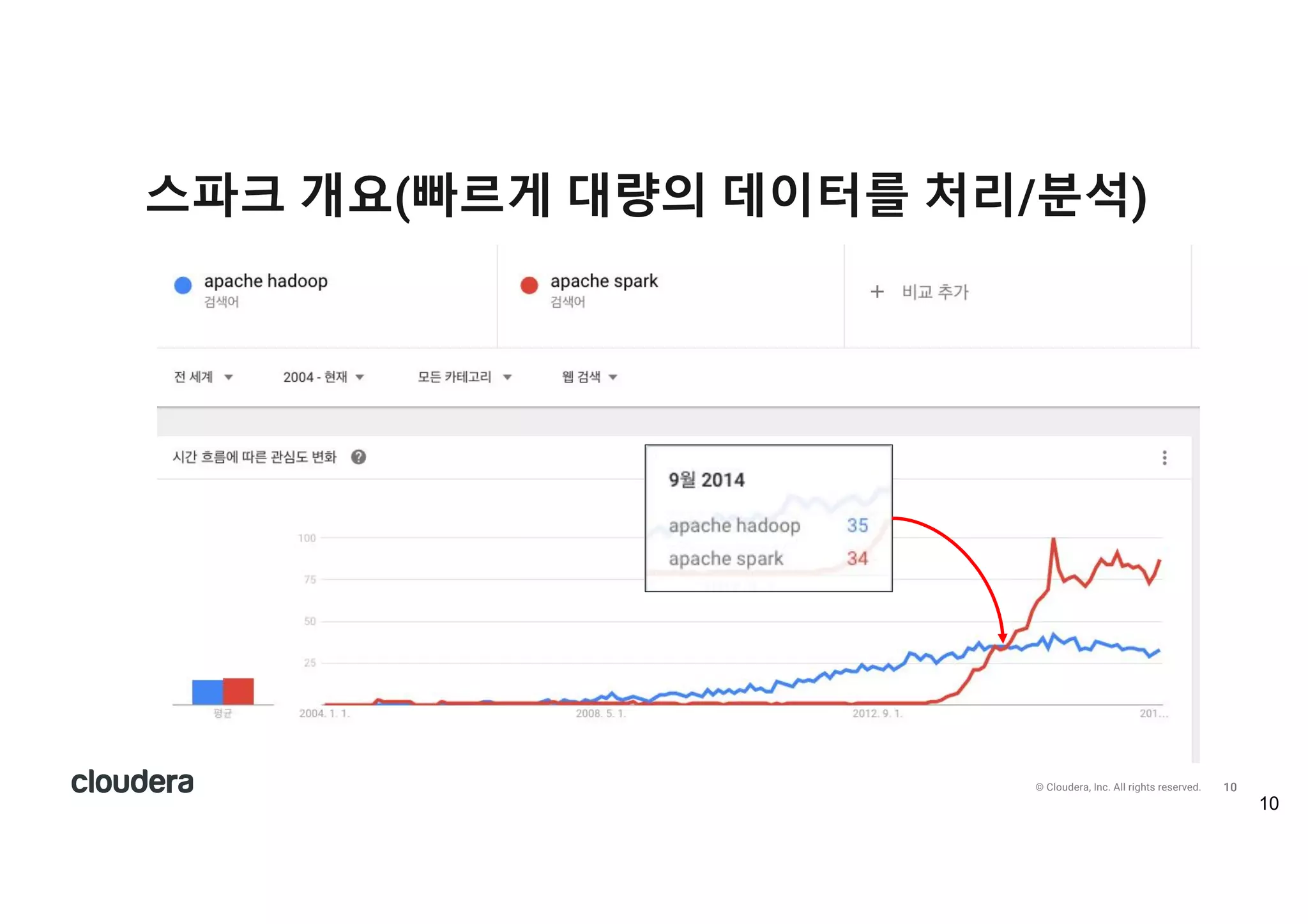
All rights reserved. • 데이터 엔지니어 : 자유롭게 데이터를 처리하고 싶다. • 데이터 분석가 : 자유롭게 데이터를 분석하고 싶다. • 나도 분석가, 나도 엔지니어 • 빅데이터 처리/분석의 표준 엔진 스파크를 왜 배워야 하나? 출처 : 전자신문 2017.01.17 http://www.etnews.com/20170117000247
6.
6© Cloudera, Inc.
All rights reserved. 스파크 개요
7.
7© Cloudera, Inc.
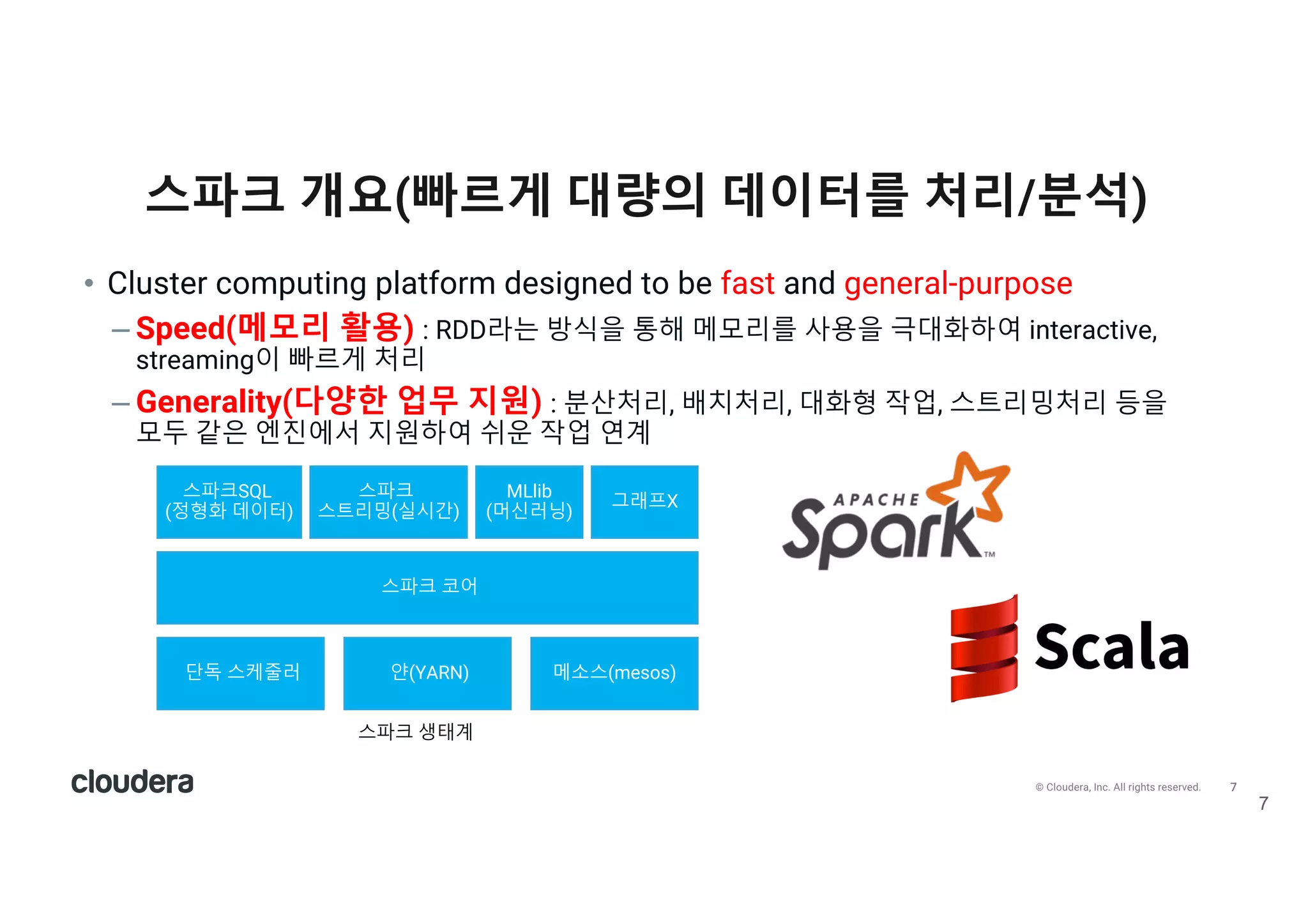
All rights reserved. 스파크 개요(빠르게 대량의 데이터를 처리/분석) 7 • Cluster computing platform designed to be fast and general-purpose – Speed(메모리 활용) : RDD라는 방식을 통해 메모리를 사용을 극대화하여 interactive, streaming이 빠르게 처리 – Generality(다양한 업무 지원) : 분산처리, 배치처리, 대화형 작업, 스트리밍처리 등을 모두 같은 엔진에서 지원하여 쉬운 작업 연계 스파크 코어 단독 스케줄러 얀(YARN) 메소스(mesos) 스파크SQL (정형화 데이터) 스파크 스트리밍(실시간) MLlib (머신러닝) 그래프X 스파크 생태계
8.
8© Cloudera, Inc.
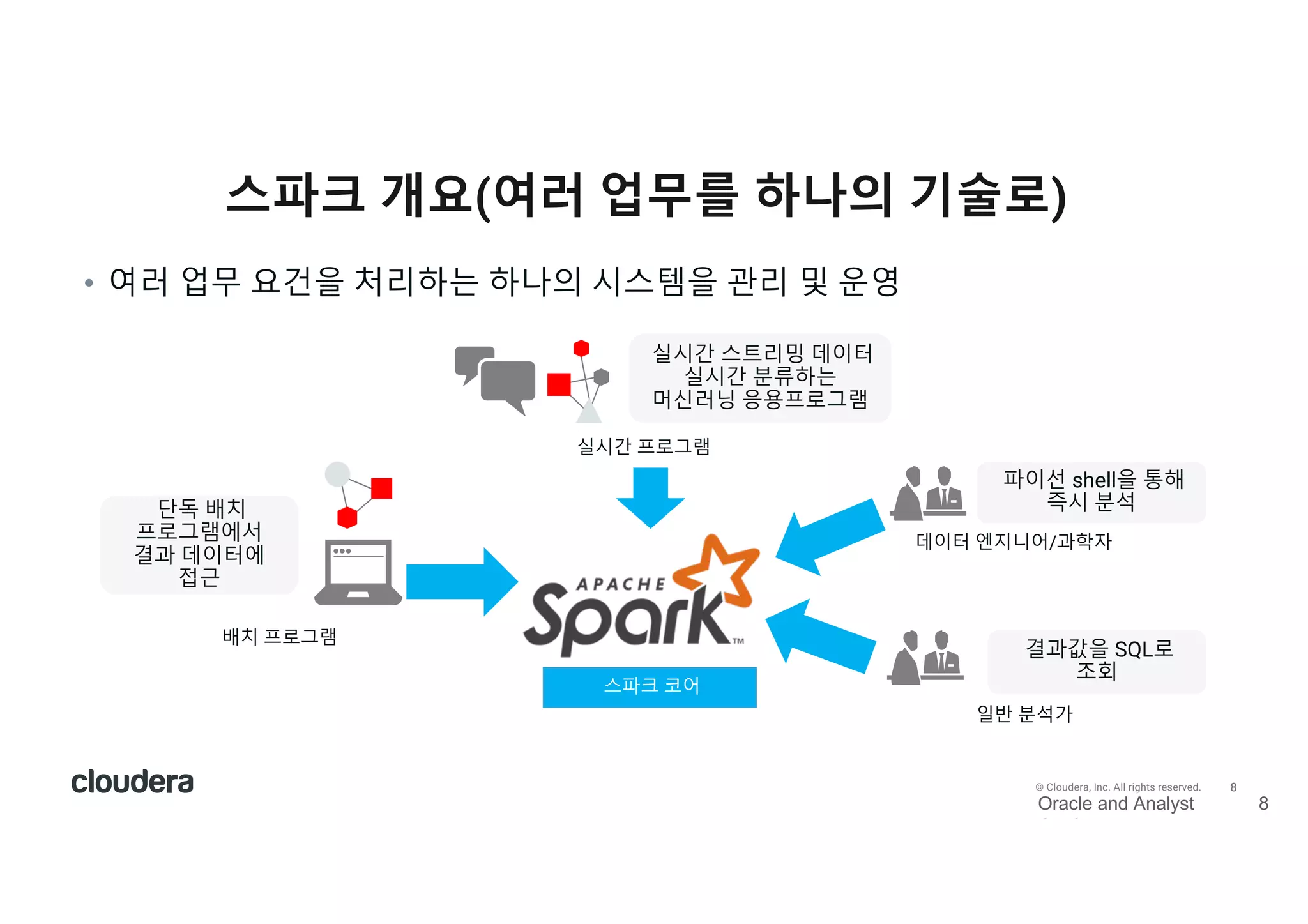
All rights reserved. 스파크 개요(여러 업무를 하나의 기술로) • 여러 업무 요건을 처리하는 하나의 시스템을 관리 및 운영 실시간 스트리밍 데이터 실시간 분류하는 머신러닝 응용프로그램 결과값을 SQL로 조회 단독 배치 프로그램에서 결과 데이터에 접근 파이선 shell을 통해 즉시 분석 데이터 엔지니어/과학자 일반 분석가 실시간 프로그램 배치 프로그램 스파크 코어
9.
9© Cloudera, Inc.
All rights reserved. Spark 1.0.0(2014.05)에서 Spark 2.0.0으로(2016.07) 스파크 현재 – 2.1.1(2017.05.02) Versioning in Spark 2.1.1 Major version(may change APIs) Minor version(adds APIs/features) Patch version(only bug fixes)
10.
10© Cloudera, Inc.
All rights reserved. 스파크 개요(빠르게 대량의 데이터를 처리/분석)
11.
11© Cloudera, Inc.
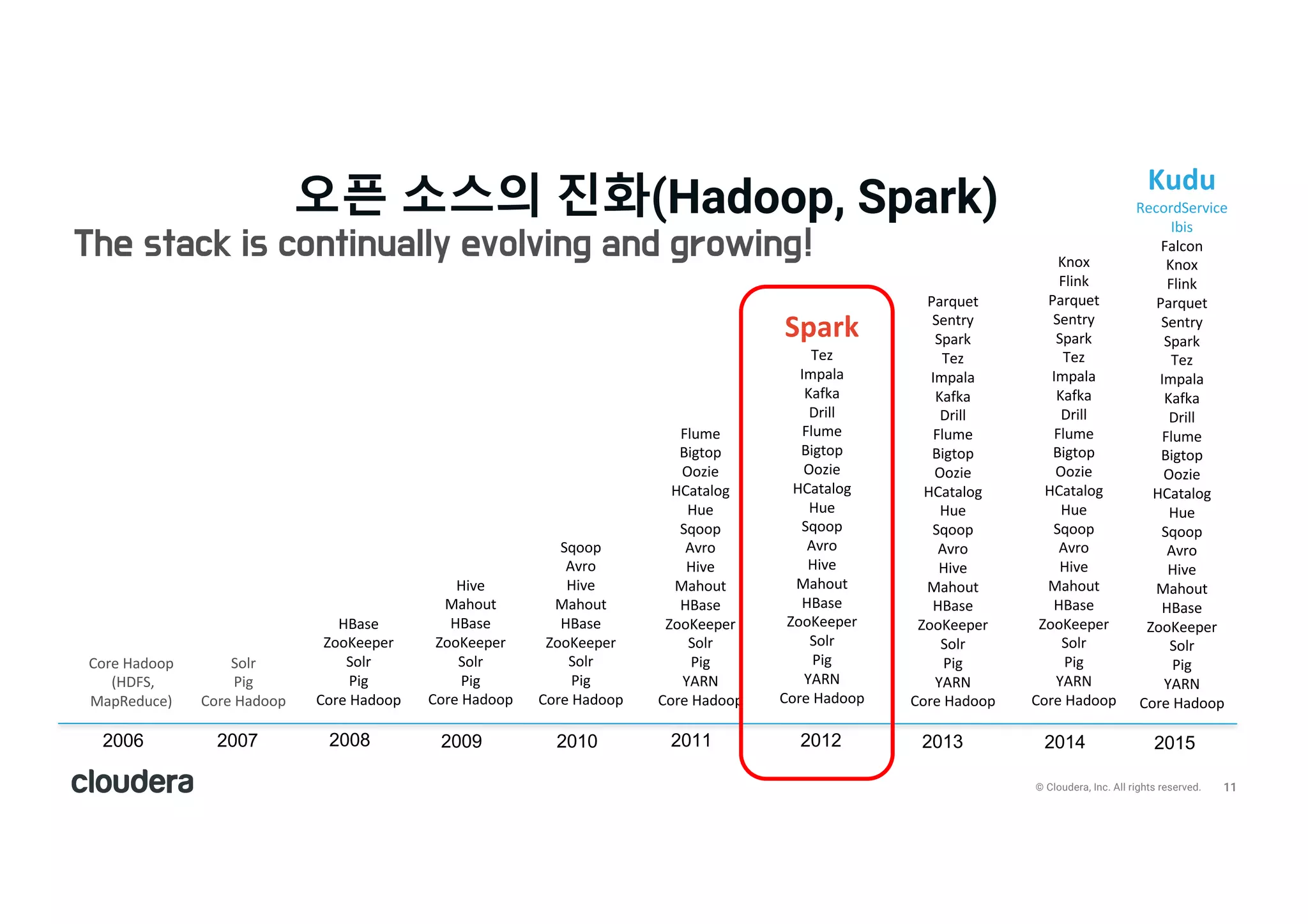
All rights reserved. 2006 2008 2009 2010 2011 2012 2013 Core Hadoop (HDFS, MapReduce) HBase ZooKeeper Solr Pig Core Hadoop Hive Mahout HBase ZooKeeper Solr Pig Core Hadoop Sqoop Avro Hive Mahout HBase ZooKeeper Solr Pig Core Hadoop Flume Bigtop Oozie HCatalog Hue Sqoop Avro Hive Mahout HBase ZooKeeper Solr Pig YARN Core Hadoop Spark Tez Impala Kafka Drill Flume Bigtop Oozie HCatalog Hue Sqoop Avro Hive Mahout HBase ZooKeeper Solr Pig YARN Core Hadoop Parquet Sentry Spark Tez Impala Kafka Drill Flume Bigtop Oozie HCatalog Hue Sqoop Avro Hive Mahout HBase ZooKeeper Solr Pig YARN Core Hadoop The stack is continually evolving and growing! 2007 Solr Pig Core Hadoop Knox Flink Parquet Sentry Spark Tez Impala Kafka Drill Flume Bigtop Oozie HCatalog Hue Sqoop Avro Hive Mahout HBase ZooKeeper Solr Pig YARN Core Hadoop 2014 2015 Kudu RecordService Ibis Falcon Knox Flink Parquet Sentry Spark Tez Impala Kafka Drill Flume Bigtop Oozie HCatalog Hue Sqoop Avro Hive Mahout HBase ZooKeeper Solr Pig YARN Core Hadoop 오픈 소스의 진화(Hadoop, Spark)
12.
12© Cloudera, Inc.
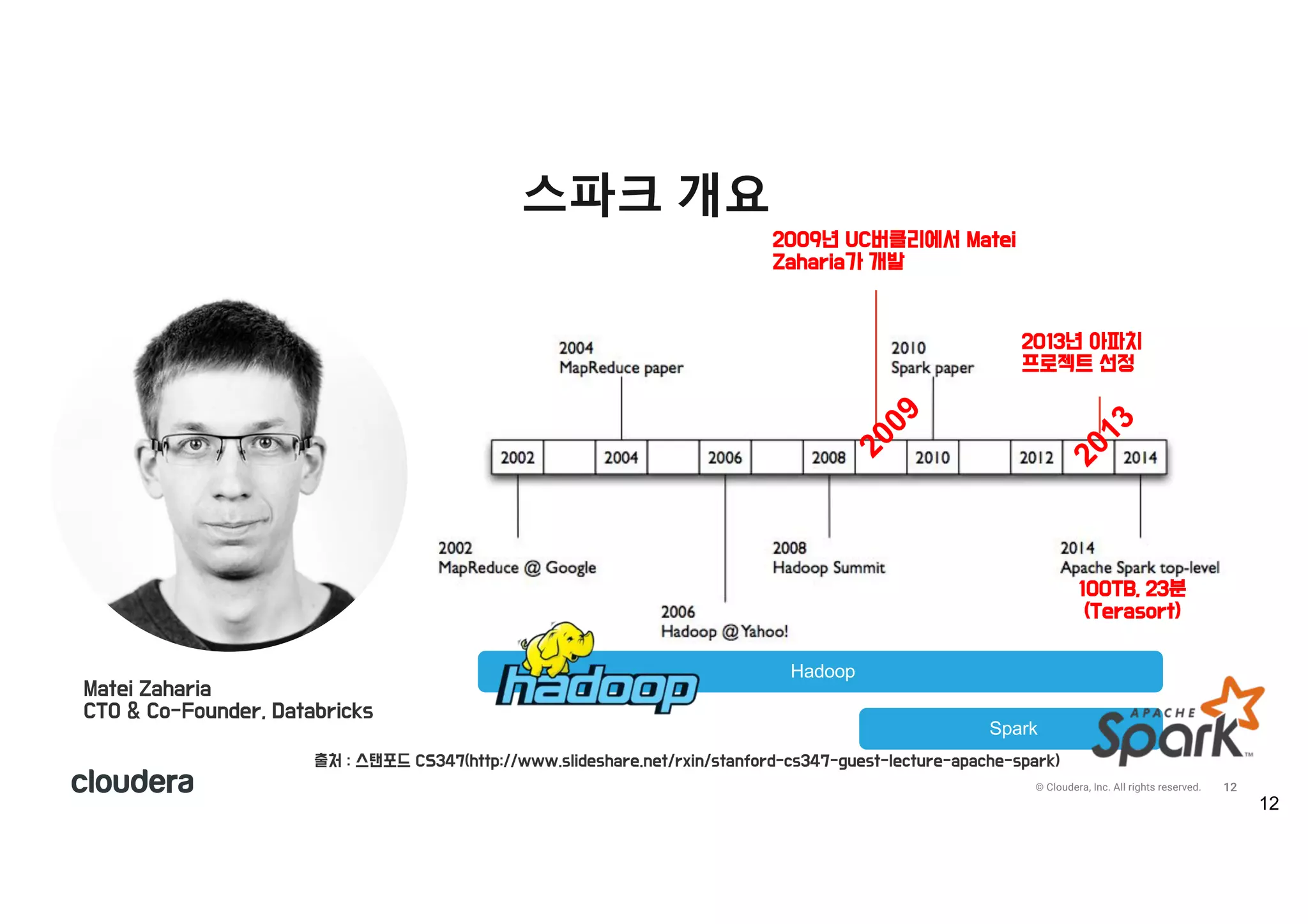
All rights reserved. 스파크 개요 Matei Zaharia CTO & Co-Founder, Databricks 2009년 UC버클리에서 Matei Zaharia가 개발 Hadoop Spark 2013년 아파치 프로젝트 선정 출처 : 스탠포드 CS347(http://www.slideshare.net/rxin/stanford-cs347-guest-lecture-apache-spark) 100TB, 23분 (Terasort)
13.
13© Cloudera, Inc.
All rights reserved. 스파크 아키텍처
14.
14© Cloudera, Inc.
All rights reserved. 스파크 아키텍처 Available languages for writing program for Spark: - Pyton - Scala - Java - R
15.
15© Cloudera, Inc.
All rights reserved. • 개인의 취향 및 여러 다른 의견이 있을 수 있지만 • 스파크의 대가는 이렇게 말합니다. - 스파크 전문가가 되려면 스칼라를 어느 정도는 학습해야 합니다. - 스파크 스칼라 API가 자바 API에 비해 더 쉽다. - 스칼라는 파이썬보다 더 좋은 성능(최신의 기능은 스칼라 먼저..) • 뭘로 하지 고민하기 보다 편한 언어로 일단 시작!!! 스칼라를 사용하는 이유? 15
16.
16© Cloudera, Inc.
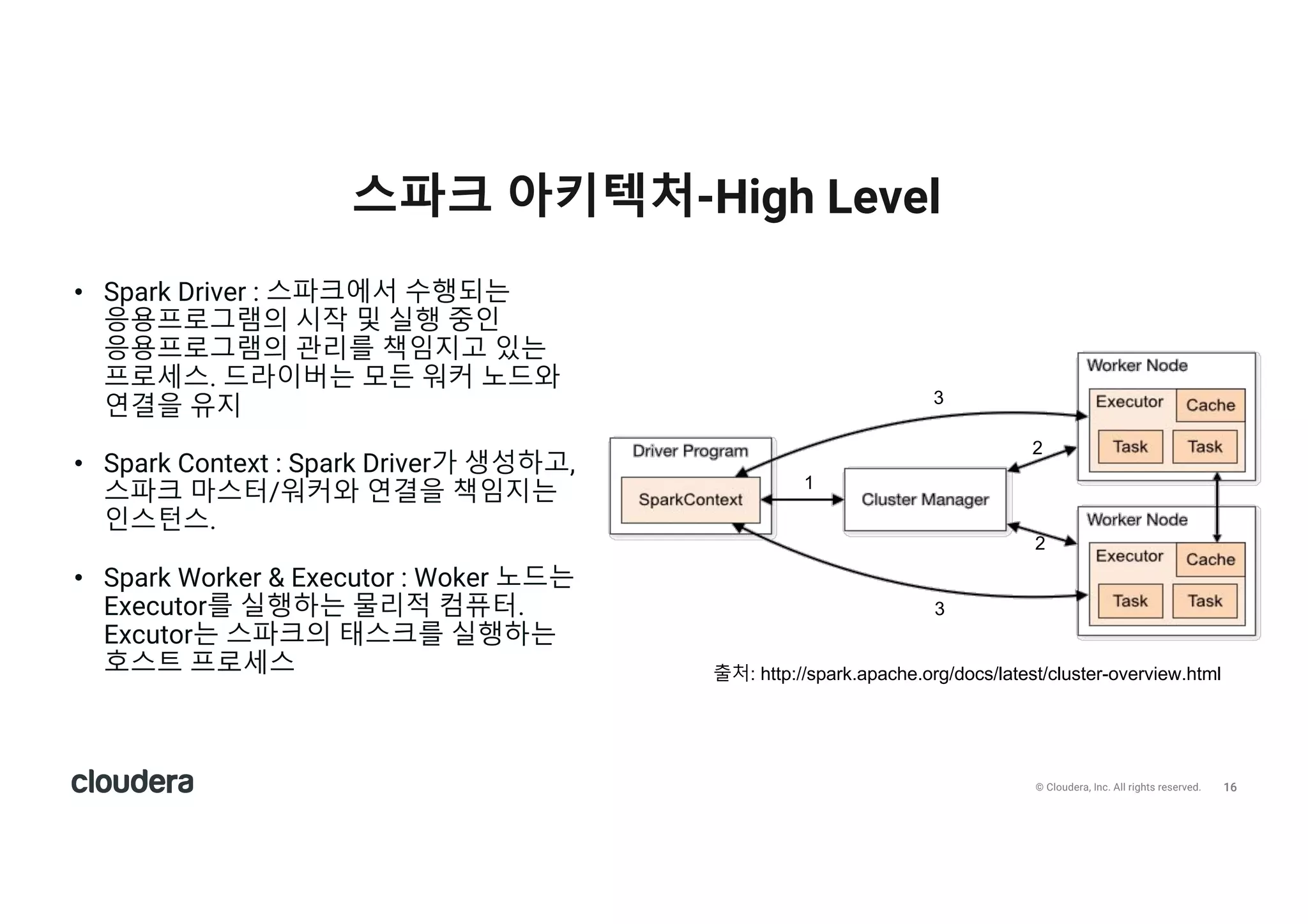
All rights reserved. 스파크 아키텍처-High Level • Spark Driver : 스파크에서 수행되는 응용프로그램의 시작 및 실행 중인 응용프로그램의 관리를 책임지고 있는 프로세스. 드라이버는 모든 워커 노드와 연결을 유지 • Spark Context : Spark Driver가 생성하고, 스파크 마스터/워커와 연결을 책임지는 인스턴스. • Spark Worker & Executor : Woker 노드는 Executor를 실행하는 물리적 컴퓨터. Excutor는 스파크의 태스크를 실행하는 호스트 프로세스 1 2 2 3 3 출처: http://spark.apache.org/docs/latest/cluster-overview.html
17.
17© Cloudera, Inc.
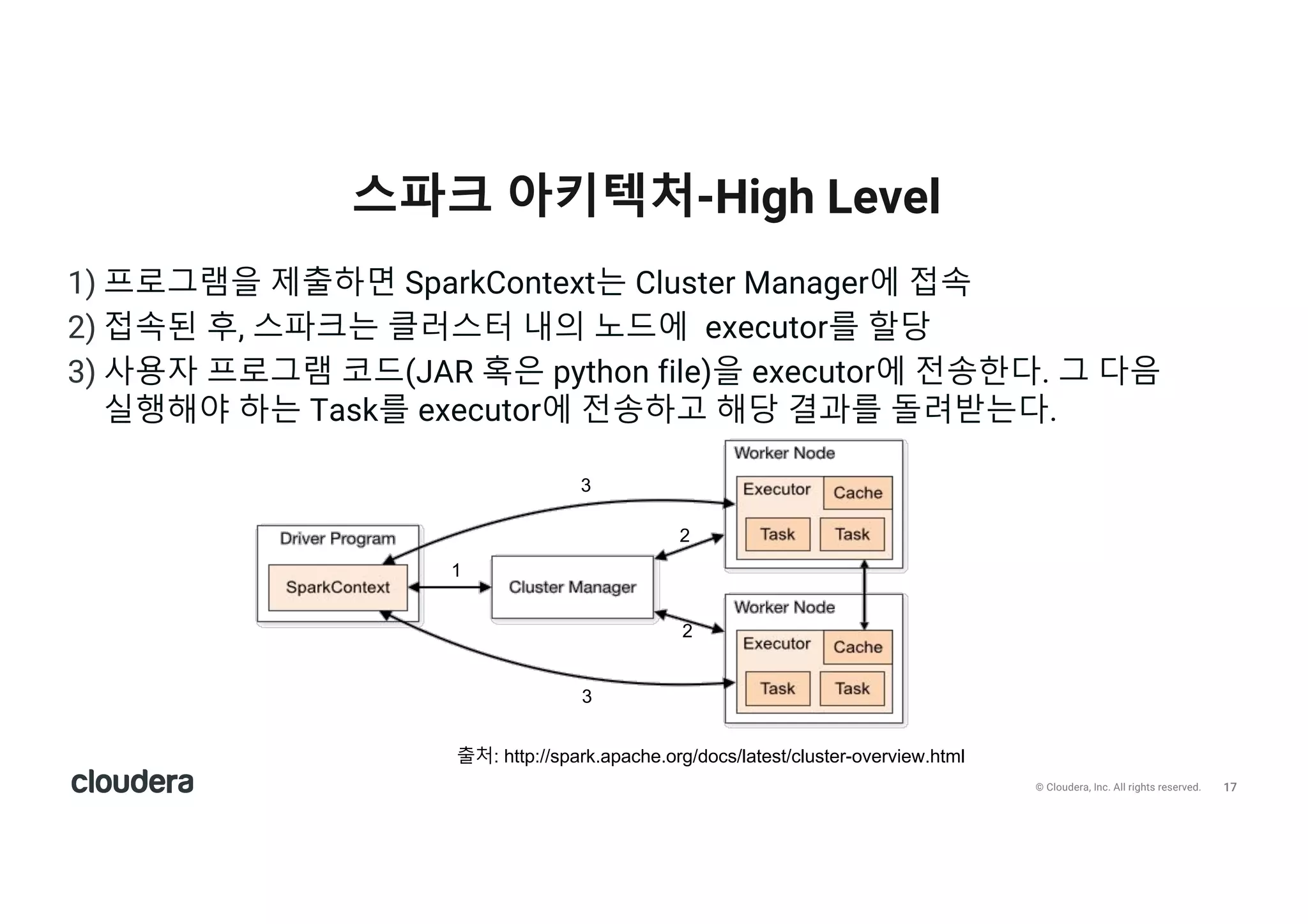
All rights reserved. 1) 프로그램을 제출하면 SparkContext는 Cluster Manager에 접속 2) 접속된 후, 스파크는 클러스터 내의 노드에 executor를 할당 3) 사용자 프로그램 코드(JAR 혹은 python file)을 executor에 전송한다. 그 다음 실행해야 하는 Task를 executor에 전송하고 해당 결과를 돌려받는다. 스파크 아키텍처-High Level 1 2 2 3 3 출처: http://spark.apache.org/docs/latest/cluster-overview.html
18.
19© Cloudera, Inc.
All rights reserved. 스파크 사용자 전 세계적으로 1000개 이상의 조직에서 사용 19
19.
20© Cloudera, Inc.
All rights reserved. 스파크의 핵심 RDD
20.
21© Cloudera, Inc.
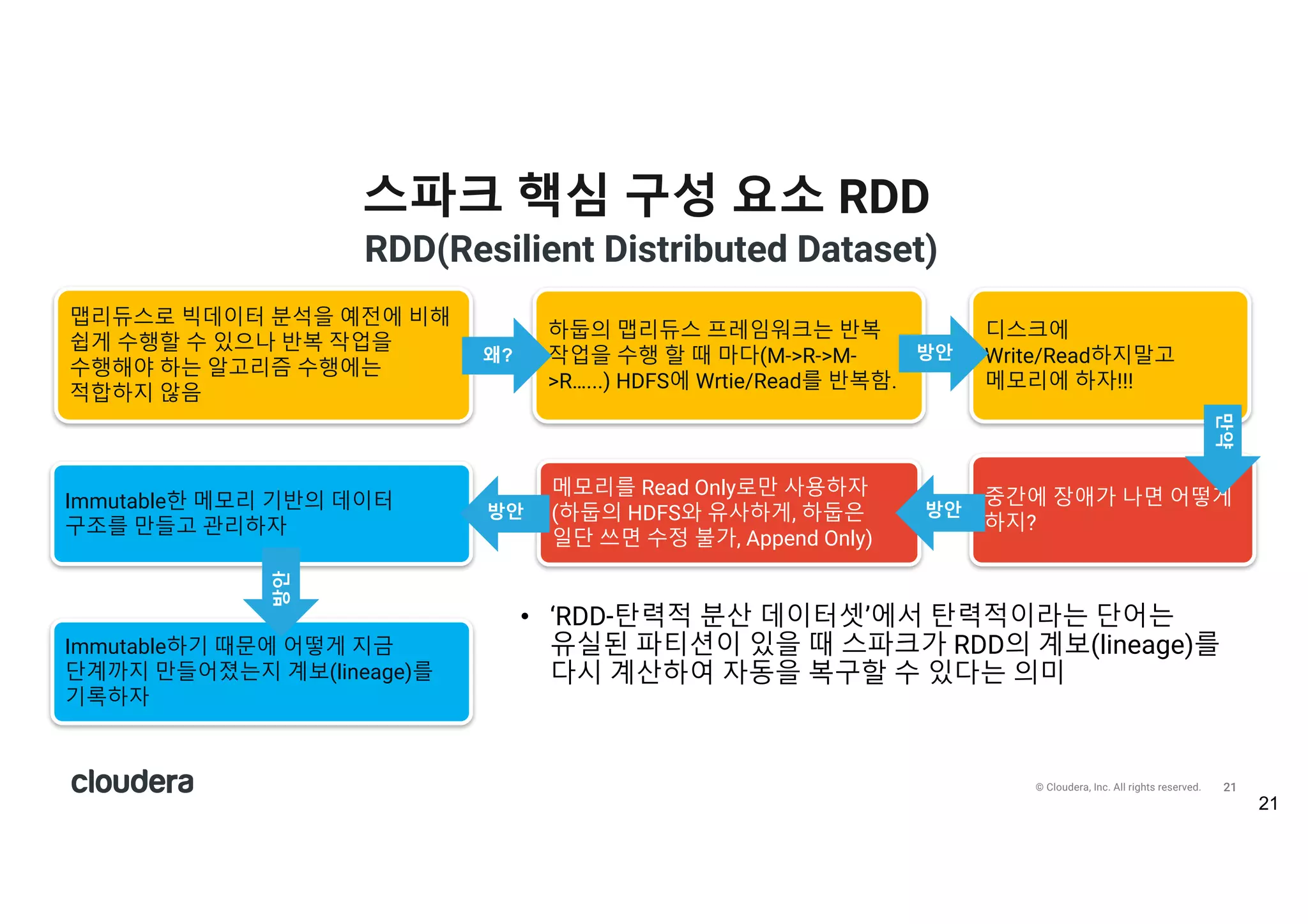
All rights reserved. 스파크 핵심 구성 요소 RDD 21 맵리듀스로 빅데이터 분석을 예전에 비해 쉽게 수행할 수 있으나 반복 작업을 수행해야 하는 알고리즘 수행에는 적합하지 않음 하둡의 맵리듀스 프레임워크는 반복 작업을 수행 할 때 마다(M->R->M- >R…...) HDFS에 Wrtie/Read를 반복함. 디스크에 Write/Read하지말고 메모리에 하자!!! 중간에 장애가 나면 어떻게 하지? 메모리를 Read Only로만 사용하자 (하둡의 HDFS와 유사하게, 하둡은 일단 쓰면 수정 불가, Append Only) 왜? 방안 Immutable한 메모리 기반의 데이터 구조를 만들고 관리하자 Immutable하기 때문에 어떻게 지금 단계까지 만들어졌는지 계보(lineage)를 기록하자 • ‘RDD-탄력적 분산 데이터셋’에서 탄력적이라는 단어는 유실된 파티션이 있을 때 스파크가 RDD의 계보(lineage)를 다시 계산하여 자동을 복구할 수 있다는 의미 만약 방안방안 방안 RDD(Resilient Distributed Dataset)
21.
22© Cloudera, Inc.
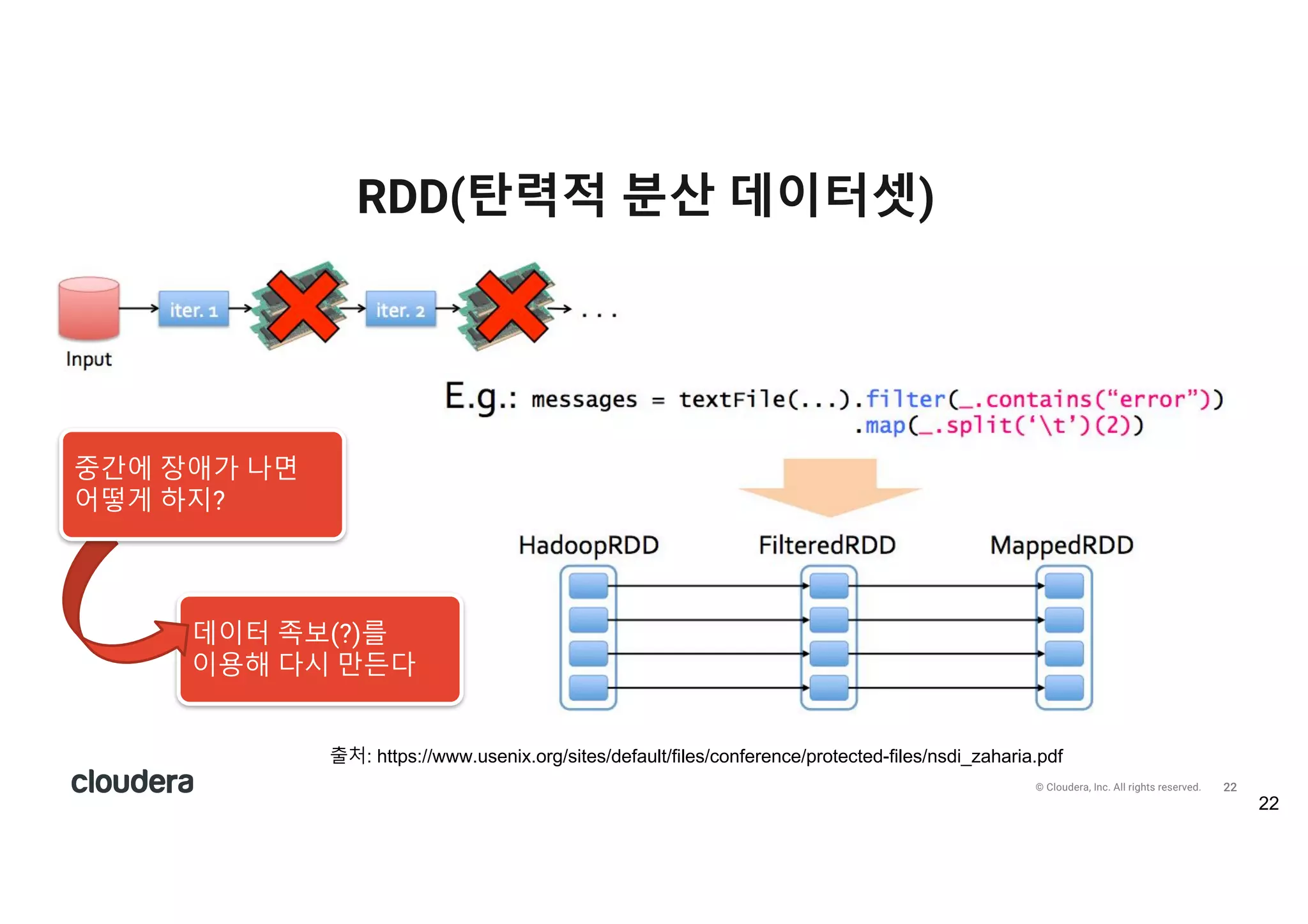
All rights reserved. RDD(탄력적 분산 데이터셋) 22 출처: https://www.usenix.org/sites/default/files/conference/protected-files/nsdi_zaharia.pdf 데이터 족보(?)를 이용해 다시 만든다 중간에 장애가 나면 어떻게 하지?
22.
23© Cloudera, Inc.
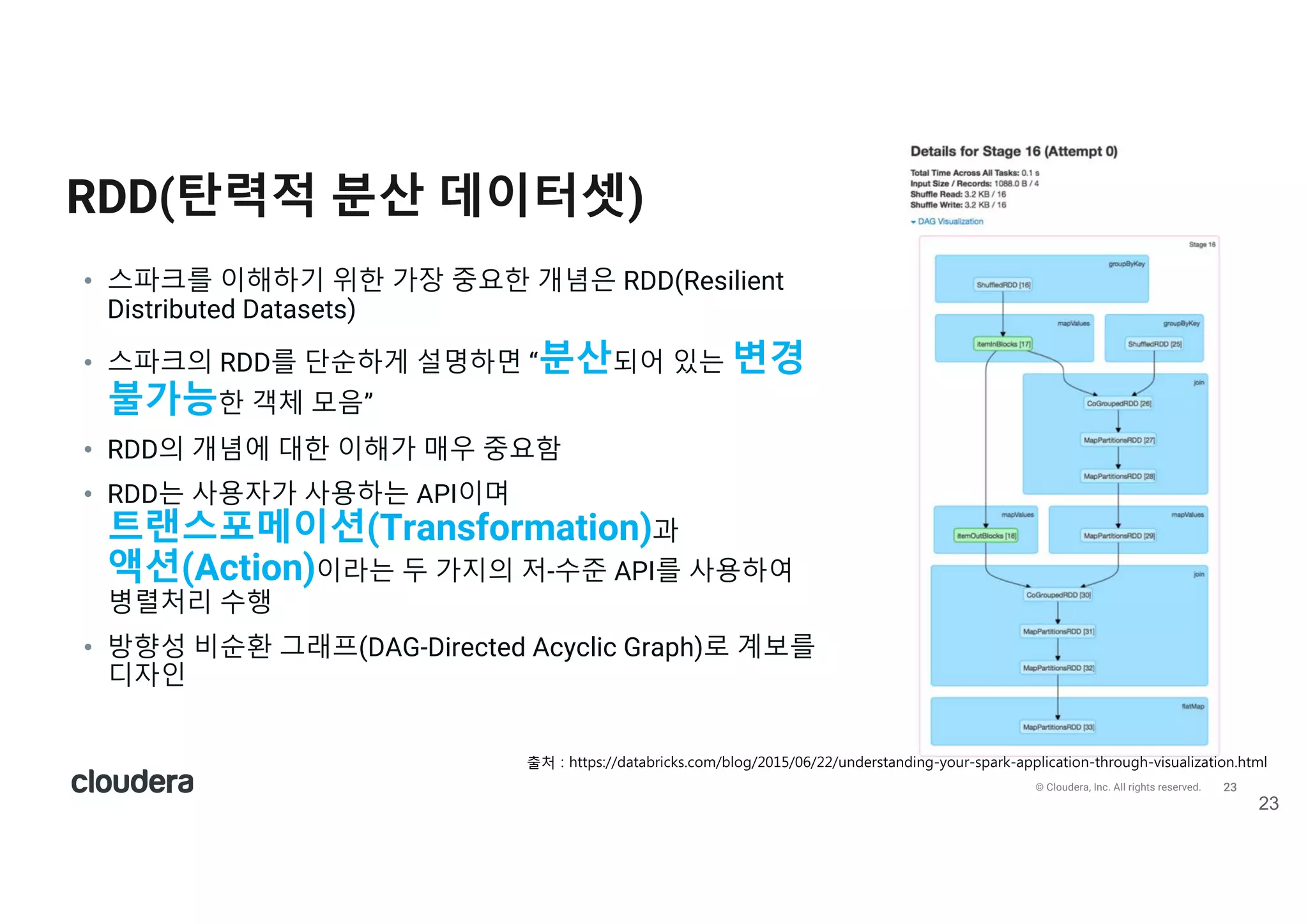
All rights reserved. RDD(탄력적 분산 데이터셋) 23 • 스파크를 이해하기 위한 가장 중요한 개념은 RDD(Resilient Distributed Datasets) • 스파크의 RDD를 단순하게 설명하면 “분산되어 있는 변경 불가능한 객체 모음” • RDD의 개념에 대한 이해가 매우 중요함 • RDD는 사용자가 사용하는 API이며 트랜스포메이션(Transformation)과 액션(Action)이라는 두 가지의 저-수준 API를 사용하여 병렬처리 수행 • 방향성 비순환 그래프(DAG-Directed Acyclic Graph)로 계보를 디자인 출v ) 6ttps)//2/t/0r71ks.1o:/0lo5/2015/06/22/un2erst/n27n5-your-sp/rk-/ppl71/t7on-t6rou56-v7su/l7z/t7on.6t:l
23.
24© Cloudera, Inc.
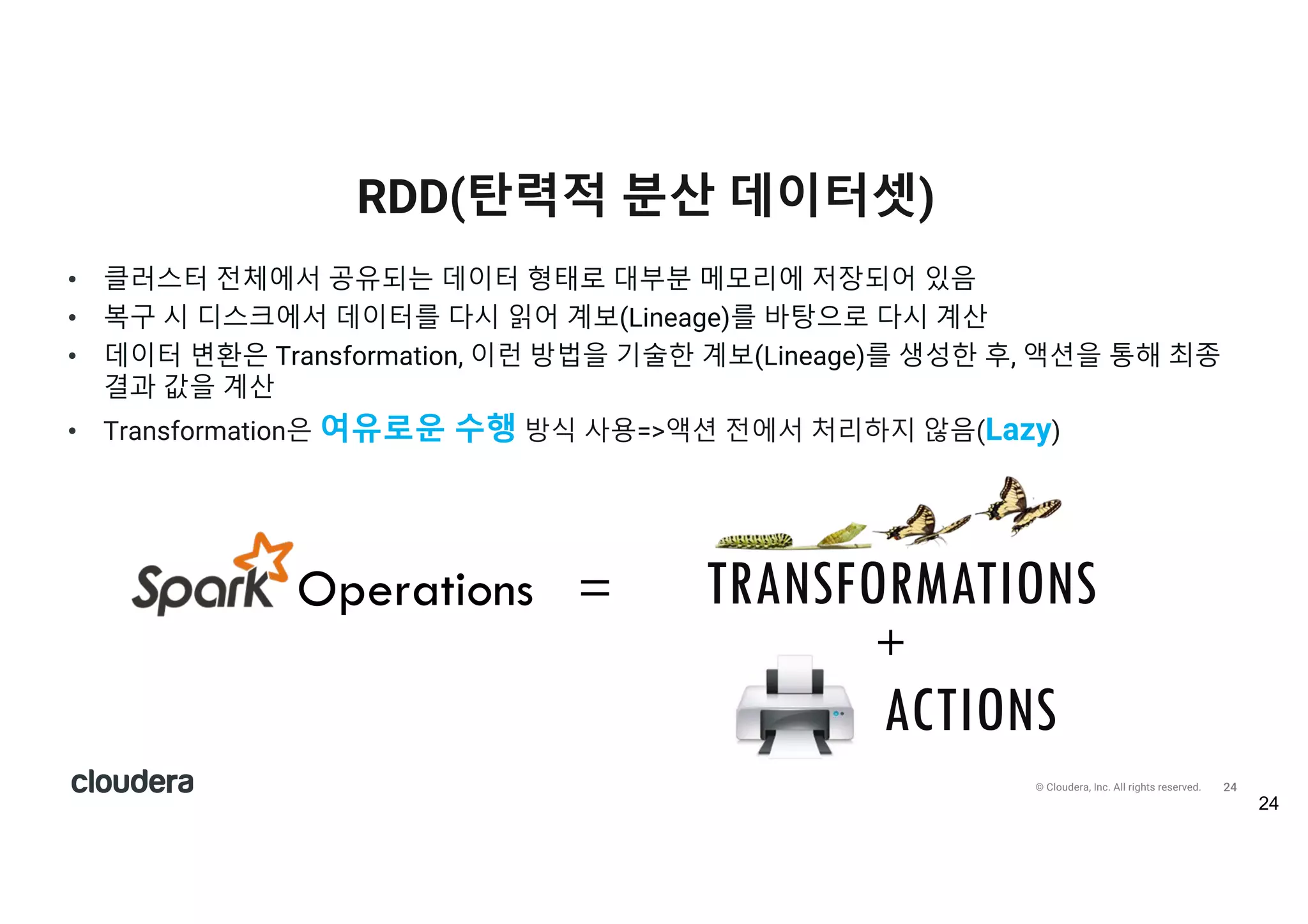
All rights reserved. • 클러스터 전체에서 공유되는 데이터 형태로 대부분 메모리에 저장되어 있음 • 복구 시 디스크에서 데이터를 다시 읽어 계보(Lineage)를 바탕으로 다시 계산 • 데이터 변환은 Transformation, 이런 방법을 기술한 계보(Lineage)를 생성한 후, 액션을 통해 최종 결과 값을 계산 • Transformation은 여유로운 수행 방식 사용=>액션 전에서 처리하지 않음(Lazy) RDD(탄력적 분산 데이터셋) 24 Operations = TRANSFORMATIONS ACTIONS +
24.
25© Cloudera, Inc.
All rights reserved. • 좀 더 알아보면 >>>Transformation은 여유로운 수행 방식 사용=>액션 전에서 처리하지 않음(Lazy) - 요청 즉시 처리하지 않고 스파크는 메타데이터에 이런 종류의 연산이 요청되었다는 사실만을 기록 - RDD에 데이터를 적재하는 것도 트랜스포메이션과 동일하게 여유로운 수행 방식임 - sc.textFile()을 호출해도 실제 필요한 시점(액션)이 되기 전까지는 수행되지 않음. - 스파크는 연산을 그룹화해서 데이터를 전달하는 횟수를 줄임(하둡 맵리듀스에서 어려운 부분, 성능 관련) - 효율적인 코딩에 대한 부담이 상대적으로 적음 Lazy execution 25 TRANSFORMATIONS
25.
26© Cloudera, Inc.
All rights reserved. Lazy execution(전체를 이해하고 최적화) 26 시나리오 전체를 미리 읽고 이해한 대배우 vs 오늘도 쪽 대본을 본 연기자
26.
27© Cloudera, Inc.
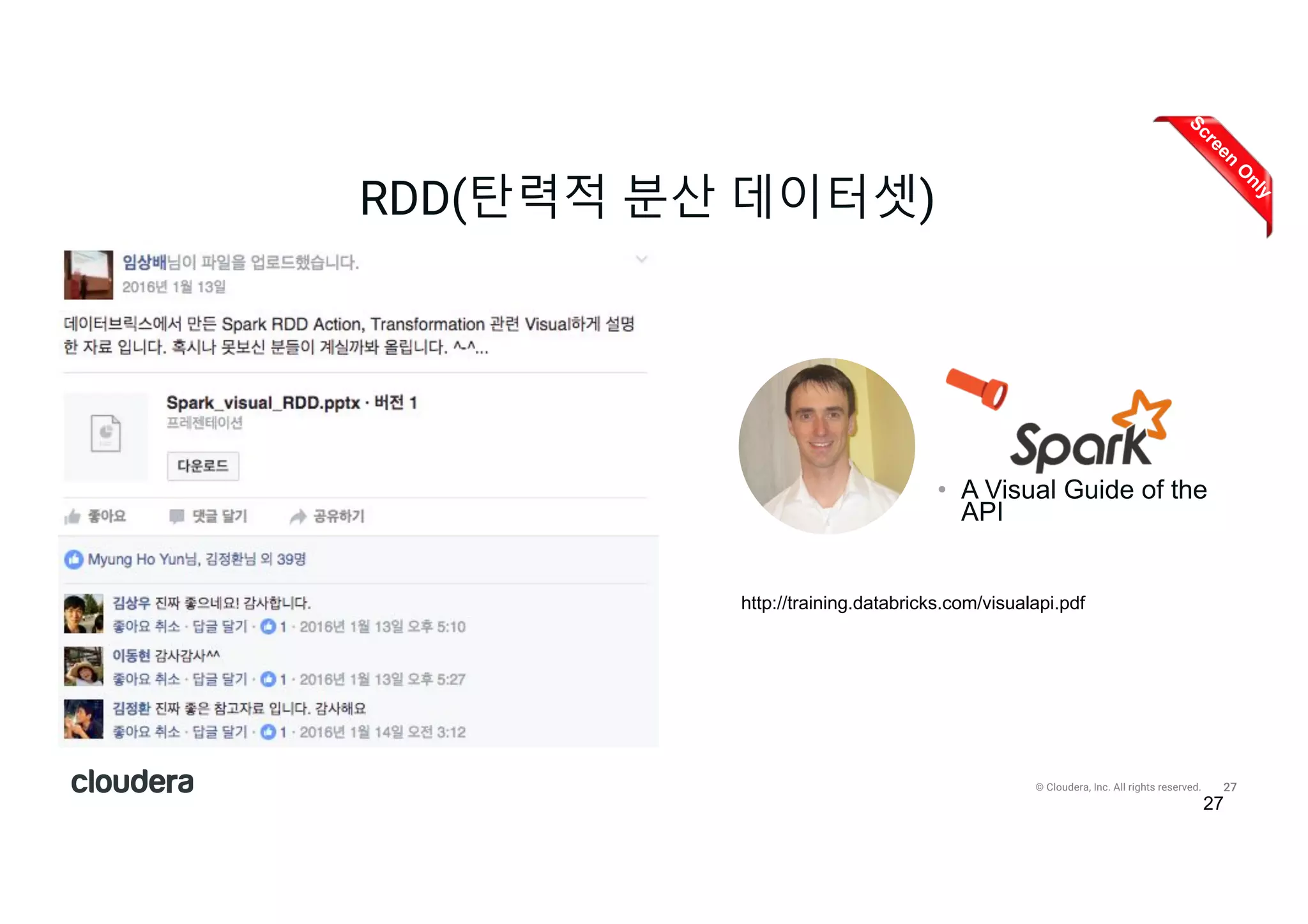
All rights reserved. RDD(탄력적 분산 데이터셋) 27 • A Visual Guide of the API http://training.databricks.com/visualapi.pdf
27.
28© Cloudera, Inc.
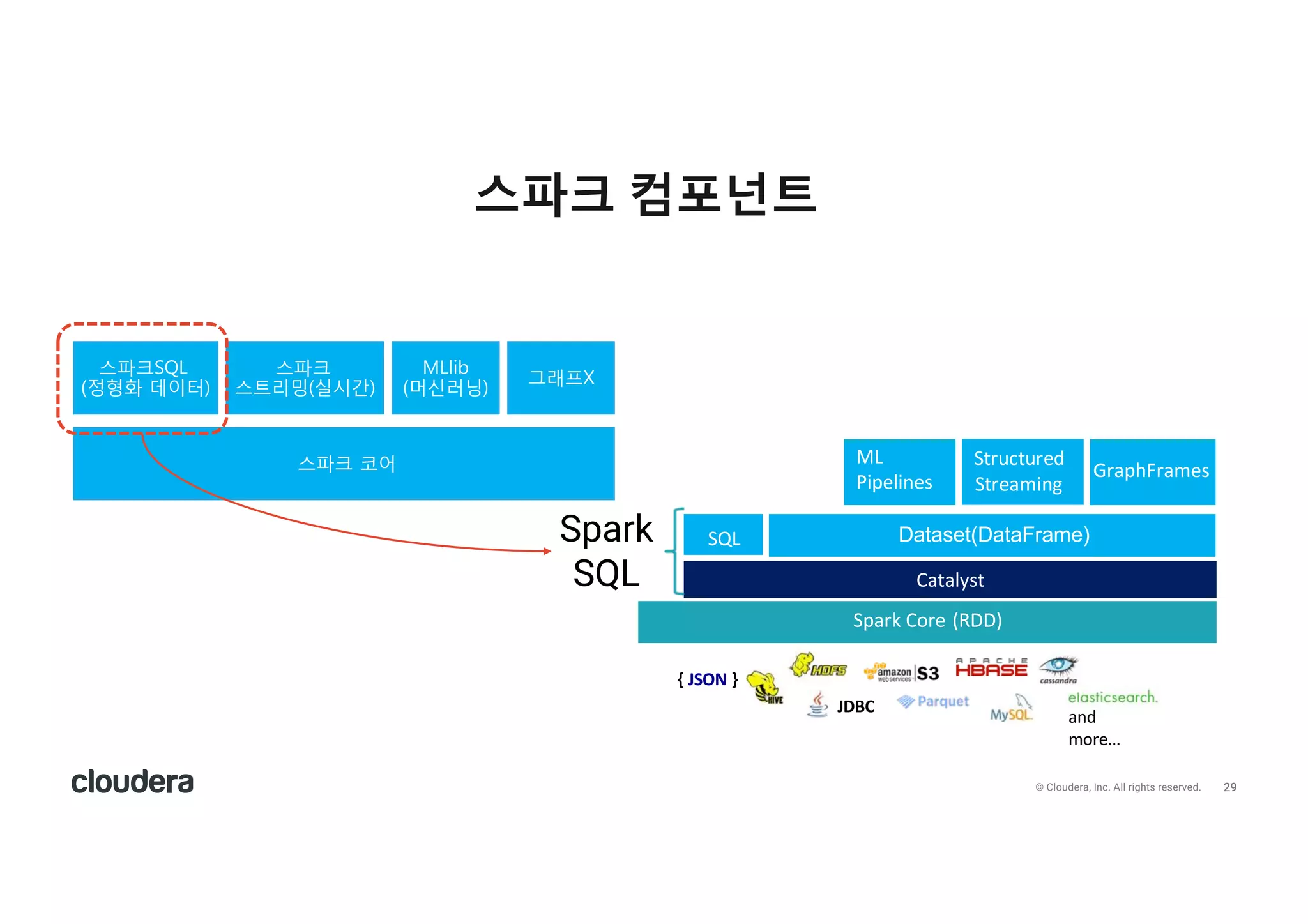
All rights reserved. 스파크 SQL c파크 zh c파크-QL (r형화 데o터) c파크 c트리밍(fd간) MLl70 (머eQ닝) 그래프.
28.
29© Cloudera, Inc.
All rights reserved. 스파크 컴포넌트 c파크 zh c파크-QL (r형화 데o터) c파크 c트리밍(fd간) MLl70 (머eQ닝) 그래프. Spark Core (RDD) Catalyst SQL ML Pipelines Structured Streaming { JSON } JDBC and more… Spark SQL GraphFrames Dataset(DataFrame)
29.
30© Cloudera, Inc.
All rights reserved. • Spark SQL is Apache Spark's module for working with structured data. • RDD를 사용해서 대용량의 데이터를 고속으로 처리할 수 있으나 부족한 점이 있음 • 데이터에 대한 데이터, 즉 메타데이터(스키마)를 지원하지 않음 • 작성한 코드의 수준에 따라 성능 차이가 매우 크며, 최적화 하기 어려움 • Spark SQL은 이를 해결, 구조화된 데이터를 쉽게 처리 • 고성능 처리(하드웨어 성능 쥐어짜기)를 위해 1.4(Dataframe), 1.6(Dataset)으로 적용 범위를 확대 • Spark SQL을 사용하는 최신 API는 Dataset(2017.3.1 현재 scala, java 언어만 지원) 스파크 SQL 개요 30
30.
31© Cloudera, Inc.
All rights reserved. 스파크 SQL 장점 • 적은 코드 작성, 효율적 데이터 Read, 옵티마이저 최대 활용
31.
32© Cloudera, Inc.
All rights reserved. Demo : Dataset 32 출처 : https://www.youtube.com/watch?v=K14plpZgy_c
32.
33© Cloudera, Inc.
All rights reserved. Demo : Dataset 33 샌프란시스코 오픈 데이터 사용한 HOL
33.
34© Cloudera, Inc.
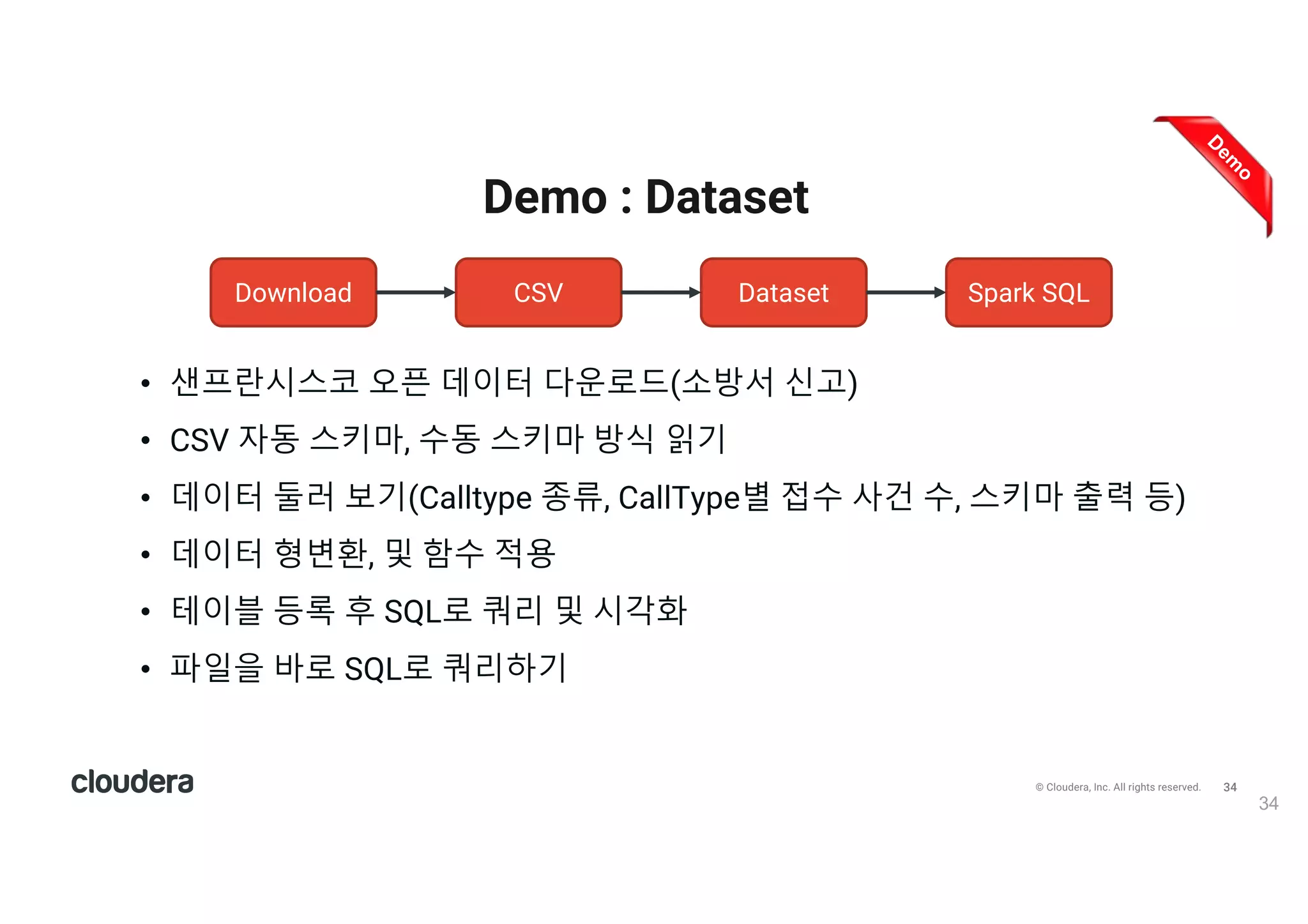
All rights reserved. Demo : Dataset 34 • 샌프란시스코 오픈 데이터 다운로드(소방서 신고) • CSV 자동 스키마, 수동 스키마 방식 읽기 • 데이터 둘러 보기(Calltype 종류, CallType별 접수 사건 수, 스키마 출력 등) • 데이터 형변환, 및 함수 적용 • 테이블 등록 후 SQL로 쿼리 및 시각화 • 파일을 바로 SQL로 쿼리하기 • Zeppelin notebook 다운로드 : https://drive.google.com/open?id=0B5O_AbgzIMpLSE9LWldKR3F5QVE Download CSV Dataset Spark SQL
34.
35© Cloudera, Inc.
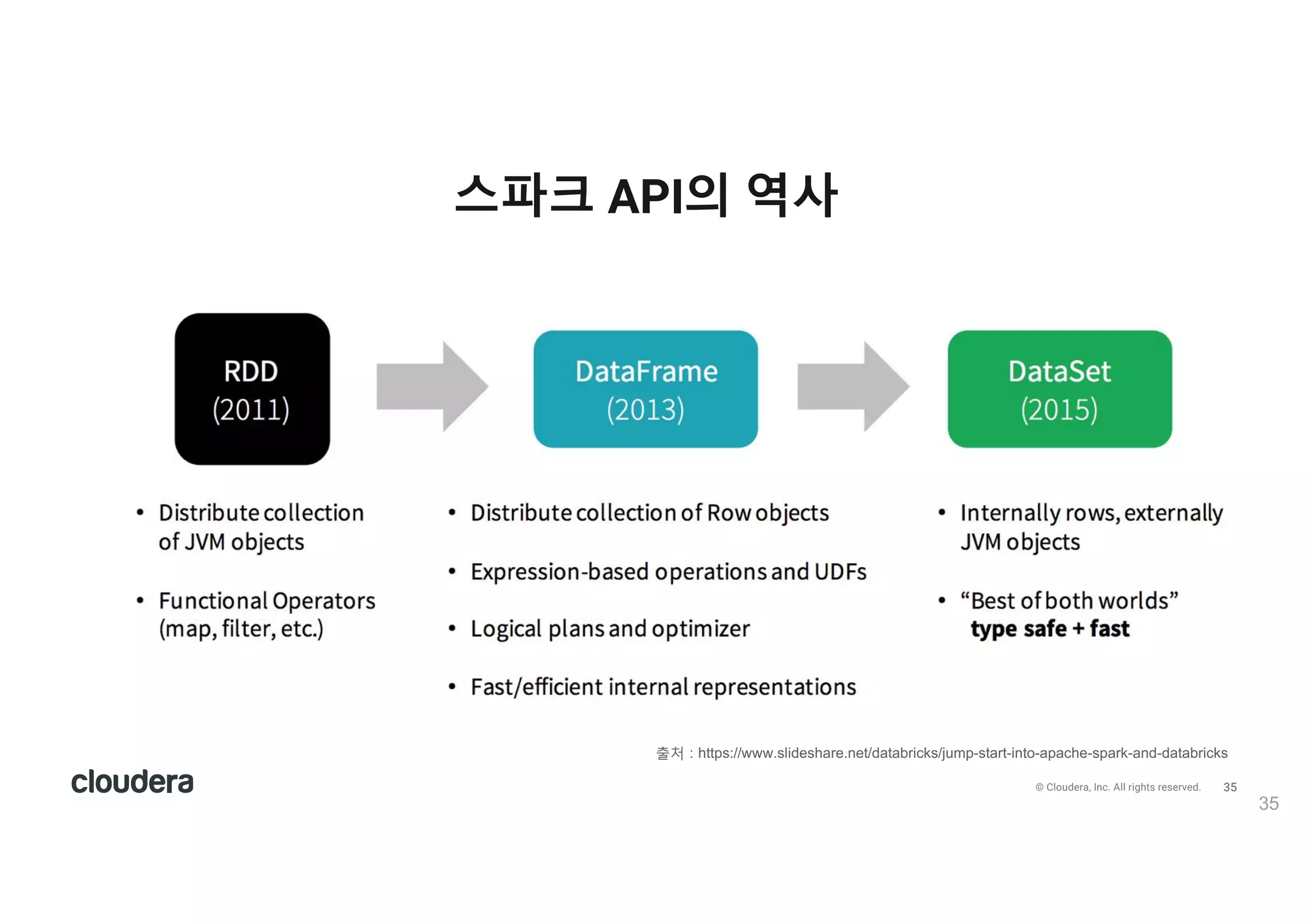
All rights reserved. 스파크 API의 역사 35 출v ) https://www.slideshare.net/databricks/jump-start-into-apache-spark-and-databricks
35.
36© Cloudera, Inc.
All rights reserved. 언어별 DataFrame 성능 36 출v ) https://www.slideshare.net/databricks/jump-start-into-apache-spark-and-databricks
36.
37© Cloudera, Inc.
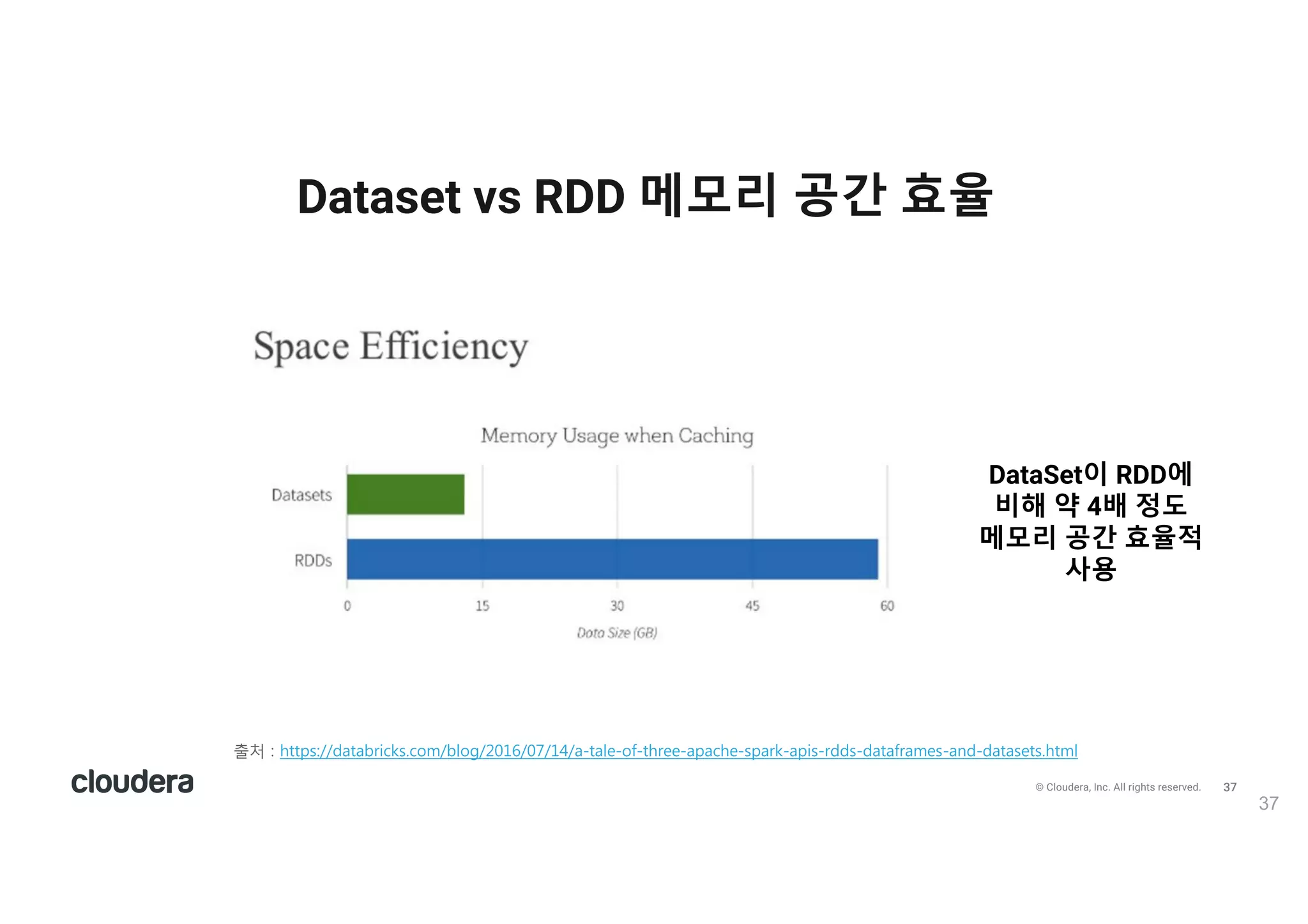
All rights reserved. Dataset vs RDD 메모리 공간 효율 37 출v ) 6ttps)//2/t/0r71ks.1o:/0lo5/2016/0(/14//-t/le-o4-t6ree-/p/16e-sp/rk-/p7s-r22s-2/t/4r/:es-/n2-2/t/sets.6t:l DataSet이 RDD에 비해 약 4배 정도 메모리 공간 효율적 사용
37.
38© Cloudera, Inc.
All rights reserved. • RDD 사용이 적합 - 데이터 처리 시 저-수준 트랜스포메이션 및 액션 사용 - 처리할 데이터가 비정형(미디어 스트림 혹은 텍스트 스트림) - 함수형 프로그래밍 방식으로 데이터를 처리 - 이름이나 컬럼으로 데이터 속성을 처리 혹은 접근 하는 동안 컬럼 형식과 같은 스키마 적용을 고려하지 않을 때 - 정형/반정형 데이터의 데이터프레임 및 데이터셋에서 사용할 수 있는 일부 최적화 및 성능 이점을 개의치 않을 수 있을 때 언제 RDD, 언제 Dataset(Dataframe)을 사용? 38 출v ) 6ttps)//2/t/0r71ks.1o:/0lo5/2016/0(/14//-t/le-o4-t6ree-/p/16e-sp/rk-/p7s-r22s-2/t/4r/:es-/n2-2/t/sets.6t:l p부 번l
38.
39© Cloudera, Inc.
All rights reserved. • DataFrame, Dataset 사용이 적합 - 고수준 추상화, 풍부한 시멘틱, 도메인 특화 API 사용이 필요 - 반정형 데이터에 고급 표현식, 필터, 맵, 집계, 평균, 합계, SQL 쿼리, 컬럼 액세스, 람다 함수 사용이 필요 - 컴파일 타임에 보다 높은 수준의 type-safety, typed-JVM 객체가 필요하고 카탈리스트 최적화와 텅스텐의 효율적인 코드 생성의 장점이 필요 - 스파크 라이브러리에서 API 통합 및 단순화가 필요 - R 사용자는 DataFrame 사용 - 파이선 사용자는 DataFrame 사용 후 더 많은 제어 작업이 필요하면 RDD 사용 언제 RDD, 언제 Dataset(Dataframe)을 사용? 39 출v ) 6ttps)//2/t/0r71ks.1o:/0lo5/2016/0(/14//-t/le-o4-t6ree-/p/16e-sp/rk-/p7s-r22s-2/t/4r/:es-/n2-2/t/sets.6t:l p부 번l val deviceEventsDS = ds.select($"device_name", $"cca3", $"c02_level").where($"c02_level" > 1300) val eventsRDD = deviceEventsDS.rdd.take(10)
39.
40© Cloudera, Inc.
All rights reserved. • RDD가 없어지나요? Apache Spark 2.0에서 RDD 40 출v ) 6ttps)//2/t/0r71ks.1o:/0lo5/2016/0(/14//-t/le-o4-t6ree-/p/16e-sp/rk-/p7s-r22s-2/t/4r/:es-/n2-2/t/sets.6t:l
40.
41© Cloudera, Inc.
All rights reserved. 스파크 스트리밍 c파크 zh c파크-QL (r형화 데o터) c파크 c트리밍(fd간) MLl70 (머eQ닝) 그래프.
41.
42© Cloudera, Inc.
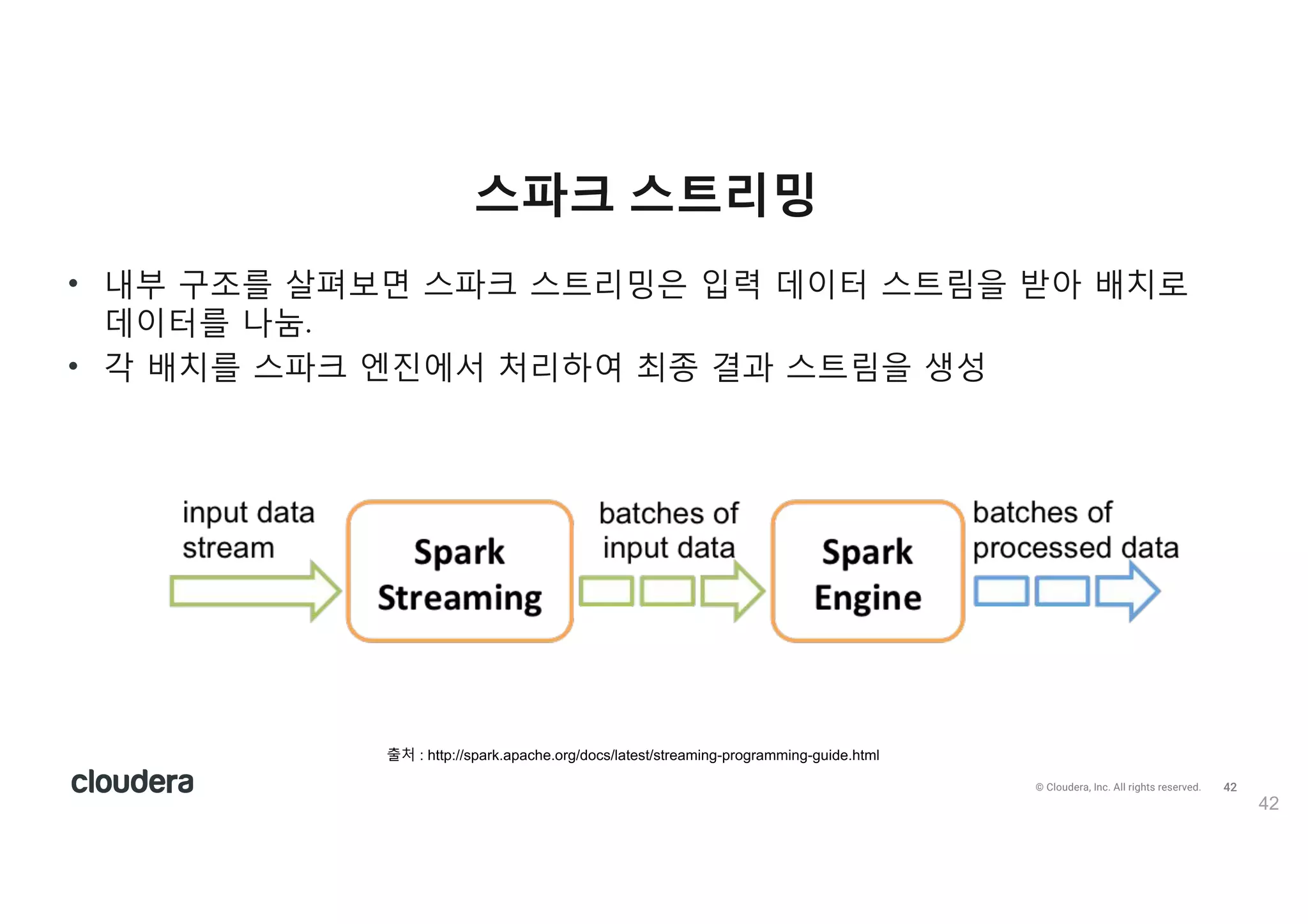
All rights reserved. • L부 구s를 살펴보X c파크 c트리밍m 입력 데o터 c트림n 받g 배yS 데o터를 나M. • 각 배y를 c파크 엔uia v리하k 최t 결과 c트림n 생b 스파크 스트리밍 42 출처 : http://spark.apache.org/docs/latest/streaming-programming-guide.html
42.
43© Cloudera, Inc.
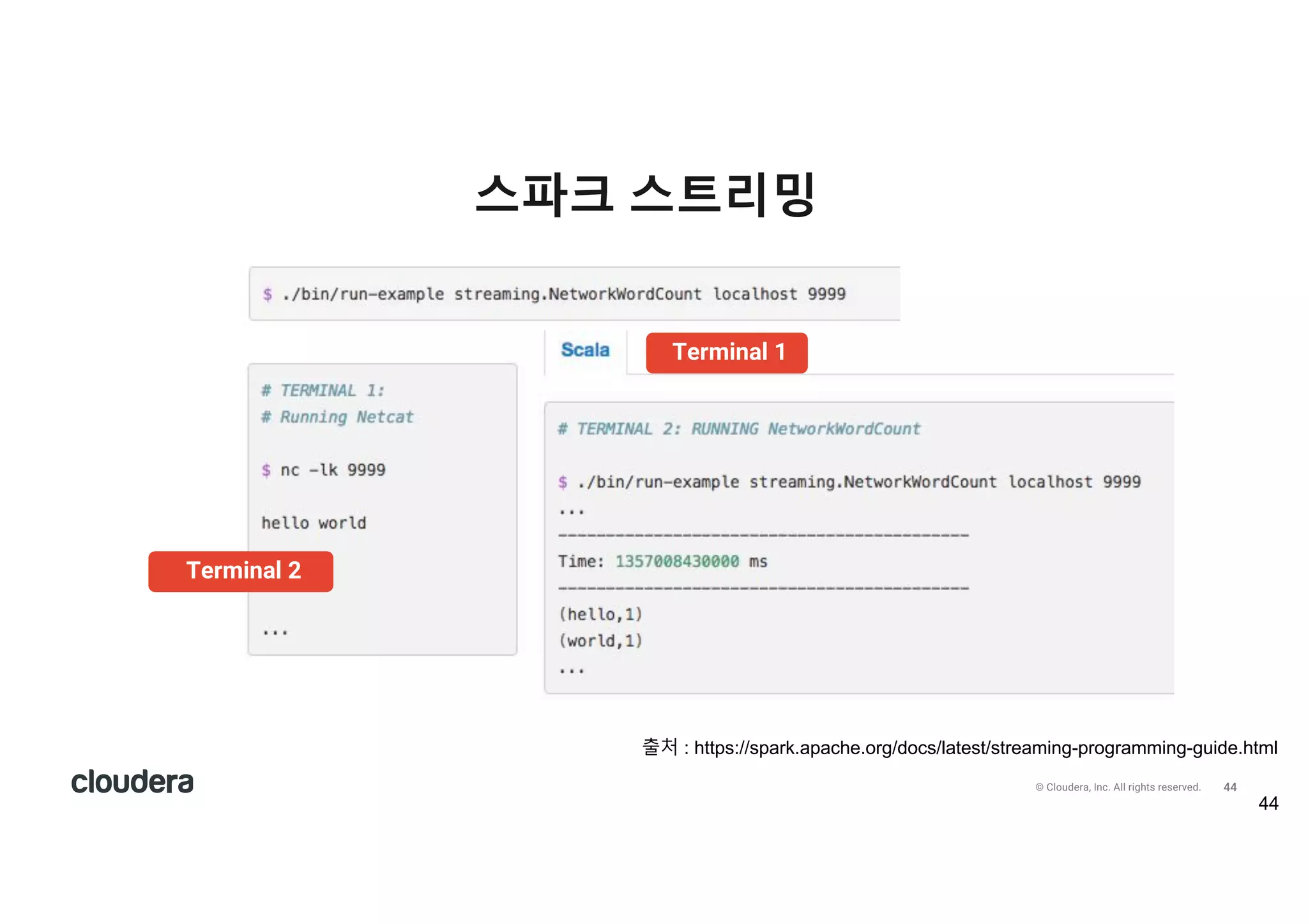
All rights reserved. 스파크 스트리밍 43 http://www.slideshare.net/databricks/a-deep-dive-into-structured-streaming https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/streaming/NetworkWordCount.scala
43.
44© Cloudera, Inc.
All rights reserved. 스파크 스트리밍 44 출처 : https://spark.apache.org/docs/latest/streaming-programming-guide.html Terminal 1 Terminal 2
44.
45© Cloudera, Inc.
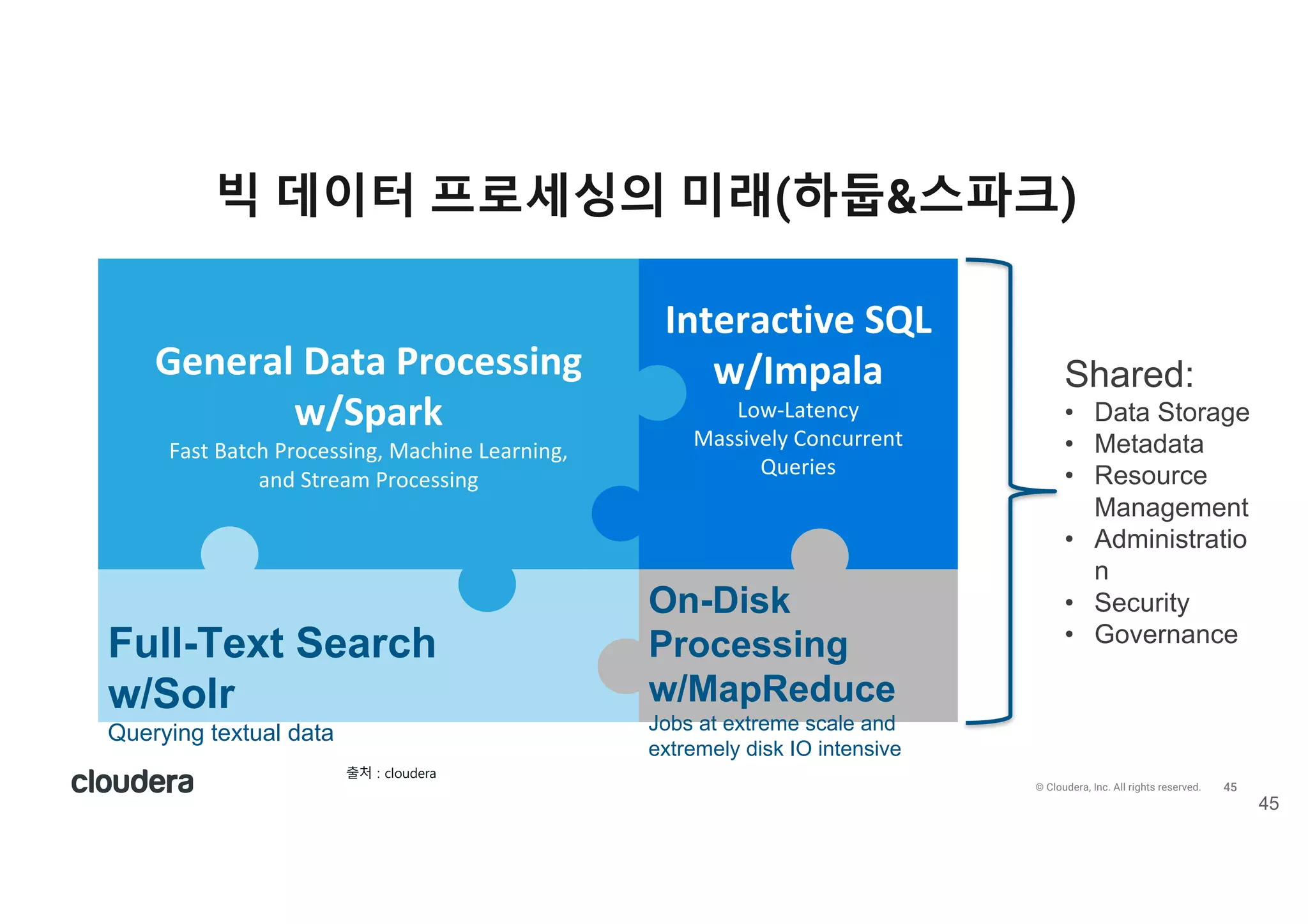
All rights reserved. 빅 데이터 프로세싱의 미래(하둡&스파크) 45 General Data Processing w/Spark Fast Batch Processing, Machine Learning, and Stream Processing Interactive SQL w/Impala Low-Latency Massively Concurrent Queries Full-Text Search w/Solr Querying textual data On-Disk Processing w/MapReduce Jobs at extreme scale and extremely disk IO intensive Shared: • Data Storage • Metadata • Resource Management • Administration • Security • Governance 출처 ) 1lou2er/
45.
46© Cloudera, Inc.
All rights reserved. Apache Spark FAQ Q1 : 하둡과 스파크는 어떤 관련이 있나요? => 스파크는 하둡 데이터와 호환되는 고성능의 범용 처리 엔진 Q2 : 스파크를 실제 사용하는 기업/단체는 어디인가요? => 1000개가 넘는 기관에서 이미 운영 중이며 http://spark.apache.org/powered-by.html 참고(오라클도 제품 혹은 서비스 형태로 도입하여 운영 중) Q3 : 스파크로 클러스터 구성하면 어느 정도까지 확장할 수 있나요?=> 현재 가장 큰 클러스터는 8000대 수준. FAQ로 알아보는 스파크 46
46.
47© Cloudera, Inc.
All rights reserved. Apache Spark FAQ Q4 : 스파크를 사용하려면 데이터가 메모리에 모두 저장되어야 하나요?=>아니오. 메모리 용량보다 처리해야 할 데이터가 크면 디스크도 사용(spill data to disk) Q5 : 클러스터 기반으로 스파크를 어떻게 실행해야 하나요?=> 단독 실행 모드, 얀(YARN), 메소스(Mesos)등을 사용할 수 있음 Q6 : 스파크를 실행하기 위해 꼭 하둡이 필요한가요? => 아니오, 하지만 클러스터 환경에서 운영 중이라면 공유파일 시스템이 필요함. 하둡과 함께 사용하는 경우가 많음 FAQ로 알아보는 스파크 47
47.
48© Cloudera, Inc.
All rights reserved. Thank you 임상배/오라클 한국 스파크 사용자 모임 https://www.facebook.com/groups/sparkkoreauser/
Download































![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)




![[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/2251016final-171017052307-thumbnail.jpg?width=640&height=640&fit=bounds)




![[NDC 2018] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산처리 자동화 인프라 구축](https://cdn.slidesharecdn.com/ss_thumbnails/jparktemp-180424105624-thumbnail.jpg?width=640&height=640&fit=bounds)

![[225]yarn 기반의 deep learning application cluster 구축 김제민](https://cdn.slidesharecdn.com/ss_thumbnails/225yarndeeplearningapplicationcluster-161025031031-thumbnail.jpg?width=640&height=640&fit=bounds)














![[SSA] 01.bigdata database technology (2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/01-140225072202-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
































