Downloaded 42 times

























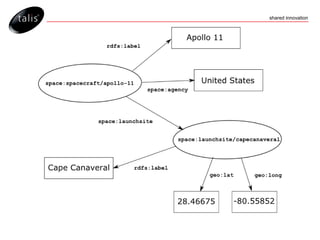







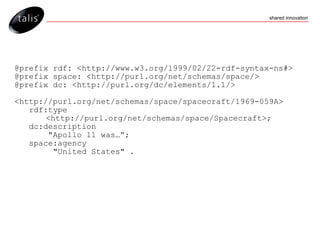





































![…as JSON { "head": { "vars": [ "name" , "agency" , "mass" ] } , "results": { "bindings": [ { "name": { "type": "literal" , "value": "Apollo 11 Command and Service Module (CSM)" } , "agency": { "type": "literal" , "value": "United States" } , "mass": { "type": "literal" , "value": "28801.0" } } , { "name": { "type": "literal" , "value": "Apollo 11 SIVB" } , "agency": { "type": "literal" , "value": "United States" } , "mass": { "type": "literal" , "value": "13300.0" } } , { "name": { "type": "literal" , "value": "Apollo 11 Lunar Module / EASEP" } , "agency": { "type": "literal" , "value": "United States" } , "mass": { "type": "literal" , "value": "15065.0" } } ] } }](https://image.slidesharecdn.com/getting-started-with-the-talis-platform-1229339721017114-2/85/Getting-Started-With-The-Talis-Platform-78-320.jpg)


![/items?query=[query] &max=[10] &offset=[0] &sort=[comma-separated fieldnames] &xsl=[XSLT stylesheet] &content-type=[mimetype for XSLT results]](https://image.slidesharecdn.com/getting-started-with-the-talis-platform-1229339721017114-2/85/Getting-Started-With-The-Talis-Platform-81-320.jpg)




![/services/facet?query=[query] &fields=[comma-separated fieldnames] &top=[10] &format=[xml|html]](https://image.slidesharecdn.com/getting-started-with-the-talis-platform-1229339721017114-2/85/Getting-Started-With-The-Talis-Platform-86-320.jpg)
















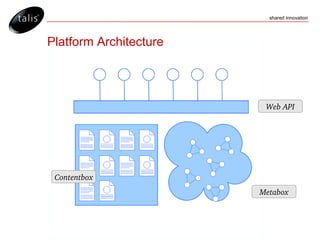
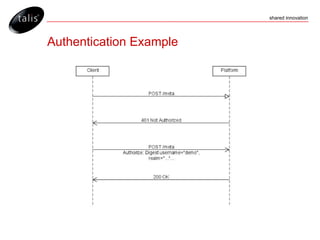
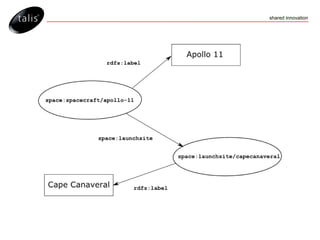
The document outlines the Talis platform, a software as a service solution for storing and managing both structured and unstructured data using RDF and SPARQL. It covers key concepts such as platform architecture, metadata management, and querying capabilities while emphasizing flexibility, standards compliance, and access control features. Additional details include content negotiation, data extraction methods, and the use of changesets for managing updates.




































































































