Download to read offline








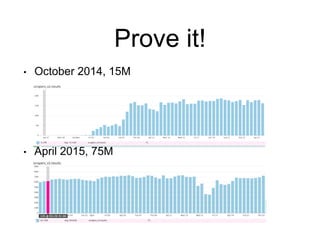
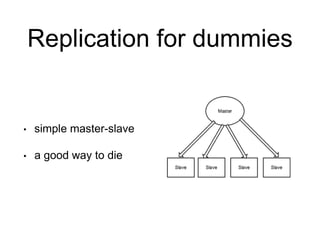
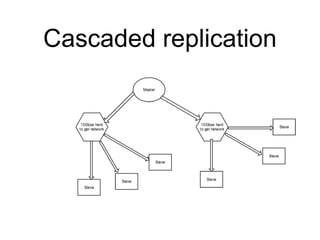














Skypicker is a flight ticket search and booking engine that processes hundreds of terabytes of airline data monthly and sells thousands of tickets daily in Europe, Russia, and China. It uses PostgreSQL extensively to power its API and databases. The document discusses Skypicker's PostgreSQL infrastructure, which includes 5 database clusters with over 0.5TB of memory each that handle 20 million updates per hour. It also covers optimizations made to scale the databases, such as table partitioning, cascading replication, and query tuning. Skypicker is currently preparing for a large increase in data and is hiring database masters and developers.

















































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)