Downloaded 18 times












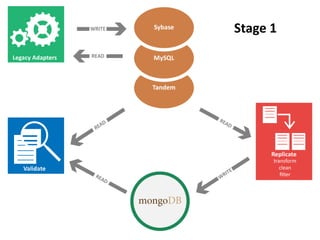
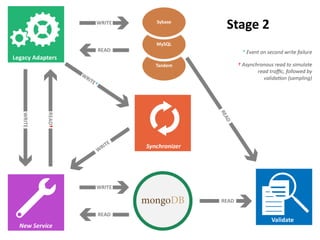
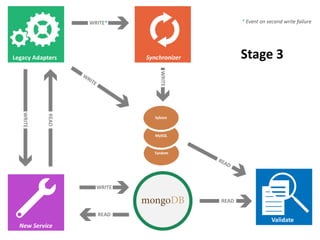
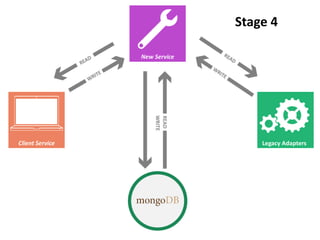






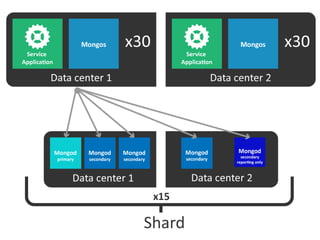




































The document details AOL's implementation of MongoDB to improve data management, overcoming challenges like functional ambiguity and scaling. It discusses their migration strategy, performance testing, deployment details, and various collections, including user identities and relationships. Key lessons learned emphasize optimizing connections, minimizing read delays, and ensuring failovers are handled efficiently.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































