Download as PDF, PPTX






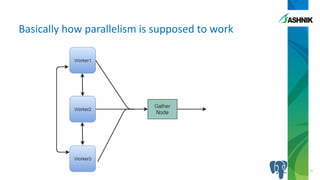

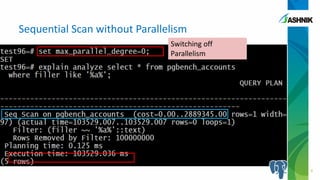

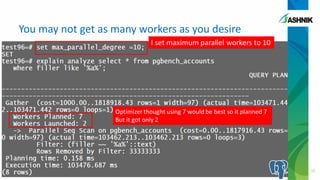
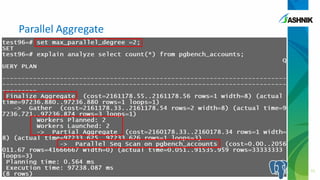
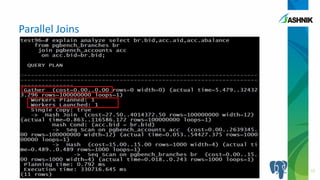


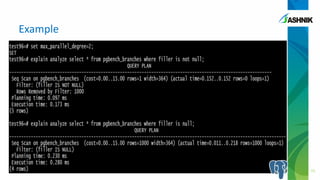
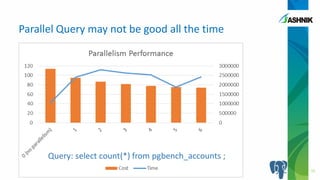







The document discusses the advancements in parallelism in PostgreSQL, particularly in versions 9.4 to 9.6, highlighting the implementation of server-side parallel queries and its benefits for tasks like sequential scans and joins. It also notes that while parallelism can improve performance, its effectiveness varies based on system resources and setup costs, sometimes making it less advantageous. The author encourages users to explore the beta version and contribute to the PostgreSQL community.








































































































