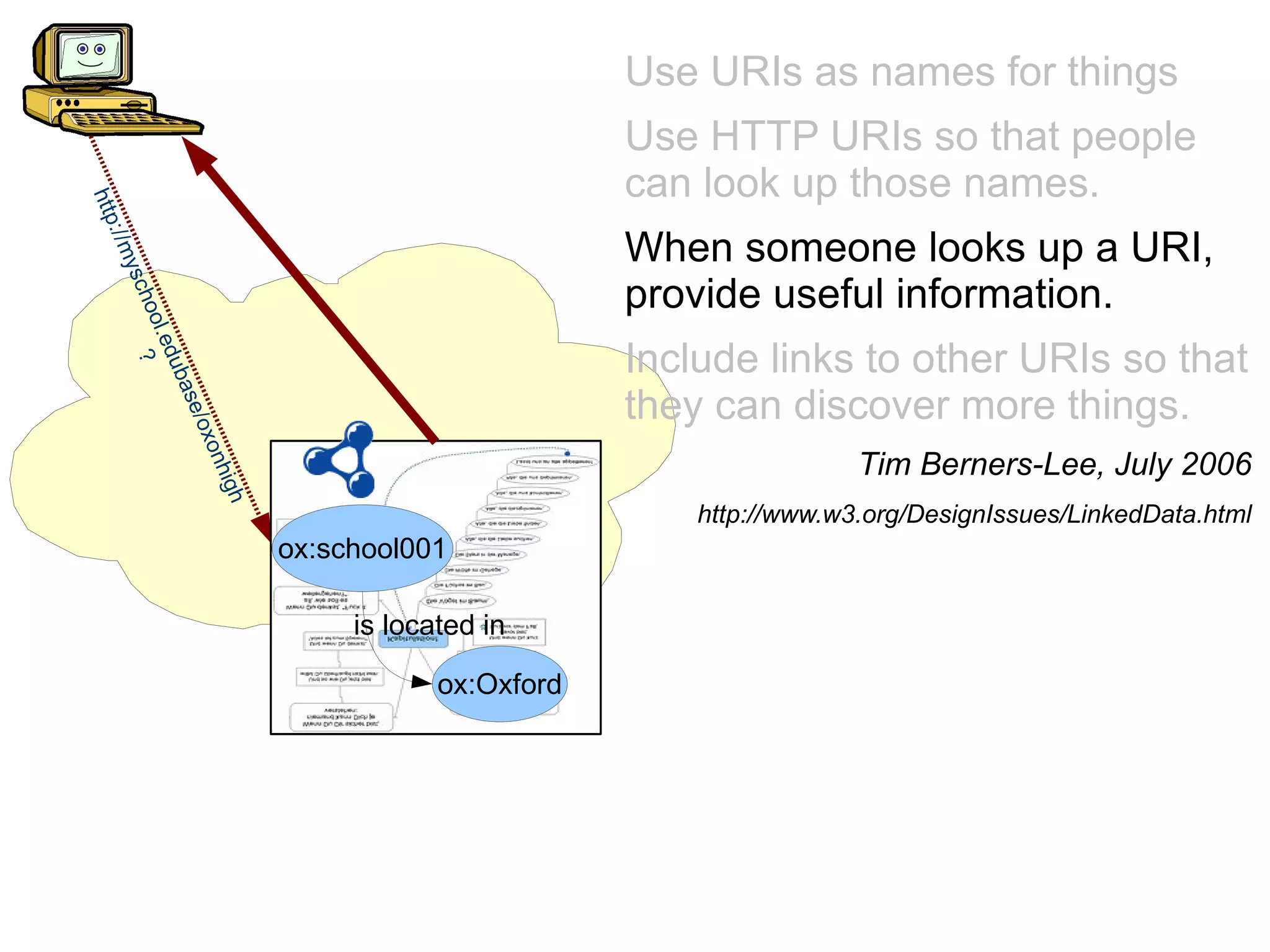
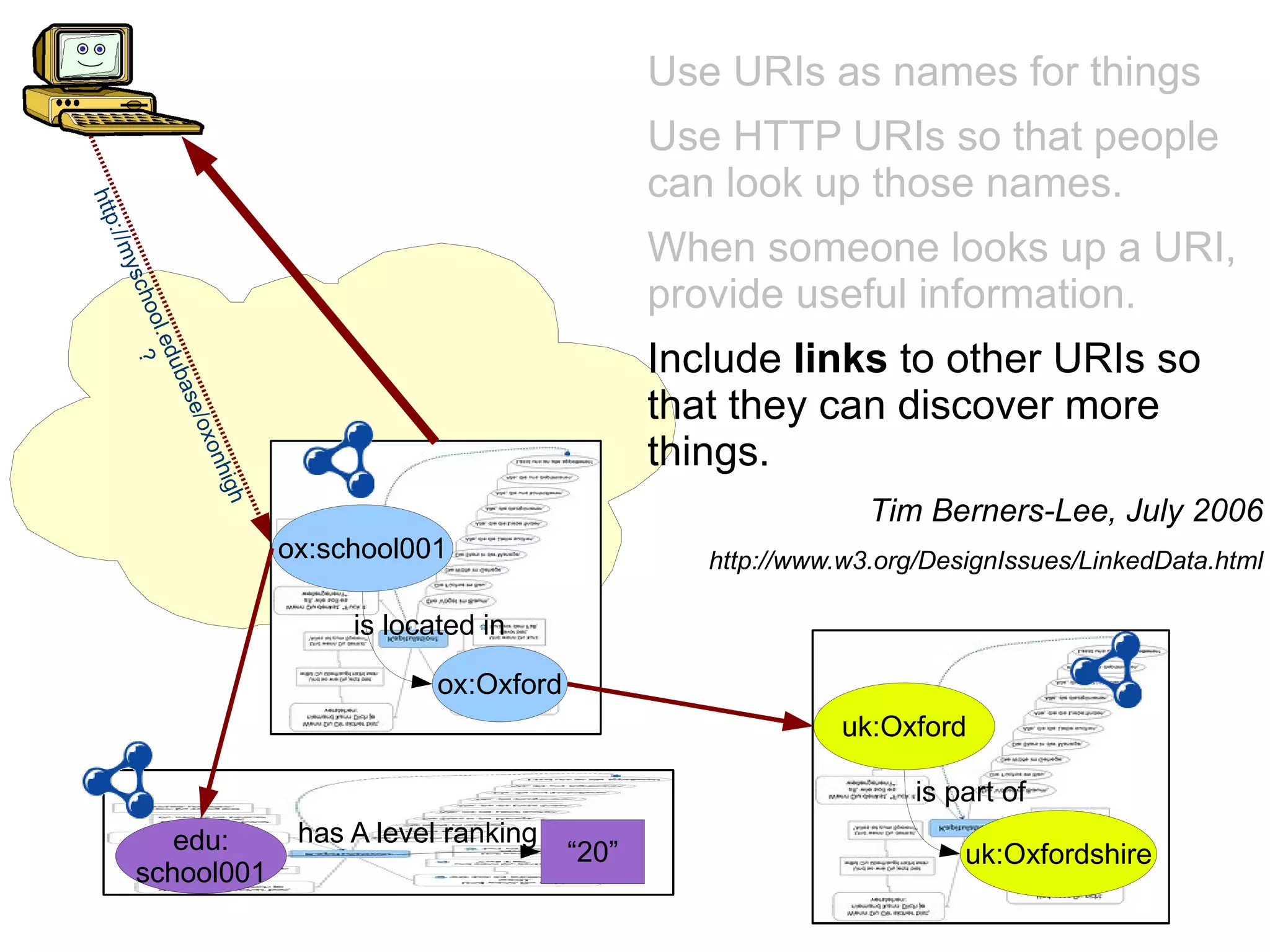
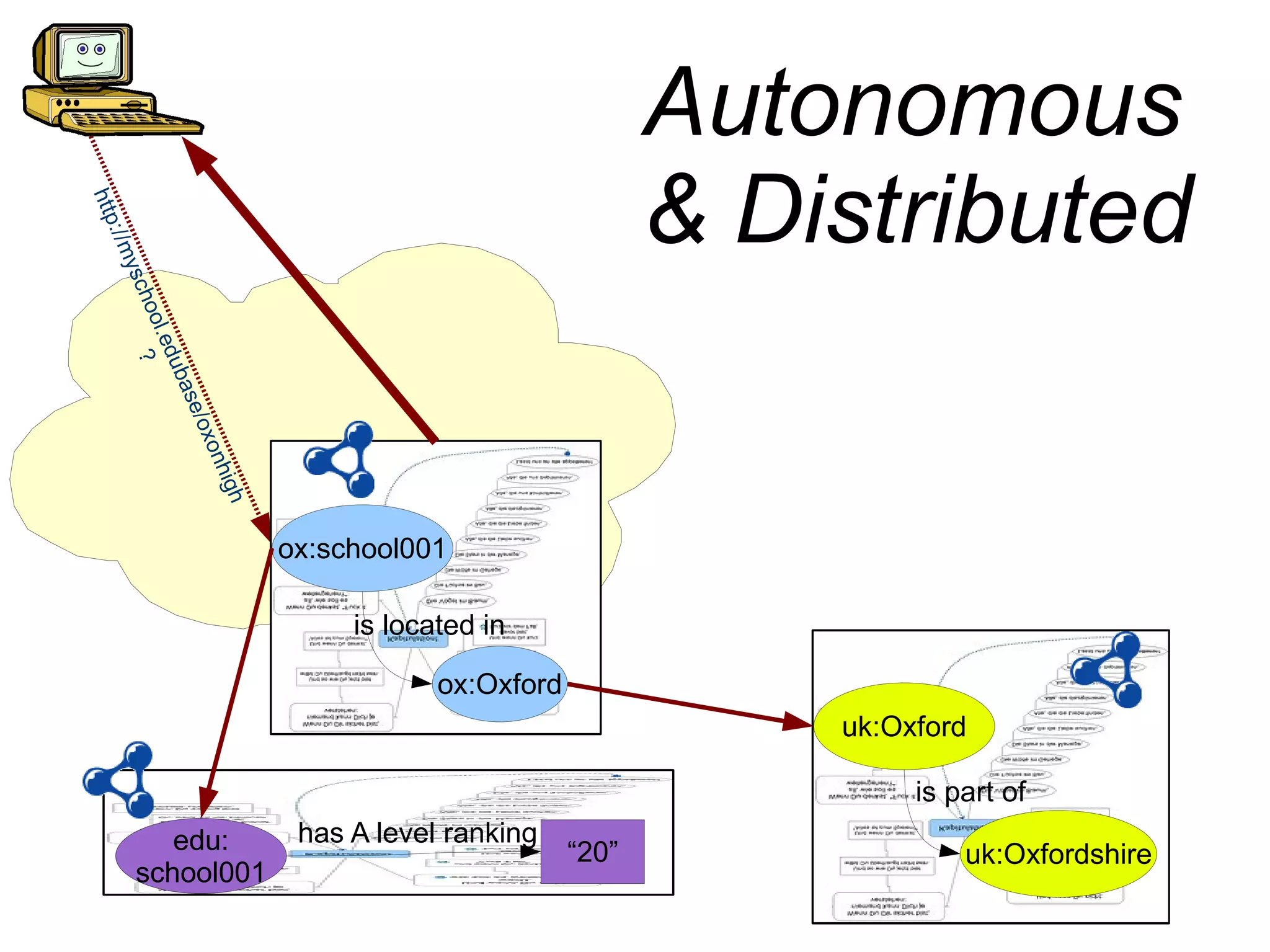
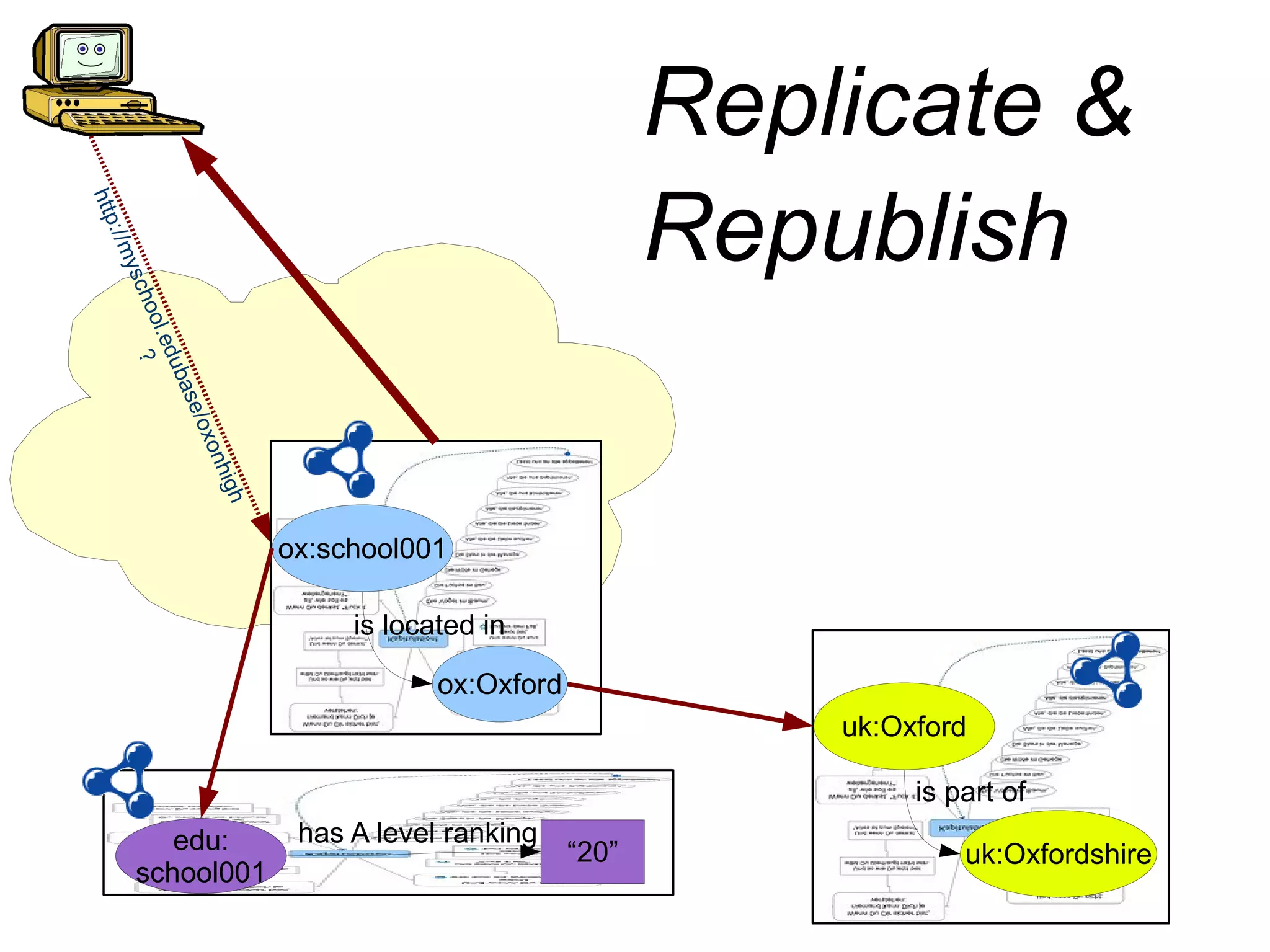
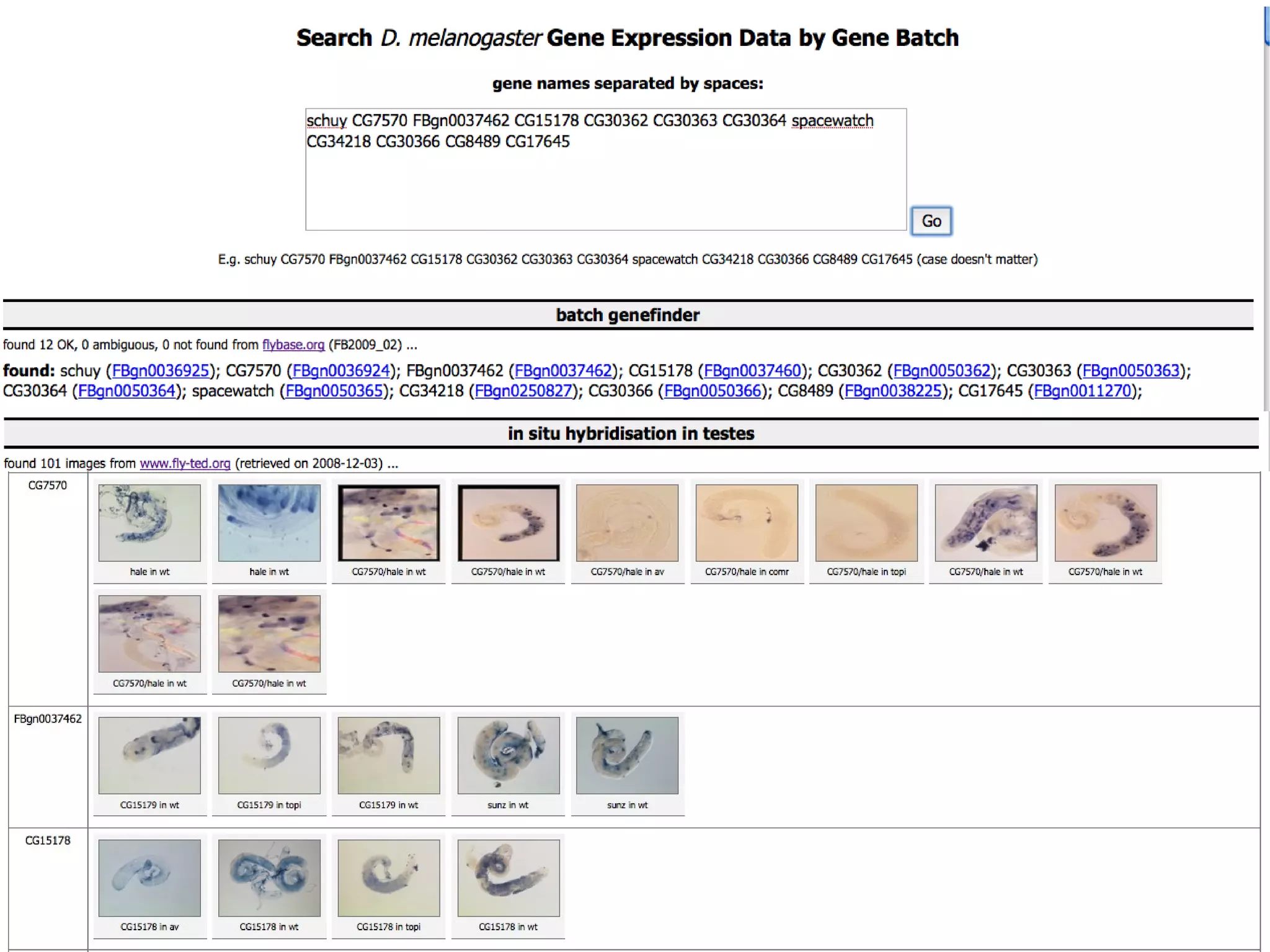
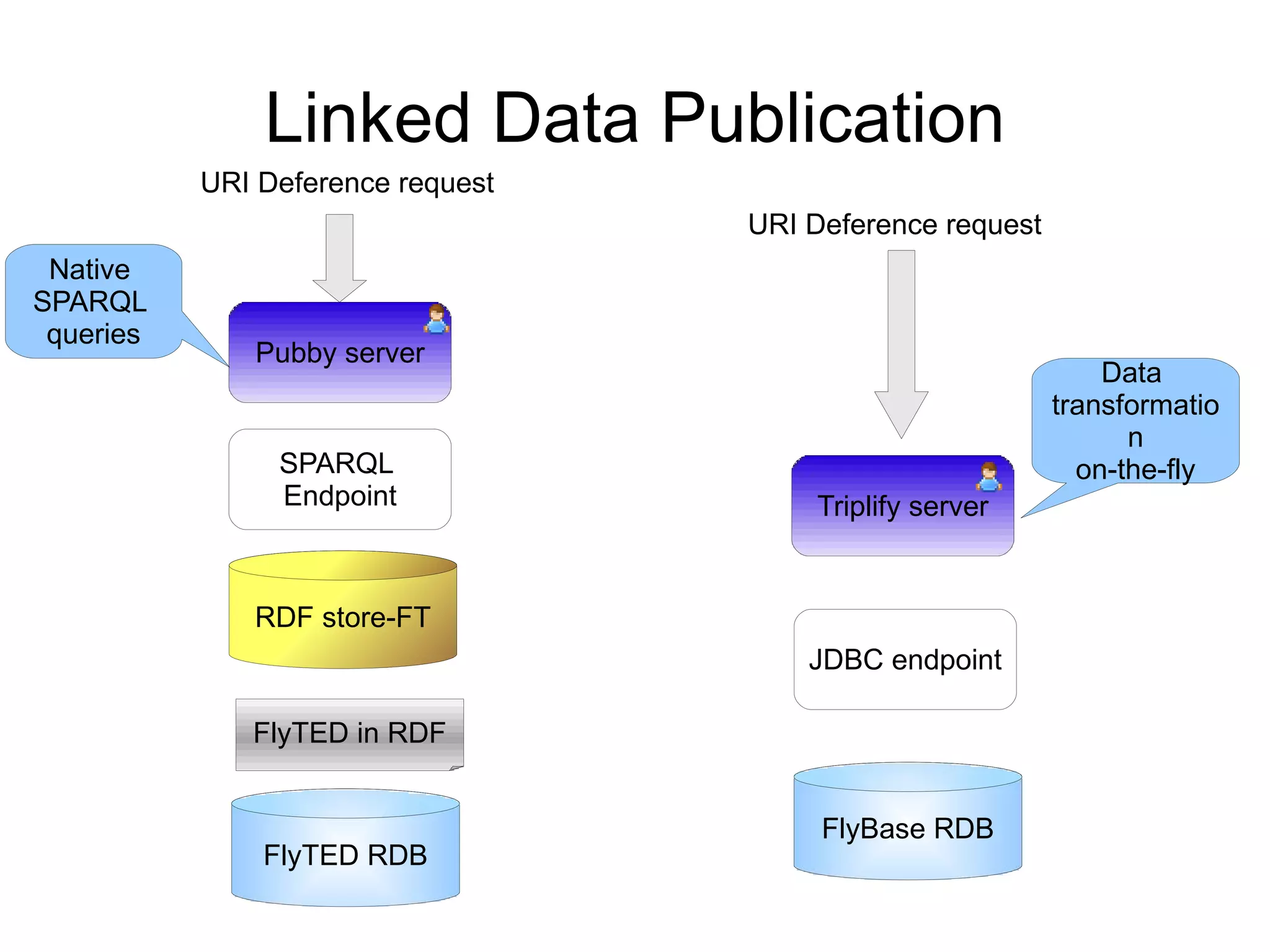
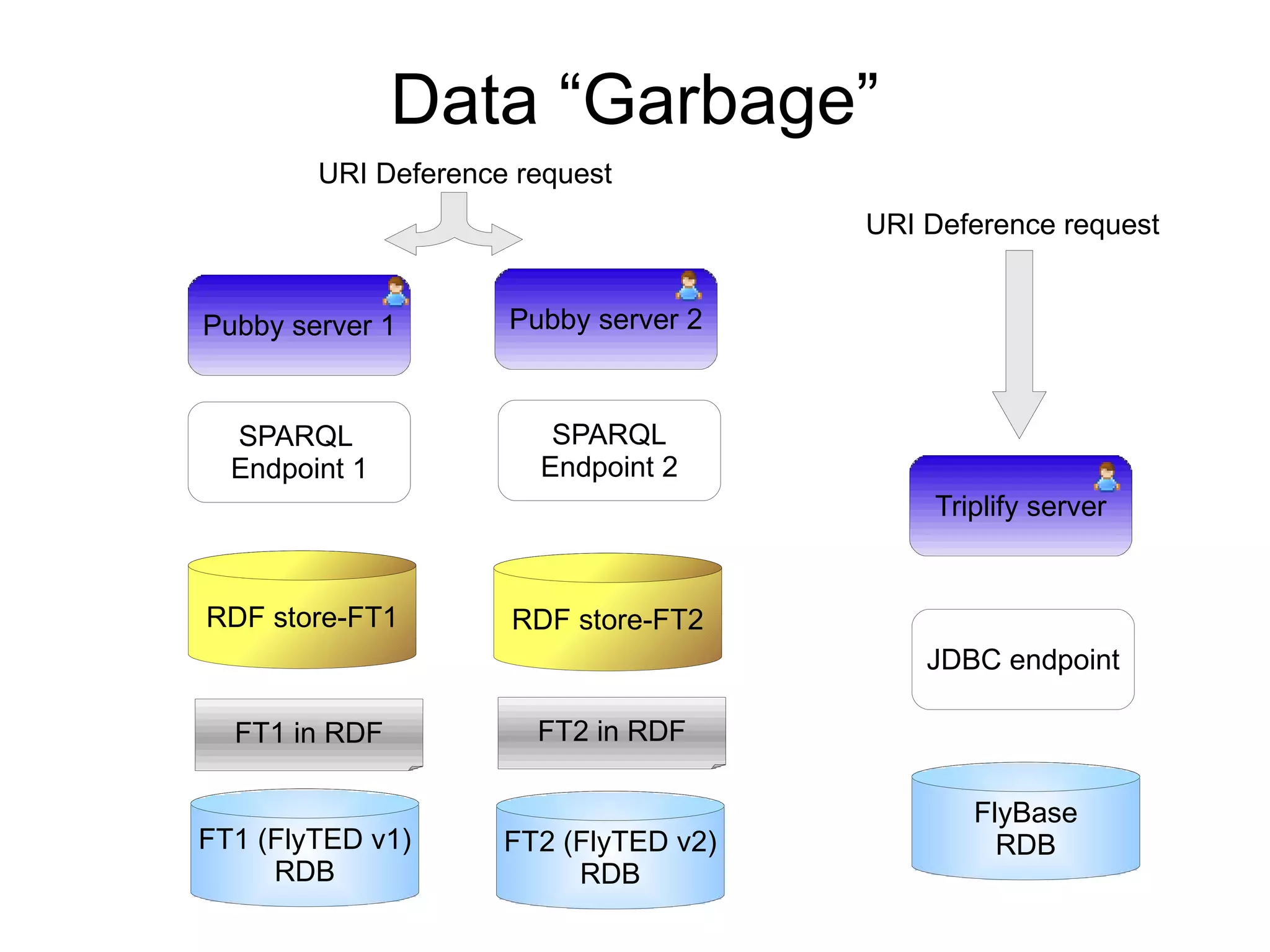
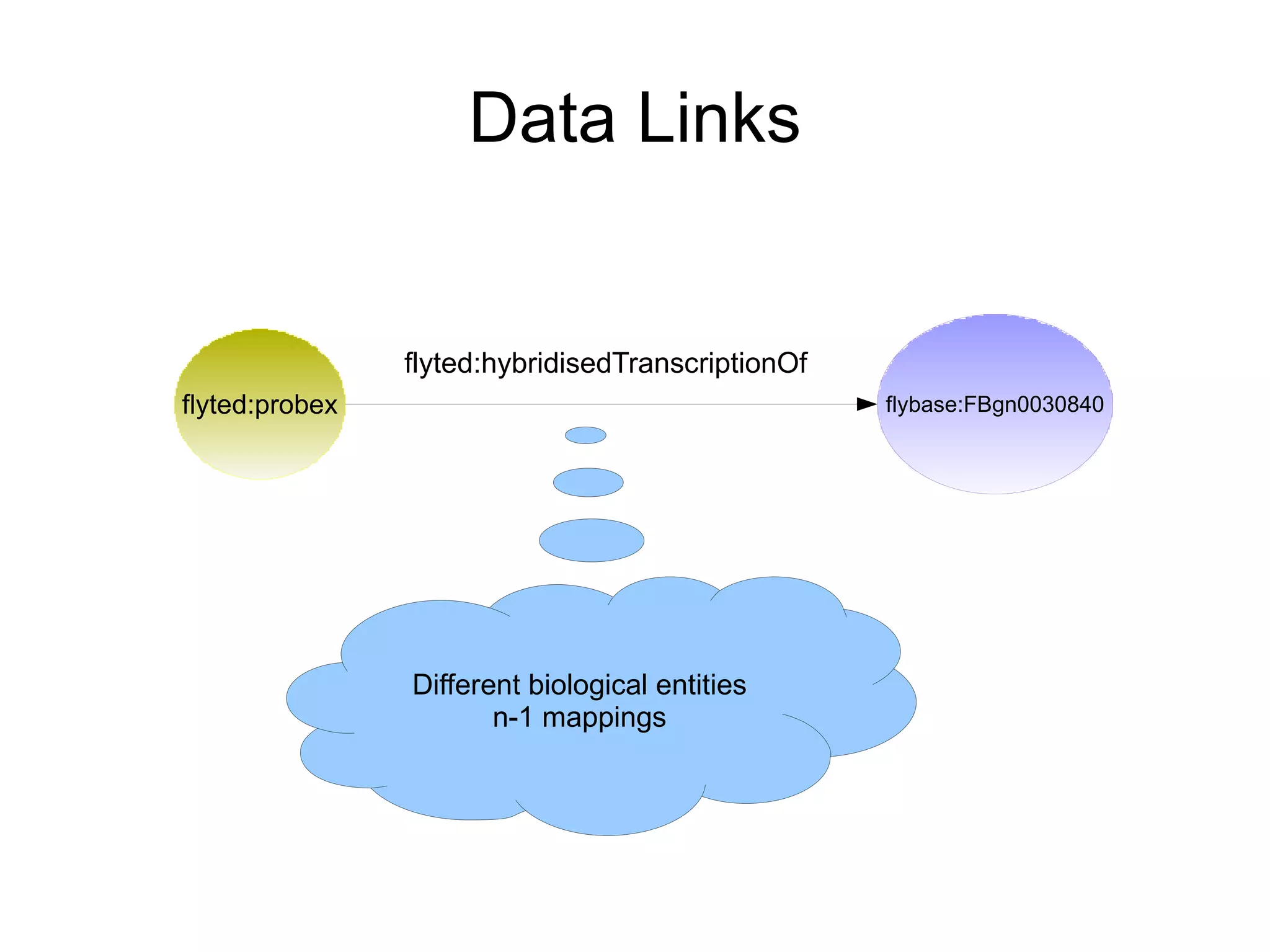
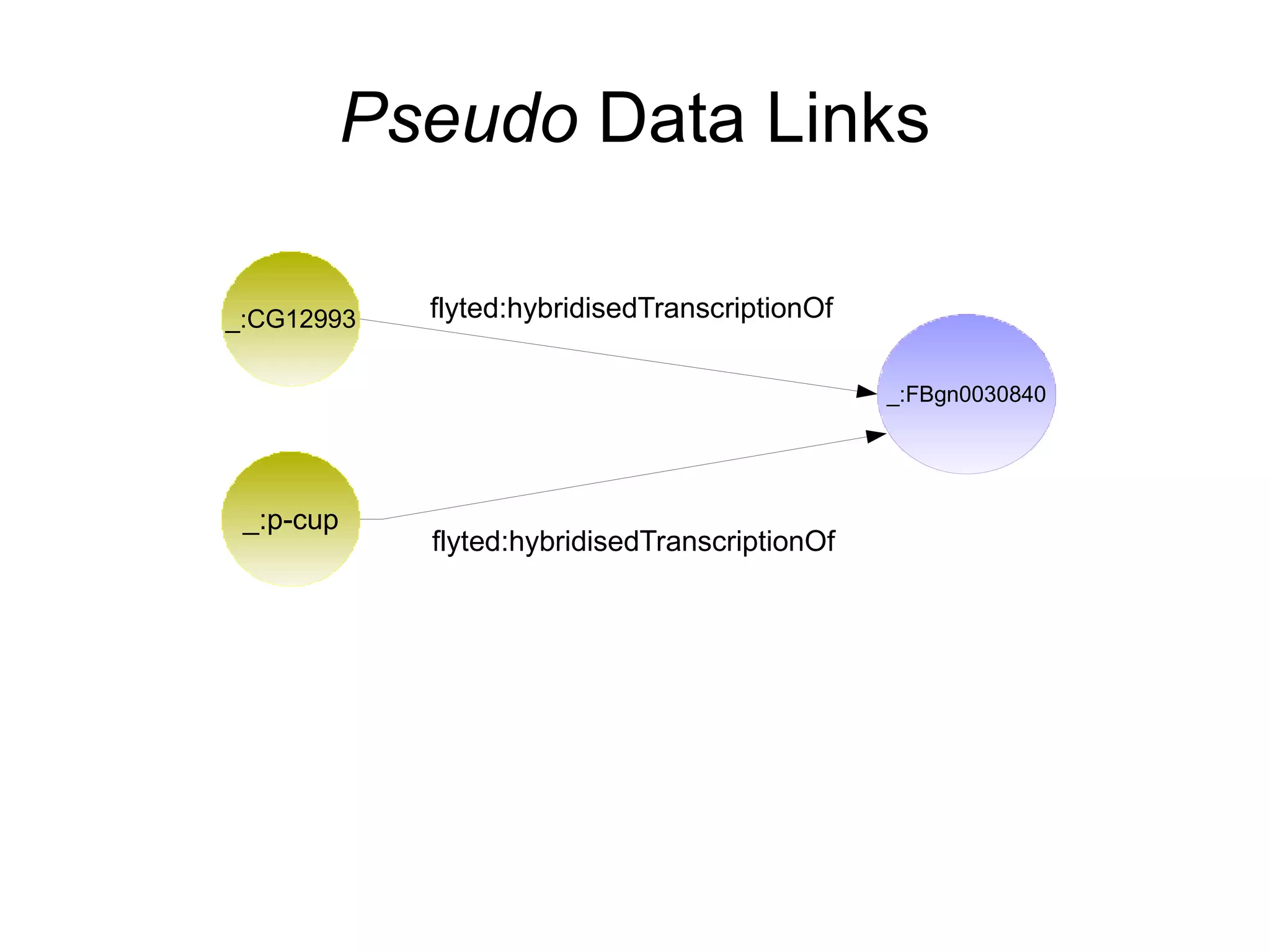
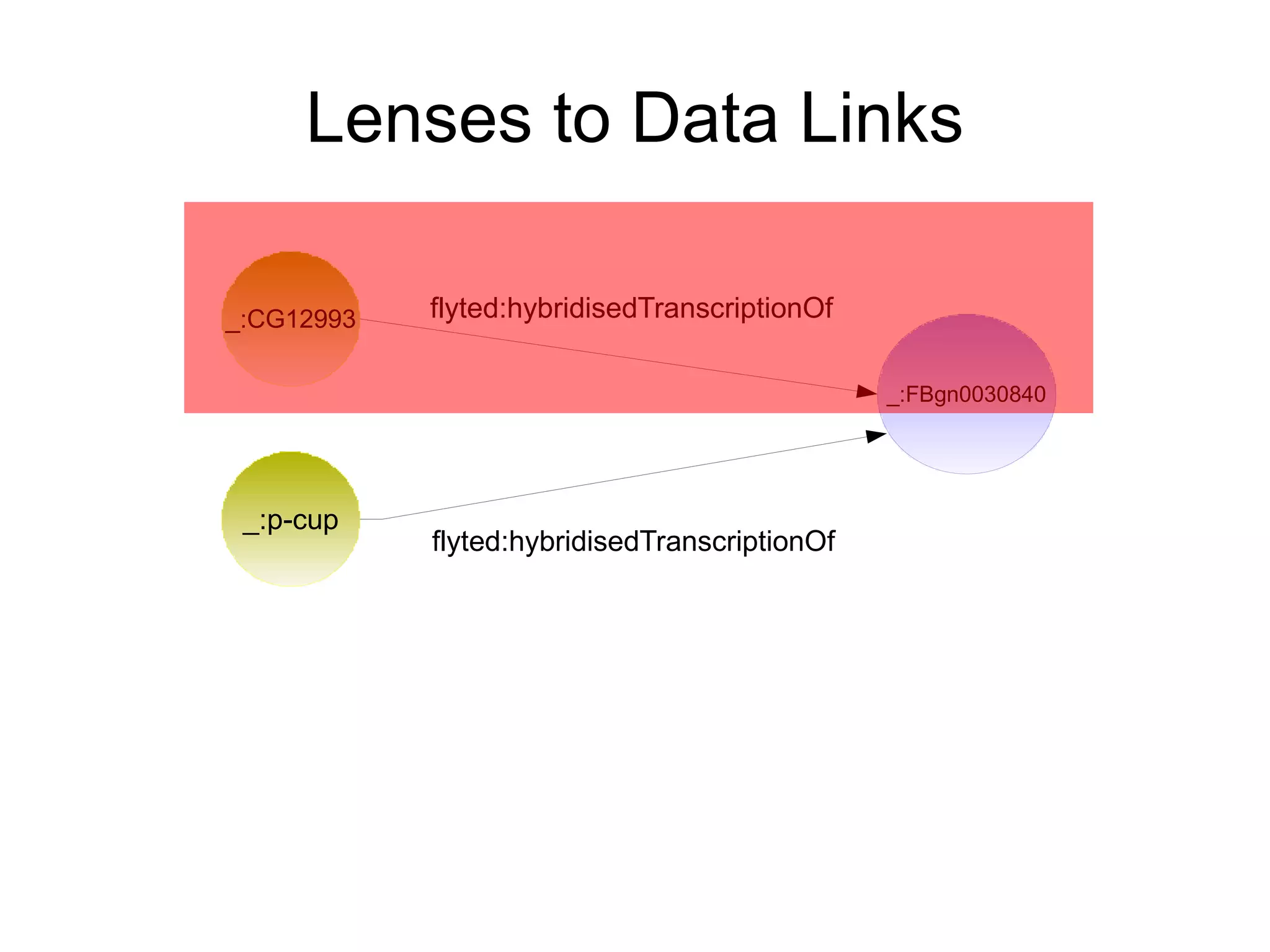
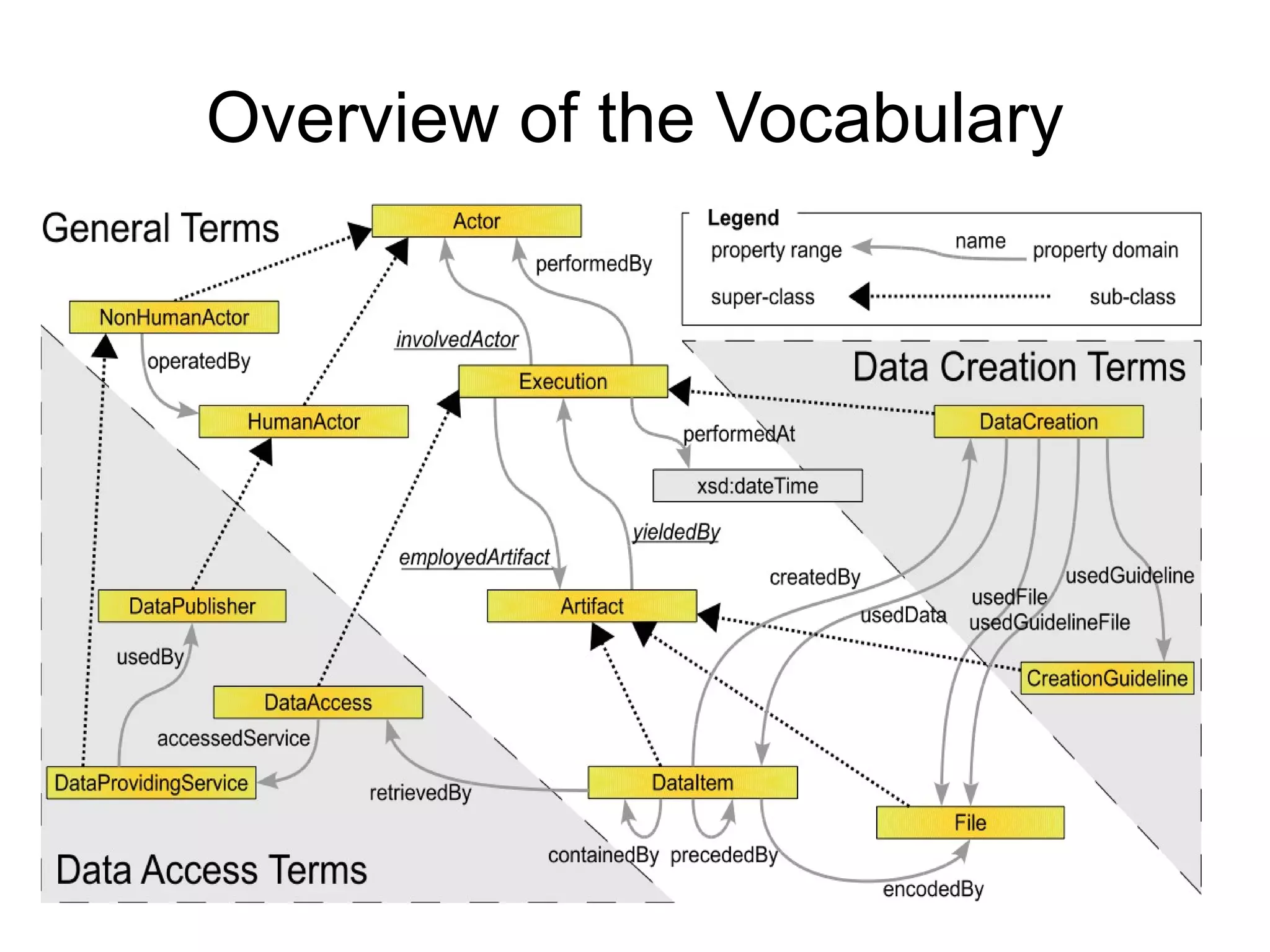
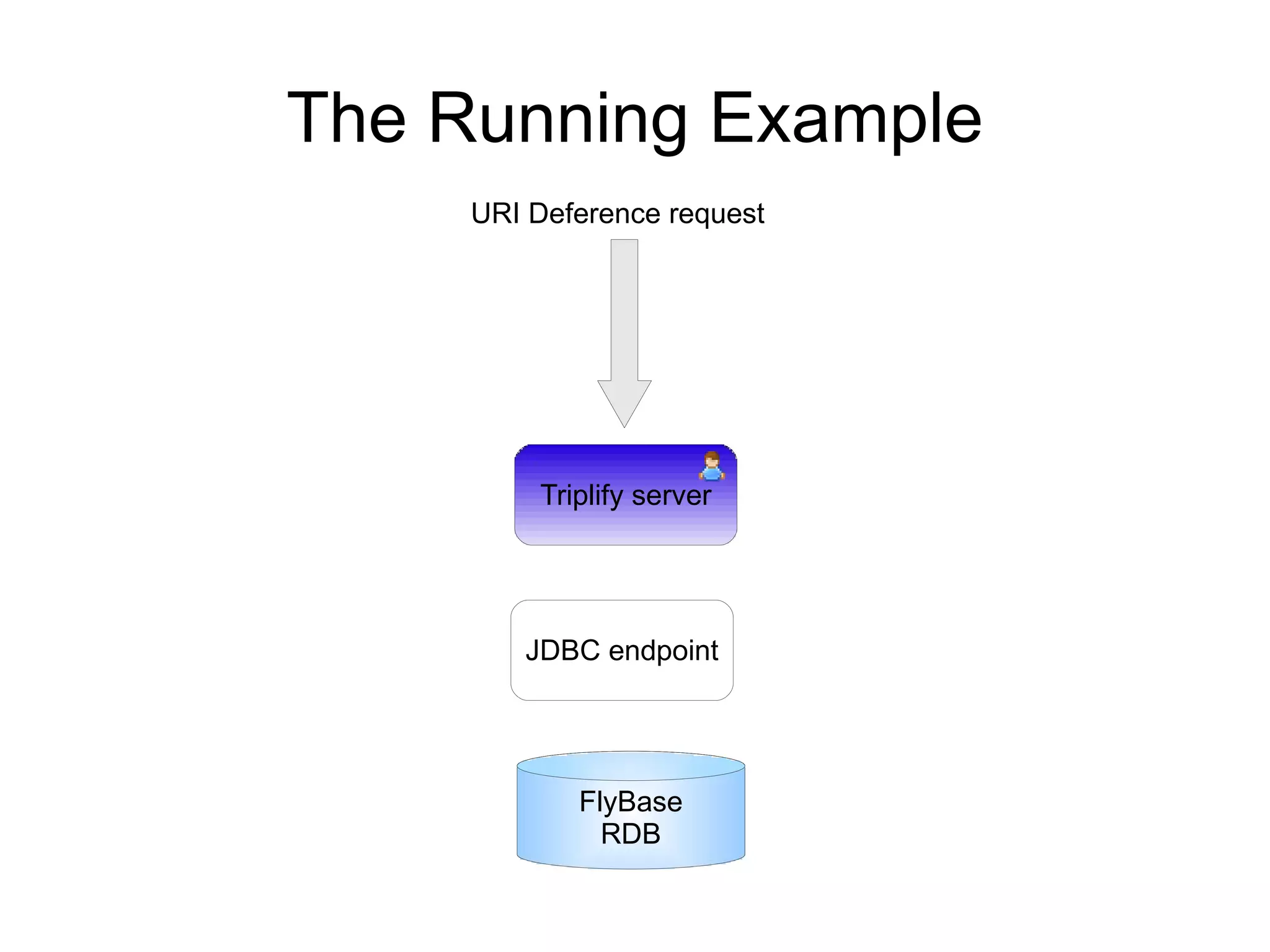
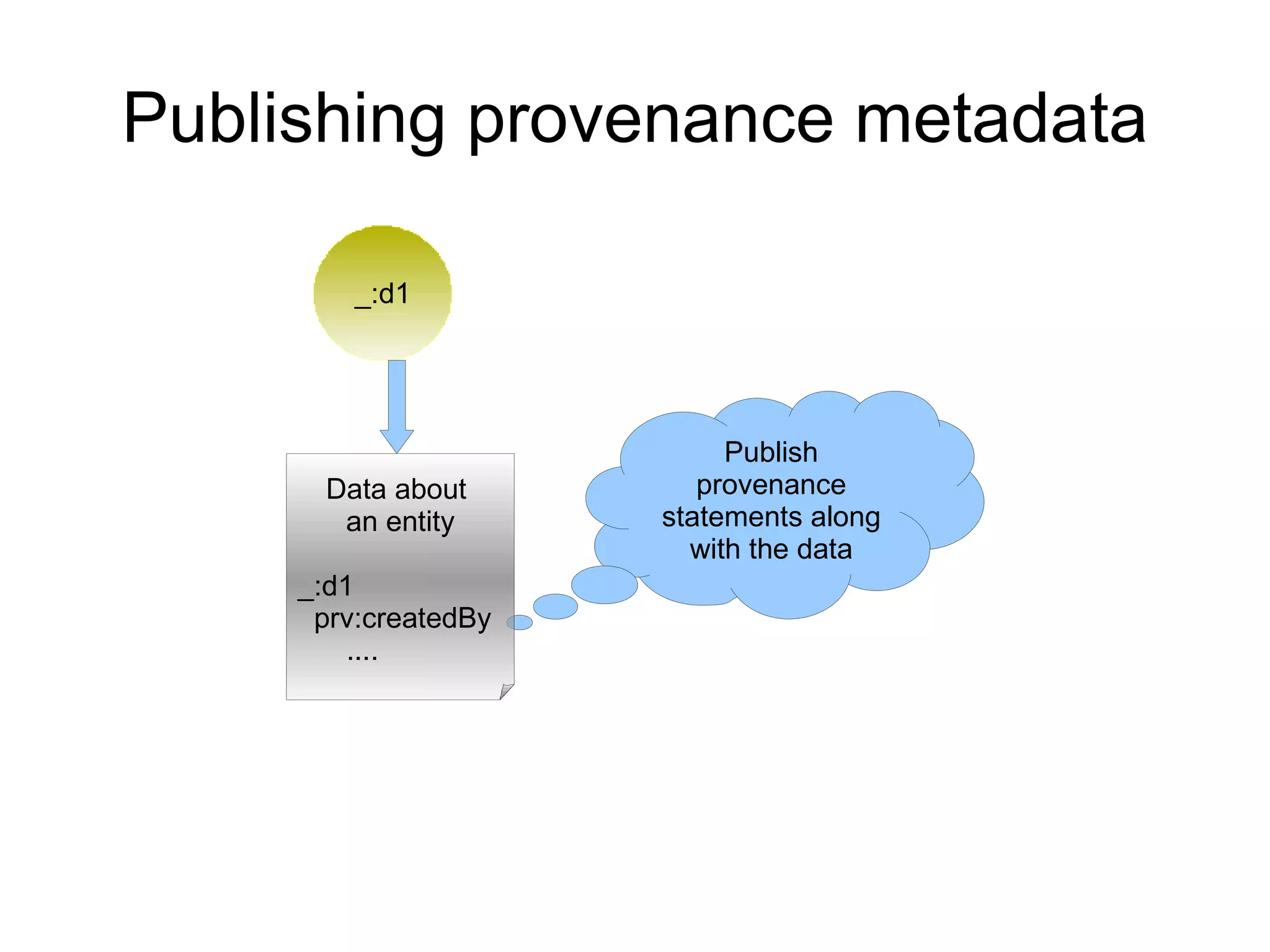
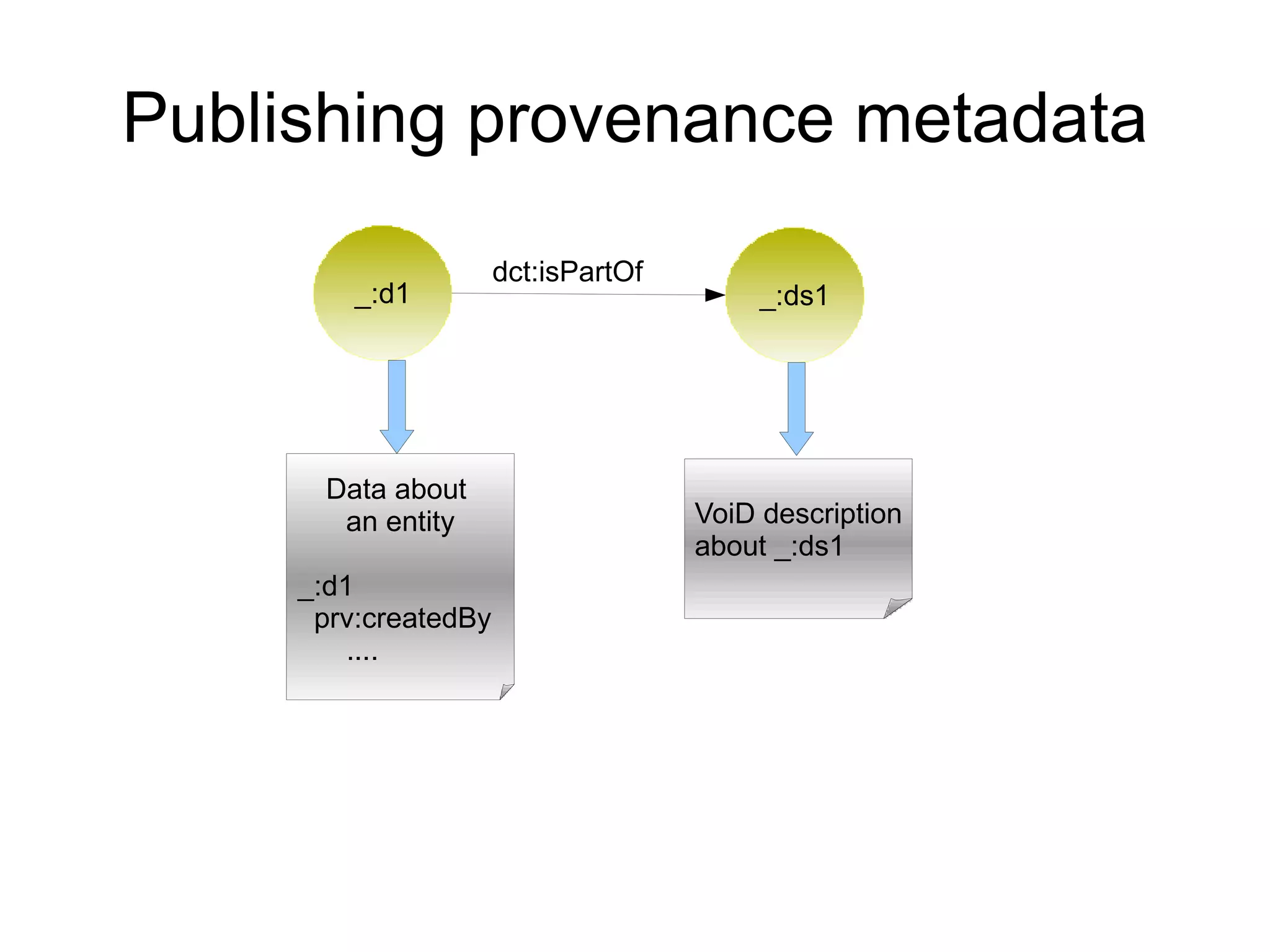
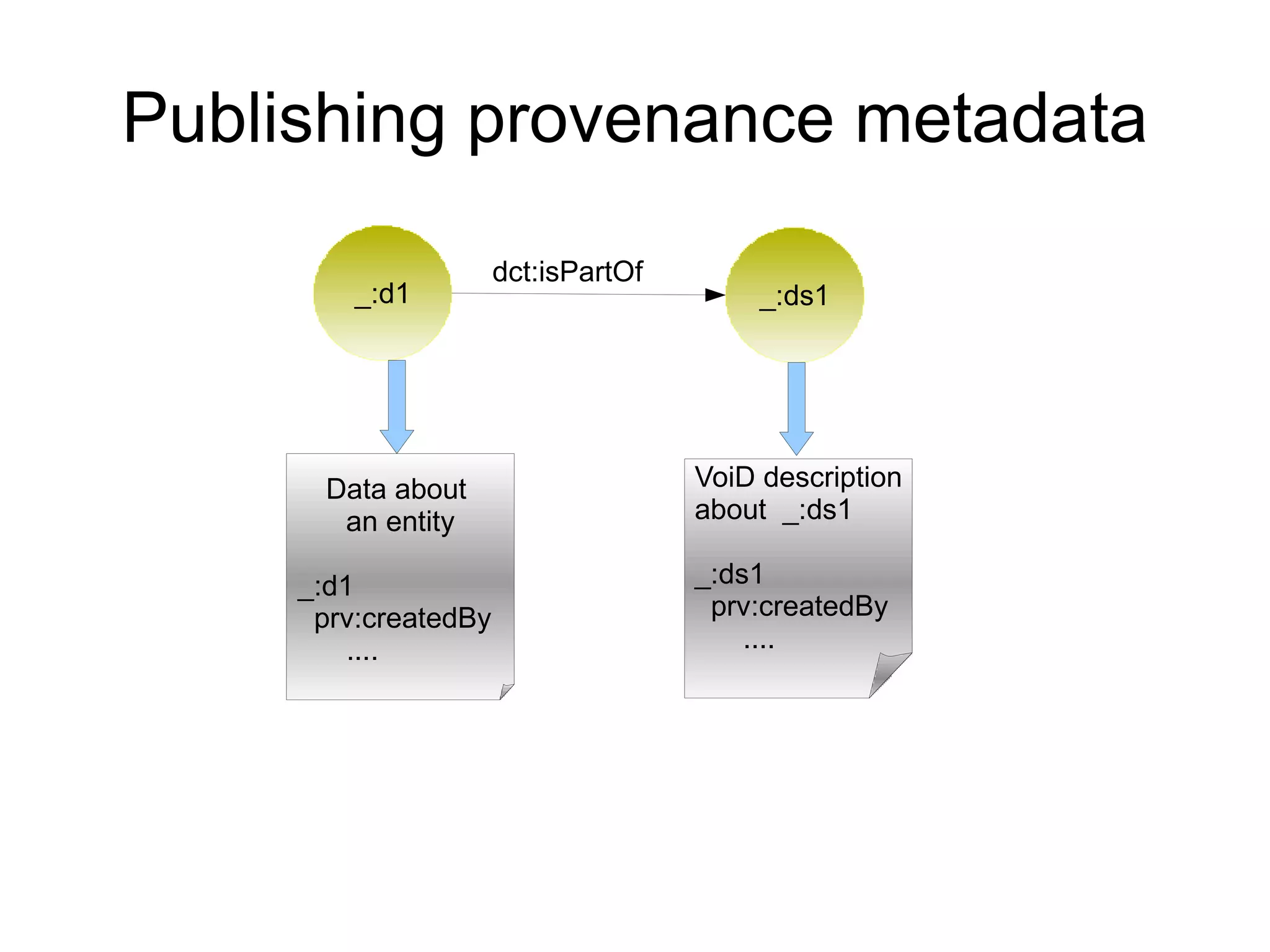
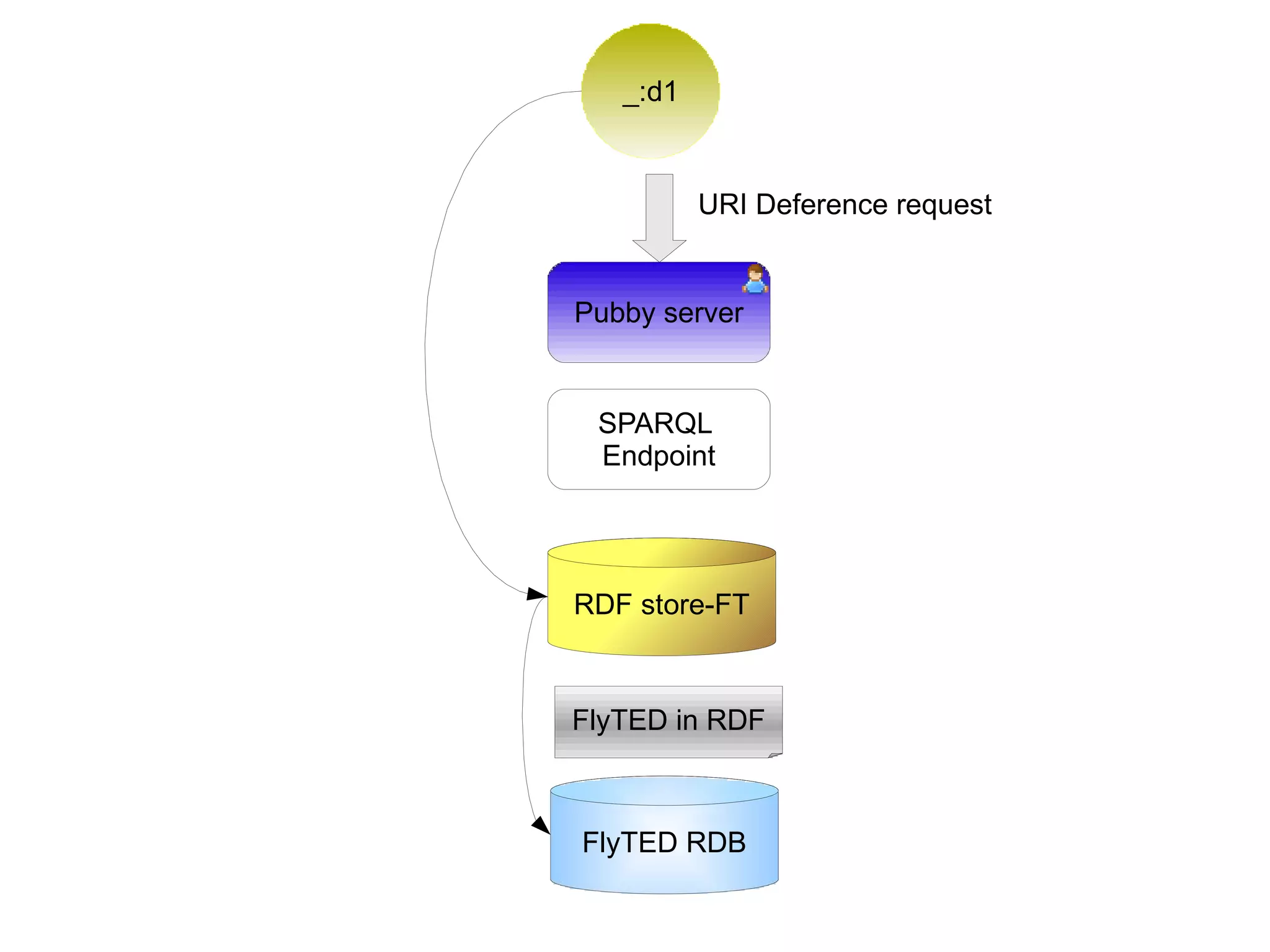
The document discusses the importance of publishing and consuming provenance metadata on the web of linked data, particularly focusing on using HTTP URIs for better accessibility and information quality assessment. It outlines the design principles and vocabulary necessary for integrating provenance metadata into linked data, emphasizing usability for developers and the importance of tracking data origin. The authors also highlight ongoing challenges, such as ensuring data quality and the need for alignment with other provenance vocabularies.