






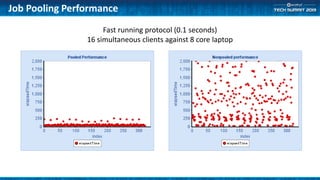

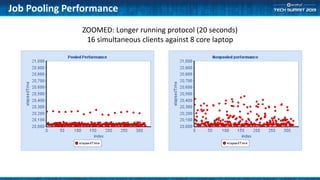



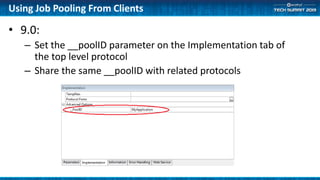

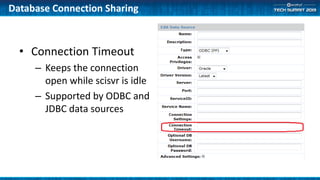












The document outlines methods for optimizing application performance, particularly through job pooling and efficient database connection management. It discusses various configurations, report templates, and guidelines for both short and long-running parallel protocols, emphasizing the importance of memory management and debugging in a server context. Deployment options are also covered, highlighting the scalability and performance implications of different server configurations.























































































