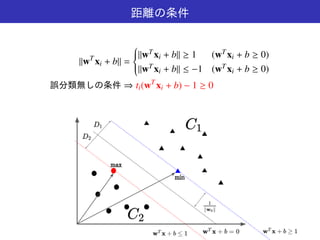
距離の条件
i 番目のデータと線形識別境界の距離を di、マージンをD、
クラスと正解ラベルの対応は (C1,C2) = (ti = 1, tj = −1)
di =
||wT xi + b||
||w||
≥ D ⇒
||wT xi + b||
||w||
||w|| ≥ D||w|| ∵ D||w|| = κ
⇒ ||wT
xi + b|| ≥ κ
⇒ ||wT
xi + b|| ≥ 1 ∵ w =
w
κ
, b =
b
κ
⇒
||wT xi + b|| ≥ 1 (wT xi + b ≥ 0)
||wT xi + b|| ≤ −1 (wT xi + b ≥ 0)
誤分類無しの条件 ⇒ ti(wT
xi + b) ≥ 1
6.
距離の条件
||wT
xi + b||=
||wT xi + b|| ≥ 1 (wT xi + b ≥ 0)
||wT xi + b|| ≤ −1 (wT xi + b ≥ 0)
誤分類無しの条件 ⇒ ti(wT
xi + b) − 1 ≥ 0
7.
マージン最大化条件
クラスそれぞれのサポートベクトルまでの距離→マージン D1, D2
ρ= D1 + D2 = min
i
di + min
j
dj
i ∈ {C1の添字集合 }
j ∈ {C2の添字集合 }
=
||wT xS V1 + b||
||w||
+
||wT xS V2 + b||
||w||
xS V1 ∈ C1
xS V2 ∈ C2
=
2
||w||
マージンを最大化するような重みとバイアスを w0, b0 とおくと、マージン
最大化の式は
ρ(w0, b0) = max
w,b
ρ(w, b) = max
w
2
||w||
∝ max
w
1
||w||
8.
マージン最大化条件
マージン最大化の式を変形していくと
ρ(w0, b0) ⇒max
w
2
||w||
⇒ max
w
1
||w||
⇒ min
w
||w||
⇒ min
w
1
2
||w||2
⇒ min
w
1
2
wT
w
マージン最大化条件は次のように書き直せる。
max
w,b
ρ(w, b) ⇒ min
w
1
2
wT
w
9.
ハードマージン SVM 主問題
不等式制約条件最適化問題の主問題
minimizef(w) =
1
2
wT
w
subject to gi(w, b) = tt(wT
x + b) − 1 ≥ 0 (i = 1, · · · , N)
最適化の対象となる評価関数 f(w) と不等式制約条件 gi(w, b) の二つから新
たな関数を導入する→ラグランジュ関数
ラグランジュ関数
minimize L(w, b, α) =
1
2
wT
w −
N∑
i=1
αi(tt(wT
x + b) − 1)
subject to αi ≥ 0 (αiラグランジュ未定乗数)
非線形変換:カーネル関数
双対問題
maxmize −
1
2
N∑
i=1
N∑
j=1
αitiαjtjK(xj,xi) +
N∑
i=1
αi
subject to αT
t = 0, C ≥ αi ≥ 0
具体的なカーネル関数の例
ユークリッド内積 K(u, v) = uT
v
多項式カーネル Kp(u, v) = (α + uT
v)p
(α ≥ 0)
動径基底関数カーネル Kσ(u, v) = exp
(
−
||u − v||2
2σ2
)
(σ 0)
カーネル関数はよく分からない。詳しくは再生核ヒルベルト空間、正定値
カーネル
56.
非線形変換:多項式カーネル
多項式カーネル
Kp(u, v)= (α + uT
v)p
(α ≥ 0)
α = 1, p = 2, u = (u1, u2), v = (v1, v2) として上記カーネルを展開
K2(u, v) = (1 + uT
v)2
= (1 + u1v1 + u2v2)2
= 1 + u2
1v2
1 + 2u1u2v1v2 + u2
2v2
2 + 2u1v1 + 2u2v2
= φ(u)T
φ(v)
φ(u) = (1, u2
1,
√
2u1u2, u2
2, u2
2,
√
2u1,
√
2u2)T
φ(v) = (1, v2
1,
√
2v1v2, v2
2, v2
2,
√
2v1,
√
2v2)T
57.
非線形変換:多項式カーネル
多項式カーネル
Kp(u, v)= (α + uT
v)p
(α ≥ 0)
右辺に二項定理を適用。
二項定理 (a + b)n
=
n∑
k=0
(
n
k
)
ak
bn−k
=
n∑
k=0
nCkak
bn−k
a = uT v, b = α と置けば
Kp(u, v) = (α + uT
v)p
=
p∑
i=0
(
p
i
)
αp−i
(uT
v)i
58.
非線形変換:多項式カーネル
多項式カーネル
Kp(u, v)= (α + uT
v)p
(α ≥ 0)
多項式カーネルによる非線形特徴空間の次元 D(d, p) は
D(d, p) =
(
d + p
p
)
入力の次元 d = 1、多項式カーネルの次数 p = 1 のそれぞれの場合
D(d = 1, p) =
(
1 + p
p
)
D(d, p = 1) =
(
d + p
1
)
次に入力の次元 d − 1、多項式カーネルの次数 p − 1 のそれぞれ一般的な場合
D(d − 1, p) =
(
d − 1 + p
p
)
D(d, p − 1) =
(
d + p − 1
p − 1
)
59.
非線形変換:多項式カーネル
多項式カーネル
Kp(u, v)= (α + uT
v)p
(α ≥ 0)
二項係数を適用することで入力の次元 d、多項式カーネルの次数 p の時の非
線形特徴空間の次元が仮定と同形式になる。
二項係数
(
n
k
)
=
(
n − 1
k
)
+
(
n − 1
k − 1
)
入力の次元 d − 1、多項式カーネルの次数 p − 1 のそれぞれ一般的な場合
D(d, p) = D(d − 1, p) + D(d, p − 1) =
(
d − 1 + p
p
)
+
(
d + p − 1
p − 1
)
=
(
d + p
p
)
例:d = 16 × 16, p = 4 の時、
D(16 × 16, 4) =
260!
(260 − 4)!4!
= 186043585
双対な例:双対グラフ
ルジャンドル変換
凸関数である関数 f(x)(x∈ R) に対して次のように定義される関数を
f(x) のルジャンドル変換であるという。
g(p) := max
x
(px − f(x))
例:全微分可能で、その一回微分が狭義凸関数であるような
1 変数関数 f(x) を考える。
d f =
∂ f
∂x
dx = pdx
p を変数とする関数を考え、全微分する。
g(p) = px − f(x) ⇒ dg = pdx − d f = pdx + xdp − pdx
= xdp
これにより、 f(x) を考える代わりに等価な g(p) を考えることでいろいろで
きるようになる。
65.
参考資料
非線形最適化の基礎/福島雅夫/2017 年 11月 25 日第 14 刷
はじめてのパターン認識/平井有三/2018 年 8 月 20 日第 1 版第 9 刷
SMO 徹底入門:
https://www.slideshare.net/sleepy_yoshi/smo-svm
Fast Training of Support Vector Machines using Sequential Minimal
Optimization /John C. Platt/ Microsoft Research 1 Microsoft Way,
Redmond, WA 98052
Convex Optimization/Stephen Boyd et al./
https://web.stanford.edu/~boyd/cvxbook/bv_cvxbook.pdf





























![ソフトマージン SVM スラック変数
線形分離不可能な場合の制約条件
上手く分類できなかったデータを分類できるような補正項を導入
gi(w, b) = ti(wT
xi + b) + ξi ≥ 1
スラック変数 ⇒
ξi = 0
0 ξi ≤ 1
ξi 1
ξi = max[0, 1 − ti(wT
xi + b)] =
ξ = 0 ⇐ 1 ≤ ti(wT xi + b)
0 ξi ≤ 1 ⇐ 0 ti(wT xi + b) ≤ 1
ξi 1 ⇐ 0 ti(wT xi + b)
0 より小さい場合は 0、大きい場合はその値を返す→ヒンジ関数](https://image.slidesharecdn.com/svm1-190912003925/85/8-31-320.jpg)














































































![Infinite SVM [改] - ICML 2011 読み会](https://cdn.slidesharecdn.com/ss_thumbnails/isvm-icml11a-110719050617-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


